 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Building Segmentation for Off-Nadir Satellite Imagery
Sep 08, 2021
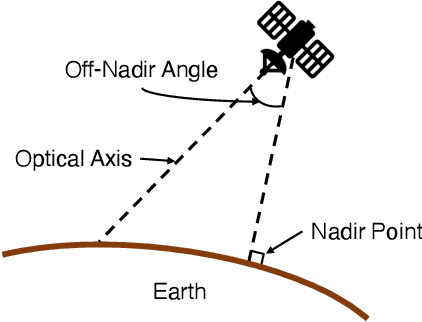
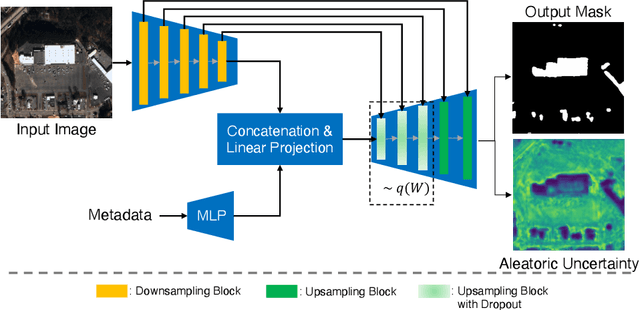
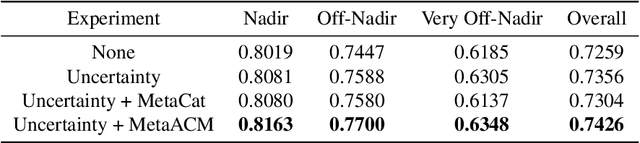
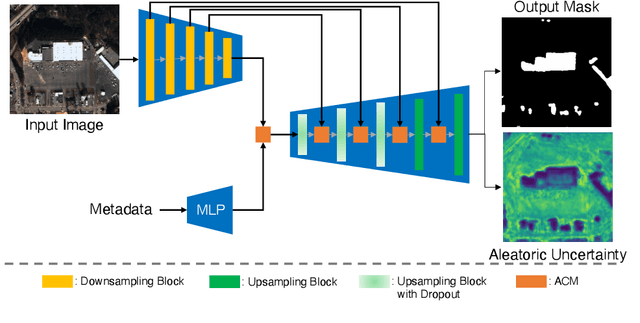
Automatic building segmentation is an important task for satellite imagery analysis and scene understanding. Most existing segmentation methods focus on the case where the images are taken from directly overhead (i.e., low off-nadir/viewing angle). These methods often fail to provide accurate results on satellite images with larger off-nadir angles due to the higher noise level and lower spatial resolution. In this paper, we propose a method that is able to provide accurate building segmentation for satellite imagery captured from a large range of off-nadir angles. Based on Bayesian deep learning, we explicitly design our method to learn the data noise via aleatoric and epistemic uncertainty modeling. Satellite image metadata (e.g., off-nadir angle and ground sample distance) is also used in our model to further improve the result. We show that with uncertainty modeling and metadata injection, our method achieves better performance than the baseline method, especially for noisy images taken from large off-nadir angles.
Test-time Batch Statistics Calibration for Covariate Shift
Oct 06, 2021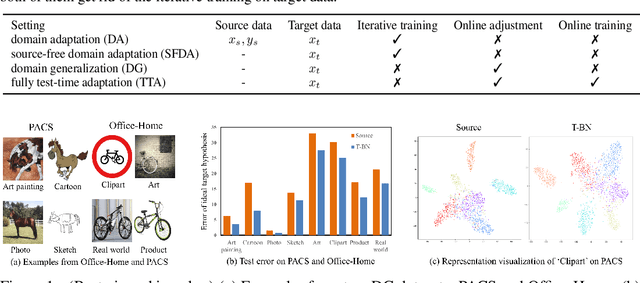

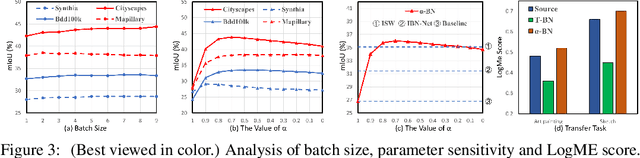
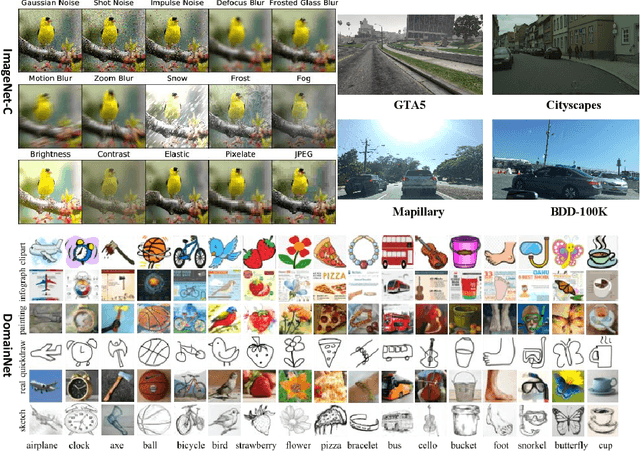
Deep neural networks have a clear degradation when applying to the unseen environment due to the covariate shift. Conventional approaches like domain adaptation requires the pre-collected target data for iterative training, which is impractical in real-world applications. In this paper, we propose to adapt the deep models to the novel environment during inference. An previous solution is test time normalization, which substitutes the source statistics in BN layers with the target batch statistics. However, we show that test time normalization may potentially deteriorate the discriminative structures due to the mismatch between target batch statistics and source parameters. To this end, we present a general formulation $\alpha$-BN to calibrate the batch statistics by mixing up the source and target statistics for both alleviating the domain shift and preserving the discriminative structures. Based on $\alpha$-BN, we further present a novel loss function to form a unified test time adaptation framework Core, which performs the pairwise class correlation online optimization. Extensive experiments show that our approaches achieve the state-of-the-art performance on total twelve datasets from three topics, including model robustness to corruptions, domain generalization on image classification and semantic segmentation. Particularly, our $\alpha$-BN improves 28.4\% to 43.9\% on GTA5 $\rightarrow$ Cityscapes without any training, even outperforms the latest source-free domain adaptation method.
AnonySIGN: Novel Human Appearance Synthesis for Sign Language Video Anonymisation
Jul 23, 2021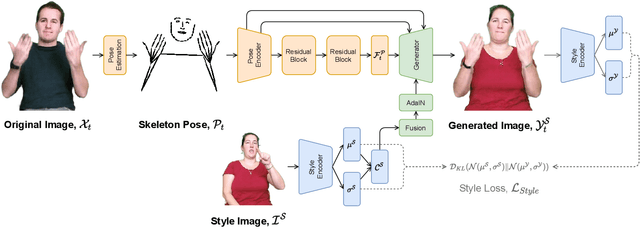
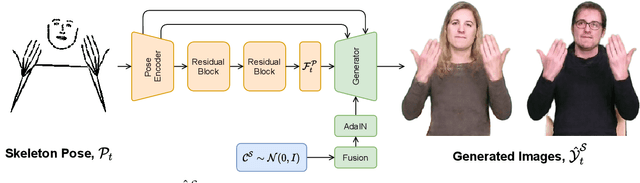


The visual anonymisation of sign language data is an essential task to address privacy concerns raised by large-scale dataset collection. Previous anonymisation techniques have either significantly affected sign comprehension or required manual, labour-intensive work. In this paper, we formally introduce the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymise the visual appearance of a sign language video whilst retaining the meaning of the original sign language sequence. To tackle SLVA, we propose AnonySign, a novel automatic approach for visual anonymisation of sign language data. We first extract pose information from the source video to remove the original signer appearance. We next generate a photo-realistic sign language video of a novel appearance from the pose sequence, using image-to-image translation methods in a conditional variational autoencoder framework. An approximate posterior style distribution is learnt, which can be sampled from to synthesise novel human appearances. In addition, we propose a novel \textit{style loss} that ensures style consistency in the anonymised sign language videos. We evaluate AnonySign for the SLVA task with extensive quantitative and qualitative experiments highlighting both realism and anonymity of our novel human appearance synthesis. In addition, we formalise an anonymity perceptual study as an evaluation criteria for the SLVA task and showcase that video anonymisation using AnonySign retains the original sign language content.
Gray Cycles of Maximum Length Related to k-Character Substitutions
Aug 31, 2021Given a word binary relation $\tau$ we define a $\tau$-Gray cycle over a finite language $X$ to be a permutation $\left(w_{[i]}\right)_{0\le i\le |X|-1}$ of $X$ such that each word $w_i$ is an image of the previous word $w_{i-1}$ by $\tau$. In that framework, we introduce the complexity measure $\lambda(n)$, equal to the largest cardinality of a language $X$ having words of length at most $n$, and such that a $\tau$-Gray cycle over $X$ exists. The present paper is concerned with the relation $\tau=\sigma_k$, the so-called $k$-character substitution, where $(u,v)$ belongs to $\sigma_k$ if, and only if, the Hamming distance of $u$ and $v$ is $k$. We compute the bound $\lambda(n)$ for all cases of the alphabet cardinality and the argument $n$.
Integrating Text and Image: Determining Multimodal Document Intent in Instagram Posts
Apr 19, 2019
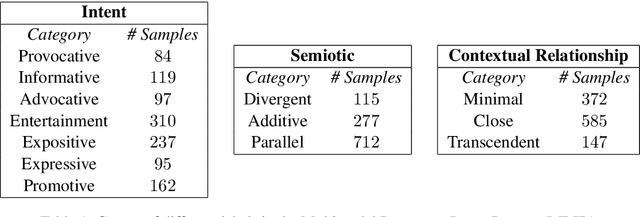

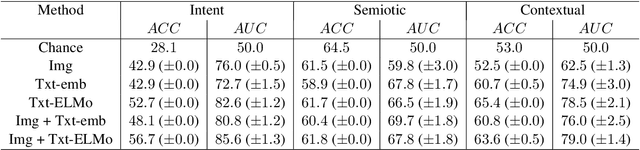
Computing author intent from multimodal data like Instagram posts requires modeling a complex relationship between text and image. For example a caption might reflect ironically on the image, so neither the caption nor the image is a mere transcript of the other. Instead they combine -- via what has been called meaning multiplication -- to create a new meaning that has a more complex relation to the literal meanings of text and image. Here we introduce a multimodal dataset of 1299 Instagram post labeled for three orthogonal taxonomies: the authorial intent behind the image-caption pair, the contextual relationship between the literal meanings of the image and caption, and the semiotic relationship between the signified meanings of the image and caption. We build a baseline deep multimodal classifier to validate the taxonomy, showing that employing both text and image improves intent detection by 8% compared to using only image modality, demonstrating the commonality of non-intersective meaning multiplication. Our dataset offers an important resource for the study of the rich meanings that results from pairing text and image.
SRR-Net: A Super-Resolution-Involved Reconstruction Method for High Resolution MR Imaging
Apr 13, 2021
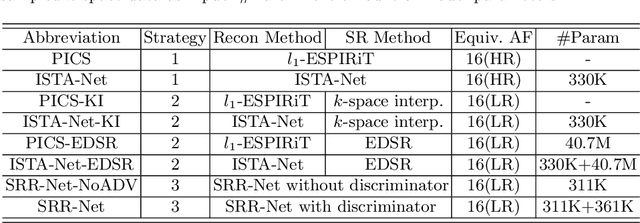
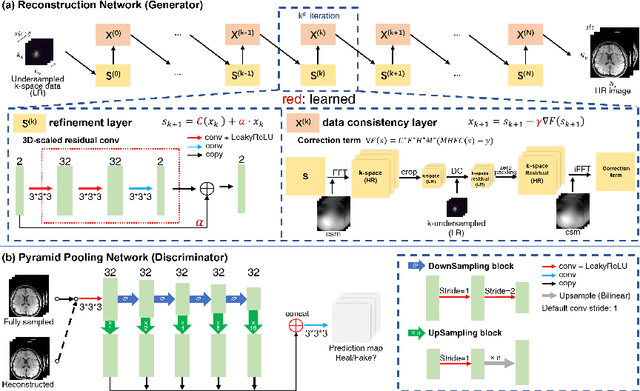
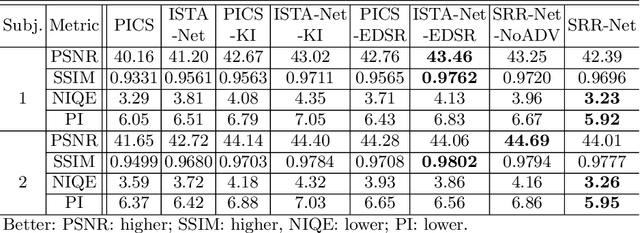
Improving the image resolution and acquisition speed of magnetic resonance imaging (MRI) is a challenging problem. There are mainly two strategies dealing with the speed-resolution trade-off: (1) $k$-space undersampling with high-resolution acquisition, and (2) a pipeline of lower resolution image reconstruction and image super-resolution. However, these approaches either have limited performance at certain high acceleration factor or suffer from the error accumulation of two-step structure. In this paper, we combine the idea of MR reconstruction and image super-resolution, and work on recovering HR images from low-resolution under-sampled $k$-space data directly. Particularly, the SR-involved reconstruction can be formulated as a variational problem, and a learnable network unrolled from its solution algorithm is proposed. A discriminator was introduced to enhance the detail refining performance. Experiment results using in-vivo HR multi-coil brain data indicate that the proposed SRR-Net is capable of recovering high-resolution brain images with both good visual quality and perceptual quality.
GIFAIR-FL: An Approach for Group and Individual Fairness in Federated Learning
Aug 05, 2021
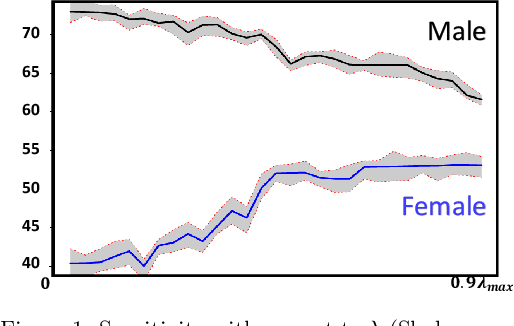
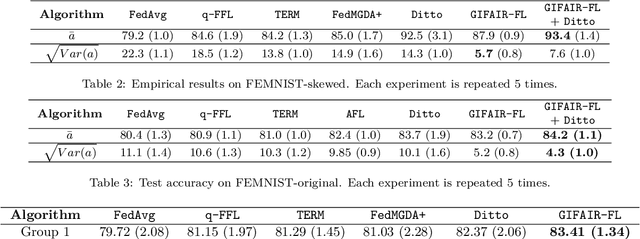
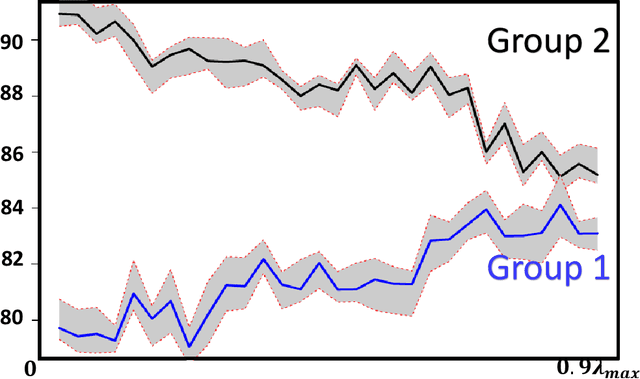
In this paper we propose \texttt{GIFAIR-FL}: an approach that imposes group and individual fairness to federated learning settings. By adding a regularization term, our algorithm penalizes the spread in the loss of client groups to drive the optimizer to fair solutions. Theoretically, we show convergence in non-convex and strongly convex settings. Our convergence guarantees hold for both $i.i.d.$ and non-$i.i.d.$ data. To demonstrate the empirical performance of our algorithm, we apply our method on image classification and text prediction tasks. Compared to existing algorithms, our method shows improved fairness results while retaining superior or similar prediction accuracy.
ACAE-REMIND for Online Continual Learning with Compressed Feature Replay
May 18, 2021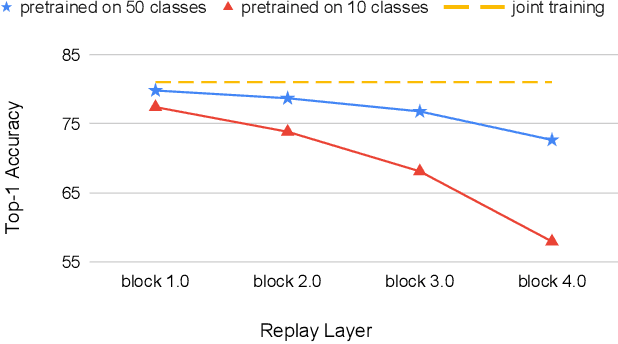

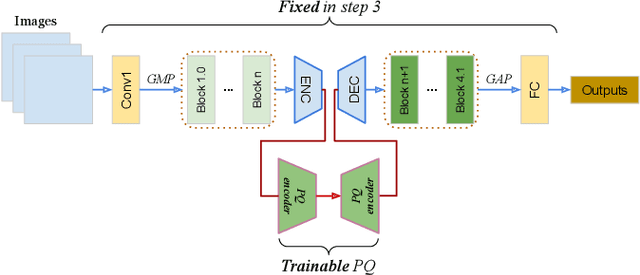
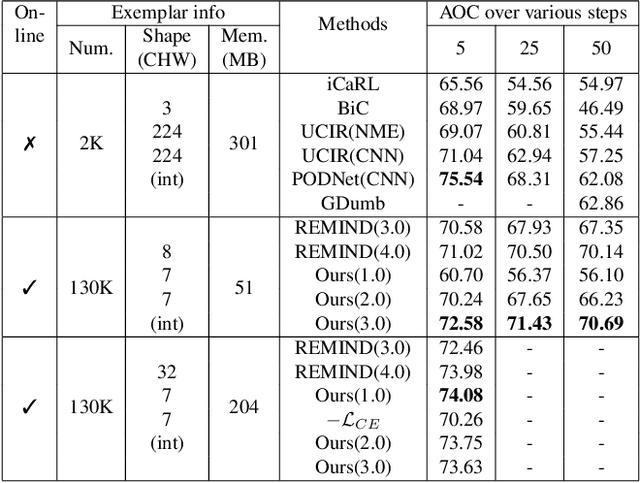
Online continual learning aims to learn from a non-IID stream of data from a number of different tasks, where the learner is only allowed to consider data once. Methods are typically allowed to use a limited buffer to store some of the images in the stream. Recently, it was found that feature replay, where an intermediate layer representation of the image is stored (or generated) leads to superior results than image replay, while requiring less memory. Quantized exemplars can further reduce the memory usage. However, a drawback of these methods is that they use a fixed (or very intransigent) backbone network. This significantly limits the learning of representations that can discriminate between all tasks. To address this problem, we propose an auxiliary classifier auto-encoder (ACAE) module for feature replay at intermediate layers with high compression rates. The reduced memory footprint per image allows us to save more exemplars for replay. In our experiments, we conduct task-agnostic evaluation under online continual learning setting and get state-of-the-art performance on ImageNet-Subset, CIFAR100 and CIFAR10 dataset.
CCVS: Context-aware Controllable Video Synthesis
Jul 16, 2021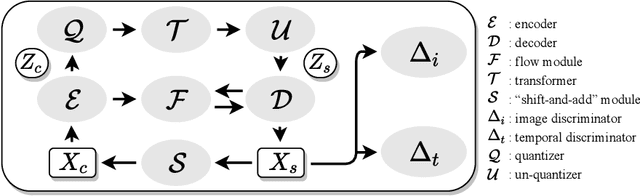
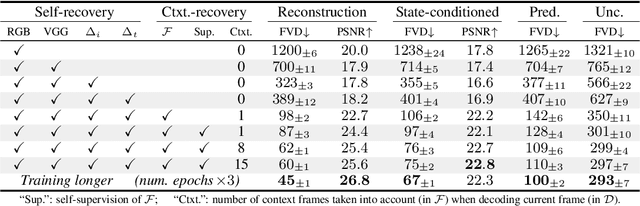
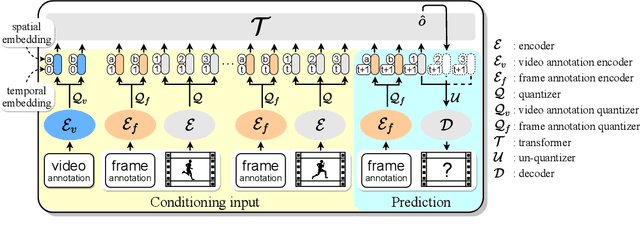
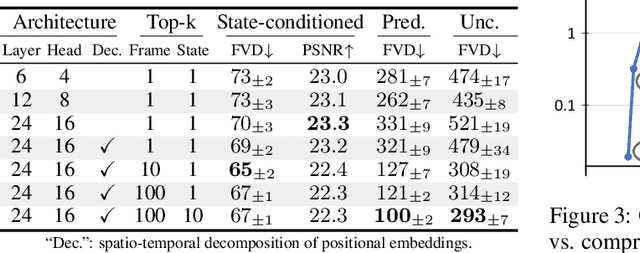
This presentation introduces a self-supervised learning approach to the synthesis of new video clips from old ones, with several new key elements for improved spatial resolution and realism: It conditions the synthesis process on contextual information for temporal continuity and ancillary information for fine control. The prediction model is doubly autoregressive, in the latent space of an autoencoder for forecasting, and in image space for updating contextual information, which is also used to enforce spatio-temporal consistency through a learnable optical flow module. Adversarial training of the autoencoder in the appearance and temporal domains is used to further improve the realism of its output. A quantizer inserted between the encoder and the transformer in charge of forecasting future frames in latent space (and its inverse inserted between the transformer and the decoder) adds even more flexibility by affording simple mechanisms for handling multimodal ancillary information for controlling the synthesis process (eg, a few sample frames, an audio track, a trajectory in image space) and taking into account the intrinsically uncertain nature of the future by allowing multiple predictions. Experiments with an implementation of the proposed approach give very good qualitative and quantitative results on multiple tasks and standard benchmarks.
Cascaded Robust Learning at Imperfect Labels for Chest X-ray Segmentation
Apr 05, 2021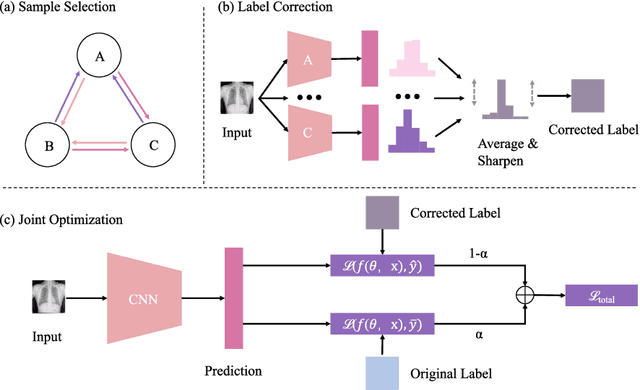
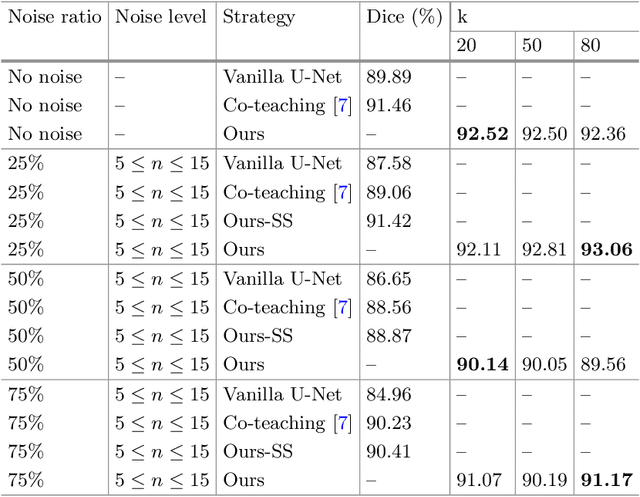

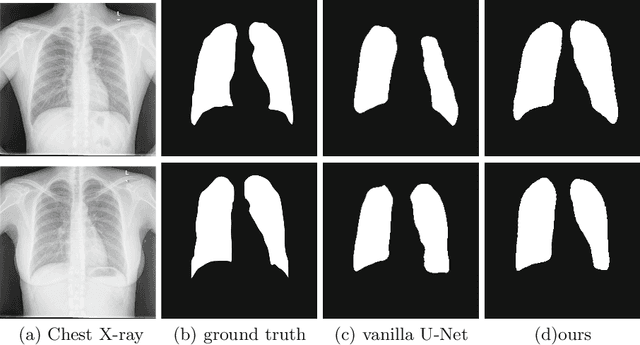
The superior performance of CNN on medical image analysis heavily depends on the annotation quality, such as the number of labeled image, the source of image, and the expert experience. The annotation requires great expertise and labour. To deal with the high inter-rater variability, the study of imperfect label has great significance in medical image segmentation tasks. In this paper, we present a novel cascaded robust learning framework for chest X-ray segmentation with imperfect annotation. Our model consists of three independent network, which can effectively learn useful information from the peer networks. The framework includes two stages. In the first stage, we select the clean annotated samples via a model committee setting, the networks are trained by minimizing a segmentation loss using the selected clean samples. In the second stage, we design a joint optimization framework with label correction to gradually correct the wrong annotation and improve the network performance. We conduct experiments on the public chest X-ray image datasets collected by Shenzhen Hospital. The results show that our methods could achieve a significant improvement on the accuracy in segmentation tasks compared to the previous methods.