 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Style transfer based data augmentation in material microscopic image processing
May 12, 2019


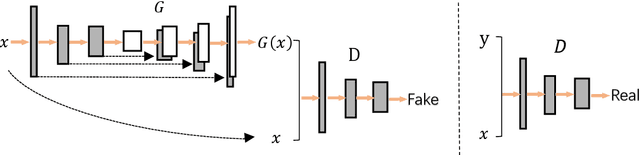

Recently progress in material microscopic image semantic segmentation has been driven by high-capacity models trained on large datasets. However, collecting microscopic images with pixel-level labels has been extremely costly due to the amount of human effort required. In this paper, we present an approach to rapidly creating microscopic images with pixel-level labels from material 3d simulated models. Usually images extracted directly from those 3d simulated models are not realistic enough. It is easy to get semantic labels, though. We introduce style transfer technique to make simulated image data more similar to real microscopic data. We validate the presented approach by using real image data from experiment and simulated image data from Monte Carlo Potts Models, which simulate the growth of polycrystal. Experiments show that using the acquired simulated image data and style transfer technique to supplement real images of polycrystalline iron significantly improves the mean precision of image processing. Besides, models trained with simulated image data and just 1/3 of the real data outperform models trained on the complete real image data. In the study of such polycrystalline materials, this approach can reduce pressure of getting and labeling images from microscopes. Also, it can be applied to numbers of other material images.
A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications
Jun 17, 2021
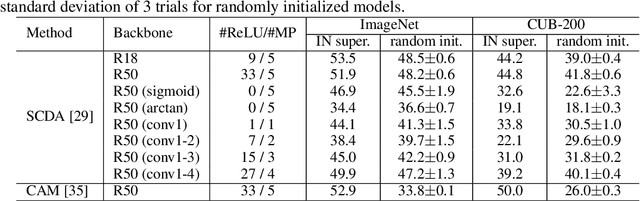
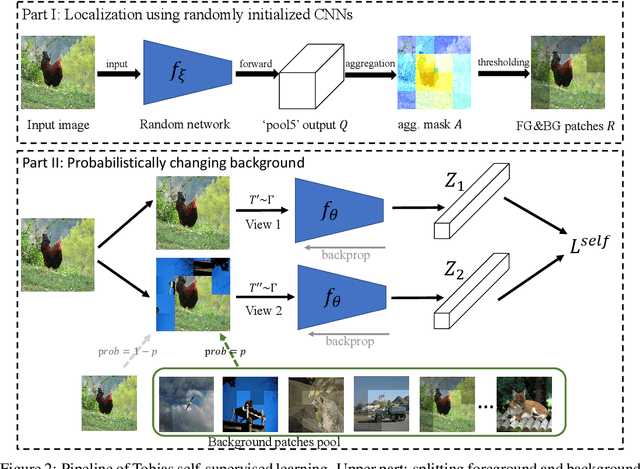
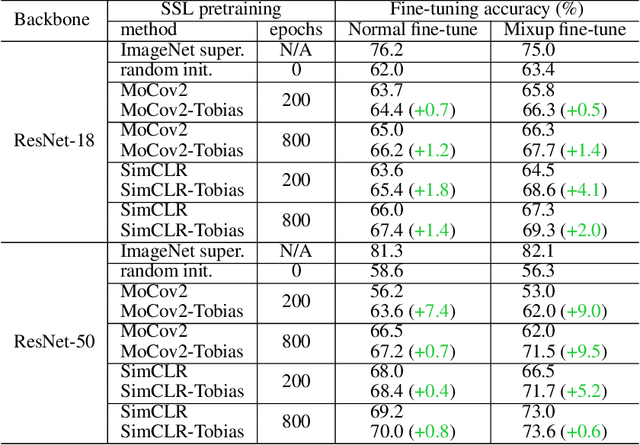
This paper starts by revealing a surprising finding: without any learning, a randomly initialized CNN can localize objects surprisingly well. That is, a CNN has an inductive bias to naturally focus on objects, named as Tobias (``The object is at sight'') in this paper. This empirical inductive bias is further analyzed and successfully applied to self-supervised learning. A CNN is encouraged to learn representations that focus on the foreground object, by transforming every image into various versions with different backgrounds, where the foreground and background separation is guided by Tobias. Experimental results show that the proposed Tobias significantly improves downstream tasks, especially for object detection. This paper also shows that Tobias has consistent improvements on training sets of different sizes, and is more resilient to changes in image augmentations. Our codes will be available at https://github.com/CupidJay/Tobias.
Improving Deep Image Clustering With Spatial Transformer Layers
Feb 09, 2019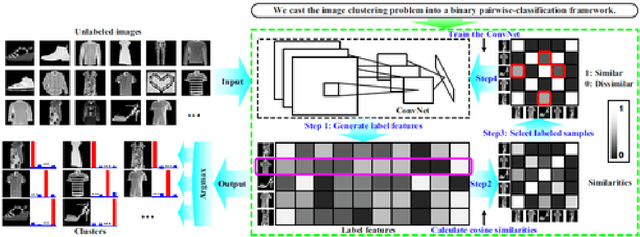
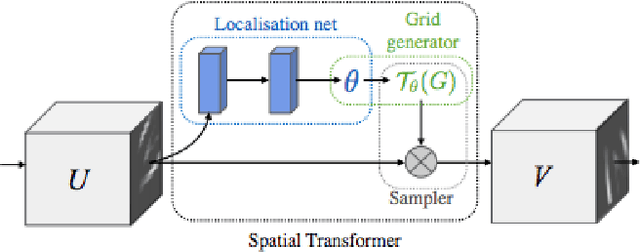
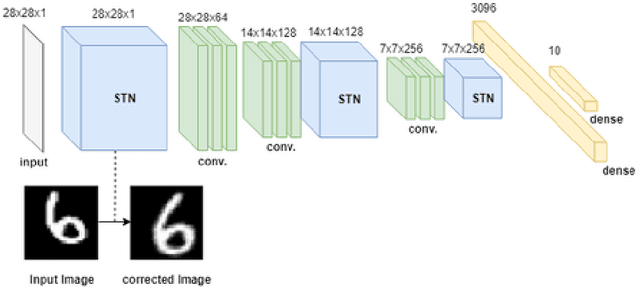

Image clustering is an important but challenging task in machine learning. As in most image processing areas, the latest improvements came from models based on the deep learning approach. However, classical deep learning methods have problems to deal with spatial image transformations like scale and rotation. In this paper, we propose the use of visual attention techniques to reduce this problem in image clustering methods. We evaluate the combination of a deep image clustering model called Deep Adaptive Clustering (DAC) with the Visual Spatial Transformer Networks (STN). The proposed model is evaluated in the datasets MNIST and FashionMNIST and outperformed the baseline model in experiments.
AnoSeg: Anomaly Segmentation Network Using Self-Supervised Learning
Oct 07, 2021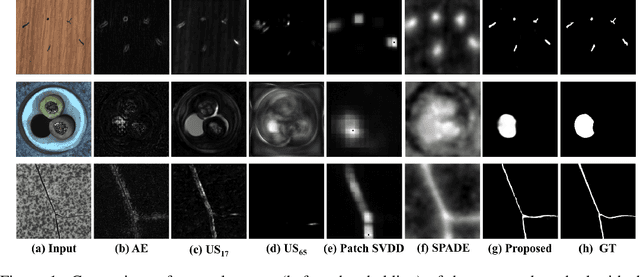
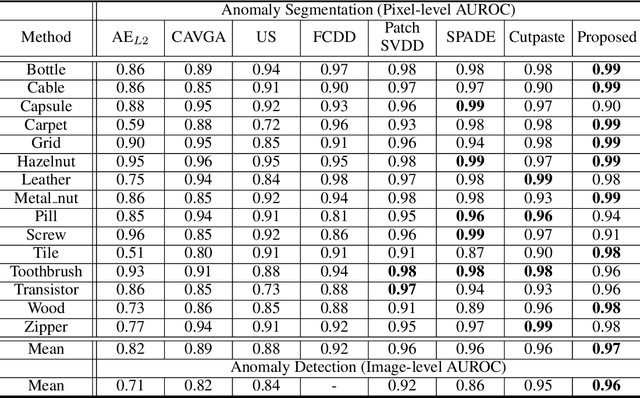
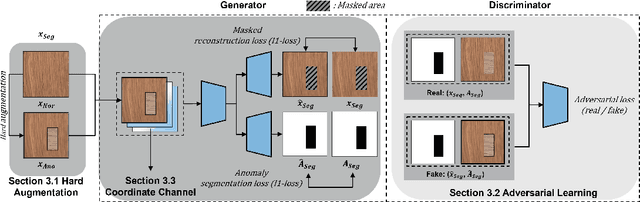

Anomaly segmentation, which localizes defective areas, is an important component in large-scale industrial manufacturing. However, most recent researches have focused on anomaly detection. This paper proposes a novel anomaly segmentation network (AnoSeg) that can directly generate an accurate anomaly map using self-supervised learning. For highly accurate anomaly segmentation, the proposed AnoSeg considers three novel techniques: Anomaly data generation based on hard augmentation, self-supervised learning with pixel-wise and adversarial losses, and coordinate channel concatenation. First, to generate synthetic anomaly images and reference masks for normal data, the proposed method uses hard augmentation to change the normal sample distribution. Then, the proposed AnoSeg is trained in a self-supervised learning manner from the synthetic anomaly data and normal data. Finally, the coordinate channel, which represents the pixel location information, is concatenated to an input of AnoSeg to consider the positional relationship of each pixel in the image. The estimated anomaly map can also be utilized to improve the performance of anomaly detection. Our experiments show that the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for the MVTec AD dataset. In addition, we compared the proposed method with the existing methods through the intersection over union (IoU) metric commonly used in segmentation tasks and demonstrated the superiority of our method for anomaly segmentation.
Guided Image Generation with Conditional Invertible Neural Networks
Jul 10, 2019

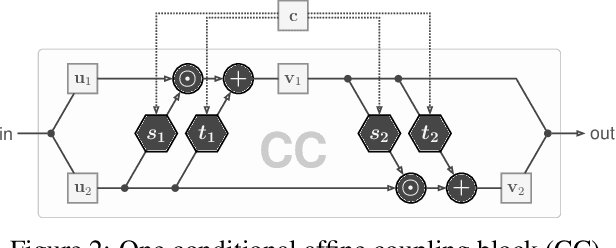
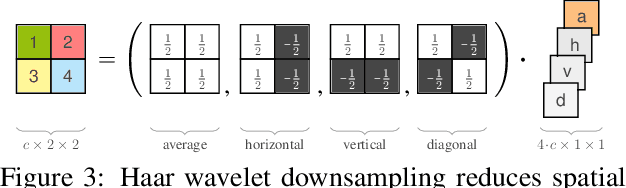
In this work, we address the task of natural image generation guided by a conditioning input. We introduce a new architecture called conditional invertible neural network (cINN). The cINN combines the purely generative INN model with an unconstrained feed-forward network, which efficiently preprocesses the conditioning input into useful features. All parameters of the cINN are jointly optimized with a stable, maximum likelihood-based training procedure. By construction, the cINN does not experience mode collapse and generates diverse samples, in contrast to e.g. cGANs. At the same time our model produces sharp images since no reconstruction loss is required, in contrast to e.g. VAEs. We demonstrate these properties for the tasks of MNIST digit generation and image colorization. Furthermore, we take advantage of our bi-directional cINN architecture to explore and manipulate emergent properties of the latent space, such as changing the image style in an intuitive way.
FD-GAN: Generative Adversarial Networks with Fusion-discriminator for Single Image Dehazing
Jan 20, 2020
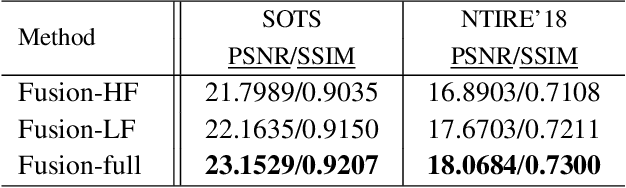


Recently, convolutional neural networks (CNNs) have achieved great improvements in single image dehazing and attained much attention in research. Most existing learning-based dehazing methods are not fully end-to-end, which still follow the traditional dehazing procedure: first estimate the medium transmission and the atmospheric light, then recover the haze-free image based on the atmospheric scattering model. However, in practice, due to lack of priors and constraints, it is hard to precisely estimate these intermediate parameters. Inaccurate estimation further degrades the performance of dehazing, resulting in artifacts, color distortion and insufficient haze removal. To address this, we propose a fully end-to-end Generative Adversarial Networks with Fusion-discriminator (FD-GAN) for image dehazing. With the proposed Fusion-discriminator which takes frequency information as additional priors, our model can generator more natural and realistic dehazed images with less color distortion and fewer artifacts. Moreover, we synthesize a large-scale training dataset including various indoor and outdoor hazy images to boost the performance and we reveal that for learning-based dehazing methods, the performance is strictly influenced by the training data. Experiments have shown that our method reaches state-of-the-art performance on both public synthetic datasets and real-world images with more visually pleasing dehazed results.
Probing Inter-modality: Visual Parsing with Self-Attention for Vision-Language Pre-training
Jun 28, 2021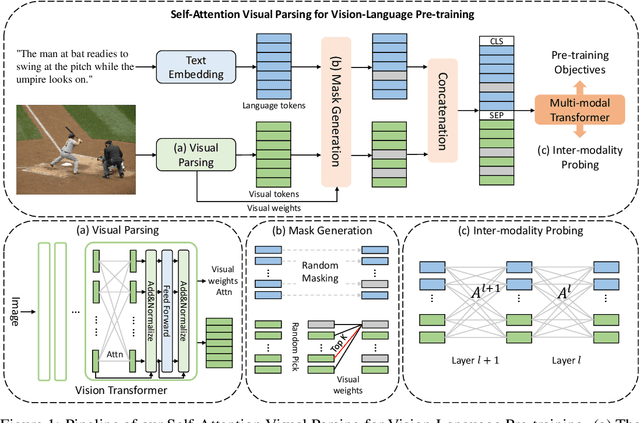
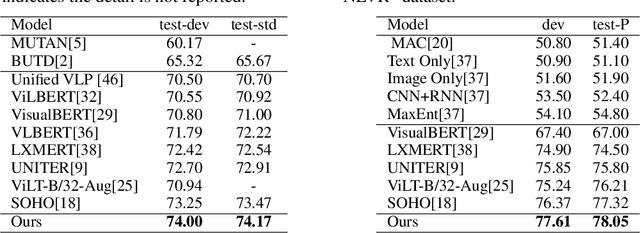

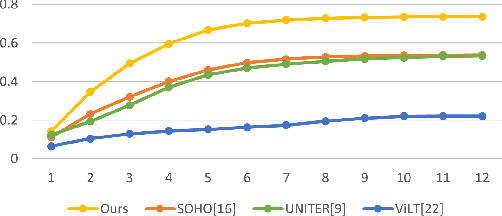
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.
Pointing Novel Objects in Image Captioning
Apr 25, 2019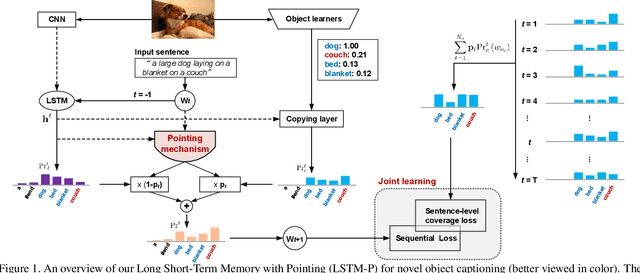
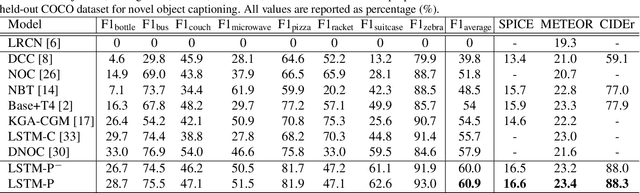

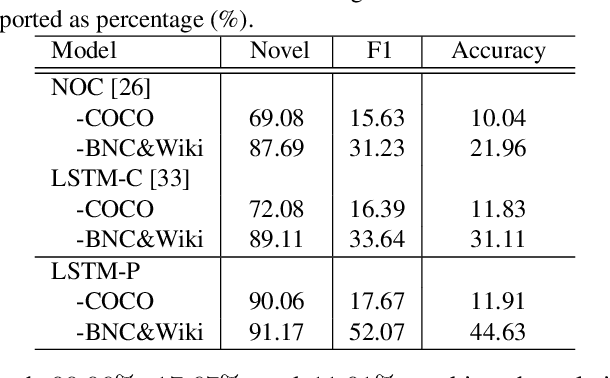
Image captioning has received significant attention with remarkable improvements in recent advances. Nevertheless, images in the wild encapsulate rich knowledge and cannot be sufficiently described with models built on image-caption pairs containing only in-domain objects. In this paper, we propose to address the problem by augmenting standard deep captioning architectures with object learners. Specifically, we present Long Short-Term Memory with Pointing (LSTM-P) --- a new architecture that facilitates vocabulary expansion and produces novel objects via pointing mechanism. Technically, object learners are initially pre-trained on available object recognition data. Pointing in LSTM-P then balances the probability between generating a word through LSTM and copying a word from the recognized objects at each time step in decoder stage. Furthermore, our captioning encourages global coverage of objects in the sentence. Extensive experiments are conducted on both held-out COCO image captioning and ImageNet datasets for describing novel objects, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain an average of 60.9% in F1 score on held-out COCO~dataset.
Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing
Dec 22, 2019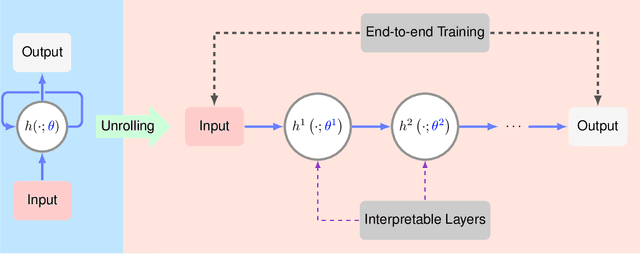
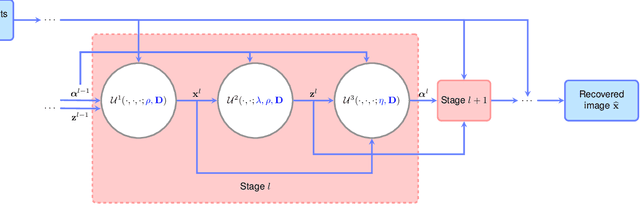

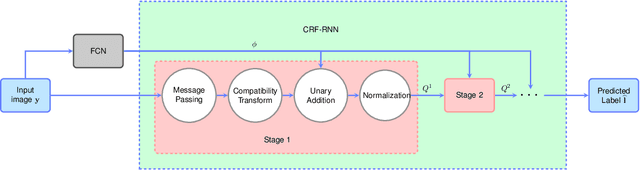
Deep neural networks provide unprecedented performance gains in many real world problems in signal and image processing. Despite these gains, future development and practical deployment of deep networks is hindered by their blackbox nature, i.e., lack of interpretability, and by the need for very large training sets. An emerging technique called algorithm unrolling or unfolding offers promise in eliminating these issues by providing a concrete and systematic connection between iterative algorithms that are used widely in signal processing and deep neural networks. Unrolling methods were first proposed to develop fast neural network approximations for sparse coding. More recently, this direction has attracted enormous attention and is rapidly growing both in theoretic investigations and practical applications. The growing popularity of unrolled deep networks is due in part to their potential in developing efficient, high-performance and yet interpretable network architectures from reasonable size training sets. In this article, we review algorithm unrolling for signal and image processing. We extensively cover popular techniques for algorithm unrolling in various domains of signal and image processing including imaging, vision and recognition, and speech processing. By reviewing previous works, we reveal the connections between iterative algorithms and neural networks and present recent theoretical results. Finally, we provide a discussion on current limitations of unrolling and suggest possible future research directions.
Structured Outdoor Architecture Reconstruction by Exploration and Classification
Aug 18, 2021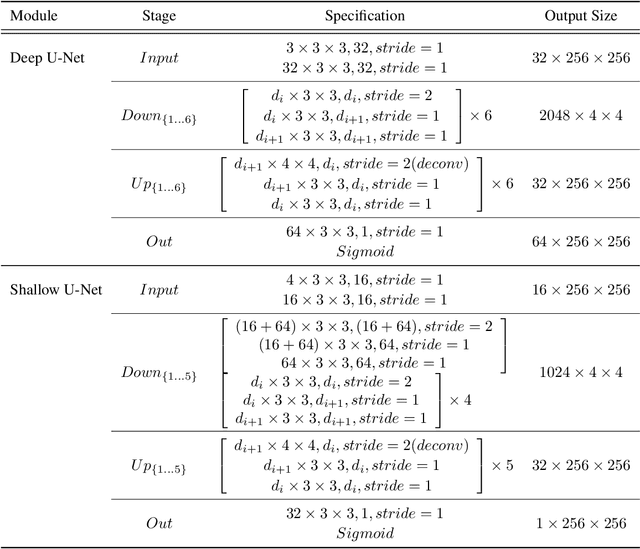


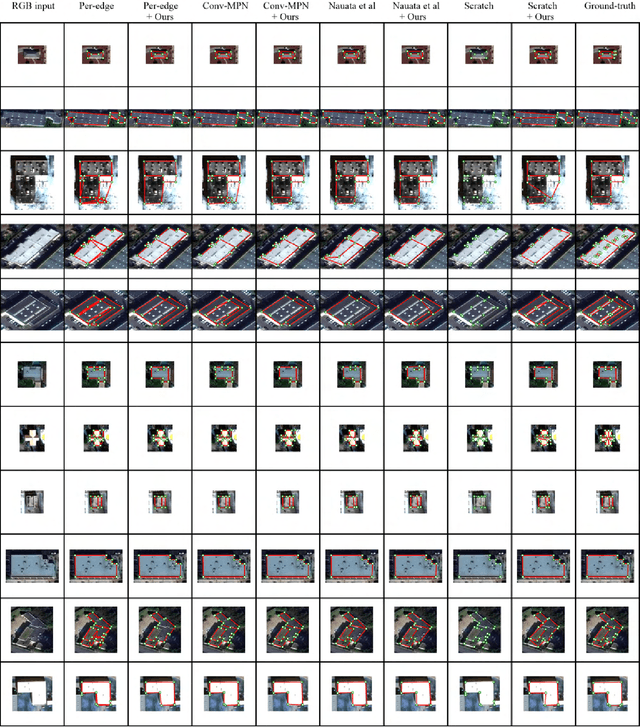
This paper presents an explore-and-classify framework for structured architectural reconstruction from an aerial image. Starting from a potentially imperfect building reconstruction by an existing algorithm, our approach 1) explores the space of building models by modifying the reconstruction via heuristic actions; 2) learns to classify the correctness of building models while generating classification labels based on the ground-truth, and 3) repeat. At test time, we iterate exploration and classification, seeking for a result with the best classification score. We evaluate the approach using initial reconstructions by two baselines and two state-of-the-art reconstruction algorithms. Qualitative and quantitative evaluations demonstrate that our approach consistently improves the reconstruction quality from every initial reconstruction.