 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Training Using Natural Transformation
May 10, 2021

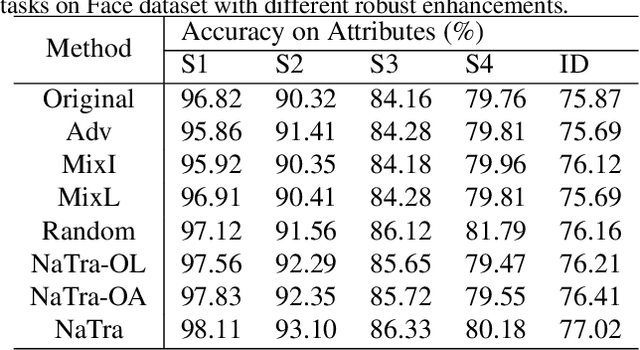

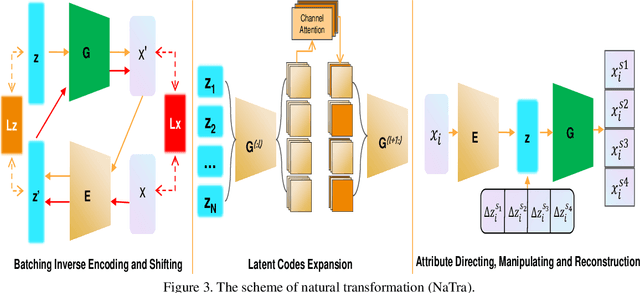
Previous robustness approaches for deep learning models such as data augmentation techniques via data transformation or adversarial training cannot capture real-world variations that preserve the semantics of the input, such as a change in lighting conditions. To bridge this gap, we present NaTra, an adversarial training scheme that is designed to improve the robustness of image classification algorithms. We target attributes of the input images that are independent of the class identification, and manipulate those attributes to mimic real-world natural transformations (NaTra) of the inputs, which are then used to augment the training dataset of the image classifier. Specifically, we apply \textit{Batch Inverse Encoding and Shifting} to map a batch of given images to corresponding disentangled latent codes of well-trained generative models. \textit{Latent Codes Expansion} is used to boost image reconstruction quality through the incorporation of extended feature maps. \textit{Unsupervised Attribute Directing and Manipulation} enables identification of the latent directions that correspond to specific attribute changes, and then produce interpretable manipulations of those attributes, thereby generating natural transformations to the input data. We demonstrate the efficacy of our scheme by utilizing the disentangled latent representations derived from well-trained GANs to mimic transformations of an image that are similar to real-world natural variations (such as lighting conditions or hairstyle), and train models to be invariant to these natural transformations. Extensive experiments show that our method improves generalization of classification models and increases its robustness to various real-world distortions
Differential Diagnosis of Frontotemporal Dementia and Alzheimer's Disease using Generative Adversarial Network
Sep 12, 2021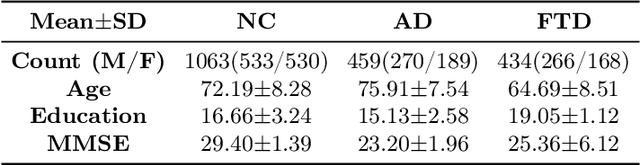
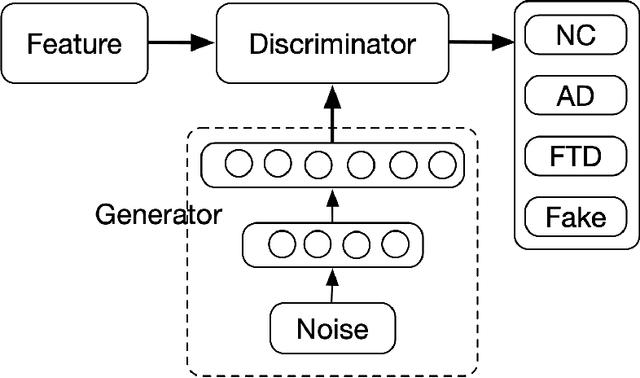
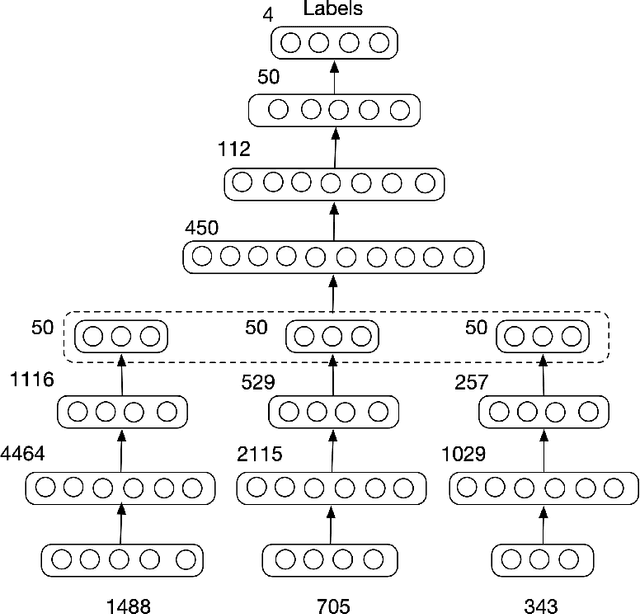
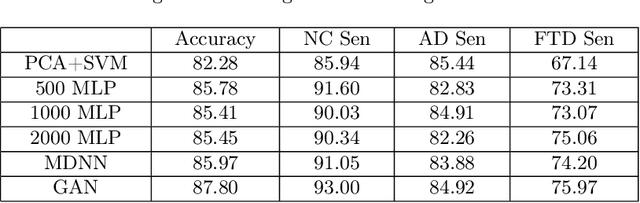
Frontotemporal dementia and Alzheimer's disease are two common forms of dementia and are easily misdiagnosed as each other due to their similar pattern of clinical symptoms. Differentiating between the two dementia types is crucial for determining disease-specific intervention and treatment. Recent development of Deep-learning-based approaches in the field of medical image computing are delivering some of the best performance for many binary classification tasks, although its application in differential diagnosis, such as neuroimage-based differentiation for multiple types of dementia, has not been explored. In this study, a novel framework was proposed by using the Generative Adversarial Network technique to distinguish FTD, AD and normal control subjects, using volumetric features extracted at coarse-to-fine structural scales from Magnetic Resonance Imaging scans. Experiments of 10-folds cross-validation on 1,954 images achieved high accuracy. With the proposed framework, we have demonstrated that the combination of multi-scale structural features and synthetic data augmentation based on generative adversarial network can improve the performance of challenging tasks such as differentiating Dementia sub-types.
NeMI: Unifying Neural Radiance Fields with Multiplane Images for Novel View Synthesis
Apr 08, 2021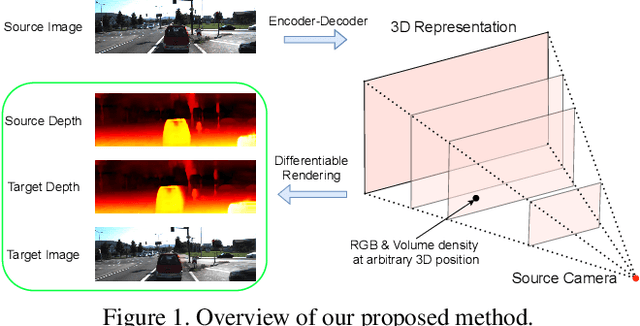
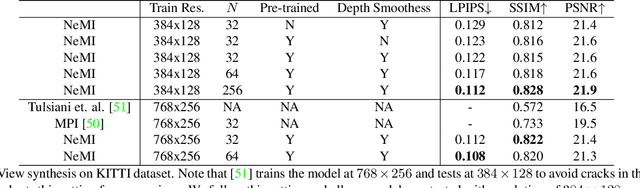
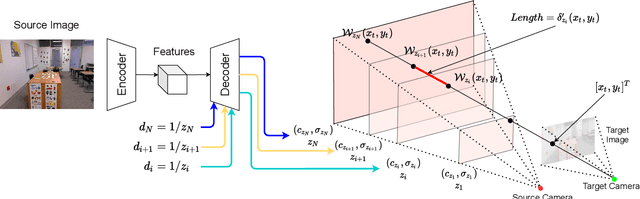

In this paper, we propose an approach to perform novel view synthesis and depth estimation via dense 3D reconstruction from a single image. Our NeMI unifies Neural radiance fields (NeRF) with Multiplane Images (MPI). Specifically, our NeMI is a general two-dimensional and image-conditioned extension of NeRF, and a continuous depth generalization of MPI. Given a single image as input, our method predicts a 4-channel image (RGB and volume density) at arbitrary depth values to jointly reconstruct the camera frustum and fill in occluded contents. The reconstructed and inpainted frustum can then be easily rendered into novel RGB or depth views using differentiable rendering. Extensive experiments on RealEstate10K, KITTI and Flowers Light Fields show that our NeMI outperforms state-of-the-art by a large margin in novel view synthesis. We also achieve competitive results in depth estimation on iBims-1 and NYU-v2 without annotated depth supervision. Project page available at https://vincentfung13.github.io/projects/nemi/
Uncertainty-Aware Multi-Shot Knowledge Distillation for Image-Based Object Re-Identification
Jan 15, 2020



Object re-identification (re-id) aims to identify a specific object across times or camera views, with the person re-id and vehicle re-id as the most widely studied applications. Re-id is challenging because of the variations in viewpoints, (human) poses, and occlusions. Multi-shots of the same object can cover diverse viewpoints/poses and thus provide more comprehensive information. In this paper, we propose exploiting the multi-shots of the same identity to guide the feature learning of each individual image. Specifically, we design an Uncertainty-aware Multi-shot Teacher-Student (UMTS) Network. It consists of a teacher network (T-net) that learns the comprehensive features from multiple images of the same object, and a student network (S-net) that takes a single image as input. In particular, we take into account the data dependent heteroscedastic uncertainty for effectively transferring the knowledge from the T-net to S-net. To the best of our knowledge, we are the first to make use of multi-shots of an object in a teacher-student learning manner for effectively boosting the single image based re-id. We validate the effectiveness of our approach on the popular vehicle re-id and person re-id datasets. In inference, the S-net alone significantly outperforms the baselines and achieves the state-of-the-art performance.
Self-supervised Learning with Local Attention-Aware Feature
Aug 01, 2021
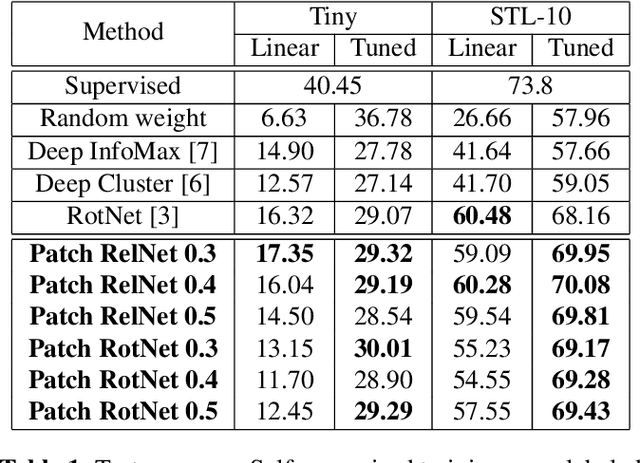
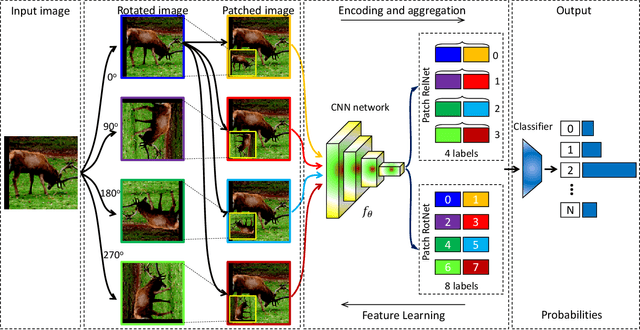
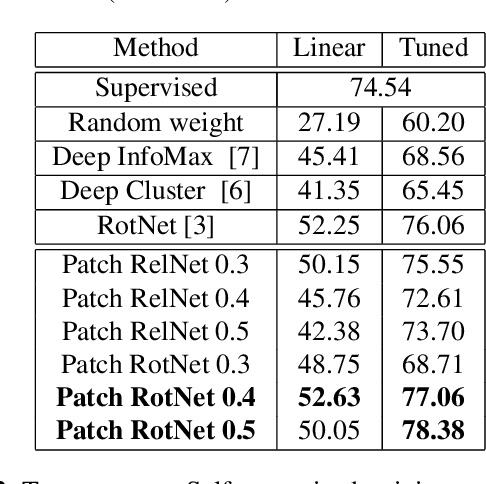
In this work, we propose a novel methodology for self-supervised learning for generating global and local attention-aware visual features. Our approach is based on training a model to differentiate between specific image transformations of an input sample and the patched images. Utilizing this approach, the proposed method is able to outperform the previous best competitor by 1.03% on the Tiny-ImageNet dataset and by 2.32% on the STL-10 dataset. Furthermore, our approach outperforms the fully-supervised learning method on the STL-10 dataset. Experimental results and visualizations show the capability of successfully learning global and local attention-aware visual representations.
Aerial Scene Understanding in The Wild: Multi-Scene Recognition via Prototype-based Memory Networks
Apr 22, 2021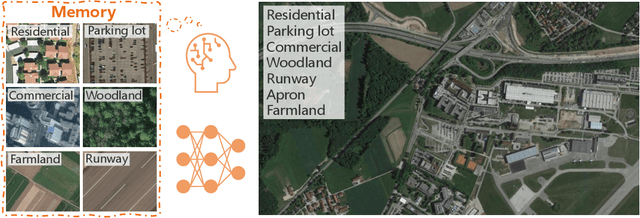
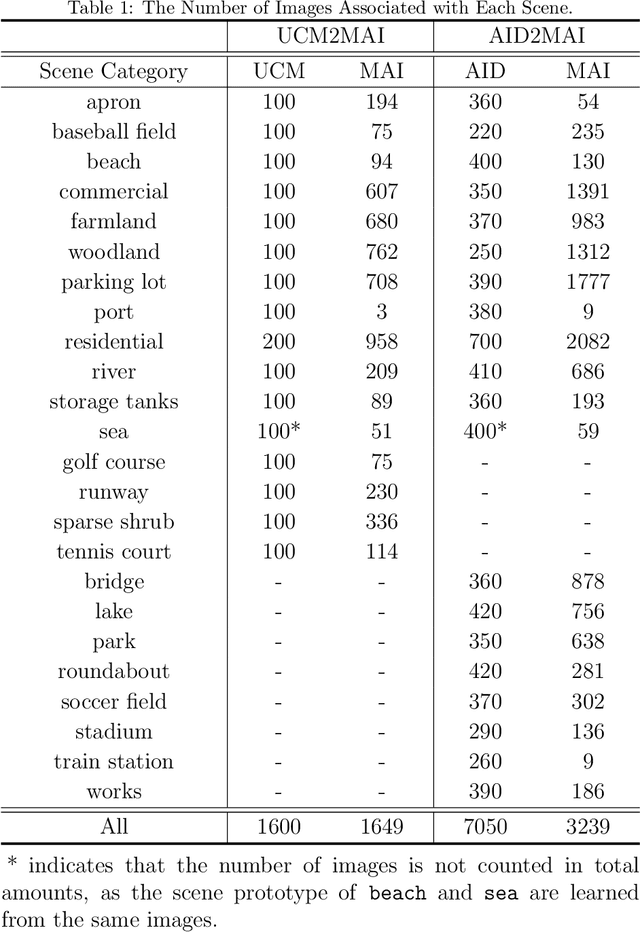

Aerial scene recognition is a fundamental visual task and has attracted an increasing research interest in the last few years. Most of current researches mainly deploy efforts to categorize an aerial image into one scene-level label, while in real-world scenarios, there often exist multiple scenes in a single image. Therefore, in this paper, we propose to take a step forward to a more practical and challenging task, namely multi-scene recognition in single images. Moreover, we note that manually yielding annotations for such a task is extraordinarily time- and labor-consuming. To address this, we propose a prototype-based memory network to recognize multiple scenes in a single image by leveraging massive well-annotated single-scene images. The proposed network consists of three key components: 1) a prototype learning module, 2) a prototype-inhabiting external memory, and 3) a multi-head attention-based memory retrieval module. To be more specific, we first learn the prototype representation of each aerial scene from single-scene aerial image datasets and store it in an external memory. Afterwards, a multi-head attention-based memory retrieval module is devised to retrieve scene prototypes relevant to query multi-scene images for final predictions. Notably, only a limited number of annotated multi-scene images are needed in the training phase. To facilitate the progress of aerial scene recognition, we produce a new multi-scene aerial image (MAI) dataset. Experimental results on variant dataset configurations demonstrate the effectiveness of our network. Our dataset and codes are publicly available.
Stereo Dense Scene Reconstruction and Accurate Laparoscope Localization for Learning-Based Navigation in Robot-Assisted Surgery
Oct 08, 2021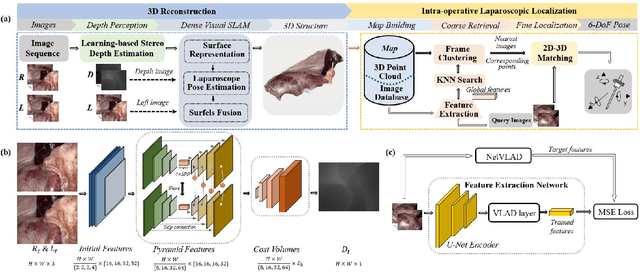
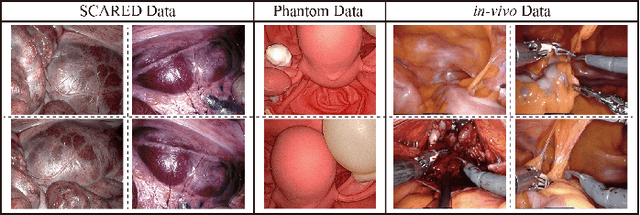
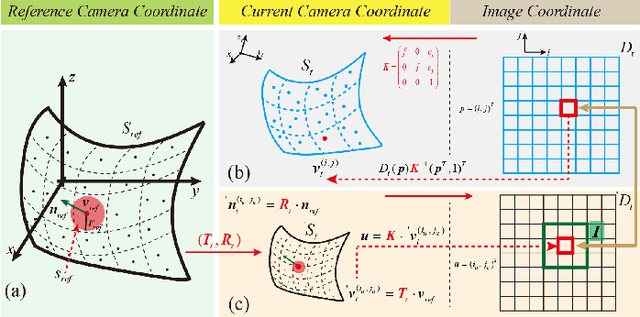
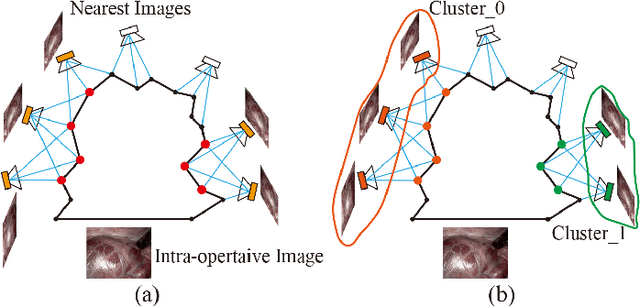
The computation of anatomical information and laparoscope position is a fundamental block of robot-assisted surgical navigation in Minimally Invasive Surgery (MIS). Recovering a dense 3D structure of surgical scene using visual cues remains a challenge, and the online laparoscopic tracking mostly relies on external sensors, which increases system complexity. In this paper, we propose a learning-driven framework, in which an image-guided laparoscopic localization with 3D reconstructions of complex anatomical structures is hereby achieved. To reconstruct the 3D structure of the whole surgical environment, we first fine-tune a learning-based stereoscopic depth perception method, which is robust to the texture-less and variant soft tissues, for depth estimation. Then, we develop a dense visual reconstruction algorithm to represent the scene by surfels, estimate the laparoscope pose and fuse the depth data into a unified reference coordinate for tissue reconstruction. To estimate poses of new laparoscope views, we realize a coarse-to-fine localization method, which incorporates our reconstructed 3D model. We evaluate the reconstruction method and the localization module on three datasets, namely, the stereo correspondence and reconstruction of endoscopic data (SCARED), the ex-vivo phantom and tissue data collected with Universal Robot (UR) and Karl Storz Laparoscope, and the in-vivo DaVinci robotic surgery dataset. Extensive experiments have been conducted to prove the superior performance of our method in 3D anatomy reconstruction and laparoscopic localization, which demonstrates its potential implementation to surgical navigation system.
Accelerating the Registration of Image Sequences by Spatio-temporal Multilevel Strategies
Jan 18, 2020
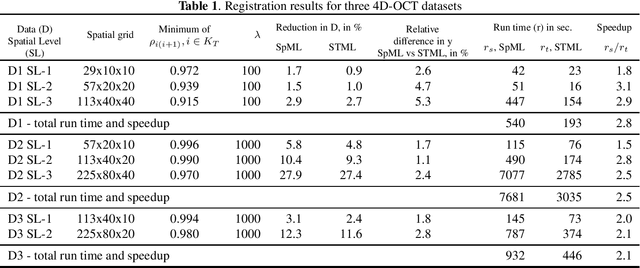
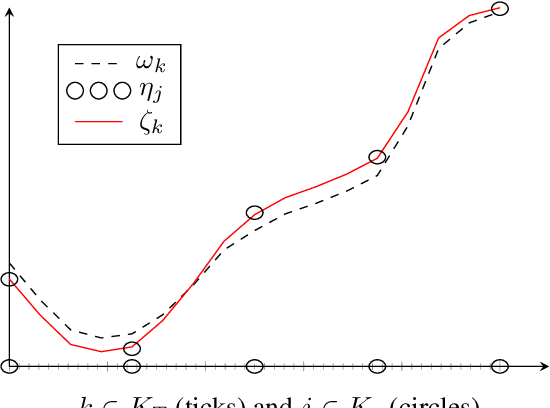

Multilevel strategies are an integral part of many image registration algorithms. These strategies are very well-known for avoiding undesirable local minima, providing an outstanding initial guess, and reducing overall computation time. State-of-the-art multilevel strategies build a hierarchy of discretization in the spatial dimensions. In this paper, we present a spatio-temporal strategy, where we introduce a hierarchical discretization in the temporal dimension at each spatial level. This strategy is suitable for a motion estimation problem where the motion is assumed smooth over time. Our strategy exploits the temporal smoothness among image frames by following a predictor-corrector approach. The strategy predicts the motion by a novel interpolation method and later corrects it by registration. The prediction step provides a good initial guess for the correction step, hence reduces the overall computational time for registration. The acceleration is achieved by a factor of 2.5 on average, over the state-of-the-art multilevel methods on three examined optical coherence tomography datasets.
Towards Interpretable Image Synthesis by Learning Sparsely Connected AND-OR Networks
Sep 10, 2019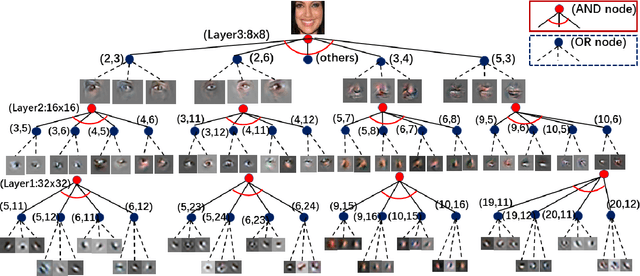

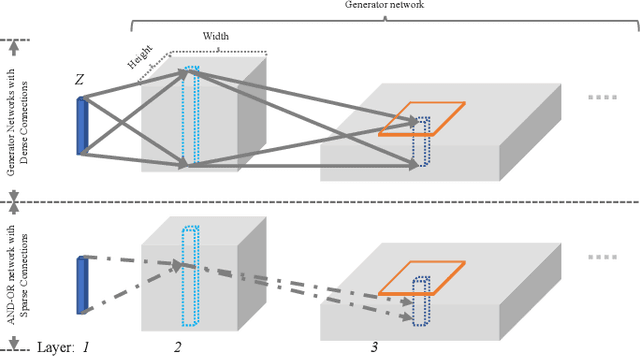

This paper proposes interpretable image synthesis by learning hierarchical AND-OR networks of sparsely connected semantically meaningful nodes. The proposed method is based on the compositionality and interpretability of scene-objects-parts-subparts-primitives hierarchy in image representation. A scene has different types (i.e., OR) each of which consists of a number of objects (i.e., AND). This can be recursively formulated across the scene-objects-parts-subparts hierarchy and is terminated at the primitive level (e.g., Gabor wavelets-like basis). To realize this interpretable AND-OR hierarchy in image synthesis, the proposed method consists of two components: (i) Each layer of the hierarchy is represented by an over-completed set of basis functions. The basis functions are instantiated using convolution to be translation covariant. Off-the-shelf convolutional neural architectures are then exploited to implement the hierarchy. (ii) Sparsity-inducing constraints are introduced in end-to-end training, which facilitate a sparsely connected AND-OR network to emerge from initially densely connected convolutional neural networks. A straightforward sparsity-inducing constraint is utilized, that is to only allow the top-$k$ basis functions to be active at each layer (where $k$ is a hyperparameter). The learned basis functions are also capable of image reconstruction to explain away input images. In experiments, the proposed method is tested on five benchmark datasets. The results show that meaningful and interpretable hierarchical representations are learned with better qualities of image synthesis and reconstruction obtained than state-of-the-art baselines.
FocalMix: Semi-Supervised Learning for 3D Medical Image Detection
Mar 20, 2020
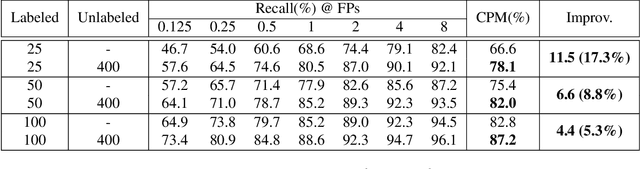
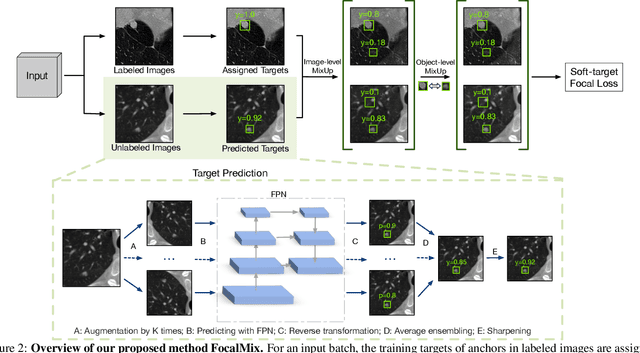
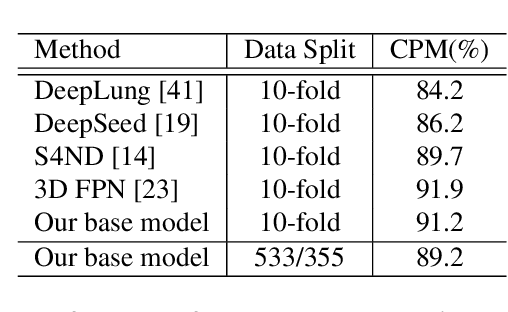
Applying artificial intelligence techniques in medical imaging is one of the most promising areas in medicine. However, most of the recent success in this area highly relies on large amounts of carefully annotated data, whereas annotating medical images is a costly process. In this paper, we propose a novel method, called FocalMix, which, to the best of our knowledge, is the first to leverage recent advances in semi-supervised learning (SSL) for 3D medical image detection. We conducted extensive experiments on two widely used datasets for lung nodule detection, LUNA16 and NLST. Results show that our proposed SSL methods can achieve a substantial improvement of up to 17.3% over state-of-the-art supervised learning approaches with 400 unlabeled CT scans.