 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Localize, Group, and Select: Boosting Text-VQA by Scene Text Modeling
Aug 20, 2021

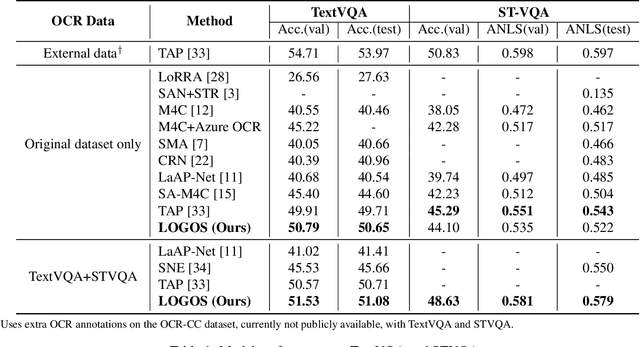
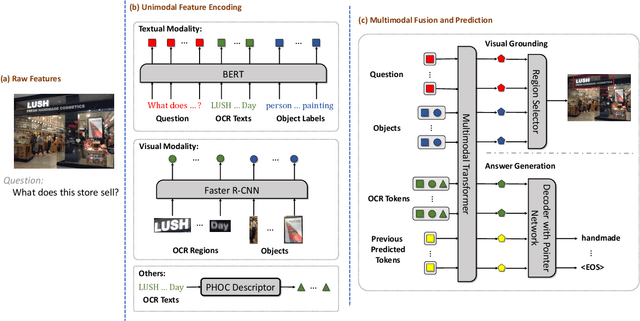
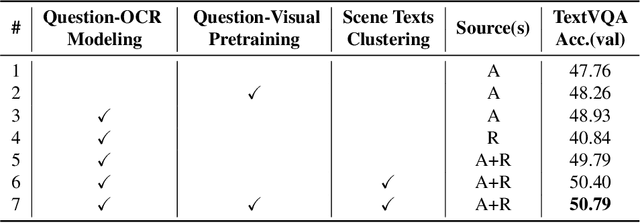
As an important task in multimodal context understanding, Text-VQA (Visual Question Answering) aims at question answering through reading text information in images. It differentiates from the original VQA task as Text-VQA requires large amounts of scene-text relationship understanding, in addition to the cross-modal grounding capability. In this paper, we propose Localize, Group, and Select (LOGOS), a novel model which attempts to tackle this problem from multiple aspects. LOGOS leverages two grounding tasks to better localize the key information of the image, utilizes scene text clustering to group individual OCR tokens, and learns to select the best answer from different sources of OCR (Optical Character Recognition) texts. Experiments show that LOGOS outperforms previous state-of-the-art methods on two Text-VQA benchmarks without using additional OCR annotation data. Ablation studies and analysis demonstrate the capability of LOGOS to bridge different modalities and better understand scene text.
Digging into Uncertainty in Self-supervised Multi-view Stereo
Sep 08, 2021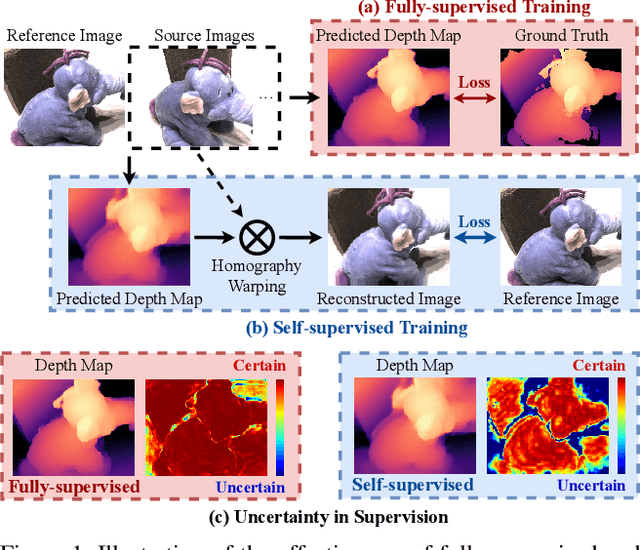
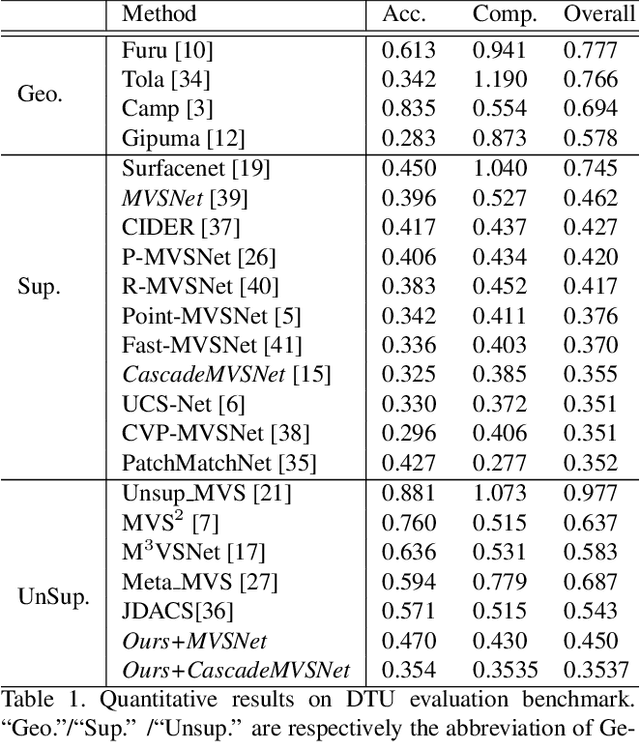
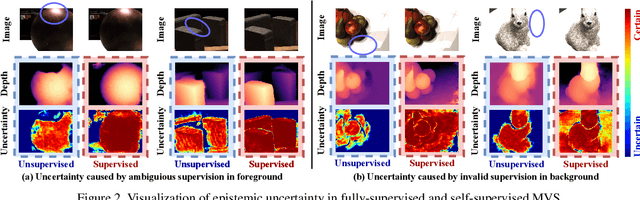
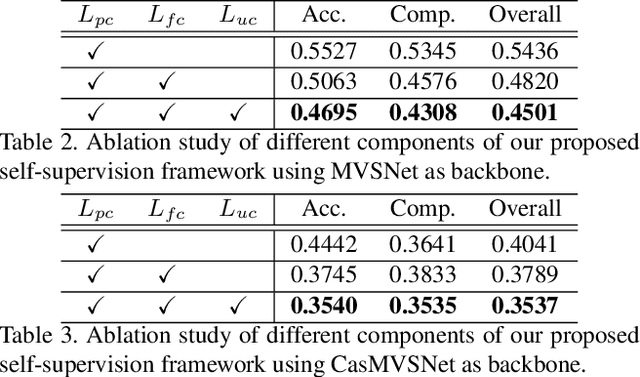
Self-supervised Multi-view stereo (MVS) with a pretext task of image reconstruction has achieved significant progress recently. However, previous methods are built upon intuitions, lacking comprehensive explanations about the effectiveness of the pretext task in self-supervised MVS. To this end, we propose to estimate epistemic uncertainty in self-supervised MVS, accounting for what the model ignores. Specially, the limitations can be categorized into two types: ambiguious supervision in foreground and invalid supervision in background. To address these issues, we propose a novel Uncertainty reduction Multi-view Stereo (UMVS) framework for self-supervised learning. To alleviate ambiguous supervision in foreground, we involve extra correspondence prior with a flow-depth consistency loss. The dense 2D correspondence of optical flows is used to regularize the 3D stereo correspondence in MVS. To handle the invalid supervision in background, we use Monte-Carlo Dropout to acquire the uncertainty map and further filter the unreliable supervision signals on invalid regions. Extensive experiments on DTU and Tank&Temples benchmark show that our U-MVS framework achieves the best performance among unsupervised MVS methods, with competitive performance with its supervised opponents.
Aligning Linguistic Words and Visual Semantic Units for Image Captioning
Aug 06, 2019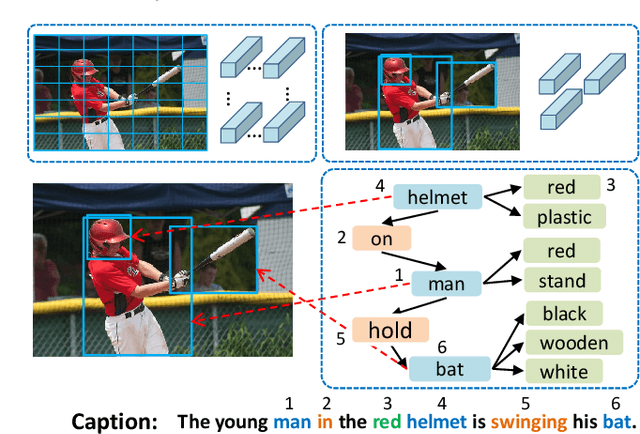
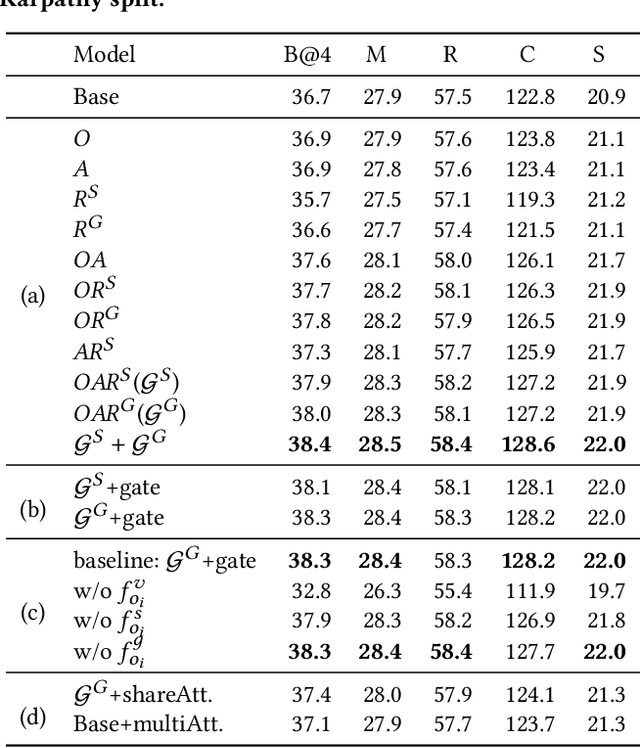
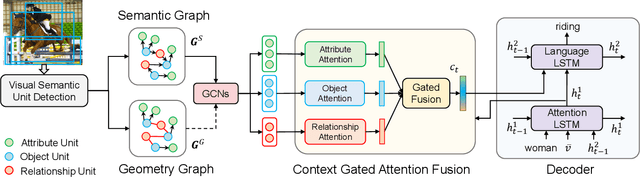
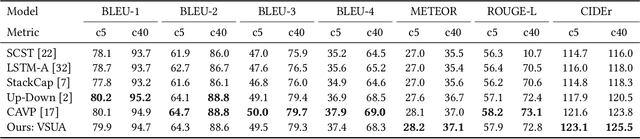
Image captioning attempts to generate a sentence composed of several linguistic words, which are used to describe objects, attributes, and interactions in an image, denoted as visual semantic units in this paper. Based on this view, we propose to explicitly model the object interactions in semantics and geometry based on Graph Convolutional Networks (GCNs), and fully exploit the alignment between linguistic words and visual semantic units for image captioning. Particularly, we construct a semantic graph and a geometry graph, where each node corresponds to a visual semantic unit, i.e., an object, an attribute, or a semantic (geometrical) interaction between two objects. Accordingly, the semantic (geometrical) context-aware embeddings for each unit are obtained through the corresponding GCN learning processers. At each time step, a context gated attention module takes as inputs the embeddings of the visual semantic units and hierarchically align the current word with these units by first deciding which type of visual semantic unit (object, attribute, or interaction) the current word is about, and then finding the most correlated visual semantic units under this type. Extensive experiments are conducted on the challenging MS-COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches.
Image Manipulation with Perceptual Discriminators
Sep 05, 2018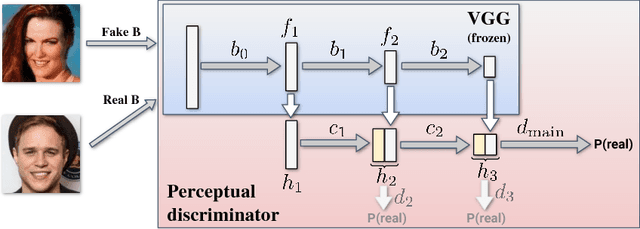


Systems that perform image manipulation using deep convolutional networks have achieved remarkable realism. Perceptual losses and losses based on adversarial discriminators are the two main classes of learning objectives behind these advances. In this work, we show how these two ideas can be combined in a principled and non-additive manner for unaligned image translation tasks. This is accomplished through a special architecture of the discriminator network inside generative adversarial learning framework. The new architecture, that we call a perceptual discriminator, embeds the convolutional parts of a pre-trained deep classification network inside the discriminator network. The resulting architecture can be trained on unaligned image datasets while benefiting from the robustness and efficiency of perceptual losses. We demonstrate the merits of the new architecture in a series of qualitative and quantitative comparisons with baseline approaches and state-of-the-art frameworks for unaligned image translation.
Semantic Segmentation of Periocular Near-Infra-Red Eye Images Under Alcohol Effects
Jun 30, 2021
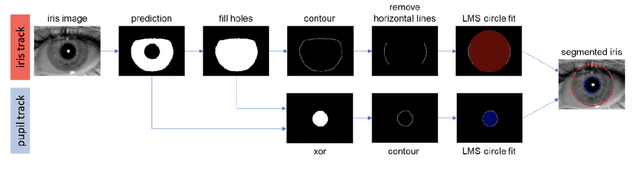
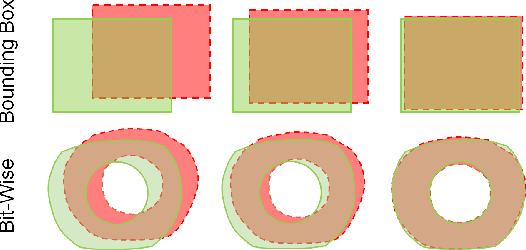
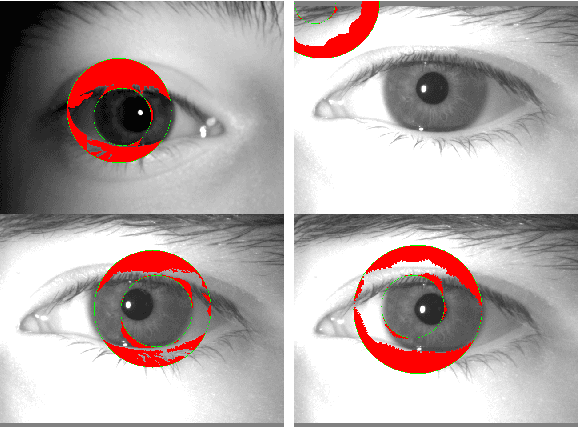
This paper proposes a new framework to detect, segment, and estimate the localization of the eyes from a periocular Near-Infra-Red iris image under alcohol consumption. The purpose of the system is to measure the fitness for duty. Fitness systems allow us to determine whether a person is physically or psychologically able to perform their tasks. Our framework is based on an object detector trained from scratch to detect both eyes from a single image. Then, two efficient networks were used for semantic segmentation; a Criss-Cross attention network and DenseNet10, with only 122,514 and 210,732 parameters, respectively. These networks can find the pupil, iris, and sclera. In the end, the binary output eye mask is used for pupil and iris diameter estimation with high precision. Five state-of-the-art algorithms were used for this purpose. A mixed proposal reached the best results. A second contribution is establishing an alcohol behavior curve to detect the alcohol presence utilizing a stream of images captured from an iris instance. Also, a manually labeled database with more than 20k images was created. Our best method obtains a mean Intersection-over-Union of 94.54% with DenseNet10 with only 210,732 parameters and an error of only 1-pixel on average.
Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning
Oct 11, 2019
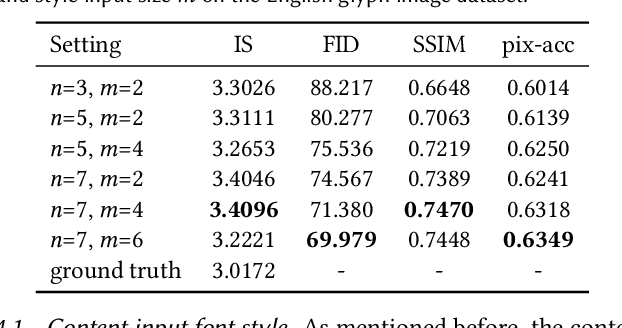
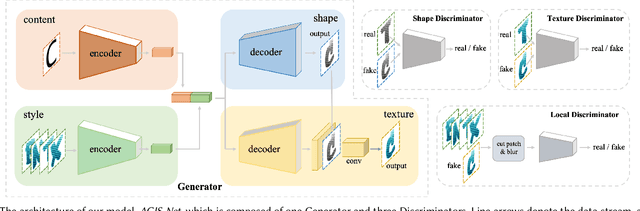
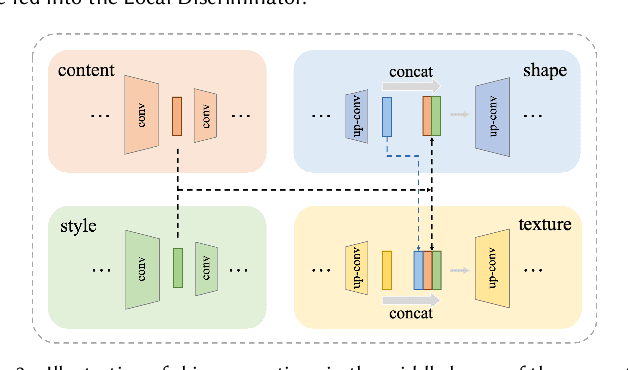
Automatic generation of artistic glyph images is a challenging task that attracts many research interests. Previous methods either are specifically designed for shape synthesis or focus on texture transfer. In this paper, we propose a novel model, AGIS-Net, to transfer both shape and texture styles in one-stage with only a few stylized samples. To achieve this goal, we first disentangle the representations for content and style by using two encoders, ensuring the multi-content and multi-style generation. Then we utilize two collaboratively working decoders to generate the glyph shape image and its texture image simultaneously. In addition, we introduce a local texture refinement loss to further improve the quality of the synthesized textures. In this manner, our one-stage model is much more efficient and effective than other multi-stage stacked methods. We also propose a large-scale dataset with Chinese glyph images in various shape and texture styles, rendered from 35 professional-designed artistic fonts with 7,326 characters and 2,460 synthetic artistic fonts with 639 characters, to validate the effectiveness and extendability of our method. Extensive experiments on both English and Chinese artistic glyph image datasets demonstrate the superiority of our model in generating high-quality stylized glyph images against other state-of-the-art methods.
* 12 pages, Accepted by SIGGRAPH Asia 2019, coda and datasets: https://hologerry.github.io/AGIS-Net/
Implicit Behavioral Cloning
Sep 01, 2021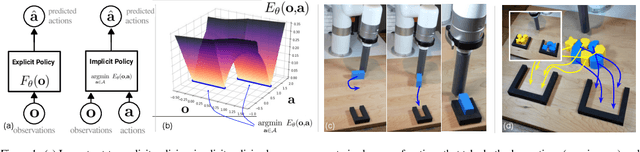

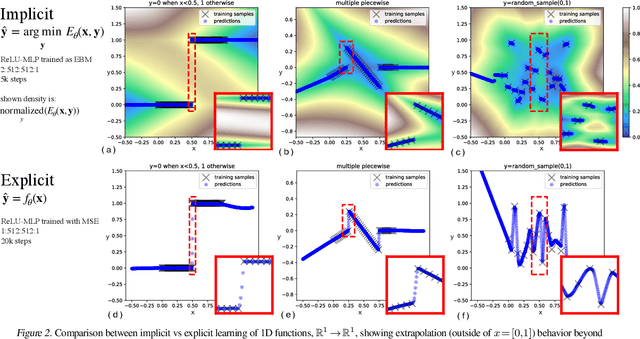
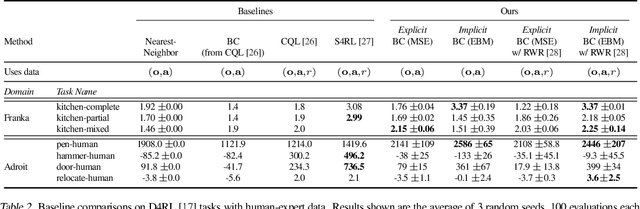
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
e-UDA: Efficient Unsupervised Domain Adaptation for Cross-Site Medical Image Segmentation
Jan 25, 2020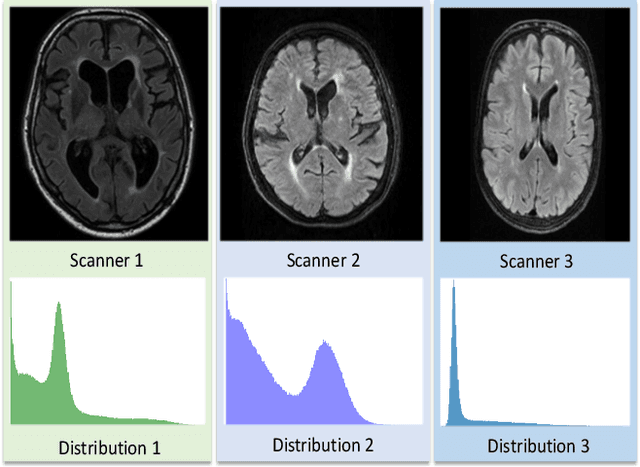

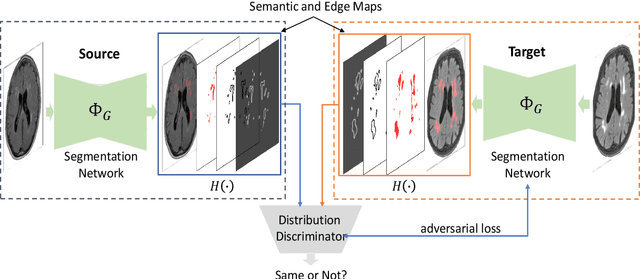
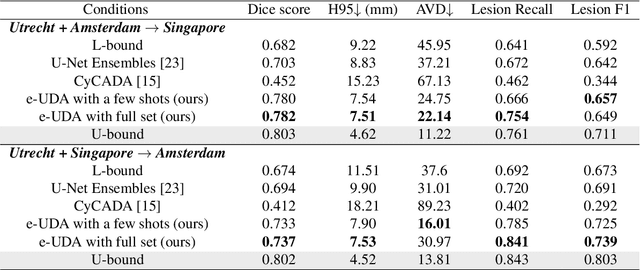
Domain adaptation in healthcare data is a potentially critical component in making computer-aided diagnostic systems applicable cross multiple sites and imaging scanners. In this paper, we propose an efficient unsupervised domain adaptation framework for robust image segmentation cross multiple similar domains. We enforce our algorithm to not only adapt to the new domains via an adversarial optimization, rejecting unlikely segmentation patterns, but also to maintain its performance on the source training data, by incorporating both semantic and boundary information into the data distributions. Further, as we do not have labels for the transfer domain, we propose a new quality score for the adaptation process, and strategies to retrain the diagnostic algorithm in a stable fashion. Using multi-centric data from a public benchmark for brain lesion segmentation, we demonstrate that recalibrating on just few unlabeled image sets from the target domain improves segmentation accuracies drastically, with performances almost similar to those from algorithms trained on fresh and fully annotated data from the test domain.
Differentiable Surface Rendering via Non-Differentiable Sampling
Aug 10, 2021

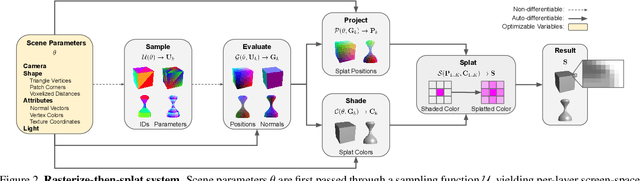
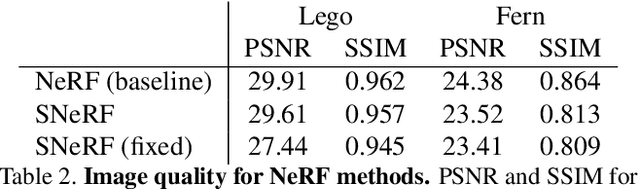
We present a method for differentiable rendering of 3D surfaces that supports both explicit and implicit representations, provides derivatives at occlusion boundaries, and is fast and simple to implement. The method first samples the surface using non-differentiable rasterization, then applies differentiable, depth-aware point splatting to produce the final image. Our approach requires no differentiable meshing or rasterization steps, making it efficient for large 3D models and applicable to isosurfaces extracted from implicit surface definitions. We demonstrate the effectiveness of our method for implicit-, mesh-, and parametric-surface-based inverse rendering and neural-network training applications. In particular, we show for the first time efficient, differentiable rendering of an isosurface extracted from a neural radiance field (NeRF), and demonstrate surface-based, rather than volume-based, rendering of a NeRF.
Stereo Computation for a Single Mixture Image
Aug 27, 2018

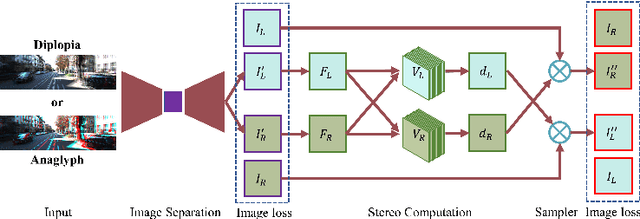
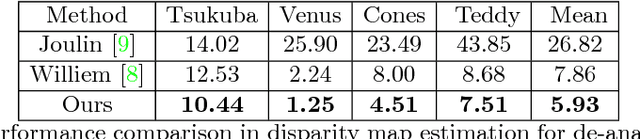
This paper proposes an original problem of \emph{stereo computation from a single mixture image}-- a challenging problem that had not been researched before. The goal is to separate (\ie, unmix) a single mixture image into two constitute image layers, such that the two layers form a left-right stereo image pair, from which a valid disparity map can be recovered. This is a severely illposed problem, from one input image one effectively aims to recover three (\ie, left image, right image and a disparity map). In this work we give a novel deep-learning based solution, by jointly solving the two subtasks of image layer separation as well as stereo matching. Training our deep net is a simple task, as it does not need to have disparity maps. Extensive experiments demonstrate the efficacy of our method.