 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InfoMax-GAN: Improved Adversarial Image Generation via Information Maximization and Contrastive Learning
Jul 09, 2020
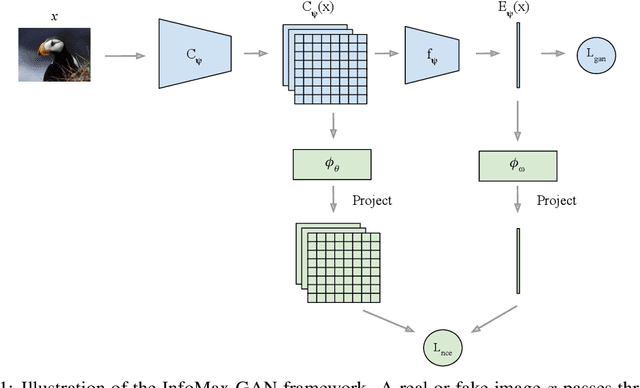
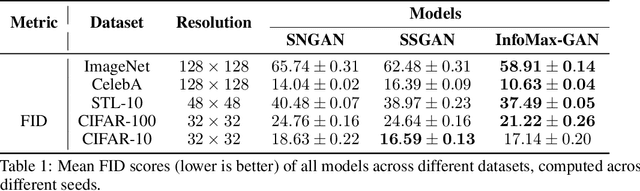
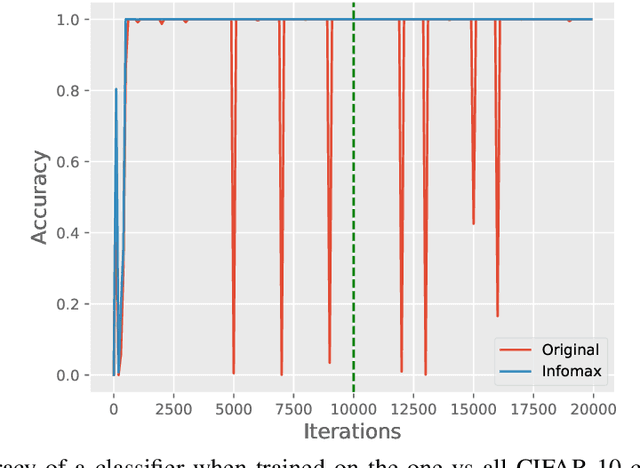
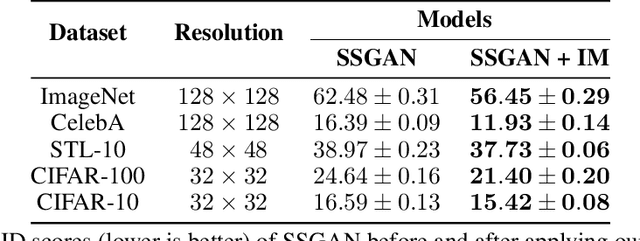
While Generative Adversarial Networks (GANs) are fundamental to many generative modelling applications, they suffer from numerous issues. In this work, we propose a principled framework to simultaneously address two fundamental issues in GANs: catastrophic forgetting of the discriminator and mode collapse of the generator. We achieve this by employing for GANs a contrastive learning and mutual information maximization approach, and perform extensive analyses to understand sources of improvements. Our approach significantly stabilises GAN training and improves GAN performance for image synthesis across five datasets under the same training and evaluation conditions against state-of-the-art works. Our approach is simple to implement and practical: it involves only one objective, is computationally inexpensive, and is robust across a wide range of hyperparameters without any tuning. For reproducibility, our code is available at https://github.com/kwotsin/mimicry.
DICOM Imaging Router: An Open Deep Learning Framework for Classification of Body Parts from DICOM X-ray Scans
Aug 17, 2021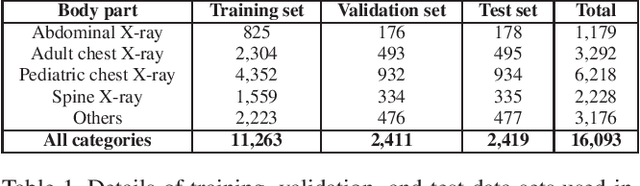
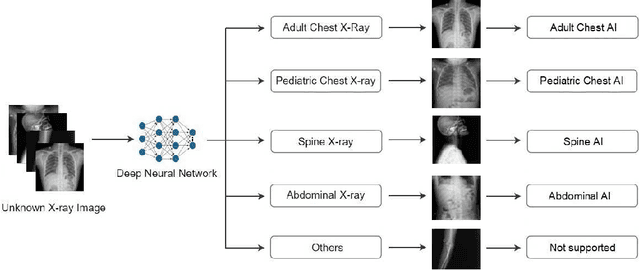
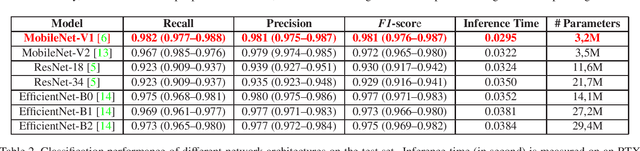

X-ray imaging in DICOM format is the most commonly used imaging modality in clinical practice, resulting in vast, non-normalized databases. This leads to an obstacle in deploying AI solutions for analyzing medical images, which often requires identifying the right body part before feeding the image into a specified AI model. This challenge raises the need for an automated and efficient approach to classifying body parts from X-ray scans. Unfortunately, to the best of our knowledge, there is no open tool or framework for this task to date. To fill this lack, we introduce a DICOM Imaging Router that deploys deep CNNs for categorizing unknown DICOM X-ray images into five anatomical groups: abdominal, adult chest, pediatric chest, spine, and others. To this end, a large-scale X-ray dataset consisting of 16,093 images has been collected and manually classified. We then trained a set of state-of-the-art deep CNNs using a training set of 11,263 images. These networks were then evaluated on an independent test set of 2,419 images and showed superior performance in classifying the body parts. Specifically, our best performing model achieved a recall of 0.982 (95% CI, 0.977-0.988), a precision of 0.985 (95% CI, 0.975-0.989) and a F1-score of 0.981 (95% CI, 0.976-0.987), whilst requiring less computation for inference (0.0295 second per image). Our external validity on 1,000 X-ray images shows the robustness of the proposed approach across hospitals. These remarkable performances indicate that deep CNNs can accurately and effectively differentiate human body parts from X-ray scans, thereby providing potential benefits for a wide range of applications in clinical settings. The dataset, codes, and trained deep learning models from this study will be made publicly available on our project website at https://vindr.ai/.
Exploring the Common Principal Subspace of Deep Features in Neural Networks
Oct 06, 2021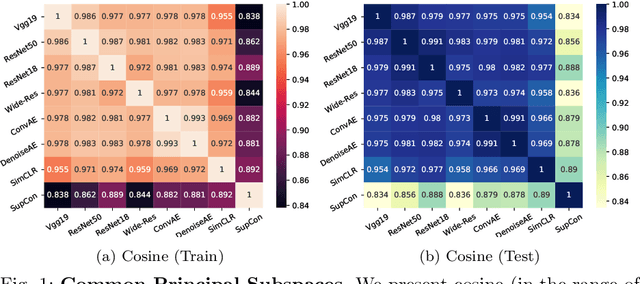

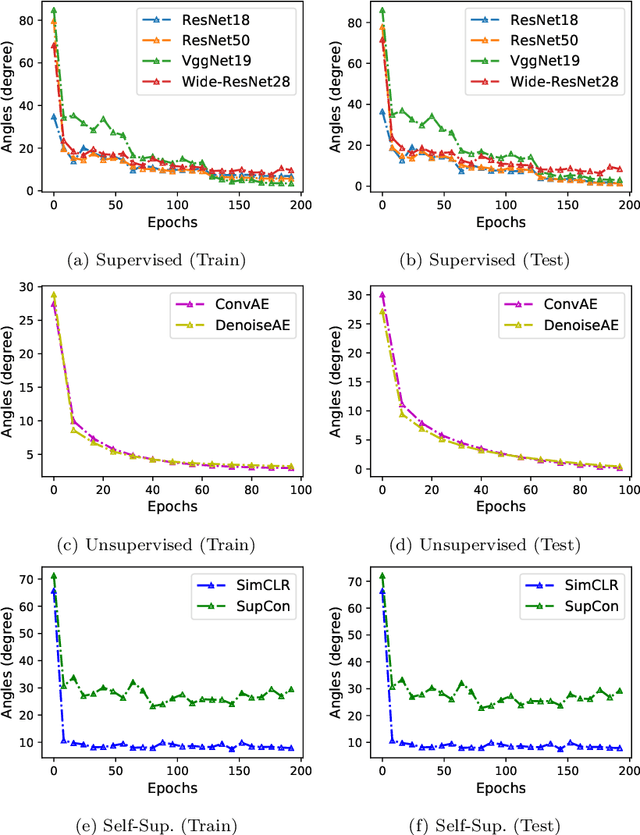
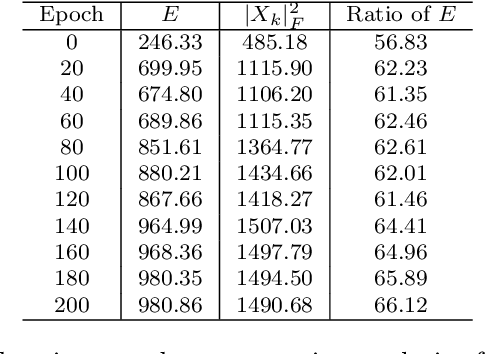
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features
Deep Microlocal Reconstruction for Limited-Angle Tomography
Aug 12, 2021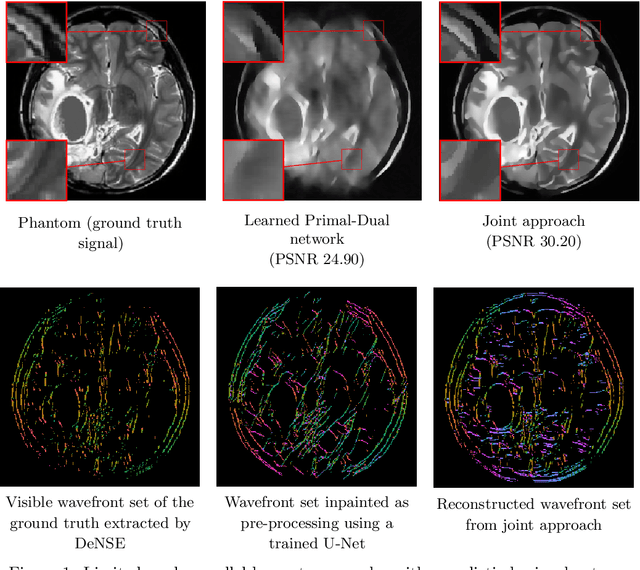
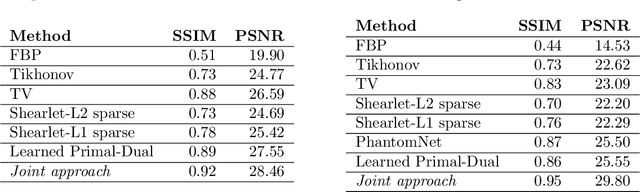

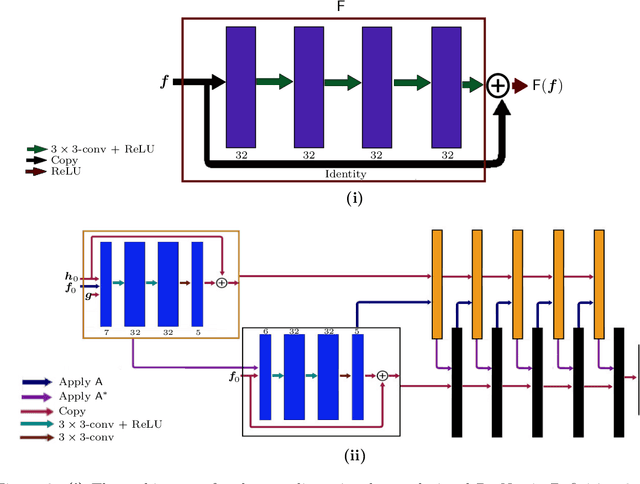
We present a deep learning-based algorithm to jointly solve a reconstruction problem and a wavefront set extraction problem in tomographic imaging. The algorithm is based on a recently developed digital wavefront set extractor as well as the well-known microlocal canonical relation for the Radon transform. We use the wavefront set information about x-ray data to improve the reconstruction by requiring that the underlying neural networks simultaneously extract the correct ground truth wavefront set and ground truth image. As a necessary theoretical step, we identify the digital microlocal canonical relations for deep convolutional residual neural networks. We find strong numerical evidence for the effectiveness of this approach.
Contrastive Mixup: Self- and Semi-Supervised learning for Tabular Domain
Sep 01, 2021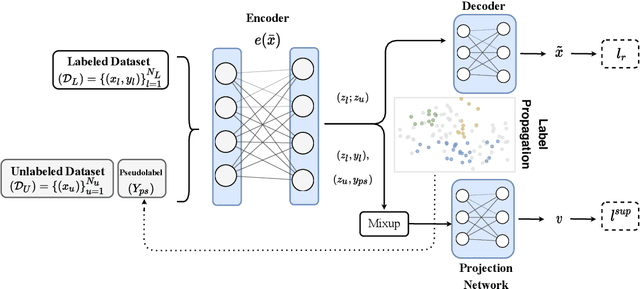
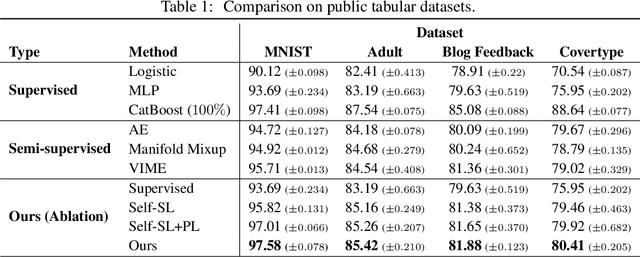
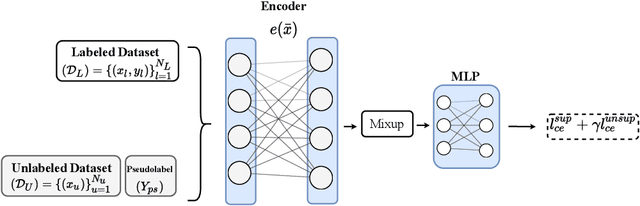
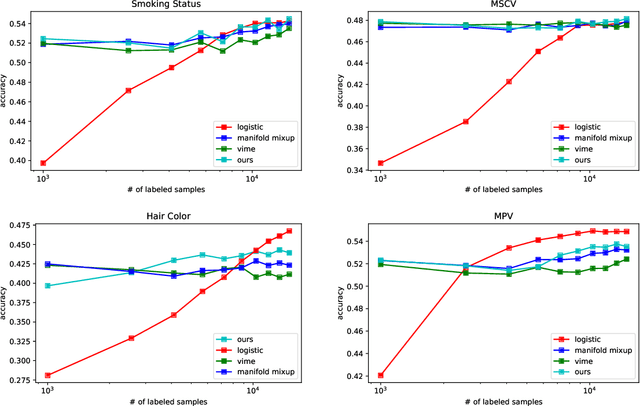
Recent literature in self-supervised has demonstrated significant progress in closing the gap between supervised and unsupervised methods in the image and text domains. These methods rely on domain-specific augmentations that are not directly amenable to the tabular domain. Instead, we introduce Contrastive Mixup, a semi-supervised learning framework for tabular data and demonstrate its effectiveness in limited annotated data settings. Our proposed method leverages Mixup-based augmentation under the manifold assumption by mapping samples to a low dimensional latent space and encourage interpolated samples to have high a similarity within the same labeled class. Unlabeled samples are additionally employed via a transductive label propagation method to further enrich the set of similar and dissimilar pairs that can be used in the contrastive loss term. We demonstrate the effectiveness of the proposed framework on public tabular datasets and real-world clinical datasets.
An Elastic Interaction-Based Loss Function for Medical Image Segmentation
Jul 06, 2020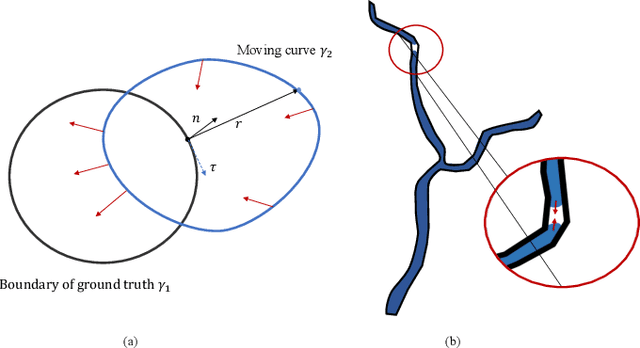
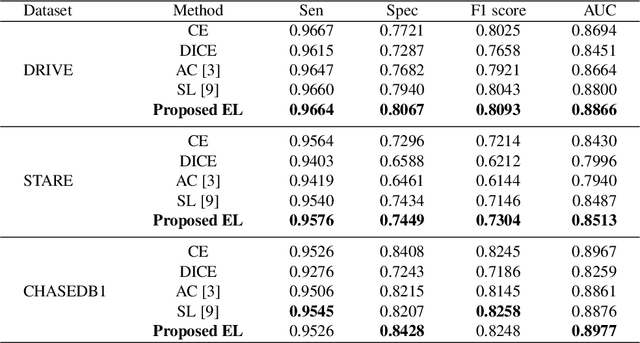
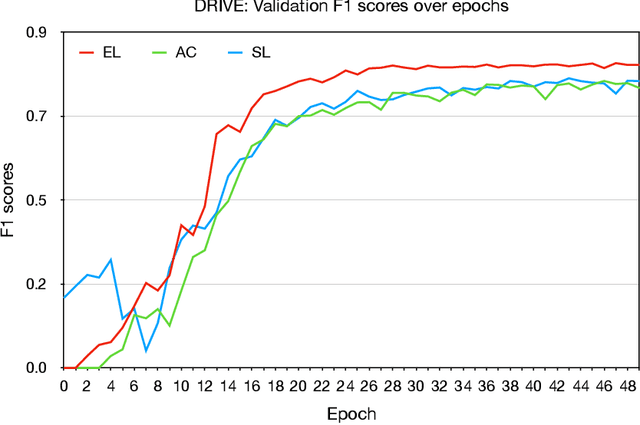
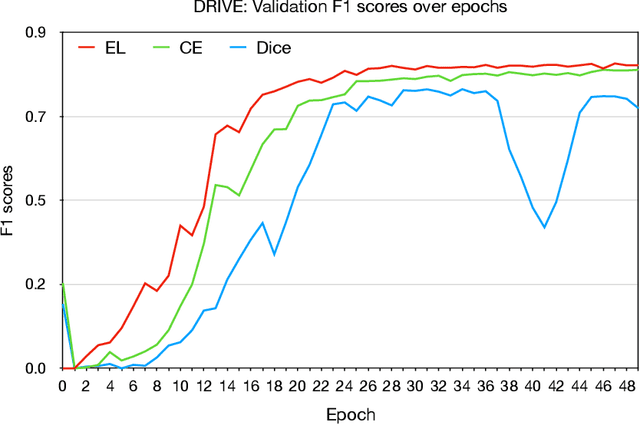
Deep learning techniques have shown their success in medical image segmentation since they are easy to manipulate and robust to various types of datasets. The commonly used loss functions in the deep segmentation task are pixel-wise loss functions. This results in a bottleneck for these models to achieve high precision for complicated structures in biomedical images. For example, the predicted small blood vessels in retinal images are often disconnected or even missed under the supervision of the pixel-wise losses. This paper addresses this problem by introducing a long-range elastic interaction-based training strategy. In this strategy, convolutional neural network (CNN) learns the target region under the guidance of the elastic interaction energy between the boundary of the predicted region and that of the actual object. Under the supervision of the proposed loss, the boundary of the predicted region is attracted strongly by the object boundary and tends to stay connected. Experimental results show that our method is able to achieve considerable improvements compared to commonly used pixel-wise loss functions (cross entropy and dice Loss) and other recent loss functions on three retinal vessel segmentation datasets, DRIVE, STARE and CHASEDB1.
Guided Image Generation with Conditional Invertible Neural Networks
Jul 10, 2019

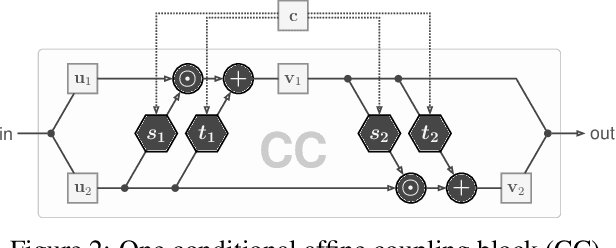
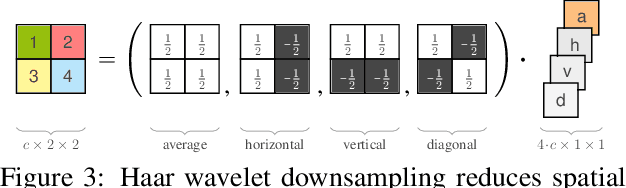
In this work, we address the task of natural image generation guided by a conditioning input. We introduce a new architecture called conditional invertible neural network (cINN). The cINN combines the purely generative INN model with an unconstrained feed-forward network, which efficiently preprocesses the conditioning input into useful features. All parameters of the cINN are jointly optimized with a stable, maximum likelihood-based training procedure. By construction, the cINN does not experience mode collapse and generates diverse samples, in contrast to e.g. cGANs. At the same time our model produces sharp images since no reconstruction loss is required, in contrast to e.g. VAEs. We demonstrate these properties for the tasks of MNIST digit generation and image colorization. Furthermore, we take advantage of our bi-directional cINN architecture to explore and manipulate emergent properties of the latent space, such as changing the image style in an intuitive way.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021



In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.
Pointing Novel Objects in Image Captioning
Apr 25, 2019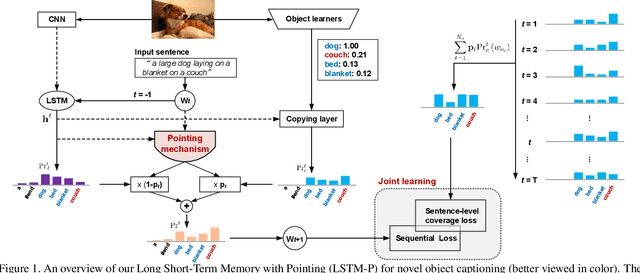
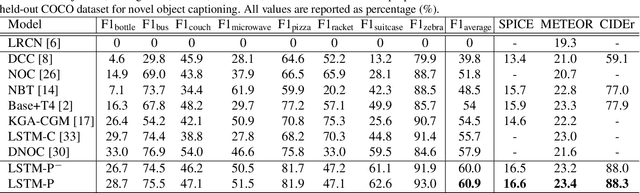

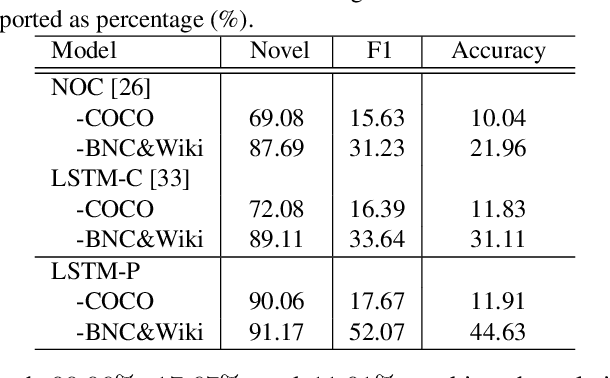
Image captioning has received significant attention with remarkable improvements in recent advances. Nevertheless, images in the wild encapsulate rich knowledge and cannot be sufficiently described with models built on image-caption pairs containing only in-domain objects. In this paper, we propose to address the problem by augmenting standard deep captioning architectures with object learners. Specifically, we present Long Short-Term Memory with Pointing (LSTM-P) --- a new architecture that facilitates vocabulary expansion and produces novel objects via pointing mechanism. Technically, object learners are initially pre-trained on available object recognition data. Pointing in LSTM-P then balances the probability between generating a word through LSTM and copying a word from the recognized objects at each time step in decoder stage. Furthermore, our captioning encourages global coverage of objects in the sentence. Extensive experiments are conducted on both held-out COCO image captioning and ImageNet datasets for describing novel objects, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain an average of 60.9% in F1 score on held-out COCO~dataset.
Style transfer based data augmentation in material microscopic image processing
May 12, 2019

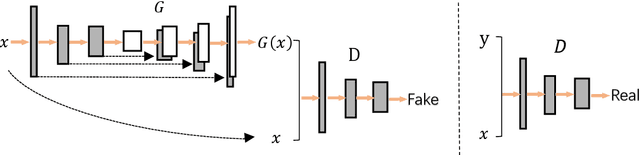

Recently progress in material microscopic image semantic segmentation has been driven by high-capacity models trained on large datasets. However, collecting microscopic images with pixel-level labels has been extremely costly due to the amount of human effort required. In this paper, we present an approach to rapidly creating microscopic images with pixel-level labels from material 3d simulated models. Usually images extracted directly from those 3d simulated models are not realistic enough. It is easy to get semantic labels, though. We introduce style transfer technique to make simulated image data more similar to real microscopic data. We validate the presented approach by using real image data from experiment and simulated image data from Monte Carlo Potts Models, which simulate the growth of polycrystal. Experiments show that using the acquired simulated image data and style transfer technique to supplement real images of polycrystalline iron significantly improves the mean precision of image processing. Besides, models trained with simulated image data and just 1/3 of the real data outperform models trained on the complete real image data. In the study of such polycrystalline materials, this approach can reduce pressure of getting and labeling images from microscopes. Also, it can be applied to numbers of other material images.