 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hand Hygiene Video Classification Based on Deep Learning
Aug 18, 2021
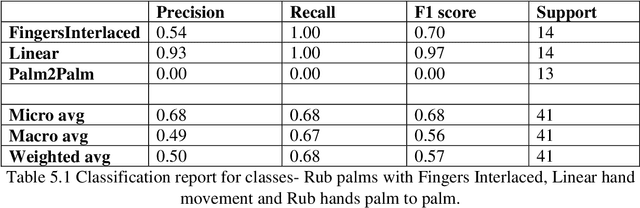
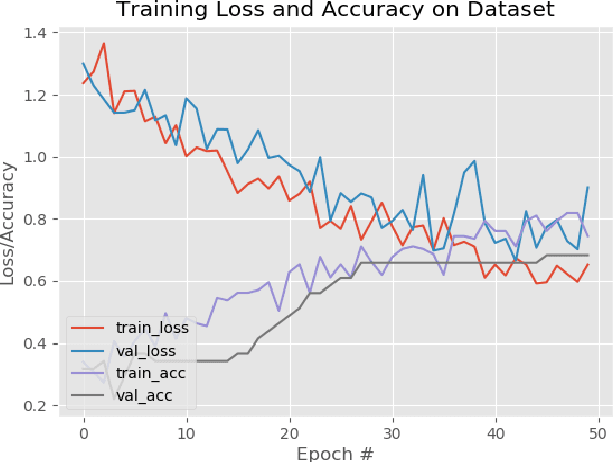


In this work, an extensive review of literature in the field of gesture recognition carried out along with the implementation of a simple classification system for hand hygiene stages based on deep learning solutions. A subset of robust dataset that consist of handwashing gestures with two hands as well as one-hand gestures such as linear hand movement utilized. A pretrained neural network model, RES Net 50, with image net weights used for the classification of 3 categories: Linear hand movement, rub hands palm to palm and rub hands with fingers interlaced movement. Correct predictions made for the first two classes with > 60% accuracy. A complete dataset along with increased number of classes and training steps will be explored as a future work.
Learning Coded Apertures for Time-Division Multiplexing Light Field Display
Jul 13, 2021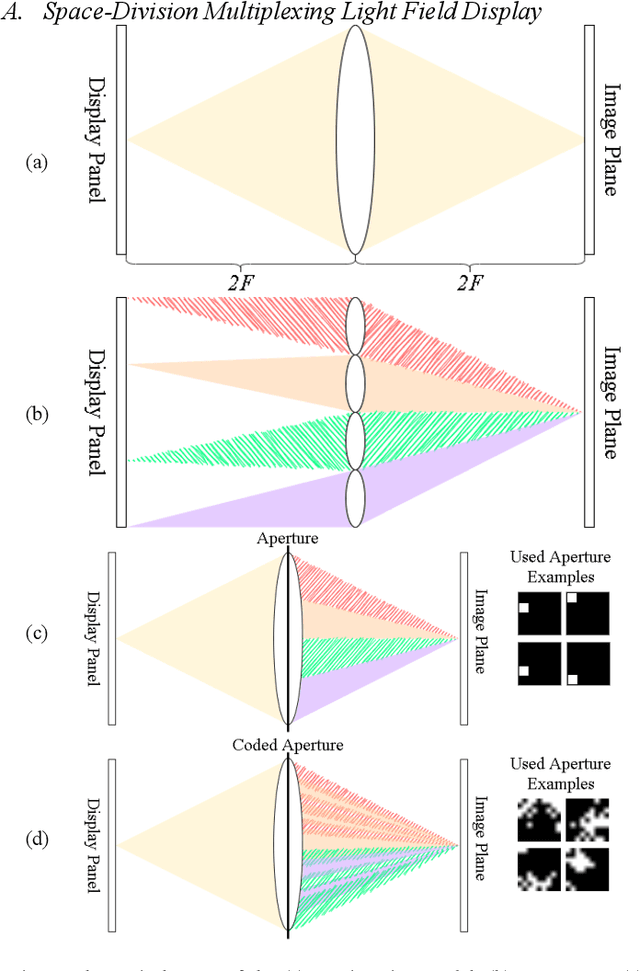



Conventional stereoscopic displays suffer from vergence-accommodation conflict which cause visual fatigue. Integral imaging-based (II) displays resolves this problem by directly projecting light field sub-views into the eye using microlens arrays. However, II-based light field displays has inherent trade-off between angular and spatial resolutions. In this paper, we propose a novel display concept called coded time-division light field display (C-TDM-LFD), which projects encoded light field sub-views to the viewers' eyes, offering correct cues for vergence-accommodation reflex. By jointly optimizing display inputs and pattern of coded apertures, our pipeline can render high resolution refocused images from sparse light field sub-views with minimal aliasing effects. By simulating light transport and image formation with Fourier optics, we can learn display inputs and coded aperture patterns via deep learning in an end-to-end fashion. To our knowledge, we are among the first to optimize the light field display pipeline with deep learning. We verify our concept with objective image quality metrics (PSNR, SSIM) and optics software simulation, and perform extensive studies on the various customizable design variables in our display pipeline. Experiments results show that our method can generate refocused images with higher quality both quantitatively and qualitatively compared to baseline display designs.
Semantic sentence similarity: size does not always matter
Jun 16, 2021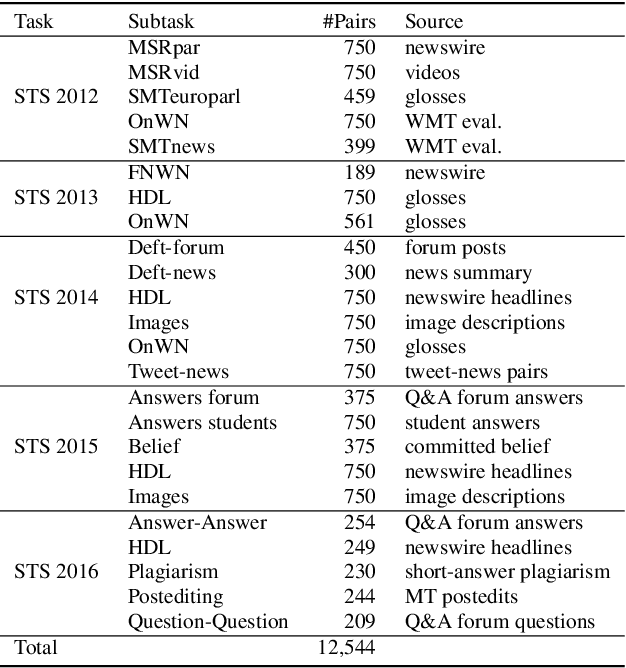
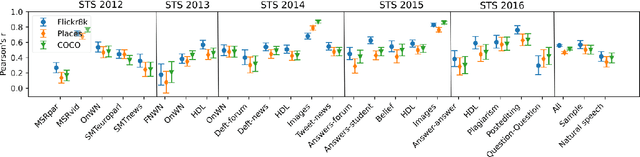
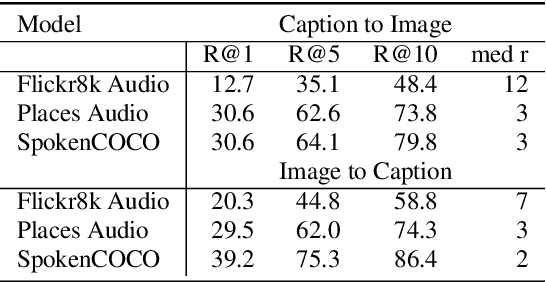
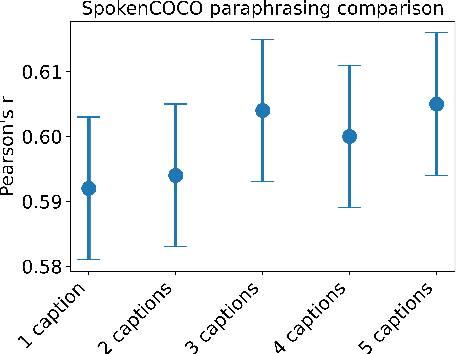
This study addresses the question whether visually grounded speech recognition (VGS) models learn to capture sentence semantics without access to any prior linguistic knowledge. We produce synthetic and natural spoken versions of a well known semantic textual similarity database and show that our VGS model produces embeddings that correlate well with human semantic similarity judgements. Our results show that a model trained on a small image-caption database outperforms two models trained on much larger databases, indicating that database size is not all that matters. We also investigate the importance of having multiple captions per image and find that this is indeed helpful even if the total number of images is lower, suggesting that paraphrasing is a valuable learning signal. While the general trend in the field is to create ever larger datasets to train models on, our findings indicate other characteristics of the database can just as important important.
Online Sensor Hallucination via Knowledge Distillation for Multimodal Image Classification
Aug 28, 2019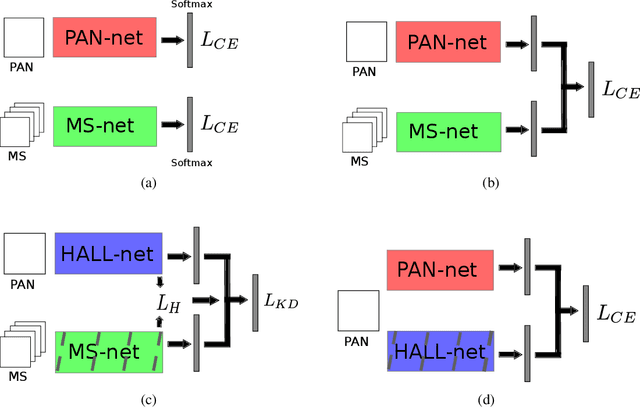
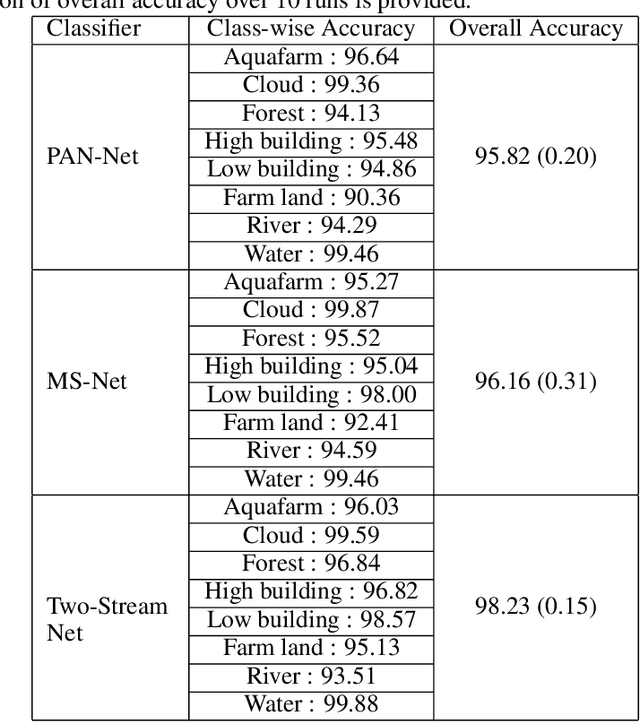
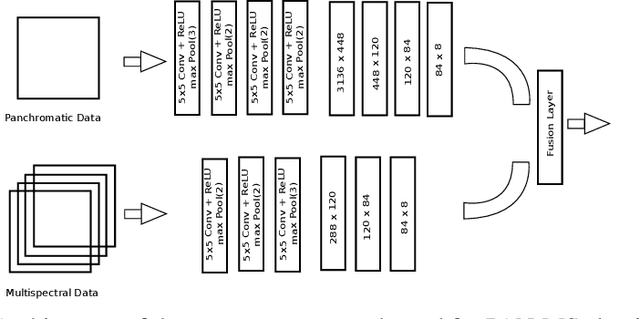
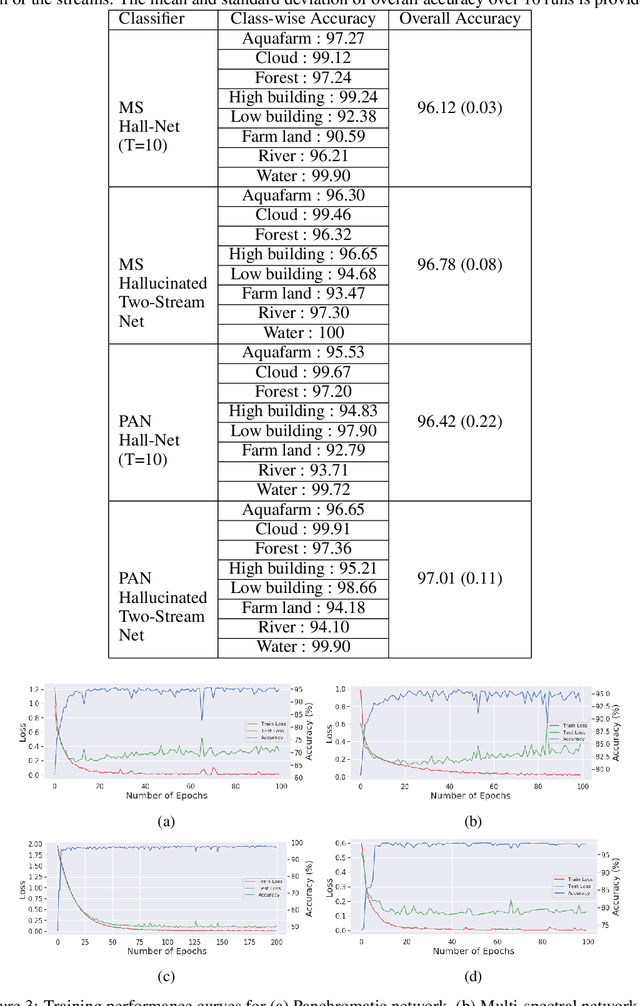
We deal with the problem of information fusion driven satellite image/scene classification and propose a generic hallucination architecture considering that all the available sensor information are present during training while some of the image modalities may be absent while testing. It is well-known that different sensors are capable of capturing complementary information for a given geographical area and a classification module incorporating information from all the sources are expected to produce an improved performance as compared to considering only a subset of the modalities. However, the classical classifier systems inherently require all the features used to train the module to be present for the test instances as well, which may not always be possible for typical remote sensing applications (say, disaster management). As a remedy, we provide a robust solution in terms of a hallucination module that can approximate the missing modalities from the available ones during the decision-making stage. In order to ensure better knowledge transfer during modality hallucination, we explicitly incorporate concepts of knowledge distillation for the purpose of exploring the privileged (side) information in our framework and subsequently introduce an intuitive modular training approach. The proposed network is evaluated extensively on a large-scale corpus of PAN-MS image pairs (scene recognition) as well as on a benchmark hyperspectral image dataset (image classification) where we follow different experimental scenarios and find that the proposed hallucination based module indeed is capable of capturing the multi-source information, albeit the explicit absence of some of the sensor information, and aid in improved scene characterization.
Confident Coreset for Active Learning in Medical Image Analysis
Apr 05, 2020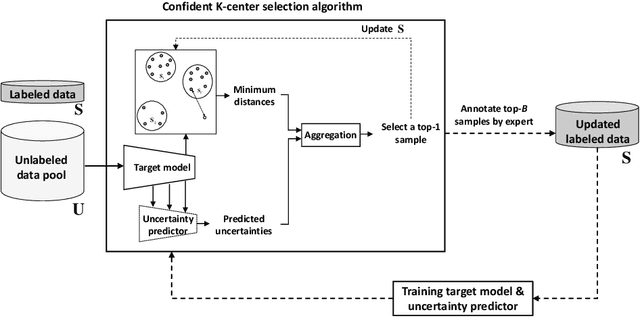
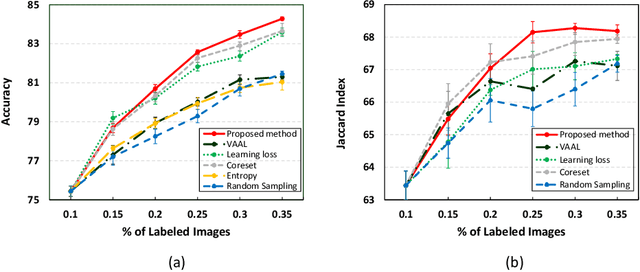
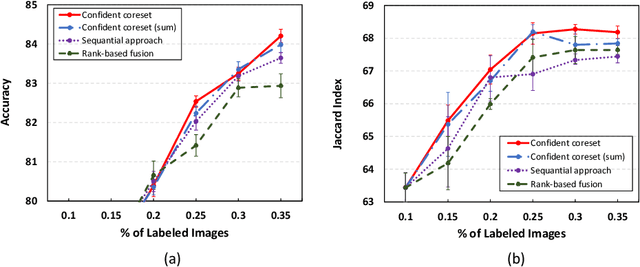
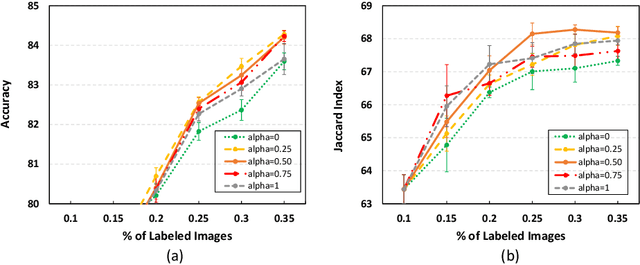
Recent advances in deep learning have resulted in great successes in various applications. Although semi-supervised or unsupervised learning methods have been widely investigated, the performance of deep neural networks highly depends on the annotated data. The problem is that the budget for annotation is usually limited due to the annotation time and expensive annotation cost in medical data. Active learning is one of the solutions to this problem where an active learner is designed to indicate which samples need to be annotated to effectively train a target model. In this paper, we propose a novel active learning method, confident coreset, which considers both uncertainty and distribution for effectively selecting informative samples. By comparative experiments on two medical image analysis tasks, we show that our method outperforms other active learning methods.
Differential Diagnosis of Frontotemporal Dementia and Alzheimer's Disease using Generative Adversarial Network
Sep 12, 2021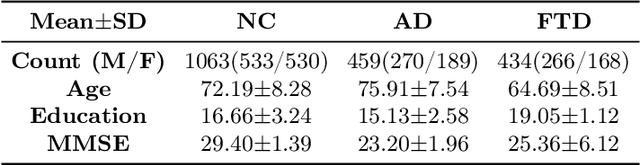
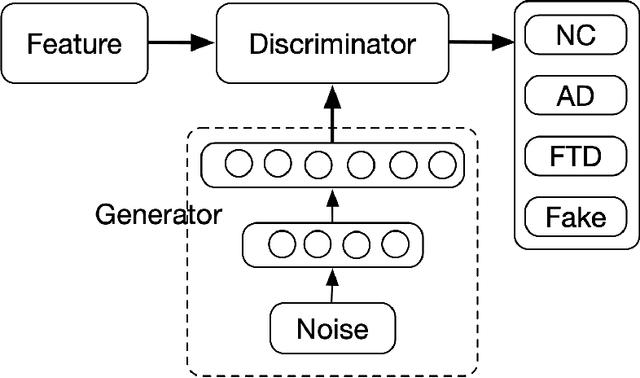
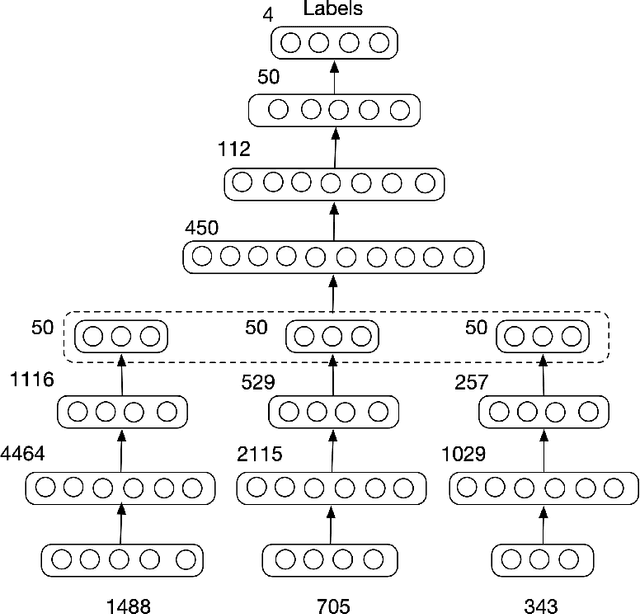
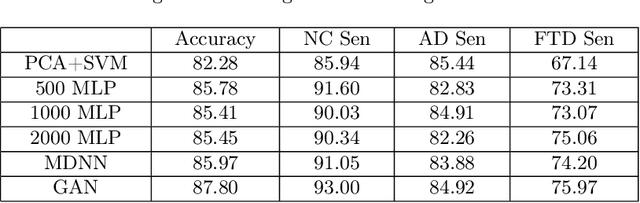
Frontotemporal dementia and Alzheimer's disease are two common forms of dementia and are easily misdiagnosed as each other due to their similar pattern of clinical symptoms. Differentiating between the two dementia types is crucial for determining disease-specific intervention and treatment. Recent development of Deep-learning-based approaches in the field of medical image computing are delivering some of the best performance for many binary classification tasks, although its application in differential diagnosis, such as neuroimage-based differentiation for multiple types of dementia, has not been explored. In this study, a novel framework was proposed by using the Generative Adversarial Network technique to distinguish FTD, AD and normal control subjects, using volumetric features extracted at coarse-to-fine structural scales from Magnetic Resonance Imaging scans. Experiments of 10-folds cross-validation on 1,954 images achieved high accuracy. With the proposed framework, we have demonstrated that the combination of multi-scale structural features and synthetic data augmentation based on generative adversarial network can improve the performance of challenging tasks such as differentiating Dementia sub-types.
A Method to Generate Synthetically Warped Document Image
Oct 15, 2019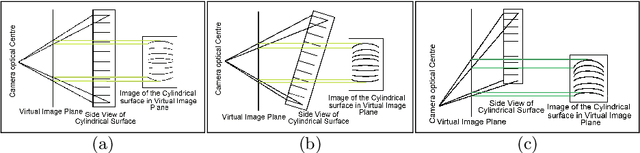

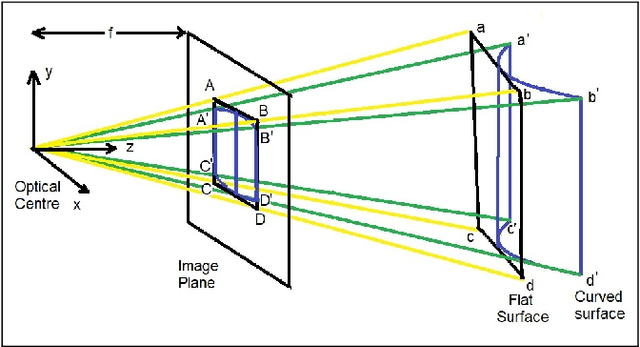

The digital camera captured document images may often be warped and distorted due to different camera angles or document surfaces. A robust technique is needed to solve this kind of distortion. The research on dewarping of the document suffers due to the limited availability of benchmark public dataset. In recent times, deep learning based approaches are used to solve the problems accurately. To train most of the deep neural networks a large number of document images is required and generating such a large volume of document images manually is difficult. In this paper, we propose a technique to generate a synthetic warped image from a flat-bedded scanned document image. It is done by calculating warping factors for each pixel position using two warping position parameters (WPP) and eight warping control parameters (WCP). These parameters can be specified as needed depending upon the desired warping. The results are compared with similar real captured images both qualitative and quantitative way.
Exploiting generative self-supervised learning for the assessment of biological images with lack of annotations: a COVID-19 case-study
Jul 26, 2021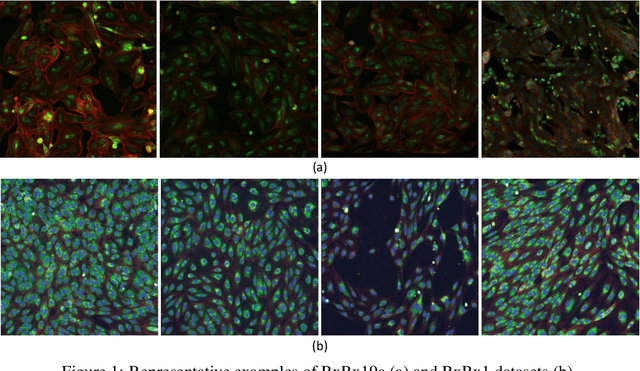

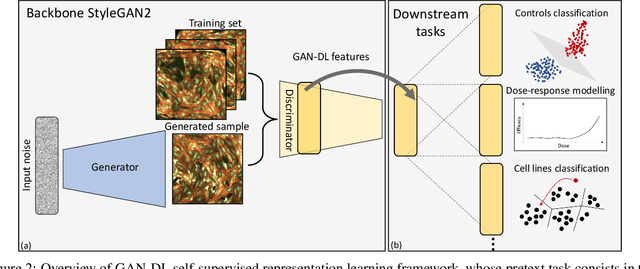
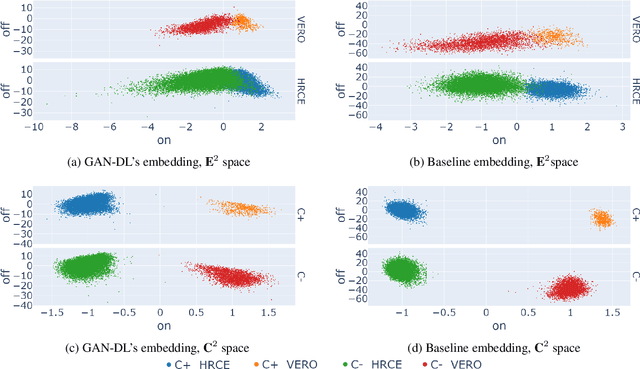
Computer-aided analysis of biological images typically requires extensive training on large-scale annotated datasets, which is not viable in many situations. In this paper we present GAN-DL, a Discriminator Learner based on the StyleGAN2 architecture, which we employ for self-supervised image representation learning in the case of fluorescent biological images. We show that Wasserstein Generative Adversarial Networks combined with linear Support Vector Machines enable high-throughput compound screening based on raw images. We demonstrate this by classifying active and inactive compounds tested for the inhibition of SARS-CoV-2 infection in VERO and HRCE cell lines. In contrast to previous methods, our deep learning based approach does not require any annotation besides the one that is normally collected during the sample preparation process. We test our technique on the RxRx19a Sars-CoV-2 image collection. The dataset consists of fluorescent images that were generated to assess the ability of regulatory-approved or in late-stage clinical trials compound to modulate the in vitro infection from SARS-CoV-2 in both VERO and HRCE cell lines. We show that our technique can be exploited not only for classification tasks, but also to effectively derive a dose response curve for the tested treatments, in a self-supervised manner. Lastly, we demonstrate its generalization capabilities by successfully addressing a zero-shot learning task, consisting in the categorization of four different cell types of the RxRx1 fluorescent images collection.
Attention-guided Low-light Image Enhancement
Aug 02, 2019
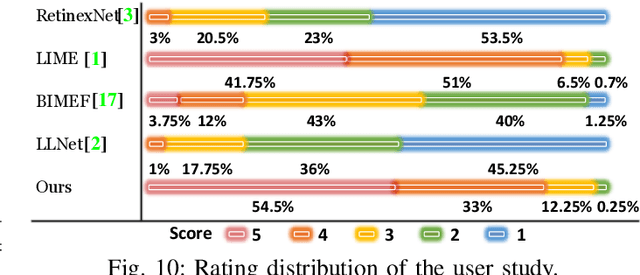


Low-light image enhancement is a challenging task since various factors, including brightness, contrast, artifacts and noise, should be handled simultaneously and effectively. To address such a difficult problem, this paper proposes a novel attention-guided enhancement solution and delivers the corresponding end-to-end multi-branch CNNs. The key of our method is the computation of two attention maps to guide the exposure enhancement and denoising respectively. In particular, the first attention map distinguishes underexposed regions from normally exposed regions, while the second attention map distinguishes noises from real-world textures. Under their guidance, the proposed multi-branch enhancement network can work in an adaptive way. Other contributions of this paper include the "decomposition/multi-branch-enhancement/fusion" design of the enhancement network, the reinforcement-net for contrast enhancement, and the proposed large-scale low-light enhancement dataset. We evaluate the proposed method through extensive experiments, and the results demonstrate that our solution outperforms state-of-the-art methods by a large margin. We additionally show that our method is flexible and effective for other image processing tasks.
Multi-level Metric Learning for Few-shot Image Recognition
Mar 31, 2021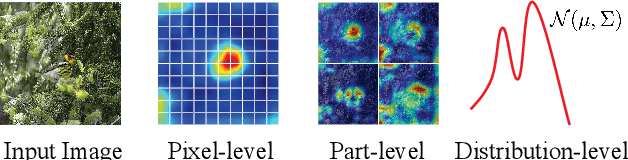
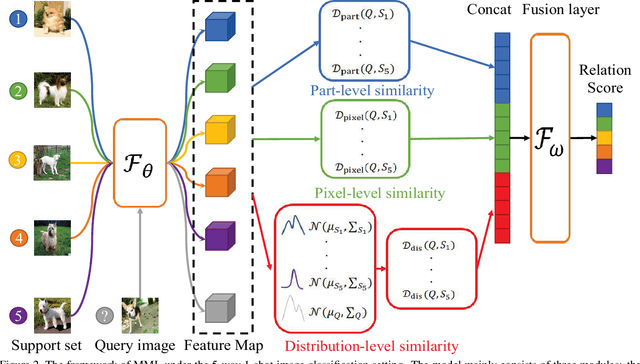
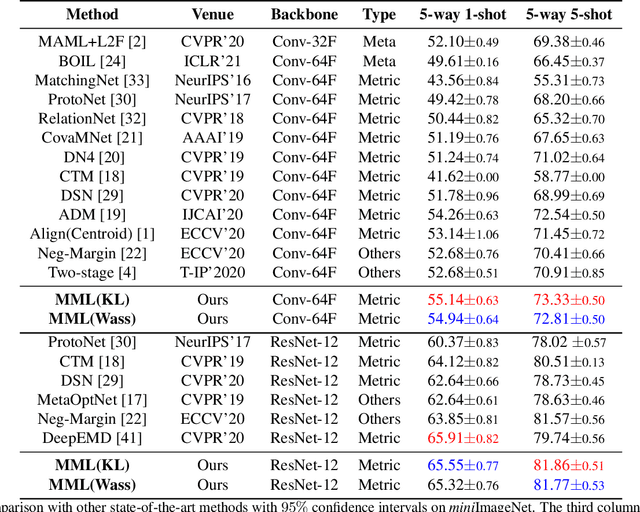
Few-shot learning is devoted to training a model on few samples. Recently, the method based on local descriptor metric-learning has achieved great performance. Most of these approaches learn a model based on a pixel-level metric. However, such works can only measure the relations between them on a single level, which is not comprehensive and effective. We argue that if query images can simultaneously be well classified via three distinct level similarity metrics, the query images within a class can be more tightly distributed in a smaller feature space, generating more discriminative feature maps. Motivated by this, we propose a novel Multi-level Metric Learning (MML) method for few-shot learning, which not only calculates the pixel-level similarity but also considers the similarity of part-level features and the similarity of distributions. First, we use a feature extractor to get the feature maps of images. Second, a multi-level metric module is proposed to calculate the part-level, pixel-level, and distribution-level similarities simultaneously. Specifically, the distribution-level similarity metric calculates the distribution distance (i.e., Wasserstein distance, Kullback-Leibler divergence) between query images and the support set, the pixel-level, and the part-level metric calculates the pixel-level and part-level similarities respectively. Finally, the fusion layer fuses three kinds of relation scores to obtain the final similarity score. Extensive experiments on popular benchmarks demonstrate that the MML method significantly outperforms the current state-of-the-art methods.