 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Sequential Feature Learning in Clinical Image Classification of Infectious Keratitis
Jun 04, 2020
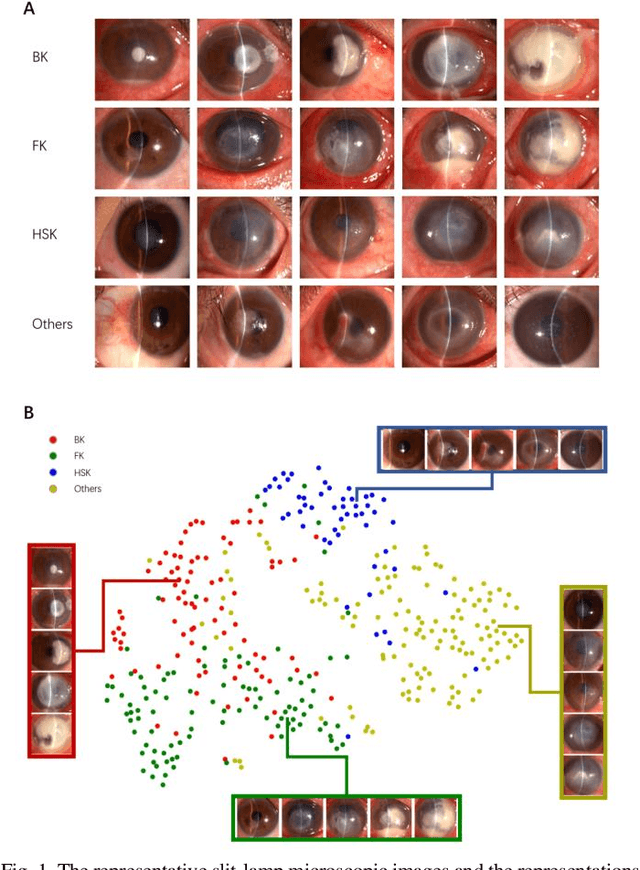
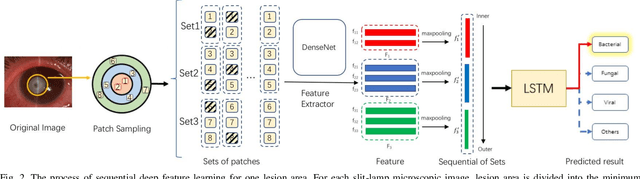
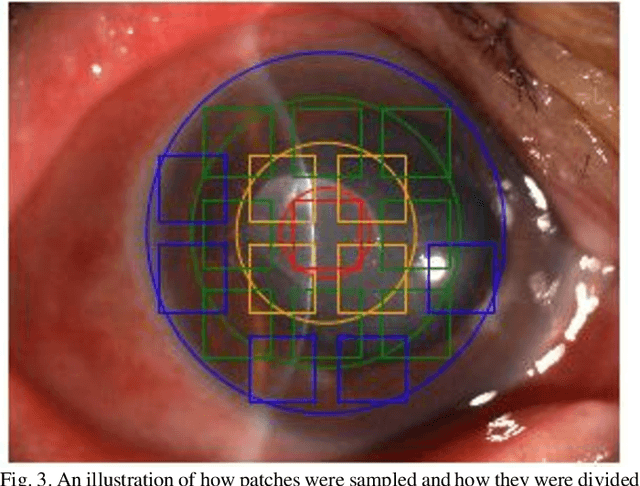
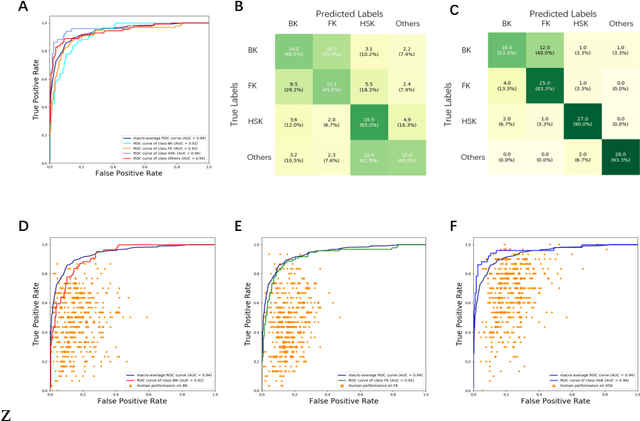
Infectious keratitis is the most common entities of corneal diseases, in which pathogen grows in the cornea leading to inflammation and destruction of the corneal tissues. Infectious keratitis is a medical emergency, for which a rapid and accurate diagnosis is needed for speedy initiation of prompt and precise treatment to halt the disease progress and to limit the extent of corneal damage; otherwise it may develop sight-threatening and even eye-globe-threatening condition. In this paper, we propose a sequential-level deep learning model to effectively discriminate the distinction and subtlety of infectious corneal disease via the classification of clinical images. In this approach, we devise an appropriate mechanism to preserve the spatial structures of clinical images and disentangle the informative features for clinical image classification of infectious keratitis. In competition with 421 ophthalmologists, the performance of the proposed sequential-level deep model achieved 80.00% diagnostic accuracy, far better than the 49.27% diagnostic accuracy achieved by ophthalmologists over 120 test images.
An End-to-end Entangled Segmentation and Classification Convolutional Neural Network for Periodontitis Stage Grading from Periapical Radiographic Images
Sep 27, 2021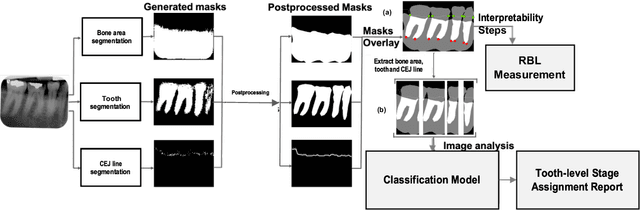
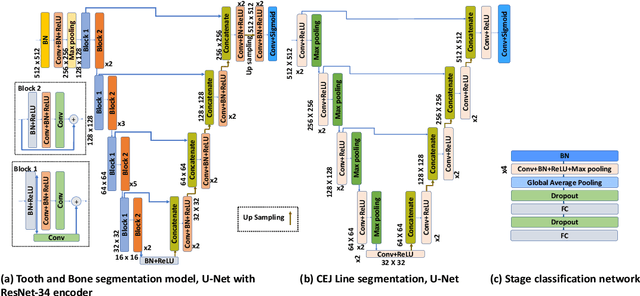
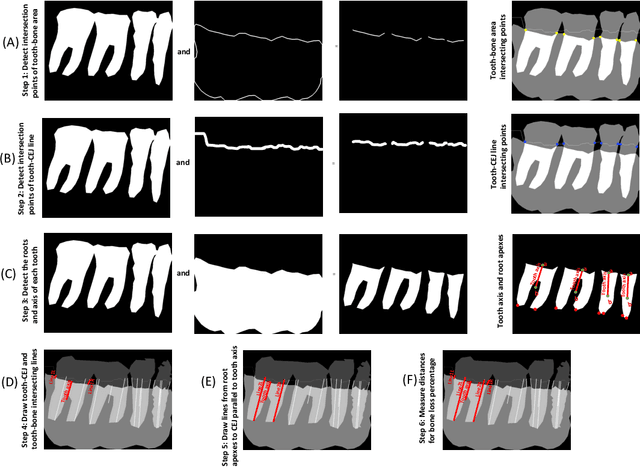
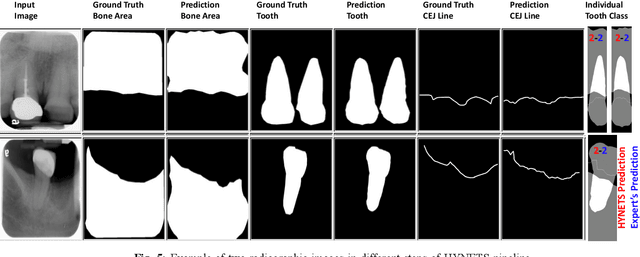
Periodontitis is a biofilm-related chronic inflammatory disease characterized by gingivitis and bone loss in the teeth area. Approximately 61 million adults over 30 suffer from periodontitis (42.2%), with 7.8% having severe periodontitis in the United States. The measurement of radiographic bone loss (RBL) is necessary to make a correct periodontal diagnosis, especially if the comprehensive and longitudinal periodontal mapping is unavailable. However, doctors can interpret X-rays differently depending on their experience and knowledge. Computerized diagnosis support for doctors sheds light on making the diagnosis with high accuracy and consistency and drawing up an appropriate treatment plan for preventing or controlling periodontitis. We developed an end-to-end deep learning network HYNETS (Hybrid NETwork for pEriodoNTiTiS STagES from radiograpH) by integrating segmentation and classification tasks for grading periodontitis from periapical radiographic images. HYNETS leverages a multi-task learning strategy by combining a set of segmentation networks and a classification network to provide an end-to-end interpretable solution and highly accurate and consistent results. HYNETS achieved the average dice coefficient of 0.96 and 0.94 for the bone area and tooth segmentation and the average AUC of 0.97 for periodontitis stage assignment. Additionally, conventional image processing techniques provide RBL measurements and build transparency and trust in the model's prediction. HYNETS will potentially transform clinical diagnosis from a manual time-consuming, and error-prone task to an efficient and automated periodontitis stage assignment based on periapical radiographic images.
Generating Synthetic Training Data for Deep Learning-Based UAV Trajectory Prediction
Jul 01, 2021



Deep learning-based models, such as recurrent neural networks (RNNs), have been applied to various sequence learning tasks with great success. Following this, these models are increasingly replacing classic approaches in object tracking applications for motion prediction. On the one hand, these models can capture complex object dynamics with less modeling required, but on the other hand, they depend on a large amount of training data for parameter tuning. Towards this end, we present an approach for generating synthetic trajectory data of unmanned-aerial-vehicles (UAVs) in image space. Since UAVs, or rather quadrotors are dynamical systems, they can not follow arbitrary trajectories. With the prerequisite that UAV trajectories fulfill a smoothness criterion corresponding to a minimal change of higher-order motion, methods for planning aggressive quadrotors flights can be utilized to generate optimal trajectories through a sequence of 3D waypoints. By projecting these maneuver trajectories, which are suitable for controlling quadrotors, to image space, a versatile trajectory data set is realized. To demonstrate the applicability of the synthetic trajectory data, we show that an RNN-based prediction model solely trained on the generated data can outperform classic reference models on a real-world UAV tracking dataset. The evaluation is done on the publicly available ANTI-UAV dataset.
Paint by Word
Mar 24, 2021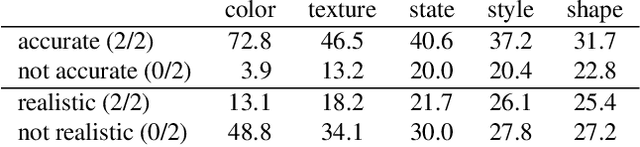
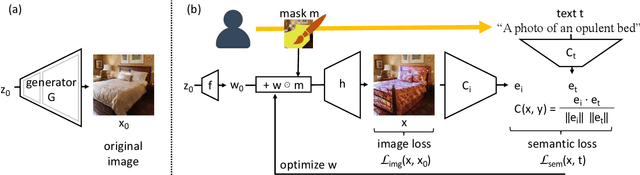

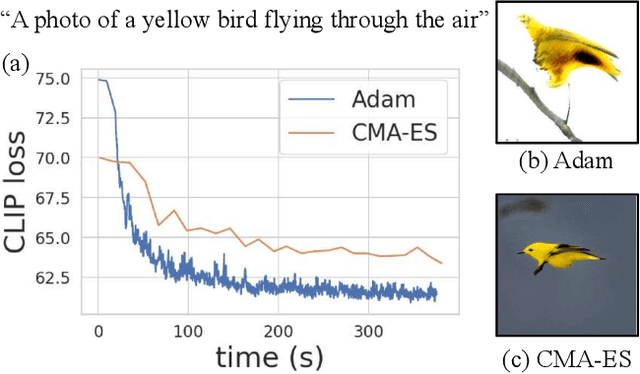
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021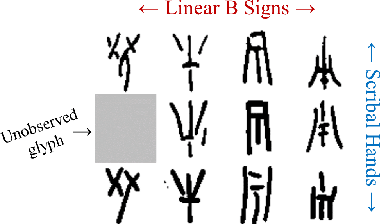
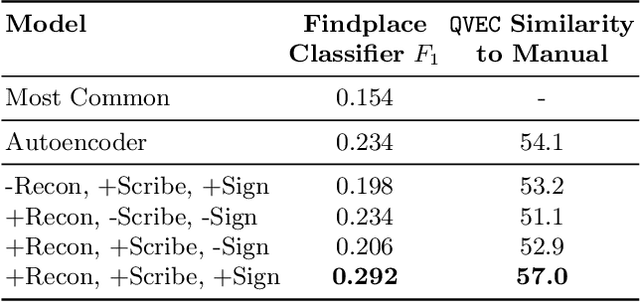
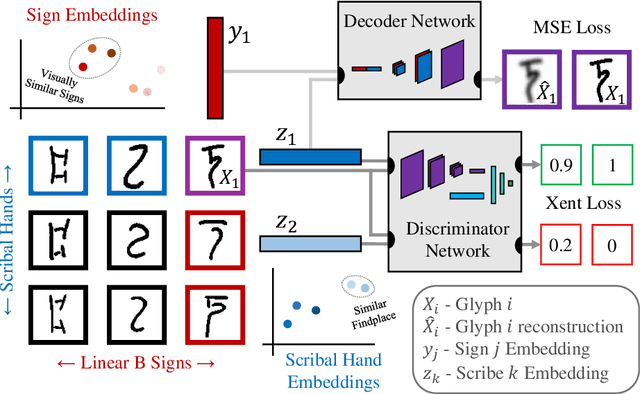
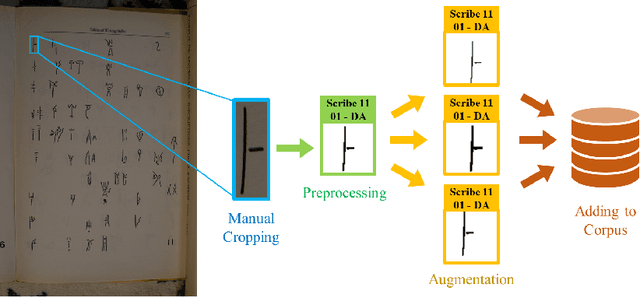
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.
Boosting Crowd Counting with Transformers
May 23, 2021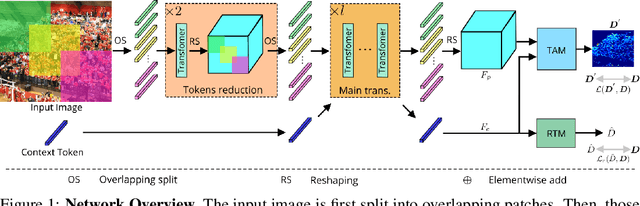
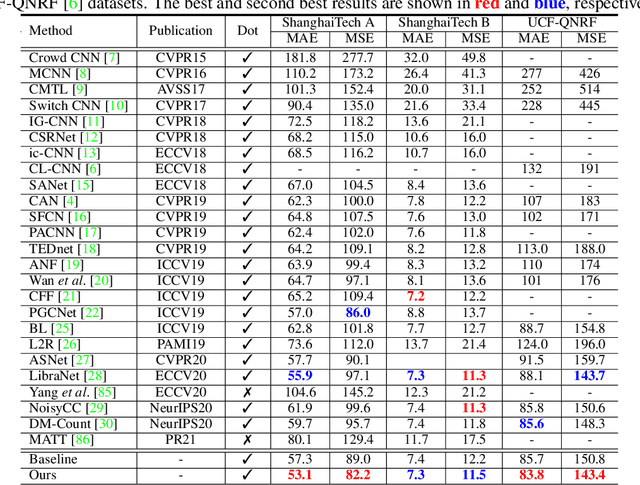
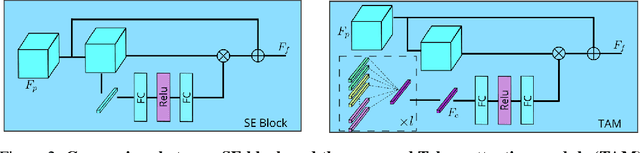
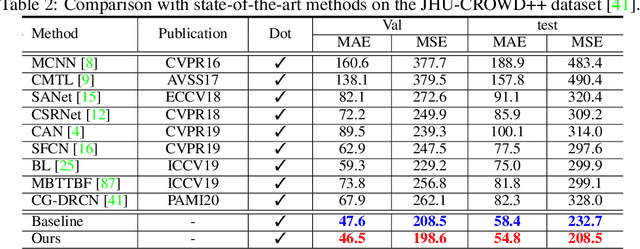
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
Image-Question-Answer Synergistic Network for Visual Dialog
Feb 26, 2019
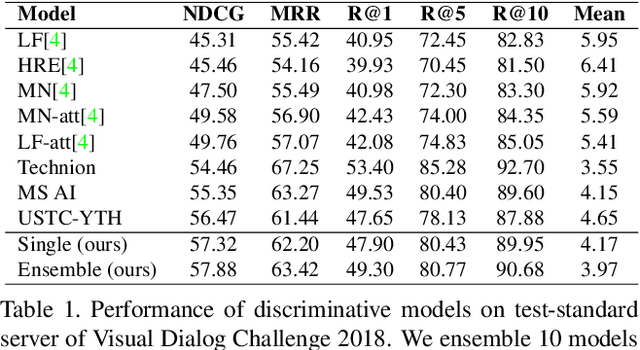

The image, question (combined with the history for de-referencing), and the corresponding answer are three vital components of visual dialog. Classical visual dialog systems integrate the image, question, and history to search for or generate the best matched answer, and so, this approach significantly ignores the role of the answer. In this paper, we devise a novel image-question-answer synergistic network to value the role of the answer for precise visual dialog. We extend the traditional one-stage solution to a two-stage solution. In the first stage, candidate answers are coarsely scored according to their relevance to the image and question pair. Afterward, in the second stage, answers with high probability of being correct are re-ranked by synergizing with image and question. On the Visual Dialog v1.0 dataset, the proposed synergistic network boosts the discriminative visual dialog model to achieve a new state-of-the-art of 57.88\% normalized discounted cumulative gain. A generative visual dialog model equipped with the proposed technique also shows promising improvements.
Direct Estimation of Appearance Models for Segmentation
Feb 22, 2021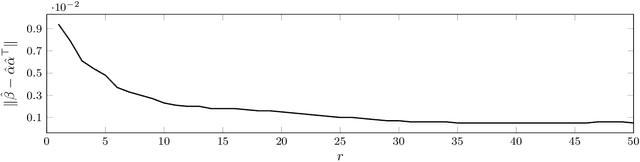
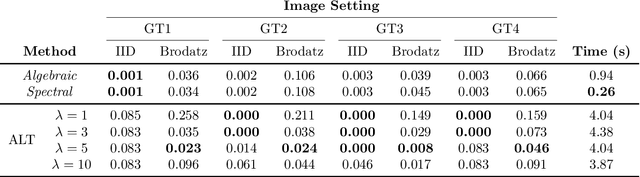
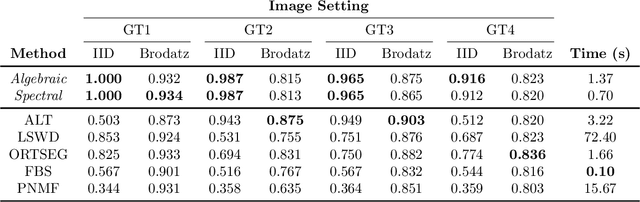
Image segmentation algorithms often depend on appearance models that characterize the distribution of pixel values in different image regions. We describe a novel approach for estimating appearance models directly from an image, without explicit consideration of the pixels that make up each region. Our approach is based on algebraic expressions that relate local image statistics to the appearance models of spatially coherent regions. We describe two algorithms that can use the aforementioned algebraic expressions for estimating appearance models. The first algorithm is based on solving a system of linear and quadratic equations. The second algorithm is a spectral method based on an eigenvector computation. We present experimental results that demonstrate the proposed methods work well in practice and lead to effective image segmentation algorithms.
NeMI: Unifying Neural Radiance Fields with Multiplane Images for Novel View Synthesis
Mar 27, 2021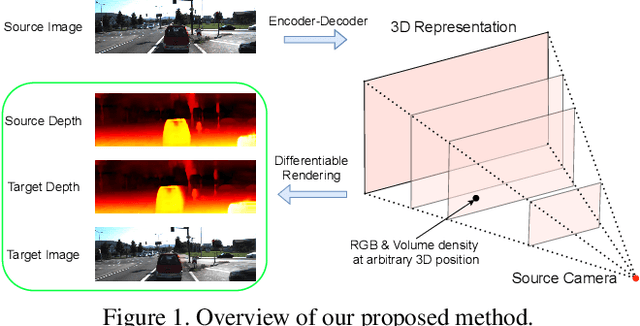
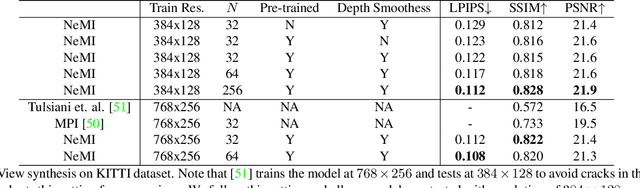
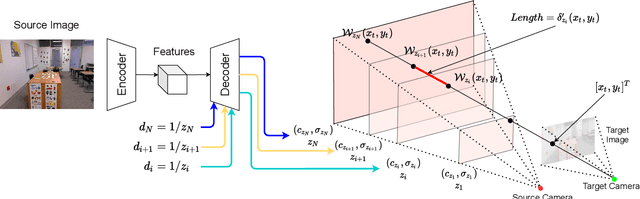

In this paper, we propose an approach to perform novel view synthesis and depth estimation via dense 3D reconstruction from a single image. Our NeMI unifies Neural radiance fields (NeRF) with Multiplane Images (MPI). Specifically, our NeMI is a general two-dimensional and image-conditioned extension of NeRF, and a continuous depth generalization of MPI. Given a single image as input, our method predicts a 4-channel image (RGB and volume density) at arbitrary depth values to jointly reconstruct the camera frustum and fill in occluded contents. The reconstructed and inpainted frustum can then be easily rendered into novel RGB or depth views using differentiable rendering. Extensive experiments on RealEstate10K, KITTI and Flowers Light Fields show that our NeMI outperforms state-of-the-art by a large margin in novel view synthesis. We also achieve competitive results in depth estimation on iBims-1 and NYU-v2 without annotated depth supervision. Project page available at https://vincentfung13.github.io/projects/nemi/
Detecting Layout Templates in Complex Multiregion Files
Sep 15, 2021
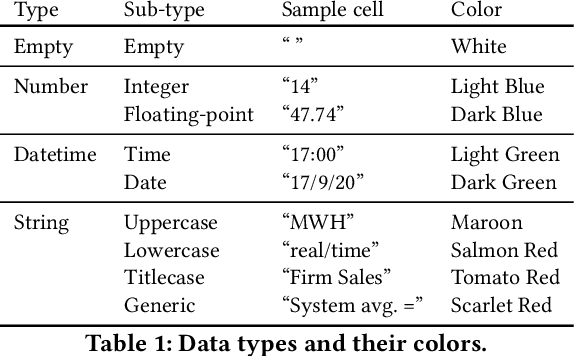
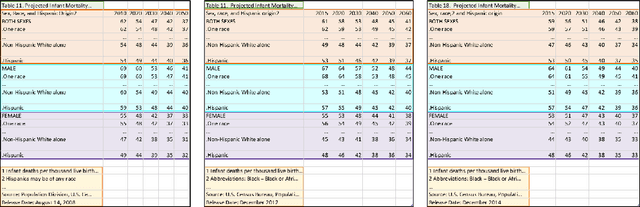

Spreadsheets are among the most commonly used file formats for data management, distribution, and analysis. Their widespread employment makes it easy to gather large collections of data, but their flexible canvas-based structure makes automated analysis difficult without heavy preparation. One of the common problems that practitioners face is the presence of multiple, independent regions in a single spreadsheet, possibly separated by repeated empty cells. We define such files as "multiregion" files. In collections of various spreadsheets, we can observe that some share the same layout. We present the Mondrian approach to automatically identify layout templates across multiple files and systematically extract the corresponding regions. Our approach is composed of three phases: first, each file is rendered as an image and inspected for elements that could form regions; then, using a clustering algorithm, the identified elements are grouped to form regions; finally, every file layout is represented as a graph and compared with others to find layout templates. We compare our method to state-of-the-art table recognition algorithms on two corpora of real-world enterprise spreadsheets. Our approach shows the best performances in detecting reliable region boundaries within each file and can correctly identify recurring layouts across files.