 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Decomposing Convolutional Neural Networks into Reusable and Replaceable Modules
Oct 11, 2021
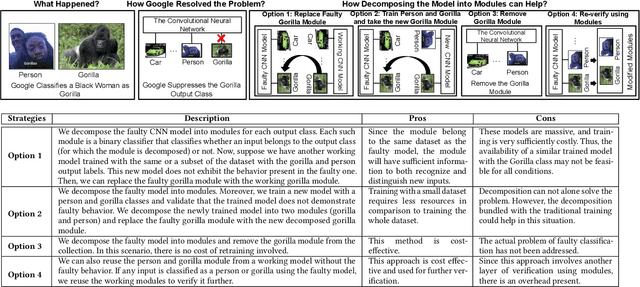
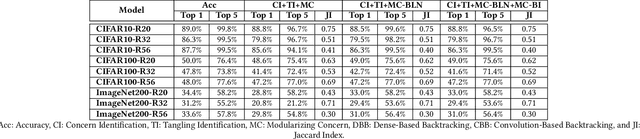
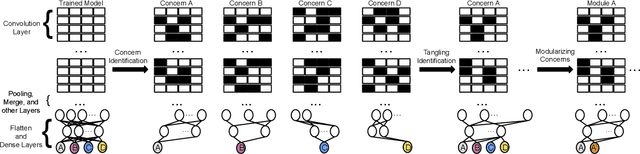
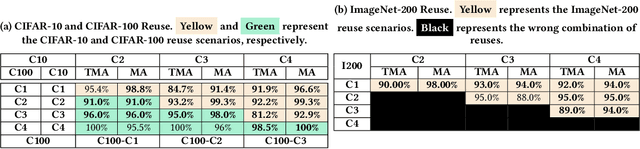
Training from scratch is the most common way to build a Convolutional Neural Network (CNN) based model. What if we can build new CNN models by reusing parts from previously build CNN models? What if we can improve a CNN model by replacing (possibly faulty) parts with other parts? In both cases, instead of training, can we identify the part responsible for each output class (module) in the model(s) and reuse or replace only the desired output classes to build a model? Prior work has proposed decomposing dense-based networks into modules (one for each output class) to enable reusability and replaceability in various scenarios. However, this work is limited to the dense layers and based on the one-to-one relationship between the nodes in consecutive layers. Due to the shared architecture in the CNN model, prior work cannot be adapted directly. In this paper, we propose to decompose a CNN model used for image classification problems into modules for each output class. These modules can further be reused or replaced to build a new model. We have evaluated our approach with CIFAR-10, CIFAR-100, and ImageNet tiny datasets with three variations of ResNet models and found that enabling decomposition comes with a small cost (2.38% and 0.81% for top-1 and top-5 accuracy, respectively). Also, building a model by reusing or replacing modules can be done with a 2.3% and 0.5% average loss of accuracy. Furthermore, reusing and replacing these modules reduces CO2e emission by ~37 times compared to training the model from scratch.
Robust Training Using Natural Transformation
May 10, 2021
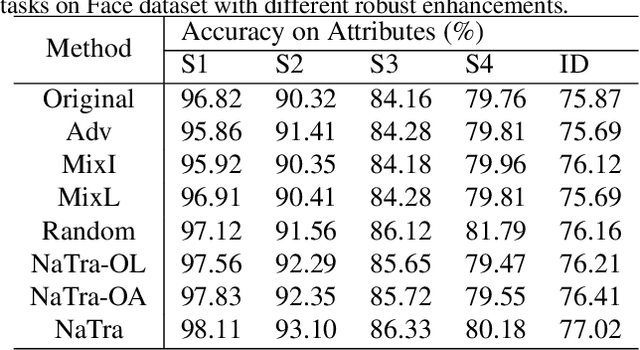

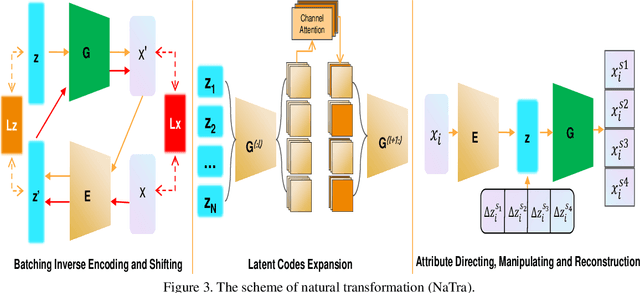
Previous robustness approaches for deep learning models such as data augmentation techniques via data transformation or adversarial training cannot capture real-world variations that preserve the semantics of the input, such as a change in lighting conditions. To bridge this gap, we present NaTra, an adversarial training scheme that is designed to improve the robustness of image classification algorithms. We target attributes of the input images that are independent of the class identification, and manipulate those attributes to mimic real-world natural transformations (NaTra) of the inputs, which are then used to augment the training dataset of the image classifier. Specifically, we apply \textit{Batch Inverse Encoding and Shifting} to map a batch of given images to corresponding disentangled latent codes of well-trained generative models. \textit{Latent Codes Expansion} is used to boost image reconstruction quality through the incorporation of extended feature maps. \textit{Unsupervised Attribute Directing and Manipulation} enables identification of the latent directions that correspond to specific attribute changes, and then produce interpretable manipulations of those attributes, thereby generating natural transformations to the input data. We demonstrate the efficacy of our scheme by utilizing the disentangled latent representations derived from well-trained GANs to mimic transformations of an image that are similar to real-world natural variations (such as lighting conditions or hairstyle), and train models to be invariant to these natural transformations. Extensive experiments show that our method improves generalization of classification models and increases its robustness to various real-world distortions
Contrastive Proposal Extension with LSTM Network for Weakly Supervised Object Detection
Oct 16, 2021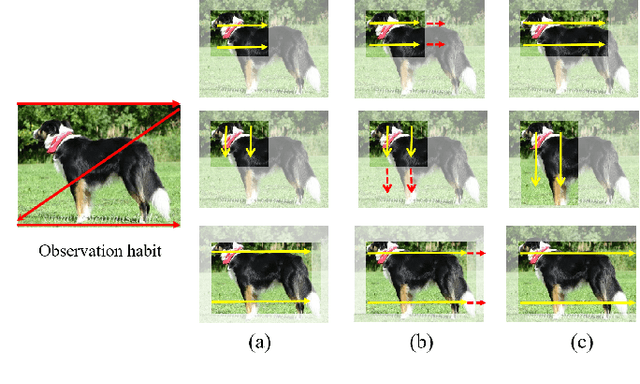

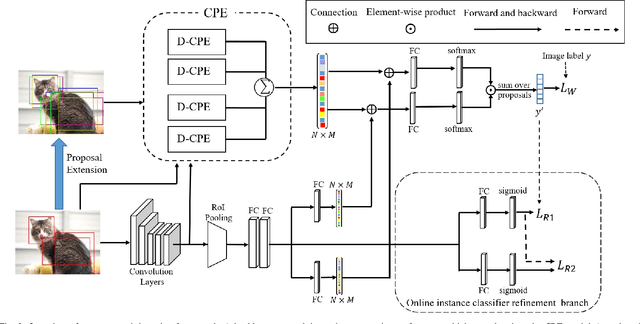
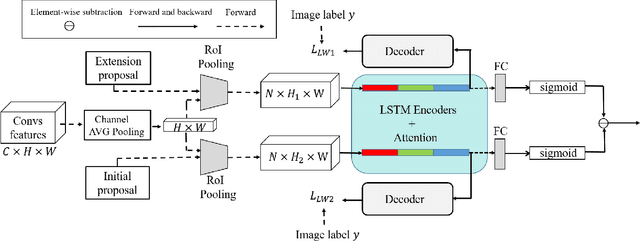
Weakly supervised object detection (WSOD) has attracted more and more attention since it only uses image-level labels and can save huge annotation costs. Most of the WSOD methods use Multiple Instance Learning (MIL) as their basic framework, which regard it as an instance classification problem. However, these methods based on MIL tends to converge only on the most discriminate regions of different instances, rather than their corresponding complete regions, that is, insufficient integrity. Inspired by the habit of observing things by the human, we propose a new method by comparing the initial proposals and the extension ones to optimize those initial proposals. Specifically, we propose one new strategy for WSOD by involving contrastive proposal extension (CPE), which consists of multiple directional contrastive proposal extensions (D-CPE), and each D-CPE contains encoders based on LSTM network and corresponding decoders. Firstly, the boundary of initial proposals in MIL is extended to different positions according to well-designed sequential order. Then, CPE compares the extended proposal and the initial proposal by extracting the feature semantics of them using the encoders, and calculates the integrity of the initial proposal to optimize the score of the initial proposal. These contrastive contextual semantics will guide the basic WSOD to suppress bad proposals and improve the scores of good ones. In addition, a simple two-stream network is designed as the decoder to constrain the temporal coding of LSTM and improve the performance of WSOD further. Experiments on PASCAL VOC 2007, VOC 2012 and MS-COCO datasets show that our method has achieved the state-of-the-art results.
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Jun 18, 2021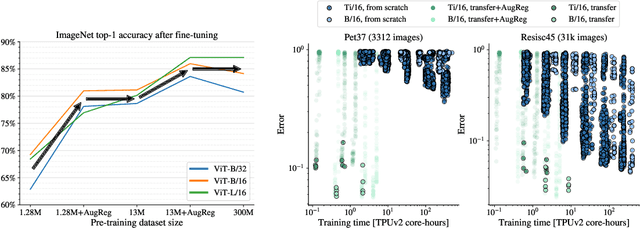
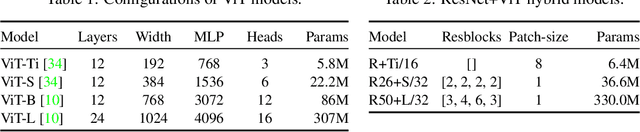
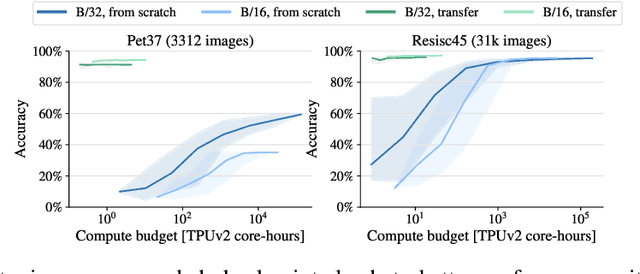
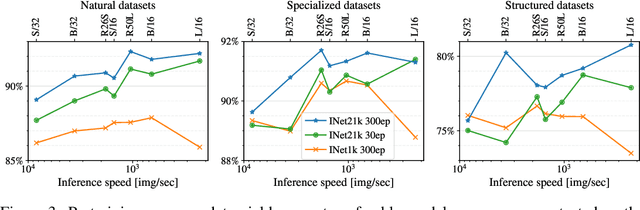
Vision Transformers (ViT) have been shown to attain highly competitive performance for a wide range of vision applications, such as image classification, object detection and semantic image segmentation. In comparison to convolutional neural networks, the Vision Transformer's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation (``AugReg'' for short) when training on smaller training datasets. We conduct a systematic empirical study in order to better understand the interplay between the amount of training data, AugReg, model size and compute budget. As one result of this study we find that the combination of increased compute and AugReg can yield models with the same performance as models trained on an order of magnitude more training data: we train ViT models of various sizes on the public ImageNet-21k dataset which either match or outperform their counterparts trained on the larger, but not publicly available JFT-300M dataset.
Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
Apr 02, 2020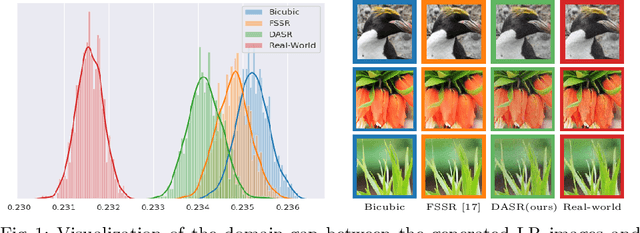
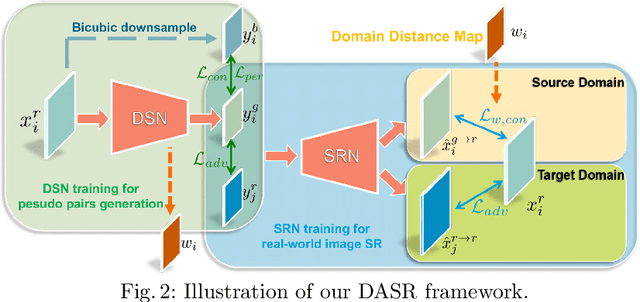
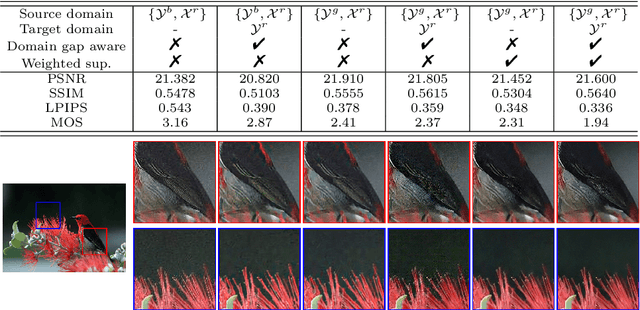
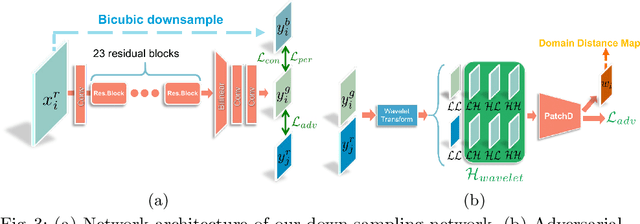
These days, unsupervised super-resolution (SR) has been soaring due to its practical and promising potential in real scenarios. The philosophy of off-the-shelf approaches lies in the augmentation of unpaired data, i.e. first generating synthetic low-resolution (LR) images $\mathcal{Y}^g$ corresponding to real-world high-resolution (HR) images $\mathcal{X}^r$ in the real-world LR domain $\mathcal{Y}^r$, and then utilizing the pseudo pairs $\{\mathcal{Y}^g, \mathcal{X}^r\}$ for training in a supervised manner. Unfortunately, since image translation itself is an extremely challenging task, the SR performance of these approaches are severely limited by the domain gap between generated synthetic LR images and real LR images. In this paper, we propose a novel domain-distance aware super-resolution (DASR) approach for unsupervised real-world image SR. The domain gap between training data (e.g. $\mathcal{Y}^g$) and testing data (e.g. $\mathcal{Y}^r$) is addressed with our \textbf{domain-gap aware training} and \textbf{domain-distance weighted supervision} strategies. Domain-gap aware training takes additional benefit from real data in the target domain while domain-distance weighted supervision brings forward the more rational use of labeled source domain data. The proposed method is validated on synthetic and real datasets and the experimental results show that DASR consistently outperforms state-of-the-art unsupervised SR approaches in generating SR outputs with more realistic and natural textures.
Deterministic Guided LiDAR Depth Map Completion
Jun 14, 2021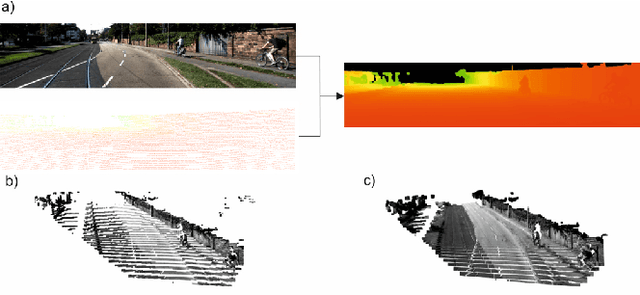

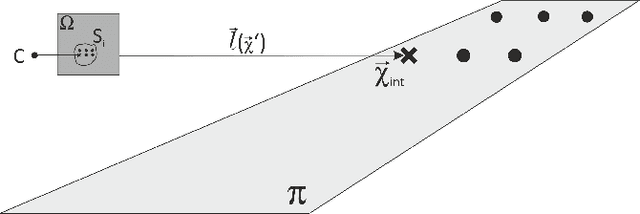
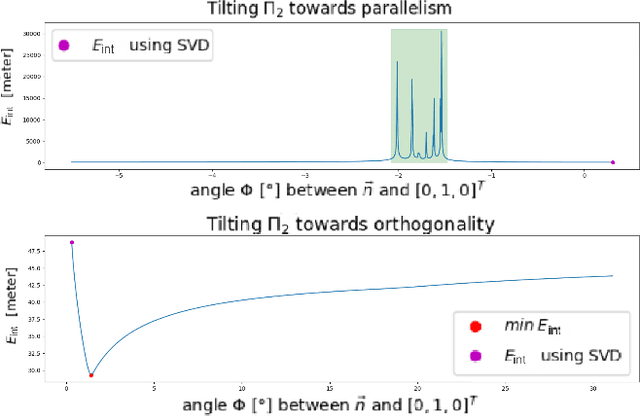
Accurate dense depth estimation is crucial for autonomous vehicles to analyze their environment. This paper presents a non-deep learning-based approach to densify a sparse LiDAR-based depth map using a guidance RGB image. To achieve this goal the RGB image is at first cleared from most of the camera-LiDAR misalignment artifacts. Afterward, it is over segmented and a plane for each superpixel is approximated. In the case a superpixel is not well represented by a plane, a plane is approximated for a convex hull of the most inlier. Finally, the pinhole camera model is used for the interpolation process and the remaining areas are interpolated. The evaluation of this work is executed using the KITTI depth completion benchmark, which validates the proposed work and shows that it outperforms the state-of-the-art non-deep learning-based methods, in addition to several deep learning-based methods.
Unsupervised Hyperspectral Mixed Noise Removal Via Spatial-Spectral Constrained Deep Image Prior
Aug 22, 2020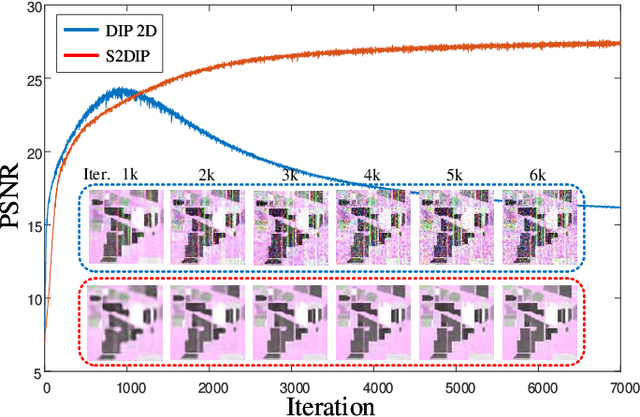

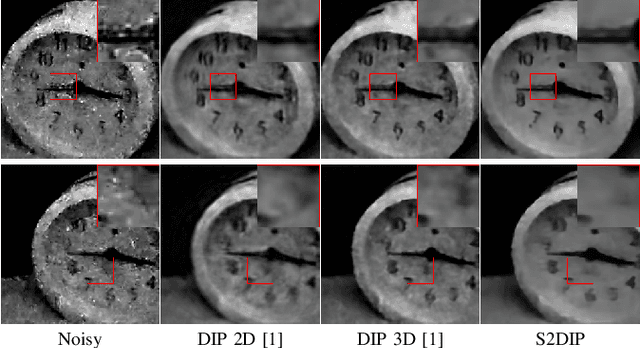
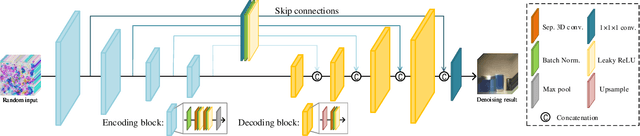
Hyperspectral images (HSIs) are unavoidably corrupted by mixed noise which hinders the subsequent applications. Traditional methods exploit the structure of the HSI via optimization-based models for denoising, while their capacity is inferior to the convolutional neural network (CNN)-based methods, which supervisedly learn the noisy-to-denoised mapping from a large amount of data. However, as the clean-noisy pairs of hyperspectral data are always unavailable in many applications, it is eager to build an unsupervised HSI denoising method with high model capability. To remove the mixed noise in HSIs, we suggest the spatial-spectral constrained deep image prior (S2DIP), which simultaneously capitalize the high model representation ability brought by the CNN in an unsupervised manner and does not need any extra training data. Specifically, we employ the separable 3D convolution blocks to faithfully encode the HSI in the framework of DIP, and a spatial-spectral total variation (SSTV) term is tailored to explore the spatial-spectral smoothness of HSIs. Moreover, our method favorably addresses the semi-convergence behavior of prevailing unsupervised methods, e.g., DIP 2D, and DIP 3D. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art optimization-based HSI denoising methods in terms of effectiveness and robustness.
Map-Guided Curriculum Domain Adaptation and Uncertainty-Aware Evaluation for Semantic Nighttime Image Segmentation
May 28, 2020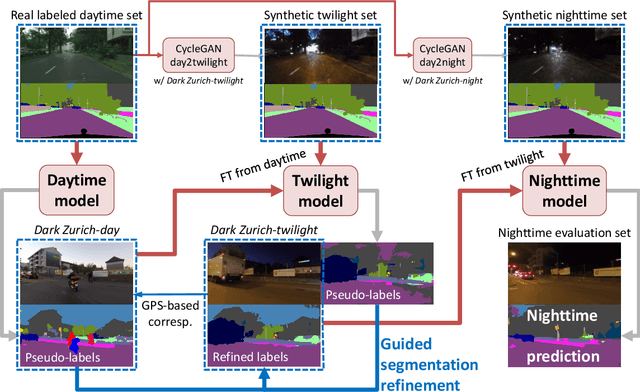
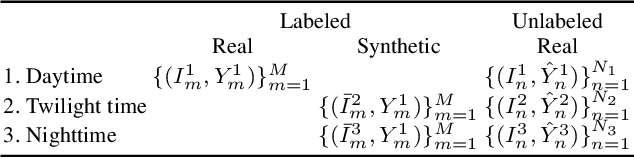

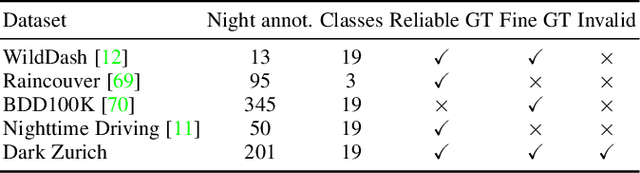
We address the problem of semantic nighttime image segmentation and improve the state-of-the-art, by adapting daytime models to nighttime without using nighttime annotations. Moreover, we design a new evaluation framework to address the substantial uncertainty of semantics in nighttime images. Our central contributions are: 1) a curriculum framework to gradually adapt semantic segmentation models from day to night through progressively darker times of day, exploiting cross-time-of-day correspondences between daytime images from a reference map and dark images to guide the label inference in the dark domains; 2) a novel uncertainty-aware annotation and evaluation framework and metric for semantic segmentation, including image regions beyond human recognition capability in the evaluation in a principled fashion; 3) the Dark Zurich dataset, comprising 2416 unlabeled nighttime and 2920 unlabeled twilight images with correspondences to their daytime counterparts plus a set of 201 nighttime images with fine pixel-level annotations created with our protocol, which serves as a first benchmark for our novel evaluation. Experiments show that our map-guided curriculum adaptation significantly outperforms state-of-the-art methods on nighttime sets both for standard metrics and our uncertainty-aware metric. Furthermore, our uncertainty-aware evaluation reveals that selective invalidation of predictions can improve results on data with ambiguous content such as our benchmark and profit safety-oriented applications involving invalid inputs.
Unsupervised Image Translation using Adversarial Networks for Improved Plant Disease Recognition
Sep 26, 2019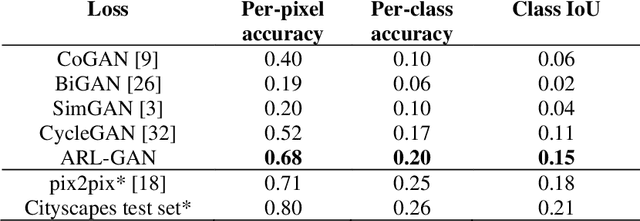
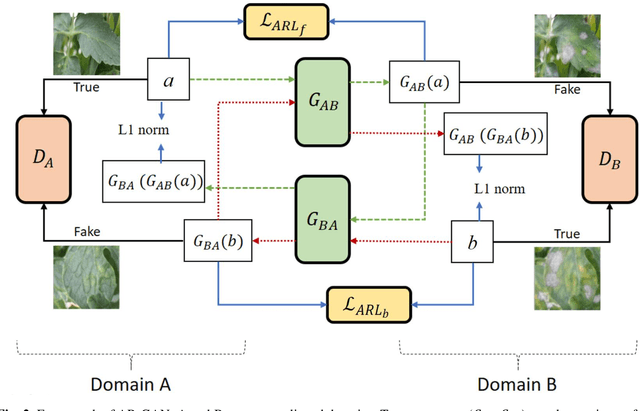
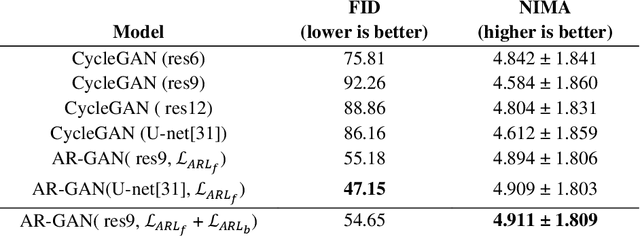

Acquisition of data in task-specific applications of machine learning like plant disease recognition is a costly endeavor owing to the requirements of professional human diligence and time constraints. In this paper, we present a simple pipeline that uses GANs in an unsupervised image translation environment to improve learning with respect to the data distribution in a plant disease dataset, reducing the partiality introduced by acute class imbalance and hence shifting the classification decision boundary towards better performance. The empirical analysis of our method is demonstrated on a limited dataset of 2789 tomato plant disease images, highly corrupted with an imbalance in the 9 disease categories. First, we extend the state of the art for the GAN-based image-to-image translation method by enhancing the perceptual quality of the generated images and preserving the semantics. We introduce AR-GAN, where in addition to the adversarial loss, our synthetic image generator optimizes on Activation Reconstruction loss (ARL) function that optimizes feature activations against the natural image. We present visually more compelling synthetic images in comparison to most prominent existing models and evaluate the performance of our GAN framework in terms of various datasets and metrics. Second, we evaluate the performance of a baseline convolutional neural network classifier for improved recognition using the resulting synthetic samples to augment our training set and compare it with the classical data augmentation scheme. We observe a significant improvement in classification accuracy (+5.2%) using generated synthetic samples as compared to (+0.8%) increase using classic augmentation in an equal class distribution environment.
Aerial Scene Understanding in The Wild: Multi-Scene Recognition via Prototype-based Memory Networks
Apr 22, 2021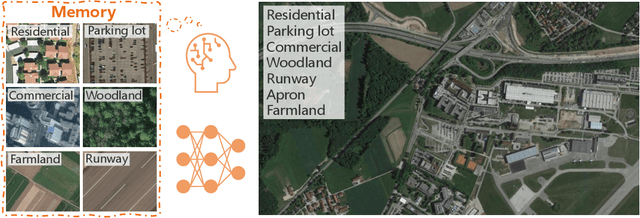
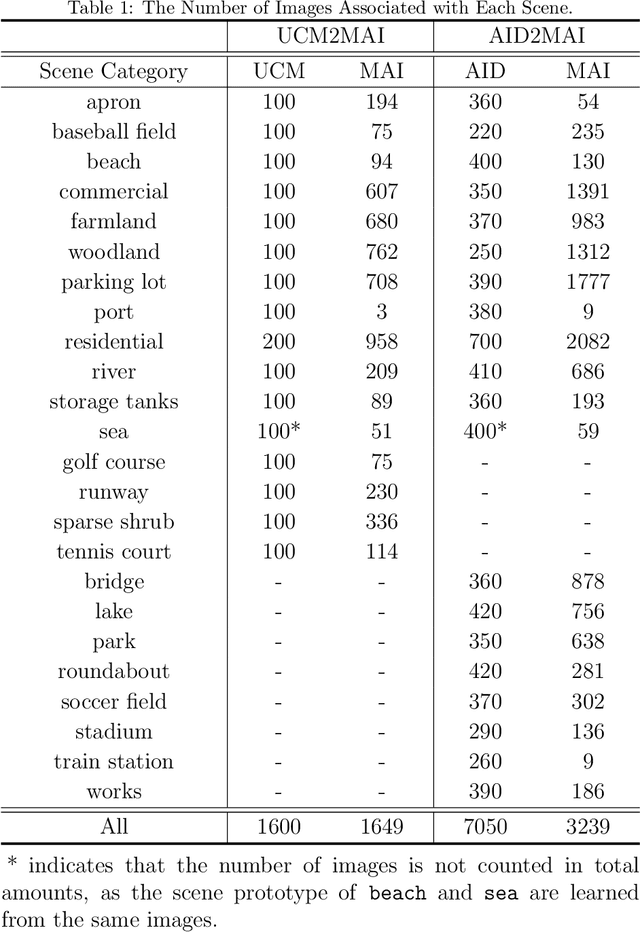

Aerial scene recognition is a fundamental visual task and has attracted an increasing research interest in the last few years. Most of current researches mainly deploy efforts to categorize an aerial image into one scene-level label, while in real-world scenarios, there often exist multiple scenes in a single image. Therefore, in this paper, we propose to take a step forward to a more practical and challenging task, namely multi-scene recognition in single images. Moreover, we note that manually yielding annotations for such a task is extraordinarily time- and labor-consuming. To address this, we propose a prototype-based memory network to recognize multiple scenes in a single image by leveraging massive well-annotated single-scene images. The proposed network consists of three key components: 1) a prototype learning module, 2) a prototype-inhabiting external memory, and 3) a multi-head attention-based memory retrieval module. To be more specific, we first learn the prototype representation of each aerial scene from single-scene aerial image datasets and store it in an external memory. Afterwards, a multi-head attention-based memory retrieval module is devised to retrieve scene prototypes relevant to query multi-scene images for final predictions. Notably, only a limited number of annotated multi-scene images are needed in the training phase. To facilitate the progress of aerial scene recognition, we produce a new multi-scene aerial image (MAI) dataset. Experimental results on variant dataset configurations demonstrate the effectiveness of our network. Our dataset and codes are publicly available.