 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FSNet: A Failure Detection Framework for Semantic Segmentation
Aug 19, 2021
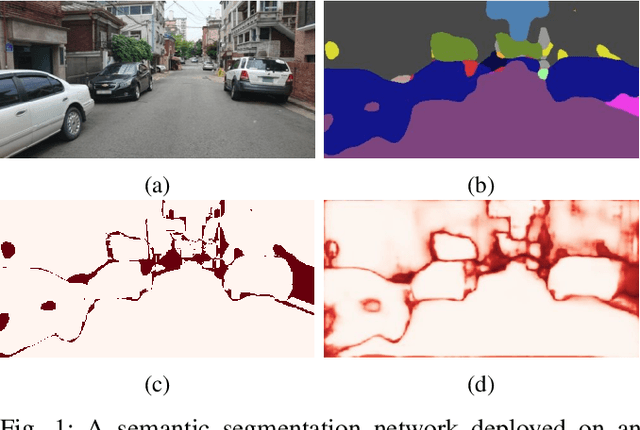
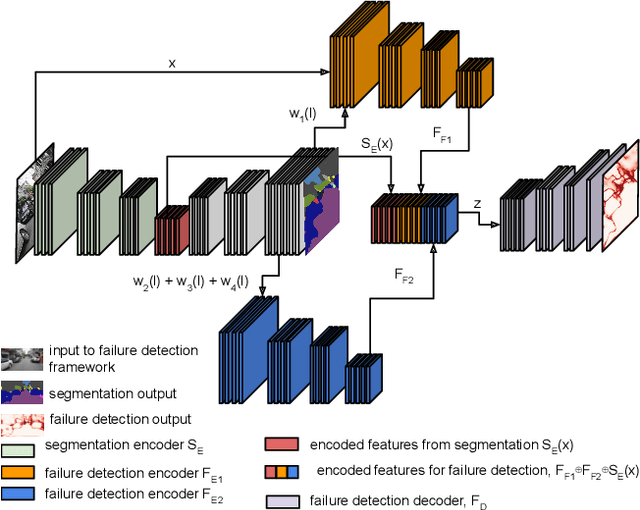


Semantic segmentation is an important task that helps autonomous vehicles understand their surroundings and navigate safely. During deployment, even the most mature segmentation models are vulnerable to various external factors that can degrade the segmentation performance with potentially catastrophic consequences for the vehicle and its surroundings. To address this issue, we propose a failure detection framework to identify pixel-level misclassification. We do so by exploiting internal features of the segmentation model and training it simultaneously with a failure detection network. During deployment, the failure detector can flag areas in the image where the segmentation model have failed to segment correctly. We evaluate the proposed approach against state-of-the-art methods and achieve 12.30%, 9.46%, and 9.65% performance improvement in the AUPR-Error metric for Cityscapes, BDD100K, and Mapillary semantic segmentation datasets.
Thinking Fast and Slow in AI: the Role of Metacognition
Oct 05, 2021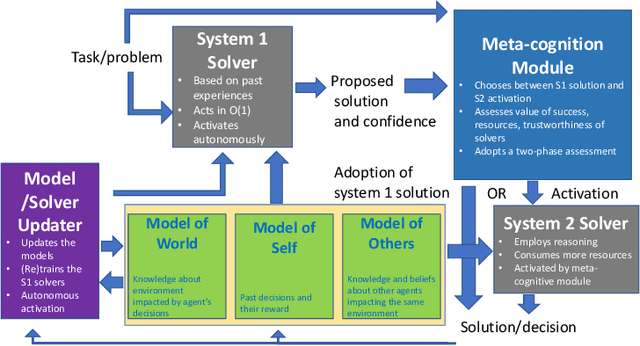
AI systems have seen dramatic advancement in recent years, bringing many applications that pervade our everyday life. However, we are still mostly seeing instances of narrow AI: many of these recent developments are typically focused on a very limited set of competencies and goals, e.g., image interpretation, natural language processing, classification, prediction, and many others. Moreover, while these successes can be accredited to improved algorithms and techniques, they are also tightly linked to the availability of huge datasets and computational power. State-of-the-art AI still lacks many capabilities that would naturally be included in a notion of (human) intelligence. We argue that a better study of the mechanisms that allow humans to have these capabilities can help us understand how to imbue AI systems with these competencies. We focus especially on D. Kahneman's theory of thinking fast and slow, and we propose a multi-agent AI architecture where incoming problems are solved by either system 1 (or "fast") agents, that react by exploiting only past experience, or by system 2 (or "slow") agents, that are deliberately activated when there is the need to reason and search for optimal solutions beyond what is expected from the system 1 agent. Both kinds of agents are supported by a model of the world, containing domain knowledge about the environment, and a model of "self", containing information about past actions of the system and solvers' skills.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021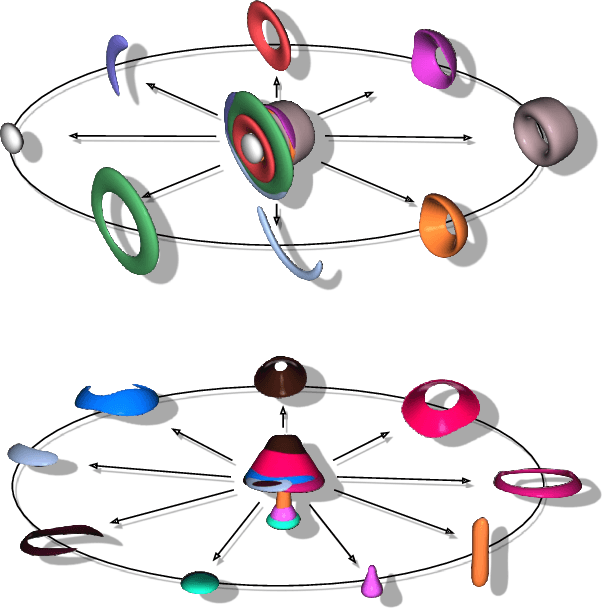
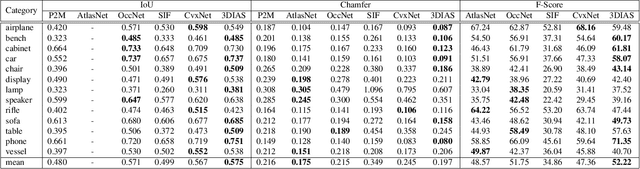
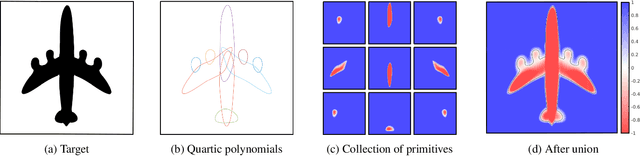

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .
WebQA: Multihop and Multimodal QA
Sep 01, 2021


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.
Holographic Maxwellian near-eye display with adjustable and continuous eye-box replication
Jun 11, 2021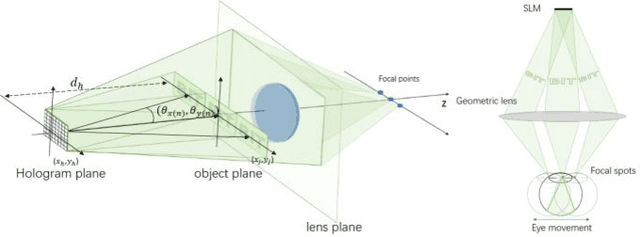
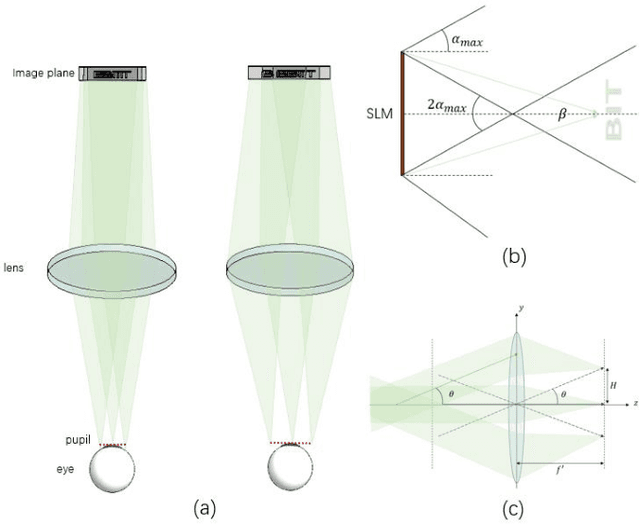
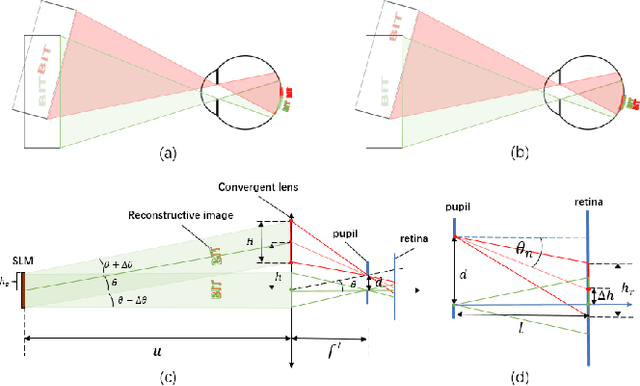
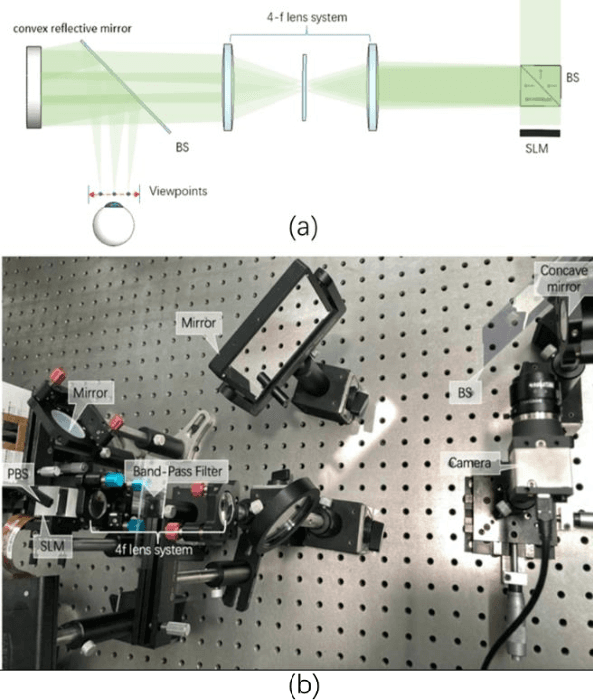
The Maxwellian display presents always-focused images to the viewer, alleviating the vergence-accommodation conflict (VAC) in near-eye displays (NEDs). However, the limited eyebox of the typical Maxwellian display prevents it from wider applications. We propose a holographic Maxwellian near-eye display with adjustable and continuous eye-box replication. Holographic display provides a way to match the human pupil size with the interval of the replicated eyeboxes, making it possible to eliminate or alleviate double image or blind area problem, which exists long in eyebox expansion for Maxwellian display. Besides, seamless image conversion between viewing points has been achieved through hologram pre-processing. Optical experiment confirms that the interval between replicated eyeboxes is dynamically adjustable, ranging from 2mm to 6mm. The proposed display can present always-focused images and seamless conversion among viewpoints with 5.32$^\circ$ horizontal field of view, and 9mmH * 3mmV eyebox.
Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation
Jul 01, 2021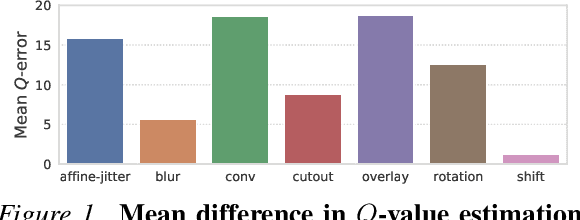
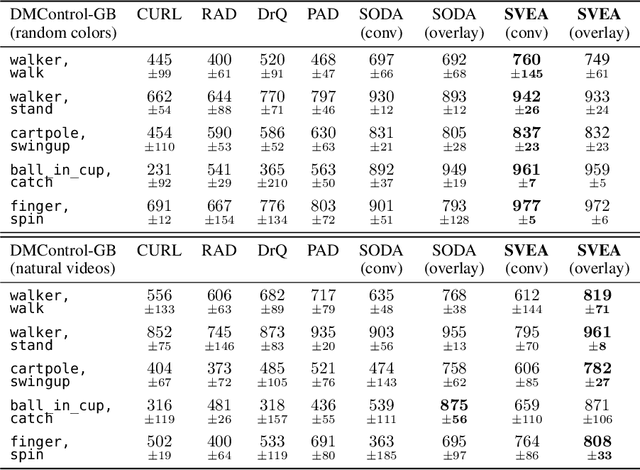
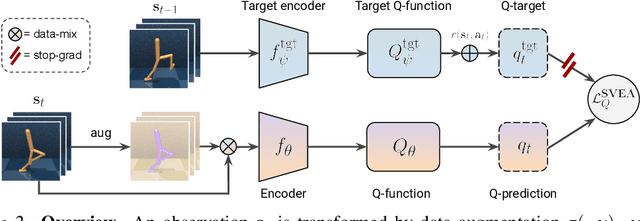
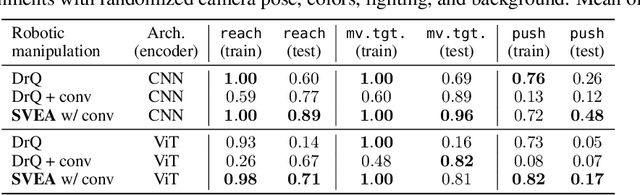
While agents trained by Reinforcement Learning (RL) can solve increasingly challenging tasks directly from visual observations, generalizing learned skills to novel environments remains very challenging. Extensive use of data augmentation is a promising technique for improving generalization in RL, but it is often found to decrease sample efficiency and can even lead to divergence. In this paper, we investigate causes of instability when using data augmentation in common off-policy RL algorithms. We identify two problems, both rooted in high-variance Q-targets. Based on our findings, we propose a simple yet effective technique for stabilizing this class of algorithms under augmentation. We perform extensive empirical evaluation of image-based RL using both ConvNets and Vision Transformers (ViT) on a family of benchmarks based on DeepMind Control Suite, as well as in robotic manipulation tasks. Our method greatly improves stability and sample efficiency of ConvNets under augmentation, and achieves generalization results competitive with state-of-the-art methods for image-based RL. We further show that our method scales to RL with ViT-based architectures, and that data augmentation may be especially important in this setting.
Convolutional Image Captioning
Nov 24, 2017
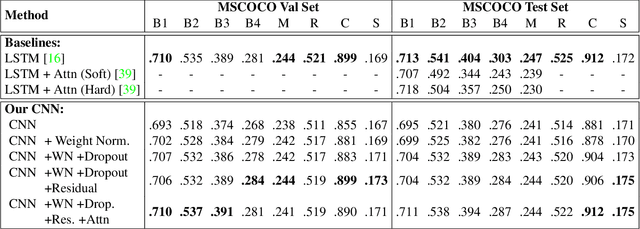
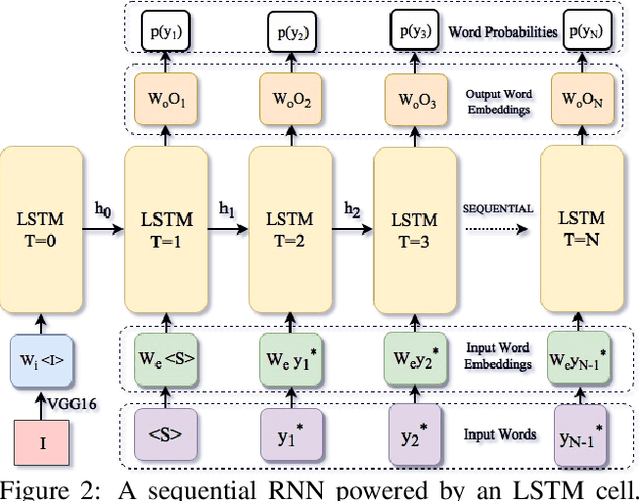

Image captioning is an important but challenging task, applicable to virtual assistants, editing tools, image indexing, and support of the disabled. Its challenges are due to the variability and ambiguity of possible image descriptions. In recent years significant progress has been made in image captioning, using Recurrent Neural Networks powered by long-short-term-memory (LSTM) units. Despite mitigating the vanishing gradient problem, and despite their compelling ability to memorize dependencies, LSTM units are complex and inherently sequential across time. To address this issue, recent work has shown benefits of convolutional networks for machine translation and conditional image generation. Inspired by their success, in this paper, we develop a convolutional image captioning technique. We demonstrate its efficacy on the challenging MSCOCO dataset and demonstrate performance on par with the baseline, while having a faster training time per number of parameters. We also perform a detailed analysis, providing compelling reasons in favor of convolutional language generation approaches.
Learning and Exploiting Interclass Visual Correlations for Medical Image Classification
Jul 13, 2020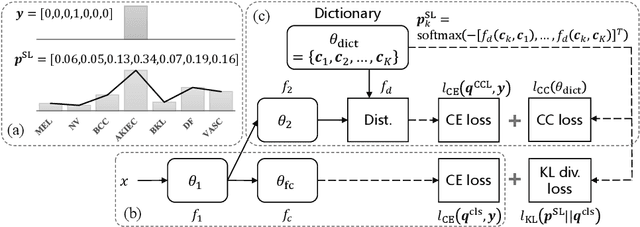
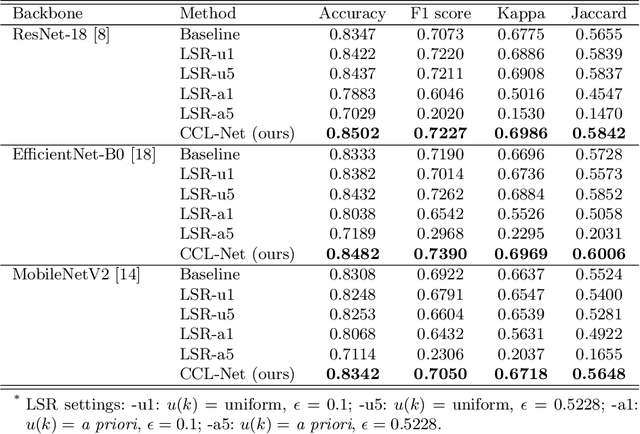

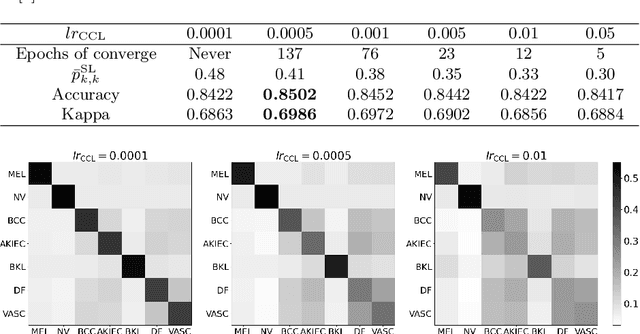
Deep neural network-based medical image classifications often use "hard" labels for training, where the probability of the correct category is 1 and those of others are 0. However, these hard targets can drive the networks over-confident about their predictions and prone to overfit the training data, affecting model generalization and adaption. Studies have shown that label smoothing and softening can improve classification performance. Nevertheless, existing approaches are either non-data-driven or limited in applicability. In this paper, we present the Class-Correlation Learning Network (CCL-Net) to learn interclass visual correlations from given training data, and produce soft labels to help with classification tasks. Instead of letting the network directly learn the desired correlations, we propose to learn them implicitly via distance metric learning of class-specific embeddings with a lightweight plugin CCL block. An intuitive loss based on a geometrical explanation of correlation is designed for bolstering learning of the interclass correlations. We further present end-to-end training of the proposed CCL block as a plugin head together with the classification backbone while generating soft labels on the fly. Our experimental results on the International Skin Imaging Collaboration 2018 dataset demonstrate effective learning of the interclass correlations from training data, as well as consistent improvements in performance upon several widely used modern network structures with the CCL block.
Salient Slices: Improved Neural Network Training and Performance with Image Entropy
Jul 29, 2019

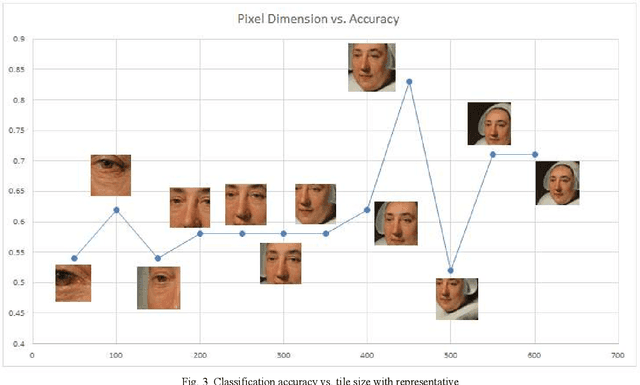

As a training and analysis strategy for convolutional neural networks (CNNs), we slice images into tiled segments and use, for training and prediction, segments that both satisfy a criterion of information diversity and contain sufficient content to support classification. In particular, we utilize image entropy as the diversity criterion. This ensures that each tile carries as much information diversity as the original image, and for many applications serves as an indicator of usefulness in classification. To make predictions, a probability aggregation framework is applied to probabilities assigned by the CNN to the input image tiles. This technique facilitates the use of large, high-resolution images that would be impractical to analyze unmodified; provides data augmentation for training, which is particularly valuable when image availability is limited; and the ensemble nature of the input for prediction enhances its accuracy.
TANet: A new Paradigm for Global Face Super-resolution via Transformer-CNN Aggregation Network
Sep 16, 2021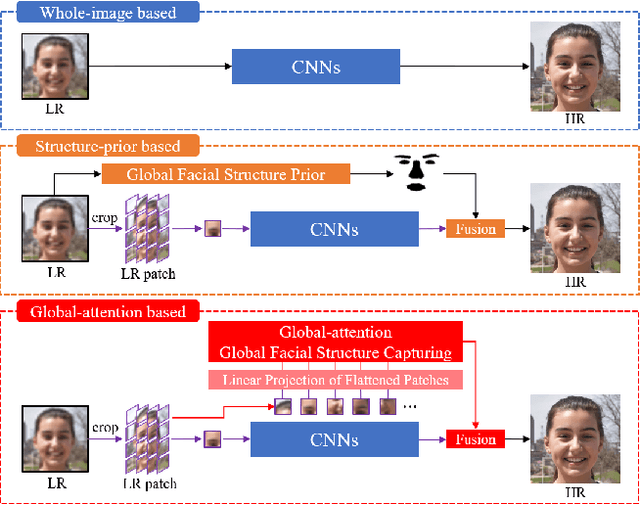
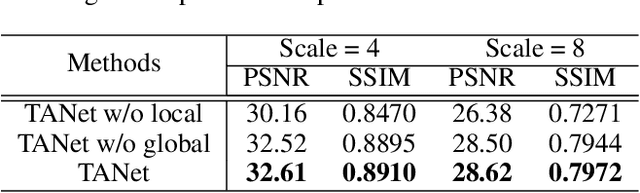
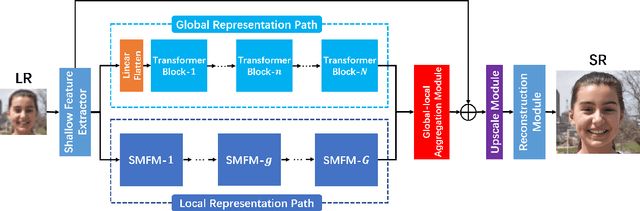
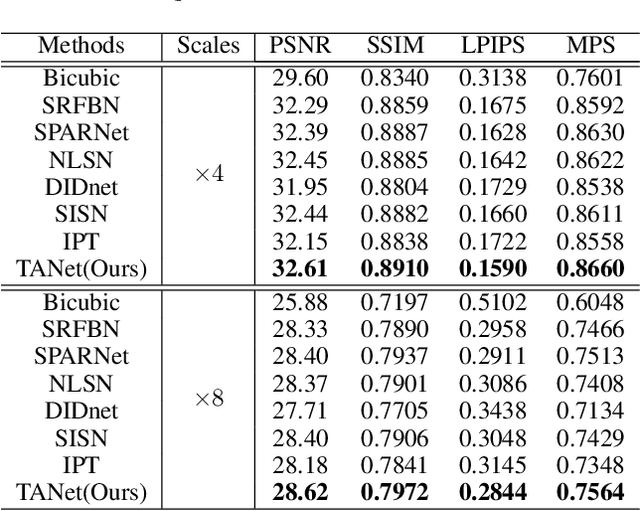
Recently, face super-resolution (FSR) methods either feed whole face image into convolutional neural networks (CNNs) or utilize extra facial priors (e.g., facial parsing maps, facial landmarks) to focus on facial structure, thereby maintaining the consistency of the facial structure while restoring facial details. However, the limited receptive fields of CNNs and inaccurate facial priors will reduce the naturalness and fidelity of the reconstructed face. In this paper, we propose a novel paradigm based on the self-attention mechanism (i.e., the core of Transformer) to fully explore the representation capacity of the facial structure feature. Specifically, we design a Transformer-CNN aggregation network (TANet) consisting of two paths, in which one path uses CNNs responsible for restoring fine-grained facial details while the other utilizes a resource-friendly Transformer to capture global information by exploiting the long-distance visual relation modeling. By aggregating the features from the above two paths, the consistency of global facial structure and fidelity of local facial detail restoration are strengthened simultaneously. Experimental results of face reconstruction and recognition verify that the proposed method can significantly outperform the state-of-the-art methods.