 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NICO: A Dataset Towards Non-I.I.D. Image Classification
Jul 01, 2019
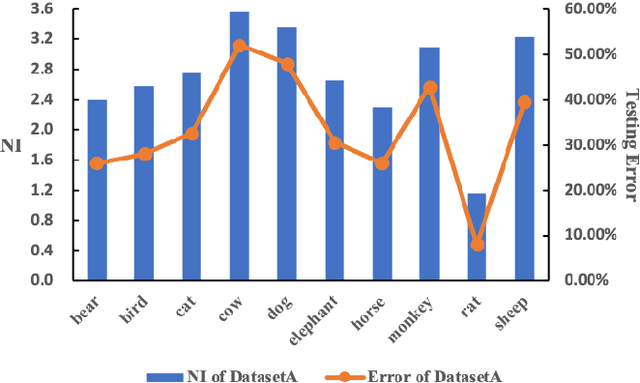
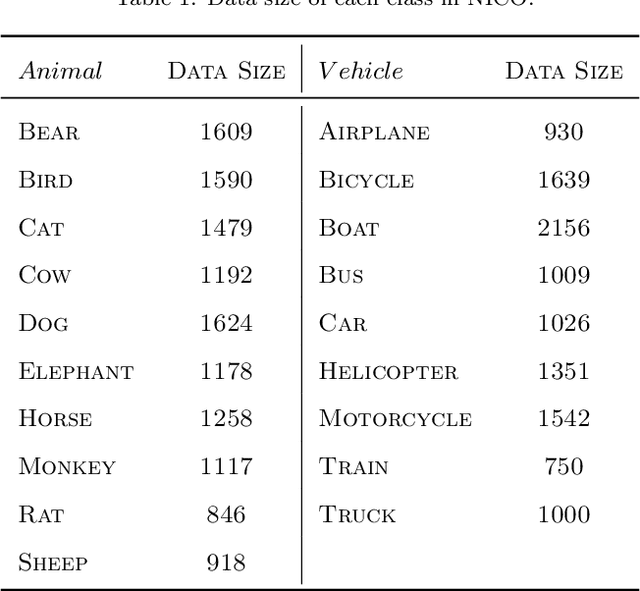
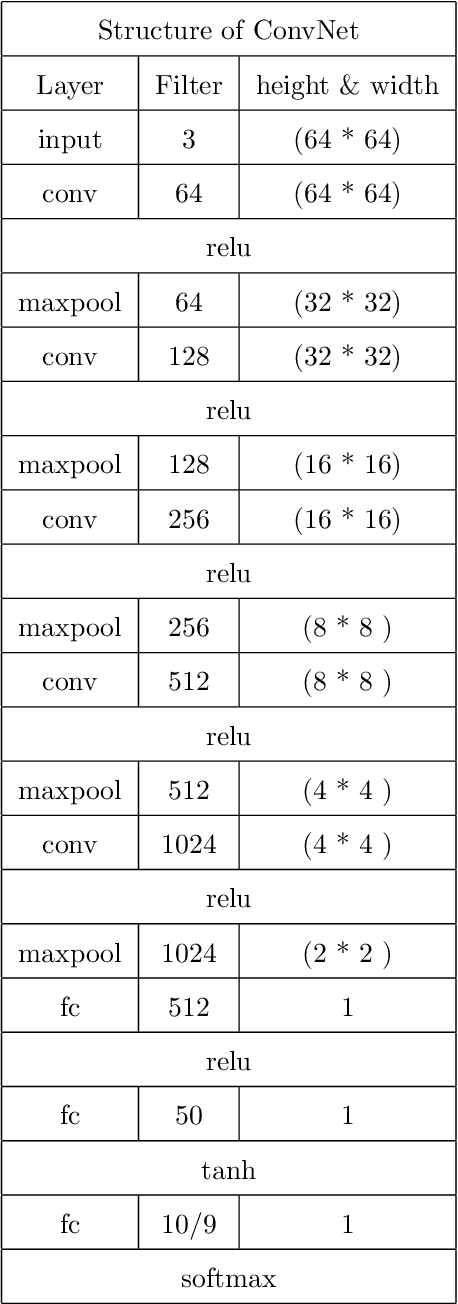
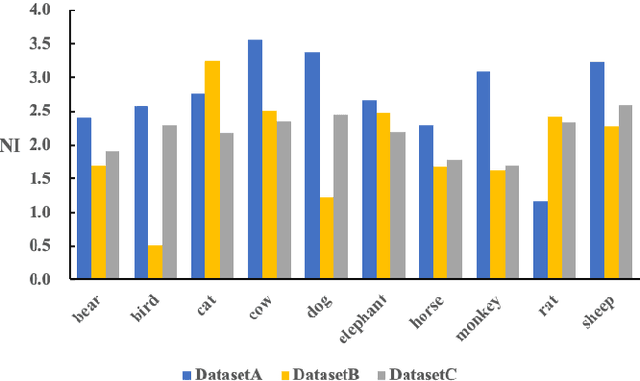
The I.I.D. hypothesis between training data and testing data is the basis of a large number of image classification methods. Such a property can hardly be guaranteed in practical cases where the Non-IIDness is common, leading to instable performances of these models. In literature, however, the Non-I.I.D. image classification problem is largely understudied. A key reason is the lacking of a well-designed dataset to support related research. In this paper, we construct and release a Non-I.I.D. image dataset called NICO, which makes use of contexts to create Non-IIDness consciously. Extended experimental results and anslyses demonstrate that the NICO dataset can well support the training of a ConvNet model from scratch, and NICO can support various Non-I.I.D. situations with sufficient flexibility compared to other datasets.
JPAD-SE: High-Level Semantics for Joint Perception-Accuracy-Distortion Enhancement in Image Compression
May 24, 2020
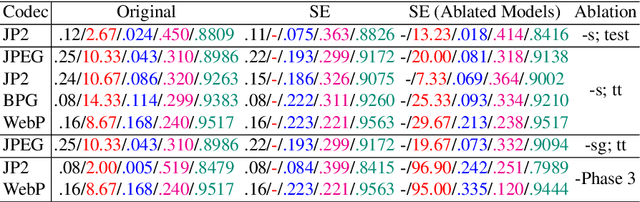

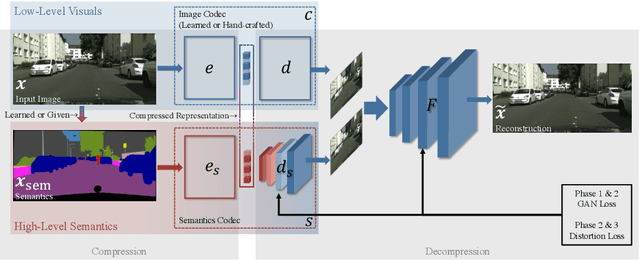
While humans can effortlessly transform complex visual scenes into simple words and the other way around by leveraging their high-level understanding of the content, conventional or the more recent learned image compression codecs do not seem to utilize the semantic meanings of visual content to its full potential. Moreover, they focus mostly on rate-distortion and tend to underperform in perception quality especially in low bitrate regime, and often disregard the performance of downstream computer vision algorithms, which is a fast-growing consumer group of compressed images in addition to human viewers. In this paper, we (1) present a generic framework that can enable any image codec to leverage high-level semantics, and (2) study the joint optimization of perception quality, accuracy of downstream computer vision task, and distortion. Our idea is that given any codec, we utilize high-level semantics to augment the low-level visual features extracted by it and produce essentially a new, semantic-aware codec. And we argue that semantic enhancement implicitly optimizes rate-perception-accuracy-distortion (R-PAD) performance. To validate our claim, we perform extensive empirical evaluations and provide both quantitative and qualitative results.
On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
Apr 22, 2021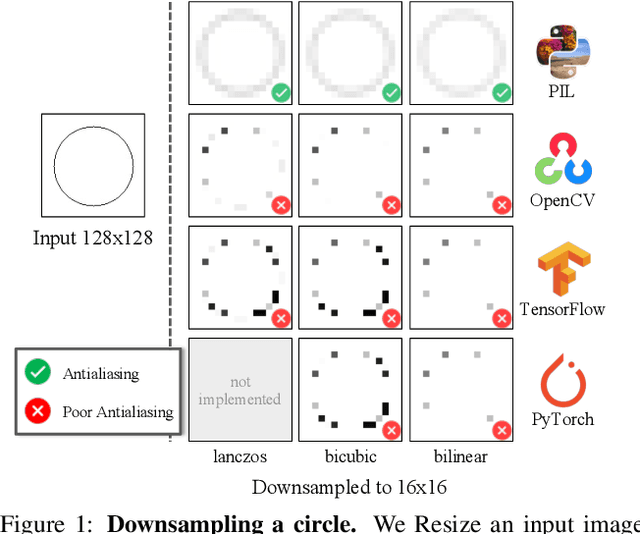
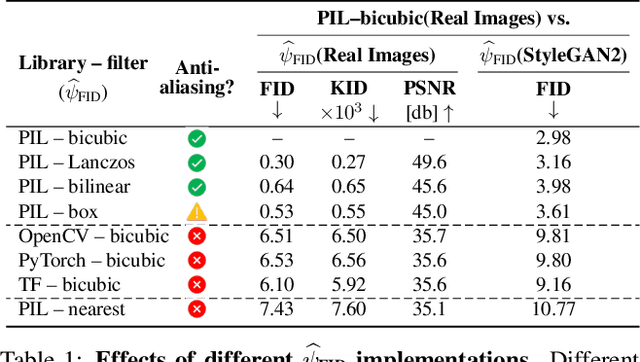
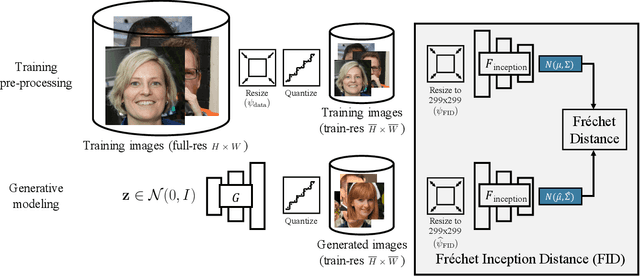
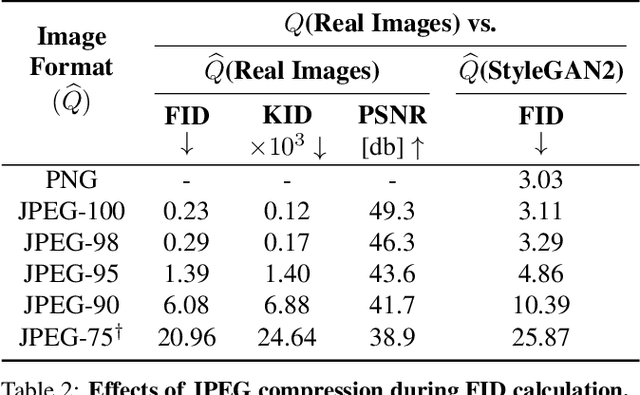
We investigate the sensitivity of the Fr\'echet Inception Distance (FID) score to inconsistent and often incorrect implementations across different image processing libraries. FID score is widely used to evaluate generative models, but each FID implementation uses a different low-level image processing process. Image resizing functions in commonly-used deep learning libraries often introduce aliasing artifacts. We observe that numerous subtle choices need to be made for FID calculation and a lack of consistencies in these choices can lead to vastly different FID scores. In particular, we show that the following choices are significant: (1) selecting what image resizing library to use, (2) choosing what interpolation kernel to use, (3) what encoding to use when representing images. We additionally outline numerous common pitfalls that should be avoided and provide recommendations for computing the FID score accurately. We provide an easy-to-use optimized implementation of our proposed recommendations in the accompanying code.
Thumbnail: A Novel Data Augmentation for Convolutional Neural Network
Mar 09, 2021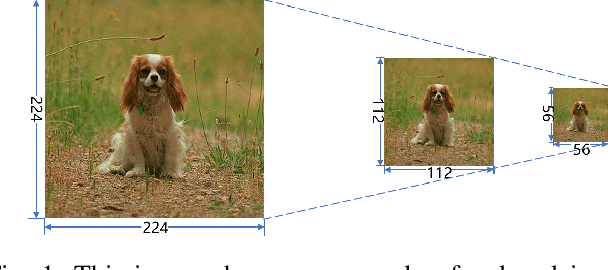


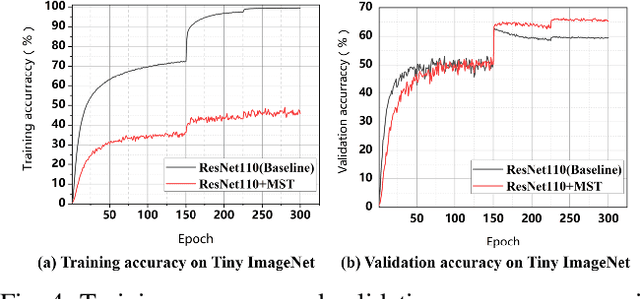
In this paper, we propose a new data augmentation strategy named Thumbnail, which aims to strengthen the network's capture of global features. We get a generated image by reducing an image to a certain size, which is called as the thumbnail, and pasting it in the random position of the original image. The generated image not only retains most of the original image information but also has the global information in the thumbnail. Furthermore, we find that the idea of thumbnail can be perfectly integrated with Mixed Sample Data Augmentation, so we paste the thumbnail in another image where the ground truth labels are also mixed with a certain weight, which makes great achievements on various computer vision tasks. Extensive experiments show that Thumbnail works better than the state-of-the-art augmentation strategies across classification, fine-grained image classification, and object detection. On ImageNet classification, ResNet50 architecture with our method achieves 79.21% accuracy, which is more than 2.89% improvement on the baseline.
Long-Short Temporal Contrastive Learning of Video Transformers
Jun 17, 2021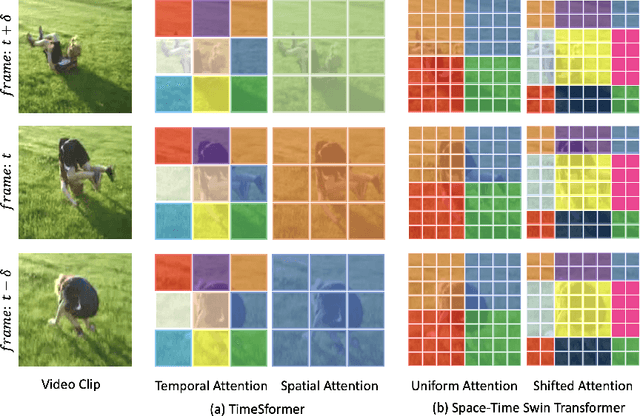

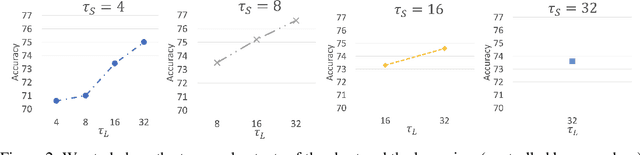
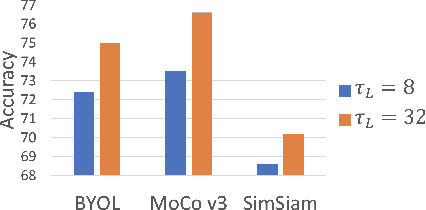
Video transformers have recently emerged as a competitive alternative to 3D CNNs for video understanding. However, due to their large number of parameters and reduced inductive biases, these models require supervised pretraining on large-scale image datasets to achieve top performance. In this paper, we empirically demonstrate that self-supervised pretraining of video transformers on video-only datasets can lead to action recognition results that are on par or better than those obtained with supervised pretraining on large-scale image datasets, even massive ones such as ImageNet-21K. Since transformer-based models are effective at capturing dependencies over extended temporal spans, we propose a simple learning procedure that forces the model to match a long-term view to a short-term view of the same video. Our approach, named Long-Short Temporal Contrastive Learning (LSTCL), enables video transformers to learn an effective clip-level representation by predicting temporal context captured from a longer temporal extent. To demonstrate the generality of our findings, we implement and validate our approach under three different self-supervised contrastive learning frameworks (MoCo v3, BYOL, SimSiam) using two distinct video-transformer architectures, including an improved variant of the Swin Transformer augmented with space-time attention. We conduct a thorough ablation study and show that LSTCL achieves competitive performance on multiple video benchmarks and represents a convincing alternative to supervised image-based pretraining.
SAFIN: Arbitrary Style Transfer With Self-Attentive Factorized Instance Normalization
May 20, 2021


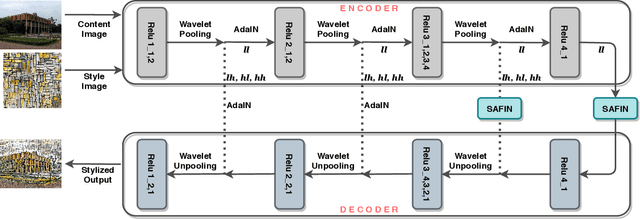
Artistic style transfer aims to transfer the style characteristics of one image onto another image while retaining its content. Existing approaches commonly leverage various normalization techniques, although these face limitations in adequately transferring diverse textures to different spatial locations. Self-Attention-based approaches have tackled this issue with partial success but suffer from unwanted artifacts. Motivated by these observations, this paper aims to combine the best of both worlds: self-attention and normalization. That yields a new plug-and-play module that we name Self-Attentive Factorized Instance Normalization (SAFIN). SAFIN is essentially a spatially adaptive normalization module whose parameters are inferred through attention on the content and style image. We demonstrate that plugging SAFIN into the base network of another state-of-the-art method results in enhanced stylization. We also develop a novel base network composed of Wavelet Transform for multi-scale style transfer, which when combined with SAFIN, produces visually appealing results with lesser unwanted textures.
Camera Calibration through Camera Projection Loss
Oct 07, 2021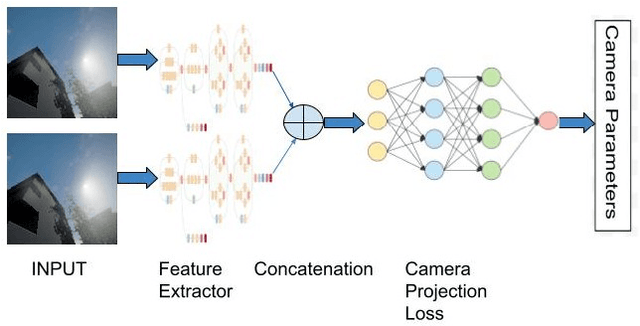



Camera calibration is a necessity in various tasks including 3D reconstruction, hand-eye coordination for a robotic interaction, autonomous driving, etc. In this work we propose a novel method to predict extrinsic (baseline, pitch, and translation), intrinsic (focal length and principal point offset) parameters using an image pair. Unlike existing methods, instead of designing an end-to-end solution, we proposed a new representation that incorporates camera model equations as a neural network in multi-task learning framework. We estimate the desired parameters via novel \emph{camera projection loss} (CPL) that uses the camera model neural network to reconstruct the 3D points and uses the reconstruction loss to estimate the camera parameters. To the best of our knowledge, ours is the first method to jointly estimate both the intrinsic and extrinsic parameters via a multi-task learning methodology that combines analytical equations in learning framework for the estimation of camera parameters. We also proposed a novel dataset using CARLA Simulator. Empirically, we demonstrate that our proposed approach achieves better performance with respect to both deep learning-based and traditional methods on 7 out of 10 parameters evaluated using both synthetic and real data. Our code and generated dataset will be made publicly available to facilitate future research.
SOLVER: Scene-Object Interrelated Visual Emotion Reasoning Network
Oct 24, 2021
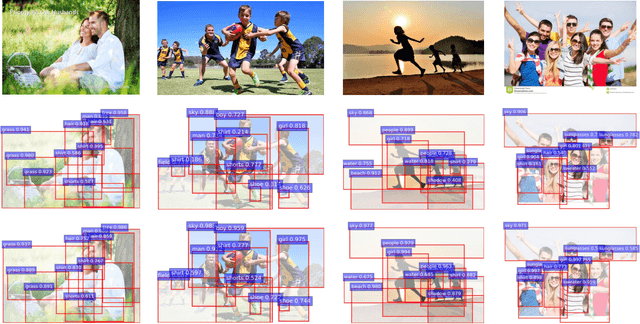


Visual Emotion Analysis (VEA) aims at finding out how people feel emotionally towards different visual stimuli, which has attracted great attention recently with the prevalence of sharing images on social networks. Since human emotion involves a highly complex and abstract cognitive process, it is difficult to infer visual emotions directly from holistic or regional features in affective images. It has been demonstrated in psychology that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. Inspired by this, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict emotions from images. To mine the emotional relationships between distinct objects, we first build up an Emotion Graph based on semantic concepts and visual features. Then, we conduct reasoning on the Emotion Graph using Graph Convolutional Network (GCN), yielding emotion-enhanced object features. We also design a Scene-Object Fusion Module to integrate scenes and objects, which exploits scene features to guide the fusion process of object features with the proposed scene-based attention mechanism. Extensive experiments and comparisons are conducted on eight public visual emotion datasets, and the results demonstrate that the proposed SOLVER consistently outperforms the state-of-the-art methods by a large margin. Ablation studies verify the effectiveness of our method and visualizations prove its interpretability, which also bring new insight to explore the mysteries in VEA. Notably, we further discuss SOLVER on three other potential datasets with extended experiments, where we validate the robustness of our method and notice some limitations of it.
* Accepted by TIP
Contrastive learning of global and local features for medical image segmentation with limited annotations
Jun 18, 2020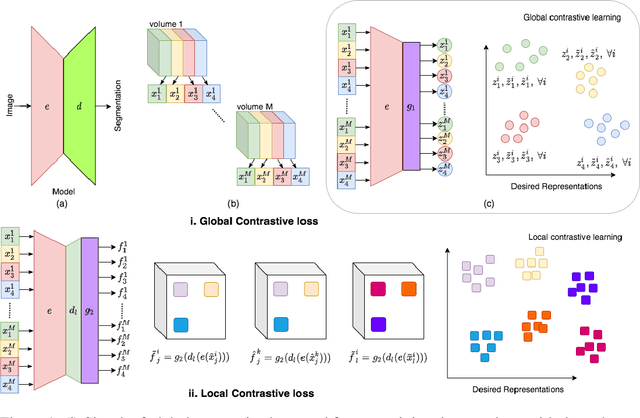
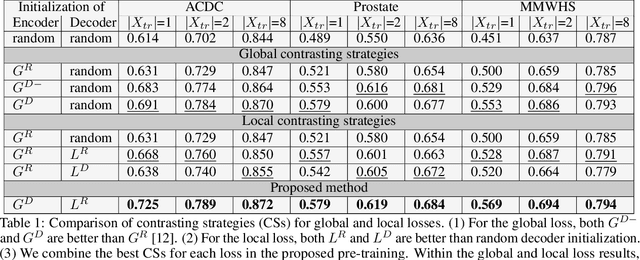
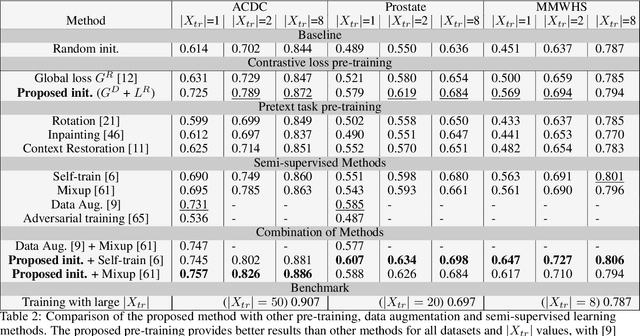
A key requirement for the success of supervised deep learning is a large labeled dataset - a condition that is difficult to meet in medical image analysis. Self-supervised learning (SSL) can help in this regard by providing a strategy to pre-train a neural network with unlabeled data, followed by fine-tuning for a downstream task with limited annotations. Contrastive learning, a particular variant of SSL, is a powerful technique for learning image-level representations. In this work, we propose strategies for extending the contrastive learning framework for segmentation of volumetric medical images in the semi-supervised setting with limited annotations, by leveraging domain-specific and problem-specific cues. Specifically, we propose (1) novel contrasting strategies that leverage structural similarity across volumetric medical images (domain-specific cue) and (2) a local version of the contrastive loss to learn distinctive representations of local regions that are useful for per-pixel segmentation (problem-specific cue). We carry out an extensive evaluation on three Magnetic Resonance Imaging (MRI) datasets. In the limited annotation setting, the proposed method yields substantial improvements compared to other self-supervision and semi-supervised learning techniques. When combined with a simple data augmentation technique, the proposed method reaches within 8% of benchmark performance using only two labeled MRI volumes for training, corresponding to only 4% (for ACDC) of the training data used to train the benchmark.
The Connection between Out-of-Distribution Generalization and Privacy of ML Models
Oct 07, 2021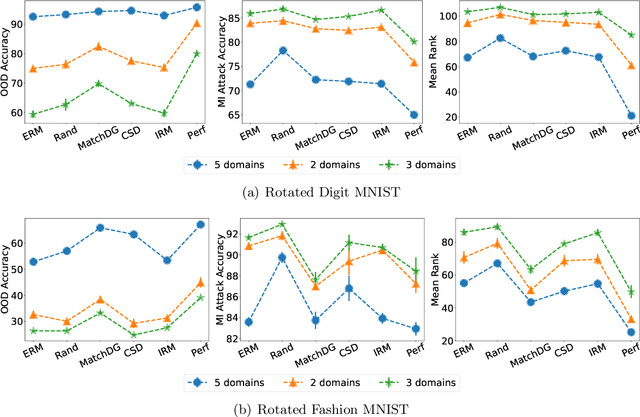

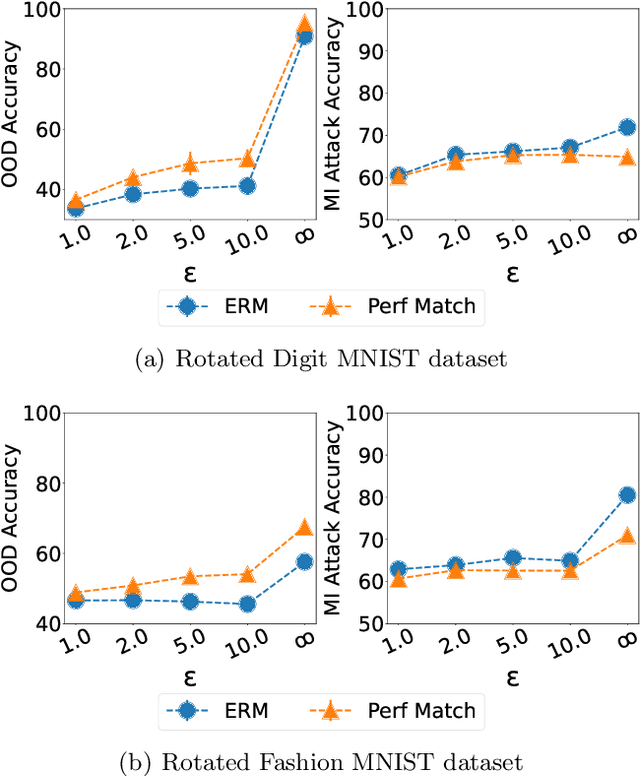
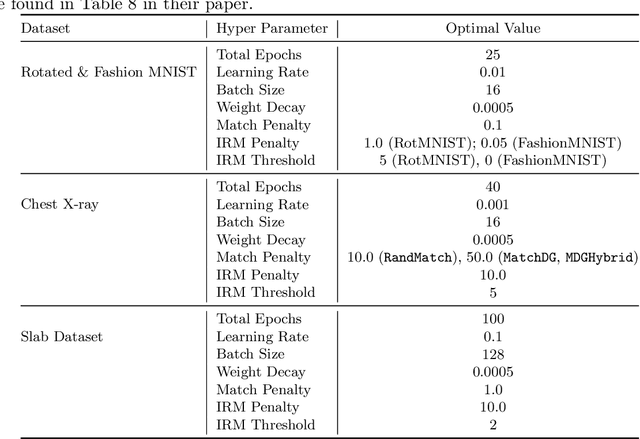
With the goal of generalizing to out-of-distribution (OOD) data, recent domain generalization methods aim to learn "stable" feature representations whose effect on the output remains invariant across domains. Given the theoretical connection between generalization and privacy, we ask whether better OOD generalization leads to better privacy for machine learning models, where privacy is measured through robustness to membership inference (MI) attacks. In general, we find that the relationship does not hold. Through extensive evaluation on a synthetic dataset and image datasets like MNIST, Fashion-MNIST, and Chest X-rays, we show that a lower OOD generalization gap does not imply better robustness to MI attacks. Instead, privacy benefits are based on the extent to which a model captures the stable features. A model that captures stable features is more robust to MI attacks than models that exhibit better OOD generalization but do not learn stable features. Further, for the same provable differential privacy guarantees, a model that learns stable features provides higher utility as compared to others. Our results offer the first extensive empirical study connecting stable features and privacy, and also have a takeaway for the domain generalization community; MI attack can be used as a complementary metric to measure model quality.