 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Hybrid Frequency-domain/Image-domain Deep Network for Magnetic Resonance Image Reconstruction
Oct 30, 2018

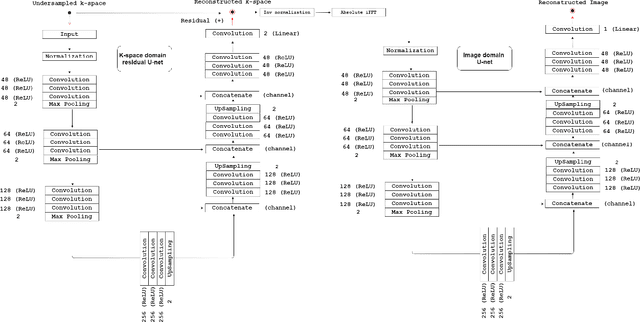
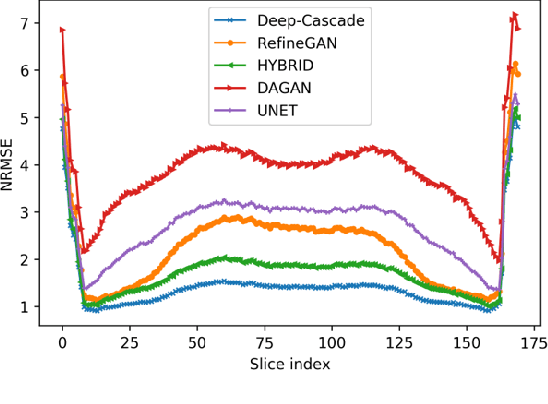
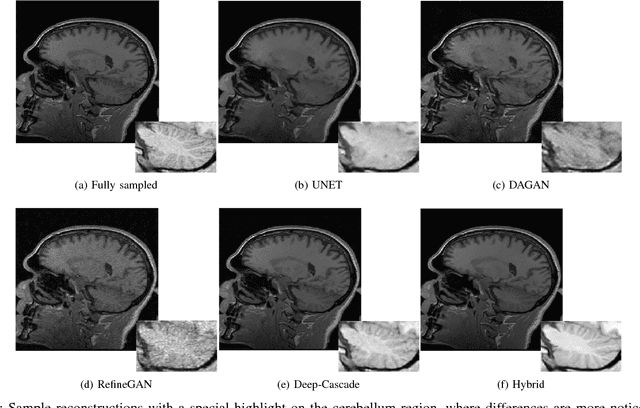
Decreasing magnetic resonance (MR) image acquisition times can potentially reduce procedural cost and make MR examinations more accessible. Compressed sensing (CS)-based image reconstruction methods, for example, decrease MR acquisition time by reconstructing high-quality images from data that were originally sampled at rates inferior to the Nyquist-Shannon sampling theorem. In this work we propose a hybrid architecture that works both in the k-space (or frequency-domain) and the image (or spatial) domains. Our network is composed of a complex-valued residual U-net in the k-space domain, an inverse Fast Fourier Transform (iFFT) operation, and a real-valued U-net in the image domain. Our experiments demonstrated, using MR raw k-space data, that the proposed hybrid approach can potentially improve CS reconstruction compared to deep-learning networks that operate only in the image domain. In this study we compare our method with four previously published deep neural networks and examine their ability to reconstruct images that are subsequently used to generate regional volume estimates. We evaluated undersampling ratios of 75% and 80%. Our technique was ranked second in the quantitative analysis, but qualitative analysis indicated that our reconstruction performed the best in hard to reconstruct regions, such as the cerebellum. All images reconstructed with our method were successfully post-processed, and showed good volumetry agreement compared with the fully sampled reconstruction measures.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021



In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.
Matching Underwater Sonar Images by the Learned Descriptor Based on Style Transfer Method
Aug 27, 2021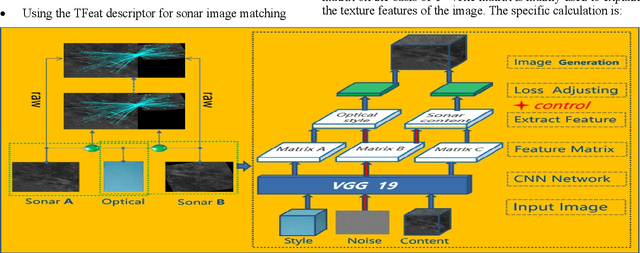
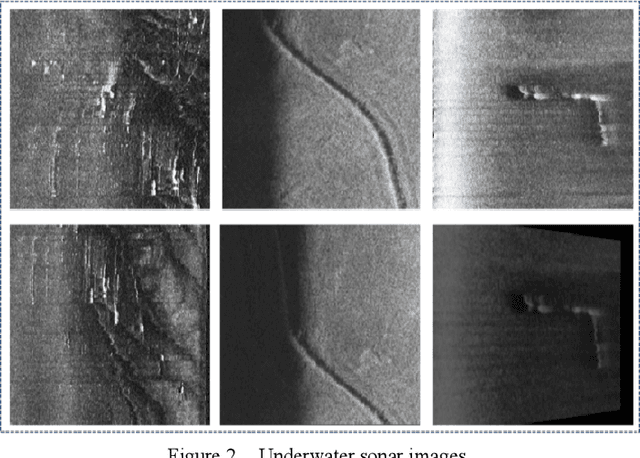

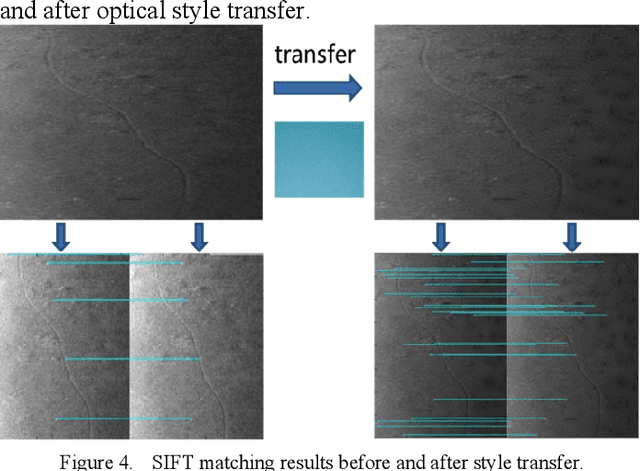
This paper proposes a method that combines the style transfer technique and the learned descriptor to enhance the matching performances of underwater sonar images. In the field of underwater vision, sonar is currently the most effective long-distance detection sensor, it has excellent performances in map building and target search tasks. However, the traditional image matching algorithms are all developed based on optical images. In order to solve this contradiction, the style transfer method is used to convert the sonar images into optical styles, and at the same time, the learned descriptor with excellent expressiveness for sonar images matching is introduced. Experiments show that this method significantly enhances the matching quality of sonar images. In addition, it also provides new ideas for the preprocessing of underwater sonar images by using the style transfer approach.
Joint haze image synthesis and dehazing with mmd-vae losses
May 15, 2019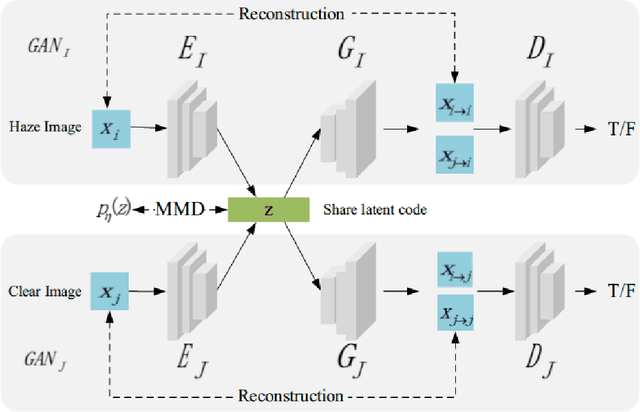
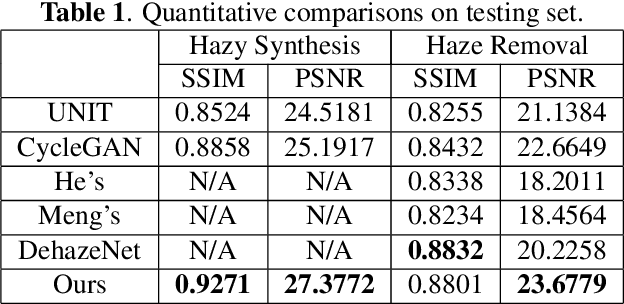


Fog and haze are weathers with low visibility which are adversarial to the driving safety of intelligent vehicles equipped with optical sensors like cameras and LiDARs. Therefore image dehazing for perception enhancement and haze image synthesis for testing perception abilities are equivalently important in the development of such autonomous driving systems. From the view of image translation, these two problems are essentially dual with each other, which have the potentiality to be solved jointly. In this paper, we propose an unsupervised Image-to-Image Translation framework based on Variational Autoencoders (VAE) and Generative Adversarial Nets (GAN) to handle haze image synthesis and haze removal simultaneously. Since the KL divergence in the VAE objectives could not guarantee the optimal mapping under imbalanced and unpaired training samples with limited size, Maximum mean discrepancy (MMD) based VAE is utilized to ensure the translating consistency in both directions. The comprehensive analysis on both synthesis and dehazing performance of our method demonstrate the feasibility and practicability of the proposed method.
Image-Based Geo-Localization Using Satellite Imagery
Mar 04, 2019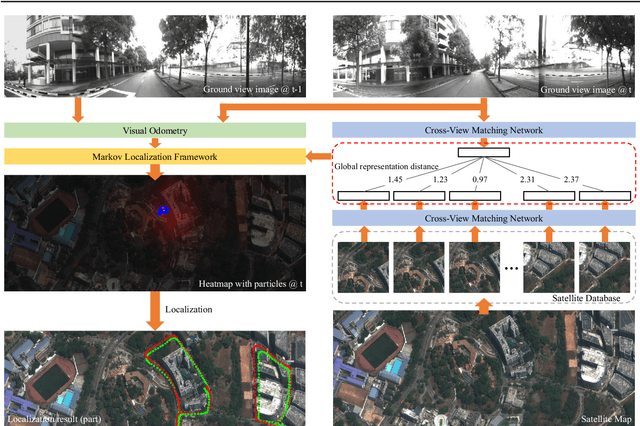
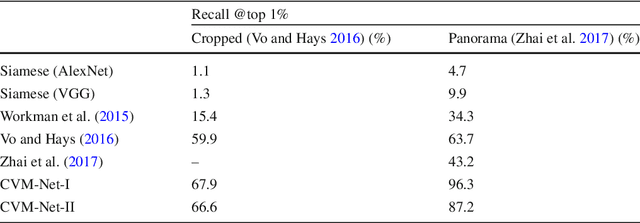
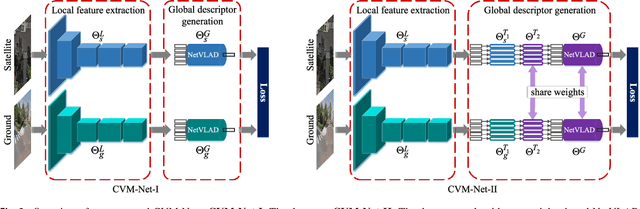

The problem of localization on a geo-referenced satellite map given a query ground view image is useful yet remains challenging due to the drastic change in viewpoint. To this end, in this paper we work on the extension of our earlier work on the Cross-View Matching Network (CVM-Net) for the ground-to-aerial image matching task since the traditional image descriptors fail due to the drastic viewpoint change. In particular, we show more extensive experimental results and analyses of the network architecture on our CVM-Net. Furthermore, we propose a Markov localization framework that enforces the temporal consistency between image frames to enhance the geo-localization results in the case where a video stream of ground view images is available. Experimental results show that our proposed Markov localization framework can continuously localize the vehicle within a small error on our Singapore dataset.
KATANA: Simple Post-Training Robustness Using Test Time Augmentations
Sep 16, 2021
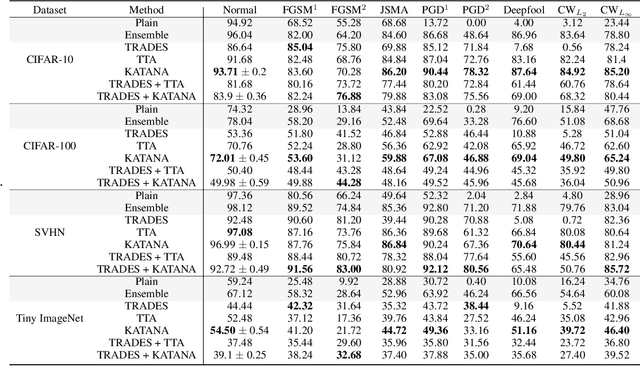

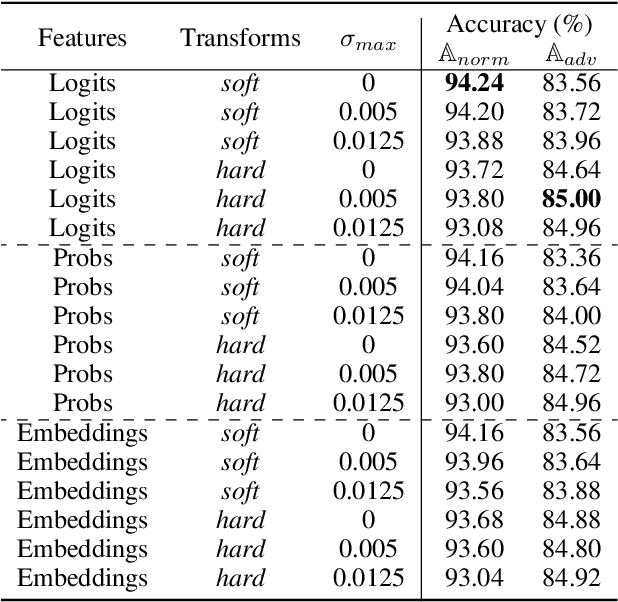
Although Deep Neural Networks (DNNs) achieve excellent performance on many real-world tasks, they are highly vulnerable to adversarial attacks. A leading defense against such attacks is adversarial training, a technique in which a DNN is trained to be robust to adversarial attacks by introducing adversarial noise to its input. This procedure is effective but must be done during the training phase. In this work, we propose a new simple and easy-to-use technique, KATANA, for robustifying an existing pretrained DNN without modifying its weights. For every image, we generate N randomized Test Time Augmentations (TTAs) by applying diverse color, blur, noise, and geometric transforms. Next, we utilize the DNN's logits output to train a simple random forest classifier to predict the real class label. Our strategy achieves state-of-the-art adversarial robustness on diverse attacks with minimal compromise on the natural images' classification. We test KATANA also against two adaptive white-box attacks and it shows excellent results when combined with adversarial training. Code is available in https://github.com/giladcohen/KATANA.
Improving Building Segmentation for Off-Nadir Satellite Imagery
Sep 08, 2021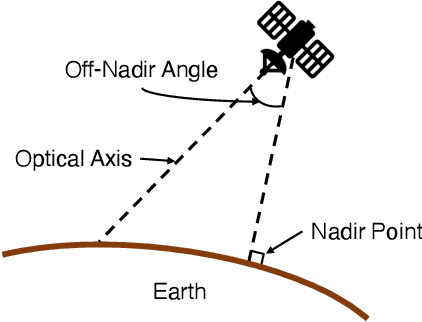
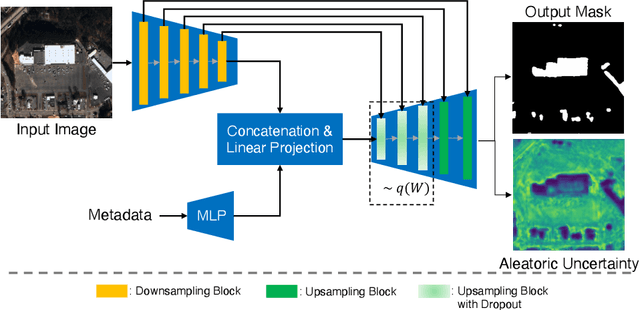
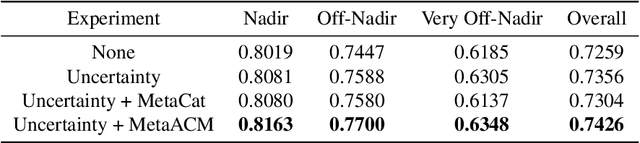
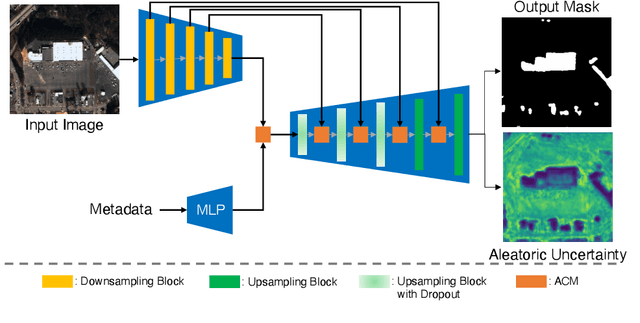
Automatic building segmentation is an important task for satellite imagery analysis and scene understanding. Most existing segmentation methods focus on the case where the images are taken from directly overhead (i.e., low off-nadir/viewing angle). These methods often fail to provide accurate results on satellite images with larger off-nadir angles due to the higher noise level and lower spatial resolution. In this paper, we propose a method that is able to provide accurate building segmentation for satellite imagery captured from a large range of off-nadir angles. Based on Bayesian deep learning, we explicitly design our method to learn the data noise via aleatoric and epistemic uncertainty modeling. Satellite image metadata (e.g., off-nadir angle and ground sample distance) is also used in our model to further improve the result. We show that with uncertainty modeling and metadata injection, our method achieves better performance than the baseline method, especially for noisy images taken from large off-nadir angles.
Test-time Batch Statistics Calibration for Covariate Shift
Oct 06, 2021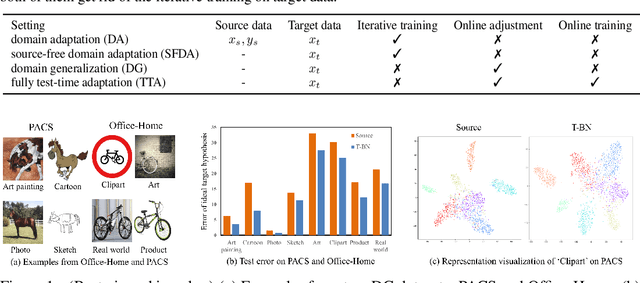

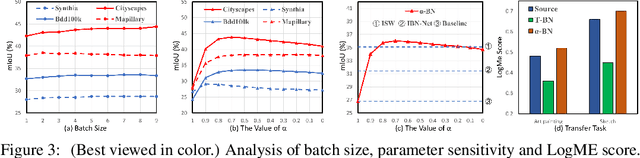
Deep neural networks have a clear degradation when applying to the unseen environment due to the covariate shift. Conventional approaches like domain adaptation requires the pre-collected target data for iterative training, which is impractical in real-world applications. In this paper, we propose to adapt the deep models to the novel environment during inference. An previous solution is test time normalization, which substitutes the source statistics in BN layers with the target batch statistics. However, we show that test time normalization may potentially deteriorate the discriminative structures due to the mismatch between target batch statistics and source parameters. To this end, we present a general formulation $\alpha$-BN to calibrate the batch statistics by mixing up the source and target statistics for both alleviating the domain shift and preserving the discriminative structures. Based on $\alpha$-BN, we further present a novel loss function to form a unified test time adaptation framework Core, which performs the pairwise class correlation online optimization. Extensive experiments show that our approaches achieve the state-of-the-art performance on total twelve datasets from three topics, including model robustness to corruptions, domain generalization on image classification and semantic segmentation. Particularly, our $\alpha$-BN improves 28.4\% to 43.9\% on GTA5 $\rightarrow$ Cityscapes without any training, even outperforms the latest source-free domain adaptation method.
Image search using multilingual texts: a cross-modal learning approach between image and text
May 14, 2019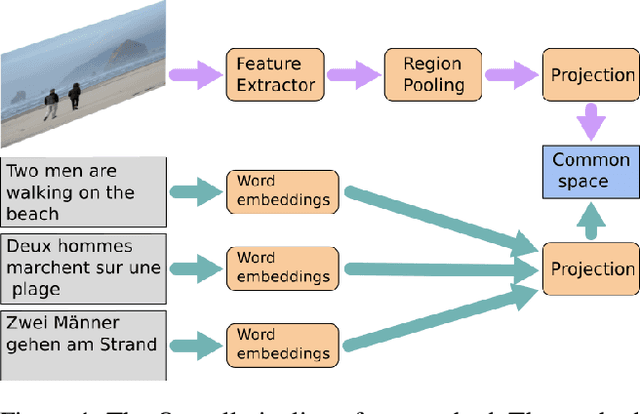
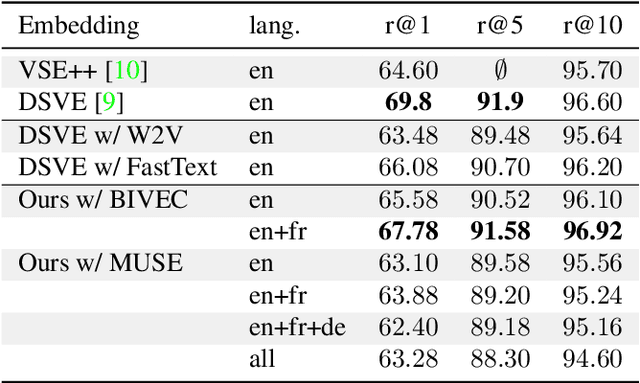
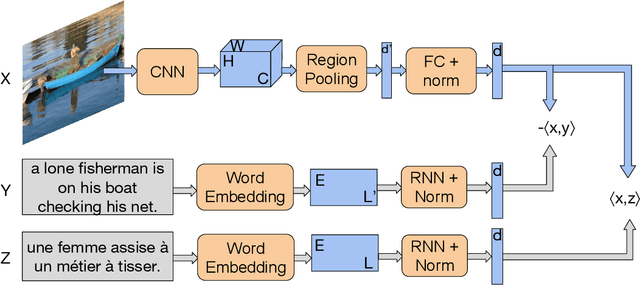
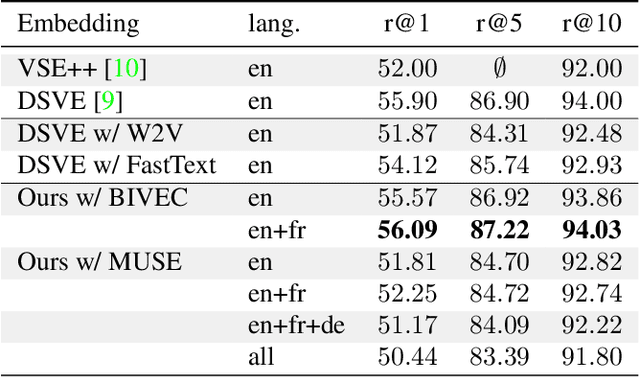
Multilingual (or cross-lingual) embeddings represent several languages in a unique vector space. Using a common embedding space enables for a shared semantic between words from different languages. In this paper, we propose to embed images and texts into a unique distributional vector space, enabling to search images by using text queries expressing information needs related to the (visual) content of images, as well as using image similarity. Our framework forces the representation of an image to be similar to the representation of the text that describes it. Moreover, by using multilingual embeddings we ensure that words from two different languages have close descriptors and thus are attached to similar images. We provide experimental evidence of the efficiency of our approach by experimenting it on two datasets: Common Objects in COntext (COCO) [19] and Multi30K [7].
AnonySIGN: Novel Human Appearance Synthesis for Sign Language Video Anonymisation
Jul 23, 2021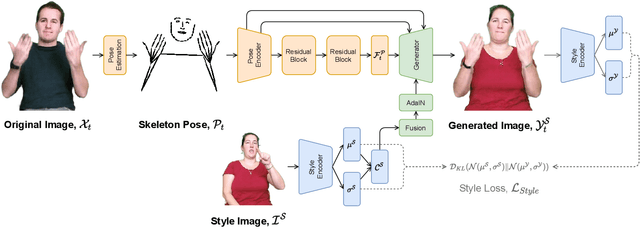
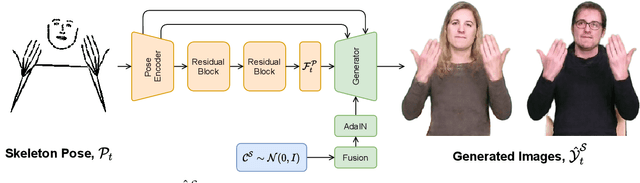


The visual anonymisation of sign language data is an essential task to address privacy concerns raised by large-scale dataset collection. Previous anonymisation techniques have either significantly affected sign comprehension or required manual, labour-intensive work. In this paper, we formally introduce the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymise the visual appearance of a sign language video whilst retaining the meaning of the original sign language sequence. To tackle SLVA, we propose AnonySign, a novel automatic approach for visual anonymisation of sign language data. We first extract pose information from the source video to remove the original signer appearance. We next generate a photo-realistic sign language video of a novel appearance from the pose sequence, using image-to-image translation methods in a conditional variational autoencoder framework. An approximate posterior style distribution is learnt, which can be sampled from to synthesise novel human appearances. In addition, we propose a novel \textit{style loss} that ensures style consistency in the anonymised sign language videos. We evaluate AnonySign for the SLVA task with extensive quantitative and qualitative experiments highlighting both realism and anonymity of our novel human appearance synthesis. In addition, we formalise an anonymity perceptual study as an evaluation criteria for the SLVA task and showcase that video anonymisation using AnonySign retains the original sign language content.