 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gray Cycles of Maximum Length Related to k-Character Substitutions
Aug 31, 2021
Given a word binary relation $\tau$ we define a $\tau$-Gray cycle over a finite language $X$ to be a permutation $\left(w_{[i]}\right)_{0\le i\le |X|-1}$ of $X$ such that each word $w_i$ is an image of the previous word $w_{i-1}$ by $\tau$. In that framework, we introduce the complexity measure $\lambda(n)$, equal to the largest cardinality of a language $X$ having words of length at most $n$, and such that a $\tau$-Gray cycle over $X$ exists. The present paper is concerned with the relation $\tau=\sigma_k$, the so-called $k$-character substitution, where $(u,v)$ belongs to $\sigma_k$ if, and only if, the Hamming distance of $u$ and $v$ is $k$. We compute the bound $\lambda(n)$ for all cases of the alphabet cardinality and the argument $n$.
An Elastic Interaction-Based Loss Function for Medical Image Segmentation
Jul 06, 2020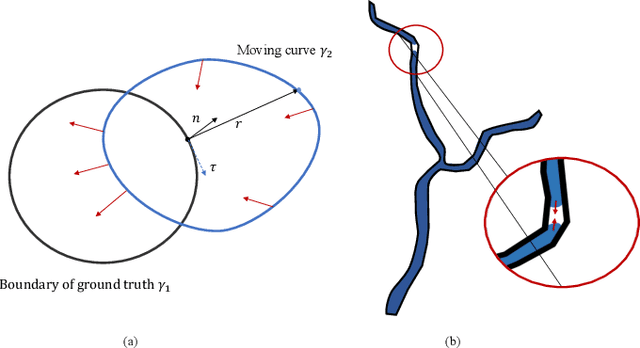
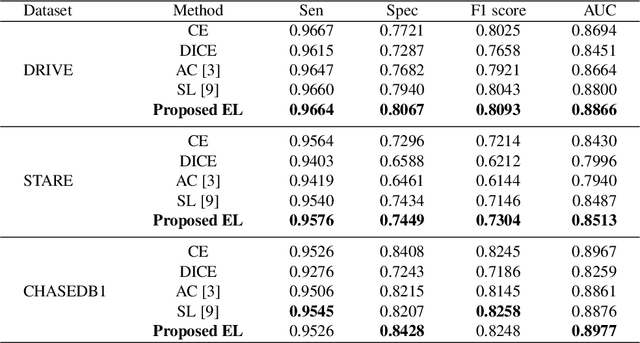
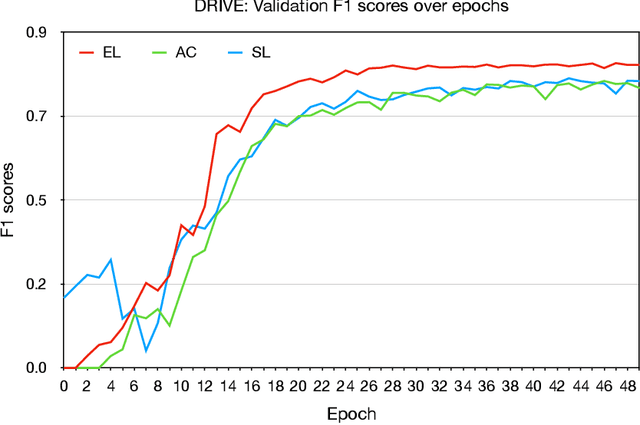
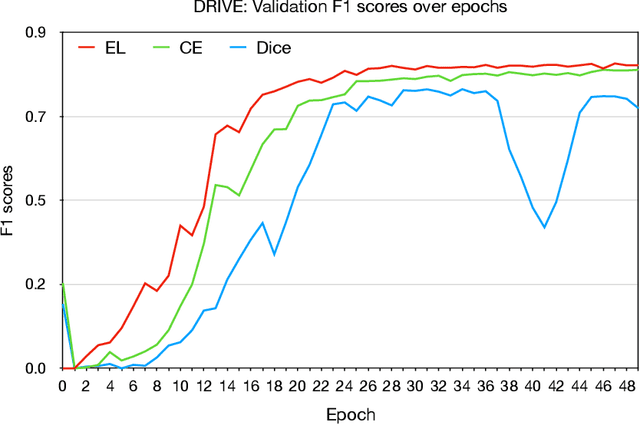
Deep learning techniques have shown their success in medical image segmentation since they are easy to manipulate and robust to various types of datasets. The commonly used loss functions in the deep segmentation task are pixel-wise loss functions. This results in a bottleneck for these models to achieve high precision for complicated structures in biomedical images. For example, the predicted small blood vessels in retinal images are often disconnected or even missed under the supervision of the pixel-wise losses. This paper addresses this problem by introducing a long-range elastic interaction-based training strategy. In this strategy, convolutional neural network (CNN) learns the target region under the guidance of the elastic interaction energy between the boundary of the predicted region and that of the actual object. Under the supervision of the proposed loss, the boundary of the predicted region is attracted strongly by the object boundary and tends to stay connected. Experimental results show that our method is able to achieve considerable improvements compared to commonly used pixel-wise loss functions (cross entropy and dice Loss) and other recent loss functions on three retinal vessel segmentation datasets, DRIVE, STARE and CHASEDB1.
Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing
Dec 22, 2019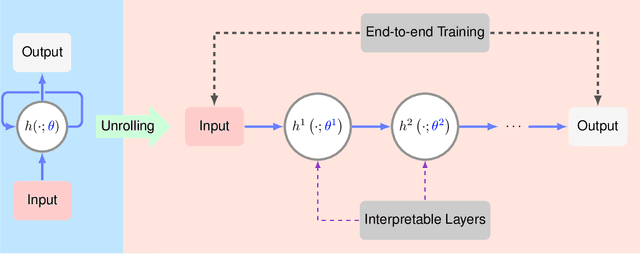
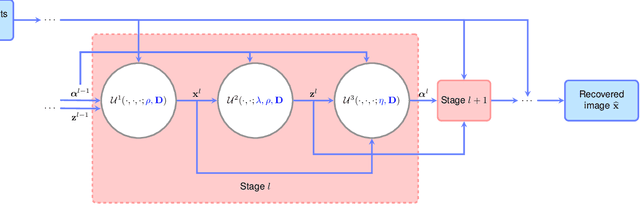

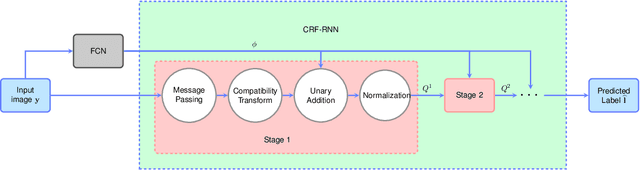
Deep neural networks provide unprecedented performance gains in many real world problems in signal and image processing. Despite these gains, future development and practical deployment of deep networks is hindered by their blackbox nature, i.e., lack of interpretability, and by the need for very large training sets. An emerging technique called algorithm unrolling or unfolding offers promise in eliminating these issues by providing a concrete and systematic connection between iterative algorithms that are used widely in signal processing and deep neural networks. Unrolling methods were first proposed to develop fast neural network approximations for sparse coding. More recently, this direction has attracted enormous attention and is rapidly growing both in theoretic investigations and practical applications. The growing popularity of unrolled deep networks is due in part to their potential in developing efficient, high-performance and yet interpretable network architectures from reasonable size training sets. In this article, we review algorithm unrolling for signal and image processing. We extensively cover popular techniques for algorithm unrolling in various domains of signal and image processing including imaging, vision and recognition, and speech processing. By reviewing previous works, we reveal the connections between iterative algorithms and neural networks and present recent theoretical results. Finally, we provide a discussion on current limitations of unrolling and suggest possible future research directions.
SinGAN: Learning a Generative Model from a Single Natural Image
May 02, 2019


We introduce SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content as the image. SinGAN contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. This allows generating new samples of arbitrary size and aspect ratio, that have significant variability, yet maintain both the global structure and the fine textures of the training image. In contrast to previous single image GAN schemes, our approach is not limited to texture images, and is not conditional (i.e. it generates samples from noise). User studies confirm that the generated samples are commonly confused to be real images. We illustrate the utility of SinGAN in a wide range of image manipulation tasks.
Dynamically Grown Generative Adversarial Networks
Jun 16, 2021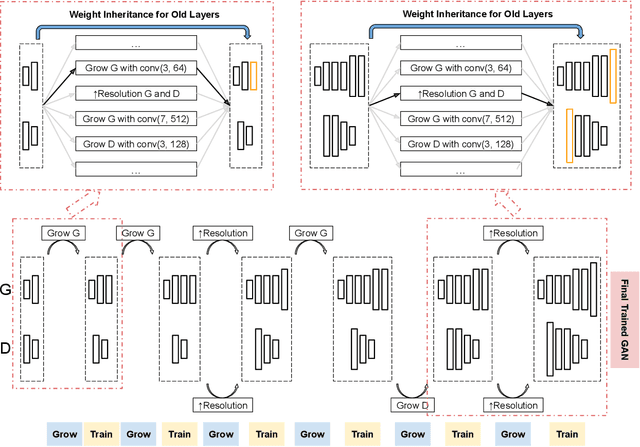
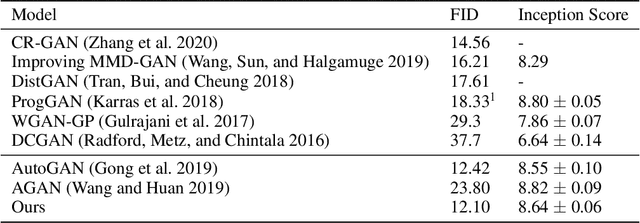


Recent work introduced progressive network growing as a promising way to ease the training for large GANs, but the model design and architecture-growing strategy still remain under-explored and needs manual design for different image data. In this paper, we propose a method to dynamically grow a GAN during training, optimizing the network architecture and its parameters together with automation. The method embeds architecture search techniques as an interleaving step with gradient-based training to periodically seek the optimal architecture-growing strategy for the generator and discriminator. It enjoys the benefits of both eased training because of progressive growing and improved performance because of broader architecture design space. Experimental results demonstrate new state-of-the-art of image generation. Observations in the search procedure also provide constructive insights into the GAN model design such as generator-discriminator balance and convolutional layer choices.
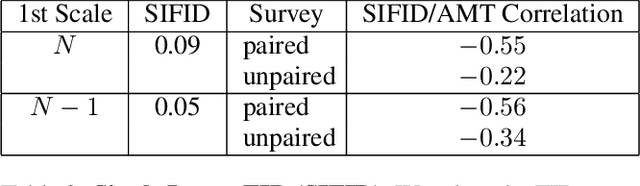
Image Identification Using SIFT Algorithm: Performance Analysis against Different Image Deformations
Mar 13, 2018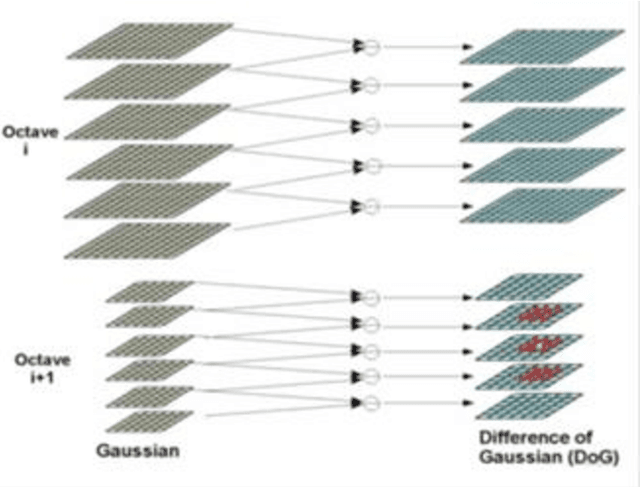
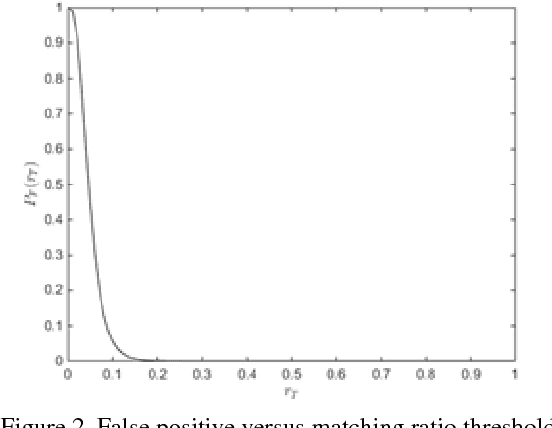
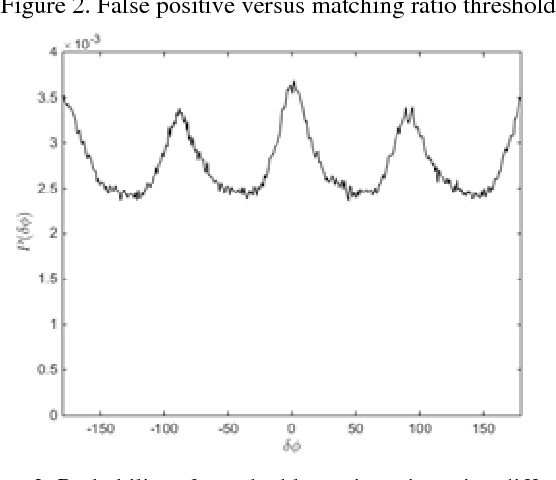
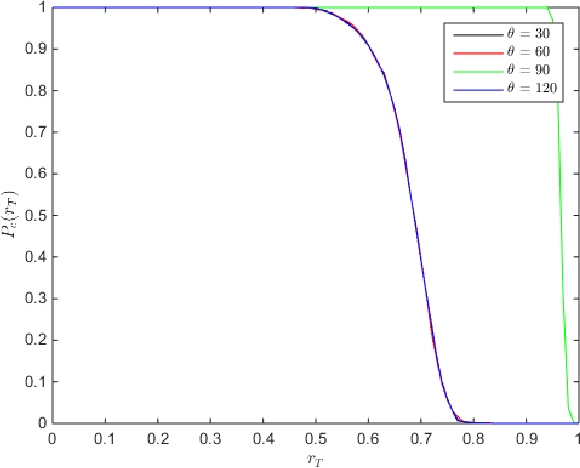
Image identification is one of the most challenging tasks in different areas of computer vision. Scale-invariant feature transform is an algorithm to detect and describe local features in images to further use them as an image matching criteria. In this paper, the performance of the SIFT matching algorithm against various image distortions such as rotation, scaling, fisheye and motion distortion are evaluated and false and true positive rates for a large number of image pairs are calculated and presented. We also evaluate the distribution of the matched keypoint orientation difference for each image deformation.
Source Printer Identification using Printer Specific Pooling of Letter Descriptors
Sep 23, 2021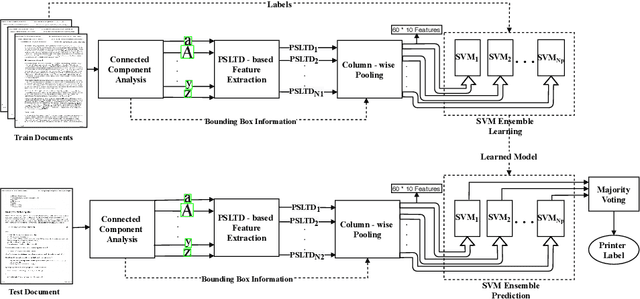
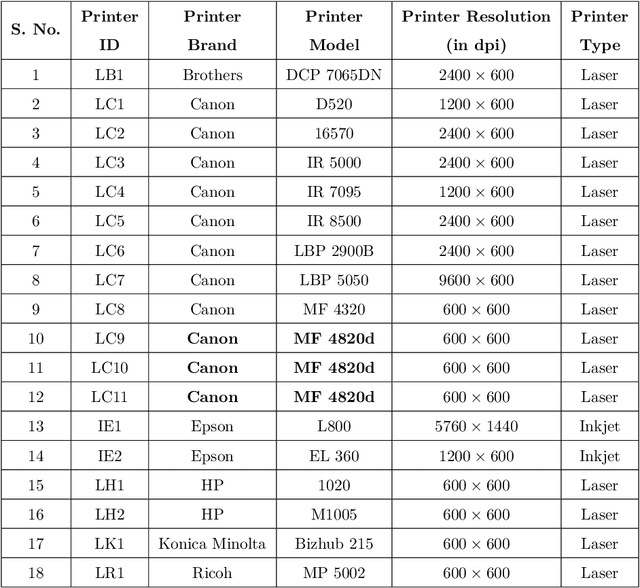
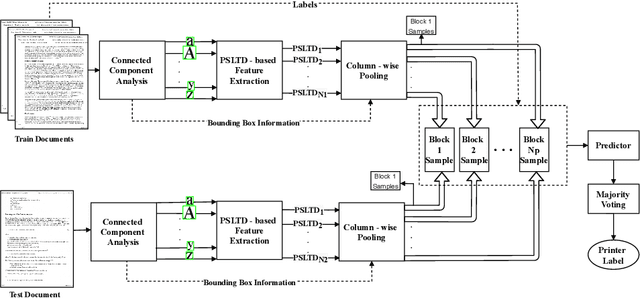
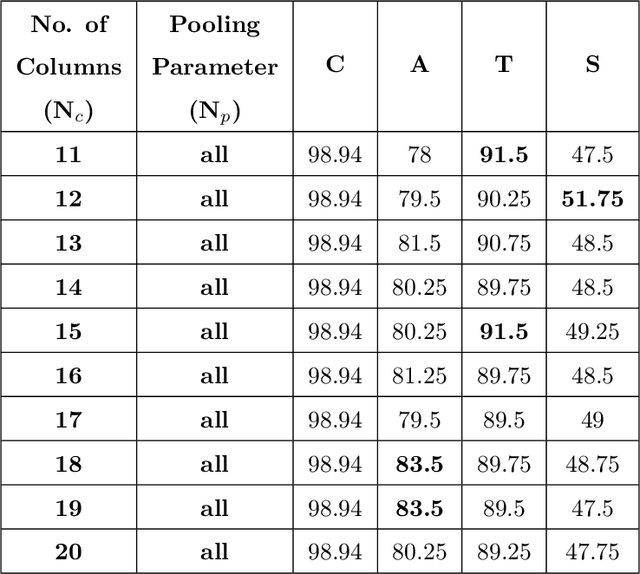
The digital revolution has replaced the use of printed documents with their digital counterparts. However, many applications require the use of both due to several factors, including challenges of digital security, installation costs, ease of use, and lack of digital expertise. Technological developments in the digital domain have also resulted in the easy availability of high-quality scanners, printers, and image editing software at lower prices. Miscreants leverage such technology to develop forged documents that may go undetected in vast volumes of printed documents. These developments mandate the research on creating fast and accurate digital systems for source printer identification of printed documents. We extensively analyze and propose a printer-specific pooling that improves the performance of printer-specific local texture descriptor on two datasets. The proposed pooling performs well using a simple correlation-based prediction instead of a complex machine learning-based classifier achieving improved performance under cross-font scenarios. The proposed system achieves an average classification accuracy of 93.5%, 94.3%, and 60.3% on documents printed in Arial, Times New Roman, and Comic Sans font types respectively, when documents printed in only Cambria font are available for training.
SCEHR: Supervised Contrastive Learning for Clinical Risk Prediction using Electronic Health Records
Oct 11, 2021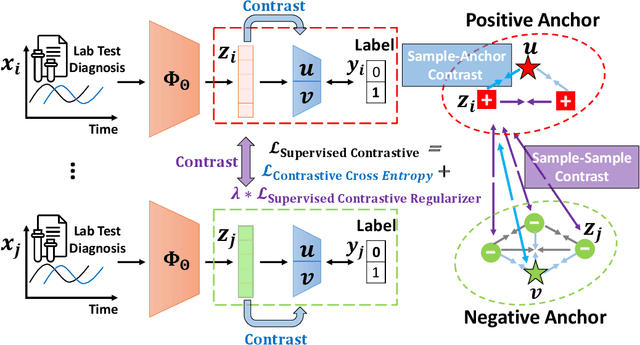
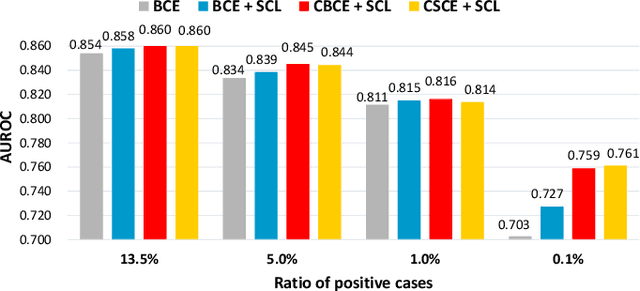
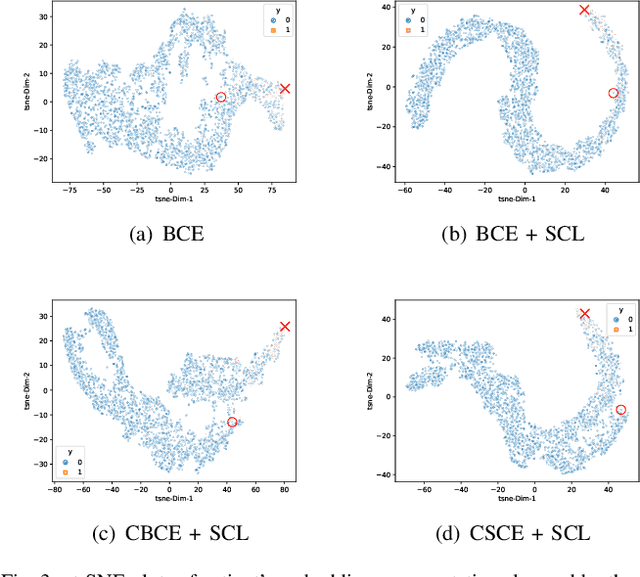

Contrastive learning has demonstrated promising performance in image and text domains either in a self-supervised or a supervised manner. In this work, we extend the supervised contrastive learning framework to clinical risk prediction problems based on longitudinal electronic health records (EHR). We propose a general supervised contrastive loss $\mathcal{L}_{\text{Contrastive Cross Entropy} } + \lambda \mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ for learning both binary classification (e.g. in-hospital mortality prediction) and multi-label classification (e.g. phenotyping) in a unified framework. Our supervised contrastive loss practices the key idea of contrastive learning, namely, pulling similar samples closer and pushing dissimilar ones apart from each other, simultaneously by its two components: $\mathcal{L}_{\text{Contrastive Cross Entropy} }$ tries to contrast samples with learned anchors which represent positive and negative clusters, and $\mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ tries to contrast samples with each other according to their supervised labels. We propose two versions of the above supervised contrastive loss and our experiments on real-world EHR data demonstrate that our proposed loss functions show benefits in improving the performance of strong baselines and even state-of-the-art models on benchmarking tasks for clinical risk predictions. Our loss functions work well with extremely imbalanced data which are common for clinical risk prediction problems. Our loss functions can be easily used to replace (binary or multi-label) cross-entropy loss adopted in existing clinical predictive models. The Pytorch code is released at \url{https://github.com/calvin-zcx/SCEHR}.
Distribution Mismatch Correction for Improved Robustness in Deep Neural Networks
Oct 05, 2021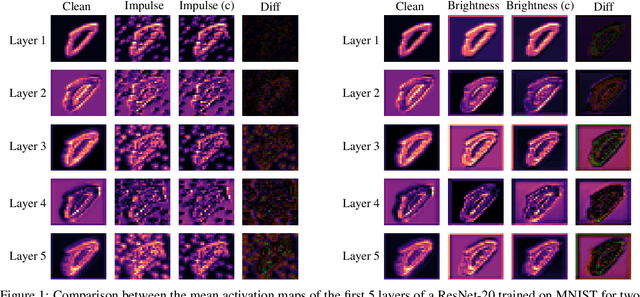
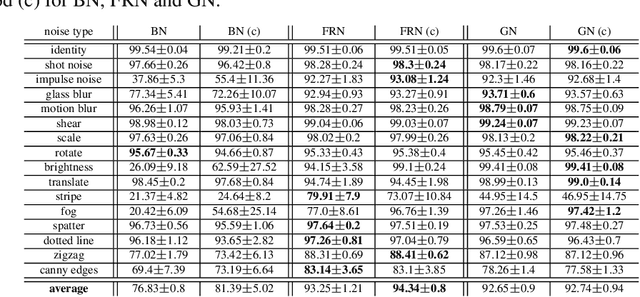
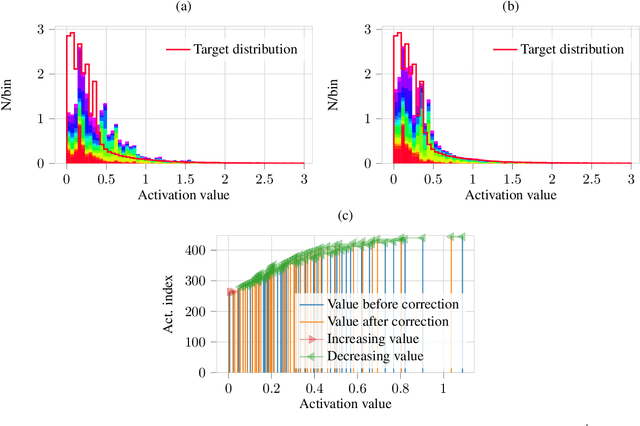
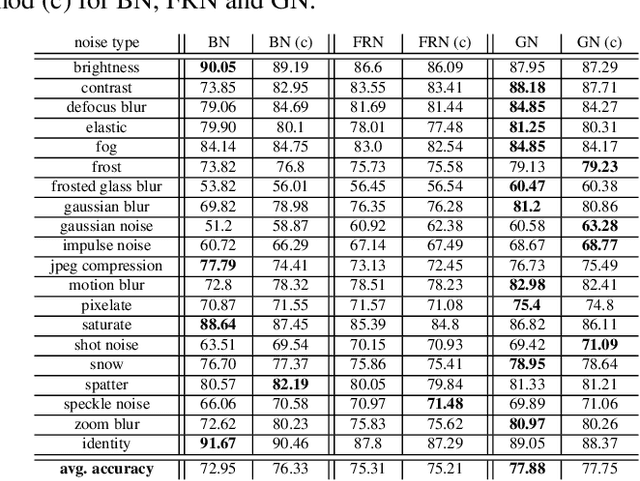
Deep neural networks rely heavily on normalization methods to improve their performance and learning behavior. Although normalization methods spurred the development of increasingly deep and efficient architectures, they also increase the vulnerability with respect to noise and input corruptions. In most applications, however, noise is ubiquitous and diverse; this can often lead to complete failure of machine learning systems as they fail to cope with mismatches between the input distribution during training- and test-time. The most common normalization method, batch normalization, reduces the distribution shift during training but is agnostic to changes in the input distribution during test time. This makes batch normalization prone to performance degradation whenever noise is present during test-time. Sample-based normalization methods can correct linear transformations of the activation distribution but cannot mitigate changes in the distribution shape; this makes the network vulnerable to distribution changes that cannot be reflected in the normalization parameters. We propose an unsupervised non-parametric distribution correction method that adapts the activation distribution of each layer. This reduces the mismatch between the training and test-time distribution by minimizing the 1-D Wasserstein distance. In our experiments, we empirically show that the proposed method effectively reduces the impact of intense image corruptions and thus improves the classification performance without the need for retraining or fine-tuning the model.
Guided Image Generation with Conditional Invertible Neural Networks
Jul 10, 2019

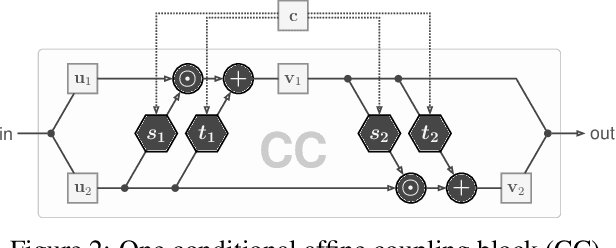
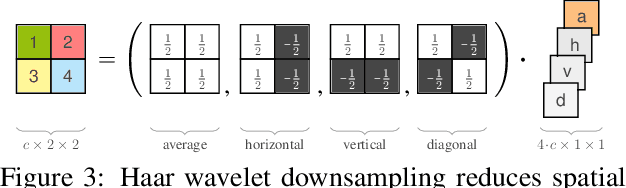
In this work, we address the task of natural image generation guided by a conditioning input. We introduce a new architecture called conditional invertible neural network (cINN). The cINN combines the purely generative INN model with an unconstrained feed-forward network, which efficiently preprocesses the conditioning input into useful features. All parameters of the cINN are jointly optimized with a stable, maximum likelihood-based training procedure. By construction, the cINN does not experience mode collapse and generates diverse samples, in contrast to e.g. cGANs. At the same time our model produces sharp images since no reconstruction loss is required, in contrast to e.g. VAEs. We demonstrate these properties for the tasks of MNIST digit generation and image colorization. Furthermore, we take advantage of our bi-directional cINN architecture to explore and manipulate emergent properties of the latent space, such as changing the image style in an intuitive way.