 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blur-Attention: A boosting mechanism for non-uniform blurred image restoration
Aug 19, 2020

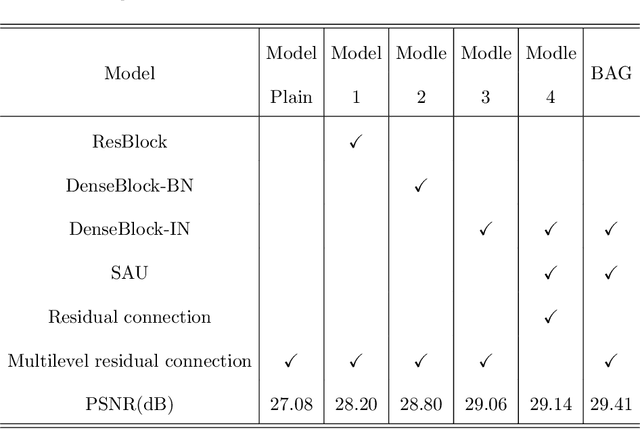
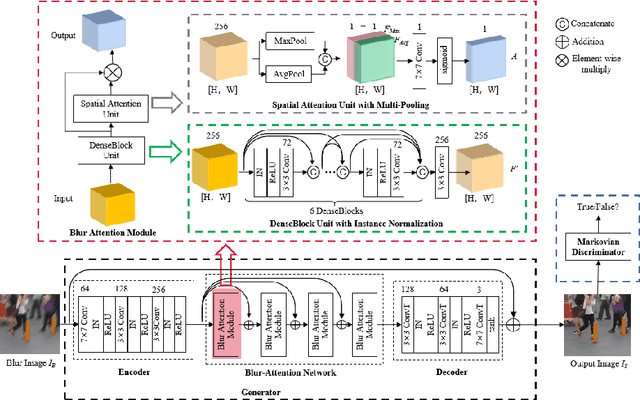
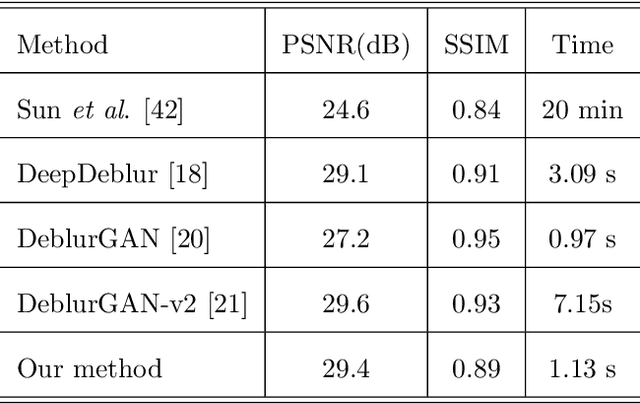
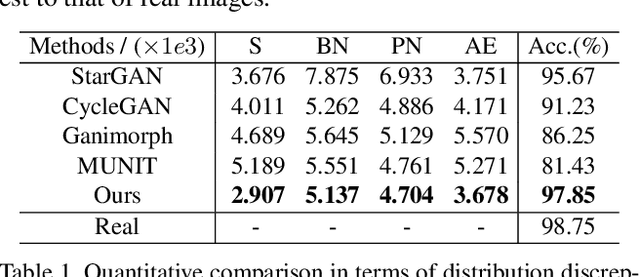
Dynamic scene deblurring is a challenging problem in computer vision. It is difficult to accurately estimate the spatially varying blur kernel by traditional methods. Data-driven-based methods usually employ kernel-free end-to-end mapping schemes, which are apt to overlook the kernel estimation. To address this issue, we propose a blur-attention module to dynamically capture the spatially varying features of non-uniform blurred images. The module consists of a DenseBlock unit and a spatial attention unit with multi-pooling feature fusion, which can effectively extract complex spatially varying blur features. We design a multi-level residual connection structure to connect multiple blur-attention modules to form a blur-attention network. By introducing the blur-attention network into a conditional generation adversarial framework, we propose an end-to-end blind motion deblurring method, namely Blur-Attention-GAN (BAG), for a single image. Our method can adaptively select the weights of the extracted features according to the spatially varying blur features, and dynamically restore the images. Experimental results show that the deblurring capability of our method achieved outstanding objective performance in terms of PSNR, SSIM, and subjective visual quality. Furthermore, by visualizing the features extracted by the blur-attention module, comprehensive discussions are provided on its effectiveness.
Attribute-Driven Spontaneous Motion in Unpaired Image Translation
Jul 02, 2019
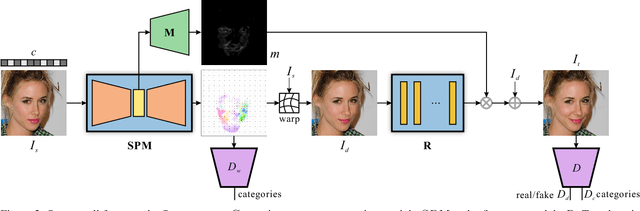
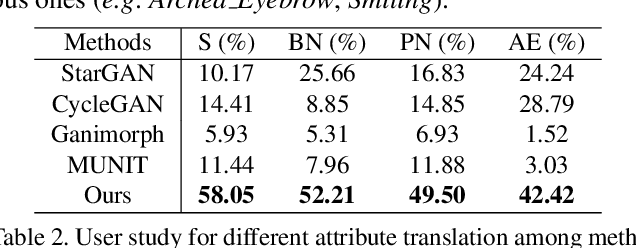
Current image translation methods, albeit effective to produce high-quality results on various applications, still do not consider much geometric transforms. We in this paper propose spontaneous motion estimation module, along with a refinement module, to learn attribute-driven deformation between source and target domains. Extensive experiments and visualization demonstrate effectiveness of these modules. We achieve promising results in unpaired image translation tasks, and enable interesting applications with spontaneous motion basis.
Disentangled Cycle Consistency for Highly-realistic Virtual Try-On
Mar 19, 2021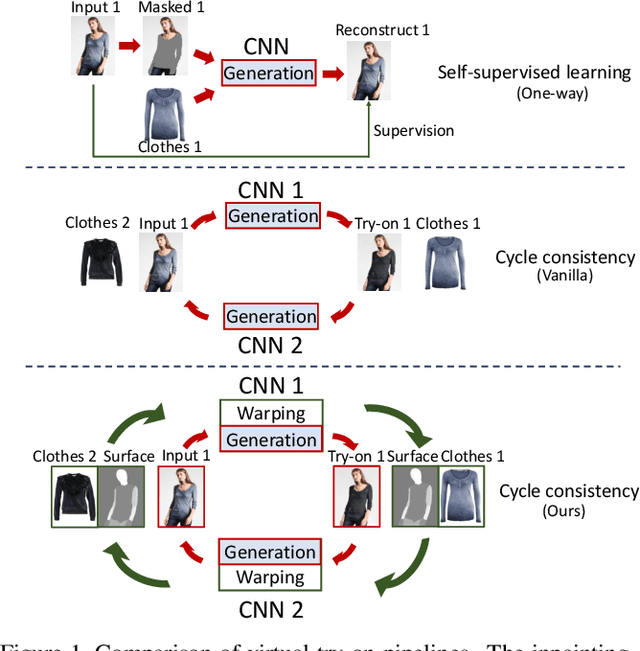
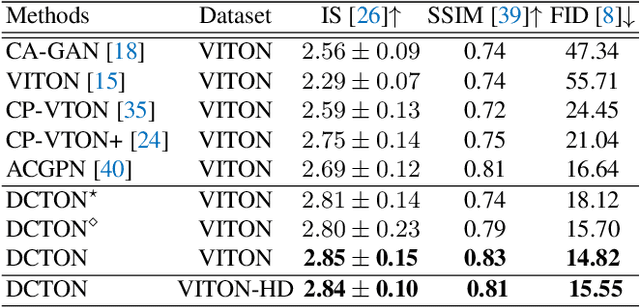

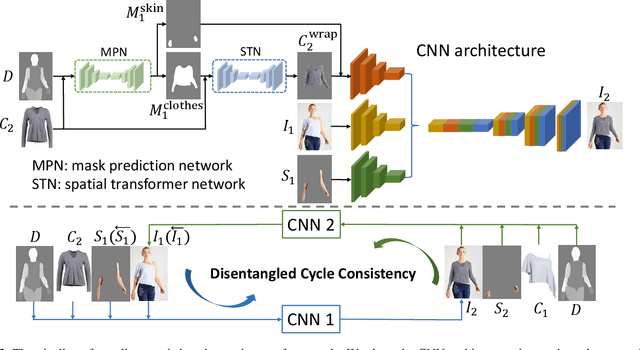
Image virtual try-on replaces the clothes on a person image with a desired in-shop clothes image. It is challenging because the person and the in-shop clothes are unpaired. Existing methods formulate virtual try-on as either in-painting or cycle consistency. Both of these two formulations encourage the generation networks to reconstruct the input image in a self-supervised manner. However, existing methods do not differentiate clothing and non-clothing regions. A straight-forward generation impedes virtual try-on quality because of the heavily coupled image contents. In this paper, we propose a Disentangled Cycle-consistency Try-On Network (DCTON). The DCTON is able to produce highly-realistic try-on images by disentangling important components of virtual try-on including clothes warping, skin synthesis, and image composition. To this end, DCTON can be naturally trained in a self-supervised manner following cycle consistency learning. Extensive experiments on challenging benchmarks show that DCTON outperforms state-of-the-art approaches favorably.
InAugment: Improving Classifiers via Internal Augmentation
Apr 08, 2021
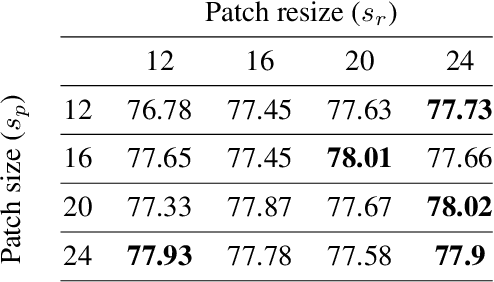
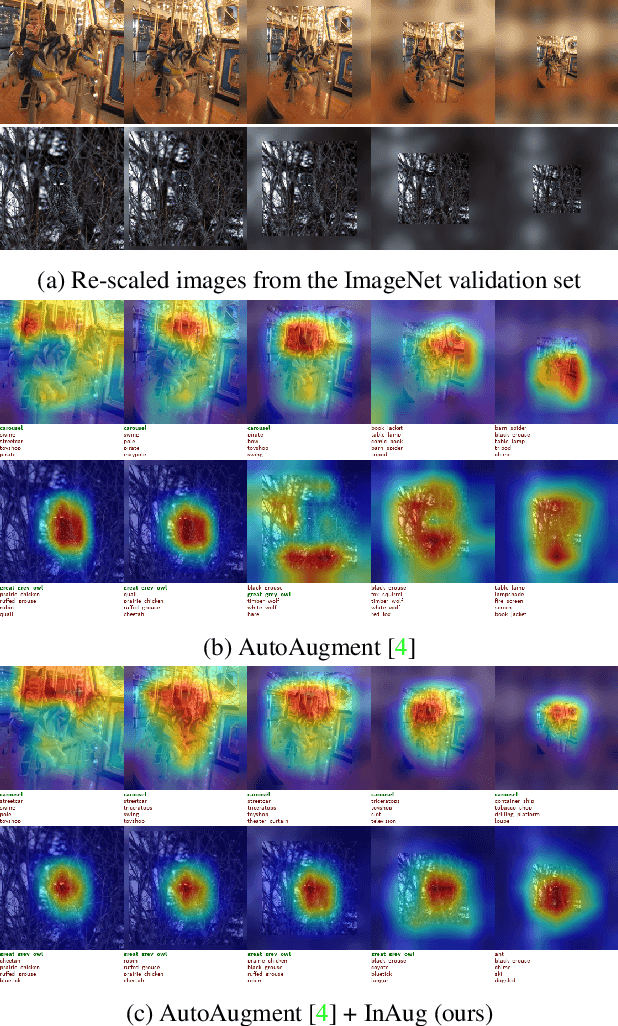

Image augmentation techniques apply transformation functions such as rotation, shearing, or color distortion on an input image. These augmentations were proven useful in improving neural networks' generalization ability. In this paper, we present a novel augmentation operation, InAugment, that exploits image internal statistics. The key idea is to copy patches from the image itself, apply augmentation operations on them, and paste them back at random positions on the same image. This method is simple and easy to implement and can be incorporated with existing augmentation techniques. We test InAugment on two popular datasets -- CIFAR and ImageNet. We show improvement over state-of-the-art augmentation techniques. Incorporating InAugment with Auto Augment yields a significant improvement over other augmentation techniques (e.g., +1% improvement over multiple architectures trained on the CIFAR dataset). We also demonstrate an increase for ResNet50 and EfficientNet-B3 top-1's accuracy on the ImageNet dataset compared to prior augmentation methods. Finally, our experiments suggest that training convolutional neural network using InAugment not only improves the model's accuracy and confidence but its performance on out-of-distribution images.
Comparing Correspondences: Video Prediction with Correspondence-wise Losses
Apr 19, 2021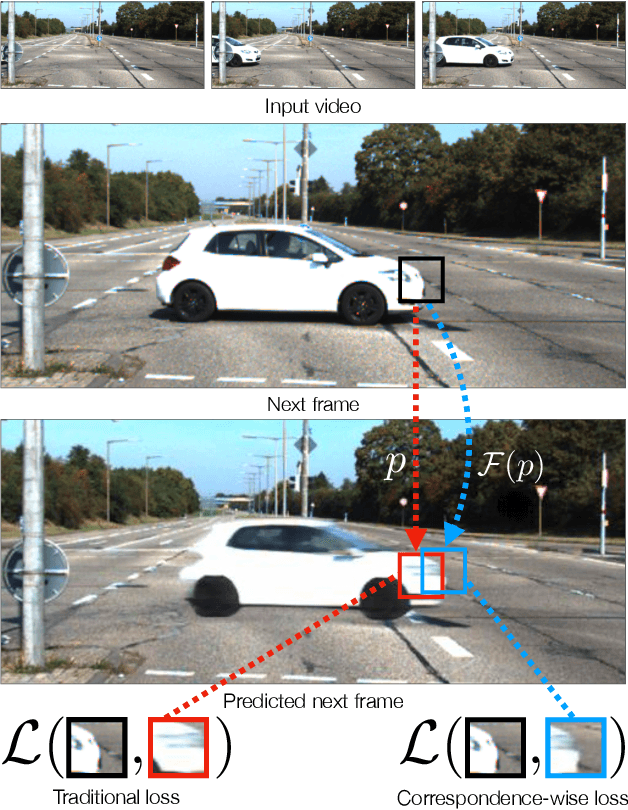
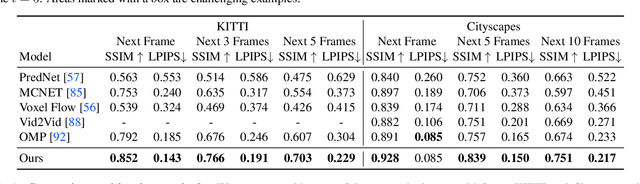
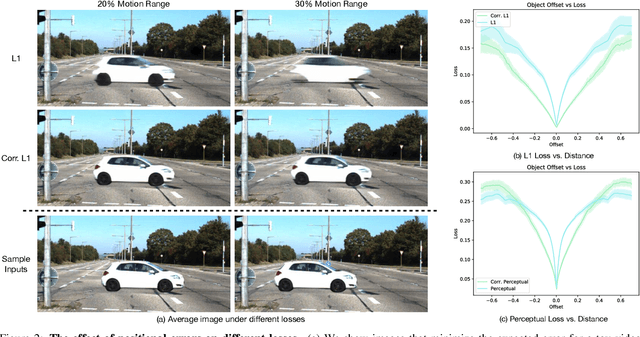
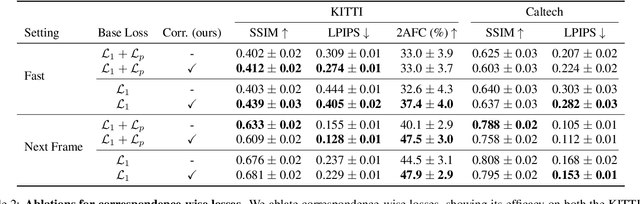
Today's image prediction methods struggle to change the locations of objects in a scene, producing blurry images that average over the many positions they might occupy. In this paper, we propose a simple change to existing image similarity metrics that makes them more robust to positional errors: we match the images using optical flow, then measure the visual similarity of corresponding pixels. This change leads to crisper and more perceptually accurate predictions, and can be used with any image prediction network. We apply our method to predicting future frames of a video, where it obtains strong performance with simple, off-the-shelf architectures.
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
Jul 01, 2020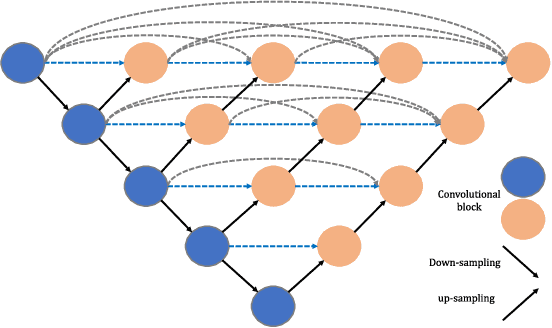



In this paper we propose a novel method for infrared and visible image fusion where we develop nest connection-based network and spatial/channel attention models. The nest connection-based network can preserve significant amounts of information from input data in a multi-scale perspective. The approach comprises three key elements: encoder, fusion strategy and decoder respectively. In our proposed fusion strategy, spatial attention models and channel attention models are developed that describe the importance of each spatial position and of each channel with deep features. Firstly, the source images are fed into the encoder to extract multi-scale deep features. The novel fusion strategy is then developed to fuse these features for each scale. Finally, the fused image is reconstructed by the nest connection-based decoder. Experiments are performed on publicly available datasets. These exhibit that our proposed approach has better fusion performance than other state-of-the-art methods. This claim is justified through both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-nestfuse
DeepMetis: Augmenting a Deep Learning Test Set to Increase its Mutation Score
Sep 15, 2021
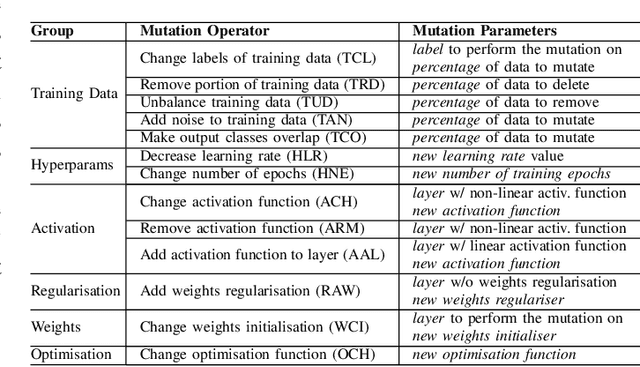

Deep Learning (DL) components are routinely integrated into software systems that need to perform complex tasks such as image or natural language processing. The adequacy of the test data used to test such systems can be assessed by their ability to expose artificially injected faults (mutations) that simulate real DL faults. In this paper, we describe an approach to automatically generate new test inputs that can be used to augment the existing test set so that its capability to detect DL mutations increases. Our tool DeepMetis implements a search based input generation strategy. To account for the non-determinism of the training and the mutation processes, our fitness function involves multiple instances of the DL model under test. Experimental results show that \tool is effective at augmenting the given test set, increasing its capability to detect mutants by 63% on average. A leave-one-out experiment shows that the augmented test set is capable of exposing unseen mutants, which simulate the occurrence of yet undetected faults.
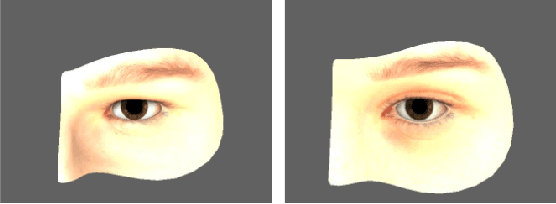
Foreground color prediction through inverse compositing
Mar 24, 2021
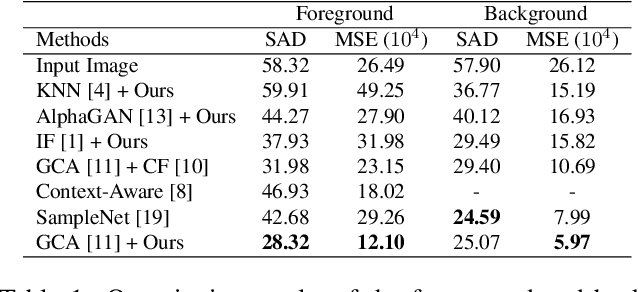
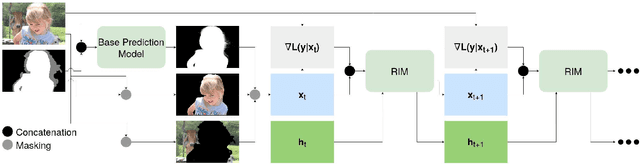
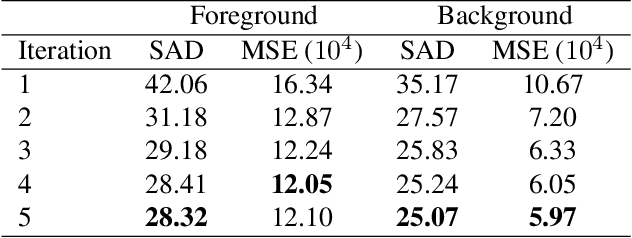
In natural image matting, the goal is to estimate the opacity of the foreground object in the image. This opacity controls the way the foreground and background is blended in transparent regions. In recent years, advances in deep learning have led to many natural image matting algorithms that have achieved outstanding performance in a fully automatic manner. However, most of these algorithms only predict the alpha matte from the image, which is not sufficient to create high-quality compositions. Further, it is not possible to manually interact with these algorithms in any way except by directly changing their input or output. We propose a novel recurrent neural network that can be used as a post-processing method to recover the foreground and background colors of an image, given an initial alpha estimation. Our method outperforms the state-of-the-art in color estimation for natural image matting and show that the recurrent nature of our method allows users to easily change candidate solutions that lead to superior color estimations.
Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021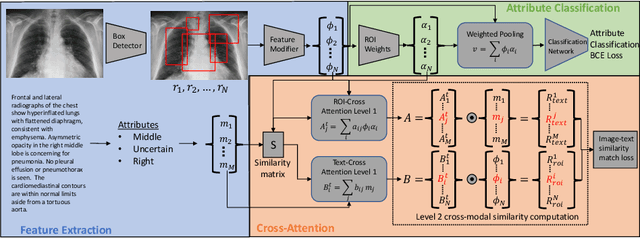
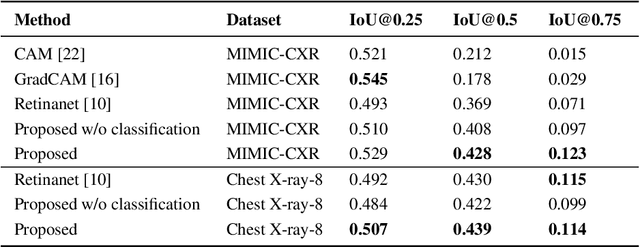
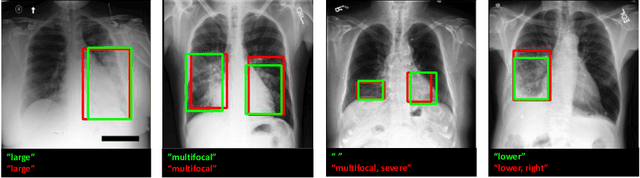

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
An investigation of pre-upsampling generative modelling and Generative Adversarial Networks in audio super resolution
Sep 30, 2021
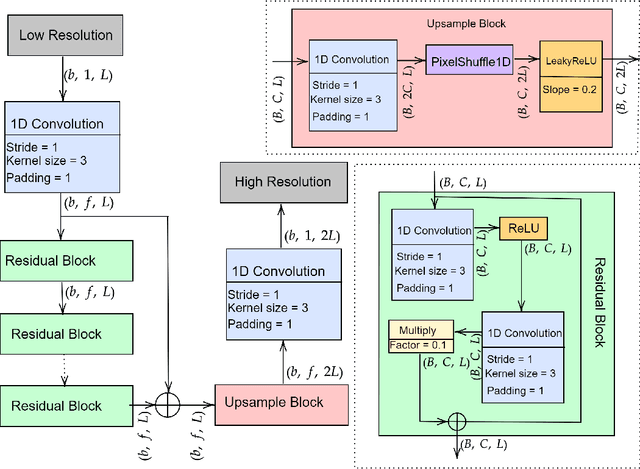
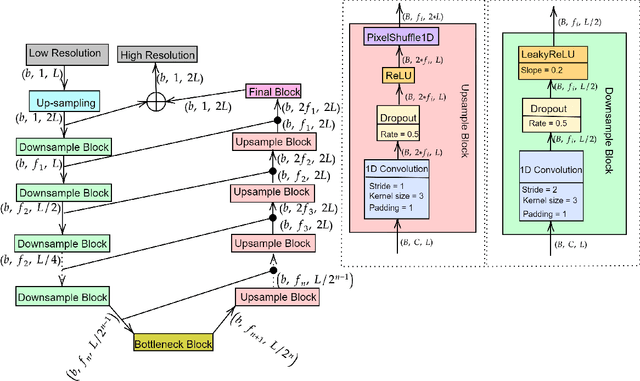
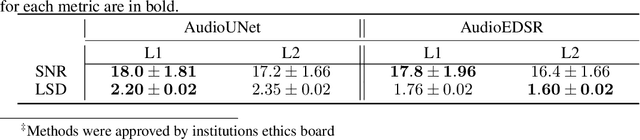
There have been several successful deep learning models that perform audio super-resolution. Many of these approaches involve using preprocessed feature extraction which requires a lot of domain-specific signal processing knowledge to implement. Convolutional Neural Networks (CNNs) improved upon this framework by automatically learning filters. An example of a convolutional approach is AudioUNet, which takes inspiration from novel methods of upsampling images. Our paper compares the pre-upsampling AudioUNet to a new generative model that upsamples the signal before using deep learning to transform it into a more believable signal. Based on the EDSR network for image super-resolution, the newly proposed model outperforms UNet with a 20% increase in log spectral distance and a mean opinion score of 4.06 compared to 3.82 for the two times upsampling case. AudioEDSR also has 87% fewer parameters than AudioUNet. How incorporating AudioUNet into a Wasserstein GAN (with gradient penalty) (WGAN-GP) structure can affect training is also explored. Finally the effects artifacting has on the current state of the art is analysed and solutions to this problem are proposed. The methods used in this paper have broad applications to telephony, audio recognition and audio generation tasks.