 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variational Diffusion Models
Jul 12, 2021
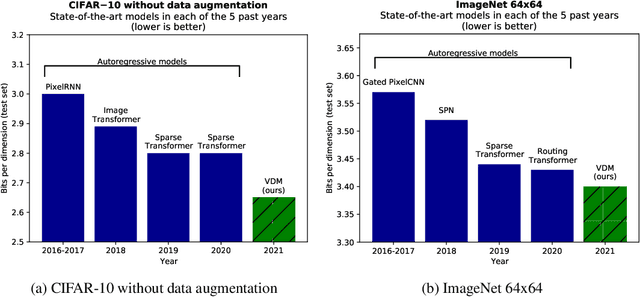
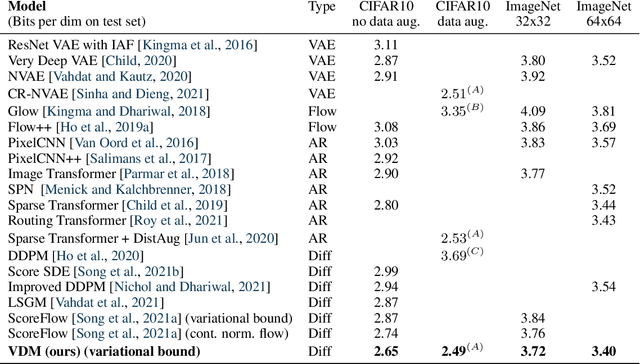

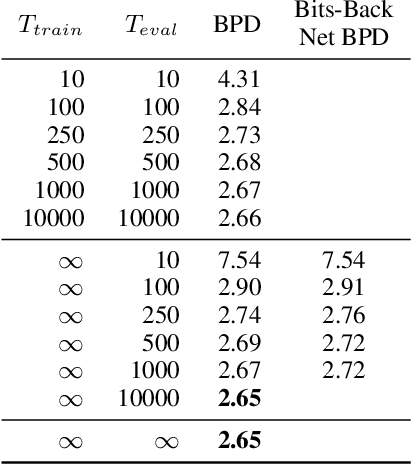
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
Less is More: Lighter and Faster Deep Neural Architecture for Tomato Leaf Disease Classification
Sep 06, 2021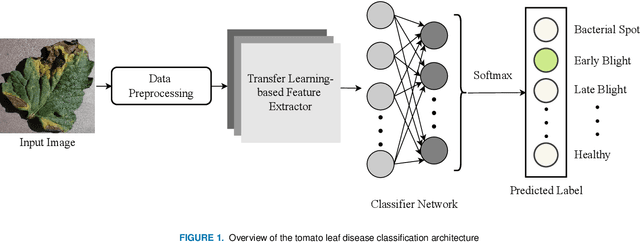
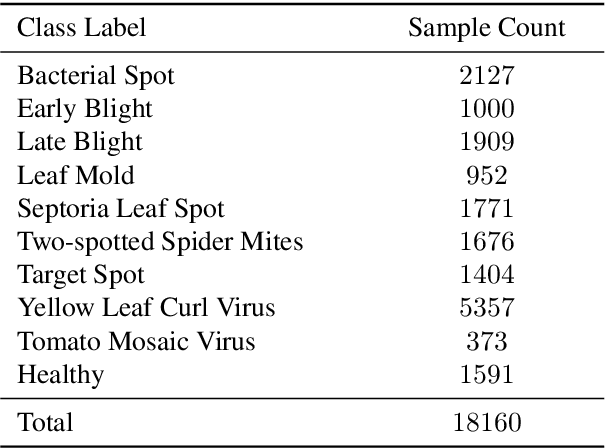

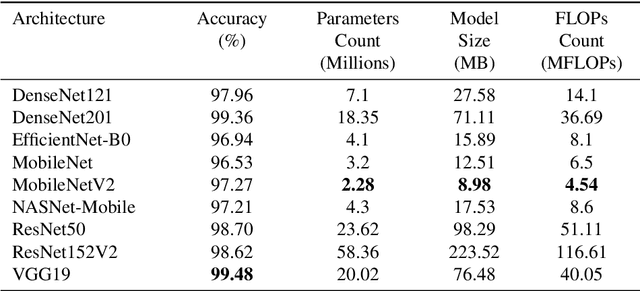
To ensure global food security and the overall profit of stakeholders, the importance of correctly detecting and classifying plant diseases is paramount. In this connection, the emergence of deep learning-based image classification has introduced a substantial number of solutions. However, the applicability of these solutions in low-end devices requires fast, accurate, and computationally inexpensive systems. This work proposes a lightweight transfer learning-based approach for detecting diseases from tomato leaves. It utilizes an effective preprocessing method to enhance the leaf images with illumination correction for improved classification. Our system extracts features using a combined model consisting of a pretrained MobileNetV2 architecture and a classifier network for effective prediction. Traditional augmentation approaches are replaced by runtime augmentation to avoid data leakage and address the class imbalance issue. Evaluation on tomato leaf images from the PlantVillage dataset shows that the proposed architecture achieves 99.30% accuracy with a model size of 9.60MB and 4.87M floating-point operations, making it a suitable choice for real-life applications in low-end devices. Our codes and models will be made available upon publication.
Selfie: Self-supervised Pretraining for Image Embedding
Jul 23, 2019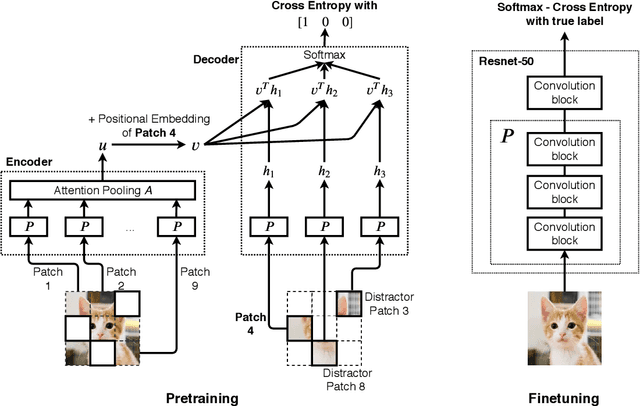
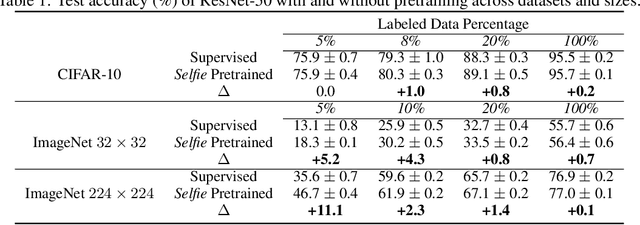

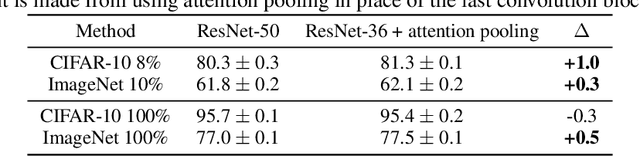
We introduce a pretraining technique called Selfie, which stands for SELFie supervised Image Embedding. Selfie generalizes the concept of masked language modeling of BERT (Devlin et al., 2019) to continuous data, such as images, by making use of the Contrastive Predictive Coding loss (Oord et al., 2018). Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture of Selfie includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate Selfie on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across different runs.
Towards Better Model Understanding with Path-Sufficient Explanations
Sep 13, 2021

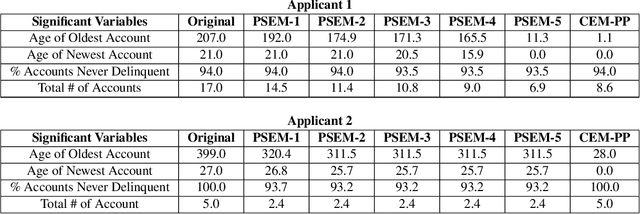

Feature based local attribution methods are amongst the most prevalent in explainable artificial intelligence (XAI) literature. Going beyond standard correlation, recently, methods have been proposed that highlight what should be minimally sufficient to justify the classification of an input (viz. pertinent positives). While minimal sufficiency is an attractive property, the resulting explanations are often too sparse for a human to understand and evaluate the local behavior of the model, thus making it difficult to judge its overall quality. To overcome these limitations, we propose a novel method called Path-Sufficient Explanations Method (PSEM) that outputs a sequence of sufficient explanations for a given input of strictly decreasing size (or value) -- from original input to a minimally sufficient explanation -- which can be thought to trace the local boundary of the model in a smooth manner, thus providing better intuition about the local model behavior for the specific input. We validate these claims, both qualitatively and quantitatively, with experiments that show the benefit of PSEM across all three modalities (image, tabular and text). A user study depicts the strength of the method in communicating the local behavior, where (many) users are able to correctly determine the prediction made by a model.
Offline RL With Resource Constrained Online Deployment
Oct 07, 2021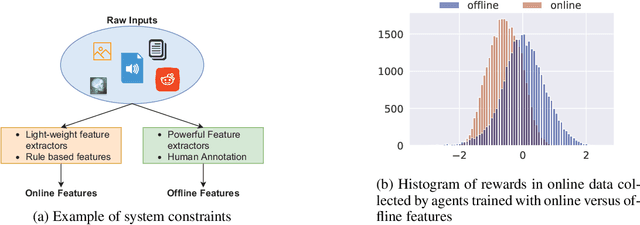


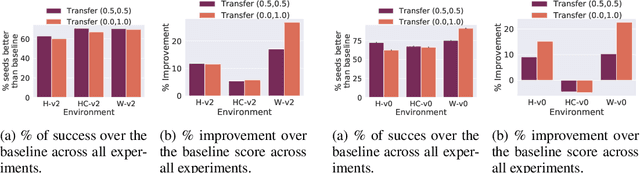
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.
Prototypical Region Proposal Networks for Few-Shot Localization and Classification
Apr 08, 2021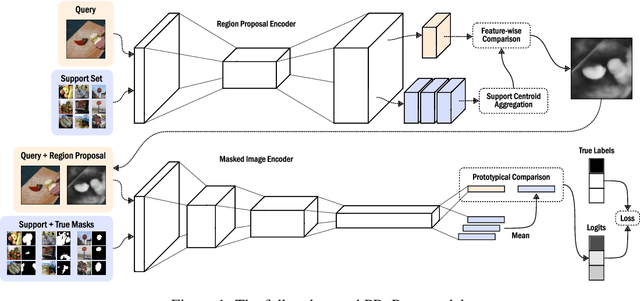
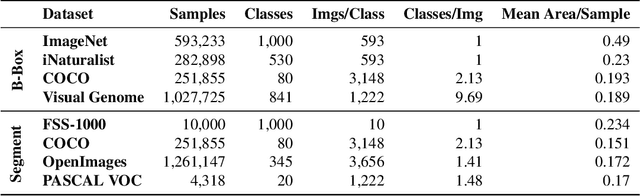
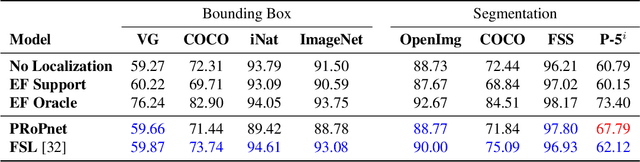
Recently proposed few-shot image classification methods have generally focused on use cases where the objects to be classified are the central subject of images. Despite success on benchmark vision datasets aligned with this use case, these methods typically fail on use cases involving densely-annotated, busy images: images common in the wild where objects of relevance are not the central subject, instead appearing potentially occluded, small, or among other incidental objects belonging to other classes of potential interest. To localize relevant objects, we employ a prototype-based few-shot segmentation model which compares the encoded features of unlabeled query images with support class centroids to produce region proposals indicating the presence and location of support set classes in a query image. These region proposals are then used as additional conditioning input to few-shot image classifiers. We develop a framework to unify the two stages (segmentation and classification) into an end-to-end classification model -- PRoPnet -- and empirically demonstrate that our methods improve accuracy on image datasets with natural scenes containing multiple object classes.
Beyond Single Stage Encoder-Decoder Networks: Deep Decoders for Semantic Image Segmentation
Jul 19, 2020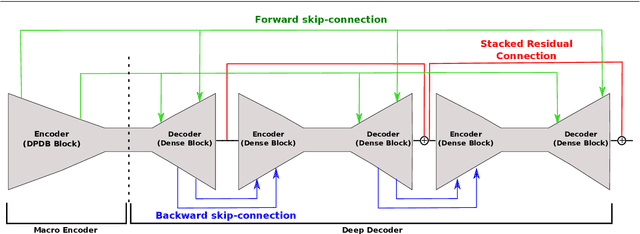
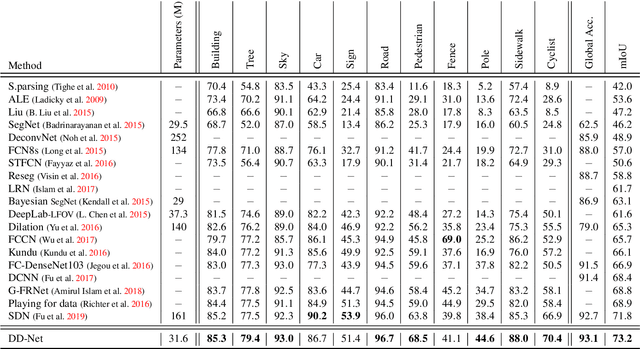
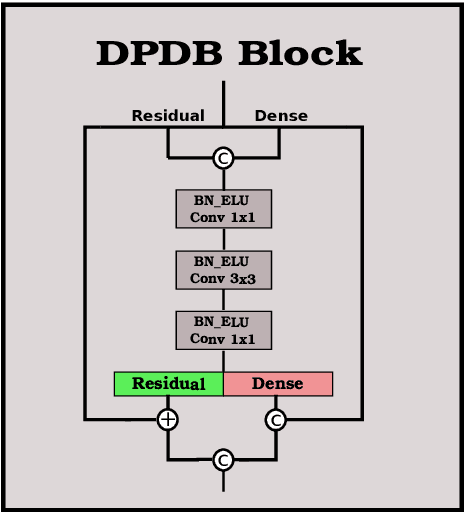
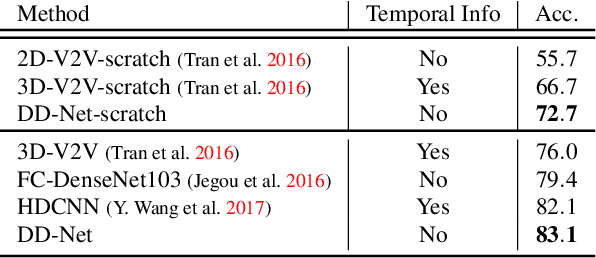
Single encoder-decoder methodologies for semantic segmentation are reaching their peak in terms of segmentation quality and efficiency per number of layers. To address these limitations, we propose a new architecture based on a decoder which uses a set of shallow networks for capturing more information content. The new decoder has a new topology of skip connections, namely backward and stacked residual connections. In order to further improve the architecture we introduce a weight function which aims to re-balance classes to increase the attention of the networks to under-represented objects. We carried out an extensive set of experiments that yielded state-of-the-art results for the CamVid, Gatech and Freiburg Forest datasets. Moreover, to further prove the effectiveness of our decoder, we conducted a set of experiments studying the impact of our decoder to state-of-the-art segmentation techniques. Additionally, we present a set of experiments augmenting semantic segmentation with optical flow information, showing that motion clues can boost pure image based semantic segmentation approaches.
Monocular Depth Estimation Primed by Salient Point Detection and Normalized Hessian Loss
Aug 25, 2021
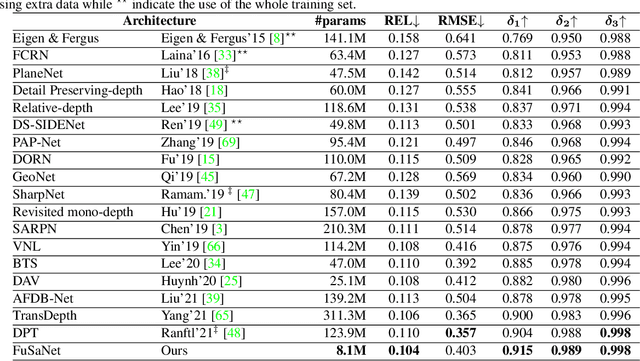
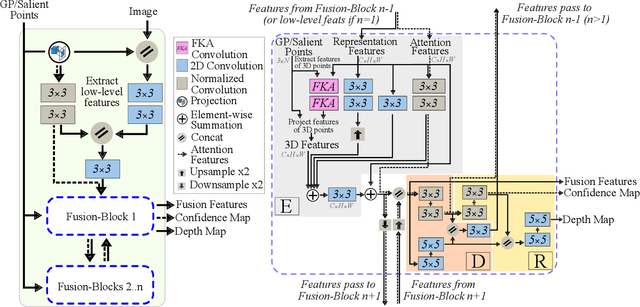
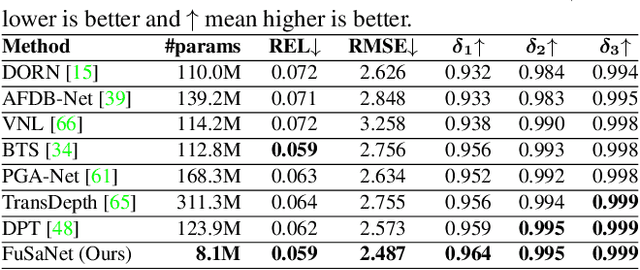
Deep neural networks have recently thrived on single image depth estimation. That being said, current developments on this topic highlight an apparent compromise between accuracy and network size. This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. In addition, we introduce a normalized Hessian loss term invariant to scaling and shear along the depth direction, which is shown to substantially improve the accuracy. The proposed method achieves state-of-the-art results on NYU-Depth-v2 and KITTI while using 3.1-38.4 times smaller model in terms of the number of parameters than baseline approaches. Experiments on the SUN-RGBD further demonstrate the generalizability of the proposed method.
BlockCopy: High-Resolution Video Processing with Block-Sparse Feature Propagation and Online Policies
Aug 20, 2021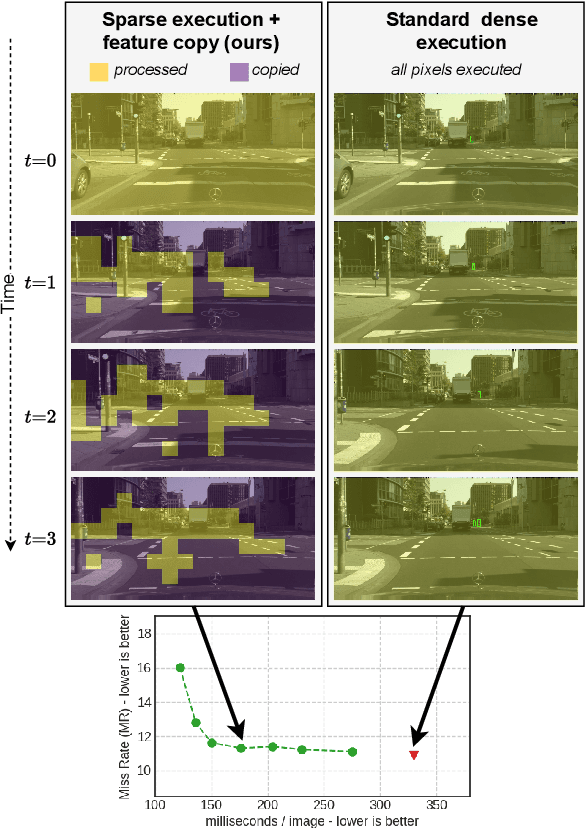
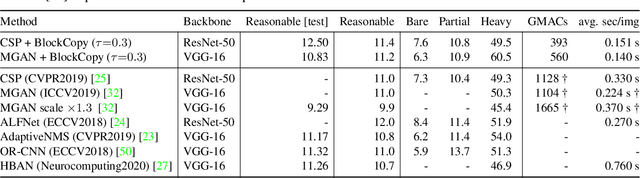
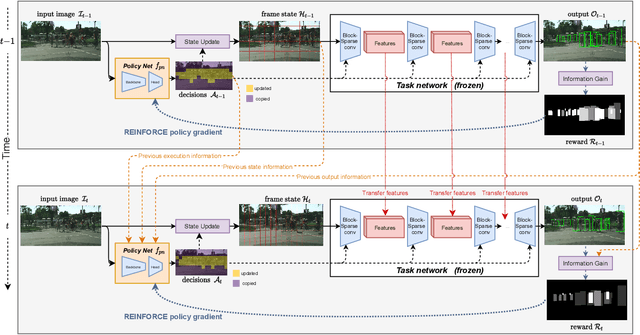
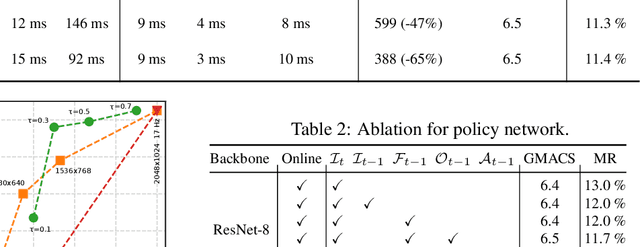
In this paper we propose BlockCopy, a scheme that accelerates pretrained frame-based CNNs to process video more efficiently, compared to standard frame-by-frame processing. To this end, a lightweight policy network determines important regions in an image, and operations are applied on selected regions only, using custom block-sparse convolutions. Features of non-selected regions are simply copied from the preceding frame, reducing the number of computations and latency. The execution policy is trained using reinforcement learning in an online fashion without requiring ground truth annotations. Our universal framework is demonstrated on dense prediction tasks such as pedestrian detection, instance segmentation and semantic segmentation, using both state of the art (Center and Scale Predictor, MGAN, SwiftNet) and standard baseline networks (Mask-RCNN, DeepLabV3+). BlockCopy achieves significant FLOPS savings and inference speedup with minimal impact on accuracy.
Road Mapping and Localization using Sparse Semantic Visual Features
Aug 11, 2021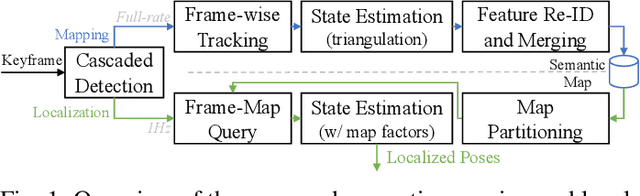
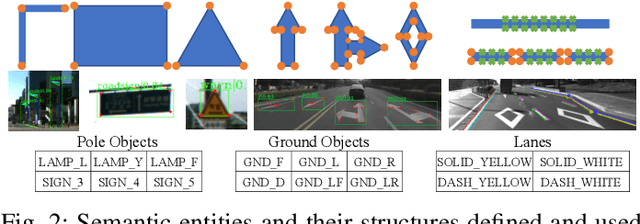
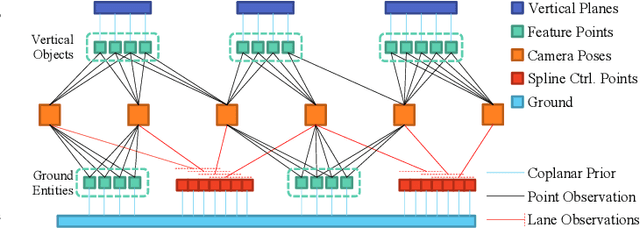
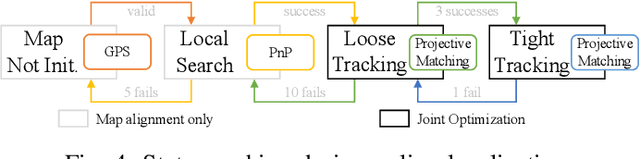
We present a novel method for visual mapping and localization for autonomous vehicles, by extracting, modeling, and optimizing semantic road elements. Specifically, our method integrates cascaded deep models to detect standardized road elements instead of traditional point features, to seek for improved pose accuracy and map representation compactness. To utilize the structural features, we model road lights and signs by their representative deep keypoints for skeleton and boundary, and parameterize lanes via piecewise cubic splines. Based on the road semantic features, we build a complete pipeline for mapping and localization, which includes a) image processing front-end, b) sensor fusion strategies, and c) optimization backend. Experiments on public datasets and our testing platform have demonstrated the effectiveness and advantages of our method by outperforming traditional approaches.