 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Sequential Feature Learning in Clinical Image Classification of Infectious Keratitis
Jun 04, 2020
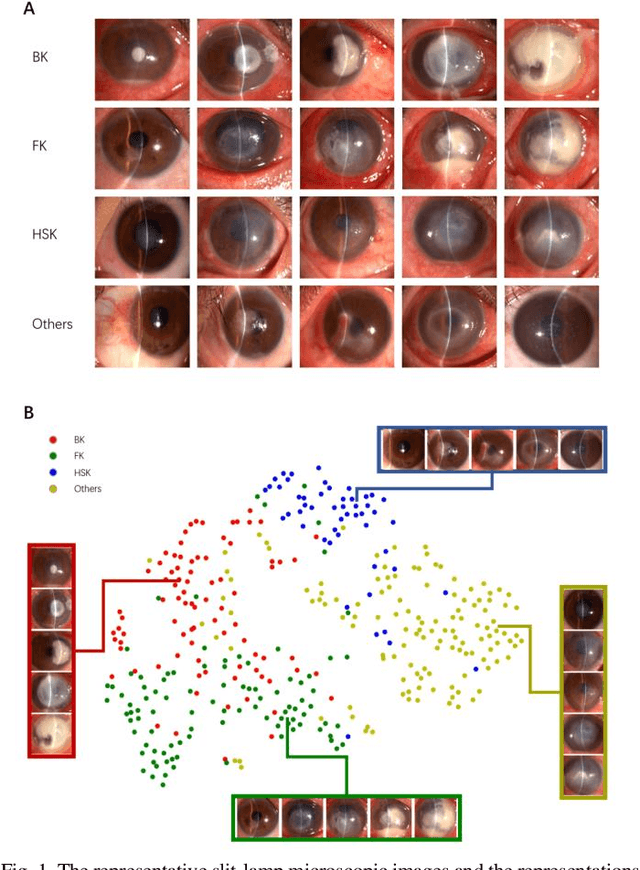
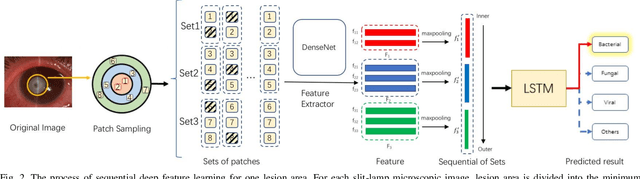
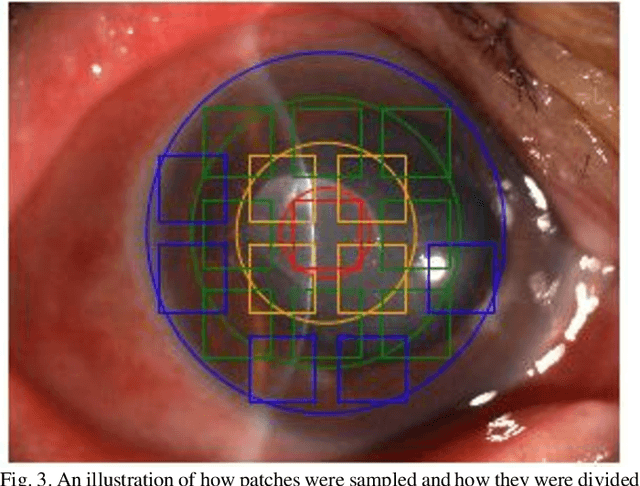
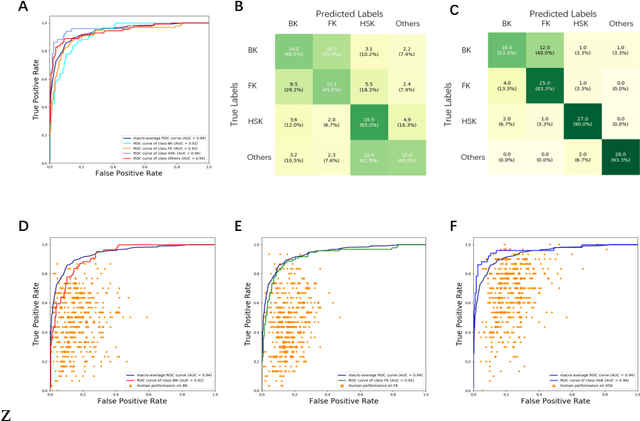
Infectious keratitis is the most common entities of corneal diseases, in which pathogen grows in the cornea leading to inflammation and destruction of the corneal tissues. Infectious keratitis is a medical emergency, for which a rapid and accurate diagnosis is needed for speedy initiation of prompt and precise treatment to halt the disease progress and to limit the extent of corneal damage; otherwise it may develop sight-threatening and even eye-globe-threatening condition. In this paper, we propose a sequential-level deep learning model to effectively discriminate the distinction and subtlety of infectious corneal disease via the classification of clinical images. In this approach, we devise an appropriate mechanism to preserve the spatial structures of clinical images and disentangle the informative features for clinical image classification of infectious keratitis. In competition with 421 ophthalmologists, the performance of the proposed sequential-level deep model achieved 80.00% diagnostic accuracy, far better than the 49.27% diagnostic accuracy achieved by ophthalmologists over 120 test images.
Geometric Image Synthesis
Sep 12, 2018
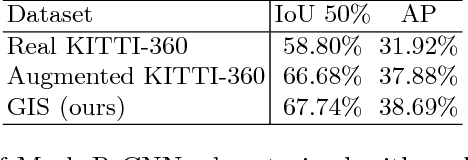
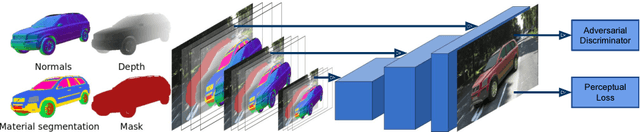

The task of generating natural images from 3D scenes has been a long standing goal in computer graphics. On the other hand, recent developments in deep neural networks allow for trainable models that can produce natural-looking images with little or no knowledge about the scene structure. While the generated images often consist of realistic looking local patterns, the overall structure of the generated images is often inconsistent. In this work we propose a trainable, geometry-aware image generation method that leverages various types of scene information, including geometry and segmentation, to create realistic looking natural images that match the desired scene structure. Our geometrically-consistent image synthesis method is a deep neural network, called Geometry to Image Synthesis (GIS) framework, which retains the advantages of a trainable method, e.g., differentiability and adaptiveness, but, at the same time, makes a step towards the generalizability, control and quality output of modern graphics rendering engines. We utilize the GIS framework to insert vehicles in outdoor driving scenes, as well as to generate novel views of objects from the Linemod dataset. We qualitatively show that our network is able to generalize beyond the training set to novel scene geometries, object shapes and segmentations. Furthermore, we quantitatively show that the GIS framework can be used to synthesize large amounts of training data which proves beneficial for training instance segmentation models.
Automatic Lumbar Spinal CT Image Segmentation with a Dual Densely Connected U-Net
Oct 21, 2019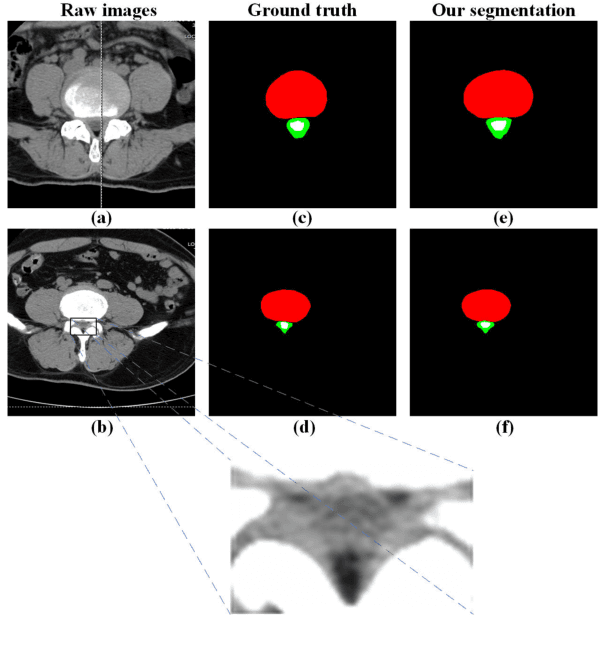
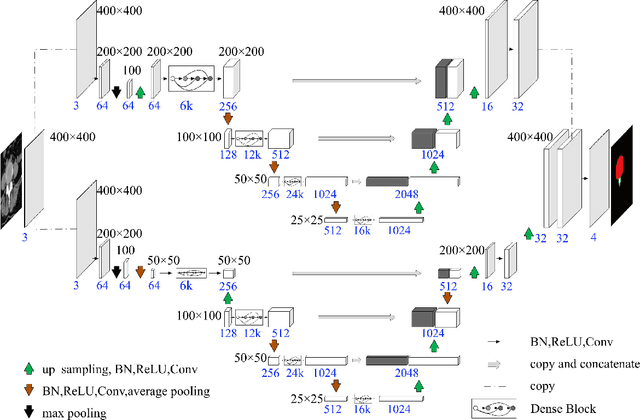
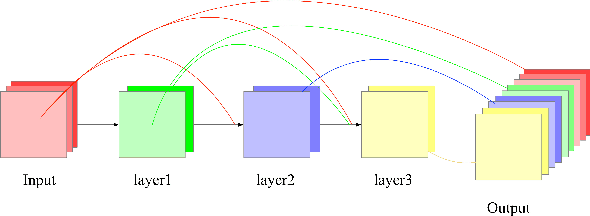
The clinical treatment of degenerative and developmental lumbar spinal stenosis (LSS) is different. Computed tomography (CT) is helpful in distinguishing degenerative and developmental LSS due to its advantage in imaging of osseous and calcified tissues. However, boundaries of the vertebral body, spinal canal and dural sac have low contrast and hard to identify in a CT image, so the diagnosis depends heavily on the knowledge of expert surgeons and radiologists. In this paper, we develop an automatic lumbar spinal CT image segmentation method to assist LSS diagnosis. The main contributions of this paper are the following: 1) a new lumbar spinal CT image dataset is constructed that contains 2393 axial CT images collected from 279 patients, with the ground truth of pixel-level segmentation labels; 2) a dual densely connected U-shaped neural network (DDU-Net) is used to segment the spinal canal, dural sac and vertebral body in an end-to-end manner; 3) DDU-Net is capable of segmenting tissues with large scale-variant, inconspicuous edges (e.g., spinal canal) and extremely small size (e.g., dural sac); and 4) DDU-Net is practical, requiring no image preprocessing such as contrast enhancement, registration and denoising, and the running time reaches 12 FPS. In the experiment, we achieve state-of-the-art performance on the lumbar spinal image segmentation task. We expect that the technique will increase both radiology workflow efficiency and the perceived value of radiology reports for referring clinicians and patients.
Gated Multiple Feedback Network for Image Super-Resolution
Jul 10, 2019
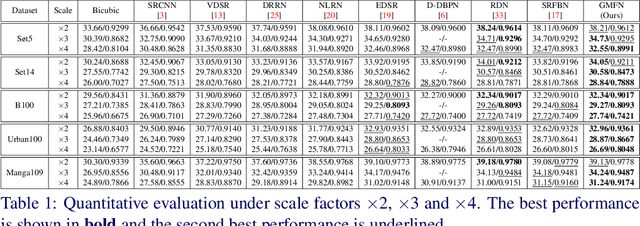
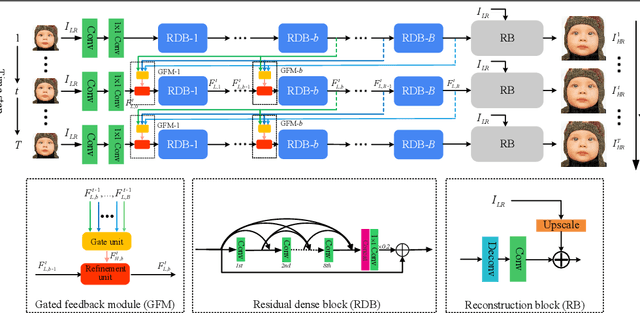
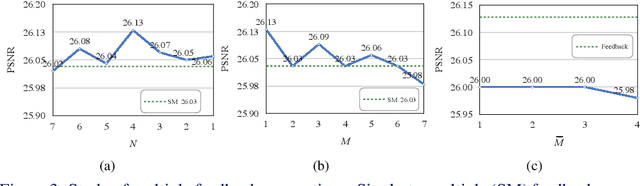
The rapid development of deep learning (DL) has driven single image super-resolution (SR) into a new era. However, in most existing DL based image SR networks, the information flows are solely feedforward, and the high-level features cannot be fully explored. In this paper, we propose the gated multiple feedback network (GMFN) for accurate image SR, in which the representation of low-level features are efficiently enriched by rerouting multiple high-level features. We cascade multiple residual dense blocks (RDBs) and recurrently unfolds them across time. The multiple feedback connections between two adjacent time steps in the proposed GMFN exploits multiple high-level features captured under large receptive fields to refine the low-level features lacking enough contextual information. The elaborately designed gated feedback module (GFM) efficiently selects and further enhances useful information from multiple rerouted high-level features, and then refine the low-level features with the enhanced high-level information. Extensive experiments demonstrate the superiority of our proposed GMFN against state-of-the-art SR methods in terms of both quantitative metrics and visual quality. Code is available at https://github.com/liqilei/GMFN.
CrowdDriven: A New Challenging Dataset for Outdoor Visual Localization
Sep 09, 2021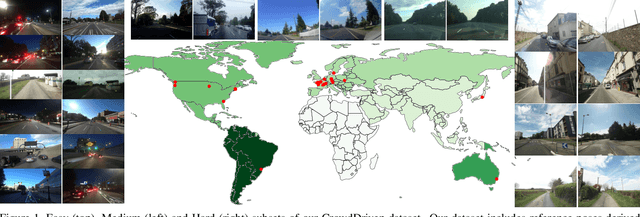


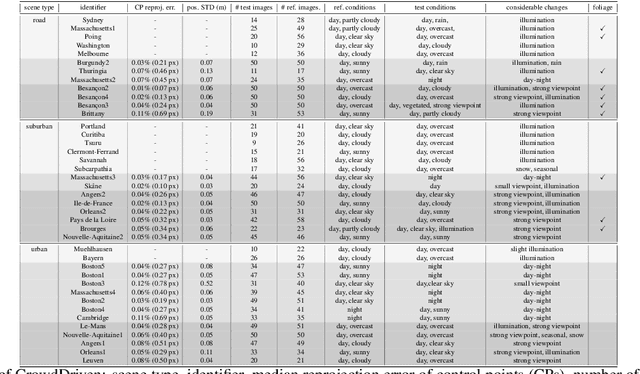
Visual localization is the problem of estimating the position and orientation from which a given image (or a sequence of images) is taken in a known scene. It is an important part of a wide range of computer vision and robotics applications, from self-driving cars to augmented/virtual reality systems. Visual localization techniques should work reliably and robustly under a wide range of conditions, including seasonal, weather, illumination and man-made changes. Recent benchmarking efforts model this by providing images under different conditions, and the community has made rapid progress on these datasets since their inception. However, they are limited to a few geographical regions and often recorded with a single device. We propose a new benchmark for visual localization in outdoor scenes, using crowd-sourced data to cover a wide range of geographical regions and camera devices with a focus on the failure cases of current algorithms. Experiments with state-of-the-art localization approaches show that our dataset is very challenging, with all evaluated methods failing on its hardest parts. As part of the dataset release, we provide the tooling used to generate it, enabling efficient and effective 2D correspondence annotation to obtain reference poses.
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
Feb 19, 2019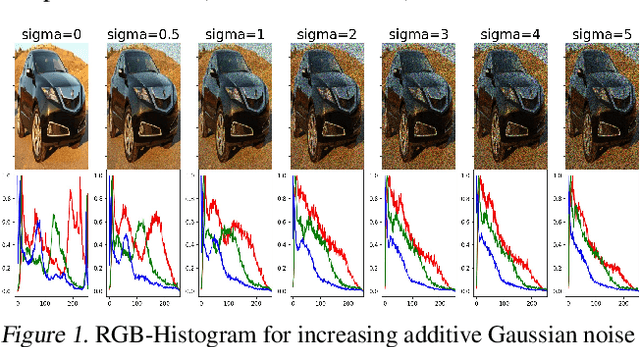
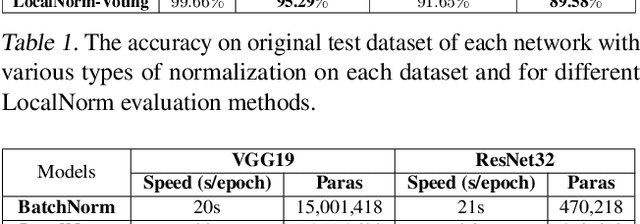

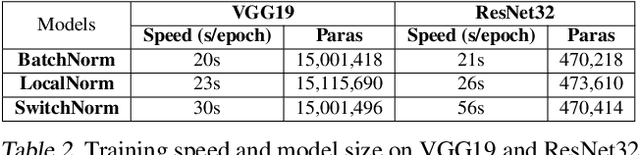
While modern convolutional neural networks achieve outstanding accuracy on many image classification tasks, they are, compared to humans, much more sensitive to image degradation. Here, we describe a variant of Batch Normalization, LocalNorm, that regularizes the normalization layer in the spirit of Dropout while dynamically adapting to the local image intensity and contrast at test-time. We show that the resulting deep neural networks are much more resistant to noise-induced image degradation, improving accuracy by up to three times, while achieving the same or slightly better accuracy on non-degraded classical benchmarks. In computational terms, LocalNorm adds negligible training cost and little or no cost at inference time, and can be applied to already-trained networks in a straightforward manner.
Sparse convolutional context-aware multiple instance learning for whole slide image classification
May 06, 2021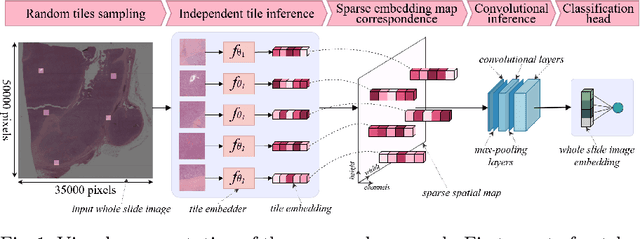
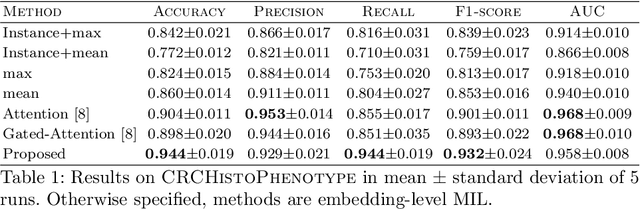
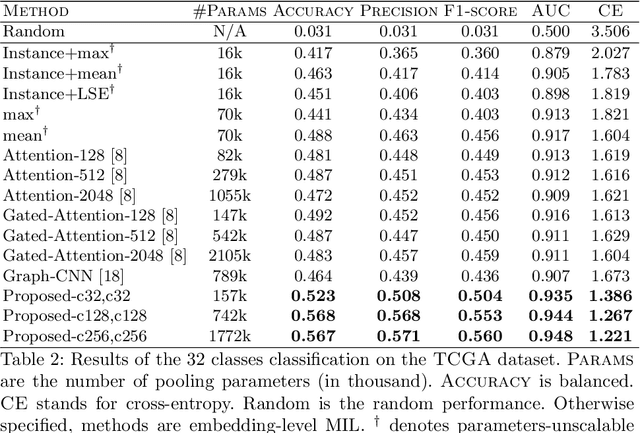
Whole slide microscopic slides display many cues about the underlying tissue guiding diagnostic and the choice of therapy for many diseases. However, their enormous size often in gigapixels hampers the use of traditional neural network architectures. To tackle this issue, multiple instance learning (MIL) classifies bags of patches instead of whole slide images. Most MIL strategies consider that patches are independent and identically distributed. Our approach presents a paradigm shift through the integration of spatial information of patches with a sparse-input convolutional-based MIL strategy. The formulated framework is generic, flexible, scalable and is the first to introduce contextual dependencies between decisions taken at the patch level. It achieved state-of-the-art performance in pan-cancer subtype classification. The code of this work will be made available.
Generating Synthetic Training Data for Deep Learning-Based UAV Trajectory Prediction
Jul 01, 2021



Deep learning-based models, such as recurrent neural networks (RNNs), have been applied to various sequence learning tasks with great success. Following this, these models are increasingly replacing classic approaches in object tracking applications for motion prediction. On the one hand, these models can capture complex object dynamics with less modeling required, but on the other hand, they depend on a large amount of training data for parameter tuning. Towards this end, we present an approach for generating synthetic trajectory data of unmanned-aerial-vehicles (UAVs) in image space. Since UAVs, or rather quadrotors are dynamical systems, they can not follow arbitrary trajectories. With the prerequisite that UAV trajectories fulfill a smoothness criterion corresponding to a minimal change of higher-order motion, methods for planning aggressive quadrotors flights can be utilized to generate optimal trajectories through a sequence of 3D waypoints. By projecting these maneuver trajectories, which are suitable for controlling quadrotors, to image space, a versatile trajectory data set is realized. To demonstrate the applicability of the synthetic trajectory data, we show that an RNN-based prediction model solely trained on the generated data can outperform classic reference models on a real-world UAV tracking dataset. The evaluation is done on the publicly available ANTI-UAV dataset.
A Comparative Study of Convolutional Neural Networks for the Detection of Strong Gravitational Lensing
Jun 03, 2021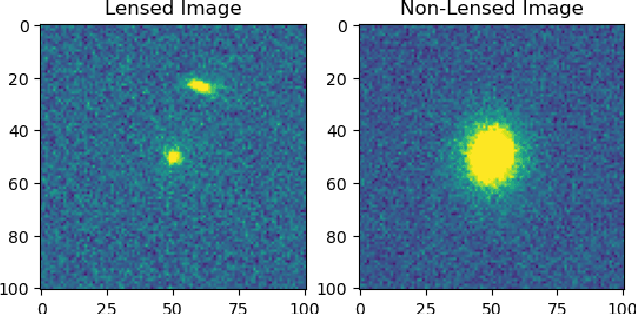

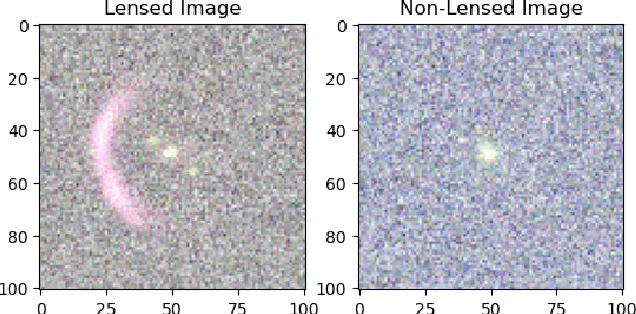
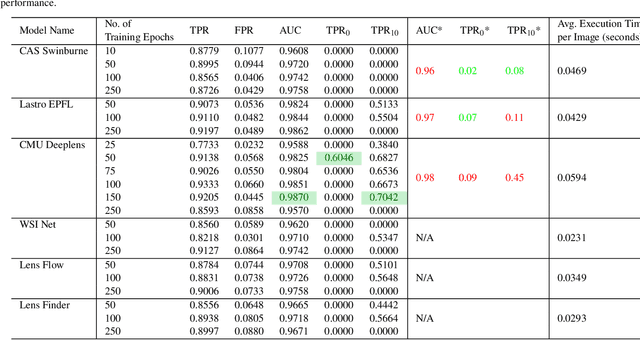
As we enter the era of large-scale imaging surveys with the up-coming telescopes such as LSST and SKA, it is envisaged that the number of known strong gravitational lensing systems will increase dramatically. However, these events are still very rare and require the efficient processing of millions of images. In order to tackle this image processing problem, we present Machine Learning techniques and apply them to the Gravitational Lens Finding Challenge. The Convolutional Neural Networks (CNNs) presented have been re-implemented within a new modular, and extendable framework, LEXACTUM. We report an Area Under the Curve (AUC) of 0.9343 and 0.9870, and an execution time of 0.0061s and 0.0594s per image, for the Space and Ground datasets respectively, showing that the results obtained by CNNs are very competitive with conventional methods (such as visual inspection and arc finders) for detecting gravitational lenses.
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021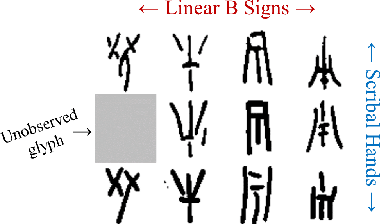
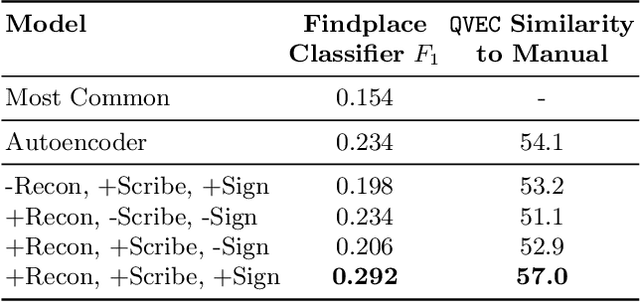
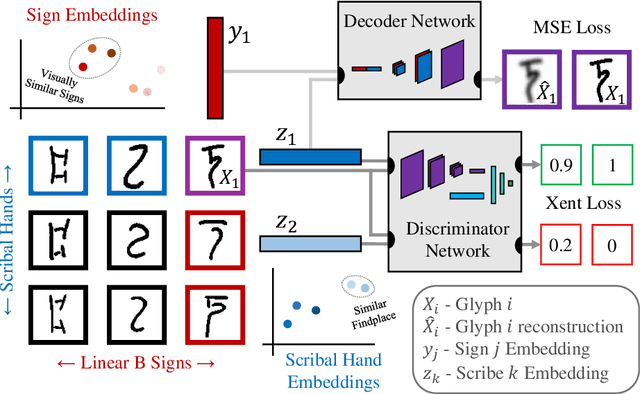
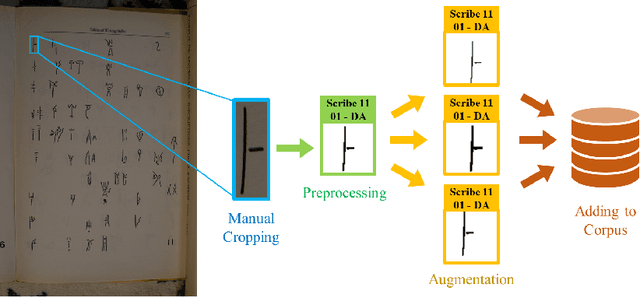
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.