 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ghost Panorama
Aug 13, 2021
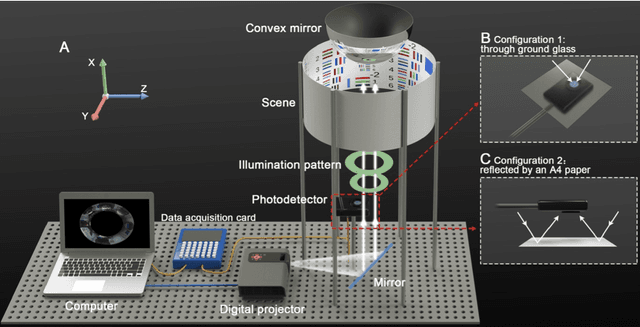
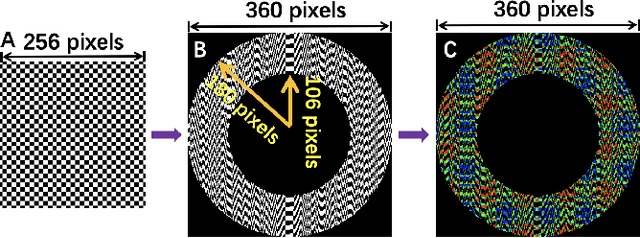


Computational ghost imaging or single-pixel imaging enables the image formation of an unknown scene using a lens-free photodetector. In this Letter, we present a computational panoramic ghost imaging system that can achieve the full-color panorama using a single-pixel photodetector, where a convex mirror performs the optical transformation of the engineered Hadamard-based circular illumination pattern from unidirectionally to omnidirectionally. To our best knowledge, it is the first time to propose the concept of ghost panorama and realize preliminary experimentations. It is foreseeable that ghost panorama will have more advantages in imaging and detection in many extreme conditions (e.g., scattering/turbulence, cryogenic temperatures, and unconventional spectra), as well as broad application prospects in the positioning of fast-moving targets and situation awareness for autonomous vehicles.
Multi-loss ensemble deep learning for chest X-ray classification
Sep 29, 2021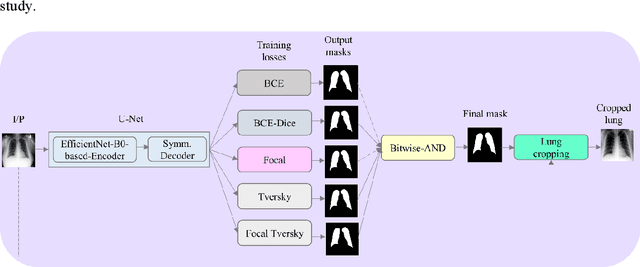
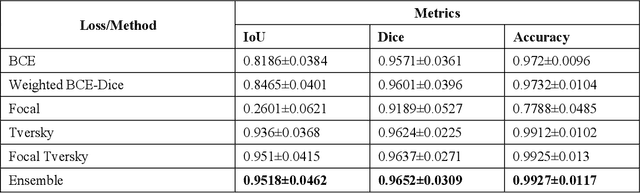
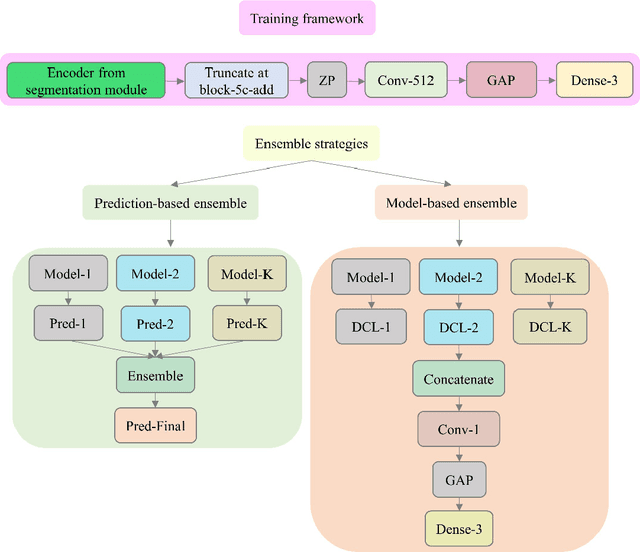
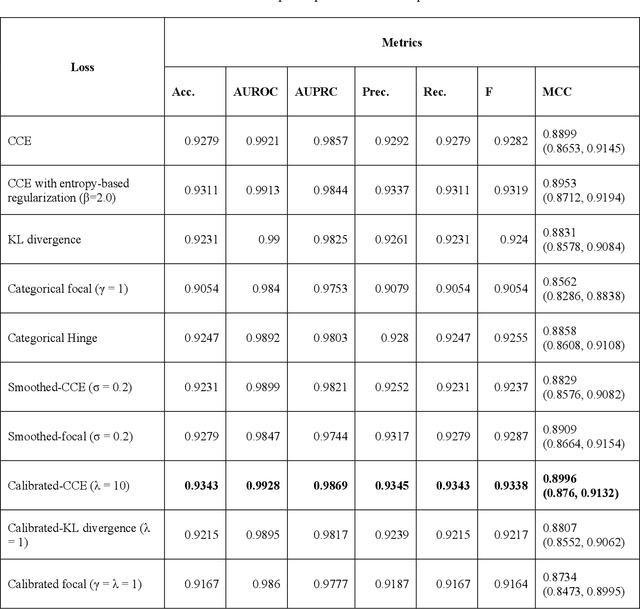
Class imbalance is common in medical image classification tasks, where the number of abnormal samples is fewer than the number of normal samples. The difficulty of imbalanced classification is compounded by other issues such as the size and distribution of the dataset. Reliable training of deep neural networks continues to be a major challenge in such class-imbalanced conditions. The loss function used to train the deep neural networks highly impact the performance of both balanced and imbalanced tasks. Currently, the cross-entropy loss remains the de-facto loss function for balanced and imbalanced classification tasks. This loss, however, asserts equal learning to all classes, leading to the classification of most samples as the majority normal class. To provide a critical analysis of different loss functions and identify those suitable for class-imbalanced classification, we benchmark various state-of-the-art loss functions and propose novel loss functions to train a DL model and analyze its performance in a multiclass classification setting that classifies pediatric chest X-rays as showing normal lungs, bacterial pneumonia, or viral pneumonia manifestations. We also construct prediction-level and model-level ensembles of the models that are trained with various loss functions to improve classification performance. We performed localization studies to interpret model behavior to ensure that the individual models and their ensembles precisely learned the regions of interest showing disease manifestations to classify the chest X-rays to their respective categories.
Image-Based Feature Representation for Insider Threat Classification
Nov 13, 2019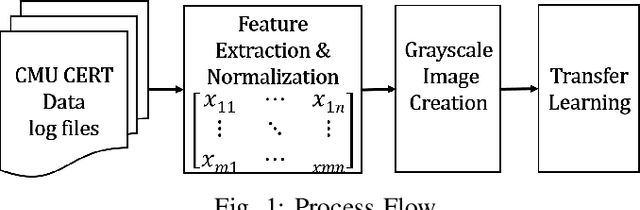
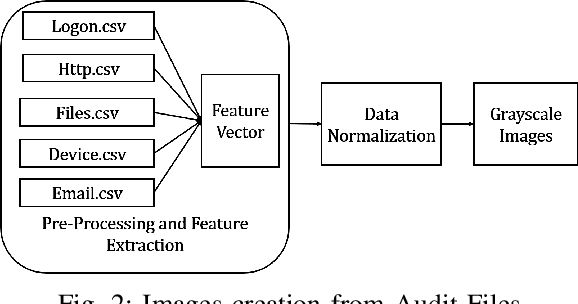

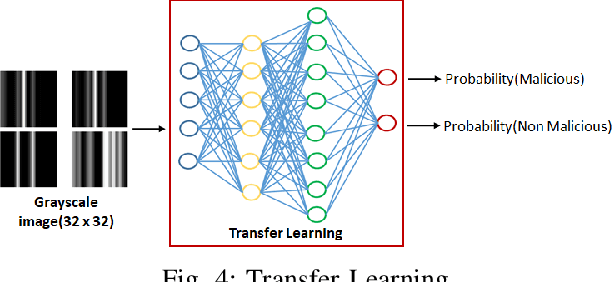
Insiders are the trusted entities in the organization, but poses threat to the with access to sensitive information network and resources. The insider threat detection is a well studied problem in security analytics. Identifying the features from data sources and using them with the right data analytics algorithms makes various kinds of threat analysis possible. The insider threat analysis is mainly done using the frequency based attributes extracted from the raw data available from data sources. In this paper, we propose an image-based feature representation of the daily resource usage pattern of users in the organization. The features extracted from the audit files of the organization are represented as gray scale images. Hence, these images are used to represent the resource access patterns and thereby the behavior of users. Classification models are applied to the representative images to detect anomalous behavior of insiders. The images are classified to malicious and non-malicious. The effectiveness of the proposed representation is evaluated using the CMU CERT data V4.2, and state-of-art image classification models like Mobilenet, VGG and ResNet. The experimental results showed improved accuracy. The comparison with existing works show a performance improvement in terms of high recall and precision values.
Physically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

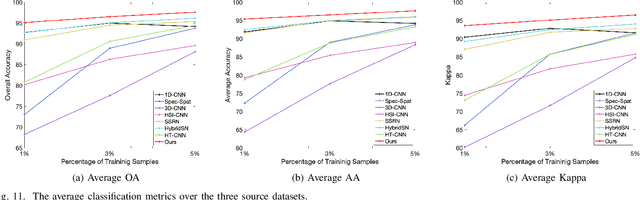
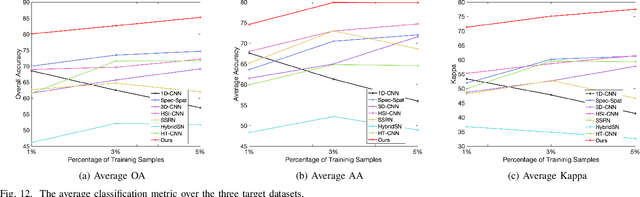
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
Multi-grained Attention Networks for Single Image Super-Resolution
Sep 26, 2019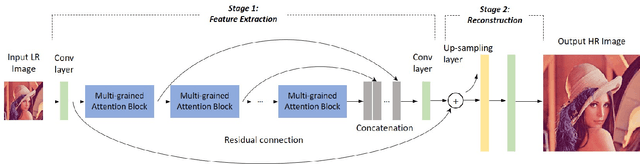
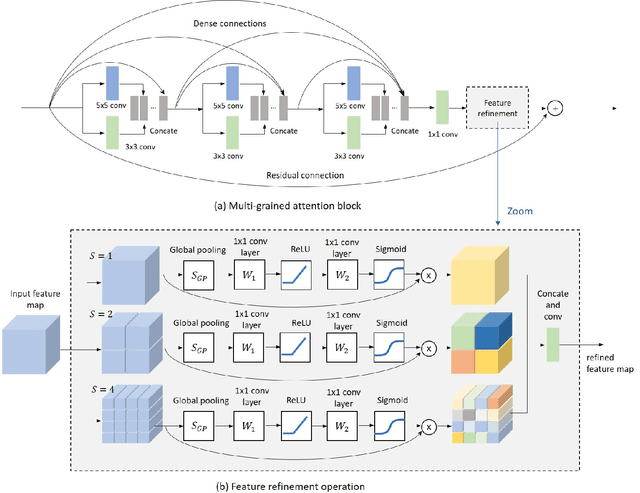


Deep Convolutional Neural Networks (CNN) have drawn great attention in image super-resolution (SR). Recently, visual attention mechanism, which exploits both of the feature importance and contextual cues, has been introduced to image SR and proves to be effective to improve CNN-based SR performance. In this paper, we make a thorough investigation on the attention mechanisms in a SR model and shed light on how simple and effective improvements on these ideas improve the state-of-the-arts. We further propose a unified approach called "multi-grained attention networks (MGAN)" which fully exploits the advantages of multi-scale and attention mechanisms in SR tasks. In our method, the importance of each neuron is computed according to its surrounding regions in a multi-grained fashion and then is used to adaptively re-scale the feature responses. More importantly, the "channel attention" and "spatial attention" strategies in previous methods can be essentially considered as two special cases of our method. We also introduce multi-scale dense connections to extract the image features at multiple scales and capture the features of different layers through dense skip connections. Ablation studies on benchmark datasets demonstrate the effectiveness of our method. In comparison with other state-of-the-art SR methods, our method shows the superiority in terms of both accuracy and model size.
Unsupervised View-Invariant Human Posture Representation
Sep 17, 2021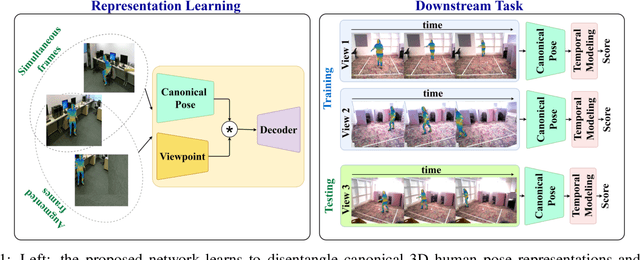

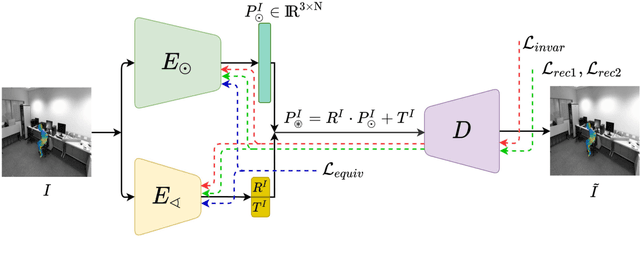
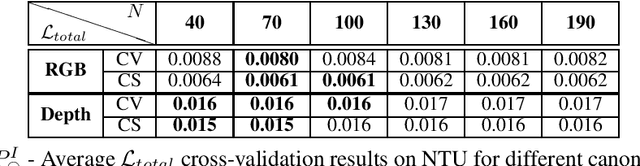
Most recent view-invariant action recognition and performance assessment approaches rely on a large amount of annotated 3D skeleton data to extract view-invariant features. However, acquiring 3D skeleton data can be cumbersome, if not impractical, in in-the-wild scenarios. To overcome this problem, we present a novel unsupervised approach that learns to extract view-invariant 3D human pose representation from a 2D image without using 3D joint data. Our model is trained by exploiting the intrinsic view-invariant properties of human pose between simultaneous frames from different viewpoints and their equivariant properties between augmented frames from the same viewpoint. We evaluate the learned view-invariant pose representations for two downstream tasks. We perform comparative experiments that show improvements on the state-of-the-art unsupervised cross-view action classification accuracy on NTU RGB+D by a significant margin, on both RGB and depth images. We also show the efficiency of transferring the learned representations from NTU RGB+D to obtain the first ever unsupervised cross-view and cross-subject rank correlation results on the multi-view human movement quality dataset, QMAR, and marginally improve on the-state-of-the-art supervised results for this dataset. We also carry out ablation studies to examine the contributions of the different components of our proposed network.
Attend More Times for Image Captioning
Dec 08, 2018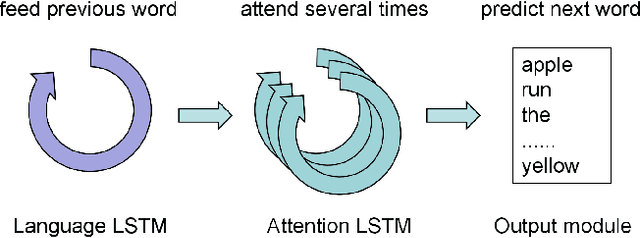
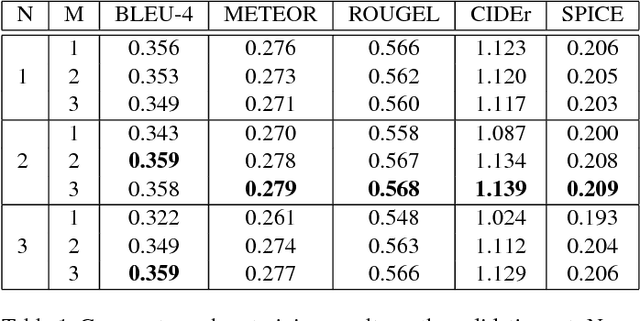
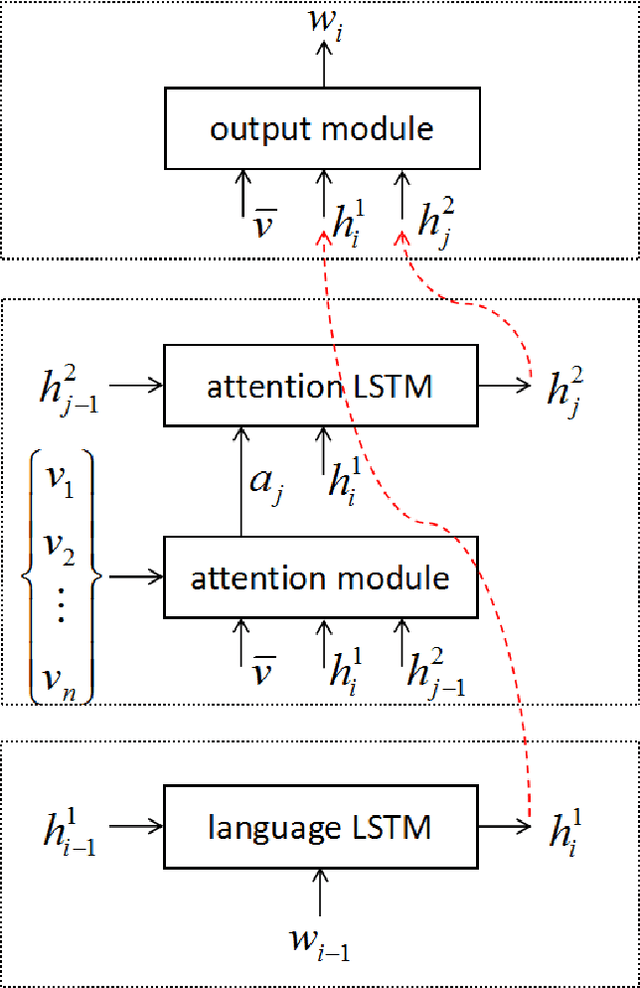
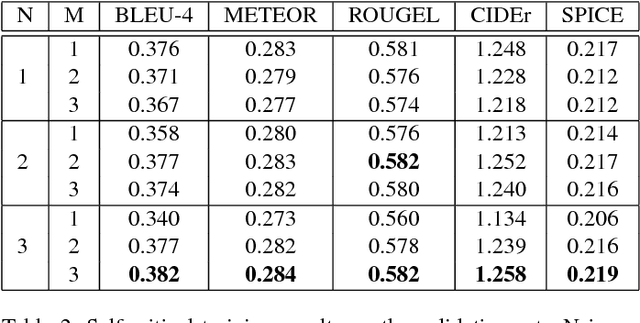
Most attention-based image captioning models attend to the image once per word. However, attending once per word is rigid and is easy to miss some information. Attending more times can adjust the attention position, find the missing information back and avoid generating the wrong word. In this paper, we show that attending more times per word can gain improvements in the image captioning task. We propose a flexible two-LSTM merge model to make it convenient to encode more attentions than words. Our captioning model uses two LSTMs to encode the word sequence and the attention sequence respectively. The information of the two LSTMs and the image feature are combined to predict the next word. Experiments on the MSCOCO caption dataset show that our method outperforms the state-of-the-art. Using bottom up features and self-critical training method, our method gets BLEU-4, METEOR, ROUGE-L and CIDEr scores of 0.381, 0.283, 0.580 and 1.261 on the Karpathy test split.
Colored Transparent Object Matting from a Single Image Using Deep Learning
Oct 05, 2019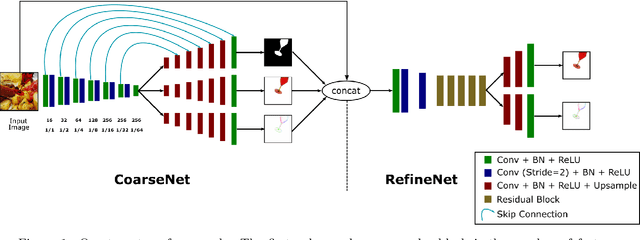
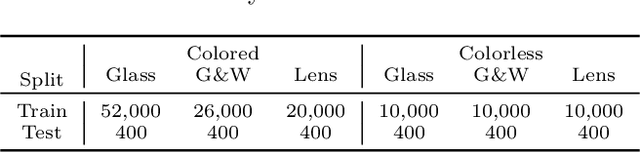

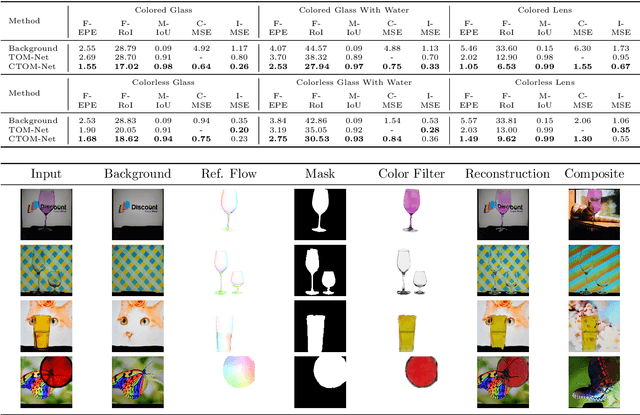
This paper proposes a deep learning based method for colored transparent object matting from a single image. Existing approaches for transparent object matting often require multiple images and long processing times, which greatly hinder their applications on real-world transparent objects. The recently proposed TOM-Net can produce a matte for a colorless transparent object from a single image in a single fast feed-forward pass. In this paper, we extend TOM-Net to handle colored transparent object by modeling the intrinsic color of a transparent object with a color filter. We formulate the problem of colored transparent object matting as simultaneously estimating an object mask, a color filter, and a refractive flow field from a single image, and present a deep learning framework for learning this task. We create a large-scale synthetic dataset for training our network. We also capture a real dataset for evaluation. Experiments on both synthetic and real datasets show promising results, which demonstrate the effectiveness of our method.
Forgery Detection in a Questioned Hyperspectral Document Image using K-means Clustering
Jun 29, 2020
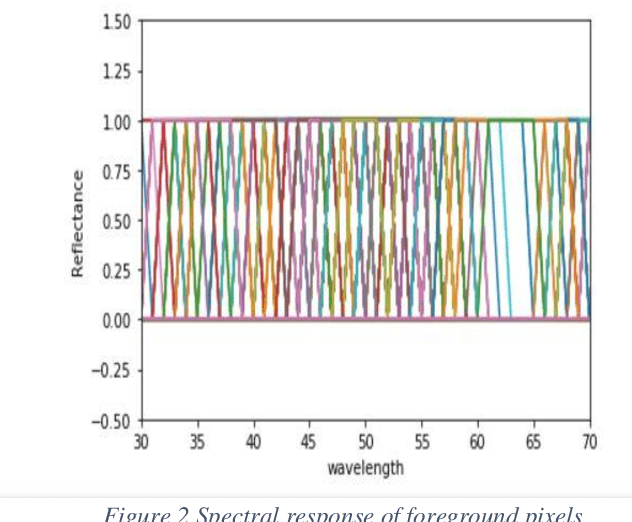

Hyperspectral imaging allows for analysis of images in several hundred of spectral bands depending on the spectral resolution of the imaging sensor. Hyperspectral document image is the one which has been captured by a hyperspectral camera so that the document can be observed in the different bands on the basis of their unique spectral signatures. To detect the forgery in a document various Ink mismatch detection techniques based on hyperspectral imaging have presented vast potential in differentiating visually similar inks. Inks of different materials exhibit different spectral signature even if they have the same color. Hyperspectral analysis of document images allows identification and discrimination of visually similar inks. Based on this analysis forensic experts can identify the authenticity of the document. In this paper an extensive ink mismatch detection technique is presented which uses KMean Clustering to identify different inks on the basis of their unique spectral response and separates them into different clusters.
Lightweight Image Super-Resolution with Information Multi-distillation Network
Sep 26, 2019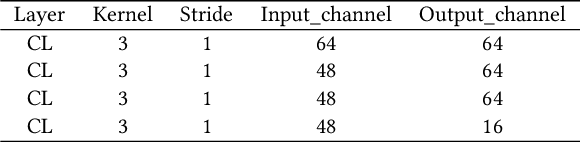
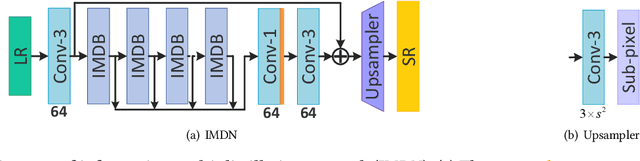
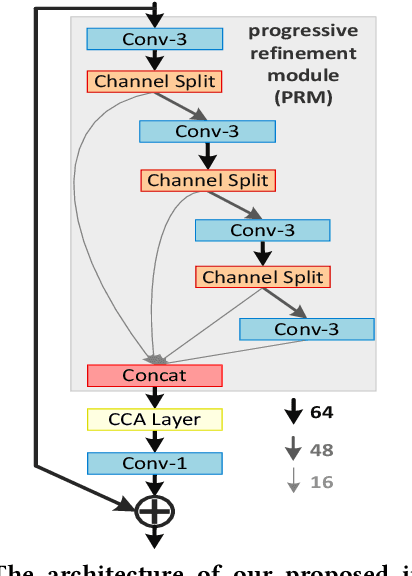

In recent years, single image super-resolution (SISR) methods using deep convolution neural network (CNN) have achieved impressive results. Thanks to the powerful representation capabilities of the deep networks, numerous previous ways can learn the complex non-linear mapping between low-resolution (LR) image patches and their high-resolution (HR) versions. However, excessive convolutions will limit the application of super-resolution technology in low computing power devices. Besides, super-resolution of any arbitrary scale factor is a critical issue in practical applications, which has not been well solved in the previous approaches. To address these issues, we propose a lightweight information multi-distillation network (IMDN) by constructing the cascaded information multi-distillation blocks (IMDB), which contains distillation and selective fusion parts. Specifically, the distillation module extracts hierarchical features step-by-step, and fusion module aggregates them according to the importance of candidate features, which is evaluated by the proposed contrast-aware channel attention mechanism. To process real images with any sizes, we develop an adaptive cropping strategy (ACS) to super-resolve block-wise image patches using the same well-trained model. Extensive experiments suggest that the proposed method performs favorably against the state-of-the-art SR algorithms in term of visual quality, memory footprint, and inference time. Code is available at \url{https://github.com/Zheng222/IMDN}.