 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RGB-T Image Saliency Detection via Collaborative Graph Learning
May 16, 2019


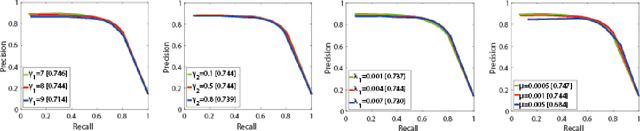
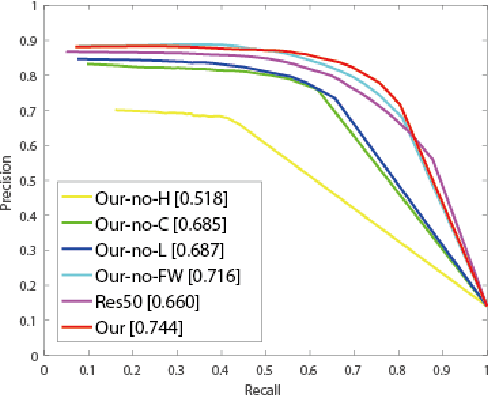
Image saliency detection is an active research topic in the community of computer vision and multimedia. Fusing complementary RGB and thermal infrared data has been proven to be effective for image saliency detection. In this paper, we propose an effective approach for RGB-T image saliency detection. Our approach relies on a novel collaborative graph learning algorithm. In particular, we take superpixels as graph nodes, and collaboratively use hierarchical deep features to jointly learn graph affinity and node saliency in a unified optimization framework. Moreover, we contribute a more challenging dataset for the purpose of RGB-T image saliency detection, which contains 1000 spatially aligned RGB-T image pairs and their ground truth annotations. Extensive experiments on the public dataset and the newly created dataset suggest that the proposed approach performs favorably against the state-of-the-art RGB-T saliency detection methods.
Efficiently Modeling Long Sequences with Structured State Spaces
Oct 31, 2021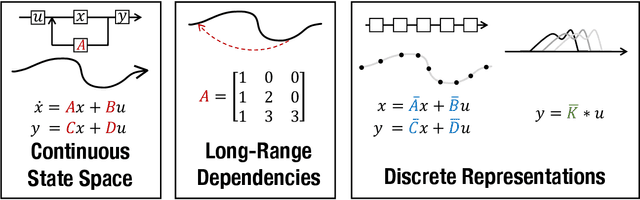
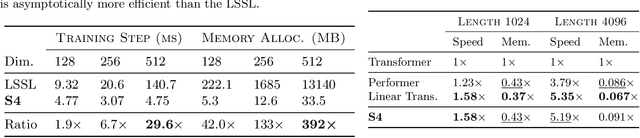


A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of $10000$ or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state space model (SSM) \( x'(t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t) \), and showed that for appropriate choices of the state matrix \( A \), this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space (S4) sequence model based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning \( A \) with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks, including (i) 91\% accuracy on sequential CIFAR-10 with no data augmentation or auxiliary losses, on par with a larger 2-D ResNet, (ii) substantially closing the gap to Transformers on image and language modeling tasks, while performing generation $60\times$ faster (iii) SoTA on every task from the Long Range Arena benchmark, including solving the challenging Path-X task of length 16k that all prior work fails on, while being as efficient as all competitors.
Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
Feb 26, 2021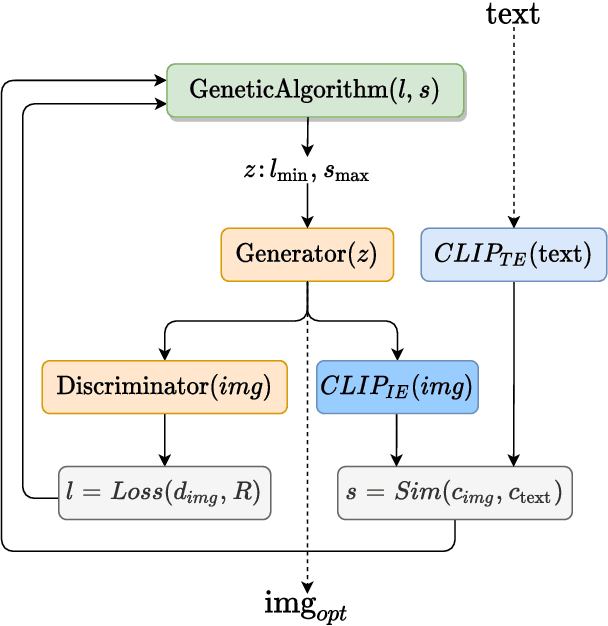
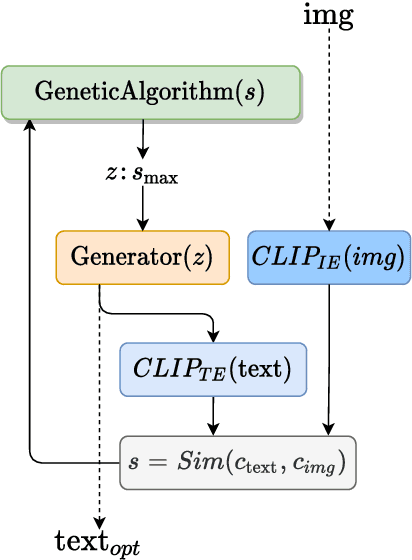


In this research work we present CLIP-GLaSS, a novel zero-shot framework to generate an image (or a caption) corresponding to a given caption (or image). CLIP-GLaSS is based on the CLIP neural network, which, given an image and a descriptive caption, provides similar embeddings. Differently, CLIP-GLaSS takes a caption (or an image) as an input, and generates the image (or the caption) whose CLIP embedding is the most similar to the input one. This optimal image (or caption) is produced via a generative network, after an exploration by a genetic algorithm. Promising results are shown, based on the experimentation of the image Generators BigGAN and StyleGAN2, and of the text Generator GPT2
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Jul 27, 2021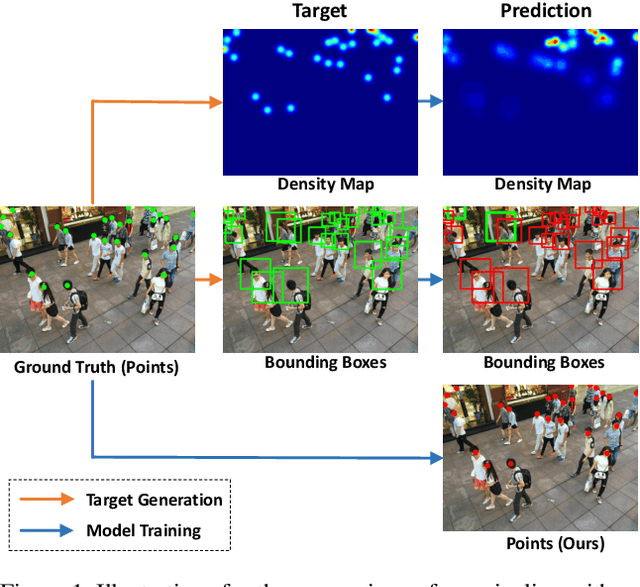
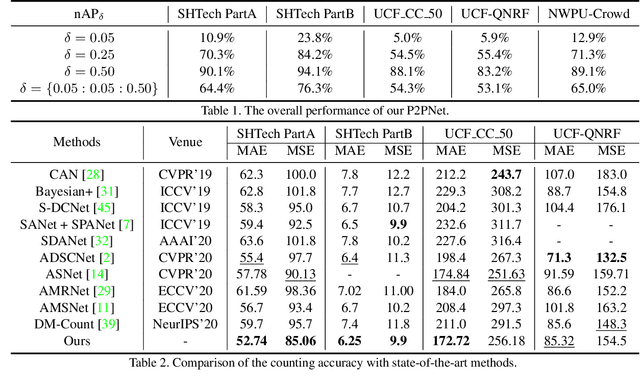
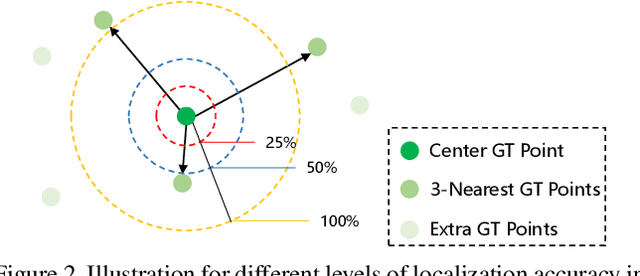
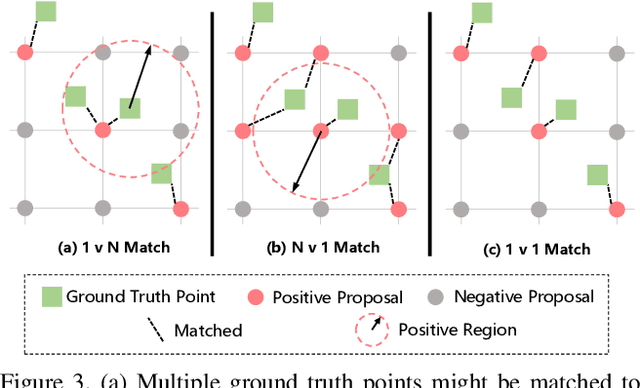
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.
A Fast Fully Octave Convolutional Neural Network for Document Image Segmentation
Apr 03, 2020



The Know Your Customer (KYC) and Anti Money Laundering (AML) are worldwide practices to online customer identification based on personal identification documents, similarity and liveness checking, and proof of address. To answer the basic regulation question: are you whom you say you are? The customer needs to upload valid identification documents (ID). This task imposes some computational challenges since these documents are diverse, may present different and complex backgrounds, some occlusion, partial rotation, poor quality, or damage. Advanced text and document segmentation algorithms were used to process the ID images. In this context, we investigated a method based on U-Net to detect the document edges and text regions in ID images. Besides the promising results on image segmentation, the U-Net based approach is computationally expensive for a real application, since the image segmentation is a customer device task. We propose a model optimization based on Octave Convolutions to qualify the method to situations where storage, processing, and time resources are limited, such as in mobile and robotic applications. We conducted the evaluation experiments in two new datasets CDPhotoDataset and DTDDataset, which are composed of real ID images of Brazilian documents. Our results showed that the proposed models are efficient to document segmentation tasks and portable.
* This paper was accepted for IJCNN 2020 Conference
Face Video Generation from a Single Image and Landmarks
Apr 25, 2019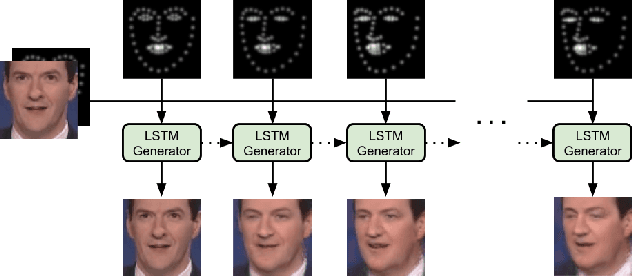
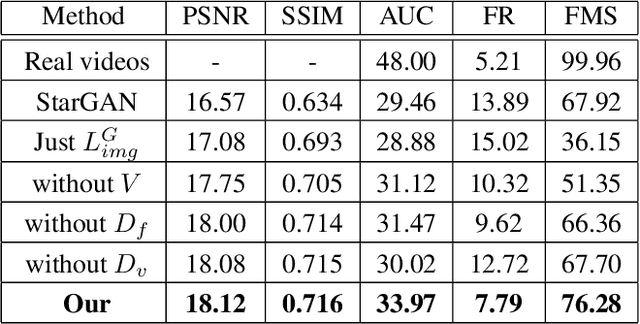
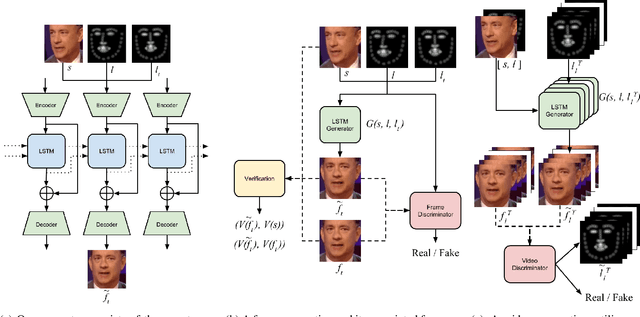
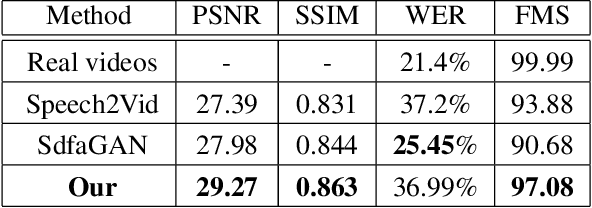
In this paper we are concerned with the challenging problem of producing a full image sequence of a deformable face given only an image and generic facial motions encoded by a set of sparse landmarks. To this end we build upon recent breakthroughs in image-to-image translation such as pix2pix, CycleGAN and StarGAN which learn Deep Convolutional Neural Networks (DCNNs) that learn to map aligned pairs or images between different domains (i.e., having different labels) and propose a new architecture which is not driven any more by labels but by spatial maps, facial landmarks. In particular, we propose the MotionGAN which transforms an input face image into a new one according to a heatmap of target landmarks. We show that it is possible to create very realistic face videos using a single image and a set of target landmarks. Furthermore, our method can be used to edit a facial image with arbitrary motions according to landmarks (e.g., expression, speech, etc.). This provides much more flexibility to face editing, expression transfer, facial video creation, etc. than models based on discrete expressions, audios or action units.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
May 25, 2019
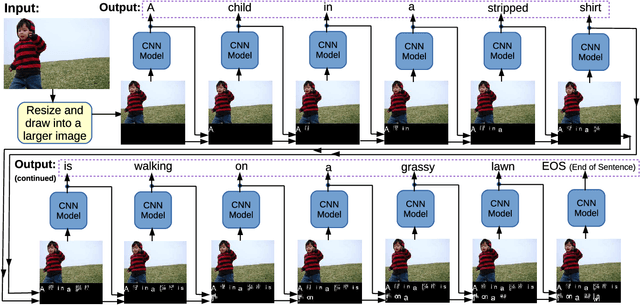
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
Spectrally Consistent UNet for High Fidelity Image Transformations
Apr 22, 2020

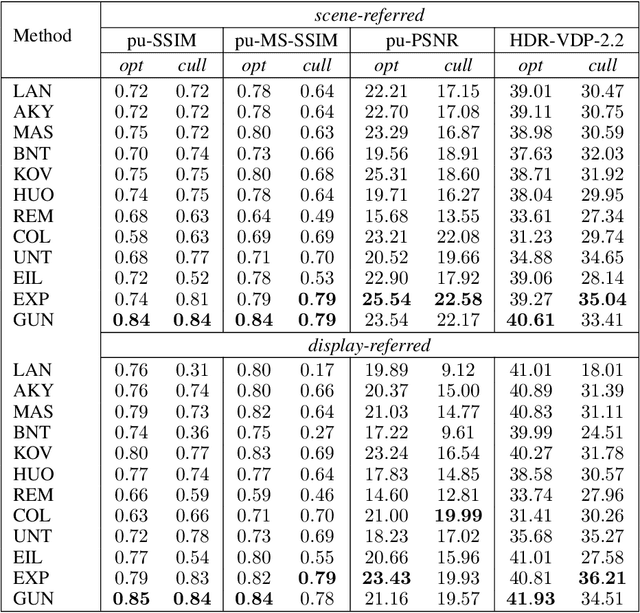
Convolutional Neural Networks (CNNs) are the current de-facto approach used for many imaging tasks due to their high learning capacity as well as their architectural qualities. The ubiquitous UNet architecture provides an efficient and multi-scale solution that combines local and global information. Despite the success of UNet architectures, the use of upsampling layers can cause checkerboard artefacts or blurring. In this work, a method for assessing the structural biases of UNets and the effects these have on the outputs is presented, characterising their impact in the Fourier domain. A new upsampling module is then proposed, based on a novel generalisation of the Guided Image Filter, that provides spectrally consistent outputs when used in a UNet architecture, forming the Guided UNet (GUNet). The GUNet architecture is evaluated quantitatively and qualitatively in an example application of dynamic range expansion for high dynamic range imaging. The proposed method provides higher fidelity results, while executing faster and consuming less memory than other dedicated architectures that avoid upsampling.
Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation
Oct 02, 2019
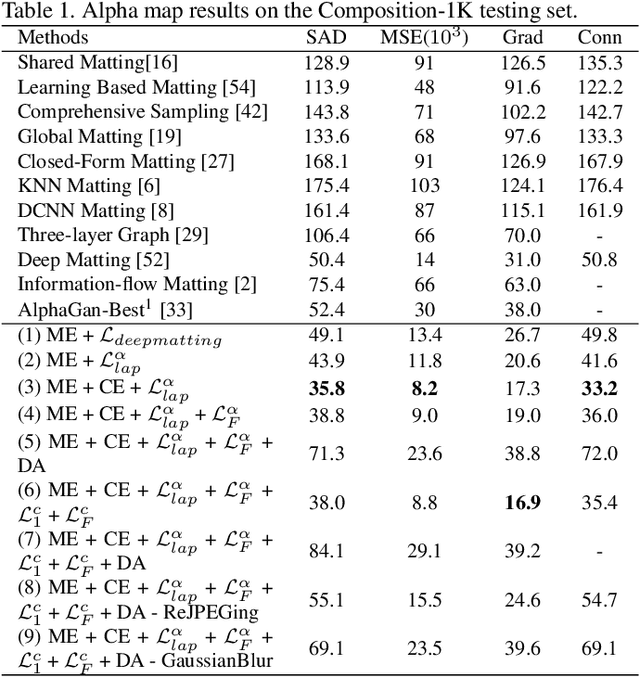
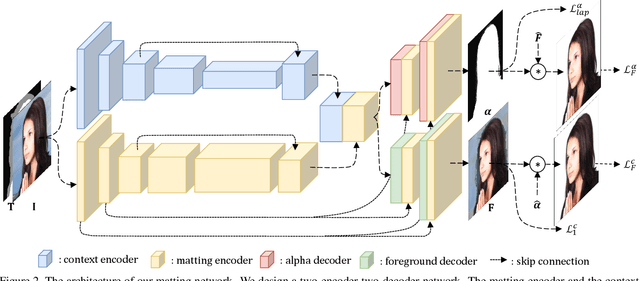
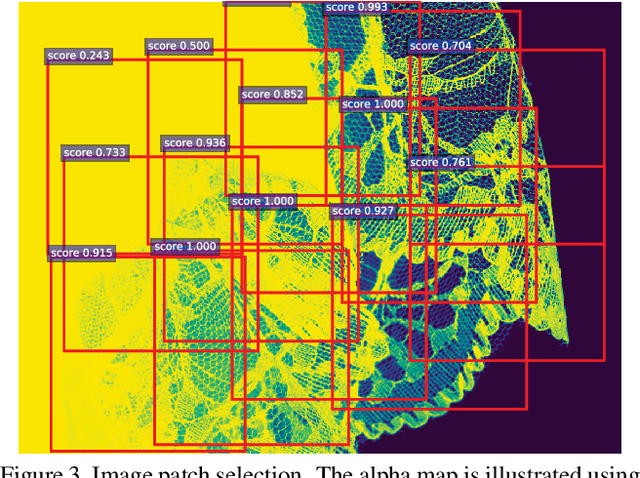
Natural image matting is an important problem in computer vision and graphics. It is an ill-posed problem when only an input image is available without any external information. While the recent deep learning approaches have shown promising results, they only estimate the alpha matte. This paper presents a context-aware natural image matting method for simultaneous foreground and alpha matte estimation. Our method employs two encoder networks to extract essential information for matting. Particularly, we use a matting encoder to learn local features and a context encoder to obtain more global context information. We concatenate the outputs from these two encoders and feed them into decoder networks to simultaneously estimate the foreground and alpha matte. To train this whole deep neural network, we employ both the standard Laplacian loss and the feature loss: the former helps to achieve high numerical performance while the latter leads to more perceptually plausible results. We also report several data augmentation strategies that greatly improve the network's generalization performance. Our qualitative and quantitative experiments show that our method enables high-quality matting for a single natural image. Our inference codes and models have been made publicly available at https://github.com/hqqxyy/Context-Aware-Matting.
Deep Edge-Aware Interactive Colorization against Color-Bleeding Effects
Jul 04, 2021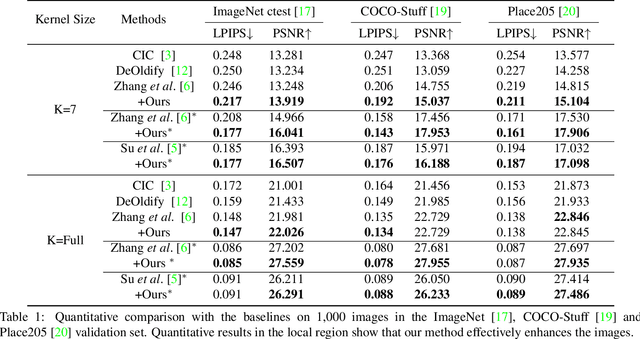
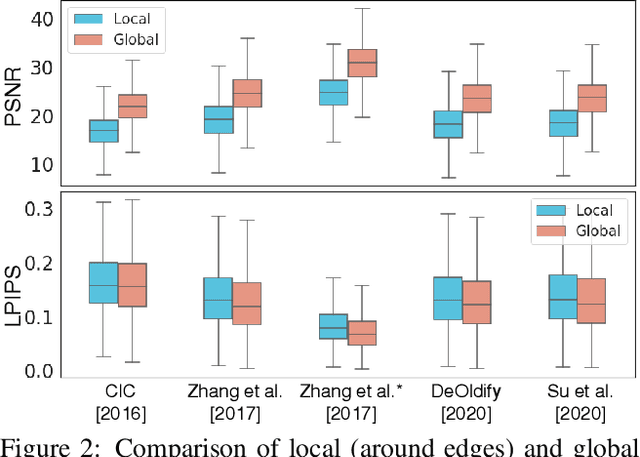
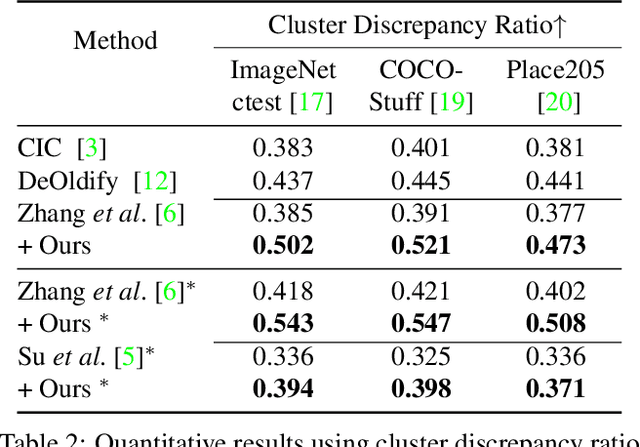
Deep image colorization networks often suffer from the color-bleeding artifact, a problematic color spreading near the boundaries between adjacent objects. The color-bleeding artifacts debase the reality of generated outputs, limiting the applicability of colorization models on a practical application. Although previous approaches have tackled this problem in an automatic manner, they often generate imperfect outputs because their enhancements are available only in limited cases, such as having a high contrast of gray-scale value in an input image. Instead, leveraging user interactions would be a promising approach, since it can help the edge correction in the desired regions. In this paper, we propose a novel edge-enhancing framework for the regions of interest, by utilizing user scribbles that indicate where to enhance. Our method requires minimal user effort to obtain satisfactory enhancements. Experimental results on various datasets demonstrate that our interactive approach has outstanding performance in improving color-bleeding artifacts against the existing baselines.