 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shift-BNN: Highly-Efficient Probabilistic Bayesian Neural Network Training via Memory-Friendly Pattern Retrieving
Oct 07, 2021
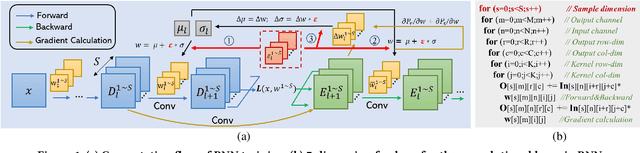
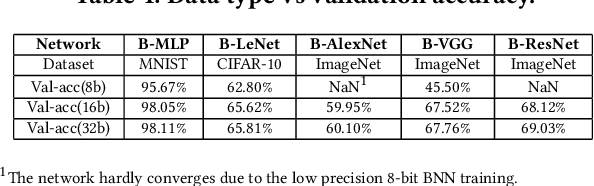
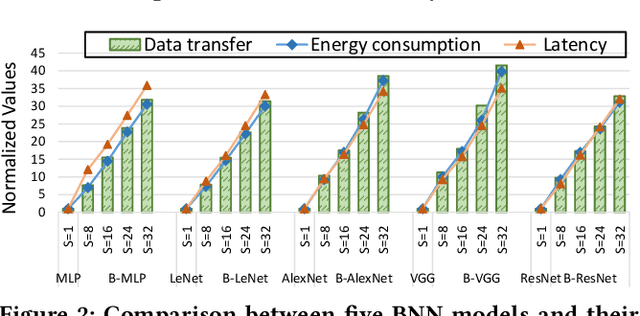
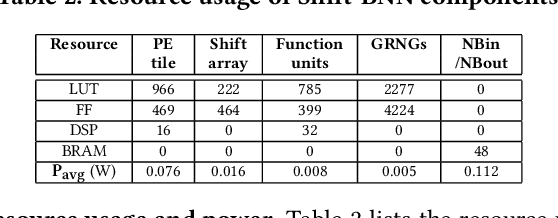
Bayesian Neural Networks (BNNs) that possess a property of uncertainty estimation have been increasingly adopted in a wide range of safety-critical AI applications which demand reliable and robust decision making, e.g., self-driving, rescue robots, medical image diagnosis. The training procedure of a probabilistic BNN model involves training an ensemble of sampled DNN models, which induces orders of magnitude larger volume of data movement than training a single DNN model. In this paper, we reveal that the root cause for BNN training inefficiency originates from the massive off-chip data transfer by Gaussian Random Variables (GRVs). To tackle this challenge, we propose a novel design that eliminates all the off-chip data transfer by GRVs through the reversed shifting of Linear Feedback Shift Registers (LFSRs) without incurring any training accuracy loss. To efficiently support our LFSR reversion strategy at the hardware level, we explore the design space of the current DNN accelerators and identify the optimal computation mapping scheme to best accommodate our strategy. By leveraging this finding, we design and prototype the first highly efficient BNN training accelerator, named Shift-BNN, that is low-cost and scalable. Extensive evaluation on five representative BNN models demonstrates that Shift-BNN achieves an average of 4.9x (up to 10.8x) boost in energy efficiency and 1.6x (up to 2.8x) speedup over the baseline DNN training accelerator.
IterNet: Retinal Image Segmentation Utilizing Structural Redundancy in Vessel Networks
Dec 12, 2019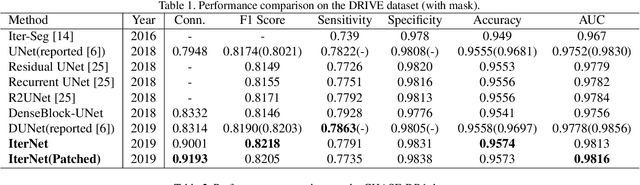
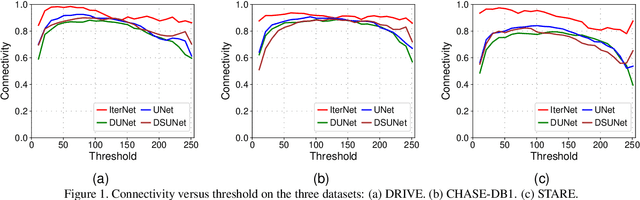
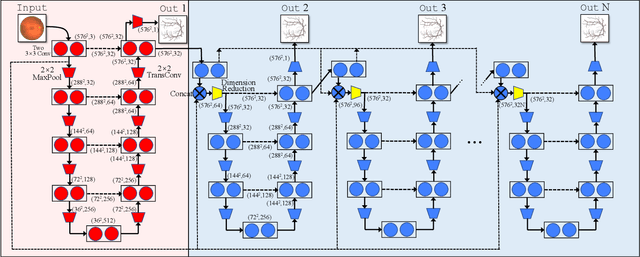
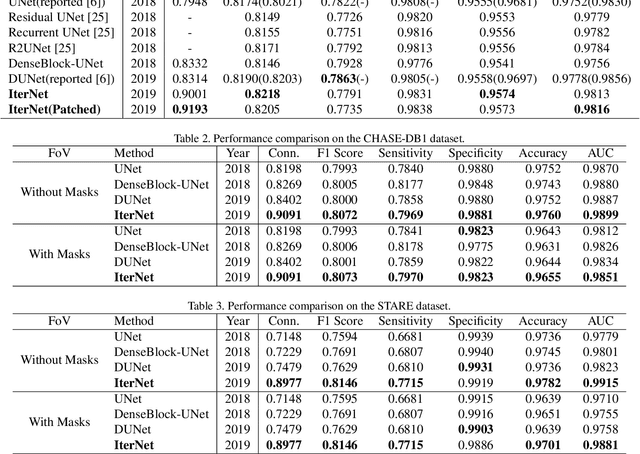
Retinal vessel segmentation is of great interest for diagnosis of retinal vascular diseases. To further improve the performance of vessel segmentation, we propose IterNet, a new model based on UNet, with the ability to find obscured details of the vessel from the segmented vessel image itself, rather than the raw input image. IterNet consists of multiple iterations of a mini-UNet, which can be 4$\times$ deeper than the common UNet. IterNet also adopts the weight-sharing and skip-connection features to facilitate training; therefore, even with such a large architecture, IterNet can still learn from merely 10$\sim$20 labeled images, without pre-training or any prior knowledge. IterNet achieves AUCs of 0.9816, 0.9851, and 0.9881 on three mainstream datasets, namely DRIVE, CHASE-DB1, and STARE, respectively, which currently are the best scores in the literature. The source code is available.
Image-Based Geo-Localization Using Satellite Imagery
Mar 04, 2019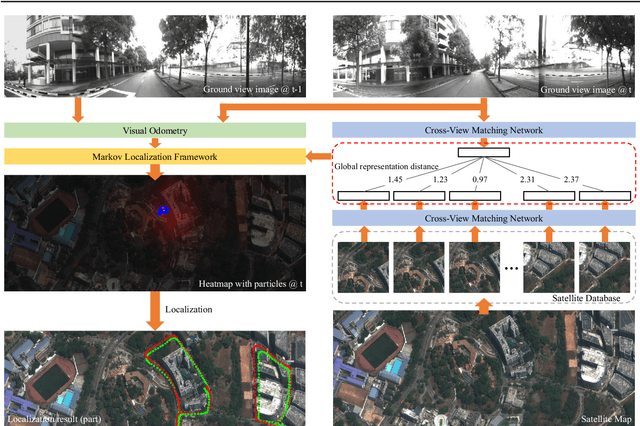
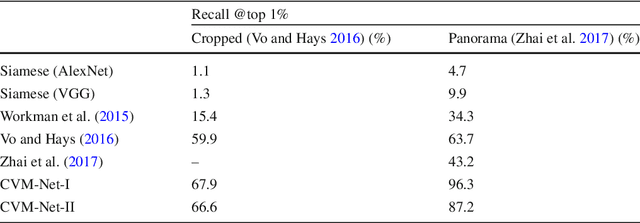
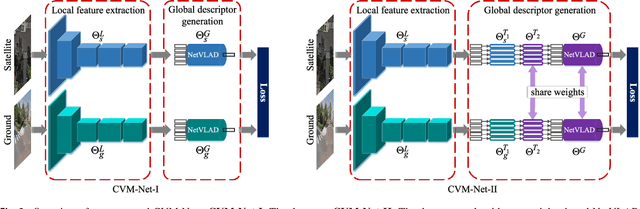

The problem of localization on a geo-referenced satellite map given a query ground view image is useful yet remains challenging due to the drastic change in viewpoint. To this end, in this paper we work on the extension of our earlier work on the Cross-View Matching Network (CVM-Net) for the ground-to-aerial image matching task since the traditional image descriptors fail due to the drastic viewpoint change. In particular, we show more extensive experimental results and analyses of the network architecture on our CVM-Net. Furthermore, we propose a Markov localization framework that enforces the temporal consistency between image frames to enhance the geo-localization results in the case where a video stream of ground view images is available. Experimental results show that our proposed Markov localization framework can continuously localize the vehicle within a small error on our Singapore dataset.
Joint haze image synthesis and dehazing with mmd-vae losses
May 15, 2019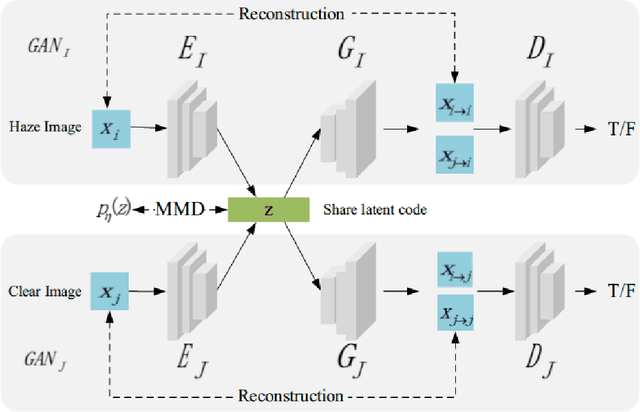
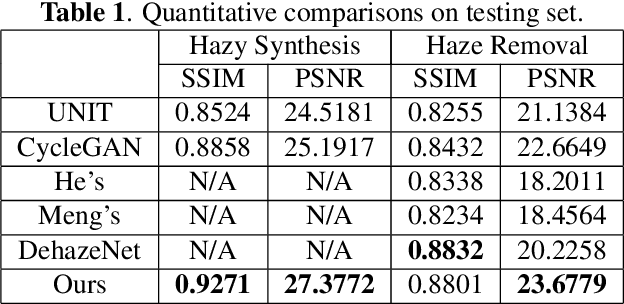


Fog and haze are weathers with low visibility which are adversarial to the driving safety of intelligent vehicles equipped with optical sensors like cameras and LiDARs. Therefore image dehazing for perception enhancement and haze image synthesis for testing perception abilities are equivalently important in the development of such autonomous driving systems. From the view of image translation, these two problems are essentially dual with each other, which have the potentiality to be solved jointly. In this paper, we propose an unsupervised Image-to-Image Translation framework based on Variational Autoencoders (VAE) and Generative Adversarial Nets (GAN) to handle haze image synthesis and haze removal simultaneously. Since the KL divergence in the VAE objectives could not guarantee the optimal mapping under imbalanced and unpaired training samples with limited size, Maximum mean discrepancy (MMD) based VAE is utilized to ensure the translating consistency in both directions. The comprehensive analysis on both synthesis and dehazing performance of our method demonstrate the feasibility and practicability of the proposed method.
AnoSeg: Anomaly Segmentation Network Using Self-Supervised Learning
Oct 07, 2021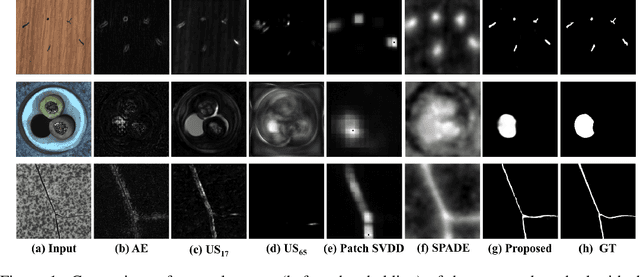
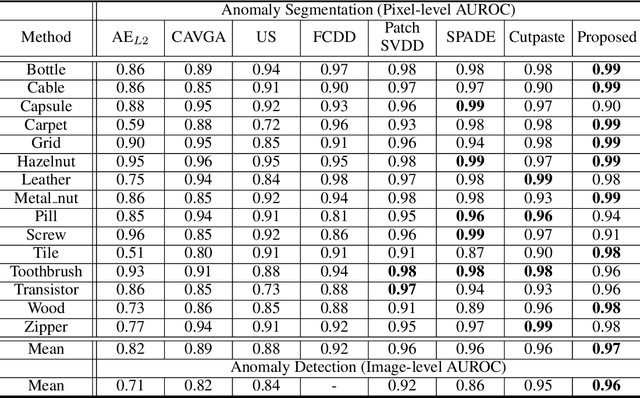
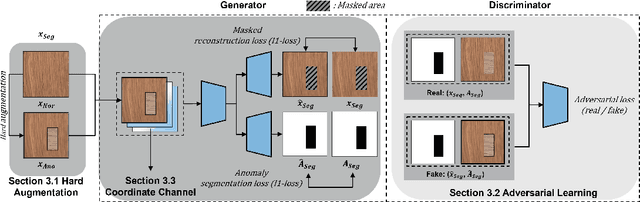

Anomaly segmentation, which localizes defective areas, is an important component in large-scale industrial manufacturing. However, most recent researches have focused on anomaly detection. This paper proposes a novel anomaly segmentation network (AnoSeg) that can directly generate an accurate anomaly map using self-supervised learning. For highly accurate anomaly segmentation, the proposed AnoSeg considers three novel techniques: Anomaly data generation based on hard augmentation, self-supervised learning with pixel-wise and adversarial losses, and coordinate channel concatenation. First, to generate synthetic anomaly images and reference masks for normal data, the proposed method uses hard augmentation to change the normal sample distribution. Then, the proposed AnoSeg is trained in a self-supervised learning manner from the synthetic anomaly data and normal data. Finally, the coordinate channel, which represents the pixel location information, is concatenated to an input of AnoSeg to consider the positional relationship of each pixel in the image. The estimated anomaly map can also be utilized to improve the performance of anomaly detection. Our experiments show that the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for the MVTec AD dataset. In addition, we compared the proposed method with the existing methods through the intersection over union (IoU) metric commonly used in segmentation tasks and demonstrated the superiority of our method for anomaly segmentation.
Dynamically Grown Generative Adversarial Networks
Jun 16, 2021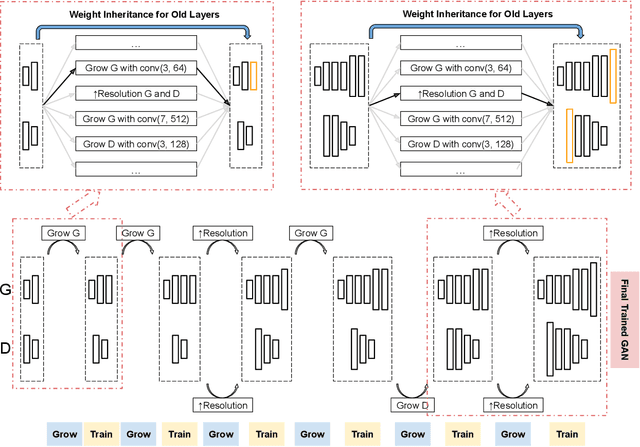
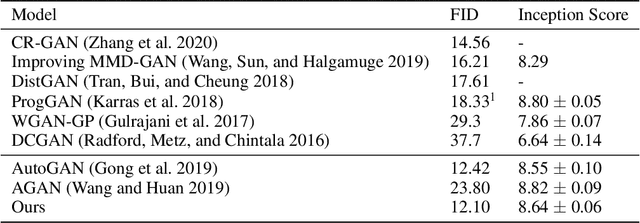


Recent work introduced progressive network growing as a promising way to ease the training for large GANs, but the model design and architecture-growing strategy still remain under-explored and needs manual design for different image data. In this paper, we propose a method to dynamically grow a GAN during training, optimizing the network architecture and its parameters together with automation. The method embeds architecture search techniques as an interleaving step with gradient-based training to periodically seek the optimal architecture-growing strategy for the generator and discriminator. It enjoys the benefits of both eased training because of progressive growing and improved performance because of broader architecture design space. Experimental results demonstrate new state-of-the-art of image generation. Observations in the search procedure also provide constructive insights into the GAN model design such as generator-discriminator balance and convolutional layer choices.
Deep Microlocal Reconstruction for Limited-Angle Tomography
Aug 12, 2021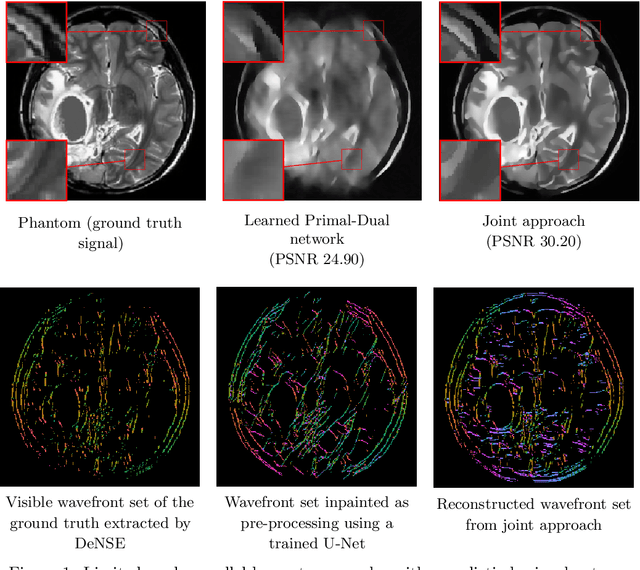
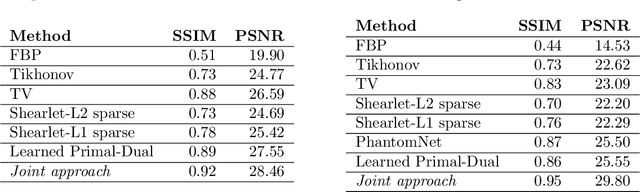

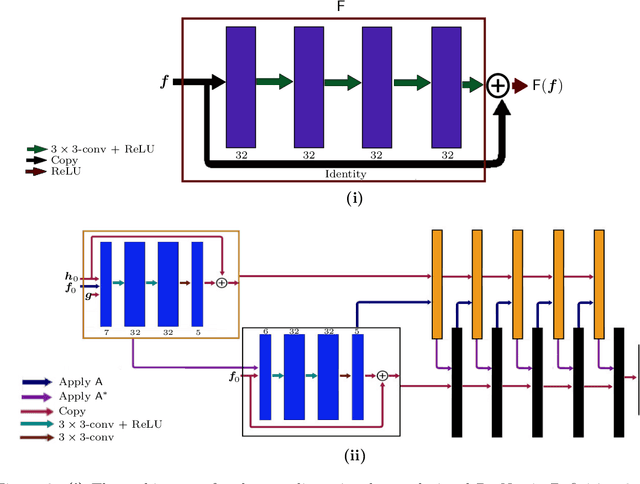
We present a deep learning-based algorithm to jointly solve a reconstruction problem and a wavefront set extraction problem in tomographic imaging. The algorithm is based on a recently developed digital wavefront set extractor as well as the well-known microlocal canonical relation for the Radon transform. We use the wavefront set information about x-ray data to improve the reconstruction by requiring that the underlying neural networks simultaneously extract the correct ground truth wavefront set and ground truth image. As a necessary theoretical step, we identify the digital microlocal canonical relations for deep convolutional residual neural networks. We find strong numerical evidence for the effectiveness of this approach.
Image search using multilingual texts: a cross-modal learning approach between image and text
May 14, 2019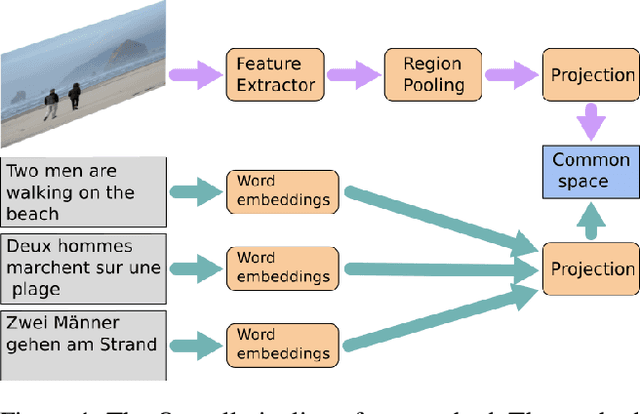
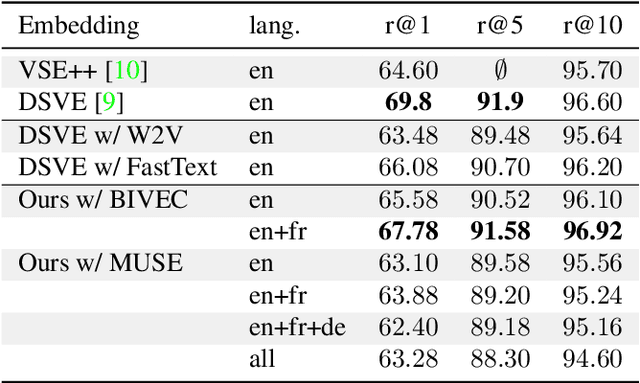
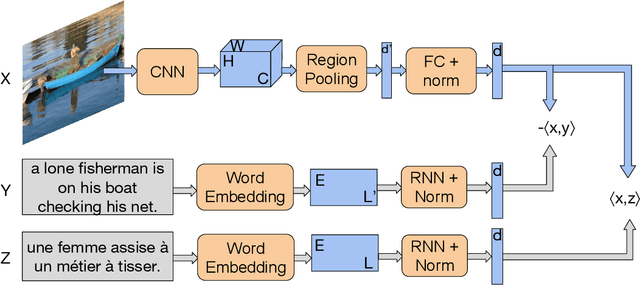
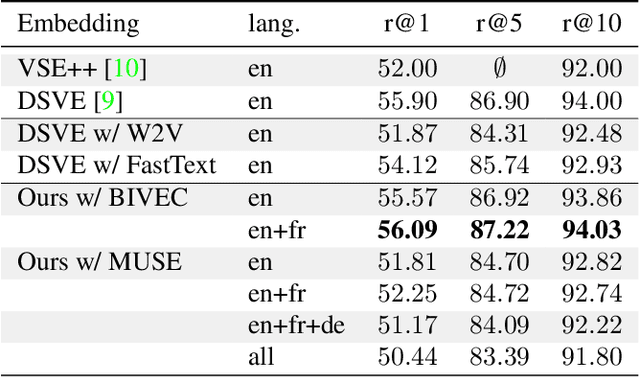
Multilingual (or cross-lingual) embeddings represent several languages in a unique vector space. Using a common embedding space enables for a shared semantic between words from different languages. In this paper, we propose to embed images and texts into a unique distributional vector space, enabling to search images by using text queries expressing information needs related to the (visual) content of images, as well as using image similarity. Our framework forces the representation of an image to be similar to the representation of the text that describes it. Moreover, by using multilingual embeddings we ensure that words from two different languages have close descriptors and thus are attached to similar images. We provide experimental evidence of the efficiency of our approach by experimenting it on two datasets: Common Objects in COntext (COCO) [19] and Multi30K [7].
Automatic Text Evaluation through the Lens of Wasserstein Barycenters
Aug 27, 2021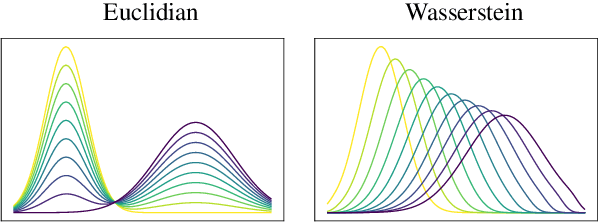
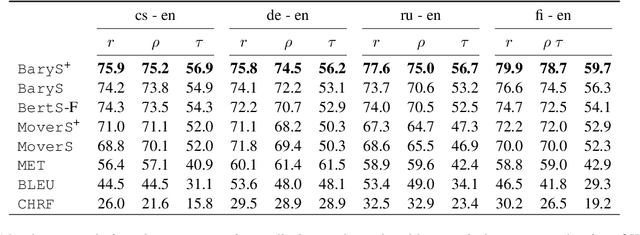
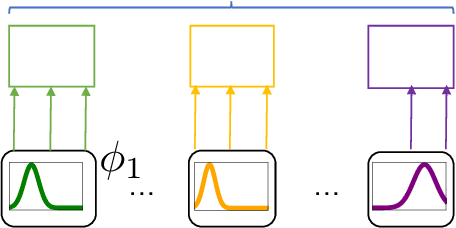
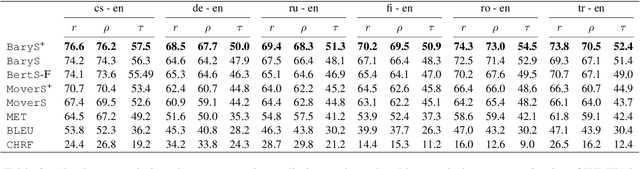
A new metric \texttt{BaryScore} to evaluate text generation based on deep contextualized embeddings (\textit{e.g.}, BERT, Roberta, ELMo) is introduced. This metric is motivated by a new framework relying on optimal transport tools, \textit{i.e.}, Wasserstein distance and barycenter. By modelling the layer output of deep contextualized embeddings as a probability distribution rather than by a vector embedding; this framework provides a natural way to aggregate the different outputs through the Wasserstein space topology. In addition, it provides theoretical grounds to our metric and offers an alternative to available solutions (\textit{e.g.}, MoverScore and BertScore). Numerical evaluation is performed on four different tasks: machine translation, summarization, data2text generation and image captioning. Our results show that \texttt{BaryScore} outperforms other BERT based metrics and exhibits more consistent behaviour in particular for text summarization.
TyXe: Pyro-based Bayesian neural nets for Pytorch
Oct 01, 2021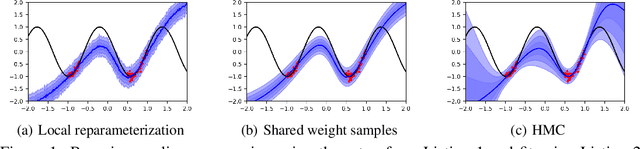
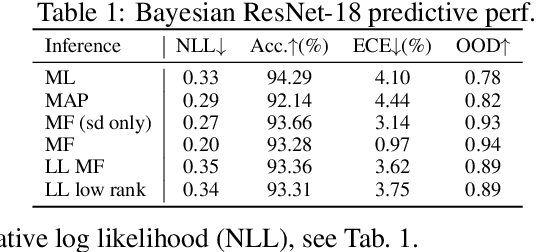
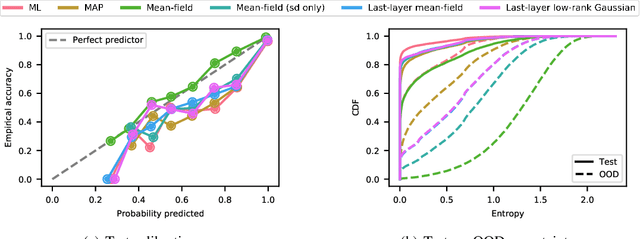

We introduce TyXe, a Bayesian neural network library built on top of Pytorch and Pyro. Our leading design principle is to cleanly separate architecture, prior, inference and likelihood specification, allowing for a flexible workflow where users can quickly iterate over combinations of these components. In contrast to existing packages TyXe does not implement any layer classes, and instead relies on architectures defined in generic Pytorch code. TyXe then provides modular choices for canonical priors, variational guides, inference techniques, and layer selections for a Bayesian treatment of the specified architecture. Sampling tricks for variance reduction, such as local reparameterization or flipout, are implemented as effect handlers, which can be applied independently of other specifications. We showcase the ease of use of TyXe to explore Bayesian versions of popular models from various libraries: toy regression with a pure Pytorch neural network; large-scale image classification with torchvision ResNets; graph neural networks based on DGL; and Neural Radiance Fields built on top of Pytorch3D. Finally, we provide convenient abstractions for variational continual learning. In all cases the change from a deterministic to a Bayesian neural network comes with minimal modifications to existing code, offering a broad range of researchers and practitioners alike practical access to uncertainty estimation techniques. The library is available at https://github.com/TyXe-BDL/TyXe.