 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deterministic Guided LiDAR Depth Map Completion
Jun 14, 2021
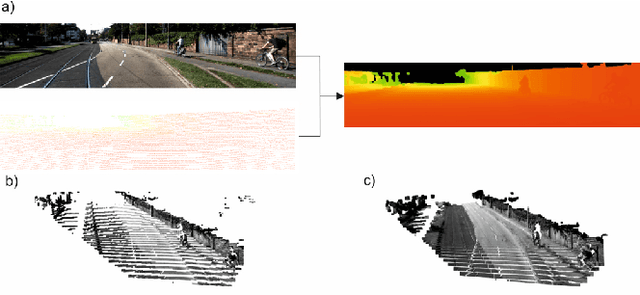

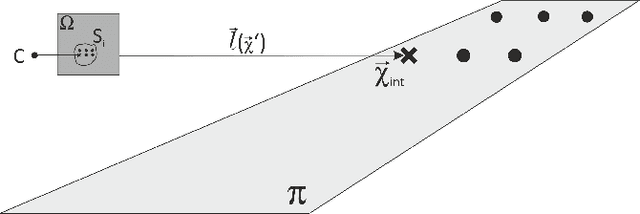
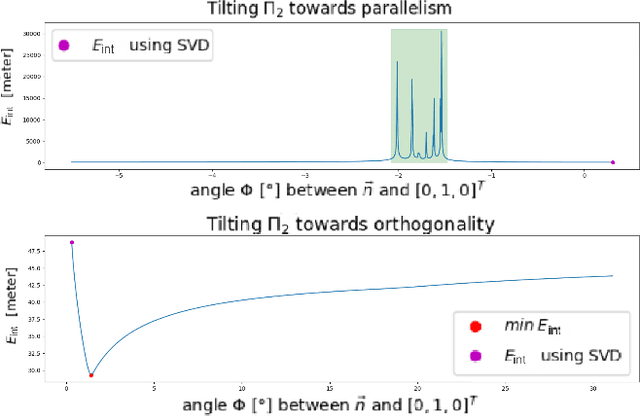
Accurate dense depth estimation is crucial for autonomous vehicles to analyze their environment. This paper presents a non-deep learning-based approach to densify a sparse LiDAR-based depth map using a guidance RGB image. To achieve this goal the RGB image is at first cleared from most of the camera-LiDAR misalignment artifacts. Afterward, it is over segmented and a plane for each superpixel is approximated. In the case a superpixel is not well represented by a plane, a plane is approximated for a convex hull of the most inlier. Finally, the pinhole camera model is used for the interpolation process and the remaining areas are interpolated. The evaluation of this work is executed using the KITTI depth completion benchmark, which validates the proposed work and shows that it outperforms the state-of-the-art non-deep learning-based methods, in addition to several deep learning-based methods.
CovXR: Automated Detection of COVID-19 Pneumonia in Chest X-Rays through Machine Learning
Oct 12, 2021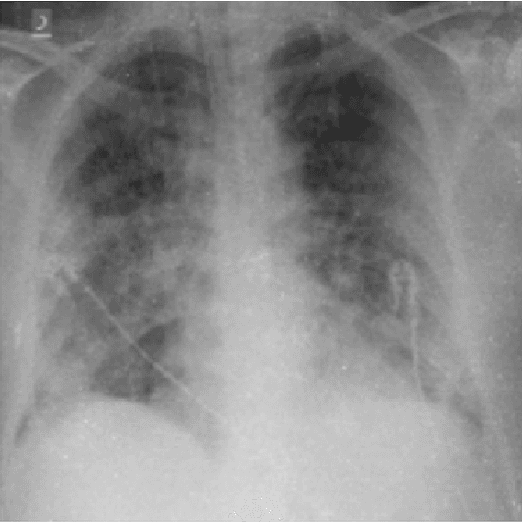
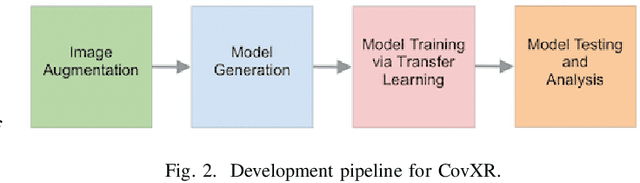
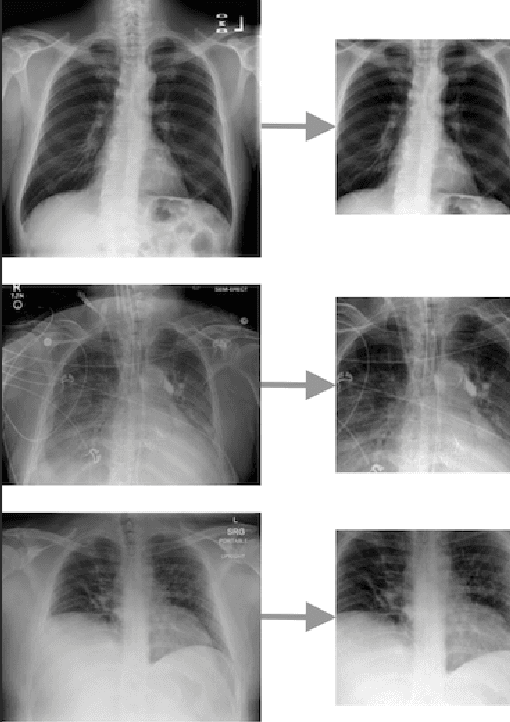
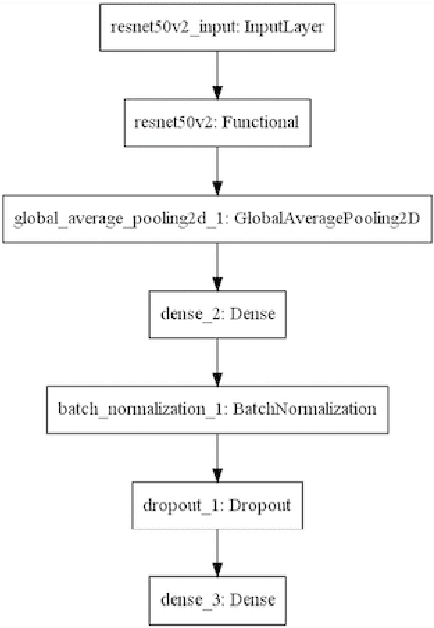
Coronavirus disease 2019 (COVID-19) is the highly contagious illness caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The standard diagnostic testing procedure for COVID-19 is testing a nasopharyngeal swab for SARS-CoV-2 nucleic acid using a real-time polymerase chain reaction (PCR), which can take multiple days to provide a diagnosis. Another widespread form of testing is rapid antigen testing, which has a low sensitivity compared to PCR, but is favored for its quick diagnosis time of usually 15-30 minutes. Patients who test positive for COVID-19 demonstrate diffuse alveolar damage in 87% of cases. Machine learning has proven to have advantages in image classification problems with radiology. In this work, we introduce CovXR as a machine learning model designed to detect COVID-19 pneumonia in chest X-rays (CXR). CovXR is a convolutional neural network (CNN) trained on over 4,300 chest X-rays. The performance of the model is measured through accuracy, F1 score, sensitivity, and specificity. The model achieves an accuracy of 95.5% and an F1 score of 0.954. The sensitivity is 93.5% and specificity is 97.5%. With accuracy above 95% and F1 score above 0.95, CovXR is highly accurate in predicting COVID-19 pneumonia on CXRs. The model achieves better accuracy than prior work and uses a unique approach to identify COVID-19 pneumonia. CovXR is highly accurate in identifying COVID-19 on CXRs of patients with a PCR confirmed positive diagnosis and provides much faster results than PCR tests.
Lunar surface image restoration using U-net based deep neural networks
Apr 14, 2019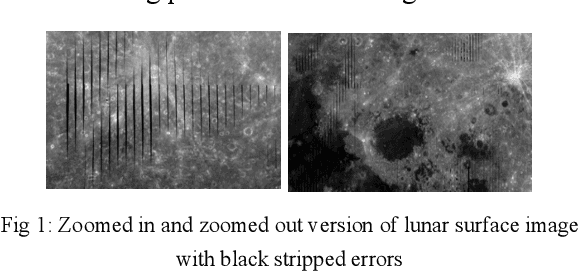
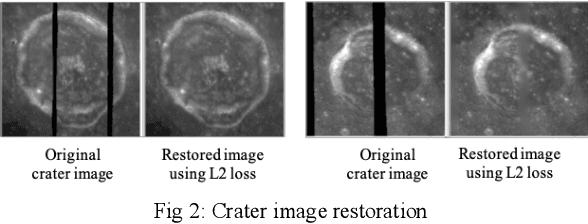
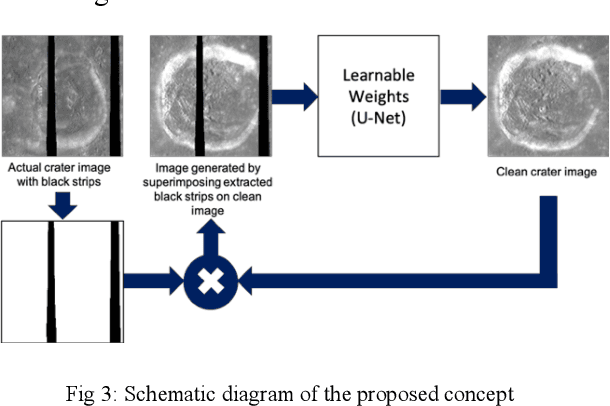
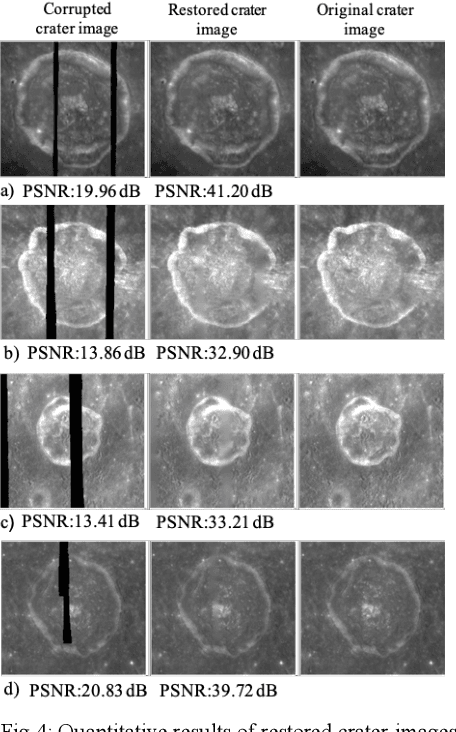
Image restoration is a technique that reconstructs a feasible estimate of the original image from the noisy observation. In this paper, we present a U-Net based deep neural network model to restore the missing pixels on the lunar surface image in a context-aware fashion, which is often known as image inpainting problem. We use the grayscale image of the lunar surface captured by Multiband Imager (MI) onboard Kaguya satellite for our experiments and the results show that our method can reconstruct the lunar surface image with good visual quality and improved PSNR values.
Unsupervised Medical Image Segmentation with Adversarial Networks: From Edge Diagrams to Segmentation Maps
Nov 12, 2019

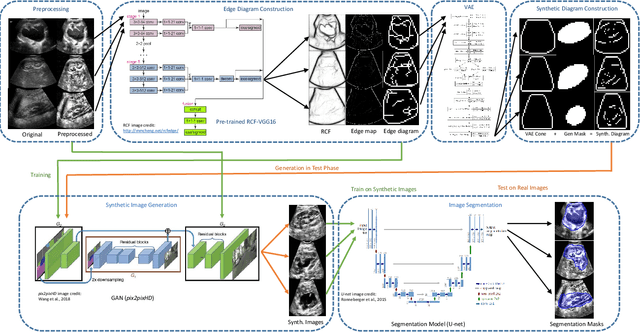
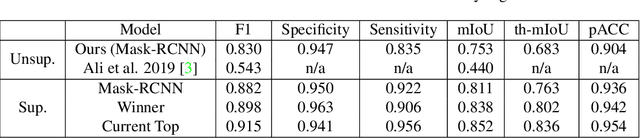
We develop and approach to unsupervised semantic medical image segmentation that extends previous work with generative adversarial networks. We use existing edge detection methods to construct simple edge diagrams, train a generative model to convert them into synthetic medical images, and construct a dataset of synthetic images with known segmentations using variations on extracted edge diagrams. This synthetic dataset is then used to train a supervised image segmentation model. We test our approach on a clinical dataset of kidney ultrasound images and the benchmark ISIC 2018 skin lesion dataset. We show that our unsupervised approach is more accurate than previous unsupervised methods, and performs reasonably compared to supervised image segmentation models. All code and trained models are available at https://github.com/kiretd/Unsupervised-MIseg.
Light Field Saliency Detection with Dual Local Graph Learning andReciprocative Guidance
Oct 02, 2021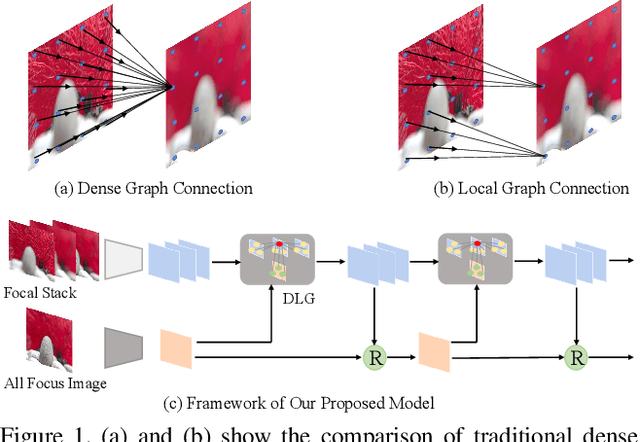
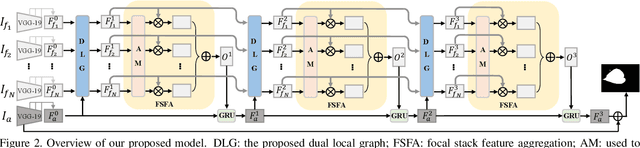
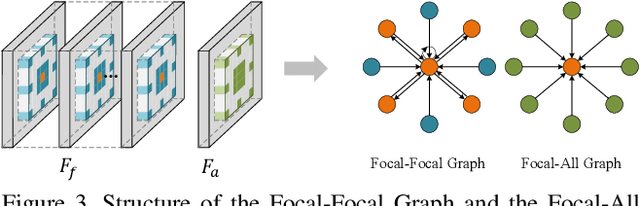
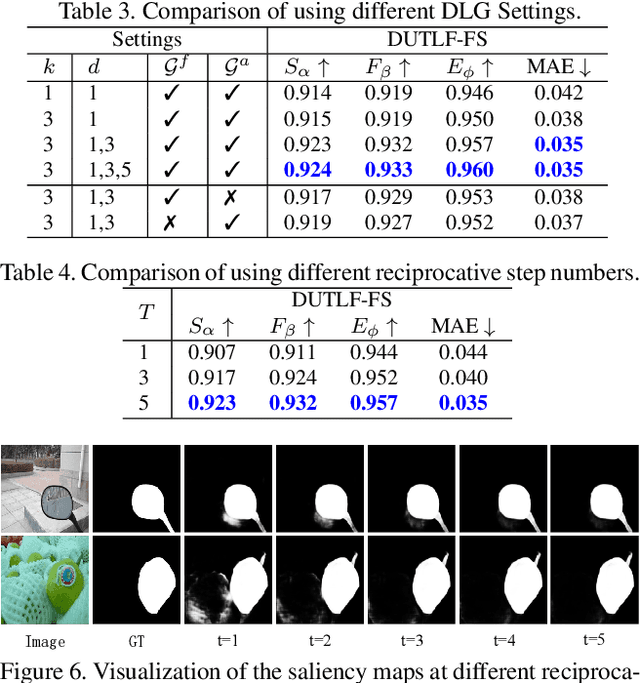
The application of light field data in salient object de-tection is becoming increasingly popular recently. The diffi-culty lies in how to effectively fuse the features within the fo-cal stack and how to cooperate them with the feature of theall-focus image. Previous methods usually fuse focal stackfeatures via convolution or ConvLSTM, which are both lesseffective and ill-posed. In this paper, we model the infor-mation fusion within focal stack via graph networks. Theyintroduce powerful context propagation from neighbouringnodes and also avoid ill-posed implementations. On the onehand, we construct local graph connections thus avoidingprohibitive computational costs of traditional graph net-works. On the other hand, instead of processing the twokinds of data separately, we build a novel dual graph modelto guide the focal stack fusion process using all-focus pat-terns. To handle the second difficulty, previous methods usu-ally implement one-shot fusion for focal stack and all-focusfeatures, hence lacking a thorough exploration of their sup-plements. We introduce a reciprocative guidance schemeand enable mutual guidance between these two kinds of in-formation at multiple steps. As such, both kinds of featurescan be enhanced iteratively, finally benefiting the saliencyprediction. Extensive experimental results show that theproposed models are all beneficial and we achieve signif-icantly better results than state-of-the-art methods.
simNet: Stepwise Image-Topic Merging Network for Generating Detailed and Comprehensive Image Captions
Aug 27, 2018
The encode-decoder framework has shown recent success in image captioning. Visual attention, which is good at detailedness, and semantic attention, which is good at comprehensiveness, have been separately proposed to ground the caption on the image. In this paper, we propose the Stepwise Image-Topic Merging Network (simNet) that makes use of the two kinds of attention at the same time. At each time step when generating the caption, the decoder adaptively merges the attentive information in the extracted topics and the image according to the generated context, so that the visual information and the semantic information can be effectively combined. The proposed approach is evaluated on two benchmark datasets and reaches the state-of-the-art performances.(The code is available at https://github.com/lancopku/simNet)
Speckles-Training-Based Denoising Convolutional Neural Network Ghost Imaging
Apr 07, 2021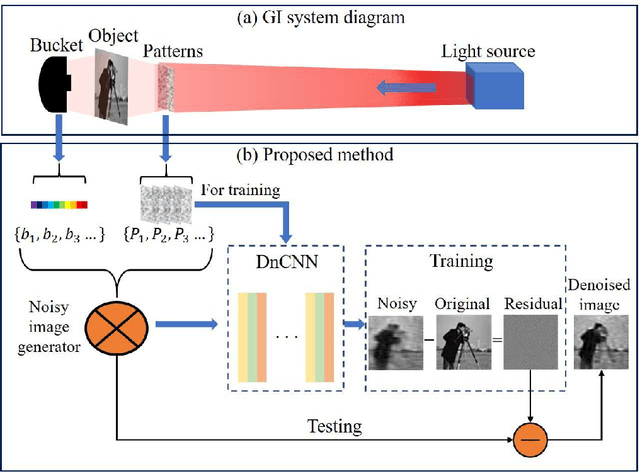

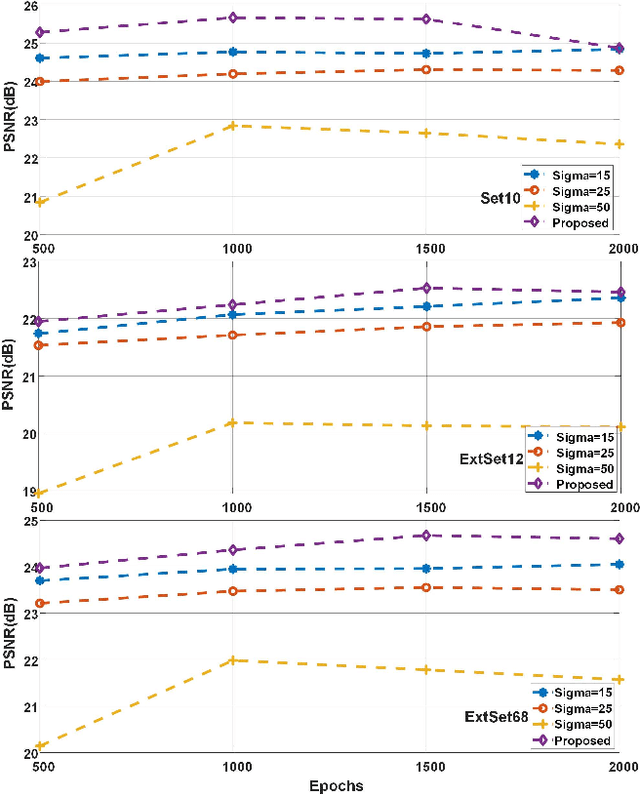
Ghost imaging (GI) has been paid attention gradually because of its lens-less imaging capability, turbulence-free imaging and high detection sensitivity. However, low image quality and slow imaging speed restrict the application process of GI. In this paper, we propose a improved GI method based on Denoising Convolutional Neural Networks (DnCNN). Inspired by the corresponding between input (noisy image) and output (residual image) in DnCNN, we construct the mapping between speckles sequence and the corresponding noise distribution in GI through training. Then, the same speckles sequence is employed to illuminate unknown targets, and a de-noising target image will be obtained. The proposed method can be regarded as a general method for GI. Under two sampling rates, extensive experiments are carried out to compare with traditional GI method (basic correlation and compressed sensing) and DnCNN method on three data sets. Moreover, we set up a physical GI experiment system to verify the proposed method. The results show that the proposed method achieves promising performance.
Continuous Conditional Random Field Convolution for Point Cloud Segmentation
Oct 12, 2021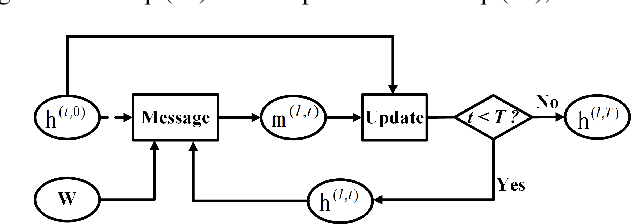
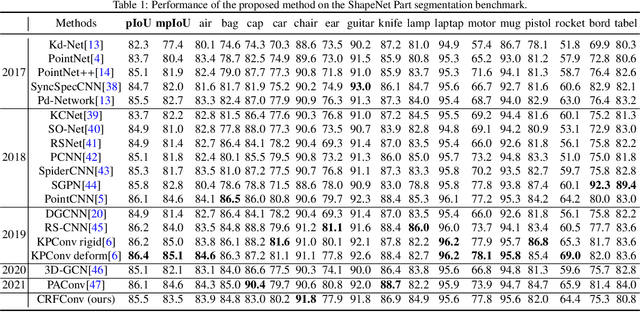
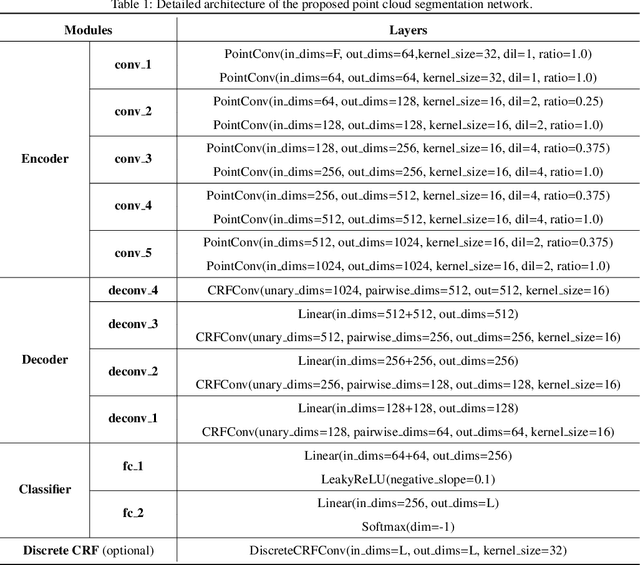

Point cloud segmentation is the foundation of 3D environmental perception for modern intelligent systems. To solve this problem and image segmentation, conditional random fields (CRFs) are usually formulated as discrete models in label space to encourage label consistency, which is actually a kind of postprocessing. In this paper, we reconsider the CRF in feature space for point cloud segmentation because it can capture the structure of features well to improve the representation ability of features rather than simply smoothing. Therefore, we first model the point cloud features with a continuous quadratic energy model and formulate its solution process as a message-passing graph convolution, by which it can be easily integrated into a deep network. We theoretically demonstrate that the message passing in the graph convolution is equivalent to the mean-field approximation of a continuous CRF model. Furthermore, we build an encoder-decoder network based on the proposed continuous CRF graph convolution (CRFConv), in which the CRFConv embedded in the decoding layers can restore the details of high-level features that were lost in the encoding stage to enhance the location ability of the network, thereby benefiting segmentation. Analogous to the CRFConv, we show that the classical discrete CRF can also work collaboratively with the proposed network via another graph convolution to further improve the segmentation results. Experiments on various point cloud benchmarks demonstrate the effectiveness and robustness of the proposed method. Compared with the state-of-the-art methods, the proposed method can also achieve competitive segmentation performance.
* 20 pages + 8 pages (supplemental material)
Multimodal Self-Supervised Learning for Medical Image Analysis
Dec 11, 2019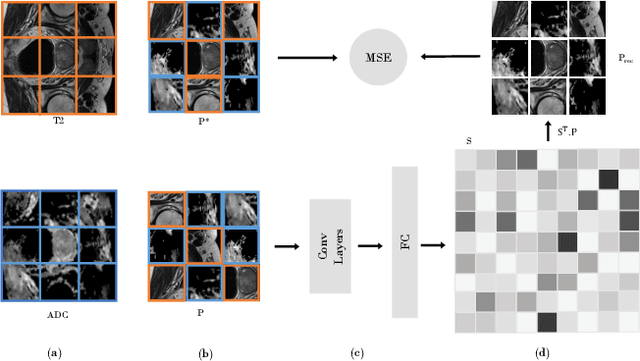
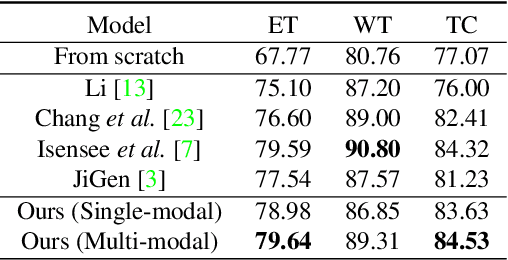
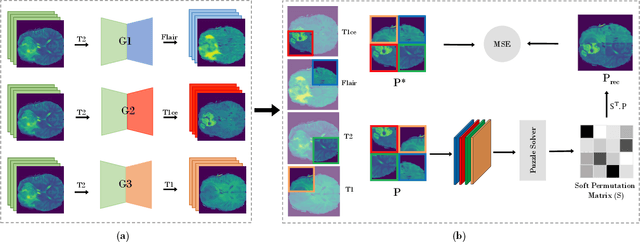
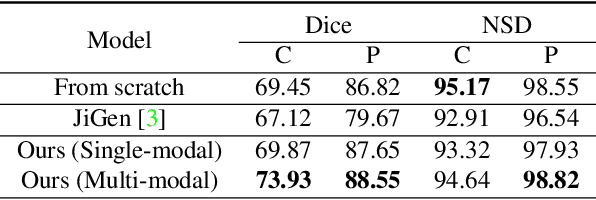
In this paper, we propose a self-supervised learning approach that leverages multiple imaging modalities to increase data efficiency for medical image analysis. To this end, we introduce multimodal puzzle-solving proxy tasks, which facilitate neural network representation learning from multiple image modalities. These representations allow for subsequent fine-tuning on different downstream tasks. To achieve that, we employ the Sinkhorn operator to predict permutations of puzzle pieces in conjunction with a modality agnostic feature embedding. Together, they allow for a lean network architecture and increased computational efficiency. Under this framework, we propose different strategies for puzzle construction, integrating multiple medical imaging modalities, with varying levels of puzzle complexity. We benchmark these strategies in a range of experiments to assess the gains of our method in downstream performance and data-efficiency on different target tasks. Our experiments show that solving puzzles interleaved with multimodal content yields more powerful semantic representations. This allows us to solve downstream tasks more accurately and efficiently, compared to treating each modality independently. We demonstrate the effectiveness of the proposed approach on two multimodal medical imaging benchmarks: the BraTS and the Prostate semantic segmentation datasets, on which we achieve competitive results to state-of-the-art solutions, at a fraction of the computational expense. We also outperform many previous solutions on the chosen benchmarks.
OpenDenoising: an Extensible Benchmark for Building Comparative Studies of Image Denoisers
Oct 18, 2019
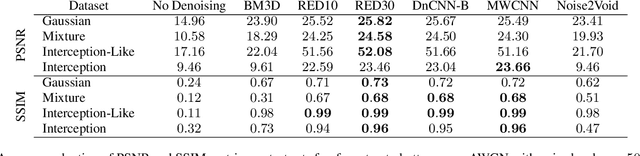
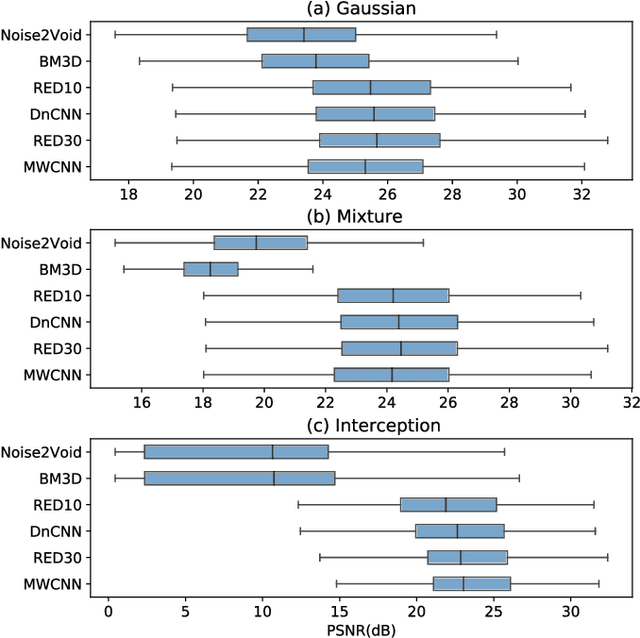

Image denoising has recently taken a leap forward due to machine learning. However, image denoisers, both expert-based and learning-based, are mostly tested on well-behaved generated noises (usually Gaussian) rather than on real-life noises, making performance comparisons difficult in real-world conditions. This is especially true for learning-based denoisers which performance depends on training data. Hence, choosing which method to use for a specific denoising problem is difficult. This paper proposes a comparative study of existing denoisers, as well as an extensible open tool that makes it possible to reproduce and extend the study. MWCNN is shown to outperform other methods when trained for a real-world image interception noise, and additionally is the second least compute hungry of the tested methods. To evaluate the robustness of conclusions, three test sets are compared. A Kendall's Tau correlation of only 60% is obtained on methods ranking between noise types, demonstrating the need for a benchmarking tool.