 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Elastic Interaction-Based Loss Function for Medical Image Segmentation
Jul 06, 2020
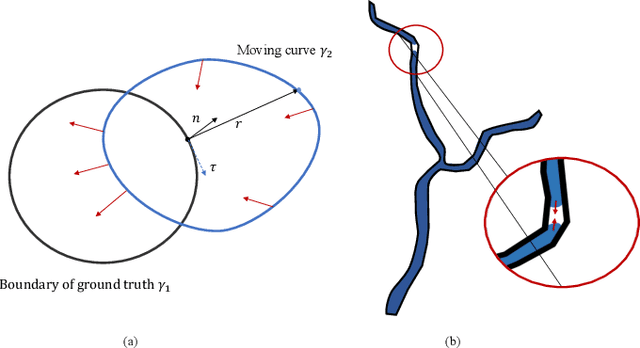
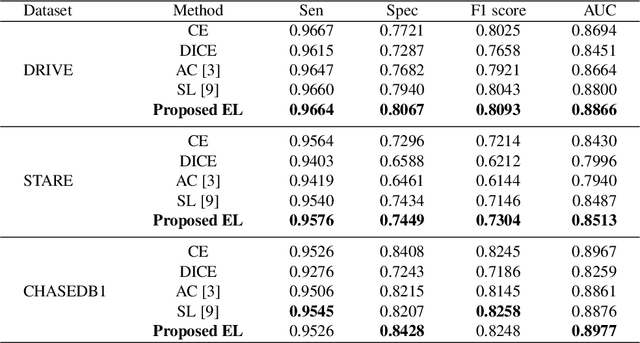
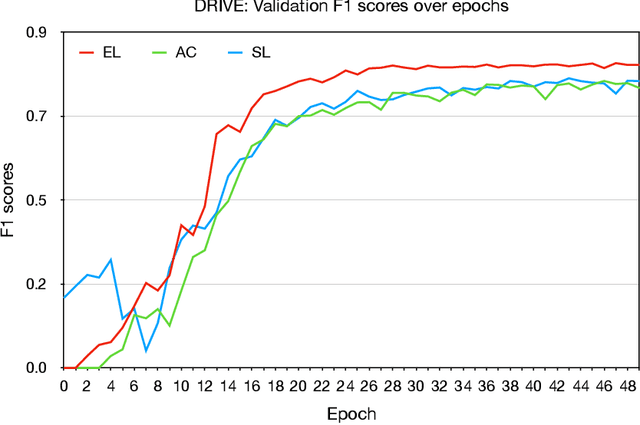
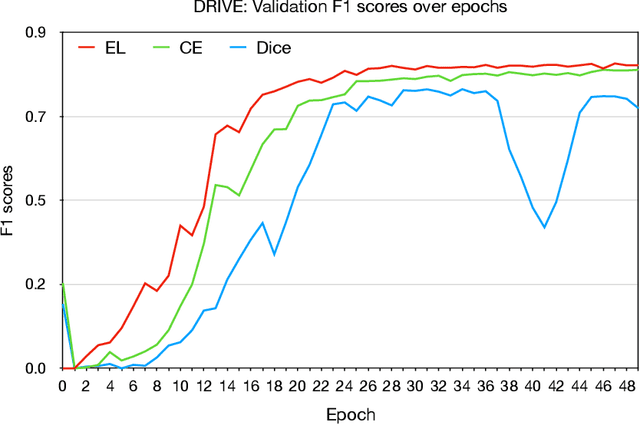
Deep learning techniques have shown their success in medical image segmentation since they are easy to manipulate and robust to various types of datasets. The commonly used loss functions in the deep segmentation task are pixel-wise loss functions. This results in a bottleneck for these models to achieve high precision for complicated structures in biomedical images. For example, the predicted small blood vessels in retinal images are often disconnected or even missed under the supervision of the pixel-wise losses. This paper addresses this problem by introducing a long-range elastic interaction-based training strategy. In this strategy, convolutional neural network (CNN) learns the target region under the guidance of the elastic interaction energy between the boundary of the predicted region and that of the actual object. Under the supervision of the proposed loss, the boundary of the predicted region is attracted strongly by the object boundary and tends to stay connected. Experimental results show that our method is able to achieve considerable improvements compared to commonly used pixel-wise loss functions (cross entropy and dice Loss) and other recent loss functions on three retinal vessel segmentation datasets, DRIVE, STARE and CHASEDB1.
Improved Image Augmentation for Convolutional Neural Networks by Copyout and CopyPairing
Sep 22, 2019
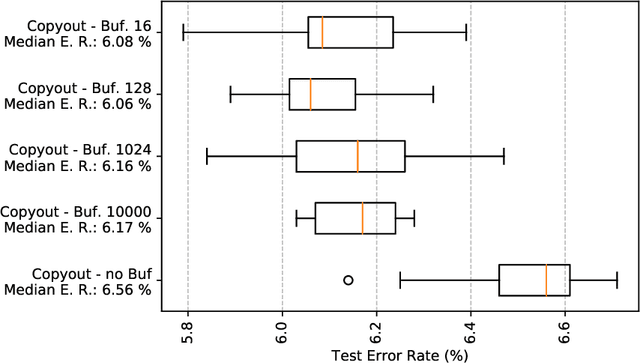
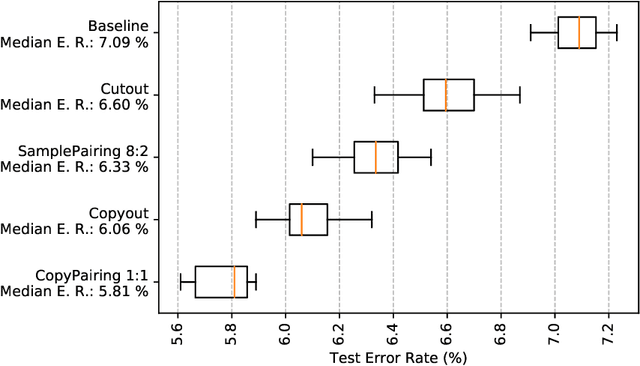
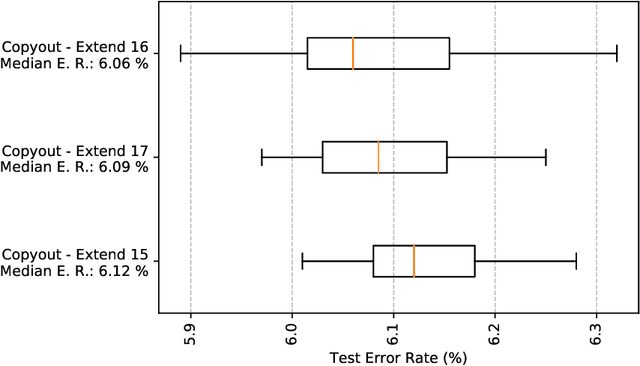
Image augmentation is a widely used technique to improve the performance of convolutional neural networks (CNNs). In common image shifting, cropping, flipping, shearing and rotating are used for augmentation. But there are more advanced techniques like Cutout and SamplePairing. In this work we present two improvements of the state-of-the-art Cutout and SamplePairing techniques. Our new method called Copyout takes a square patch of another random training image and copies it onto a random location of each image used for training. The second technique we discovered is called CopyPairing. It combines Copyout and SamplePairing for further augmentation and even better performance. We apply different experiments with these augmentation techniques on the CIFAR-10 dataset to evaluate and compare them under different configurations. In our experiments we show that Copyout reduces the test error rate by 8.18% compared with Cutout and 4.27% compared with SamplePairing. CopyPairing reduces the test error rate by 11.97% compared with Cutout and 8.21% compared with SamplePairing. Copyout and CopyPairing implementations are available at https://github.com/t-systems-on-site-services-gmbh/coocop.
SNIDER: Single Noisy Image Denoising and Rectification for Improving License Plate Recognition
Oct 09, 2019
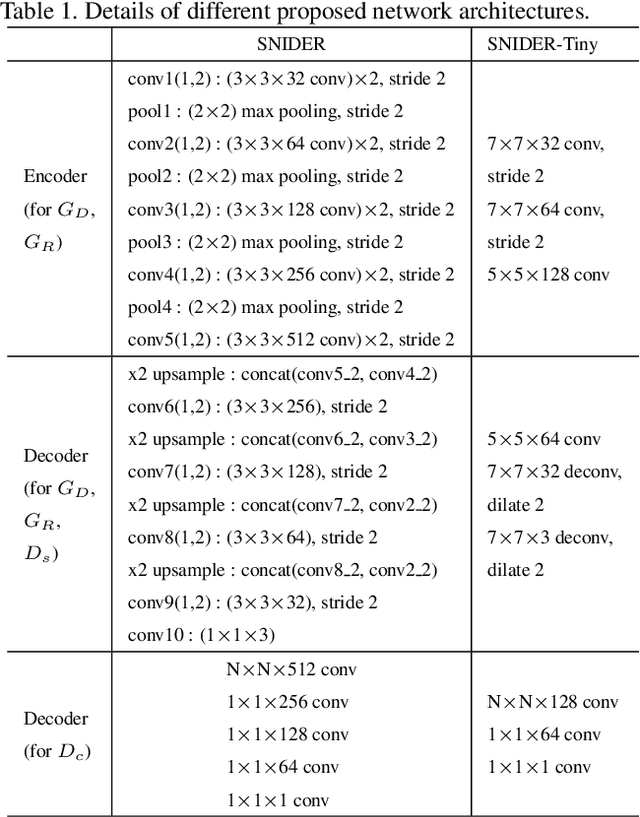
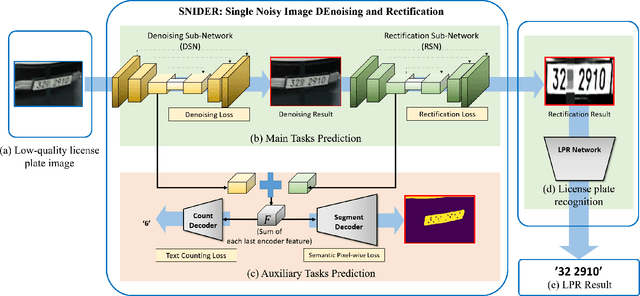
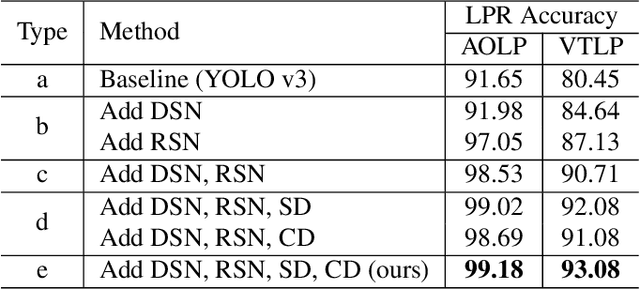
In this paper, we present an algorithm for real-world license plate recognition (LPR) from a low-quality image. Our method is built upon a framework that includes denoising and rectification, and each task is conducted by Convolutional Neural Networks. Existing denoising and rectification have been treated separately as a single network in previous research. In contrast to the previous work, we here propose an end-to-end trainable network for image recovery, Single Noisy Image DEnoising and Rectification (SNIDER), which focuses on solving both the problems jointly. It overcomes those obstacles by designing a novel network to address the denoising and rectification jointly. Moreover, we propose a way to leverage optimization with the auxiliary tasks for multi-task fitting and novel training losses. Extensive experiments on two challenging LPR datasets demonstrate the effectiveness of our proposed method in recovering the high-quality license plate image from the low-quality one and show that the the proposed method outperforms other state-of-the-art methods.
Remote Sensing Image Scene Classification with Deep Neural Networks in JPEG 2000 Compressed Domain
Jun 20, 2020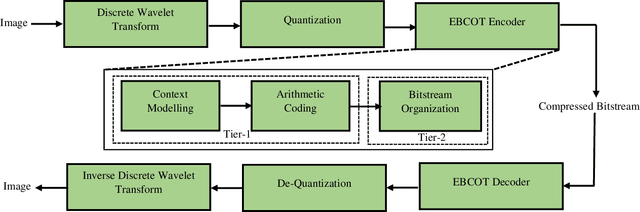
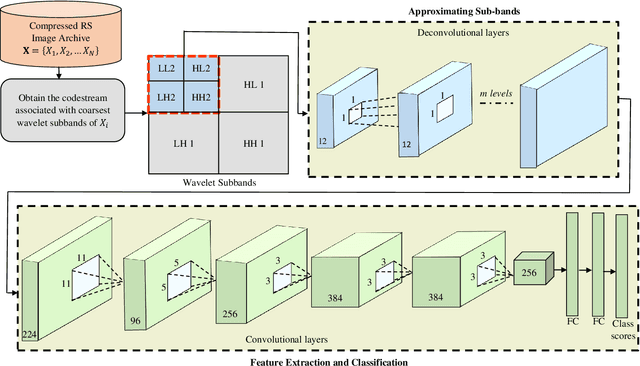
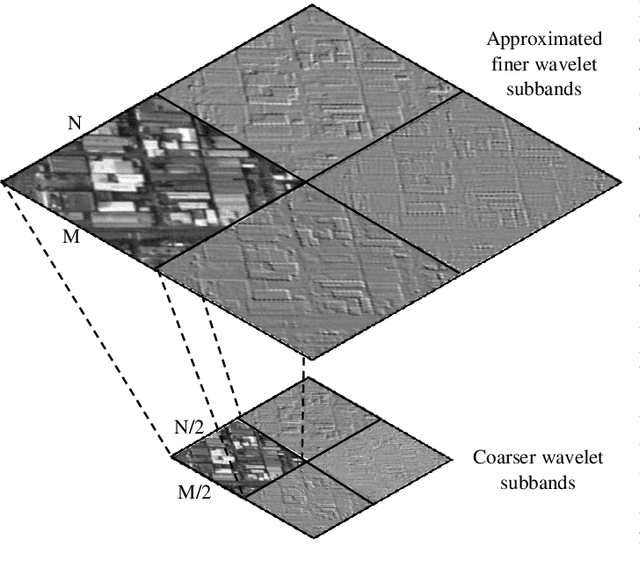
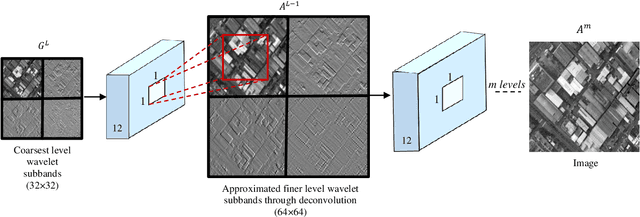
To reduce the storage requirements, remote sensing (RS) images are usually stored in compressed format. Existing scene classification approaches using deep neural networks (DNNs) require to fully decompress the images, which is a computationally demanding task in operational applications. To address this issue, in this paper we propose a novel approach to achieve scene classification in JPEG 2000 compressed RS images. The proposed approach consists of two main steps: i) approximation of the finer resolution sub-bands of reversible biorthogonal wavelet filters used in JPEG 2000; and ii) characterization of the high-level semantic content of approximated wavelet sub-bands and scene classification based on the learnt descriptors. This is achieved by taking codestreams associated with the coarsest resolution wavelet sub-band as input to approximate finer resolution sub-bands using a number of transposed convolutional layers. Then, a series of convolutional layers models the high-level semantic content of the approximated wavelet sub-band. Thus, the proposed approach models the multiresolution paradigm given in the JPEG 2000 compression algorithm in an end-to-end trainable unified neural network. In the classification stage, the proposed approach takes only the coarsest resolution wavelet sub-bands as input, thereby reducing the time required to apply decoding. Experimental results performed on two benchmark aerial image archives demonstrate that the proposed approach significantly reduces the computational time with similar classification accuracies when compared to traditional RS scene classification approaches (which requires full image decompression).
RegionViT: Regional-to-Local Attention for Vision Transformers
Jun 04, 2021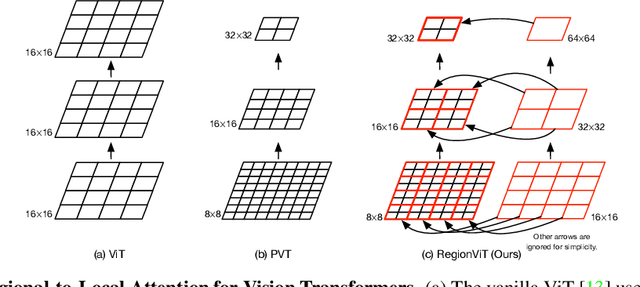
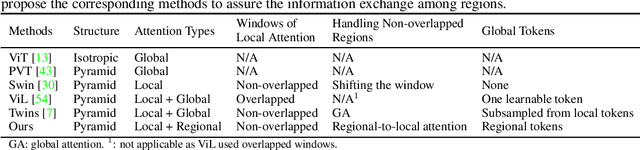

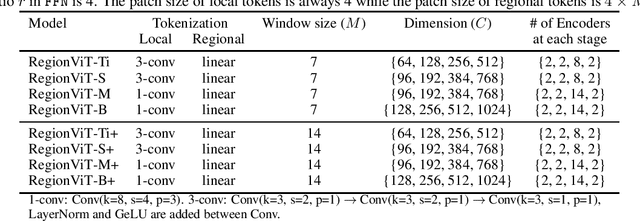
Vision transformer (ViT) has recently showed its strong capability in achieving comparable results to convolutional neural networks (CNNs) on image classification. However, vanilla ViT simply inherits the same architecture from the natural language processing directly, which is often not optimized for vision applications. Motivated by this, in this paper, we propose a new architecture that adopts the pyramid structure and employ a novel regional-to-local attention rather than global self-attention in vision transformers. More specifically, our model first generates regional tokens and local tokens from an image with different patch sizes, where each regional token is associated with a set of local tokens based on the spatial location. The regional-to-local attention includes two steps: first, the regional self-attention extract global information among all regional tokens and then the local self-attention exchanges the information among one regional token and the associated local tokens via self-attention. Therefore, even though local self-attention confines the scope in a local region but it can still receive global information. Extensive experiments on three vision tasks, including image classification, object detection and action recognition, show that our approach outperforms or is on par with state-of-the-art ViT variants including many concurrent works. Our source codes and models will be publicly available.
Task-related self-supervised learning for remote sensing image change detection
May 11, 2021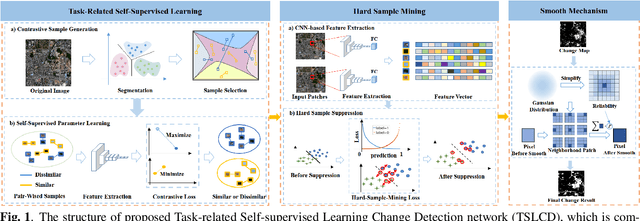
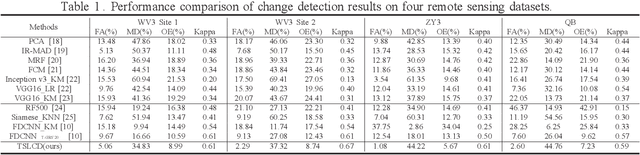
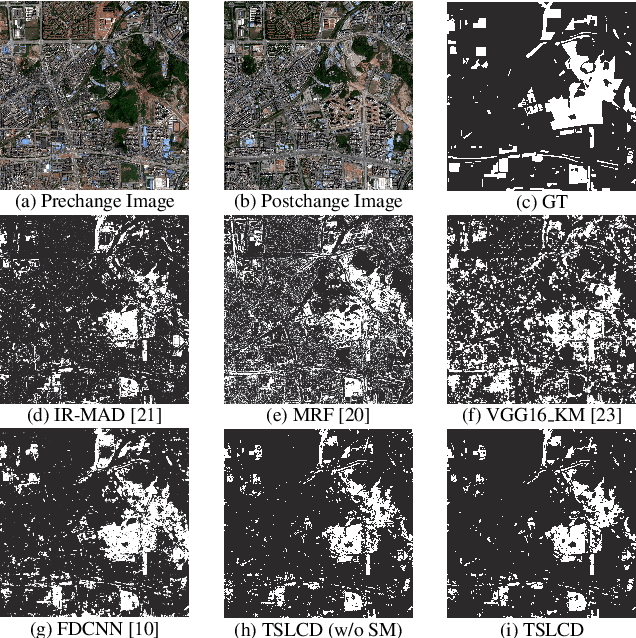
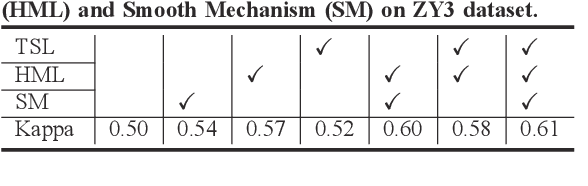
Change detection for remote sensing images is widely applied for urban change detection, disaster assessment and other fields. However, most of the existing CNN-based change detection methods still suffer from the problem of inadequate pseudo-changes suppression and insufficient feature representation. In this work, an unsupervised change detection method based on Task-related Self-supervised Learning Change Detection network with smooth mechanism(TSLCD) is proposed to eliminate it. The main contributions include: (1) the task-related self-supervised learning module is introduced to extract spatial features more effectively. (2) a hard-sample-mining loss function is applied to pay more attention to the hard-to-classify samples. (3) a smooth mechanism is utilized to remove some of pseudo-changes and noise. Experiments on four remote sensing change detection datasets reveal that the proposed TSLCD method achieves the state-of-the-art for change detection task.
Image-based table recognition: data, model, and evaluation
Dec 13, 2019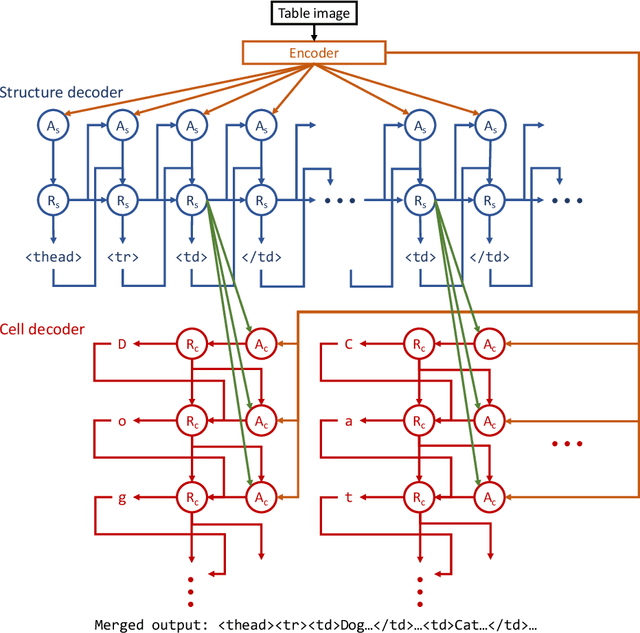
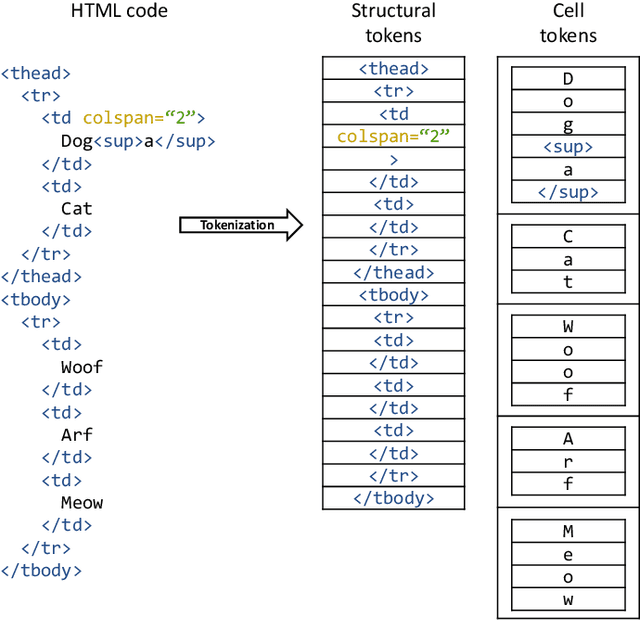
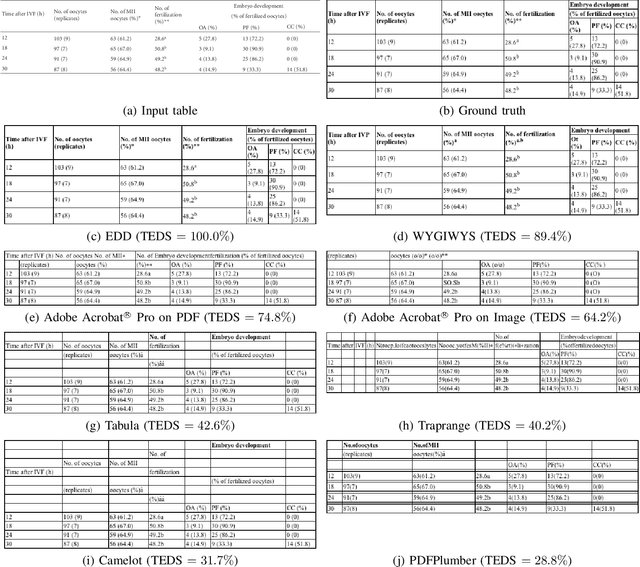

Important information that relates to a specific topic in a document is often organized in tabular format to assist readers with information retrieval and comparison, which may be difficult to provide in natural language. However, tabular data in unstructured digital documents, e.g., Portable Document Format (PDF) and images, are difficult to parse into structured machine-readable format, due to complexity and diversity in their structure and style. To facilitate image-based table recognition with deep learning, we develop the largest publicly available table recognition dataset PubTabNet (https://github.com/ibm-aur-nlp/PubTabNet), containing 568k table images with corresponding structured HTML representation. PubTabNet is automatically generated by matching the XML and PDF representations of the scientific articles in PubMed Central Open Access Subset (PMCOA). We also propose a novel attention-based encoder-dual-decoder (EDD) architecture that converts images of tables into HTML code. The model has a structure decoder which reconstructs the table structure and helps the cell decoder to recognize cell content. In addition, we propose a new Tree-Edit-Distance-based Similarity (TEDS) metric for table recognition. The experiments demonstrate that the EDD model can accurately recognize complex tables solely relying on the image representation, outperforming the state-of-the-art by 7.7% absolute TEDS score.
Distinguishing rule- and exemplar-based generalization in learning systems
Oct 08, 2021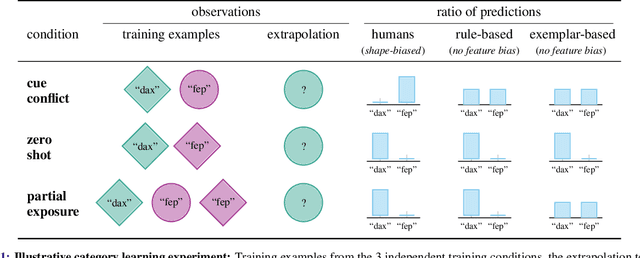
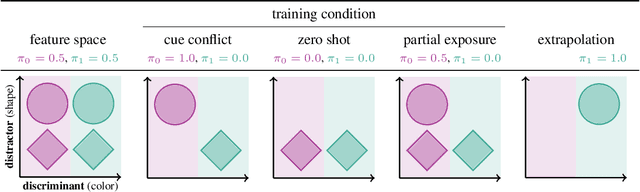
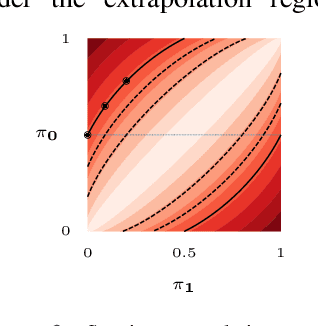
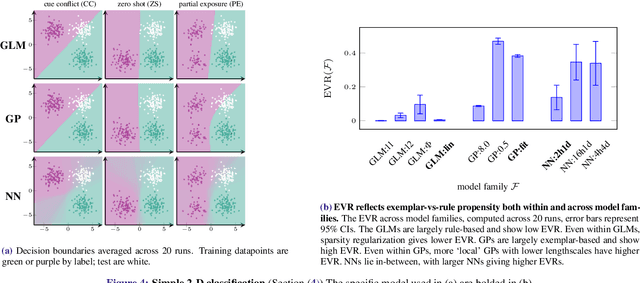
Despite the increasing scale of datasets in machine learning, generalization to unseen regions of the data distribution remains crucial. Such extrapolation is by definition underdetermined and is dictated by a learner's inductive biases. Machine learning systems often do not share the same inductive biases as humans and, as a result, extrapolate in ways that are inconsistent with our expectations. We investigate two distinct such inductive biases: feature-level bias (differences in which features are more readily learned) and exemplar-vs-rule bias (differences in how these learned features are used for generalization). Exemplar- vs. rule-based generalization has been studied extensively in cognitive psychology, and, in this work, we present a protocol inspired by these experimental approaches for directly probing this trade-off in learning systems. The measures we propose characterize changes in extrapolation behavior when feature coverage is manipulated in a combinatorial setting. We present empirical results across a range of models and across both expository and real-world image and language domains. We demonstrate that measuring the exemplar-rule trade-off while controlling for feature-level bias provides a more complete picture of extrapolation behavior than existing formalisms. We find that most standard neural network models have a propensity towards exemplar-based extrapolation and discuss the implications of these findings for research on data augmentation, fairness, and systematic generalization.
Combining Deep Learning with Geometric Features for Image based Localization in the Gastrointestinal Tract
May 13, 2020

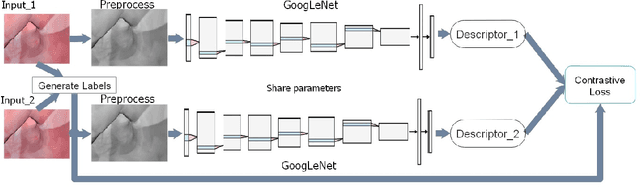
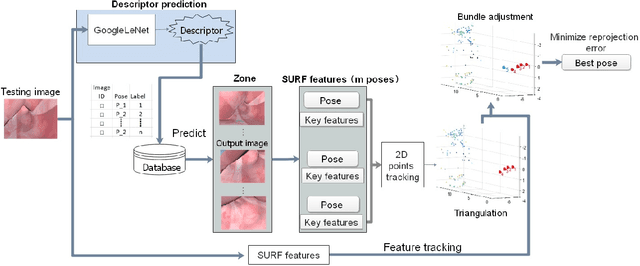
Tracking monocular colonoscope in the Gastrointestinal tract (GI) is a challenging problem as the images suffer from deformation, blurred textures, significant changes in appearance. They greatly restrict the tracking ability of conventional geometry based methods. Even though Deep Learning (DL) can overcome these issues, limited labeling data is a roadblock to state-of-art DL method. Considering these, we propose a novel approach to combine DL method with traditional feature based approach to achieve better localization with small training data. Our method fully exploits the best of both worlds by introducing a Siamese network structure to perform few-shot classification to the closest zone in the segmented training image set. The classified label is further adopted to initialize the pose of scope. To fully use the training dataset, a pre-generated triangulated map points within the zone in the training set are registered with observation and contribute to estimating the optimal pose of the test image. The proposed hybrid method is extensively tested and compared with existing methods, and the result shows significant improvement over traditional geometric based or DL based localization. The accuracy is improved by 28.94% (Position) and 10.97% (Orientation) with respect to state-of-art method.
Spectral Distribution Aware Image Generation
Dec 30, 2020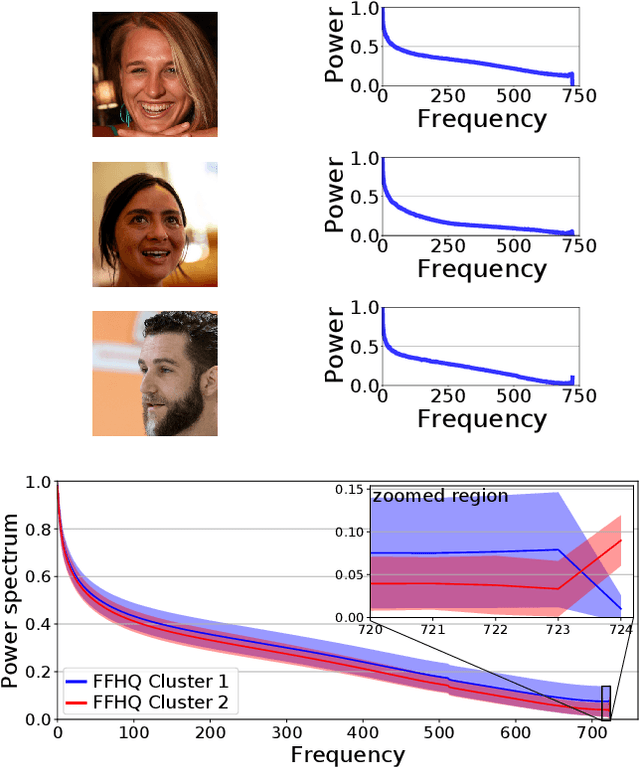
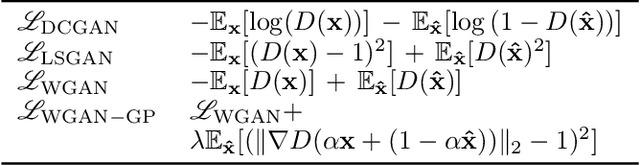
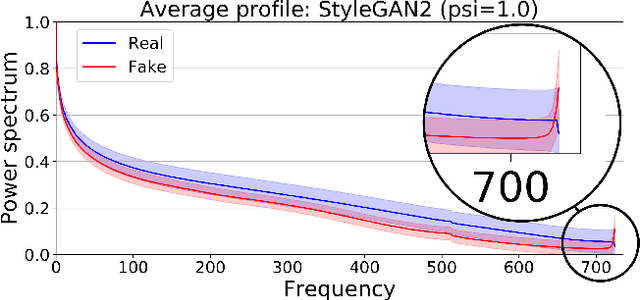
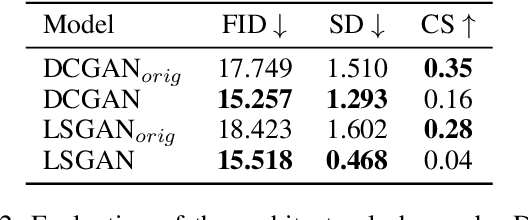
Recent advances in deep generative models for photo-realistic images have led to high quality visual results. Such models learn to generate data from a given training distribution such that generated images can not be easily distinguished from real images by the human eye. Yet, recent work on the detection of such fake images pointed out that they are actually easily distinguishable by artifacts in their frequency spectra. In this paper, we propose to generate images according to the frequency distribution of the real data by employing a spectral discriminator. The proposed discriminator is lightweight, modular and works stably with different commonly used GAN losses. We show that the resulting models can better generate images with realistic frequency spectra, which are thus harder to detect by this cue.