 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PathMMU: A Massive Multimodal Expert-Level Benchmark for Understanding and Reasoning in Pathology
Feb 05, 2024
The emergence of large multimodal models has unlocked remarkable potential in AI, particularly in pathology. However, the lack of specialized, high-quality benchmark impeded their development and precise evaluation. To address this, we introduce PathMMU, the largest and highest-quality expert-validated pathology benchmark for LMMs. It comprises 33,573 multimodal multi-choice questions and 21,599 images from various sources, and an explanation for the correct answer accompanies each question. The construction of PathMMU capitalizes on the robust capabilities of GPT-4V, utilizing approximately 30,000 gathered image-caption pairs to generate Q\&As. Significantly, to maximize PathMMU's authority, we invite six pathologists to scrutinize each question under strict standards in PathMMU's validation and test sets, while simultaneously setting an expert-level performance benchmark for PathMMU. We conduct extensive evaluations, including zero-shot assessments of 14 open-sourced and three closed-sourced LMMs and their robustness to image corruption. We also fine-tune representative LMMs to assess their adaptability to PathMMU. The empirical findings indicate that advanced LMMs struggle with the challenging PathMMU benchmark, with the top-performing LMM, GPT-4V, achieving only a 51.7\% zero-shot performance, significantly lower than the 71.4\% demonstrated by human pathologists. After fine-tuning, even open-sourced LMMs can surpass GPT-4V with a performance of over 60\%, but still fall short of the expertise shown by pathologists. We hope that the PathMMU will offer valuable insights and foster the development of more specialized, next-generation LLMs for pathology.
Generalizing GradCAM for Embedding Networks
Feb 05, 2024
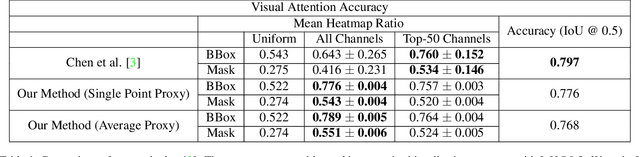
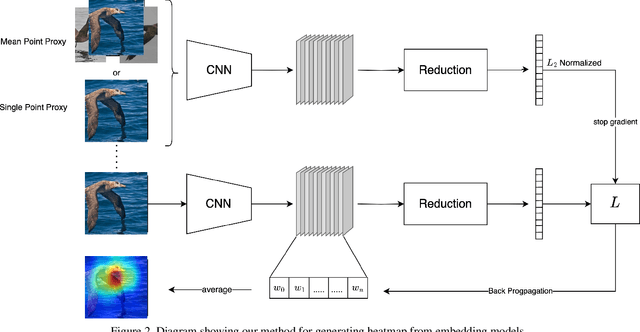
Visualizing CNN is an important part in building trust and explaining model's prediction. Methods like CAM and GradCAM have been really successful in localizing area of the image responsible for the output but are only limited to classification models. In this paper, we present a new method EmbeddingCAM, which generalizes the Grad-CAM for embedding networks. We show that for classification networks, EmbeddingCAM reduces to GradCAM. We show the effectiveness of our method on CUB-200-2011 dataset and also present quantitative and qualitative analysis on the dataset.
Polyp-DAM: Polyp segmentation via depth anything model
Feb 03, 2024Recently, large models (Segment Anything model) came on the scene to provide a new baseline for polyp segmentation tasks. This demonstrates that large models with a sufficient image level prior can achieve promising performance on a given task. In this paper, we unfold a new perspective on polyp segmentation modeling by leveraging the Depth Anything Model (DAM) to provide depth prior to polyp segmentation models. Specifically, the input polyp image is first passed through a frozen DAM to generate a depth map. The depth map and the input polyp images are then concatenated and fed into a convolutional neural network with multiscale to generate segmented images. Extensive experimental results demonstrate the effectiveness of our method, and in addition, we observe that our method still performs well on images of polyps with noise. The URL of our code is \url{https://github.com/zzr-idam/Polyp-DAM}.
A Bandit Approach with Evolutionary Operators for Model Selection
Feb 07, 2024This paper formulates model selection as an infinite-armed bandit problem. The models are arms, and picking an arm corresponds to a partial training of the model (resource allocation). The reward is the accuracy of the selected model after its partial training. In this best arm identification problem, regret is the gap between the expected accuracy of the optimal model and that of the model finally chosen. We first consider a straightforward generalization of UCB-E to the stochastic infinite-armed bandit problem and show that, under basic assumptions, the expected regret order is $T^{-\alpha}$ for some $\alpha \in (0,1/5)$ and $T$ the number of resources to allocate. From this vanilla algorithm, we introduce the algorithm Mutant-UCB that incorporates operators from evolutionary algorithms. Tests carried out on three open source image classification data sets attest to the relevance of this novel combining approach, which outperforms the state-of-the-art for a fixed budget.
Universal Neural Functionals
Feb 07, 2024A challenging problem in many modern machine learning tasks is to process weight-space features, i.e., to transform or extract information from the weights and gradients of a neural network. Recent works have developed promising weight-space models that are equivariant to the permutation symmetries of simple feedforward networks. However, they are not applicable to general architectures, since the permutation symmetries of a weight space can be complicated by recurrence or residual connections. This work proposes an algorithm that automatically constructs permutation equivariant models, which we refer to as universal neural functionals (UNFs), for any weight space. Among other applications, we demonstrate how UNFs can be substituted into existing learned optimizer designs, and find promising improvements over prior methods when optimizing small image classifiers and language models. Our results suggest that learned optimizers can benefit from considering the (symmetry) structure of the weight space they optimize. We open-source our library for constructing UNFs at https://github.com/AllanYangZhou/universal_neural_functional.
Code as Reward: Empowering Reinforcement Learning with VLMs
Feb 07, 2024Pre-trained Vision-Language Models (VLMs) are able to understand visual concepts, describe and decompose complex tasks into sub-tasks, and provide feedback on task completion. In this paper, we aim to leverage these capabilities to support the training of reinforcement learning (RL) agents. In principle, VLMs are well suited for this purpose, as they can naturally analyze image-based observations and provide feedback (reward) on learning progress. However, inference in VLMs is computationally expensive, so querying them frequently to compute rewards would significantly slowdown the training of an RL agent. To address this challenge, we propose a framework named Code as Reward (VLM-CaR). VLM-CaR produces dense reward functions from VLMs through code generation, thereby significantly reducing the computational burden of querying the VLM directly. We show that the dense rewards generated through our approach are very accurate across a diverse set of discrete and continuous environments, and can be more effective in training RL policies than the original sparse environment rewards.
STAR: Shape-focused Texture Agnostic Representations for Improved Object Detection and 6D Pose Estimation
Feb 07, 2024Recent advances in machine learning have greatly benefited object detection and 6D pose estimation for robotic grasping. However, textureless and metallic objects still pose a significant challenge due to fewer visual cues and the texture bias of CNNs. To address this issue, we propose a texture-agnostic approach that focuses on learning from CAD models and emphasizes object shape features. To achieve a focus on learning shape features, the textures are randomized during the rendering of the training data. By treating the texture as noise, the need for real-world object instances or their final appearance during training data generation is eliminated. The TLESS and ITODD datasets, specifically created for industrial settings in robotics and featuring textureless and metallic objects, were used for evaluation. Texture agnosticity also increases the robustness against image perturbations such as imaging noise, motion blur, and brightness changes, which are common in robotics applications. Code and datasets are publicly available at github.com/hoenigpeter/randomized_texturing.
Exploring Compressed Image Representation as a Perceptual Proxy: A Study
Jan 14, 2024We propose an end-to-end learned image compression codec wherein the analysis transform is jointly trained with an object classification task. This study affirms that the compressed latent representation can predict human perceptual distance judgments with an accuracy comparable to a custom-tailored DNN-based quality metric. We further investigate various neural encoders and demonstrate the effectiveness of employing the analysis transform as a perceptual loss network for image tasks beyond quality judgments. Our experiments show that the off-the-shelf neural encoder proves proficient in perceptual modeling without needing an additional VGG network. We expect this research to serve as a valuable reference developing of a semantic-aware and coding-efficient neural encoder.
SAMF: Small-Area-Aware Multi-focus Image Fusion for Object Detection
Jan 16, 2024Existing multi-focus image fusion (MFIF) methods often fail to preserve the uncertain transition region and detect small focus areas within large defocused regions accurately. To address this issue, this study proposes a new small-area-aware MFIF algorithm for enhancing object detection capability. First, we enhance the pixel attributes within the small focus and boundary regions, which are subsequently combined with visual saliency detection to obtain the pre-fusion results used to discriminate the distribution of focused pixels. To accurately ensure pixel focus, we consider the source image as a combination of focused, defocused, and uncertain regions and propose a three-region segmentation strategy. Finally, we design an effective pixel selection rule to generate segmentation decision maps and obtain the final fusion results. Experiments demonstrated that the proposed method can accurately detect small and smooth focus areas while improving object detection performance, outperforming existing methods in both subjective and objective evaluations. The source code is available at https://github.com/ixilai/SAMF.
More than the Sum of Its Parts: Ensembling Backbone Networks for Few-Shot Segmentation
Feb 09, 2024Semantic segmentation is a key prerequisite to robust image understanding for applications in \acrlong{ai} and Robotics. \acrlong{fss}, in particular, concerns the extension and optimization of traditional segmentation methods in challenging conditions where limited training examples are available. A predominant approach in \acrlong{fss} is to rely on a single backbone for visual feature extraction. Choosing which backbone to leverage is a deciding factor contributing to the overall performance. In this work, we interrogate on whether fusing features from different backbones can improve the ability of \acrlong{fss} models to capture richer visual features. To tackle this question, we propose and compare two ensembling techniques-Independent Voting and Feature Fusion. Among the available \acrlong{fss} methods, we implement the proposed ensembling techniques on PANet. The module dedicated to predicting segmentation masks from the backbone embeddings in PANet avoids trainable parameters, creating a controlled `in vitro' setting for isolating the impact of different ensembling strategies. Leveraging the complementary strengths of different backbones, our approach outperforms the original single-backbone PANet across standard benchmarks even in challenging one-shot learning scenarios. Specifically, it achieved a performance improvement of +7.37\% on PASCAL-5\textsuperscript{i} and of +10.68\% on COCO-20\textsuperscript{i} in the top-performing scenario where three backbones are combined. These results, together with the qualitative inspection of the predicted subject masks, suggest that relying on multiple backbones in PANet leads to a more comprehensive feature representation, thus expediting the successful application of \acrlong{fss} methods in challenging, data-scarce environments.