 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Cycle-Consistent Adversarial Networks for Edge Denoising of Computed Tomography Images
Apr 25, 2021
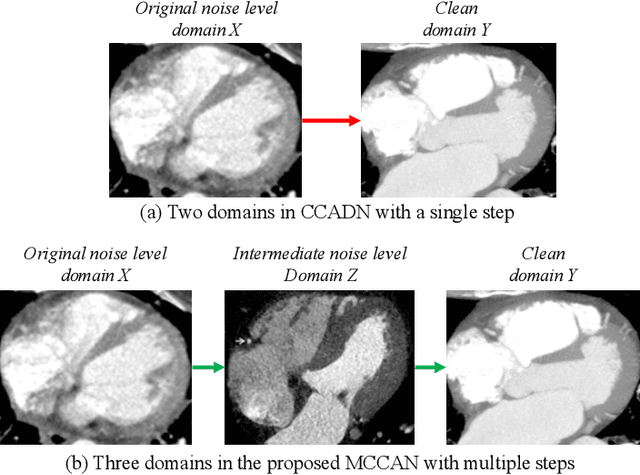

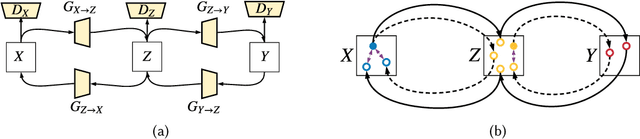
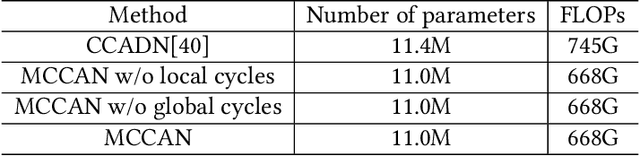
As one of the most commonly ordered imaging tests, computed tomography (CT) scan comes with inevitable radiation exposure that increases the cancer risk to patients. However, CT image quality is directly related to radiation dose, thus it is desirable to obtain high-quality CT images with as little dose as possible. CT image denoising tries to obtain high dose like high-quality CT images (domain X) from low dose low-quality CTimages (domain Y), which can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain X (noisy images) and a target domain Y (clean images). In this paper, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency for edge denoising of CT images. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperformsCCADN in terms of denoising quality with slightly less computation resource consumption.
Fourier Neural Operator Networks: A Fast and General Solver for the Photoacoustic Wave Equation
Aug 20, 2021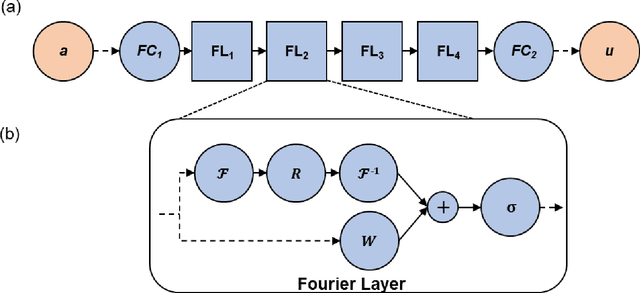
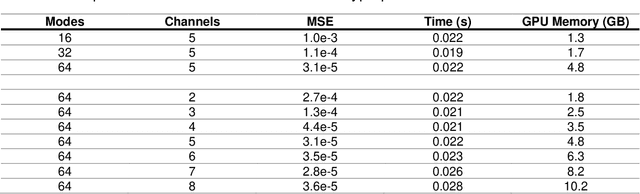
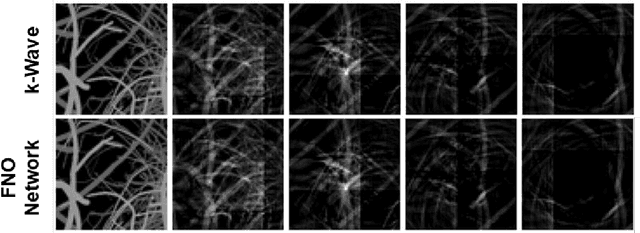
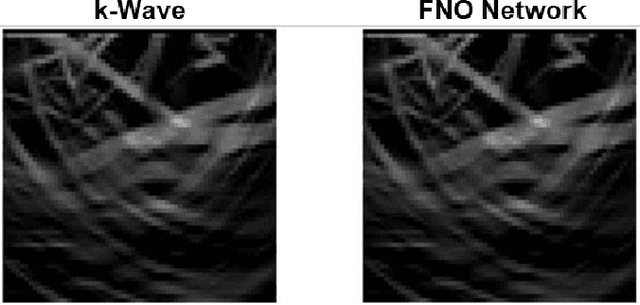
Simulation tools for photoacoustic wave propagation have played a key role in advancing photoacoustic imaging by providing quantitative and qualitative insights into parameters affecting image quality. Classical methods for numerically solving the photoacoustic wave equation relies on a fine discretization of space and can become computationally expensive for large computational grids. In this work, we apply Fourier Neural Operator (FNO) networks as a fast data-driven deep learning method for solving the 2D photoacoustic wave equation in a homogeneous medium. Comparisons between the FNO network and pseudo-spectral time domain approach demonstrated that the FNO network generated comparable simulations with small errors and was several orders of magnitude faster. Moreover, the FNO network was generalizable and can generate simulations not observed in the training data.
Distribution Mismatch Correction for Improved Robustness in Deep Neural Networks
Oct 05, 2021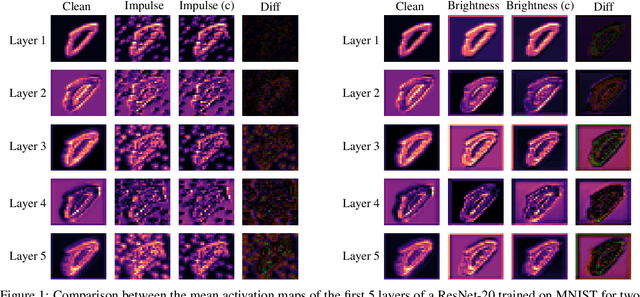
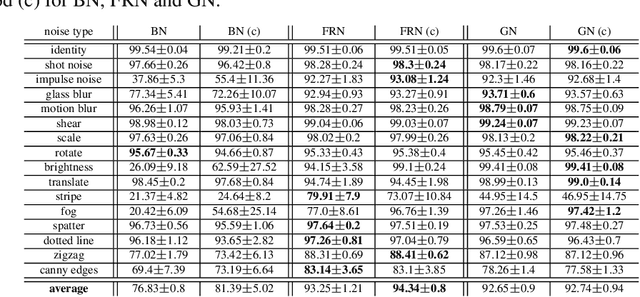
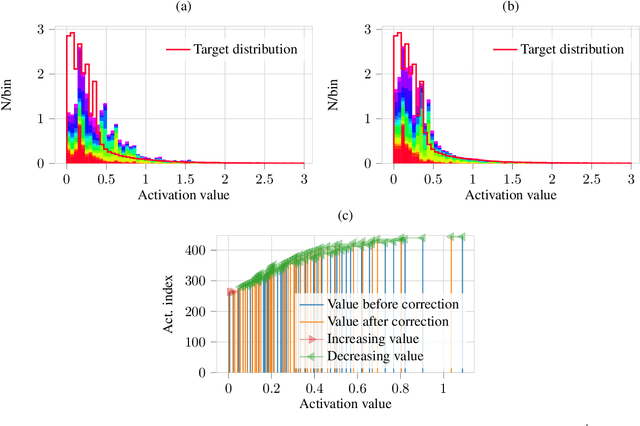
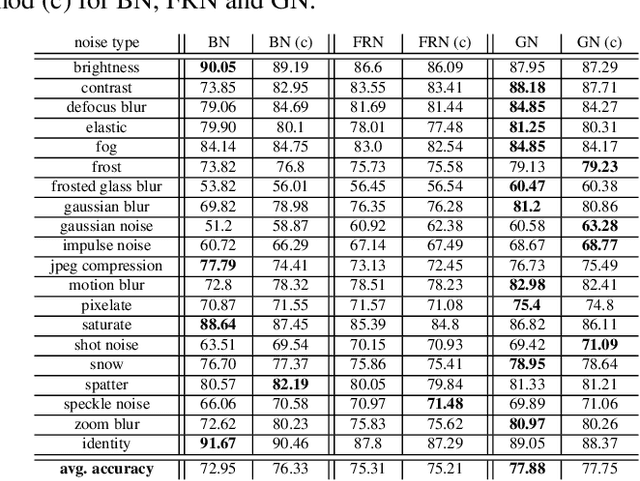
Deep neural networks rely heavily on normalization methods to improve their performance and learning behavior. Although normalization methods spurred the development of increasingly deep and efficient architectures, they also increase the vulnerability with respect to noise and input corruptions. In most applications, however, noise is ubiquitous and diverse; this can often lead to complete failure of machine learning systems as they fail to cope with mismatches between the input distribution during training- and test-time. The most common normalization method, batch normalization, reduces the distribution shift during training but is agnostic to changes in the input distribution during test time. This makes batch normalization prone to performance degradation whenever noise is present during test-time. Sample-based normalization methods can correct linear transformations of the activation distribution but cannot mitigate changes in the distribution shape; this makes the network vulnerable to distribution changes that cannot be reflected in the normalization parameters. We propose an unsupervised non-parametric distribution correction method that adapts the activation distribution of each layer. This reduces the mismatch between the training and test-time distribution by minimizing the 1-D Wasserstein distance. In our experiments, we empirically show that the proposed method effectively reduces the impact of intense image corruptions and thus improves the classification performance without the need for retraining or fine-tuning the model.
Deep Algorithmic Question Answering: Towards a Compositionally Hybrid AI for Algorithmic Reasoning
Sep 29, 2021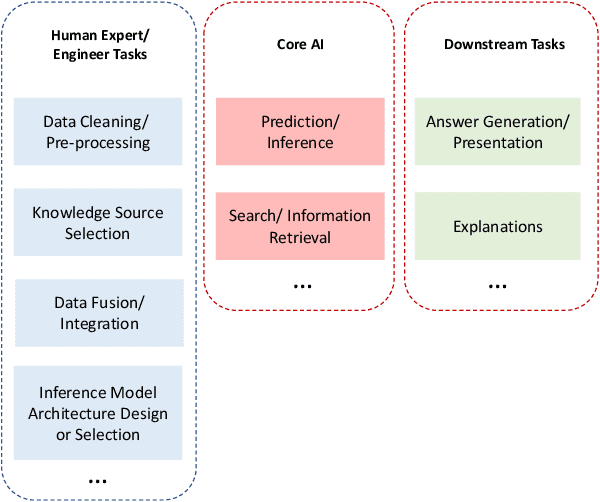
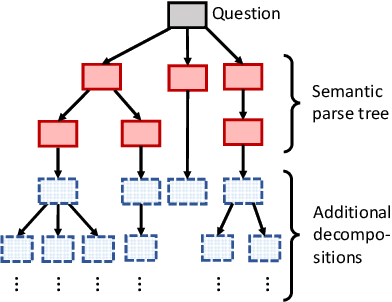
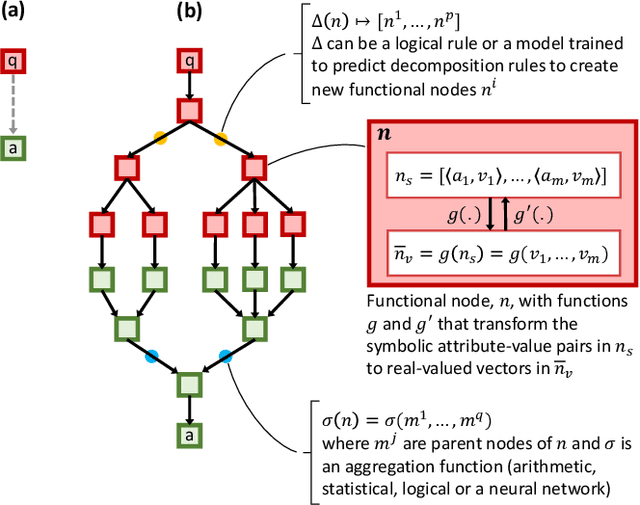
An important aspect of artificial intelligence (AI) is the ability to reason in a step-by-step "algorithmic" manner that can be inspected and verified for its correctness. This is especially important in the domain of question answering (QA). We argue that the challenge of algorithmic reasoning in QA can be effectively tackled with a "systems" approach to AI which features a hybrid use of symbolic and sub-symbolic methods including deep neural networks. Additionally, we argue that while neural network models with end-to-end training pipelines perform well in narrow applications such as image classification and language modelling, they cannot, on their own, successfully perform algorithmic reasoning, especially if the task spans multiple domains. We discuss a few notable exceptions and point out how they are still limited when the QA problem is widened to include other intelligence-requiring tasks. However, deep learning, and machine learning in general, do play important roles as components in the reasoning process. We propose an approach to algorithm reasoning for QA, Deep Algorithmic Question Answering (DAQA), based on three desirable properties: interpretability, generalizability and robustness which such an AI system should possess and conclude that they are best achieved with a combination of hybrid and compositional AI.
SCEHR: Supervised Contrastive Learning for Clinical Risk Prediction using Electronic Health Records
Oct 11, 2021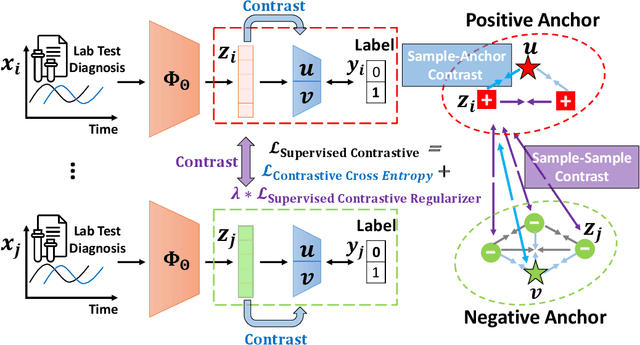
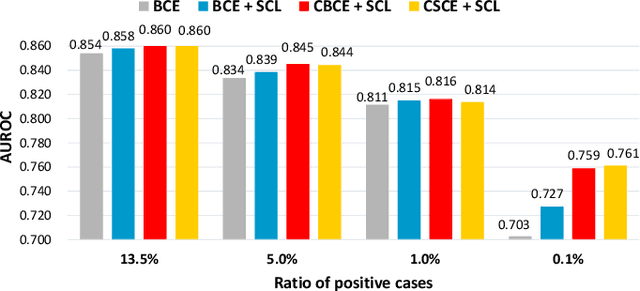
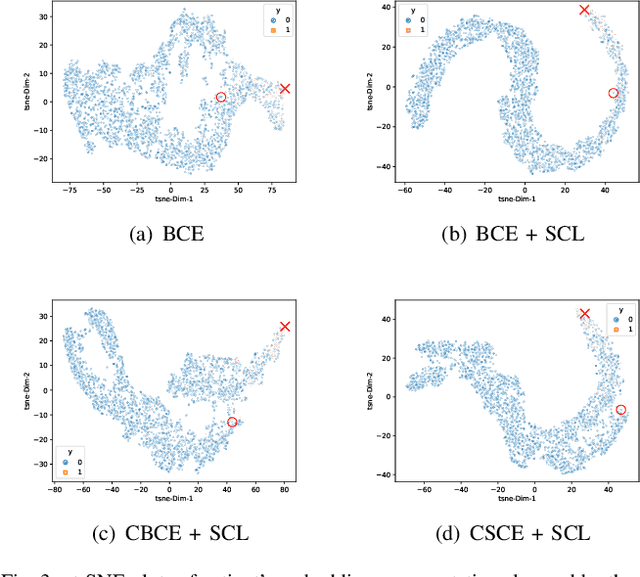

Contrastive learning has demonstrated promising performance in image and text domains either in a self-supervised or a supervised manner. In this work, we extend the supervised contrastive learning framework to clinical risk prediction problems based on longitudinal electronic health records (EHR). We propose a general supervised contrastive loss $\mathcal{L}_{\text{Contrastive Cross Entropy} } + \lambda \mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ for learning both binary classification (e.g. in-hospital mortality prediction) and multi-label classification (e.g. phenotyping) in a unified framework. Our supervised contrastive loss practices the key idea of contrastive learning, namely, pulling similar samples closer and pushing dissimilar ones apart from each other, simultaneously by its two components: $\mathcal{L}_{\text{Contrastive Cross Entropy} }$ tries to contrast samples with learned anchors which represent positive and negative clusters, and $\mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ tries to contrast samples with each other according to their supervised labels. We propose two versions of the above supervised contrastive loss and our experiments on real-world EHR data demonstrate that our proposed loss functions show benefits in improving the performance of strong baselines and even state-of-the-art models on benchmarking tasks for clinical risk predictions. Our loss functions work well with extremely imbalanced data which are common for clinical risk prediction problems. Our loss functions can be easily used to replace (binary or multi-label) cross-entropy loss adopted in existing clinical predictive models. The Pytorch code is released at \url{https://github.com/calvin-zcx/SCEHR}.
Example-Guided Style Consistent Image Synthesis from Semantic Labeling
Jun 04, 2019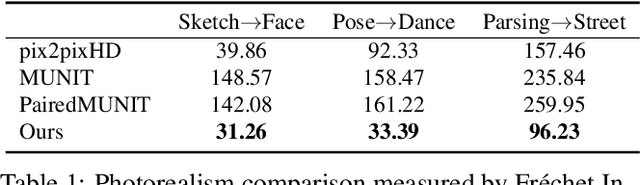
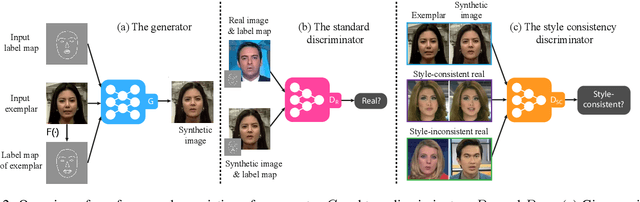
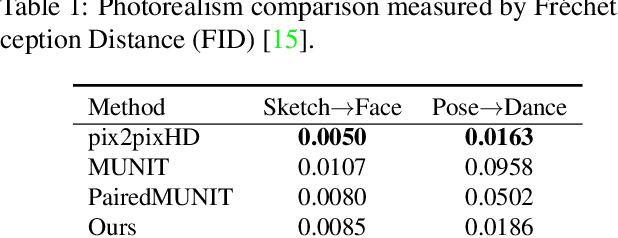
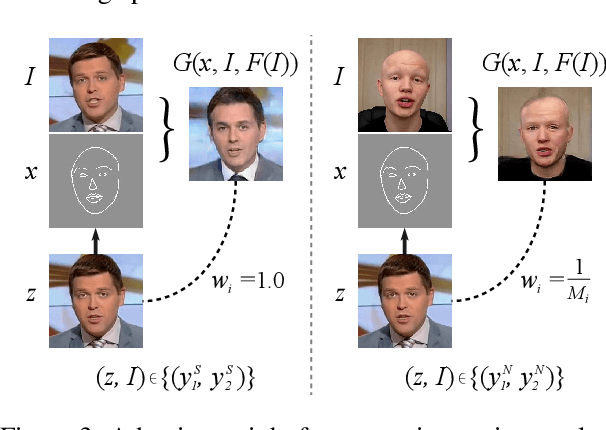
Example-guided image synthesis aims to synthesize an image from a semantic label map and an exemplary image indicating style. We use the term "style" in this problem to refer to implicit characteristics of images, for example: in portraits "style" includes gender, racial identity, age, hairstyle; in full body pictures it includes clothing; in street scenes, it refers to weather and time of day and such like. A semantic label map in these cases indicates facial expression, full body pose, or scene segmentation. We propose a solution to the example-guided image synthesis problem using conditional generative adversarial networks with style consistency. Our key contributions are (i) a novel style consistency discriminator to determine whether a pair of images are consistent in style; (ii) an adaptive semantic consistency loss; and (iii) a training data sampling strategy, for synthesizing style-consistent results to the exemplar.
Cloud-based Image Classification Service Is Not Robust To Adversarial Examples: A Forgotten Battlefield
Jan 08, 2020

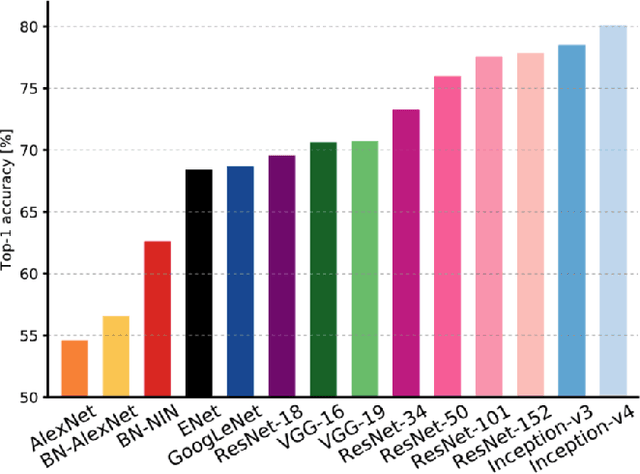
In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance . While many recent works demonstrated that DL models are vulnerable to adversarial examples.Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security.In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose two novel attack methods, Image Fusion(IF) attack and Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model ,which achieve a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our methods find the adversarial examples using only two queries per image ; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that Spatial Transformation (ST) attack has a success rate of approximately 100\% except Amazon approximately 50\%, IF and FFL-PGD attack have a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services.Our defense technology is mainly divided into model training stage and image preprocessing stage.
FFA-Net: Feature Fusion Attention Network for Single Image Dehazing
Dec 05, 2019
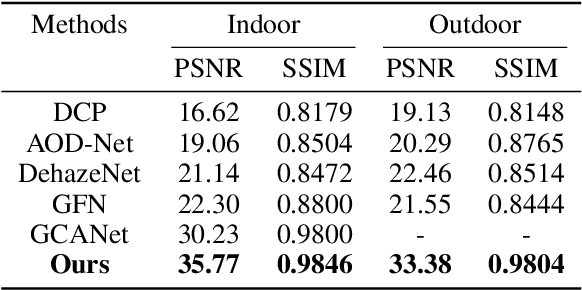
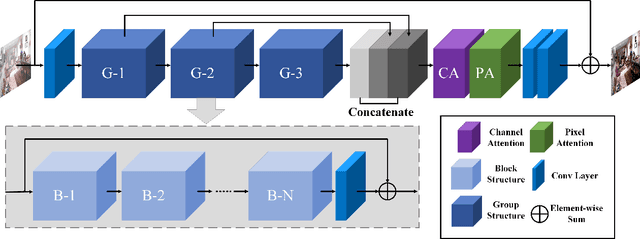
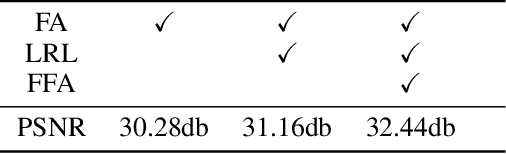
In this paper, we propose an end-to-end feature fusion at-tention network (FFA-Net) to directly restore the haze-free image. The FFA-Net architecture consists of three key components: 1) A novel Feature Attention (FA) module combines Channel Attention with Pixel Attention mechanism, considering that different channel-wise features contain totally different weighted information and haze distribution is uneven on the different image pixels. FA treats different features and pixels unequally, which provides additional flexibility in dealing with different types of information, expanding the representational ability of CNNs. 2) A basic block structure consists of Local Residual Learning and Feature Attention, Local Residual Learning allowing the less important information such as thin haze region or low-frequency to be bypassed through multiple local residual connections, let main network architecture focus on more effective information. 3) An Attention-based different levels Feature Fusion (FFA) structure, the feature weights are adaptively learned from the Feature Attention (FA) module, giving more weight to important features. This structure can also retain the information of shallow layers and pass it into deep layers. The experimental results demonstrate that our proposed FFA-Net surpasses previous state-of-the-art single image dehazing methods by a very large margin both quantitatively and qualitatively, boosting the best published PSNR metric from 30.23db to 36.39db on the SOTS indoor test dataset. Code has been made available at GitHub.
AI-Enabled Ultra-Low-Dose CT Reconstruction
Jun 17, 2021
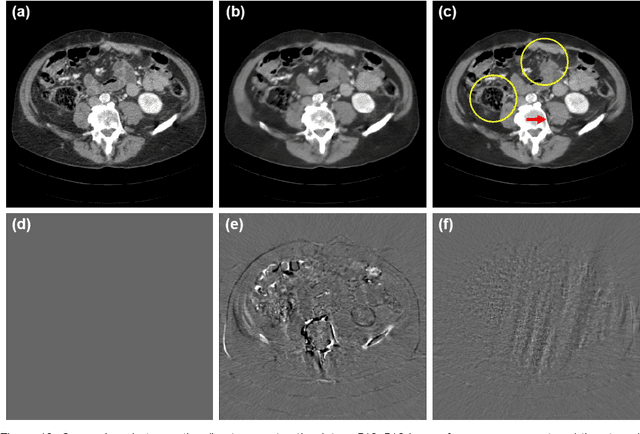
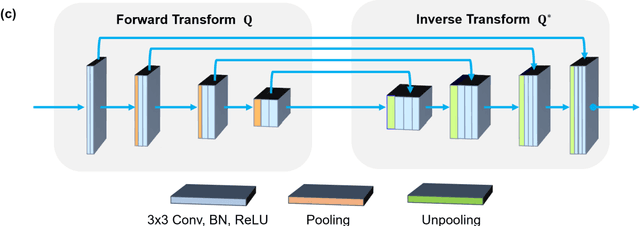
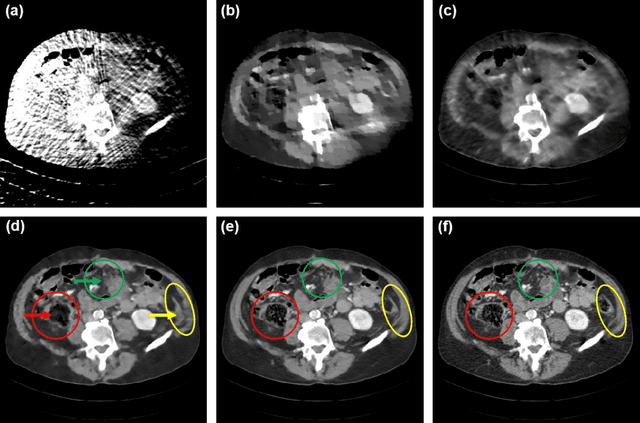
By the ALARA (As Low As Reasonably Achievable) principle, ultra-low-dose CT reconstruction is a holy grail to minimize cancer risks and genetic damages, especially for children. With the development of medical CT technologies, the iterative algorithms are widely used to reconstruct decent CT images from a low-dose scan. Recently, artificial intelligence (AI) techniques have shown a great promise in further reducing CT radiation dose to the next level. In this paper, we demonstrate that AI-powered CT reconstruction offers diagnostic image quality at an ultra-low-dose level comparable to that of radiography. Specifically, here we develop a Split Unrolled Grid-like Alternative Reconstruction (SUGAR) network, in which deep learning, physical modeling and image prior are integrated. The reconstruction results from clinical datasets show that excellent images can be reconstructed using SUGAR from 36 projections. This approach has a potential to change future healthcare.
Cyclist Trajectory Forecasts by Incorporation of Multi-View Video Information
Jun 30, 2021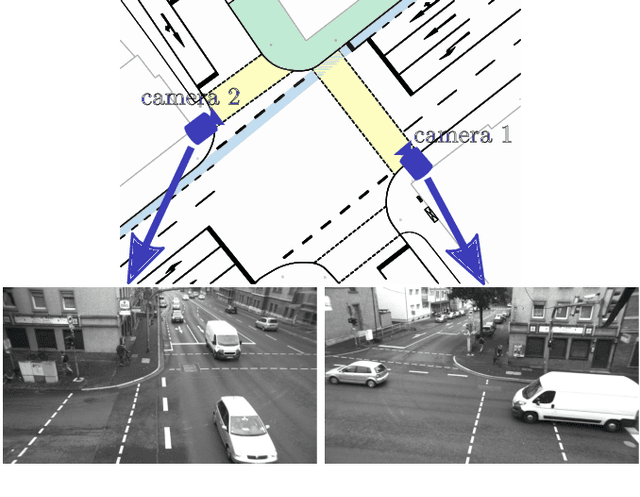

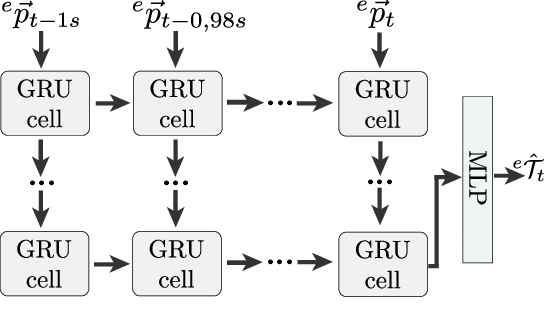
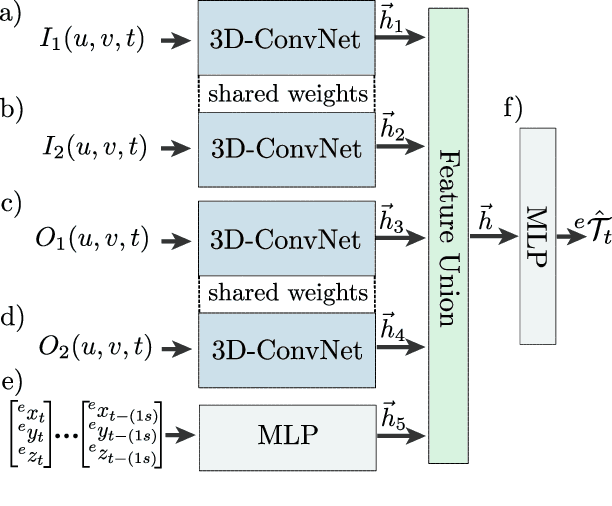
This article presents a novel approach to incorporate visual cues from video-data from a wide-angle stereo camera system mounted at an urban intersection into the forecast of cyclist trajectories. We extract features from image and optical flow (OF) sequences using 3D convolutional neural networks (3D-ConvNet) and combine them with features extracted from the cyclist's past trajectory to forecast future cyclist positions. By the use of additional information, we are able to improve positional accuracy by about 7.5 % for our test dataset and by up to 22 % for specific motion types compared to a method solely based on past trajectories. Furthermore, we compare the use of image sequences to the use of OF sequences as additional information, showing that OF alone leads to significant improvements in positional accuracy. By training and testing our methods using a real-world dataset recorded at a heavily frequented public intersection and evaluating the methods' runtimes, we demonstrate the applicability in real traffic scenarios. Our code and parts of our dataset are made publicly available.