 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AtrialGeneral: Domain Generalization for Left Atrial Segmentation of Multi-Center LGE MRIs
Jul 05, 2021
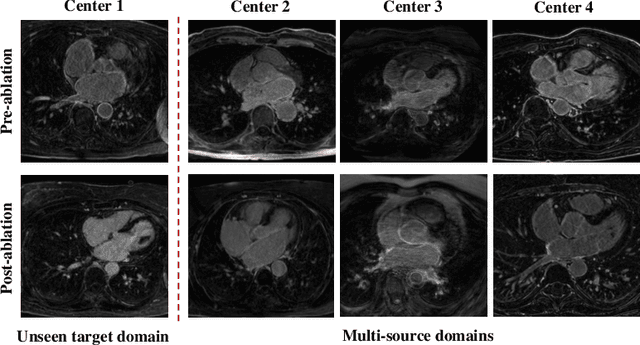

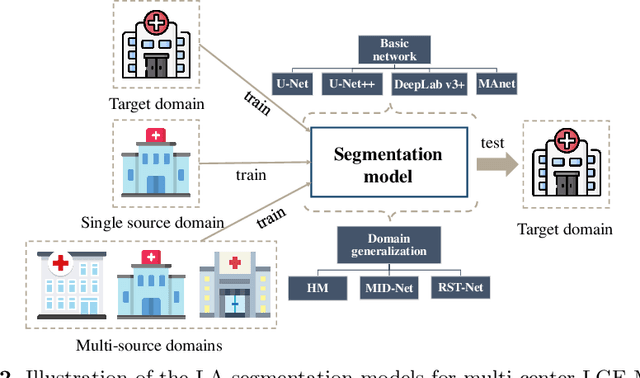
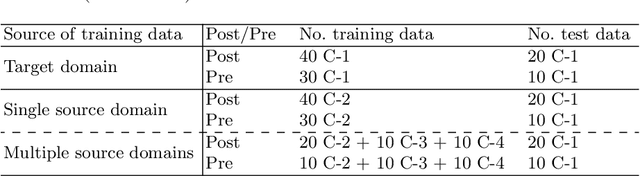
Left atrial (LA) segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is a crucial step needed for planning the treatment of atrial fibrillation. However, automatic LA segmentation from LGE MRI is still challenging, due to the poor image quality, high variability in LA shapes, and unclear LA boundary. Though deep learning-based methods can provide promising LA segmentation results, they often generalize poorly to unseen domains, such as data from different scanners and/or sites. In this work, we collect 210 LGE MRIs from different centers with different levels of image quality. To evaluate the domain generalization ability of models on the LA segmentation task, we employ four commonly used semantic segmentation networks for the LA segmentation from multi-center LGE MRIs. Besides, we investigate three domain generalization strategies, i.e., histogram matching, mutual information based disentangled representation, and random style transfer, where a simple histogram matching is proved to be most effective.
Multi-Kernel Filtering: An Extension of Bilateral Filtering Using Image Context
Aug 17, 2019
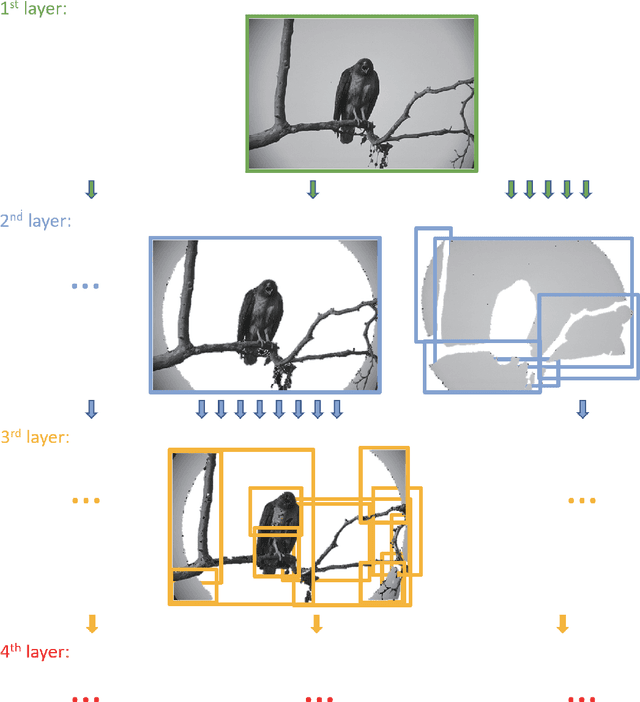
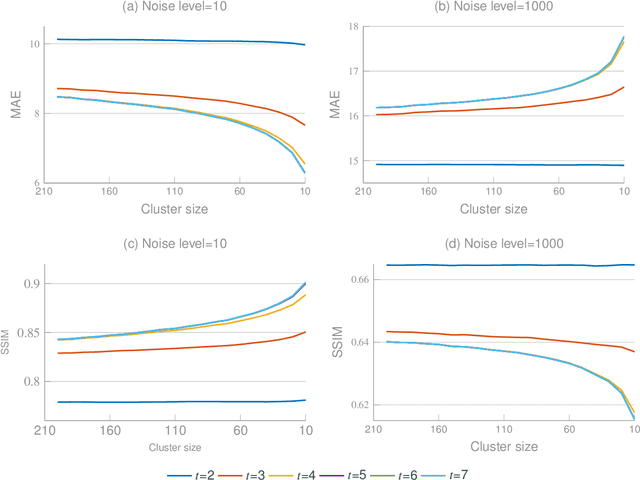
Bilateral filtering is one of the most classical denoising filters. However, the parameter of its range kernel needs to be initialized manually, which hampers its adaptivity across images with different characteristics. For coping with image variation (e.g., changeable signal-to-noise ratio and spatially-varying noise), it is necessary to adapt the kernel to specific image characteristics automatically. In this paper, we propose multi-kernel filter (MKF) inspired by adaptive mechanisms of human vision. We first design a hierarchically clustering algorithm to generate a hierarchy of large to small coherent image patches, organized as a cluster tree, so that multi-scale represent an image. One leaf cluster and two corresponding predecessor clusters are used to generate one of a number of range kernels that are capable of catering to image variation. We evaluate MKF on two public datasets, BSD$300$ and Phantom$\alpha$s. Extensive experimental results show that MKF outperforms various state-of-the-art filters on both mean absolute error and structural similarity.
Temporally Coherent Person Matting Trained on Fake-Motion Dataset
Sep 10, 2021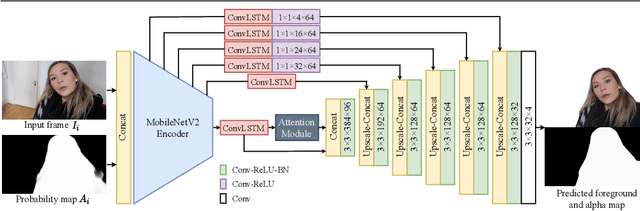
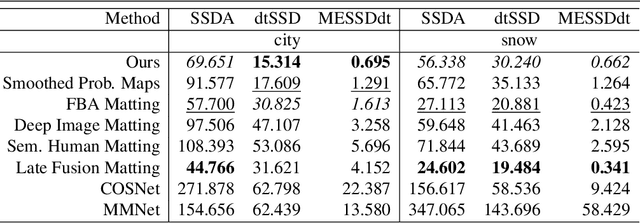
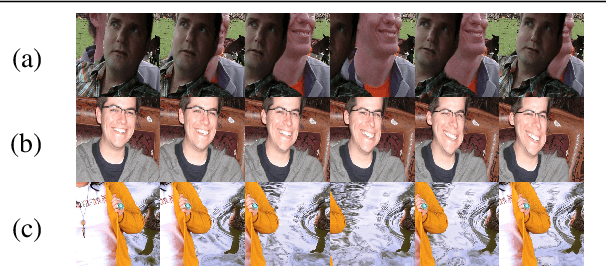
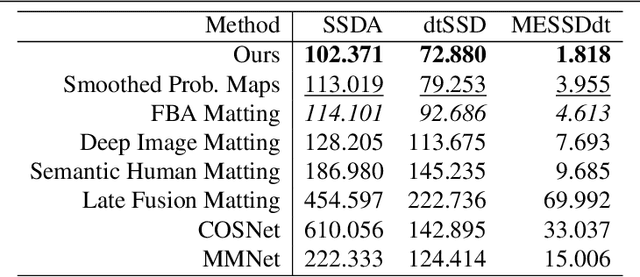
We propose a novel neural-network-based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion-estimation-based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground-truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground-truth training-clip foreground optical flow for use in loss functions.
Contrastive Attention for Automatic Chest X-ray Report Generation
Jun 13, 2021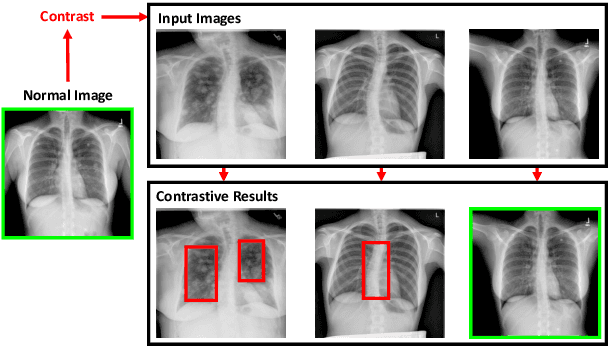
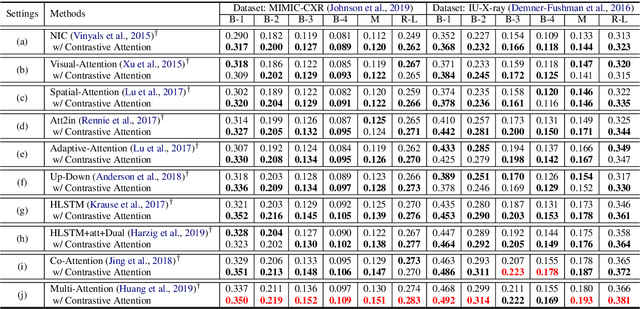
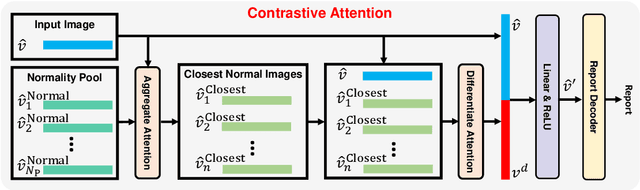

Recently, chest X-ray report generation, which aims to automatically generate descriptions of given chest X-ray images, has received growing research interests. The key challenge of chest X-ray report generation is to accurately capture and describe the abnormal regions. In most cases, the normal regions dominate the entire chest X-ray image, and the corresponding descriptions of these normal regions dominate the final report. Due to such data bias, learning-based models may fail to attend to abnormal regions. In this work, to effectively capture and describe abnormal regions, we propose the Contrastive Attention (CA) model. Instead of solely focusing on the current input image, the CA model compares the current input image with normal images to distill the contrastive information. The acquired contrastive information can better represent the visual features of abnormal regions. According to the experiments on the public IU-X-ray and MIMIC-CXR datasets, incorporating our CA into several existing models can boost their performance across most metrics. In addition, according to the analysis, the CA model can help existing models better attend to the abnormal regions and provide more accurate descriptions which are crucial for an interpretable diagnosis. Specifically, we achieve the state-of-the-art results on the two public datasets.
Generating superpixels using deep image representations
Mar 11, 2019

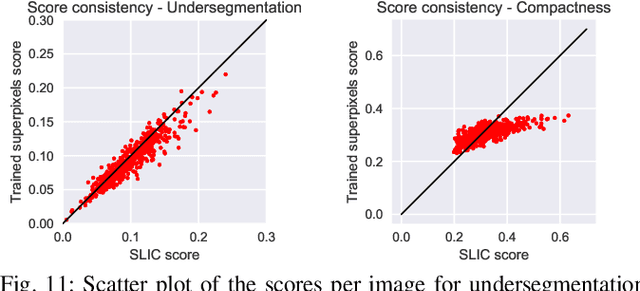

Superpixel algorithms are a common pre-processing step for computer vision algorithms such as segmentation, object tracking and localization. Many superpixel methods only rely on colors features for segmentation, limiting performance in low-contrast regions and applicability to infrared or medical images where object boundaries have wide appearance variability. We study the inclusion of deep image features in the SLIC superpixel algorithm to exploit higher-level image representations. In addition, we devise a trainable superpixel algorithm, yielding an intermediate domain-specific image representation that can be applied to different tasks. A clustering-based superpixel algorithm is transformed into a pixel-wise classification task and superpixel training data is derived from semantic segmentation datasets. Our results demonstrate that this approach is able to improve superpixel quality consistently.
Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
Apr 12, 2021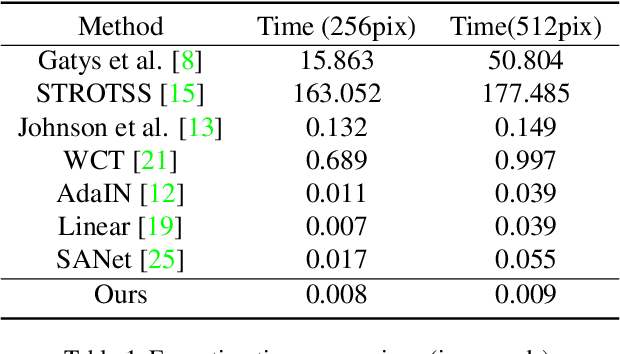
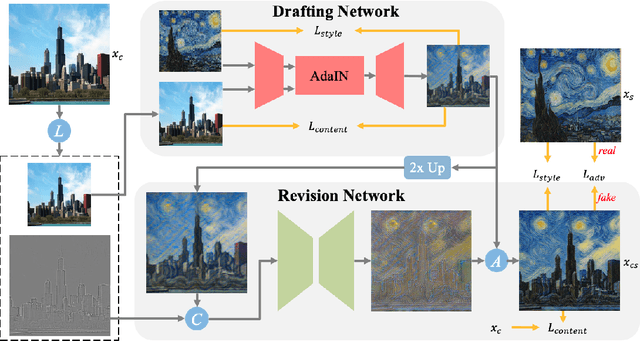
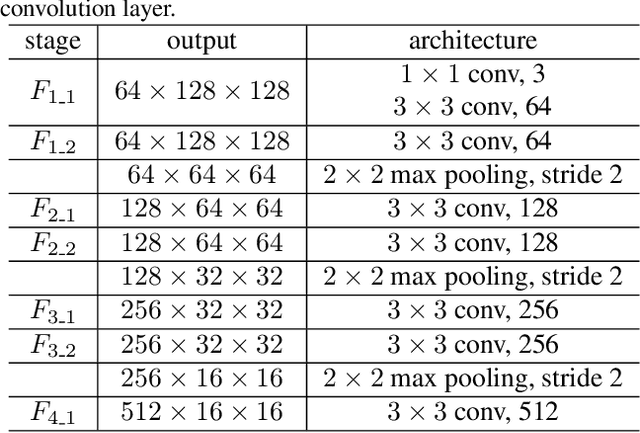
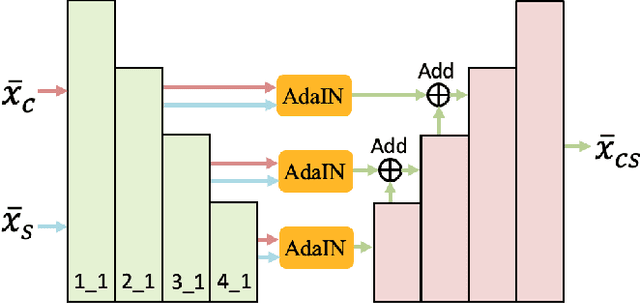
Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization-based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process of drawing a draft and revising the details, we introduce a novel feed-forward method named Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style patterns in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs of all pyramid levels. %We also introduce a patch discriminator to better learn local patterns adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
Jun 21, 2021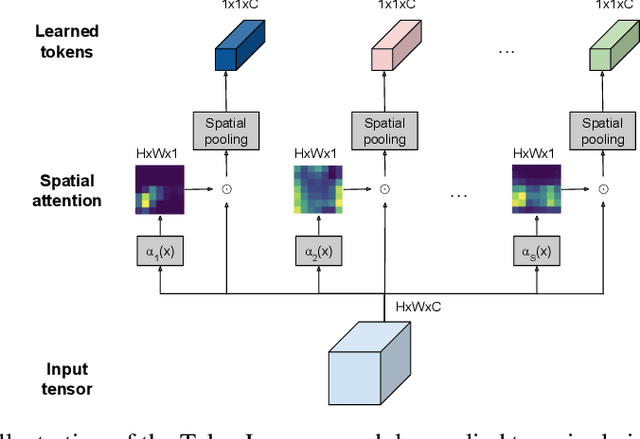
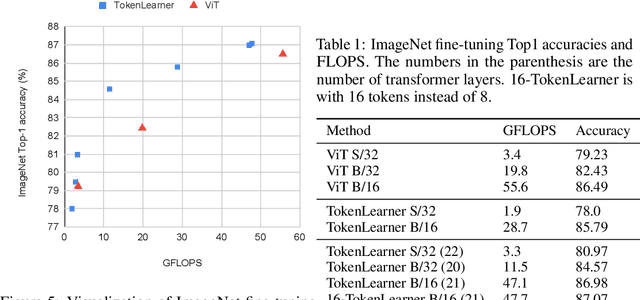
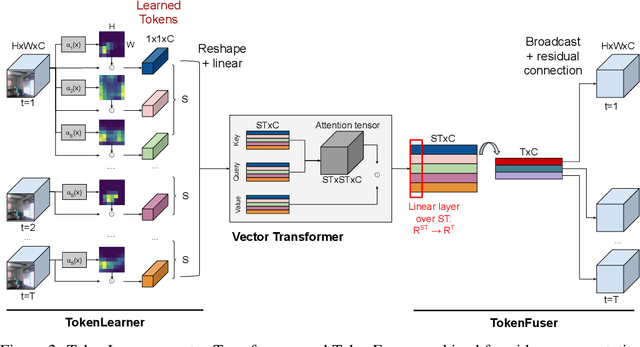

In this paper, we introduce a novel visual representation learning which relies on a handful of adaptively learned tokens, and which is applicable to both image and video understanding tasks. Instead of relying on hand-designed splitting strategies to obtain visual tokens and processing a large number of densely sampled patches for attention, our approach learns to mine important tokens in visual data. This results in efficiently and effectively finding a few important visual tokens and enables modeling of pairwise attention between such tokens, over a longer temporal horizon for videos, or the spatial content in images. Our experiments demonstrate strong performance on several challenging benchmarks for both image and video recognition tasks. Importantly, due to our tokens being adaptive, we accomplish competitive results at significantly reduced compute amount.
A Comparison of Deep Saliency Map Generators on Multispectral Data in Object Detection
Aug 26, 2021

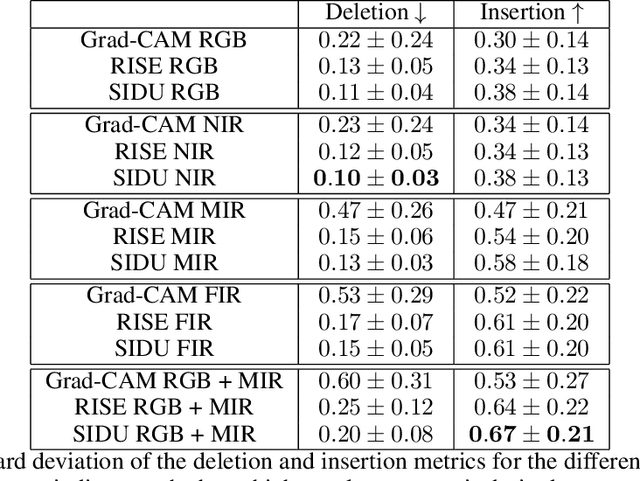
Deep neural networks, especially convolutional deep neural networks, are state-of-the-art methods to classify, segment or even generate images, movies, or sounds. However, these methods lack of a good semantic understanding of what happens internally. The question, why a COVID-19 detector has classified a stack of lung-ct images as positive, is sometimes more interesting than the overall specificity and sensitivity. Especially when human domain expert knowledge disagrees with the given output. This way, human domain experts could also be advised to reconsider their choice, regarding the information pointed out by the system. In addition, the deep learning model can be controlled, and a present dataset bias can be found. Currently, most explainable AI methods in the computer vision domain are purely used on image classification, where the images are ordinary images in the visible spectrum. As a result, there is no comparison on how the methods behave with multimodal image data, as well as most methods have not been investigated on how they behave when used for object detection. This work tries to close the gaps. Firstly, investigating three saliency map generator methods on how their maps differ across the different spectra. This is achieved via accurate and systematic training. Secondly, we examine how they behave when used for object detection. As a practical problem, we chose object detection in the infrared and visual spectrum for autonomous driving. The dataset used in this work is the Multispectral Object Detection Dataset, where each scene is available in the FIR, MIR and NIR as well as visual spectrum. The results show that there are differences between the infrared and visual activation maps. Further, an advanced training with both, the infrared and visual data not only improves the network's output, it also leads to more focused spots in the saliency maps.
Efficiently Modeling Long Sequences with Structured State Spaces
Oct 31, 2021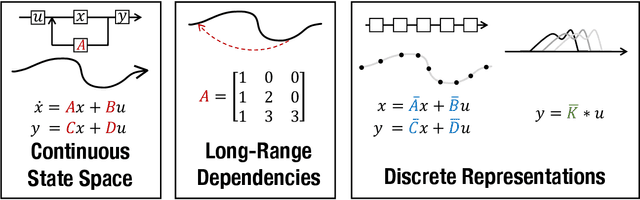
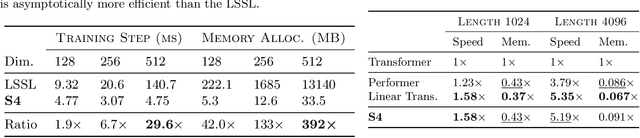


A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of $10000$ or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state space model (SSM) \( x'(t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t) \), and showed that for appropriate choices of the state matrix \( A \), this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space (S4) sequence model based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning \( A \) with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks, including (i) 91\% accuracy on sequential CIFAR-10 with no data augmentation or auxiliary losses, on par with a larger 2-D ResNet, (ii) substantially closing the gap to Transformers on image and language modeling tasks, while performing generation $60\times$ faster (iii) SoTA on every task from the Long Range Arena benchmark, including solving the challenging Path-X task of length 16k that all prior work fails on, while being as efficient as all competitors.
Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-modal Pretraining
Aug 09, 2021
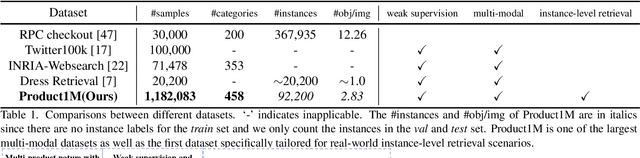
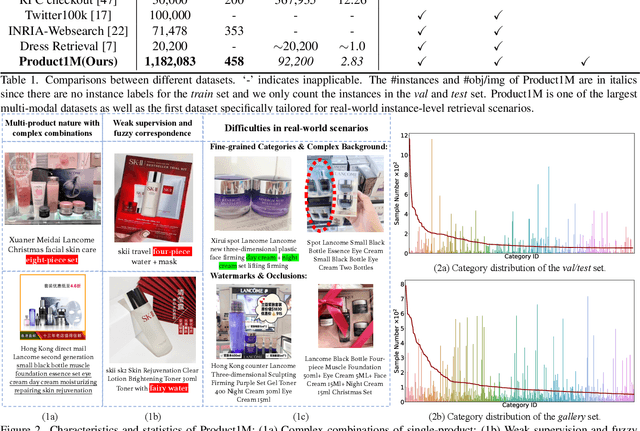
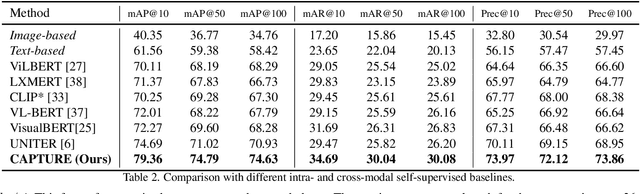
Nowadays, customer's demands for E-commerce are more diversified, which introduces more complications to the product retrieval industry. Previous methods are either subject to single-modal input or perform supervised image-level product retrieval, thus fail to accommodate real-life scenarios where enormous weakly annotated multi-modal data are present. In this paper, we investigate a more realistic setting that aims to perform weakly-supervised multi-modal instance-level product retrieval among fine-grained product categories. To promote the study of this challenging task, we contribute Product1M, one of the largest multi-modal cosmetic datasets for real-world instance-level retrieval. Notably, Product1M contains over 1 million image-caption pairs and consists of two sample types, i.e., single-product and multi-product samples, which encompass a wide variety of cosmetics brands. In addition to the great diversity, Product1M enjoys several appealing characteristics including fine-grained categories, complex combinations, and fuzzy correspondence that well mimic the real-world scenes. Moreover, we propose a novel model named Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval (CAPTURE), that excels in capturing the potential synergy between multi-modal inputs via a hybrid-stream transformer in a self-supervised manner.CAPTURE generates discriminative instance features via masked multi-modal learning as well as cross-modal contrastive pretraining and it outperforms several SOTA cross-modal baselines. Extensive ablation studies well demonstrate the effectiveness and the generalization capacity of our model. Dataset and codes are available at https: //github.com/zhanxlin/Product1M.