 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An improved 3D region detection network: automated detection of the 12th thoracic vertebra in image guided radiation therapy
Mar 26, 2020
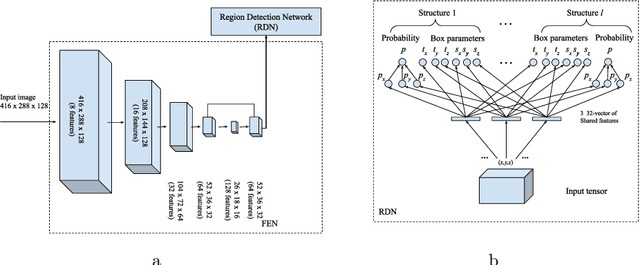
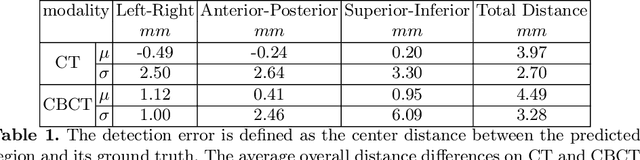
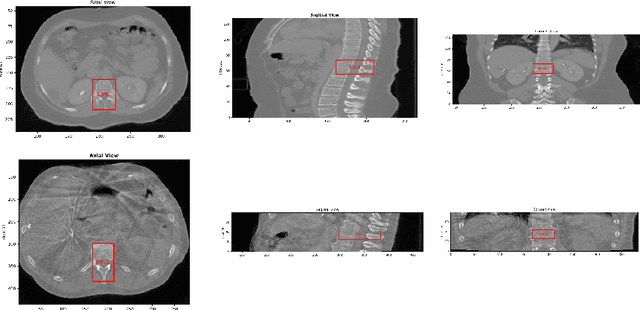
Abstract. Image guidance has been widely used in radiation therapy. Correctly identifying anatomical landmarks, like the 12th thoracic vertebra (T12), is the key to success. Until recently, the detection of those landmarks still requires tedious manual inspections and annotations; and superior-inferior misalignment to the wrong vertebral body is still relatively common in image guided radiation therapy. It is necessary to develop an automated approach to detect those landmarks from images. There are three major challenges to identify T12 vertebra automatically: 1) subtle difference in the structures with high similarity, 2) limited annotated training data, and 3) high memory usage of 3D networks. Abstract. In this study, we propose a novel 3D full convolutional network (FCN) that is trained to detect anatomical structures from 3D volumetric data, requiring only a small amount of training data. Comparing with existing approaches, the network architecture, target generation and loss functions were significantly improved to address the challenges specific to medical images. In our experiments, the proposed network, which was trained from a small amount of annotated images, demonstrated the capability of accurately detecting structures with high similarity. Furthermore, the trained network showed the capability of cross-modality learning. This is meaningful in the situation where image annotations in one modality are easier to obtain than others. The cross-modality learning ability also indicated that the learned features were robust to noise in different image modalities. In summary, our approach has a great potential to be integrated into the clinical workflow to improve the safety of image guided radiation therapy.
An MRF-UNet Product of Experts for Image Segmentation
Apr 12, 2021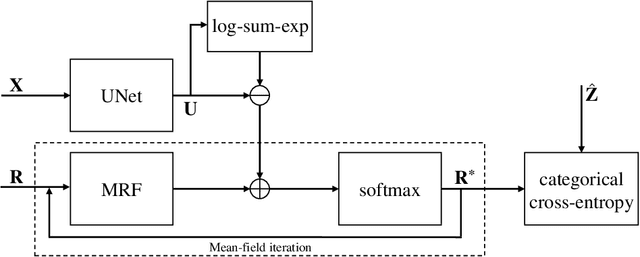
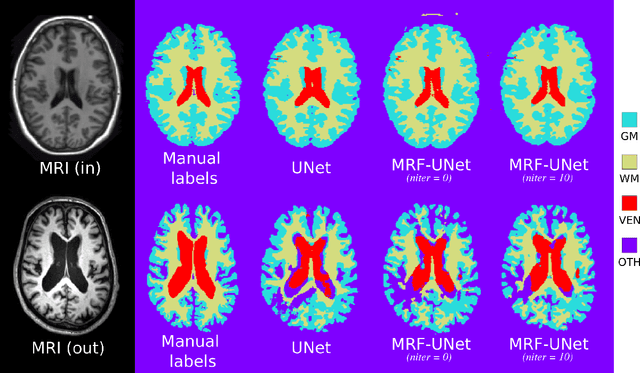
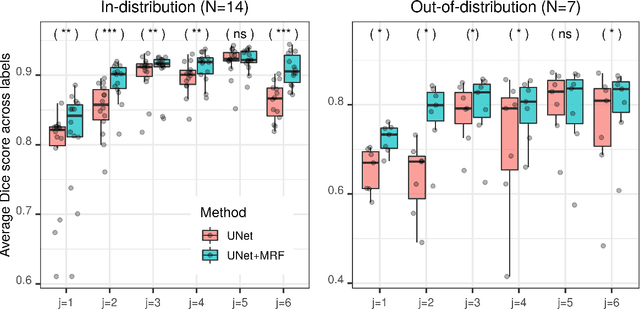
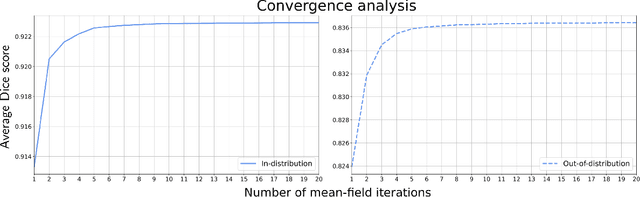
While convolutional neural networks (CNNs) trained by back-propagation have seen unprecedented success at semantic segmentation tasks, they are known to struggle on out-of-distribution data. Markov random fields (MRFs) on the other hand, encode simpler distributions over labels that, although less flexible than UNets, are less prone to over-fitting. In this paper, we propose to fuse both strategies by computing the product of distributions of a UNet and an MRF. As this product is intractable, we solve for an approximate distribution using an iterative mean-field approach. The resulting MRF-UNet is trained jointly by back-propagation. Compared to other works using conditional random fields (CRFs), the MRF has no dependency on the imaging data, which should allow for less over-fitting. We show on 3D neuroimaging data that this novel network improves generalisation to out-of-distribution samples. Furthermore, it allows the overall number of parameters to be reduced while preserving high accuracy. These results suggest that a classic MRF smoothness prior can allow for less over-fitting when principally integrated into a CNN model. Our implementation is available at https://github.com/balbasty/nitorch.
Deeply Matting-based Dual Generative Adversarial Network for Image and Document Label Supervision
Sep 19, 2019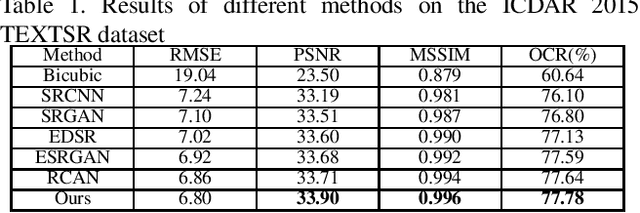
Although many methods have been proposed to deal with nature image super-resolution (SR) and get impressive performance, the text images SR is not good due to their ignorance of document images. In this paper, we propose a matting-based dual generative adversarial network (mdGAN) for document image SR. Firstly, the input image is decomposed into document text, foreground and background layers using deep image matting. Then two parallel branches are constructed to recover text boundary information and color information respectively. Furthermore, in order to improve the restoration accuracy of characters in output image, we use the input image's corresponding ground truth text label as extra supervise information to refine the two-branch networks during training. Experiments on real text images demonstrate that our method outperforms several state-of-the-art methods quantitatively and qualitatively.
Dynamic Slimmable Denoising Network
Oct 17, 2021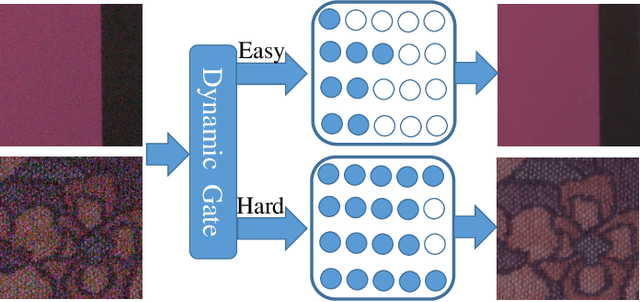

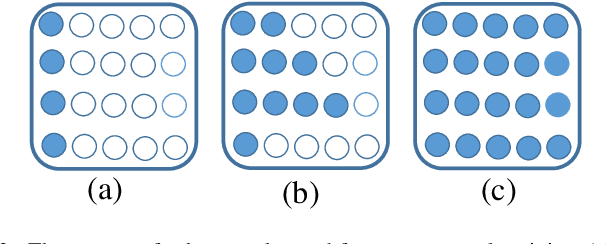
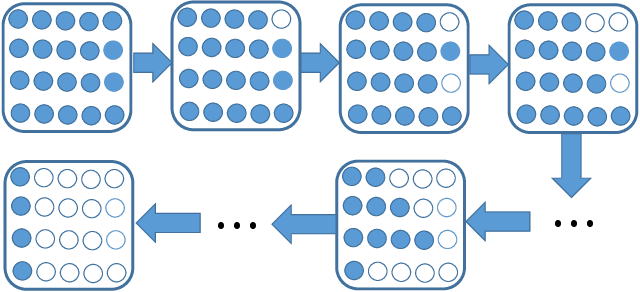
Recently, tremendous human-designed and automatically searched neural networks have been applied to image denoising. However, previous works intend to handle all noisy images in a pre-defined static network architecture, which inevitably leads to high computational complexity for good denoising quality. Here, we present dynamic slimmable denoising network (DDS-Net), a general method to achieve good denoising quality with less computational complexity, via dynamically adjusting the channel configurations of networks at test time with respect to different noisy images. Our DDS-Net is empowered with the ability of dynamic inference by a dynamic gate, which can predictively adjust the channel configuration of networks with negligible extra computation cost. To ensure the performance of each candidate sub-network and the fairness of the dynamic gate, we propose a three-stage optimization scheme. In the first stage, we train a weight-shared slimmable super network. In the second stage, we evaluate the trained slimmable super network in an iterative way and progressively tailor the channel numbers of each layer with minimal denoising quality drop. By a single pass, we can obtain several sub-networks with good performance under different channel configurations. In the last stage, we identify easy and hard samples in an online way and train a dynamic gate to predictively select the corresponding sub-network with respect to different noisy images. Extensive experiments demonstrate our DDS-Net consistently outperforms the state-of-the-art individually trained static denoising networks.
Exploring Heterogeneous Metadata for Video Recommendation with Two-tower Model
Sep 22, 2021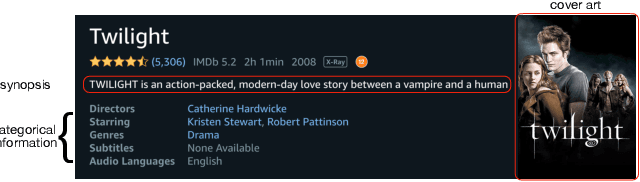
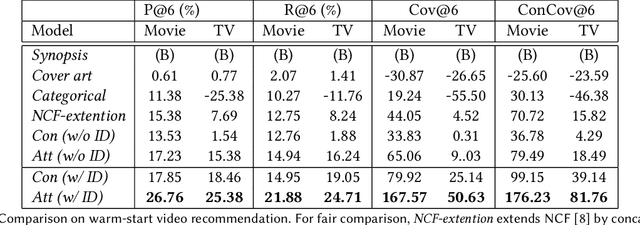
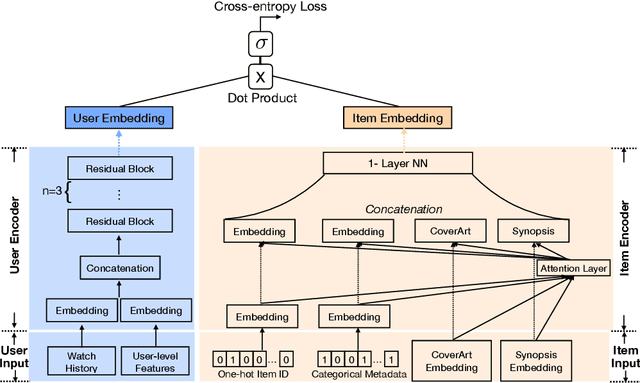

Online video services acquire new content on a daily basis to increase engagement, and improve the user experience. Traditional recommender systems solely rely on watch history, delaying the recommendation of newly added titles to the right customer. However, one can use the metadata information of a cold-start title to bootstrap the personalization. In this work, we propose to adopt a two-tower model, in which one tower is to learn the user representation based on their watch history, and the other tower is to learn the effective representations for titles using metadata. The contribution of this work can be summarized as: (1) we show the feasibility of using two-tower model for recommendations and conduct a series of offline experiments to show its performance for cold-start titles; (2) we explore different types of metadata (categorical features, text description, cover-art image) and an attention layer to fuse them; (3) with our Amazon proprietary data, we show that the attention layer can assign weights adaptively to different metadata with improved recommendation for warm- and cold-start items.
Synergic Adversarial Label Learning with DR and AMD for Retinal Image Grading
Mar 24, 2020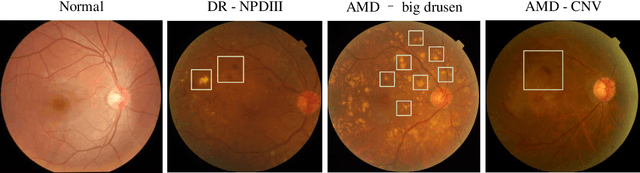
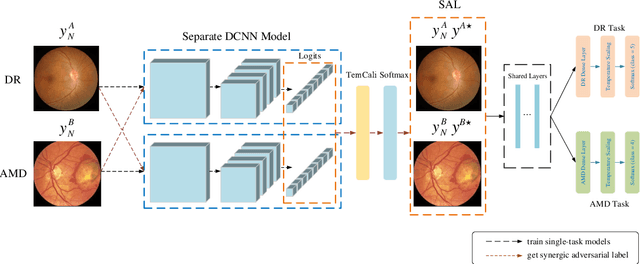
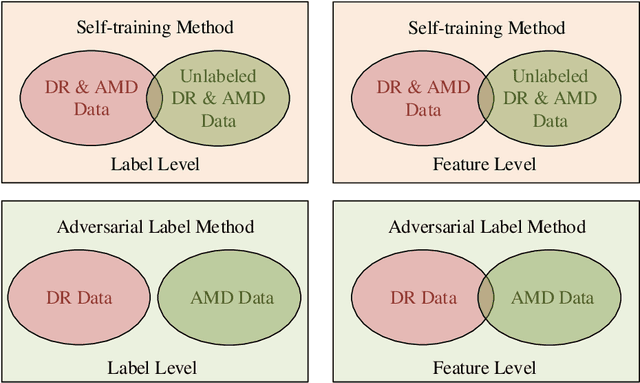
The need for comprehensive and automated screening methods for retinal image classification has long been recognized. Well-qualified doctors annotated images are very expensive and only a limited amount of data is available for various retinal diseases such as age-related macular degeneration (AMD) and diabetic retinopathy (DR). Some studies show that AMD and DR share some common features like hemorrhagic points and exudation but most classification algorithms only train those disease models independently. Inspired by knowledge distillation where additional monitoring signals from various sources is beneficial to train a robust model with much fewer data. We propose a method called synergic adversarial label learning (SALL) which leverages relevant retinal disease labels in both semantic and feature space as additional signals and train the model in a collaborative manner. Our experiments on DR and AMD fundus image classification task demonstrate that the proposed method can significantly improve the accuracy of the model for grading diseases. In addition, we conduct additional experiments to show the effectiveness of SALL from the aspects of reliability and interpretability in the context of medical imaging application.
Time Series to Images: Monitoring the Condition of Industrial Assets with Deep Learning Image Processing Algorithms
May 14, 2020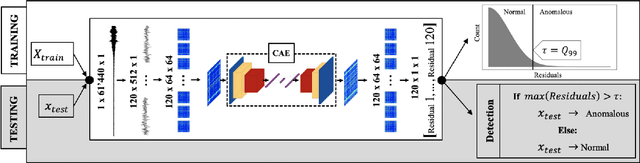
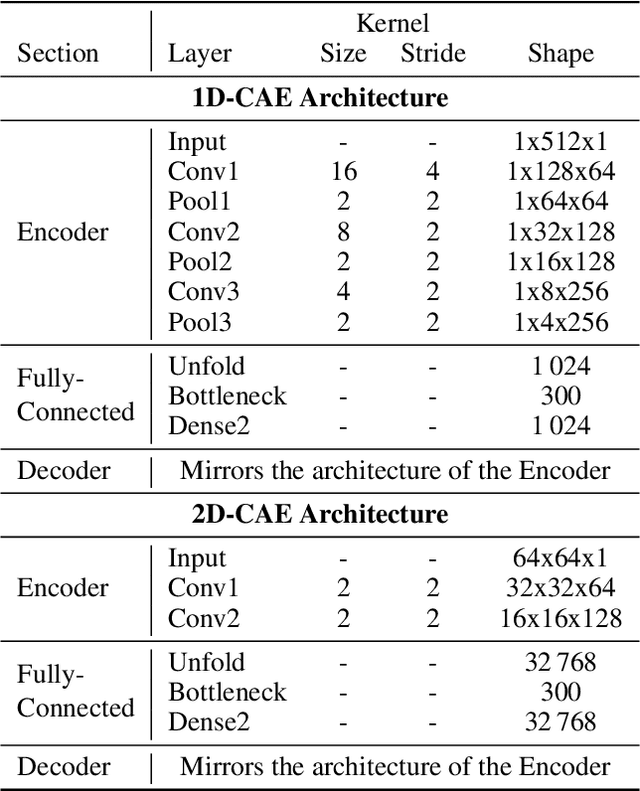
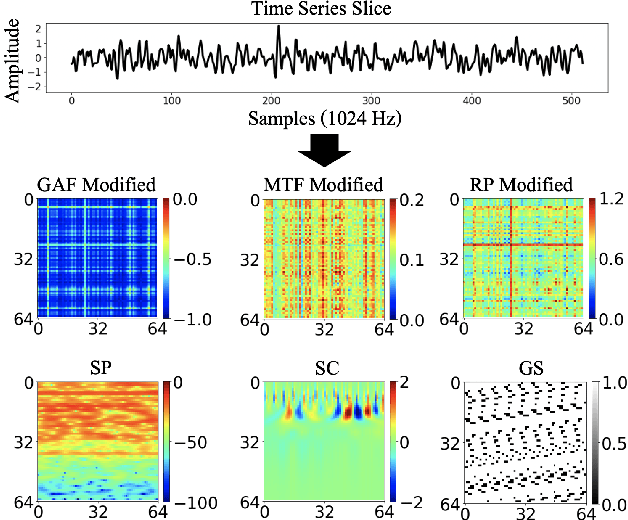
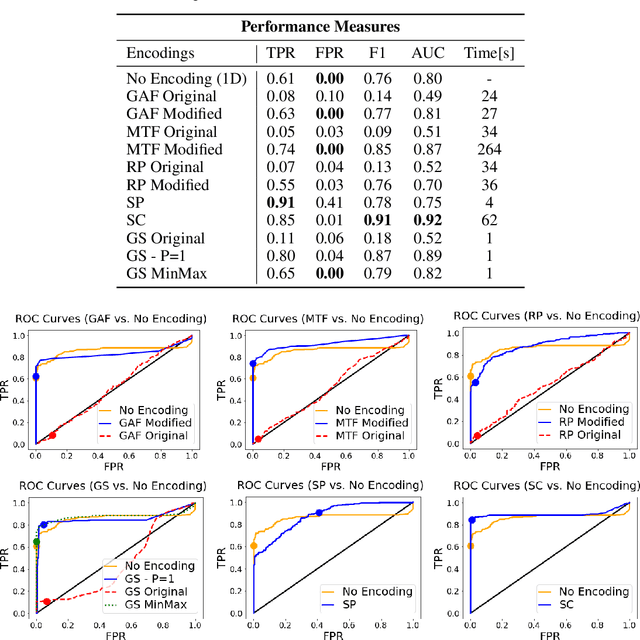
The ability to detect anomalies in time series is considered as highly valuable within plenty of application domains. The sequential nature of time series objects is responsible for an additional feature complexity, ultimately requiring specialized approaches for solving the task. Essential characteristics of time series, laying outside the time domain, are often difficult to capture with state-of-the-art anomaly detection methods, when no transformations on the time series have been applied. Inspired by the success of deep learning methods in computer vision, several studies have proposed to transform time-series into image-like representations, leading to very promising results. However, most of the previous studies implementing time-series to image encodings have focused on the supervised classification. The application to unsupervised anomaly detection tasks has been limited. The paper has the following contributions: First, we evaluate the application of six time-series to image encodings to DL algorithms: Gramian Angular Field, Markov Transition Field, Recurrence Plot, Grey Scale Encoding, Spectrogram and Scalogram. Second, we propose modifications of the original encoding definitions, to make them more robust to the variability in large datasets. And third, we provide a comprehensive comparison between using the raw time series directly and the different encodings, with and without the proposed improvements. The comparison is performed on a dataset collected and released by Airbus, containing highly complex vibration measurements from real helicopters flight tests. The different encodings provide competitive results for anomaly detection.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020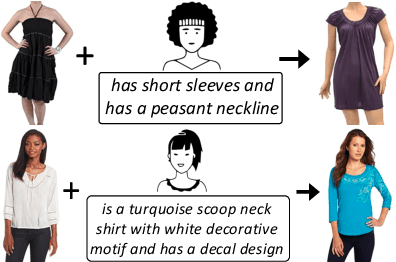
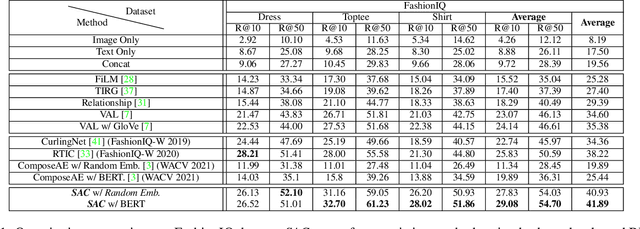
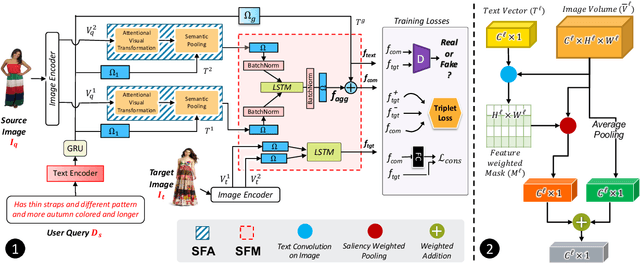
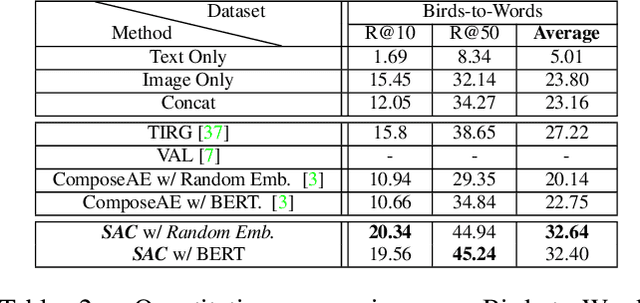
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.
Finding Physical Adversarial Examples for Autonomous Driving with Fast and Differentiable Image Compositing
Oct 17, 2020
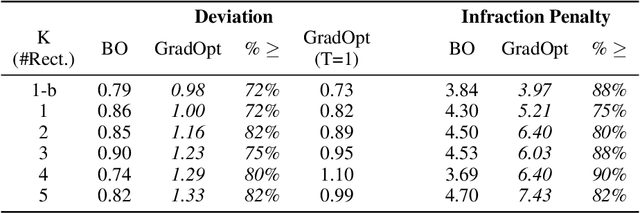
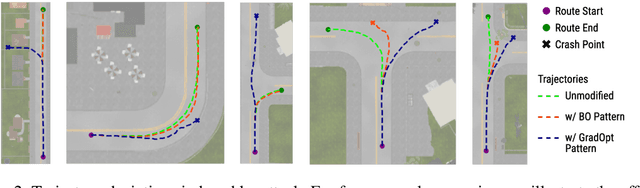
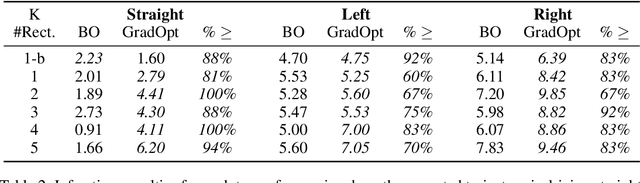
There is considerable evidence that deep neural networks are vulnerable to adversarial perturbations applied directly to their digital inputs. However, it remains an open question whether this translates to vulnerabilities in real-world systems. Specifically, in the context of image inputs to autonomous driving systems, an attack can be achieved only by modifying the physical environment, so as to ensure that the resulting stream of video inputs to the car's controller leads to incorrect driving decisions. Inducing this effect on the video inputs indirectly through the environment requires accounting for system dynamics and tracking viewpoint changes. We propose a scalable and efficient approach for finding adversarial physical modifications, using a differentiable approximation for the mapping from environmental modifications-namely, rectangles drawn on the road-to the corresponding video inputs to the controller network. Given the color, location, position, and orientation parameters of the rectangles, our mapping composites them onto pre-recorded video streams of the original environment. Our mapping accounts for geometric and color variations, is differentiable with respect to rectangle parameters, and uses multiple original video streams obtained by varying the driving trajectory. When combined with a neural network-based controller, our approach allows the design of adversarial modifications through end-to-end gradient-based optimization. We evaluate our approach using the Carla autonomous driving simulator, and show that it is significantly more scalable and far more effective at generating attacks than a prior black-box approach based on Bayesian Optimization.
Multi-level Metric Learning for Few-shot Image Recognition
Apr 12, 2021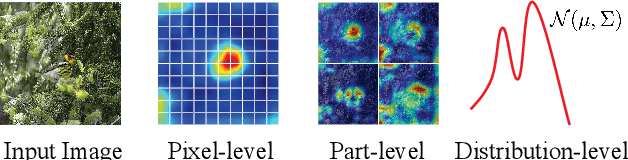
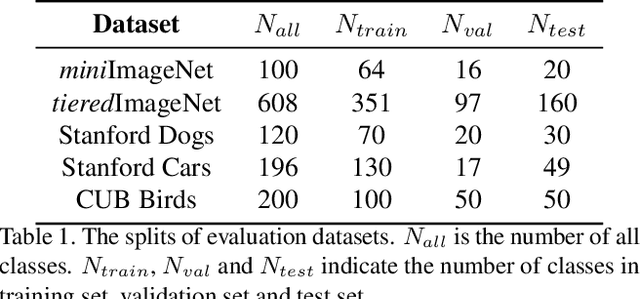
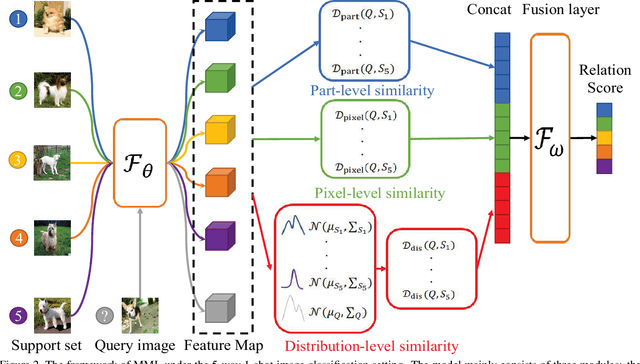
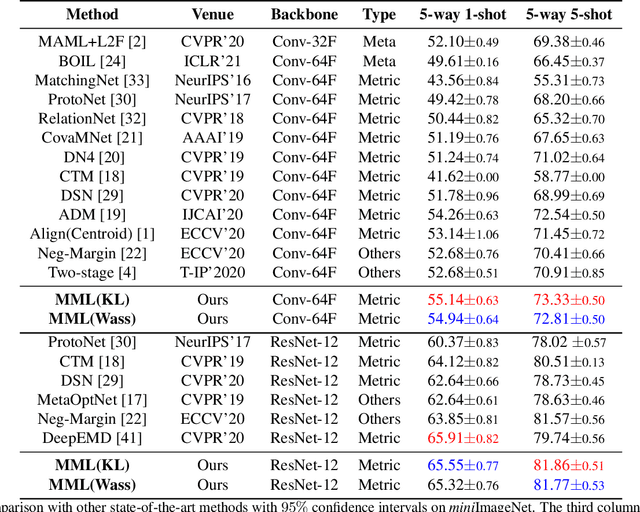
Few-shot learning is devoted to training a model on few samples. Recently, the method based on local descriptor metric-learning has achieved great performance. Most of these approaches learn a model based on a pixel-level metric. However, such works can only measure the relations between them on a single level, which is not comprehensive and effective. We argue that if query images can simultaneously be well classified via three distinct level similarity metrics, the query images within a class can be more tightly distributed in a smaller feature space, generating more discriminative feature maps. Motivated by this, we propose a novel Multi-level Metric Learning (MML) method for few-shot learning, which not only calculates the pixel-level similarity but also considers the similarity of part-level features and the similarity of distributions. First, we use a feature extractor to get the feature maps of images. Second, a multi-level metric module is proposed to calculate the part-level, pixel-level, and distribution-level similarities simultaneously. Specifically, the distribution-level similarity metric calculates the distribution distance (i.e., Wasserstein distance, Kullback-Leibler divergence) between query images and the support set, the pixel-level, and the part-level metric calculates the pixel-level and part-level similarities respectively. Finally, the fusion layer fuses three kinds of relation scores to obtain the final similarity score. Extensive experiments on popular benchmarks demonstrate that the MML method significantly outperforms the current state-of-the-art methods.