 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Salient Object Ranking with Position-Preserved Attention
Jun 10, 2021

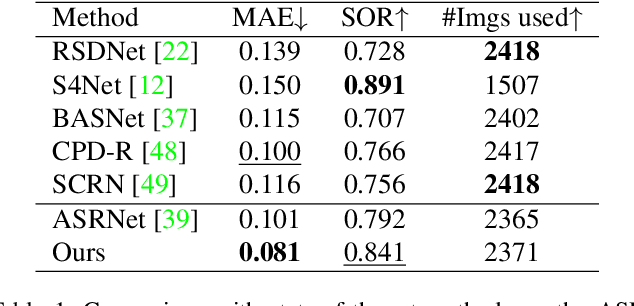
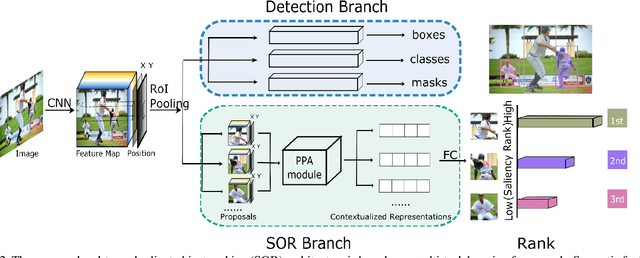
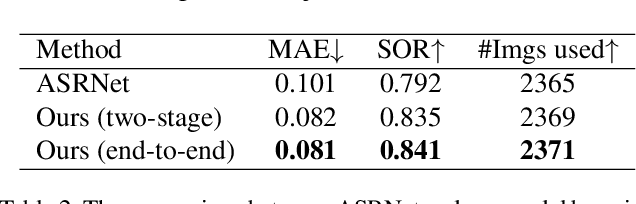
Instance segmentation can detect where the objects are in an image, but hard to understand the relationship between them. We pay attention to a typical relationship, relative saliency. A closely related task, salient object detection, predicts a binary map highlighting a visually salient region while hard to distinguish multiple objects. Directly combining two tasks by post-processing also leads to poor performance. There is a lack of research on relative saliency at present, limiting the practical applications such as content-aware image cropping, video summary, and image labeling. In this paper, we study the Salient Object Ranking (SOR) task, which manages to assign a ranking order of each detected object according to its visual saliency. We propose the first end-to-end framework of the SOR task and solve it in a multi-task learning fashion. The framework handles instance segmentation and salient object ranking simultaneously. In this framework, the SOR branch is independent and flexible to cooperate with different detection methods, so that easy to use as a plugin. We also introduce a Position-Preserved Attention (PPA) module tailored for the SOR branch. It consists of the position embedding stage and feature interaction stage. Considering the importance of position in saliency comparison, we preserve absolute coordinates of objects in ROI pooling operation and then fuse positional information with semantic features in the first stage. In the feature interaction stage, we apply the attention mechanism to obtain proposals' contextualized representations to predict their relative ranking orders. Extensive experiments have been conducted on the ASR dataset. Without bells and whistles, our proposed method outperforms the former state-of-the-art method significantly. The code will be released publicly available.
Gated Multiple Feedback Network for Image Super-Resolution
Jul 10, 2019
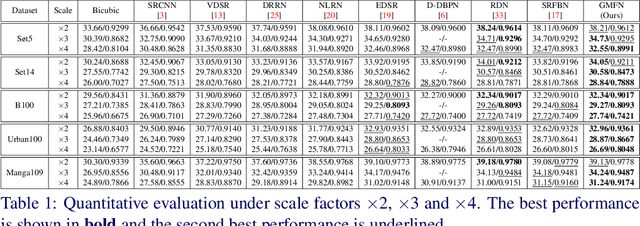
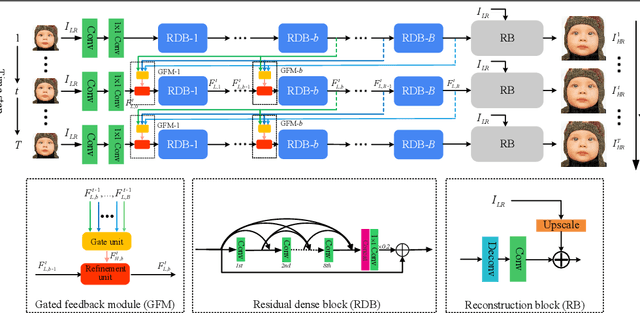
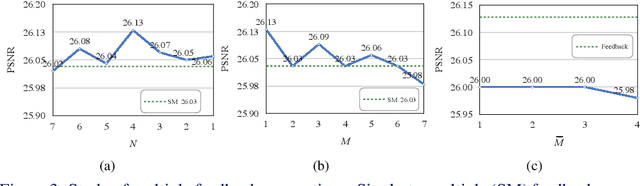
The rapid development of deep learning (DL) has driven single image super-resolution (SR) into a new era. However, in most existing DL based image SR networks, the information flows are solely feedforward, and the high-level features cannot be fully explored. In this paper, we propose the gated multiple feedback network (GMFN) for accurate image SR, in which the representation of low-level features are efficiently enriched by rerouting multiple high-level features. We cascade multiple residual dense blocks (RDBs) and recurrently unfolds them across time. The multiple feedback connections between two adjacent time steps in the proposed GMFN exploits multiple high-level features captured under large receptive fields to refine the low-level features lacking enough contextual information. The elaborately designed gated feedback module (GFM) efficiently selects and further enhances useful information from multiple rerouted high-level features, and then refine the low-level features with the enhanced high-level information. Extensive experiments demonstrate the superiority of our proposed GMFN against state-of-the-art SR methods in terms of both quantitative metrics and visual quality. Code is available at https://github.com/liqilei/GMFN.
Deblurring Processor for Motion-Blurred Faces Based on Generative Adversarial Networks
Mar 03, 2021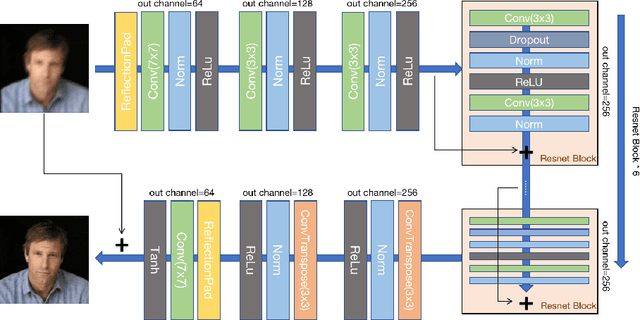
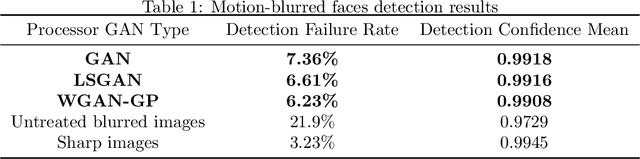
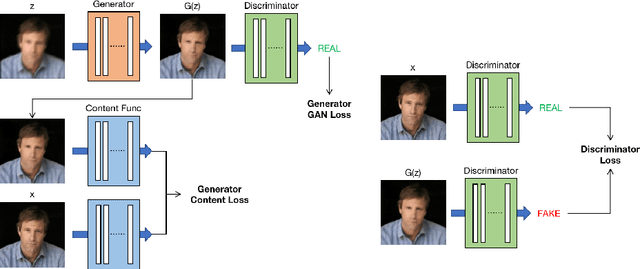

Low-quality face image restoration is a popular research direction in today's computer vision field. It can be used as a pre-work for tasks such as face detection and face recognition. At present, there is a lot of work to solve the problem of low-quality faces under various environmental conditions. This paper mainly focuses on the restoration of motion-blurred faces. In increasingly abundant mobile scenes, the fast recovery of motion-blurred faces can bring highly effective speed improvements in tasks such as face matching. In order to achieve this goal, a deblurring method for motion-blurred facial image signals based on generative adversarial networks(GANs) is proposed. It uses an end-to-end method to train a sharp image generator, i.e., a processor for motion-blurred facial images. This paper introduce the processing progress of motion-blurred images, the development and changes of GANs and some basic concepts. After that, it give the details of network structure and training optimization design of the image processor. Then we conducted a motion blur image generation experiment on some general facial data set, and used the pairs of blurred and sharp face image data to perform the training and testing experiments of the processor GAN, and gave some visual displays. Finally, MTCNN is used to detect the faces of the image generated by the deblurring processor, and compare it with the result of the blurred image. From the results, the processing effect of the deblurring processor on the motion-blurred picture has a significant improvement both in terms of intuition and evaluation indicators of face detection.
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
Feb 19, 2019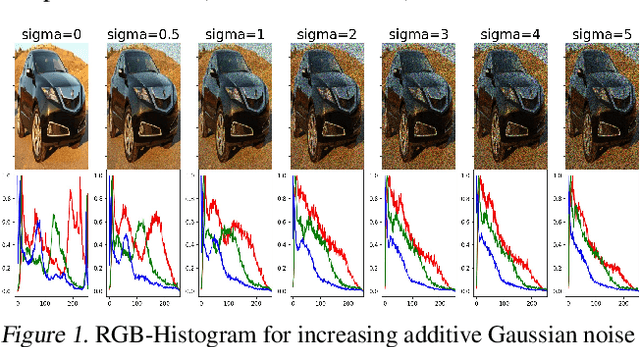
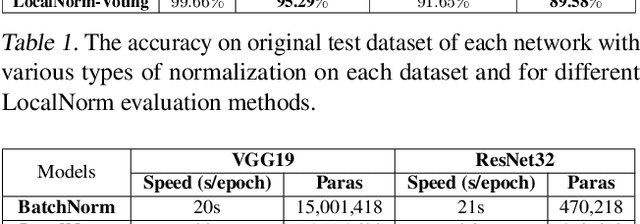

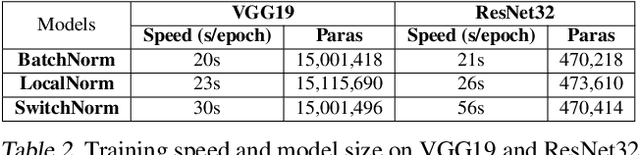
While modern convolutional neural networks achieve outstanding accuracy on many image classification tasks, they are, compared to humans, much more sensitive to image degradation. Here, we describe a variant of Batch Normalization, LocalNorm, that regularizes the normalization layer in the spirit of Dropout while dynamically adapting to the local image intensity and contrast at test-time. We show that the resulting deep neural networks are much more resistant to noise-induced image degradation, improving accuracy by up to three times, while achieving the same or slightly better accuracy on non-degraded classical benchmarks. In computational terms, LocalNorm adds negligible training cost and little or no cost at inference time, and can be applied to already-trained networks in a straightforward manner.
Lighting the Darkness in the Deep Learning Era
Apr 21, 2021
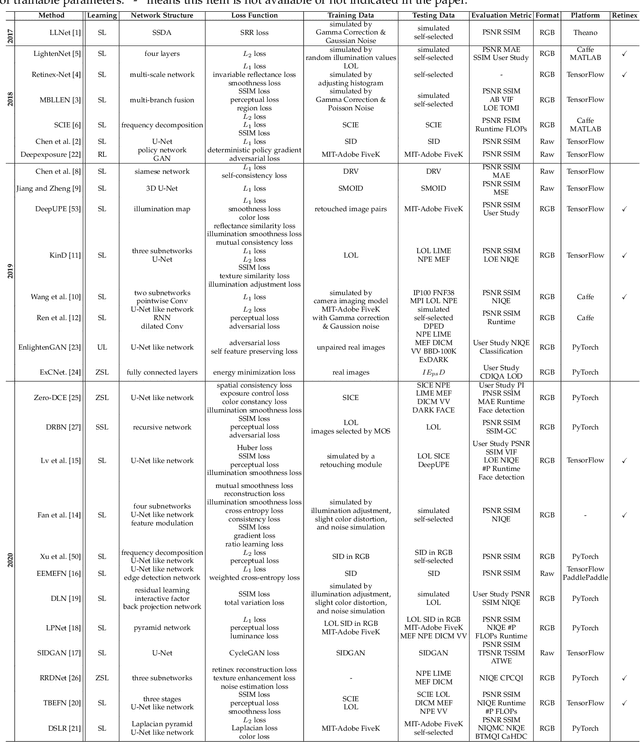

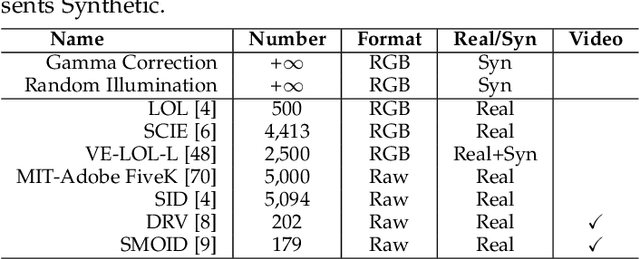
Low-light image enhancement (LLIE) aims at improving the perception or interpretability of an image captured in an environment with poor illumination. Recent advances in this area are dominated by deep learning-based solutions, where many learning strategies, network structures, loss functions, training data, etc. have been employed. In this paper, we provide a comprehensive survey to cover various aspects ranging from algorithm taxonomy to unsolved open issues. To examine the generalization of existing methods, we propose a large-scale low-light image and video dataset, in which the images and videos are taken by different mobile phones' cameras under diverse illumination conditions. Besides, for the first time, we provide a unified online platform that covers many popular LLIE methods, of which the results can be produced through a user-friendly web interface. In addition to qualitative and quantitative evaluation of existing methods on publicly available and our proposed datasets, we also validate their performance in face detection in the dark. This survey together with the proposed dataset and online platform could serve as a reference source for future study and promote the development of this research field. The proposed platform and the collected methods, datasets, and evaluation metrics are publicly available and will be regularly updated at https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open. We will release our low-light image and video dataset.
An End-to-end Entangled Segmentation and Classification Convolutional Neural Network for Periodontitis Stage Grading from Periapical Radiographic Images
Sep 27, 2021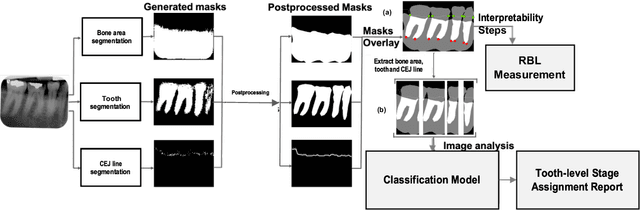
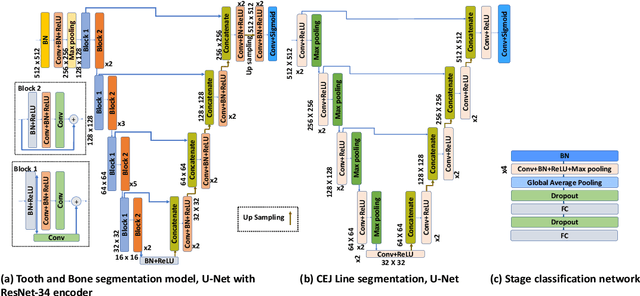
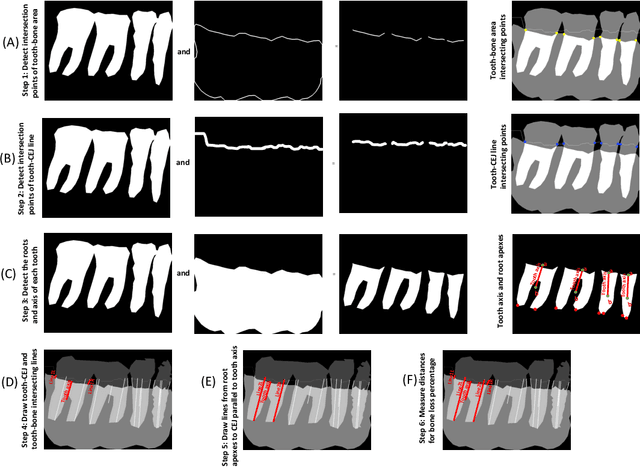
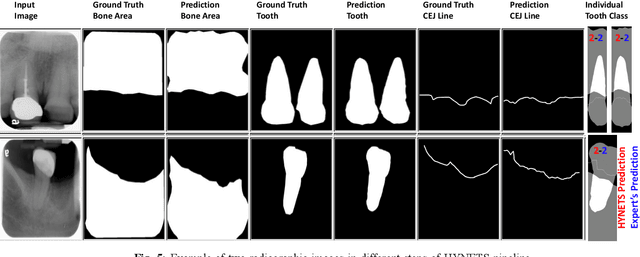
Periodontitis is a biofilm-related chronic inflammatory disease characterized by gingivitis and bone loss in the teeth area. Approximately 61 million adults over 30 suffer from periodontitis (42.2%), with 7.8% having severe periodontitis in the United States. The measurement of radiographic bone loss (RBL) is necessary to make a correct periodontal diagnosis, especially if the comprehensive and longitudinal periodontal mapping is unavailable. However, doctors can interpret X-rays differently depending on their experience and knowledge. Computerized diagnosis support for doctors sheds light on making the diagnosis with high accuracy and consistency and drawing up an appropriate treatment plan for preventing or controlling periodontitis. We developed an end-to-end deep learning network HYNETS (Hybrid NETwork for pEriodoNTiTiS STagES from radiograpH) by integrating segmentation and classification tasks for grading periodontitis from periapical radiographic images. HYNETS leverages a multi-task learning strategy by combining a set of segmentation networks and a classification network to provide an end-to-end interpretable solution and highly accurate and consistent results. HYNETS achieved the average dice coefficient of 0.96 and 0.94 for the bone area and tooth segmentation and the average AUC of 0.97 for periodontitis stage assignment. Additionally, conventional image processing techniques provide RBL measurements and build transparency and trust in the model's prediction. HYNETS will potentially transform clinical diagnosis from a manual time-consuming, and error-prone task to an efficient and automated periodontitis stage assignment based on periapical radiographic images.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
May 29, 2021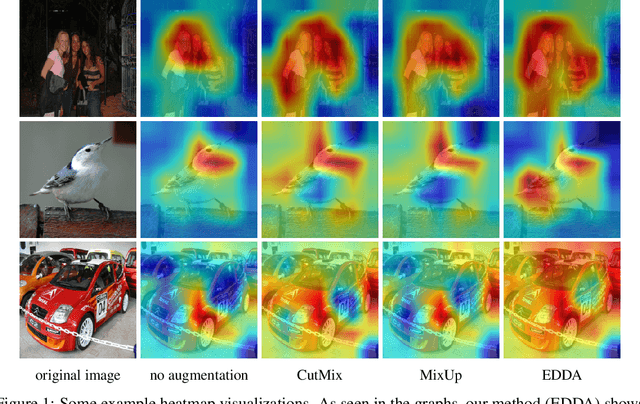
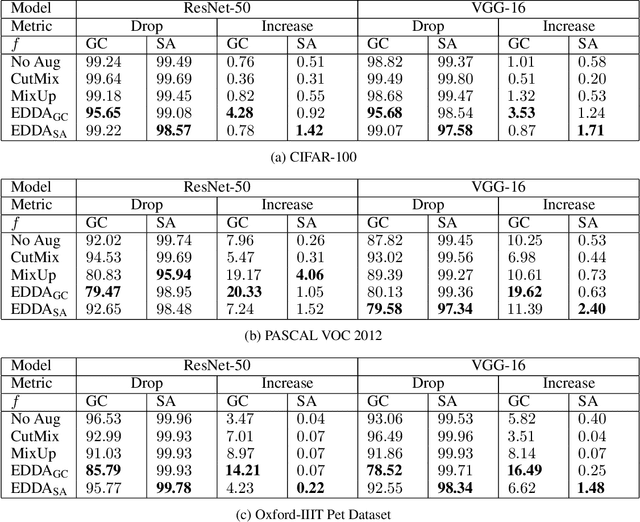
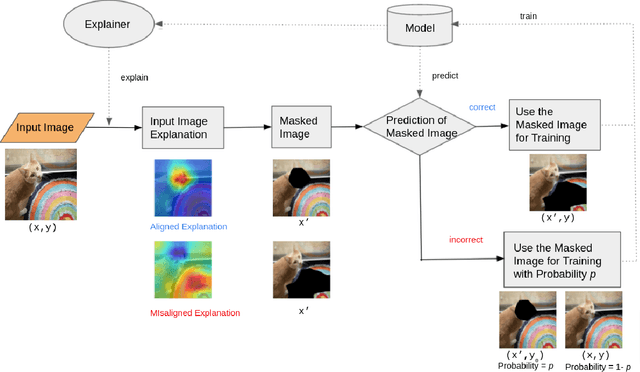
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Multi-Dimension Modulation for Image Restoration with Dynamic Controllable Residual Learning
Dec 11, 2019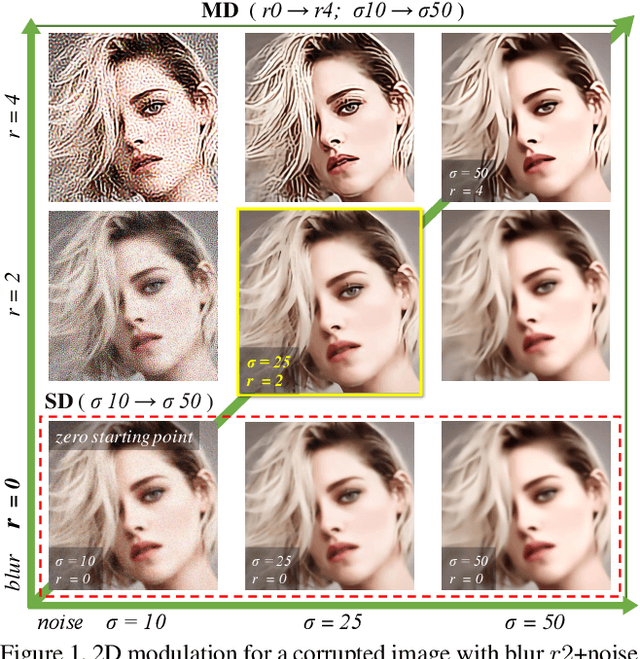
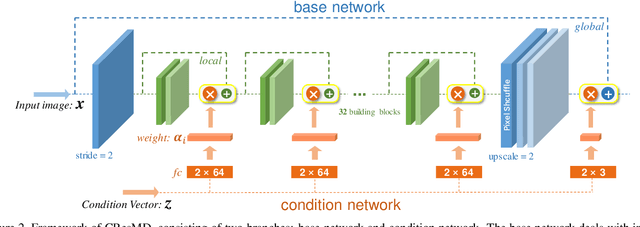
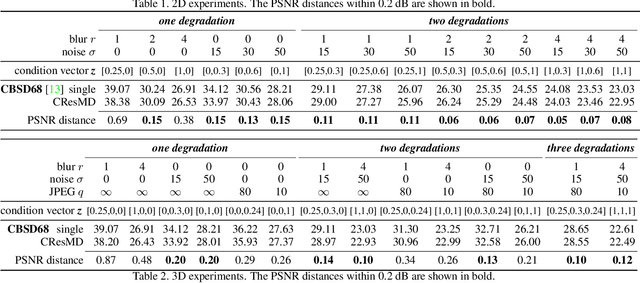

Based on the great success of deterministic learning, to interactively control the output effects has attracted increasingly attention in the image restoration field. The goal is to generate continuous restored images by adjusting a controlling coefficient. Existing methods are restricted in realizing smooth transition between two objectives, while the real input images may contain different kinds of degradations. To make a step forward, we present a new problem called multi-dimension (MD) modulation, which aims at modulating output effects across multiple degradation types and levels. Compared with the previous single-dimension (SD) modulation, the MD task has three distinct properties, namely joint modulation, zero starting point and unbalanced learning. These obstacles motivate us to propose the first MD modulation framework -- CResMD with newly introduced controllable residual connections. Specifically, we add a controlling variable on the conventional residual connection to allow a weighted summation of input and residual. The exact values of these weights are generated by a condition network. We further propose a new data sampling strategy based on beta distribution to balance different degradation types and levels. With the corrupted image and the degradation information as inputs, the network could output the corresponding restored image. By tweaking the condition vector, users are free to control the output effects in MD space at test time. Extensive experiments demonstrate that the proposed CResMD could achieve excellent performance on both SD and MD modulation tasks.
Contrastive Learning for View Classification of Echocardiograms
Aug 06, 2021



Analysis of cardiac ultrasound images is commonly performed in routine clinical practice for quantification of cardiac function. Its increasing automation frequently employs deep learning networks that are trained to predict disease or detect image features. However, such models are extremely data-hungry and training requires labelling of many thousands of images by experienced clinicians. Here we propose the use of contrastive learning to mitigate the labelling bottleneck. We train view classification models for imbalanced cardiac ultrasound datasets and show improved performance for views/classes for which minimal labelled data is available. Compared to a naive baseline model, we achieve an improvement in F1 score of up to 26% in those views while maintaining state-of-the-art performance for the views with sufficiently many labelled training observations.
Detecting Layout Templates in Complex Multiregion Files
Sep 15, 2021
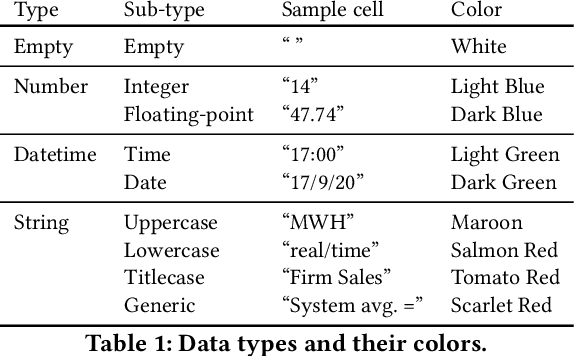
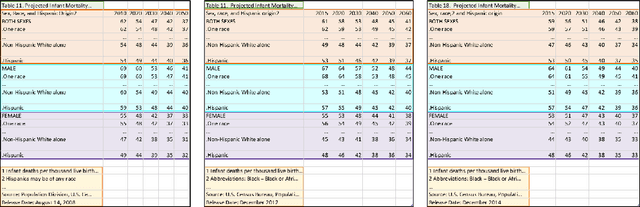

Spreadsheets are among the most commonly used file formats for data management, distribution, and analysis. Their widespread employment makes it easy to gather large collections of data, but their flexible canvas-based structure makes automated analysis difficult without heavy preparation. One of the common problems that practitioners face is the presence of multiple, independent regions in a single spreadsheet, possibly separated by repeated empty cells. We define such files as "multiregion" files. In collections of various spreadsheets, we can observe that some share the same layout. We present the Mondrian approach to automatically identify layout templates across multiple files and systematically extract the corresponding regions. Our approach is composed of three phases: first, each file is rendered as an image and inspected for elements that could form regions; then, using a clustering algorithm, the identified elements are grouped to form regions; finally, every file layout is represented as a graph and compared with others to find layout templates. We compare our method to state-of-the-art table recognition algorithms on two corpora of real-world enterprise spreadsheets. Our approach shows the best performances in detecting reliable region boundaries within each file and can correctly identify recurring layouts across files.