 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cycle In Cycle Generative Adversarial Networks for Keypoint-Guided Image Generation
Sep 14, 2019

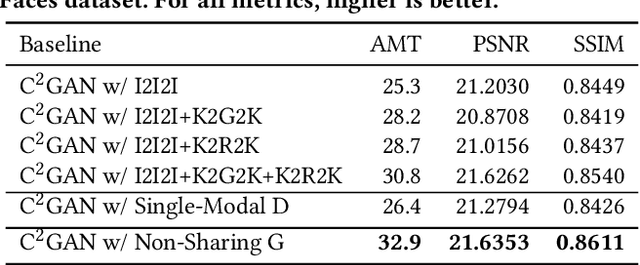
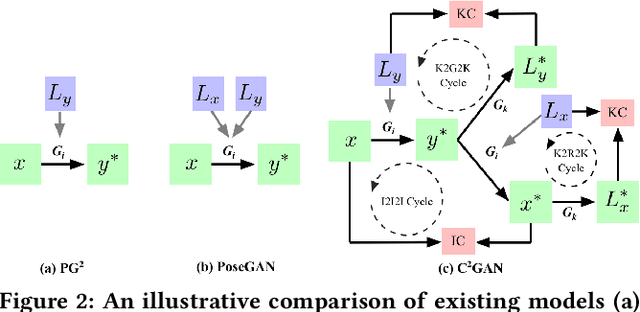
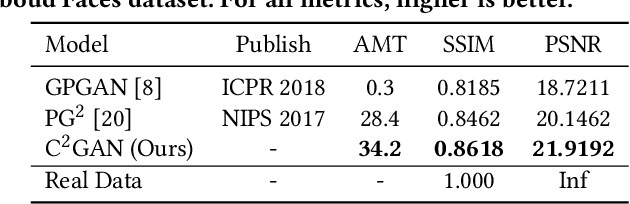
In this work, we propose a novel Cycle In Cycle Generative Adversarial Network (C$^2$GAN) for the task of keypoint-guided image generation. The proposed C$^2$GAN is a cross-modal framework exploring a joint exploitation of the keypoint and the image data in an interactive manner. C$^2$GAN contains two different types of generators, i.e., keypoint-oriented generator and image-oriented generator. Both of them are mutually connected in an end-to-end learnable fashion and explicitly form three cycled sub-networks, i.e., one image generation cycle and two keypoint generation cycles. Each cycle not only aims at reconstructing the input domain, and also produces useful output involving in the generation of another cycle. By so doing, the cycles constrain each other implicitly, which provides complementary information from the two different modalities and brings extra supervision across cycles, thus facilitating more robust optimization of the whole network. Extensive experimental results on two publicly available datasets, i.e., Radboud Faces and Market-1501, demonstrate that our approach is effective to generate more photo-realistic images compared with state-of-the-art models.
* 9 pages, 8 figures, accepted to ACM MM 2019
On the effectiveness of convolutional autoencoders on image-based personalized recommender systems
Mar 13, 2020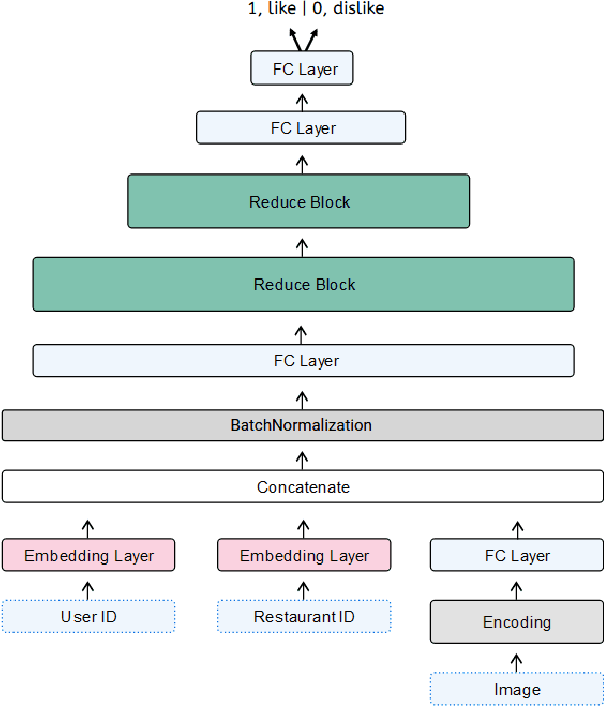
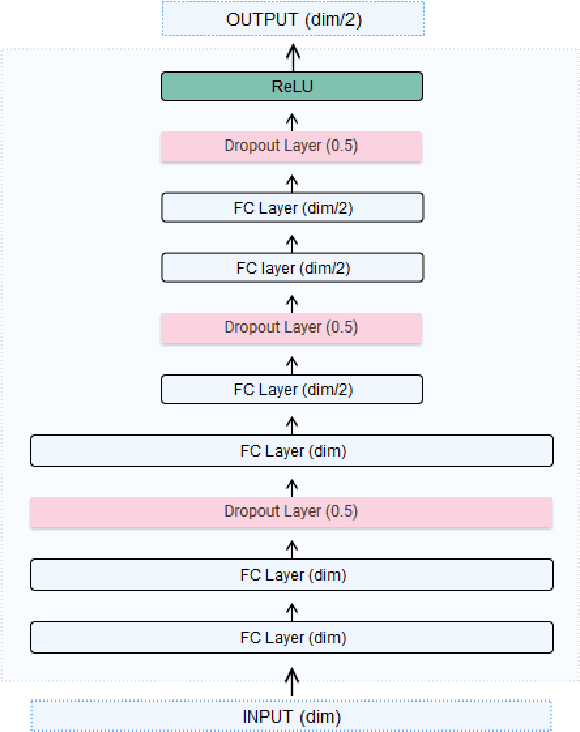
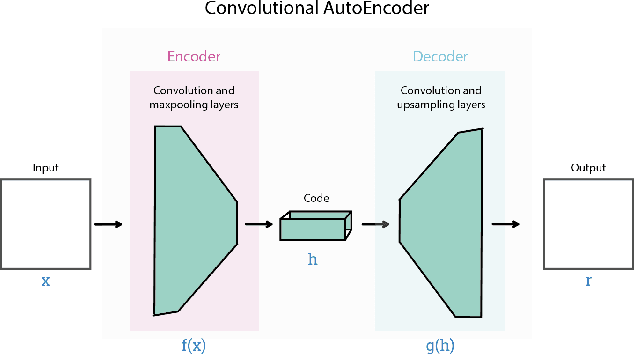
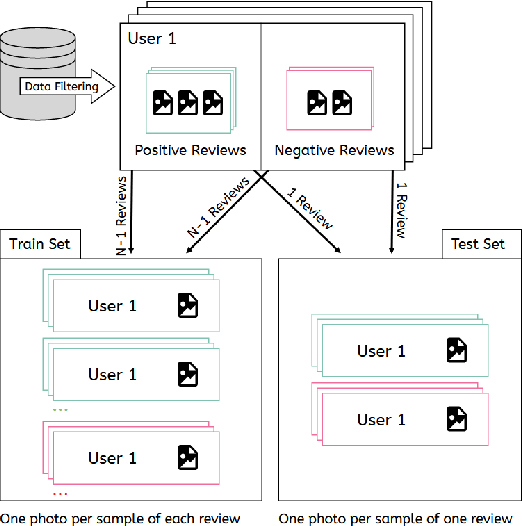
Recommender systems (RS) are increasingly present in our daily lives, especially since the advent of Big Data, which allows for storing all kinds of information about users' preferences. Personalized RS are successfully applied in platforms such as Netflix, Amazon or YouTube. However, they are missing in gastronomic platforms such as TripAdvisor, where moreover we can find millions of images tagged with users' tastes. This paper explores the potential of using those images as sources of information for modeling users' tastes and proposes an image-based classification system to obtain personalized recommendations, using a convolutional autoencoder as feature extractor. The proposed architecture will be applied to TripAdvisor data, using users' reviews that can be defined as a triad composed by a user, a restaurant, and an image of it taken by the user. Since the dataset is highly unbalanced, the use of data augmentation on the minority class is also considered in the experimentation. Results on data from three cities of different sizes (Santiago de Compostela, Barcelona and New York) demonstrate the effectiveness of using a convolutional autoencoder as feature extractor, instead of the standard deep features computed with convolutional neural networks.
Difficulty-aware Image Super Resolution via Deep Adaptive Dual-Network
Apr 11, 2019
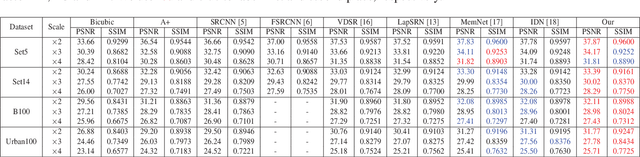
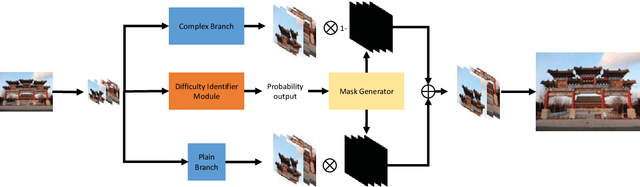
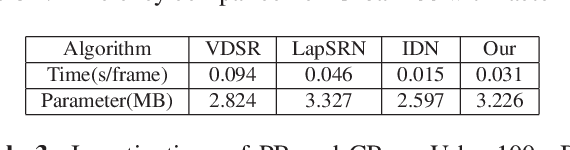
Recently, deep learning based single image super-resolution(SR) approaches have achieved great development. The state-of-the-art SR methods usually adopt a feed-forward pipeline to establish a non-linear mapping between low-res(LR) and high-res(HR) images. However, due to treating all image regions equally without considering the difficulty diversity, these approaches meet an upper bound for optimization. To address this issue, we propose a novel SR approach that discriminately processes each image region within an image by its difficulty. Specifically, we propose a dual-way SR network that one way is trained to focus on easy image regions and another is trained to handle hard image regions. To identify whether a region is easy or hard, we propose a novel image difficulty recognition network based on PSNR prior. Our SR approach that uses the region mask to adaptively enforce the dual-way SR network yields superior results. Extensive experiments on several standard benchmarks (e.g., Set5, Set14, BSD100, and Urban100) show that our approach achieves state-of-the-art performance.
VSGM -- Enhance robot task understanding ability through visual semantic graph
May 19, 2021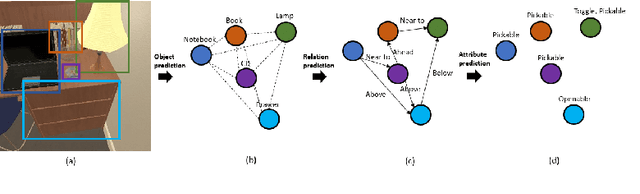
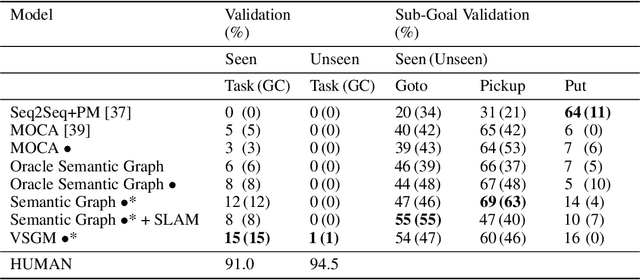

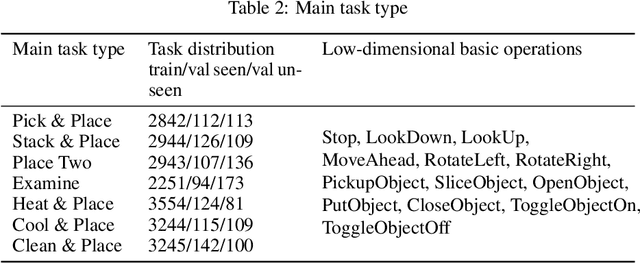
In recent years, developing AI for robotics has raised much attention. The interaction of vision and language of robots is particularly difficult. We consider that giving robots an understanding of visual semantics and language semantics will improve inference ability. In this paper, we propose a novel method-VSGM (Visual Semantic Graph Memory), which uses the semantic graph to obtain better visual image features, improve the robot's visual understanding ability. By providing prior knowledge of the robot and detecting the objects in the image, it predicts the correlation between the attributes of the object and the objects and converts them into a graph-based representation; and mapping the object in the image to be a top-down egocentric map. Finally, the important object features of the current task are extracted by Graph Neural Networks. The method proposed in this paper is verified in the ALFRED (Action Learning From Realistic Environments and Directives) dataset. In this dataset, the robot needs to perform daily indoor household tasks following the required language instructions. After the model is added to the VSGM, the task success rate can be improved by 6~10%.
Q-Net: A Quantitative Susceptibility Mapping-based Deep Neural Network for Differential Diagnosis of Brain Iron Deposition in Hemochromatosis
Oct 01, 2021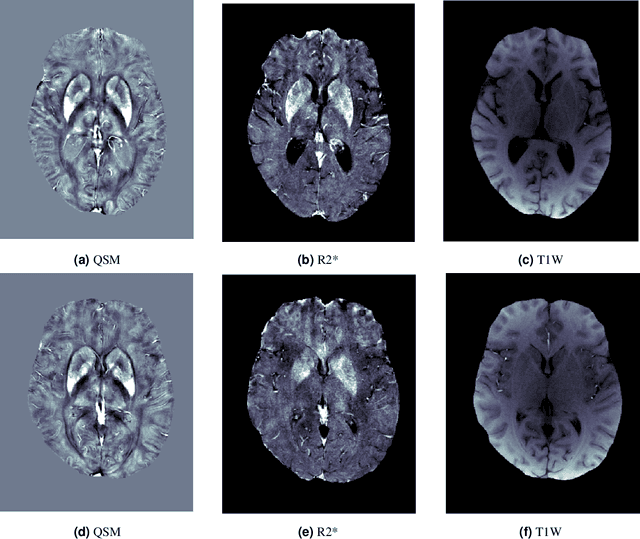

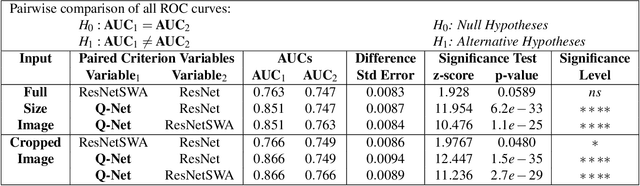
Brain iron deposition, in particular deep gray matter nuclei, increases with advancing age. Hereditary Hemochromatosis (HH) is the most common inherited disorder of systemic iron excess in Europeans and recent studies claimed high brain iron accumulation in patient with Hemochromatosis. In this study, we focus on Artificial Intelligence (AI)-based differential diagnosis of brain iron deposition in HH via Quantitative Susceptibility Mapping (QSM), which is an established Magnetic Resonance Imaging (MRI) technique to study the distribution of iron in the brain. Our main objective is investigating potentials of AI-driven frameworks to accurately and efficiently differentiate individuals with Hemochromatosis from those of the healthy control group. More specifically, we developed the Q-Net framework, which is a data-driven model that processes information on iron deposition in the brain obtained from multi-echo gradient echo imaging data and anatomical information on T1-Weighted images of the brain. We illustrate that the Q-Net framework can assist in differentiating between someone with HH and Healthy control (HC) of the same age, something that is not possible by just visualizing images. The study is performed based on a unique dataset that was collected from 52 subjects with HH and 47 HC. The Q-Net provides a differential diagnosis accuracy of 83.16% and 80.37% in the scan-level and image-level classification, respectively.
Confidence Calibration and Predictive Uncertainty Estimation for Deep Medical Image Segmentation
Nov 29, 2019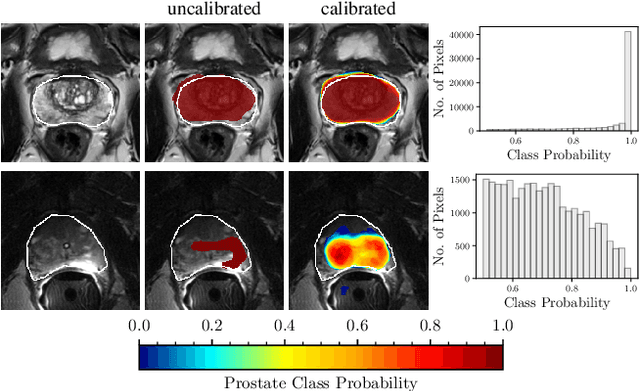
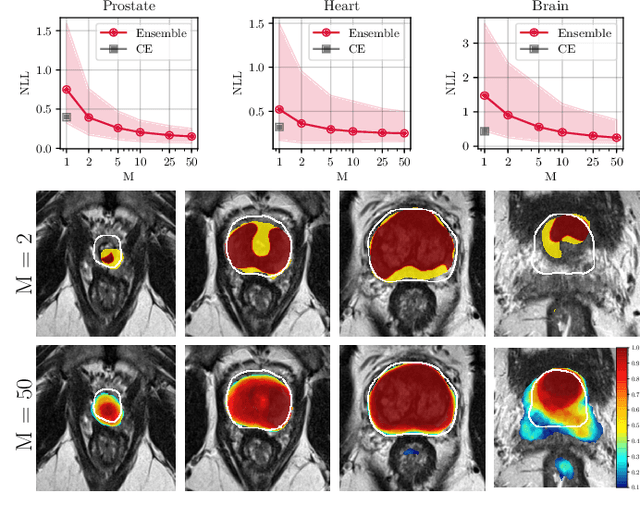
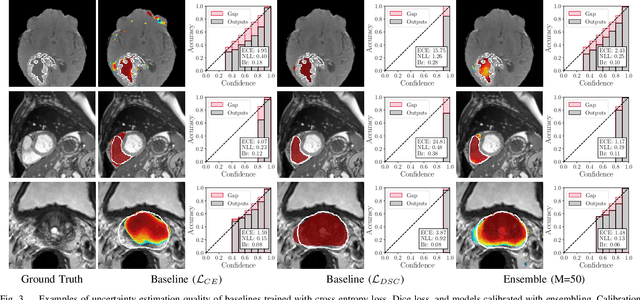
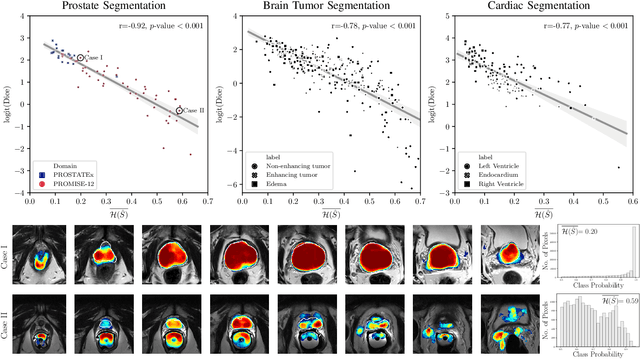
Fully convolutional neural networks (FCNs), and in particular U-Nets, have achieved state-of-the-art results in semantic segmentation for numerous medical imaging applications. Moreover, batch normalization and Dice loss have been used successfully to stabilize and accelerate training. However, these networks are poorly calibrated i.e. they tend to produce overconfident predictions both in correct and erroneous classifications, making them unreliable and hard to interpret. In this paper, we study predictive uncertainty estimation in FCNs for medical image segmentation. We make the following contributions: 1) We systematically compare cross entropy loss with Dice loss in terms of segmentation quality and uncertainty estimation of FCNs; 2) We propose model ensembling for confidence calibration of the FCNs trained with batch normalization and Dice loss; 3) We assess the ability of calibrated FCNs to predict segmentation quality of structures and detect out-of-distribution test examples. We conduct extensive experiments across three medical image segmentation applications of the brain, the heart, and the prostate to evaluate our contributions. The results of this study offer considerable insight into the predictive uncertainty estimation and out-of-distribution detection in medical image segmentation and provide practical recipes for confidence calibration. Moreover, we consistently demonstrate that model ensembling improves confidence calibration.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
Jun 17, 2021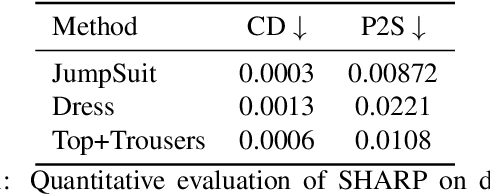
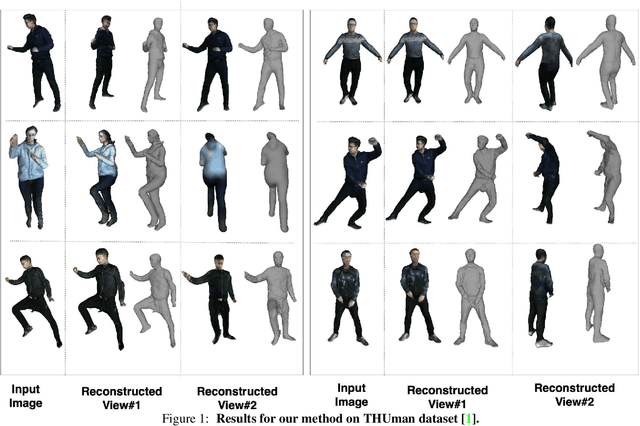
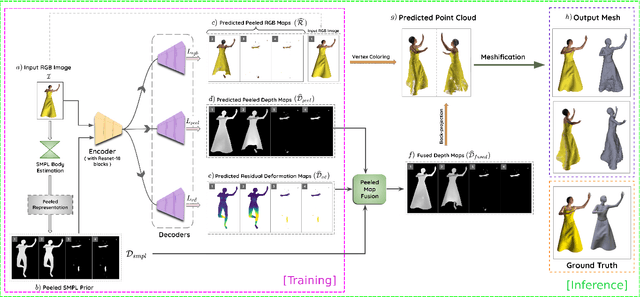
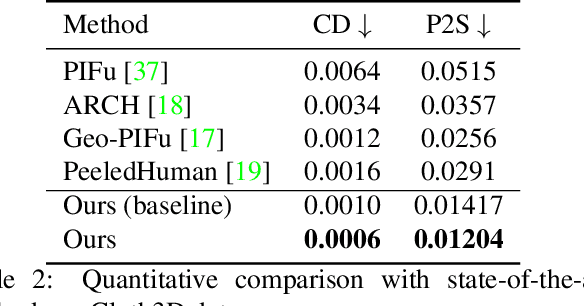
3D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
High Resolution Face Editing with Masked GAN Latent Code Optimization
Mar 20, 2021

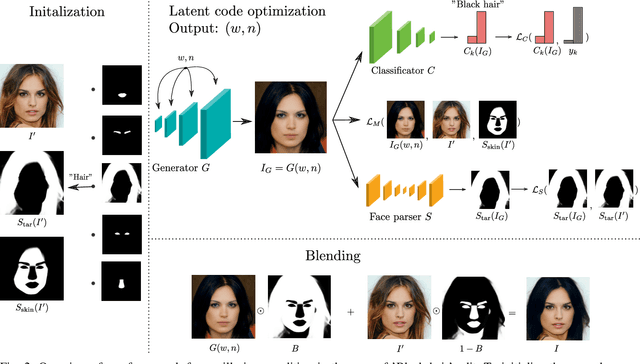

Face editing is a popular research topic in the computer vision community that aims to edit a specific characteristic of a face image. Recent proposed methods are based on either training a conditional encoder-decoder Generative Adversarial Network (GAN) in an end-to-end fashion or on defining an operation in the latent space of a pre-trained vanilla GAN generator model. However, these methods exhibit a certain degree of visual degradation and lack disentanglement properties in the edited images. Moreover, they usually operate on lower image resolution. In this paper, we propose a GAN embedding optimization procedure with spatial and semantic constraints. We optimize a latent code of a GAN, pre-trained on face dataset, to embed a fixed region of the image, while imposing constraints on the inpainted regions with face parsing and attribute classification networks. By latent code optimization, we constrain the result to follow an image probability distribution, as defined by the GAN model. We use such framework to produce high image quality face edits. Due to the spatial constraints introduced, the edited images exhibit higher degree of disentanglement between the desired facial attributes and the rest of the image than other methods. The approach is validated in experiments on three datasets and in comparison with four state-of-the-art approaches. The results demonstrate that the proposed approach is able to edit face images with respect to several facial attributes with unprecedented image quality, while disentangling the undesired factors of variation. Code will be made available.
Decomposing Convolutional Neural Networks into Reusable and Replaceable Modules
Oct 11, 2021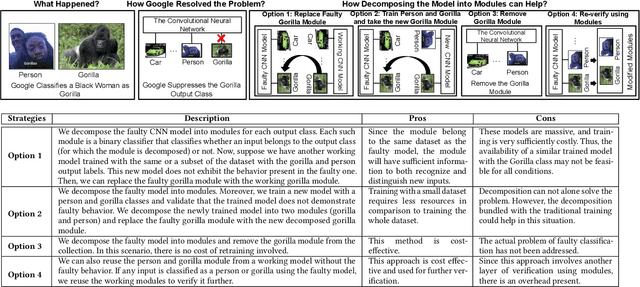
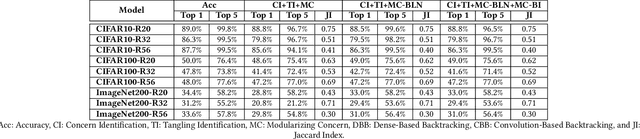
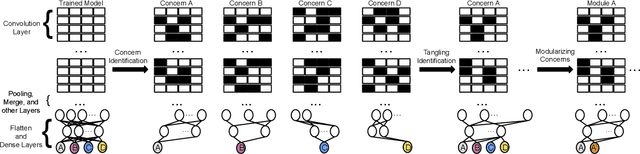
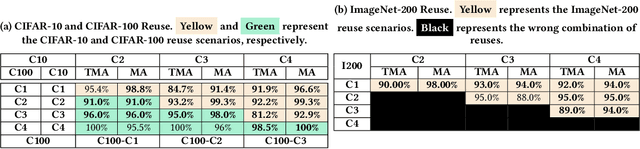
Training from scratch is the most common way to build a Convolutional Neural Network (CNN) based model. What if we can build new CNN models by reusing parts from previously build CNN models? What if we can improve a CNN model by replacing (possibly faulty) parts with other parts? In both cases, instead of training, can we identify the part responsible for each output class (module) in the model(s) and reuse or replace only the desired output classes to build a model? Prior work has proposed decomposing dense-based networks into modules (one for each output class) to enable reusability and replaceability in various scenarios. However, this work is limited to the dense layers and based on the one-to-one relationship between the nodes in consecutive layers. Due to the shared architecture in the CNN model, prior work cannot be adapted directly. In this paper, we propose to decompose a CNN model used for image classification problems into modules for each output class. These modules can further be reused or replaced to build a new model. We have evaluated our approach with CIFAR-10, CIFAR-100, and ImageNet tiny datasets with three variations of ResNet models and found that enabling decomposition comes with a small cost (2.38% and 0.81% for top-1 and top-5 accuracy, respectively). Also, building a model by reusing or replacing modules can be done with a 2.3% and 0.5% average loss of accuracy. Furthermore, reusing and replacing these modules reduces CO2e emission by ~37 times compared to training the model from scratch.
Interpreting and improving deep-learning models with reality checks
Aug 16, 2021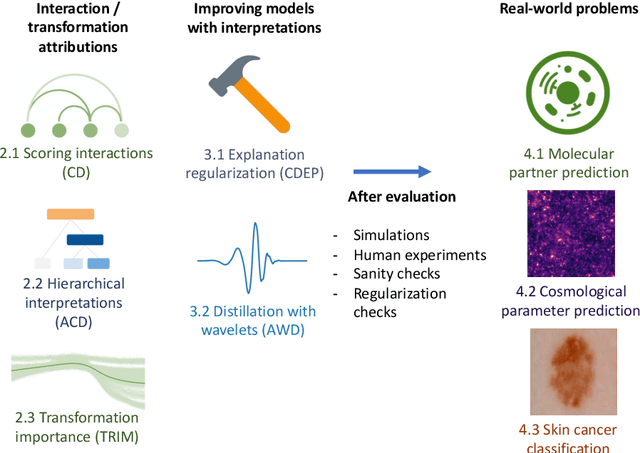

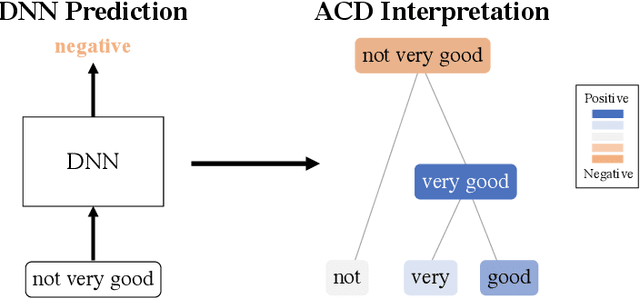
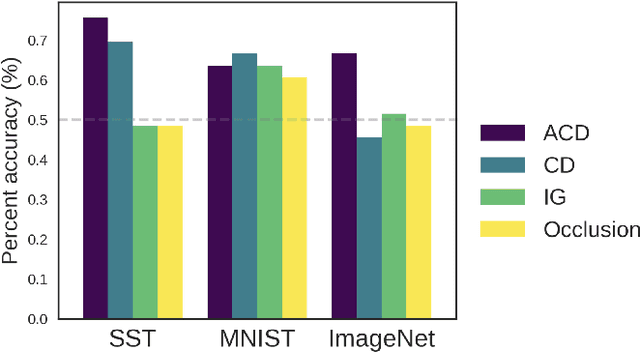
Recent deep-learning models have achieved impressive predictive performance by learning complex functions of many variables, often at the cost of interpretability. This chapter covers recent work aiming to interpret models by attributing importance to features and feature groups for a single prediction. Importantly, the proposed attributions assign importance to interactions between features, in addition to features in isolation. These attributions are shown to yield insights across real-world domains, including bio-imaging, cosmology image and natural-language processing. We then show how these attributions can be used to directly improve the generalization of a neural network or to distill it into a simple model. Throughout the chapter, we emphasize the use of reality checks to scrutinize the proposed interpretation techniques.