 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FSNet: A Failure Detection Framework for Semantic Segmentation
Aug 19, 2021
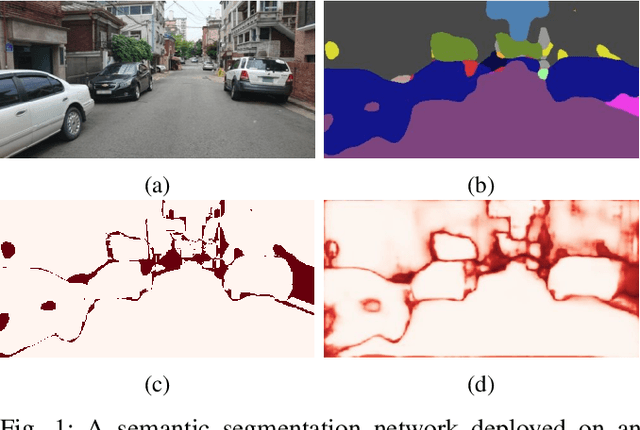
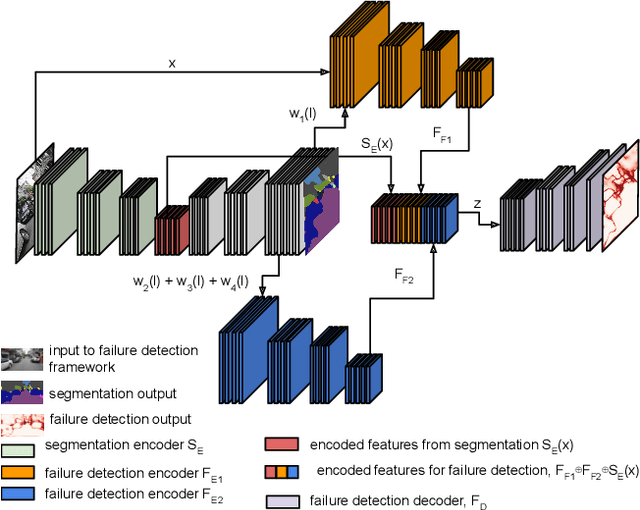


Semantic segmentation is an important task that helps autonomous vehicles understand their surroundings and navigate safely. During deployment, even the most mature segmentation models are vulnerable to various external factors that can degrade the segmentation performance with potentially catastrophic consequences for the vehicle and its surroundings. To address this issue, we propose a failure detection framework to identify pixel-level misclassification. We do so by exploiting internal features of the segmentation model and training it simultaneously with a failure detection network. During deployment, the failure detector can flag areas in the image where the segmentation model have failed to segment correctly. We evaluate the proposed approach against state-of-the-art methods and achieve 12.30%, 9.46%, and 9.65% performance improvement in the AUPR-Error metric for Cityscapes, BDD100K, and Mapillary semantic segmentation datasets.
Gleason Score Prediction using Deep Learning in Tissue Microarray Image
May 11, 2020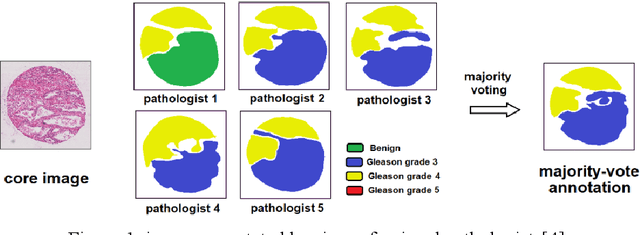
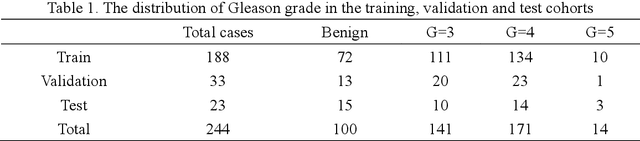
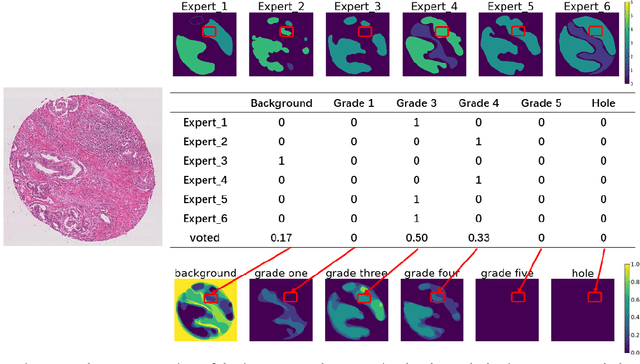
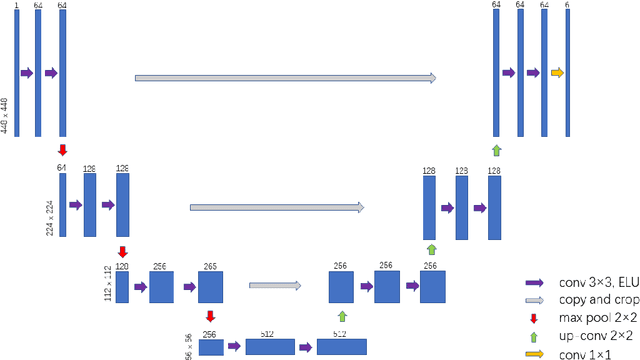
Prostate cancer (PCa) is one of the most common cancers in men around the world. The most accurate method to evaluate lesion levels of PCa is microscopic inspection of stained biopsy tissue and estimate the Gleason score of tissue microarray (TMA) image by expert pathologists. However, it is time-consuming for pathologists to identify the cellular and glandular patterns for Gleason grading in large TMA images. We used Gleason2019 Challenge dataset to build a convolutional neural network (CNN) model to segment TMA images to regions of different Gleason grades and predict the Gleason score according to the grading segmentation. We used a pre-trained model of prostate segmentation to increase the accuracy of the Gleason grade segmentation. The model achieved a mean Dice of 75.6% on the test cohort and ranked 4th in the Gleason2019 Challenge with a score of 0.778 combined of Cohen's kappa and the f1-score.
Multi-concept adversarial attacks
Oct 19, 2021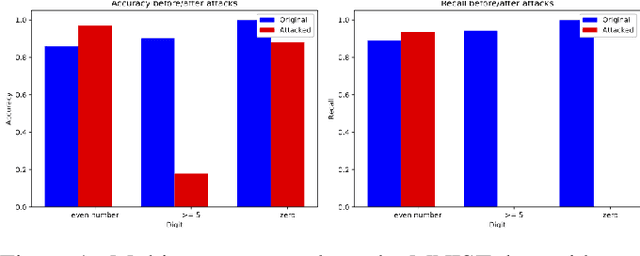
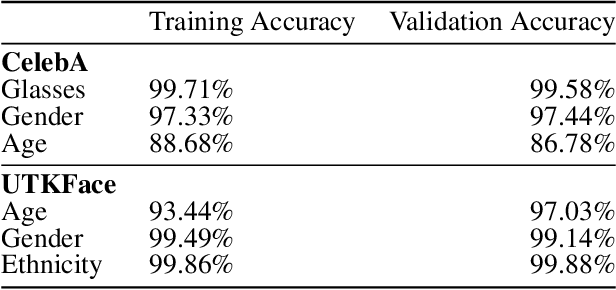

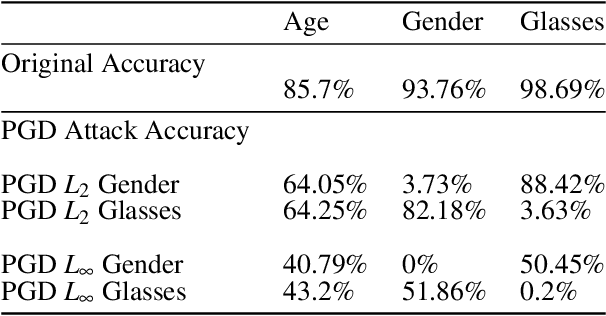
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.
Holographic Maxwellian near-eye display with adjustable and continuous eye-box replication
Jun 11, 2021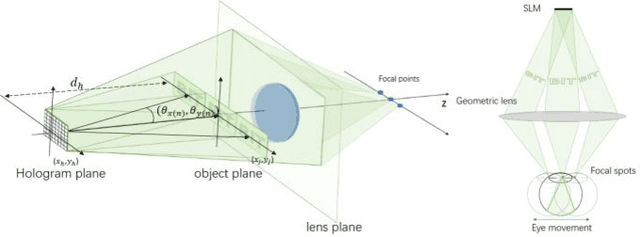
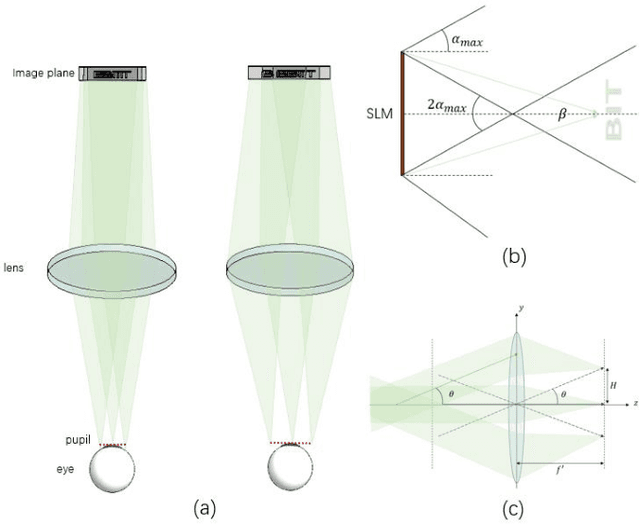
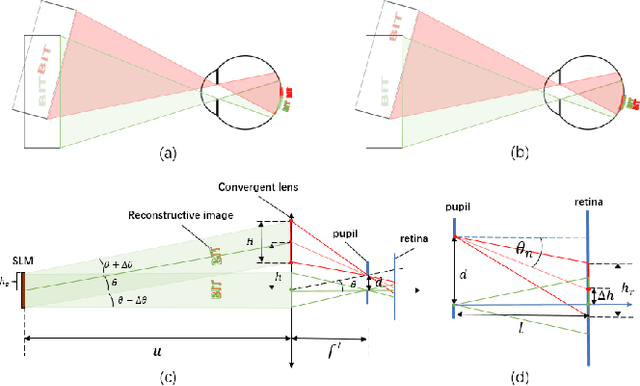
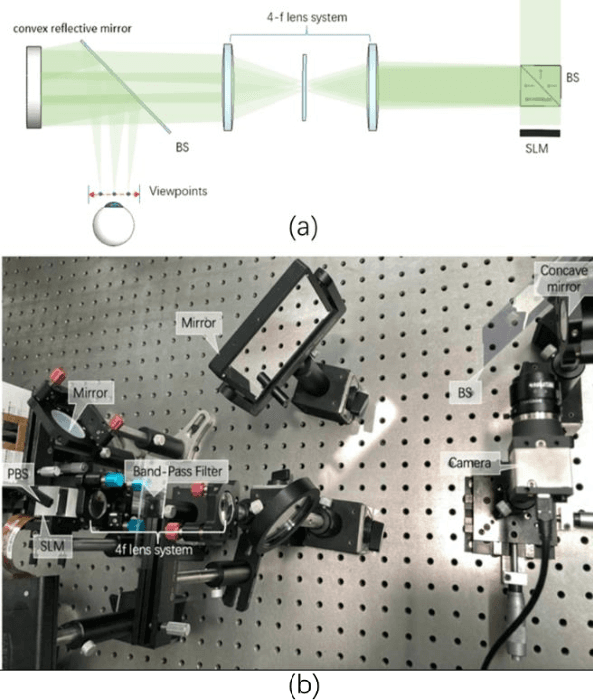
The Maxwellian display presents always-focused images to the viewer, alleviating the vergence-accommodation conflict (VAC) in near-eye displays (NEDs). However, the limited eyebox of the typical Maxwellian display prevents it from wider applications. We propose a holographic Maxwellian near-eye display with adjustable and continuous eye-box replication. Holographic display provides a way to match the human pupil size with the interval of the replicated eyeboxes, making it possible to eliminate or alleviate double image or blind area problem, which exists long in eyebox expansion for Maxwellian display. Besides, seamless image conversion between viewing points has been achieved through hologram pre-processing. Optical experiment confirms that the interval between replicated eyeboxes is dynamically adjustable, ranging from 2mm to 6mm. The proposed display can present always-focused images and seamless conversion among viewpoints with 5.32$^\circ$ horizontal field of view, and 9mmH * 3mmV eyebox.
Early- and in-season crop type mapping without current-year ground truth: generating labels from historical information via a topology-based approach
Oct 19, 2021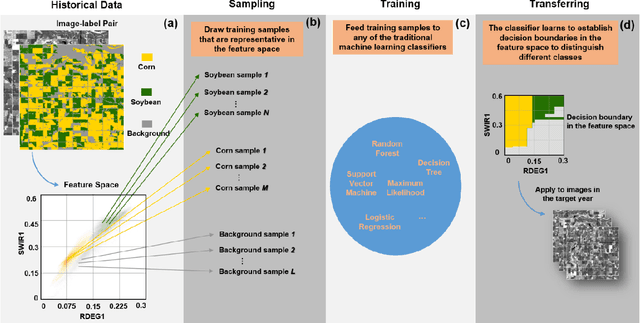

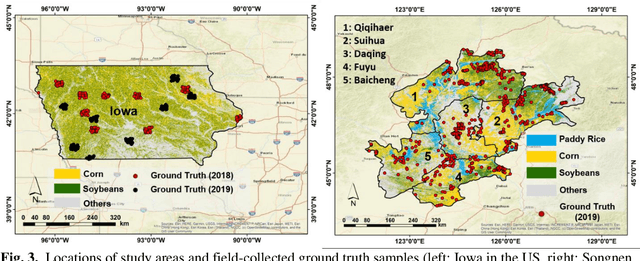
Land cover classification in remote sensing is often faced with the challenge of limited ground truth. Incorporating historical information has the potential to significantly lower the expensive cost associated with collecting ground truth and, more importantly, enable early- and in-season mapping that is helpful to many pre-harvest decisions. In this study, we propose a new approach that can effectively transfer knowledge about the topology (i.e. relative position) of different crop types in the spectral feature space (e.g. the histogram of SWIR1 vs RDEG1 bands) to generate labels, thereby support crop classification in a different year. Importantly, our approach does not attempt to transfer classification decision boundaries that are susceptible to inter-annual variations of weather and management, but relies on the more robust and shift-invariant topology information. We tested this approach for mapping corn/soybeans in the US Midwest and paddy rice/corn/soybeans in Northeast China using Landsat-8 and Sentinel-2 data. Results show that our approach automatically generates high-quality labels for crops in the target year immediately after each image becomes available. Based on these generated labels from our approach, the subsequent crop type mapping using a random forest classifier reach the F1 score as high as 0.887 for corn as early as the silking stage and 0.851 for soybean as early as the flowering stage and the overall accuracy of 0.873 in Iowa. In Northeast China, F1 scores of paddy rice, corn and soybeans and the overall accuracy can exceed 0.85 two and half months ahead of harvest. Overall, these results highlight unique advantages of our approach in transferring historical knowledge and maximizing the timeliness of crop maps. Our approach supports a general paradigm shift towards learning transferrable and generalizable knowledge to facilitate land cover classification.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021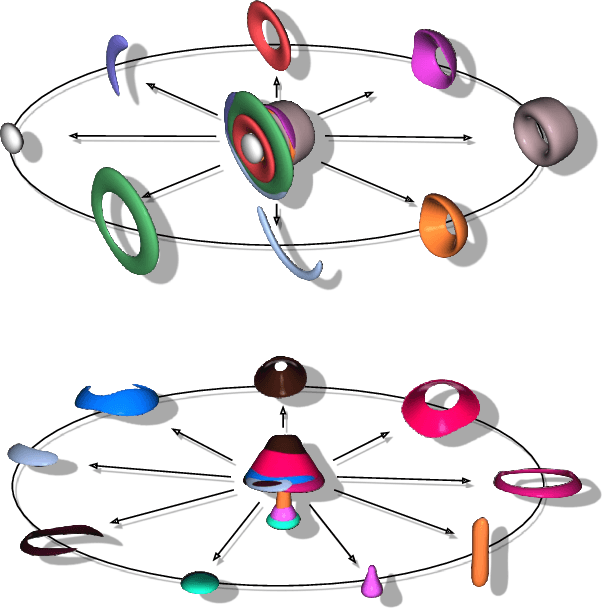
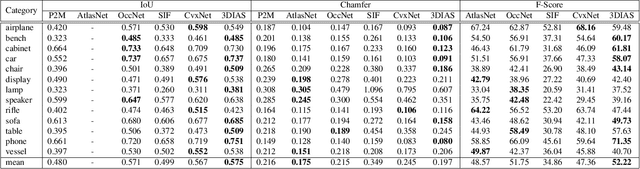
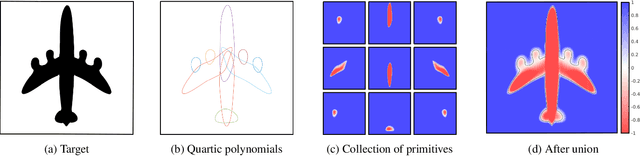

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .
Thinking Fast and Slow in AI: the Role of Metacognition
Oct 05, 2021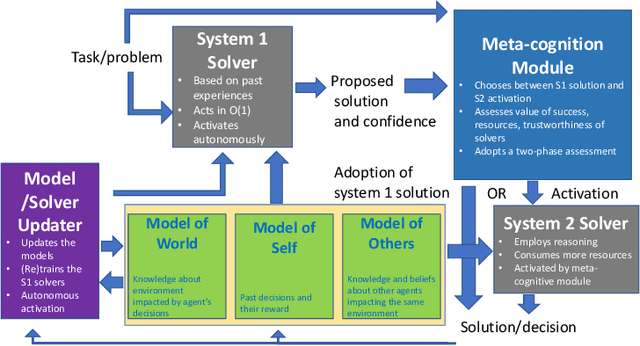
AI systems have seen dramatic advancement in recent years, bringing many applications that pervade our everyday life. However, we are still mostly seeing instances of narrow AI: many of these recent developments are typically focused on a very limited set of competencies and goals, e.g., image interpretation, natural language processing, classification, prediction, and many others. Moreover, while these successes can be accredited to improved algorithms and techniques, they are also tightly linked to the availability of huge datasets and computational power. State-of-the-art AI still lacks many capabilities that would naturally be included in a notion of (human) intelligence. We argue that a better study of the mechanisms that allow humans to have these capabilities can help us understand how to imbue AI systems with these competencies. We focus especially on D. Kahneman's theory of thinking fast and slow, and we propose a multi-agent AI architecture where incoming problems are solved by either system 1 (or "fast") agents, that react by exploiting only past experience, or by system 2 (or "slow") agents, that are deliberately activated when there is the need to reason and search for optimal solutions beyond what is expected from the system 1 agent. Both kinds of agents are supported by a model of the world, containing domain knowledge about the environment, and a model of "self", containing information about past actions of the system and solvers' skills.
WebQA: Multihop and Multimodal QA
Sep 01, 2021
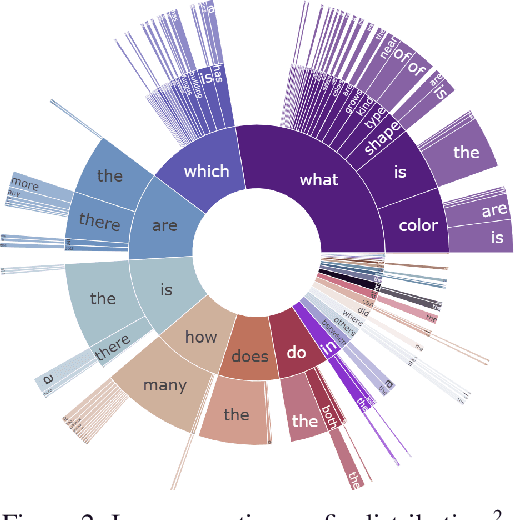


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.
Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation
Jul 01, 2021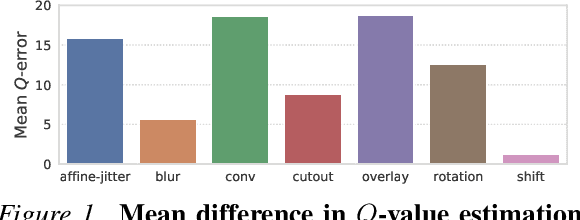
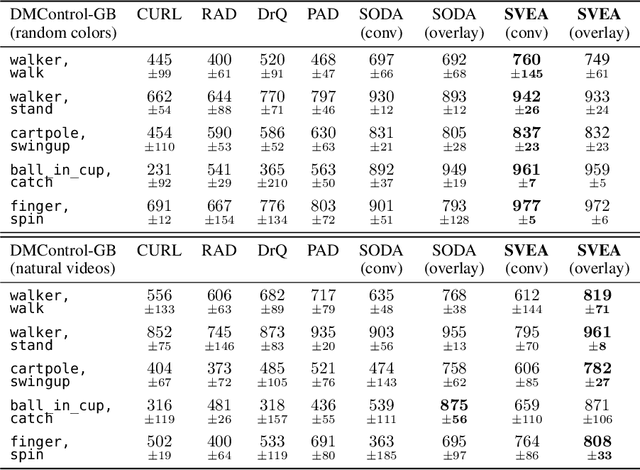
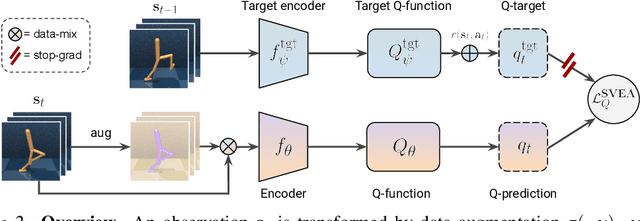
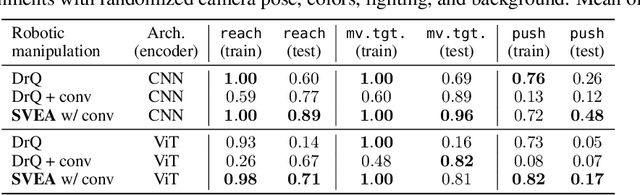
While agents trained by Reinforcement Learning (RL) can solve increasingly challenging tasks directly from visual observations, generalizing learned skills to novel environments remains very challenging. Extensive use of data augmentation is a promising technique for improving generalization in RL, but it is often found to decrease sample efficiency and can even lead to divergence. In this paper, we investigate causes of instability when using data augmentation in common off-policy RL algorithms. We identify two problems, both rooted in high-variance Q-targets. Based on our findings, we propose a simple yet effective technique for stabilizing this class of algorithms under augmentation. We perform extensive empirical evaluation of image-based RL using both ConvNets and Vision Transformers (ViT) on a family of benchmarks based on DeepMind Control Suite, as well as in robotic manipulation tasks. Our method greatly improves stability and sample efficiency of ConvNets under augmentation, and achieves generalization results competitive with state-of-the-art methods for image-based RL. We further show that our method scales to RL with ViT-based architectures, and that data augmentation may be especially important in this setting.
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Apr 08, 2021
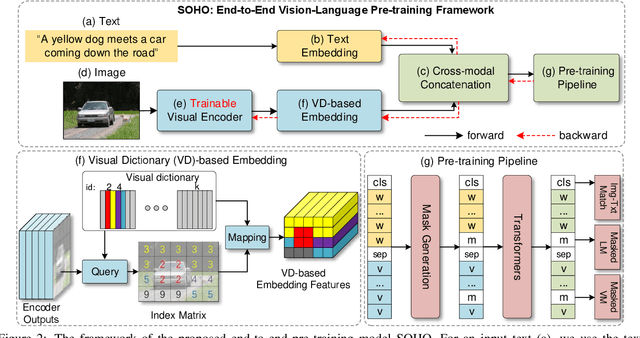
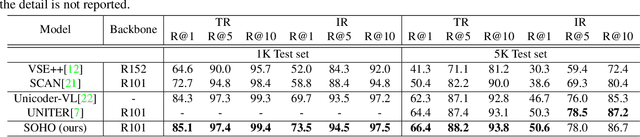
We study joint learning of Convolutional Neural Network (CNN) and Transformer for vision-language pre-training (VLPT) which aims to learn cross-modal alignments from millions of image-text pairs. State-of-the-art approaches extract salient image regions and align regions with words step-by-step. As region-based visual features usually represent parts of an image, it is challenging for existing vision-language models to fully understand the semantics from paired natural languages. In this paper, we propose SOHO to "See Out of tHe bOx" that takes a whole image as input, and learns vision-language representation in an end-to-end manner. SOHO does not require bounding box annotations which enables inference 10 times faster than region-based approaches. In particular, SOHO learns to extract comprehensive yet compact image features through a visual dictionary (VD) that facilitates cross-modal understanding. VD is designed to represent consistent visual abstractions of similar semantics. It is updated on-the-fly and utilized in our proposed pre-training task Masked Visual Modeling (MVM). We conduct experiments on four well-established vision-language tasks by following standard VLPT settings. In particular, SOHO achieves absolute gains of 2.0% R@1 score on MSCOCO text retrieval 5k test split, 1.5% accuracy on NLVR$^2$ test-P split, 6.7% accuracy on SNLI-VE test split, respectively.