 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-based table recognition: data, model, and evaluation
Dec 13, 2019
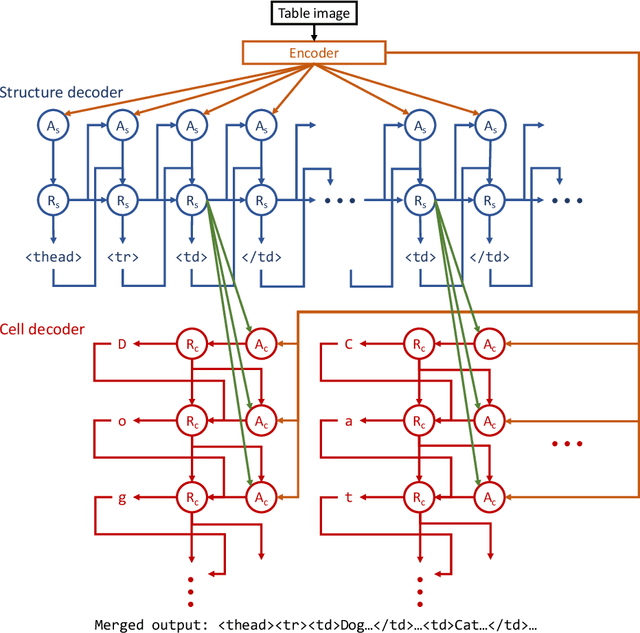
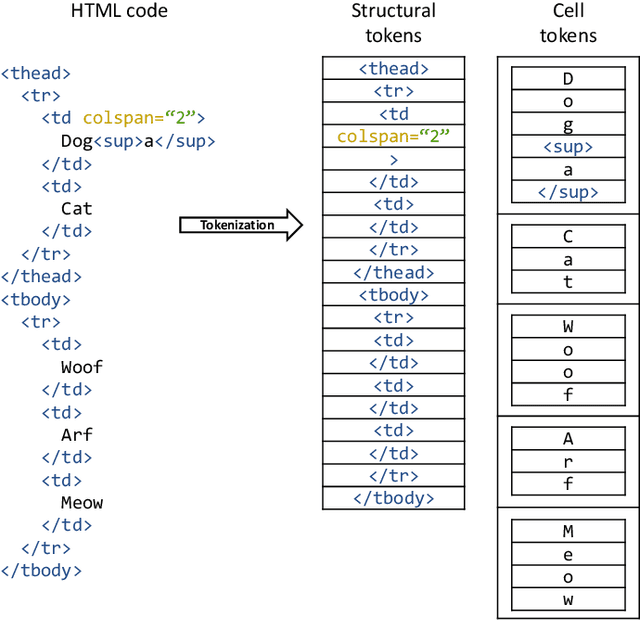
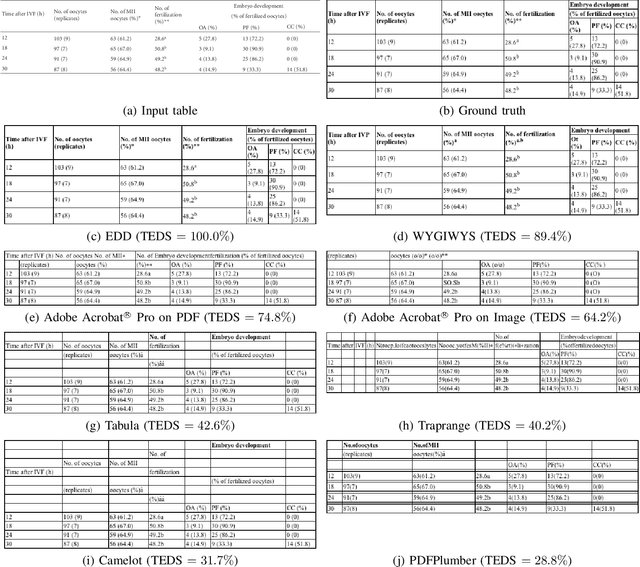

Important information that relates to a specific topic in a document is often organized in tabular format to assist readers with information retrieval and comparison, which may be difficult to provide in natural language. However, tabular data in unstructured digital documents, e.g., Portable Document Format (PDF) and images, are difficult to parse into structured machine-readable format, due to complexity and diversity in their structure and style. To facilitate image-based table recognition with deep learning, we develop the largest publicly available table recognition dataset PubTabNet (https://github.com/ibm-aur-nlp/PubTabNet), containing 568k table images with corresponding structured HTML representation. PubTabNet is automatically generated by matching the XML and PDF representations of the scientific articles in PubMed Central Open Access Subset (PMCOA). We also propose a novel attention-based encoder-dual-decoder (EDD) architecture that converts images of tables into HTML code. The model has a structure decoder which reconstructs the table structure and helps the cell decoder to recognize cell content. In addition, we propose a new Tree-Edit-Distance-based Similarity (TEDS) metric for table recognition. The experiments demonstrate that the EDD model can accurately recognize complex tables solely relying on the image representation, outperforming the state-of-the-art by 7.7% absolute TEDS score.
CCVS: Context-aware Controllable Video Synthesis
Jul 16, 2021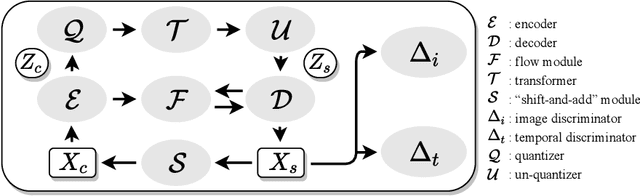
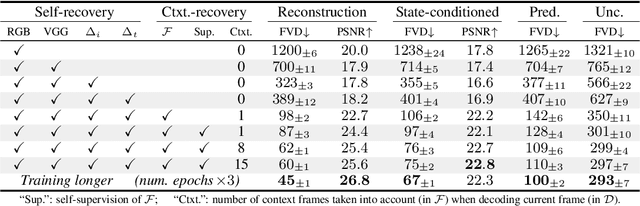
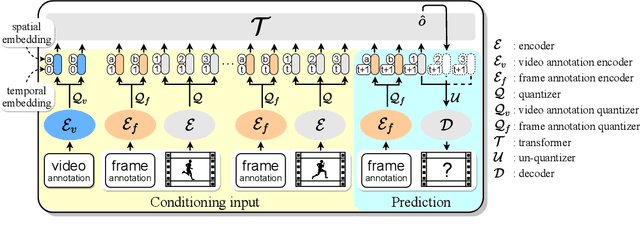
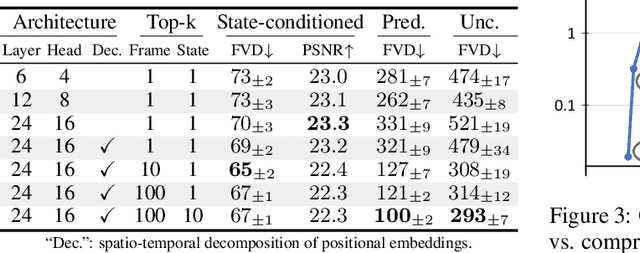
This presentation introduces a self-supervised learning approach to the synthesis of new video clips from old ones, with several new key elements for improved spatial resolution and realism: It conditions the synthesis process on contextual information for temporal continuity and ancillary information for fine control. The prediction model is doubly autoregressive, in the latent space of an autoencoder for forecasting, and in image space for updating contextual information, which is also used to enforce spatio-temporal consistency through a learnable optical flow module. Adversarial training of the autoencoder in the appearance and temporal domains is used to further improve the realism of its output. A quantizer inserted between the encoder and the transformer in charge of forecasting future frames in latent space (and its inverse inserted between the transformer and the decoder) adds even more flexibility by affording simple mechanisms for handling multimodal ancillary information for controlling the synthesis process (eg, a few sample frames, an audio track, a trajectory in image space) and taking into account the intrinsically uncertain nature of the future by allowing multiple predictions. Experiments with an implementation of the proposed approach give very good qualitative and quantitative results on multiple tasks and standard benchmarks.
Cross-Modal Self-Attention Network for Referring Image Segmentation
Apr 09, 2019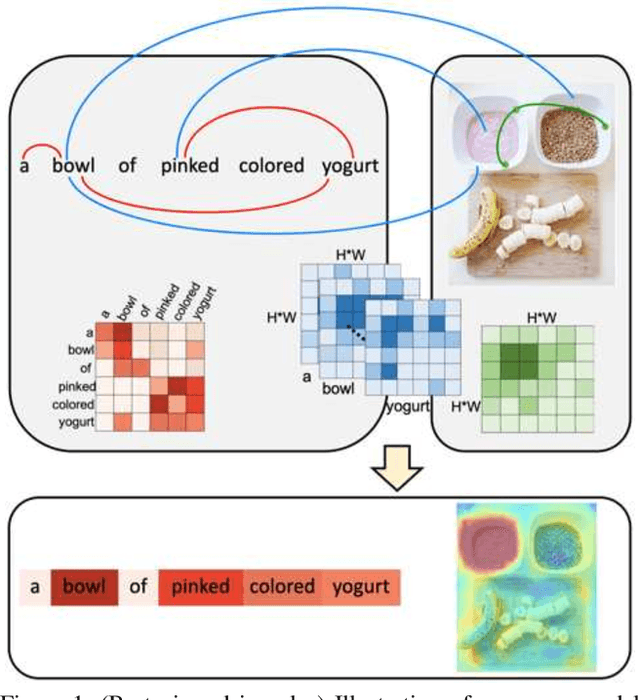
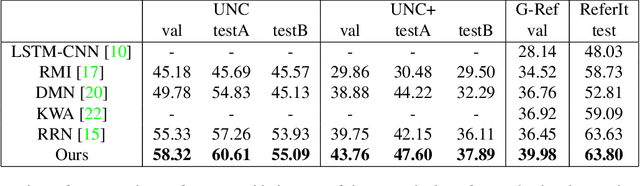
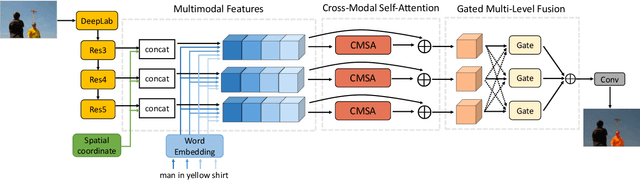
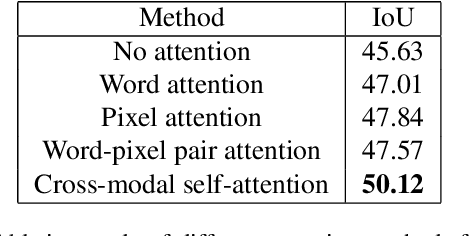
We consider the problem of referring image segmentation. Given an input image and a natural language expression, the goal is to segment the object referred by the language expression in the image. Existing works in this area treat the language expression and the input image separately in their representations. They do not sufficiently capture long-range correlations between these two modalities. In this paper, we propose a cross-modal self-attention (CMSA) module that effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the input image. In addition, we propose a gated multi-level fusion module to selectively integrate self-attentive cross-modal features corresponding to different levels in the image. This module controls the information flow of features at different levels. We validate the proposed approach on four evaluation datasets. Our proposed approach consistently outperforms existing state-of-the-art methods.
Milking CowMask for Semi-Supervised Image Classification
Apr 03, 2020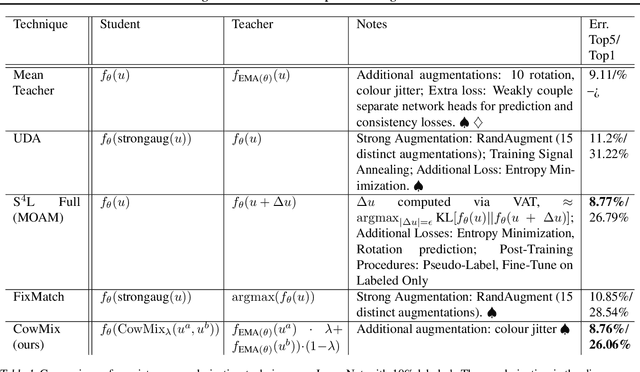

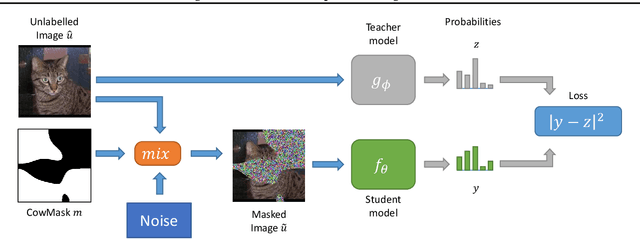
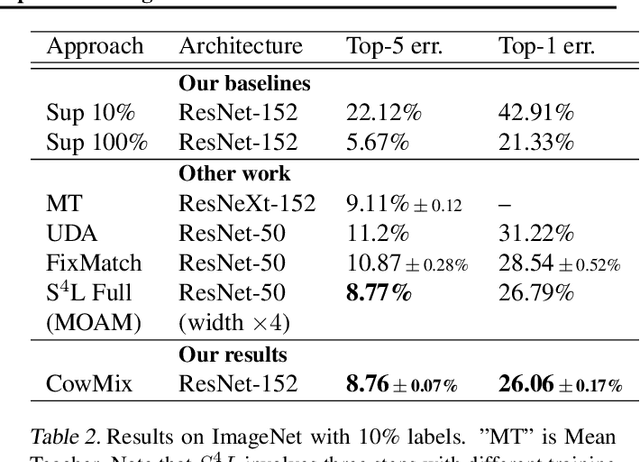
Consistency regularization is a technique for semi-supervised learning that has recently been shown to yield strong results for classification with few labeled data. The method works by perturbing input data using augmentation or adversarial examples, and encouraging the learned model to be robust to these perturbations on unlabeled data. Here, we evaluate the use of a recently proposed augmentation method, called CowMasK, for this purpose. Using CowMask as the augmentation method in semi-supervised consistency regularization, we establish a new state-of-the-art result on Imagenet with 10% labeled data, with a top-5 error of 8.76% and top-1 error of 26.06%. Moreover, we do so with a method that is much simpler than alternative methods. We further investigate the behavior of CowMask for semi-supervised learning by running many smaller scale experiments on the small image benchmarks SVHN, CIFAR-10 and CIFAR-100, where we achieve results competitive with the state of the art, and where we find evidence that the CowMask perturbation is widely applicable. We open source our code at https://github.com/google-research/google-research/tree/master/milking_cowmask
On the combined effect of class imbalance and concept complexity in deep learning
Jul 29, 2021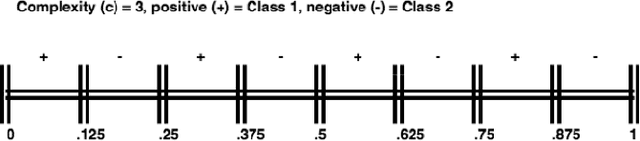
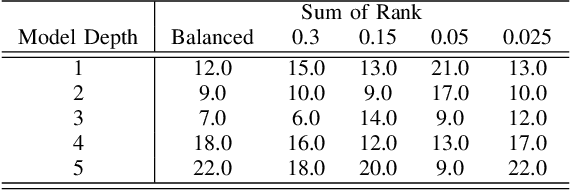
Structural concept complexity, class overlap, and data scarcity are some of the most important factors influencing the performance of classifiers under class imbalance conditions. When these effects were uncovered in the early 2000s, understandably, the classifiers on which they were demonstrated belonged to the classical rather than Deep Learning categories of approaches. As Deep Learning is gaining ground over classical machine learning and is beginning to be used in critical applied settings, it is important to assess systematically how well they respond to the kind of challenges their classical counterparts have struggled with in the past two decades. The purpose of this paper is to study the behavior of deep learning systems in settings that have previously been deemed challenging to classical machine learning systems to find out whether the depth of the systems is an asset in such settings. The results in both artificial and real-world image datasets (MNIST Fashion, CIFAR-10) show that these settings remain mostly challenging for Deep Learning systems and that deeper architectures seem to help with structural concept complexity but not with overlap challenges in simple artificial domains. Data scarcity is not overcome by deeper layers, either. In the real-world image domains, where overfitting is a greater concern than in the artificial domains, the advantage of deeper architectures is less obvious: while it is observed in certain cases, it is quickly cancelled as models get deeper and perform worse than their shallower counterparts.
UWB Radar for through Foliage Imaging using Cyclic Prefix-based OFDM
Aug 16, 2021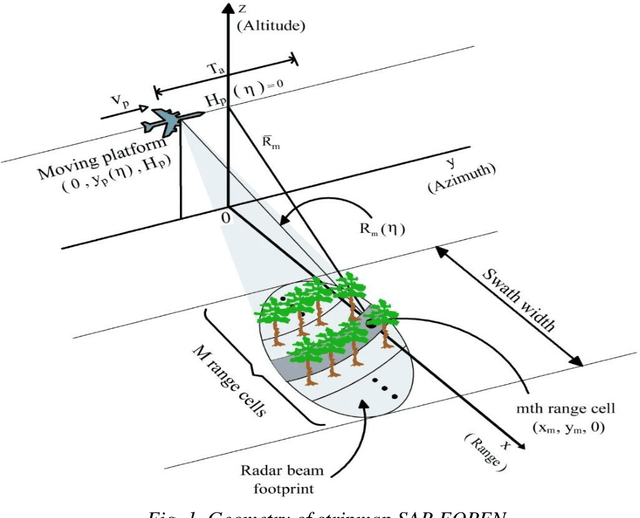
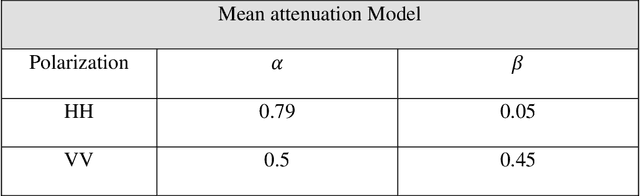
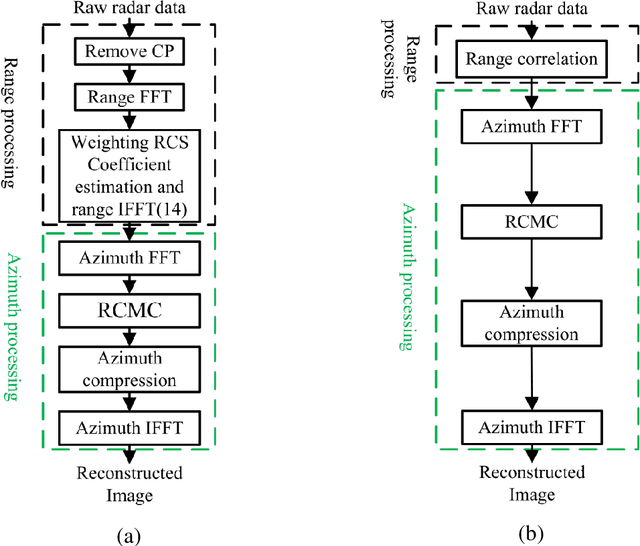
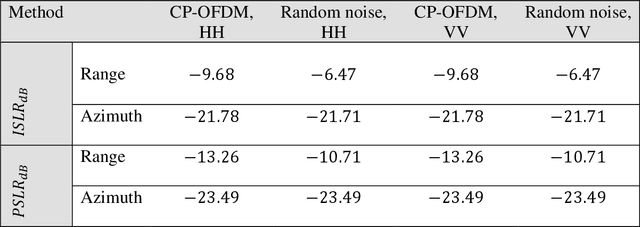
This paper proposes the use of sufficient cyclic prefix (CP) OFDM synthetic aperture radar (SAR) for foliage penetration (FOPEN). The foliage introduces phase and amplitude fluctuation which cause the sidelobes to increase and affects the final image of the obscured targets. The wideband CP-based OFDM SAR inherently eliminates the sidelobes that arise from the interference between targets on the same range line. The integrated sidelobe level ratio (ISLR) of the CP-based OFDM signal along the range direction is lower than that of the random noise signal by 2 dB for foliage penetration application, while the peak sidelobe level ratio (PSLR) are almost the same of both of the two signals.
Multi-layer Residual Sparsifying Transform Learning for Image Reconstruction
Jun 01, 2019
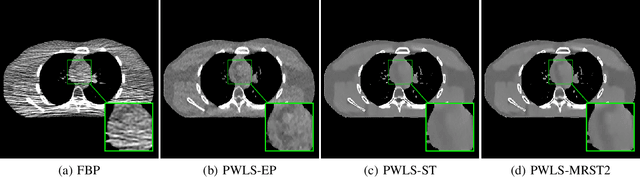
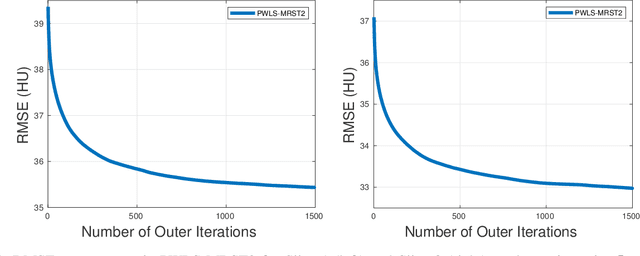
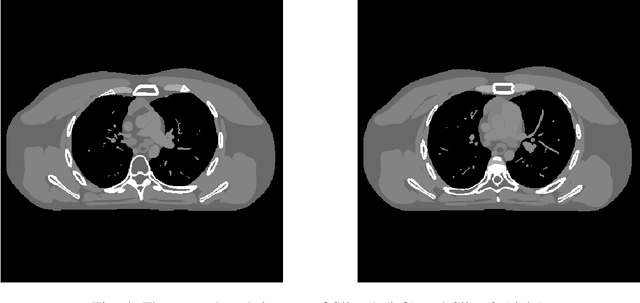
Signal models based on sparsity, low-rank and other properties have been exploited for image reconstruction from limited and corrupted data in medical imaging and other computational imaging applications. In particular, sparsifying transform models have shown promise in various applications, and offer numerous advantages such as efficiencies in sparse coding and learning. This work investigates pre-learning a multi-layer extension of the transform model for image reconstruction, wherein the transform domain or filtering residuals of the image are further sparsified over the layers. The residuals from multiple layers are jointly minimized during learning, and in the regularizer for reconstruction. The proposed block coordinate descent optimization algorithms involve highly efficient updates. Preliminary numerical experiments demonstrate the usefulness of a two-layer model over the previous related schemes for CT image reconstruction from low-dose measurements.
Semantically Invariant Text-to-Image Generation
Sep 27, 2018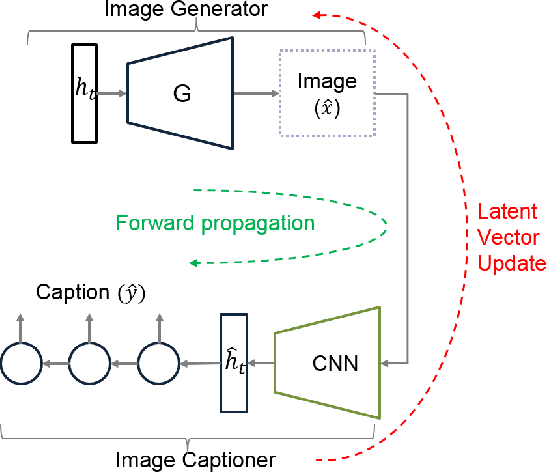
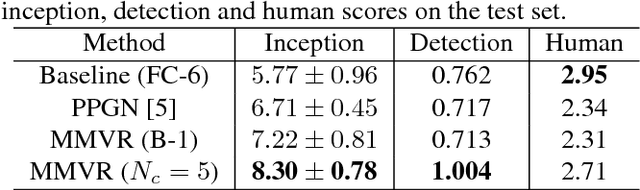

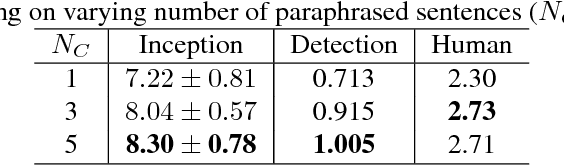
Image captioning has demonstrated models that are capable of generating plausible text given input images or videos. Further, recent work in image generation has shown significant improvements in image quality when text is used as a prior. Our work ties these concepts together by creating an architecture that can enable bidirectional generation of images and text. We call this network Multi-Modal Vector Representation (MMVR). Along with MMVR, we propose two improvements to the text conditioned image generation. Firstly, a n-gram metric based cost function is introduced that generalizes the caption with respect to the image. Secondly, multiple semantically similar sentences are shown to help in generating better images. Qualitative and quantitative evaluations demonstrate that MMVR improves upon existing text conditioned image generation results by over 20%, while integrating visual and text modalities.
Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
May 03, 2021
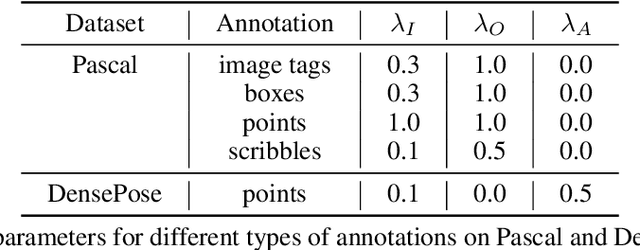
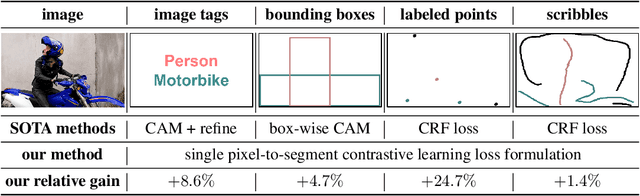
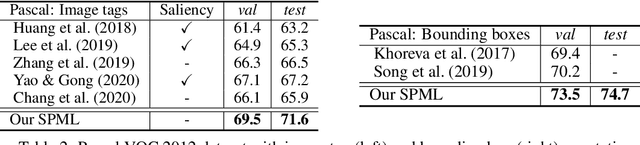
Weakly supervised segmentation requires assigning a label to every pixel based on training instances with partial annotations such as image-level tags, object bounding boxes, labeled points and scribbles. This task is challenging, as coarse annotations (tags, boxes) lack precise pixel localization whereas sparse annotations (points, scribbles) lack broad region coverage. Existing methods tackle these two types of weak supervision differently: Class activation maps are used to localize coarse labels and iteratively refine the segmentation model, whereas conditional random fields are used to propagate sparse labels to the entire image. We formulate weakly supervised segmentation as a semi-supervised metric learning problem, where pixels of the same (different) semantics need to be mapped to the same (distinctive) features. We propose 4 types of contrastive relationships between pixels and segments in the feature space, capturing low-level image similarity, semantic annotation, co-occurrence, and feature affinity They act as priors; the pixel-wise feature can be learned from training images with any partial annotations in a data-driven fashion. In particular, unlabeled pixels in training images participate not only in data-driven grouping within each image, but also in discriminative feature learning within and across images. We deliver a universal weakly supervised segmenter with significant gains on Pascal VOC and DensePose.
AWGAN: Empowering High-Dimensional Discriminator Output for Generative Adversarial Networks
Sep 08, 2021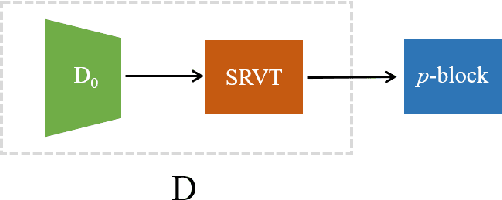
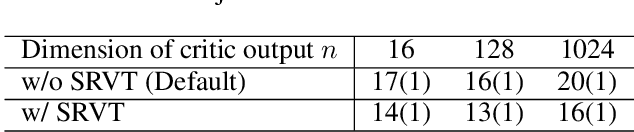
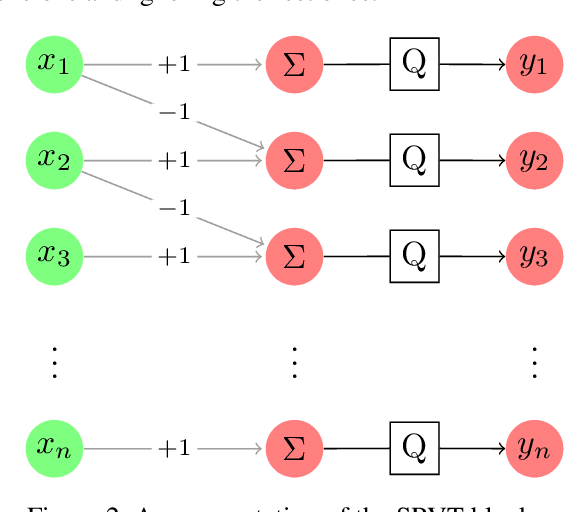
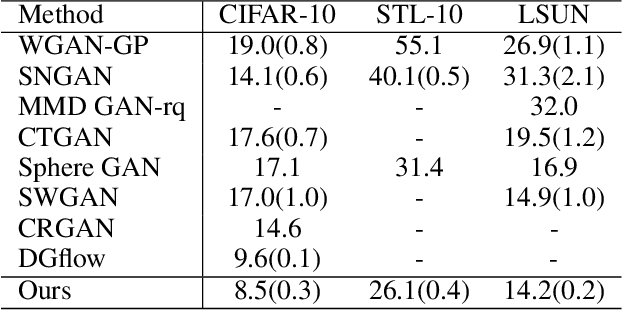
Empirically multidimensional discriminator (critic) output can be advantageous, while a solid explanation for it has not been discussed. In this paper, (i) we rigorously prove that high-dimensional critic output has advantage on distinguishing real and fake distributions; (ii) we also introduce an square-root velocity transformation (SRVT) block which further magnifies this advantage. The proof is based on our proposed maximal p-centrality discrepancy which is bounded above by p-Wasserstein distance and perfectly fits the Wasserstein GAN framework with high-dimensional critic output n. We have also showed when n = 1, the proposed discrepancy is equivalent to 1-Wasserstein distance. The SRVT block is applied to break the symmetric structure of high-dimensional critic output and improve the generalization capability of the discriminator network. In terms of implementation, the proposed framework does not require additional hyper-parameter tuning, which largely facilitates its usage. Experiments on image generation tasks show performance improvement on benchmark datasets.