 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021
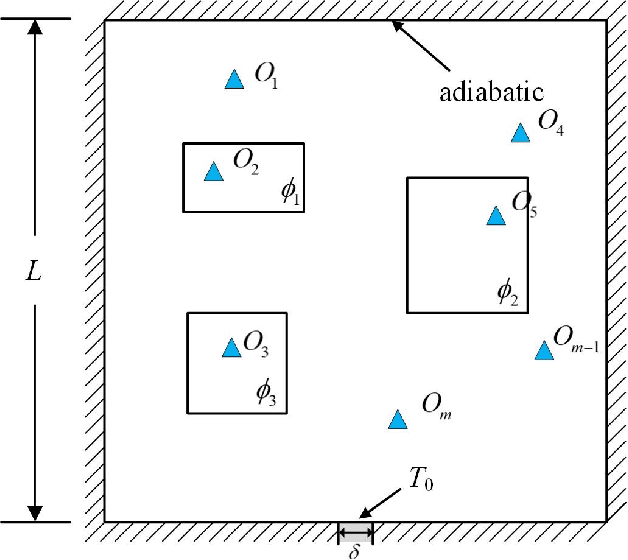
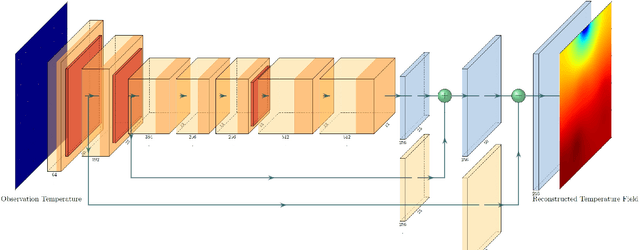
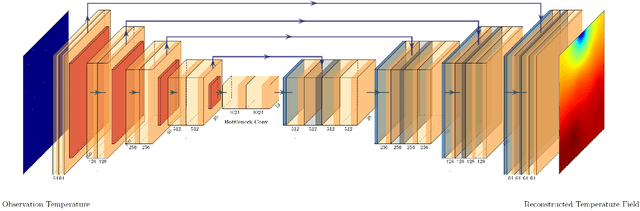
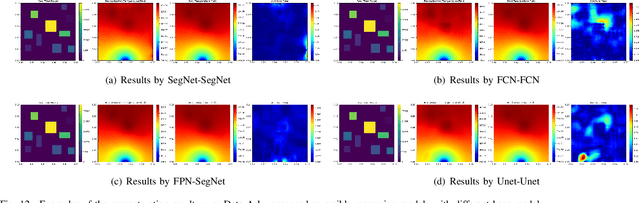
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.
ArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis
Sep 12, 2021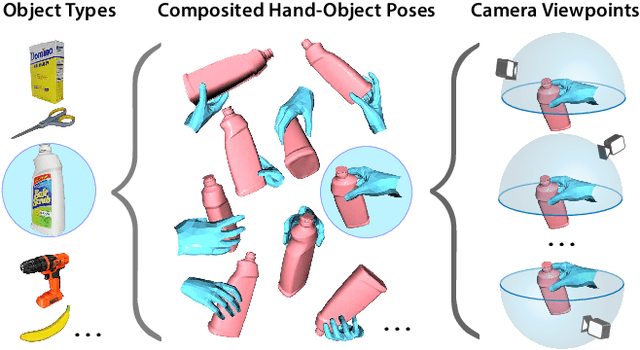
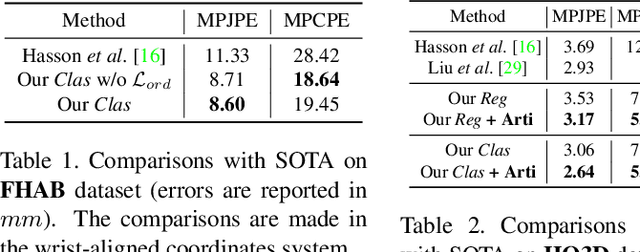
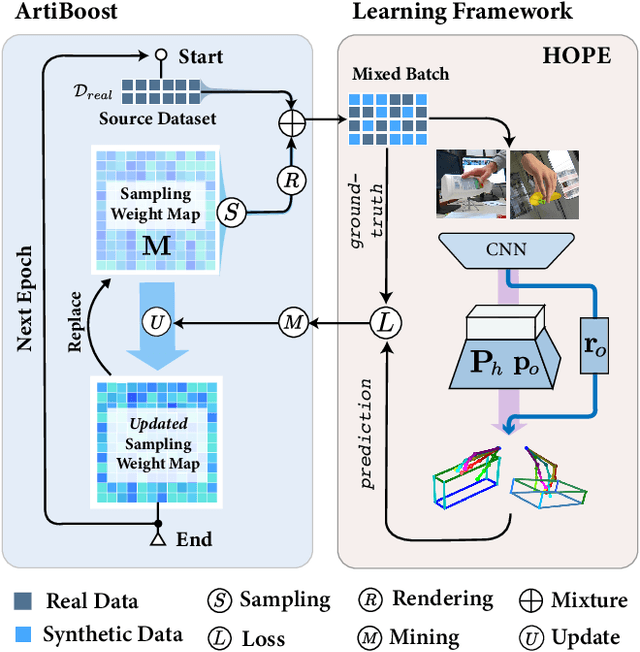
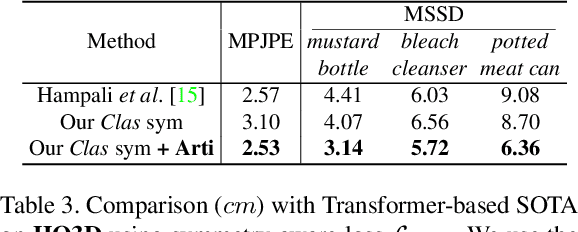
Estimating the articulated 3D hand-object pose from a single RGB image is a highly ambiguous and challenging problem requiring large-scale datasets that contain diverse hand poses, object poses, and camera viewpoints. Most real-world datasets lack this diversity. In contrast, synthetic datasets can easily ensure vast diversity, but learning from them is inefficient and suffers from heavy training consumption. To address the above issues, we propose ArtiBoost, a lightweight online data enrichment method that boosts articulated hand-object pose estimation from the data perspective. ArtiBoost is employed along with a real-world source dataset. During training, ArtiBoost alternatively performs data exploration and synthesis. ArtiBoost can cover various hand-object poses and camera viewpoints based on a Compositional hand-object Configuration and Viewpoint space (CCV-space) and can adaptively enrich the current hard-discernable samples by a mining strategy. We apply ArtiBoost on a simple learning baseline network and demonstrate the performance boost on several hand-object benchmarks. As an illustrative example, with ArtiBoost, even a simple baseline network can outperform the previous start-of-the-art based on Transformer on the HO3D dataset. Our code is available at https://github.com/MVIG-SJTU/ArtiBoost.
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Aug 19, 2020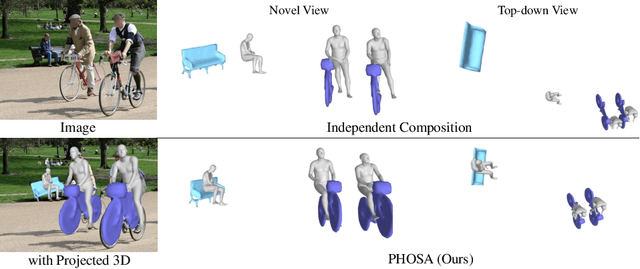
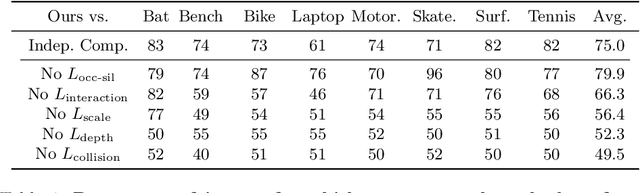
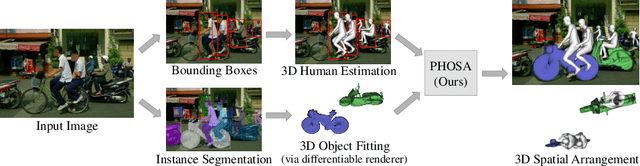
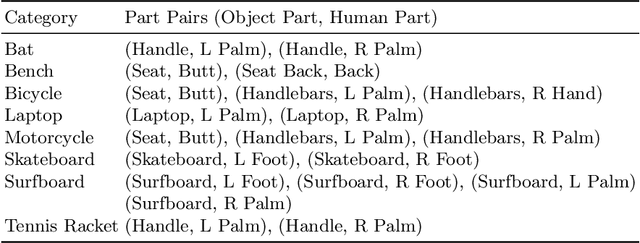
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively domain. The project webpage can be found at https://jasonyzhang.com/phosa.
Learning Multimodal Affinities for Textual Editing in Images
Mar 18, 2021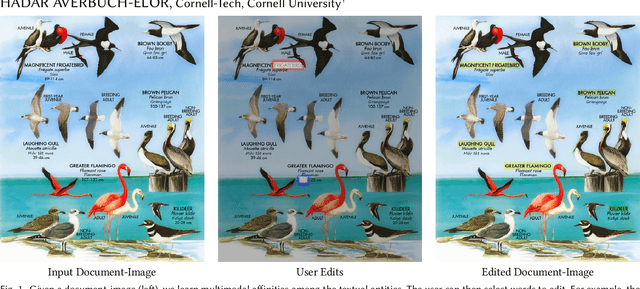
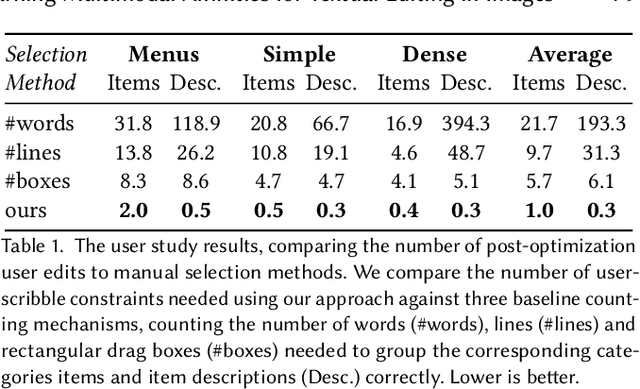
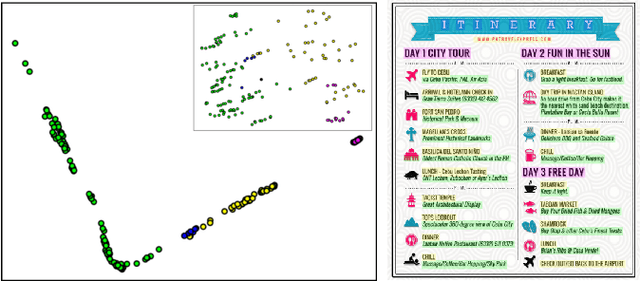
Nowadays, as cameras are rapidly adopted in our daily routine, images of documents are becoming both abundant and prevalent. Unlike natural images that capture physical objects, document-images contain a significant amount of text with critical semantics and complicated layouts. In this work, we devise a generic unsupervised technique to learn multimodal affinities between textual entities in a document-image, considering their visual style, the content of their underlying text and their geometric context within the image. We then use these learned affinities to automatically cluster the textual entities in the image into different semantic groups. The core of our approach is a deep optimization scheme dedicated for an image provided by the user that detects and leverages reliable pairwise connections in the multimodal representation of the textual elements in order to properly learn the affinities. We show that our technique can operate on highly varying images spanning a wide range of documents and demonstrate its applicability for various editing operations manipulating the content, appearance and geometry of the image.
Fast and Flexible Image Blind Denoising via Competition of Experts
Nov 20, 2019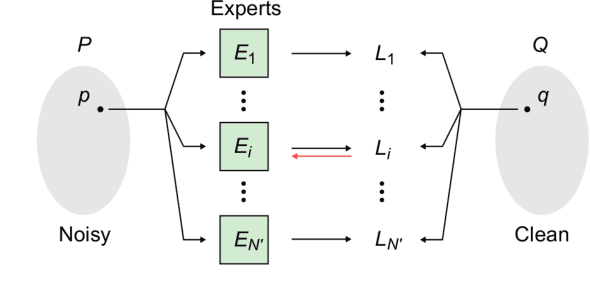
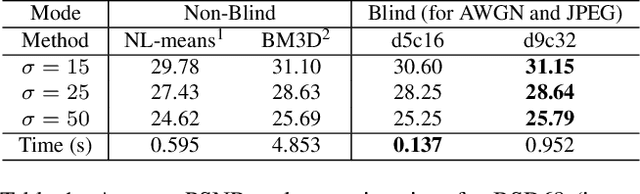
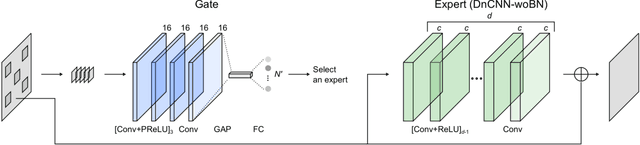
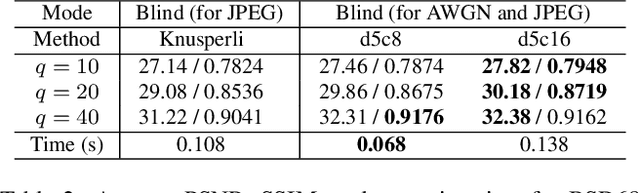
Fast and flexible processing are two essential requirements for a number of practical applications of image denoising. Current state-of-the-art methods, however, still require either high computational cost or limited scopes of the target. We introduce an efficient ensemble network trained via a competition of expert networks, as an application for image blind denoising. We realize automatic division of unlabeled noisy datasets into clusters respectively optimized to enhance denoising performance. The architecture is scalable, can be extended to deal with diverse noise sources/levels without increasing the computation time. Taking advantage of this method, we save up to approximately 90% of computational cost without sacrifice of the denoising performance compared to single network models with identical architectures. We also compare the proposed method with several existing algorithms and observe significant outperformance over prior arts in terms of computational efficiency.
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
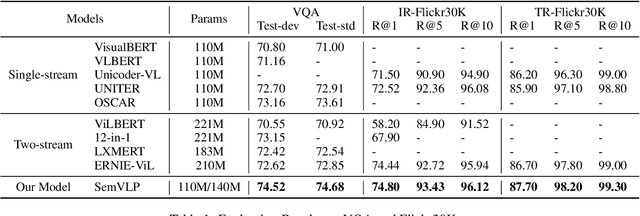
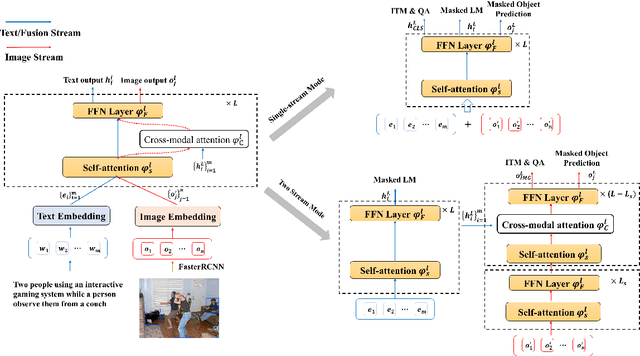

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
A General Decoupled Learning Framework for Parameterized Image Operators
Jul 11, 2019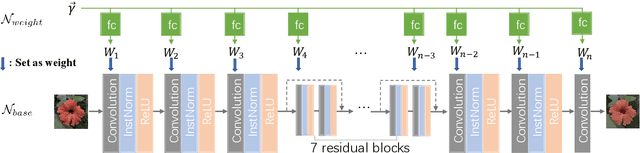
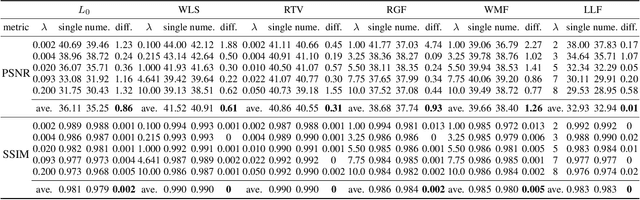
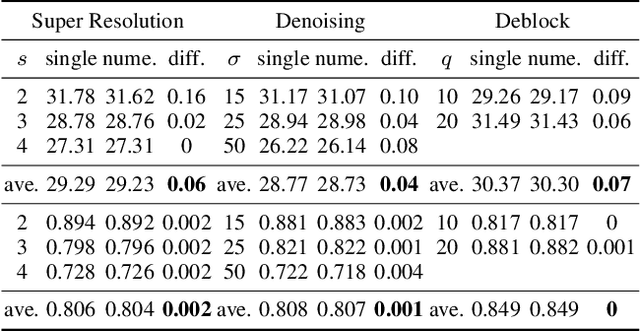

Many different deep networks have been used to approximate, accelerate or improve traditional image operators. Among these traditional operators, many contain parameters which need to be tweaked to obtain the satisfactory results, which we refer to as parameterized image operators. However, most existing deep networks trained for these operators are only designed for one specific parameter configuration, which does not meet the needs of real scenarios that usually require flexible parameters settings. To overcome this limitation, we propose a new decoupled learning algorithm to learn from the operator parameters to dynamically adjust the weights of a deep network for image operators, denoted as the base network. The learned algorithm is formed as another network, namely the weight learning network, which can be end-to-end jointly trained with the base network. Experiments demonstrate that the proposed framework can be successfully applied to many traditional parameterized image operators. To accelerate the parameter tuning for practical scenarios, the proposed framework can be further extended to dynamically change the weights of only one single layer of the base network while sharing most computation cost. We demonstrate that this cheap parameter-tuning extension of the proposed decoupled learning framework even outperforms the state-of-the-art alternative approaches.
Active Fine-Tuning from gMAD Examples Improves Blind Image Quality Assessment
Mar 08, 2020

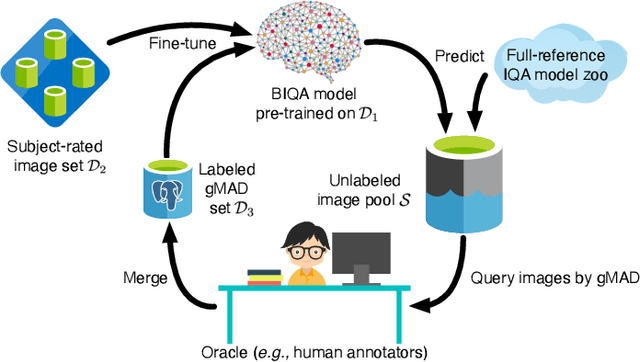
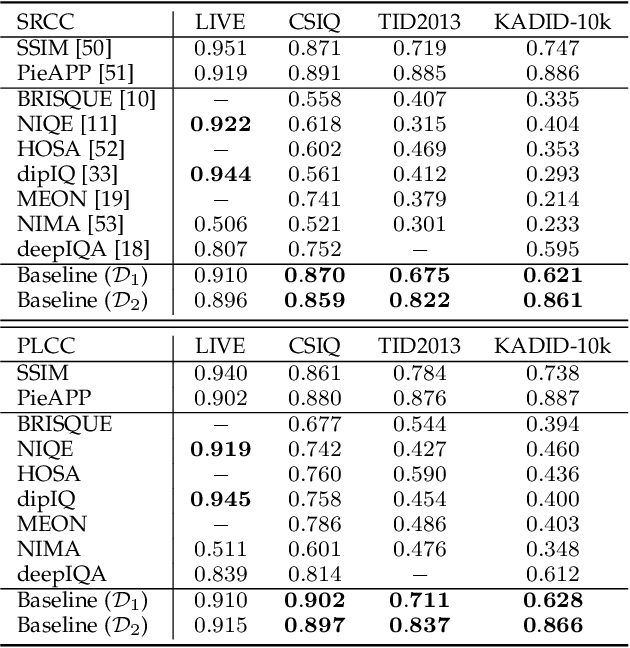
The research in image quality assessment (IQA) has a long history, and significant progress has been made by leveraging recent advances in deep neural networks (DNNs). Despite high correlation numbers on existing IQA datasets, DNN-based models may be easily falsified in the group maximum differentiation (gMAD) competition with strong counterexamples being identified. Here we show that gMAD examples can be used to improve blind IQA (BIQA) methods. Specifically, we first pre-train a DNN-based BIQA model using multiple noisy annotators, and fine-tune it on multiple subject-rated databases of synthetically distorted images, resulting in a top-performing baseline model. We then seek pairs of images by comparing the baseline model with a set of full-reference IQA methods in gMAD. The resulting gMAD examples are most likely to reveal the relative weaknesses of the baseline, and suggest potential ways for refinement. We query ground truth quality annotations for the selected images in a well controlled laboratory environment, and further fine-tune the baseline on the combination of human-rated images from gMAD and existing databases. This process may be iterated, enabling active and progressive fine-tuning from gMAD examples for BIQA. We demonstrate the feasibility of our active learning scheme on a large-scale unlabeled image set, and show that the fine-tuned method achieves improved generalizability in gMAD, without destroying performance on previously trained databases.
Coarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization
Mar 24, 2021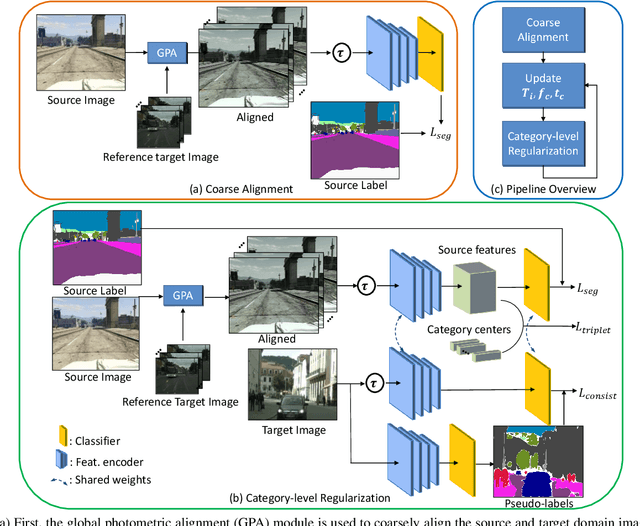
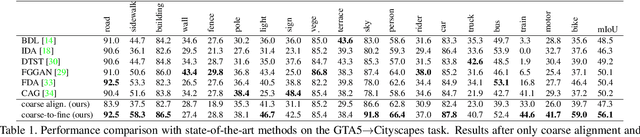
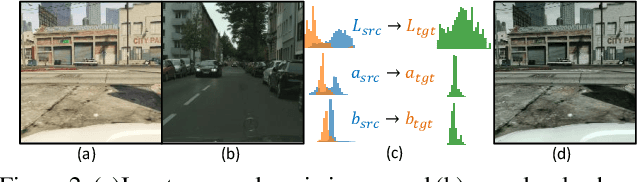
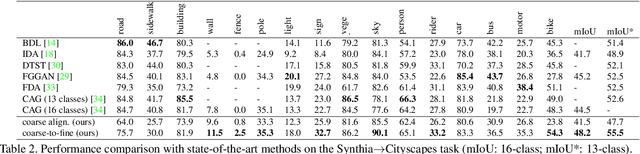
Unsupervised domain adaptation (UDA) in semantic segmentation is a fundamental yet promising task relieving the need for laborious annotation works. However, the domain shifts/discrepancies problem in this task compromise the final segmentation performance. Based on our observation, the main causes of the domain shifts are differences in imaging conditions, called image-level domain shifts, and differences in object category configurations called category-level domain shifts. In this paper, we propose a novel UDA pipeline that unifies image-level alignment and category-level feature distribution regularization in a coarse-to-fine manner. Specifically, on the coarse side, we propose a photometric alignment module that aligns an image in the source domain with a reference image from the target domain using a set of image-level operators; on the fine side, we propose a category-oriented triplet loss that imposes a soft constraint to regularize category centers in the source domain and a self-supervised consistency regularization method in the target domain. Experimental results show that our proposed pipeline improves the generalization capability of the final segmentation model and significantly outperforms all previous state-of-the-arts.
Attention Control with Metric Learning Alignment for Image Set-based Recognition
Aug 05, 2019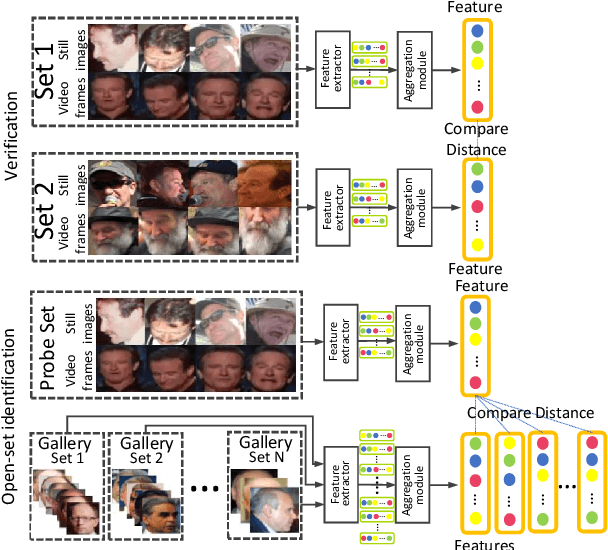
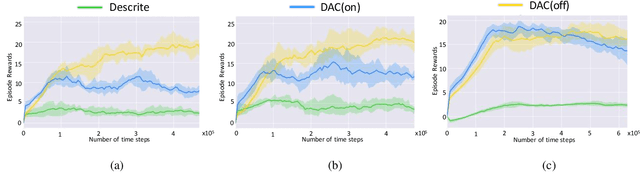

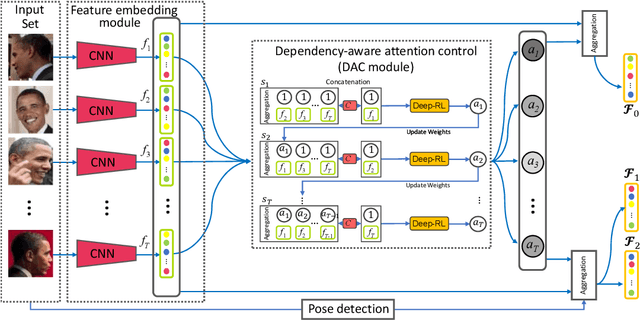
This paper considers the problem of image set-based face verification and identification. Unlike traditional single sample (an image or a video) setting, this situation assumes the availability of a set of heterogeneous collection of orderless images and videos. The samples can be taken at different check points, different identity documents $etc$. The importance of each image is usually considered either equal or based on a quality assessment of that image independent of other images and/or videos in that image set. How to model the relationship of orderless images within a set remains a challenge. We address this problem by formulating it as a Markov Decision Process (MDP) in a latent space. Specifically, we first propose a dependency-aware attention control (DAC) network, which uses actor-critic reinforcement learning for attention decision of each image to exploit the correlations among the unordered images. An off-policy experience replay is introduced to speed up the learning process. Moreover, the DAC is combined with a temporal model for videos using divide and conquer strategies. We also introduce a pose-guided representation (PGR) scheme that can further boost the performance at extreme poses. We propose a parameter-free PGR without the need for training as well as a novel metric learning-based PGR for pose alignment without the need for pose detection in testing stage. Extensive evaluations on IJB-A/B/C, YTF, Celebrity-1000 datasets demonstrate that our method outperforms many state-of-art approaches on the set-based as well as video-based face recognition databases.