 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transform-Invariant Convolutional Neural Networks for Image Classification and Search
Nov 28, 2019
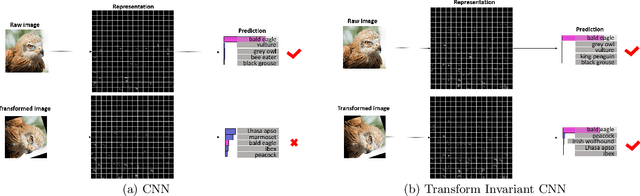
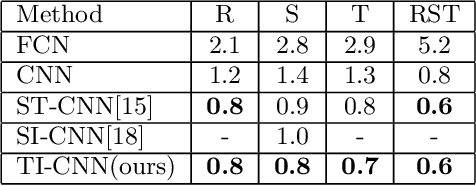
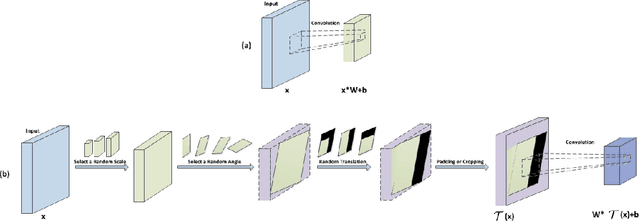
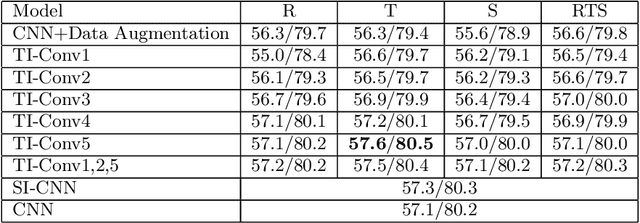
Convolutional neural networks (CNNs) have achieved state-of-the-art results on many visual recognition tasks. However, current CNN models still exhibit a poor ability to be invariant to spatial transformations of images. Intuitively, with sufficient layers and parameters, hierarchical combinations of convolution (matrix multiplication and non-linear activation) and pooling operations should be able to learn a robust mapping from transformed input images to transform-invariant representations. In this paper, we propose randomly transforming (rotation, scale, and translation) feature maps of CNNs during the training stage. This prevents complex dependencies of specific rotation, scale, and translation levels of training images in CNN models. Rather, each convolutional kernel learns to detect a feature that is generally helpful for producing the transform-invariant answer given the combinatorially large variety of transform levels of its input feature maps. In this way, we do not require any extra training supervision or modification to the optimization process and training images. We show that random transformation provides significant improvements of CNNs on many benchmark tasks, including small-scale image recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com/jasonustc/caffe-multigpu/tree/TICNN.
XDEEP-MSI: Explainable Bias-Rejecting Microsatellite Instability Deep Learning System In Colorectal Cancer
Oct 28, 2021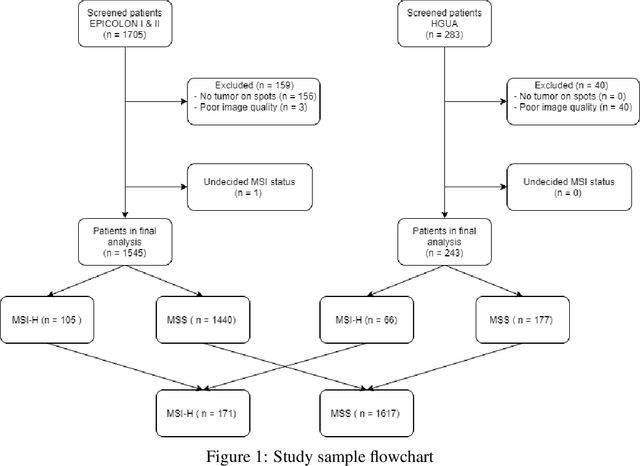
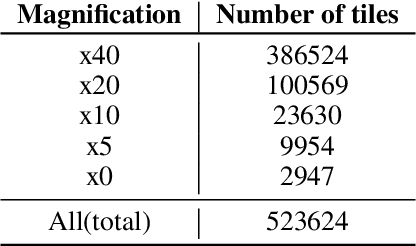
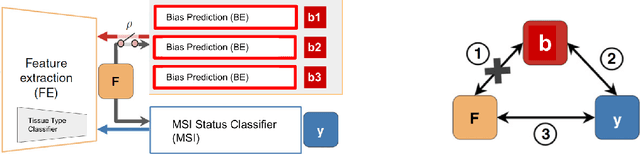
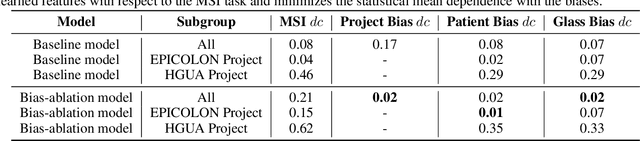
We present a system for the prediction of microsatellite instability (MSI) from H&E images of colorectal cancer using deep learning (DL) techniques customized for tissue microarrays (TMAs). The system incorporates an end-to-end image preprocessing module that produces tiles at multiple magnifications in the regions of interest as guided by a tissue classifier module, and a multiple-bias rejecting module. The training and validation TMA samples were obtained from the EPICOLON project and further enriched with samples from a single institution. A systematic study of biases at tile level identified three protected (bias) variables associated with the learned representations of a baseline model: the project of origin of samples, the patient spot and the TMA glass where each spot was placed. A multiple bias rejecting technique based on adversarial training is implemented at the DL architecture so to directly avoid learning the batch effects of those variables. The learned features from the bias-ablated model have maximum discriminative power with respect to the task and minimal statistical mean dependence with the biases. The impact of different magnifications, types of tissues and the model performance at tile vs patient level is analyzed. The AUC at tile level, and including all three selected tissues (tumor epithelium, mucine and lymphocytic regions) and 4 magnifications, was 0.87 +/- 0.03 and increased to 0.9 +/- 0.03 at patient level. To the best of our knowledge, this is the first work that incorporates a multiple bias ablation technique at the DL architecture in digital pathology, and the first using TMAs for the MSI prediction task.
Fourier Series Expansion Based Filter Parametrization for Equivariant Convolutions
Jul 30, 2021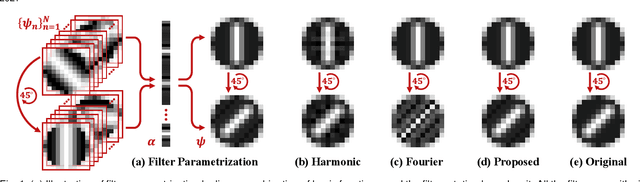
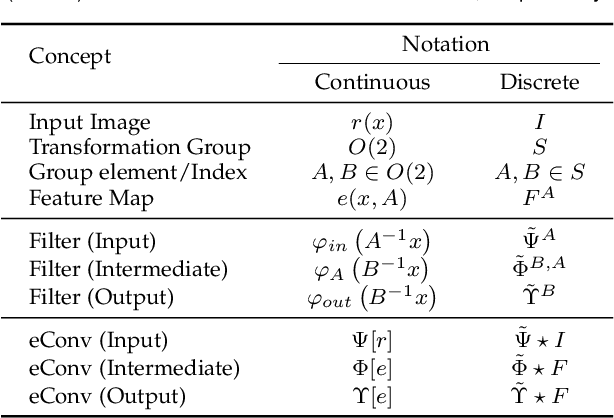
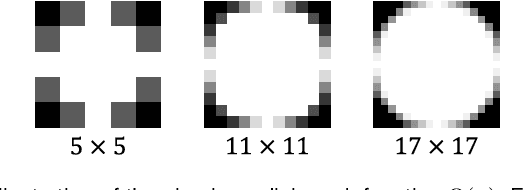
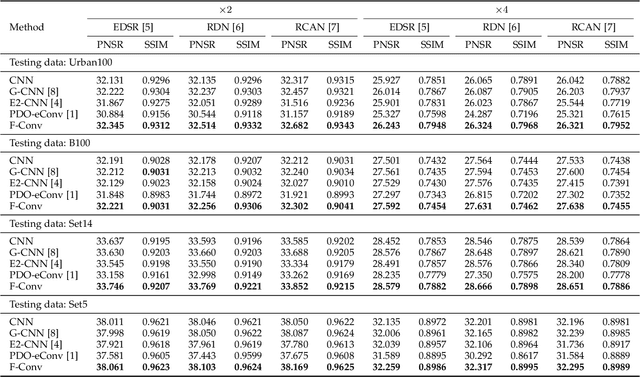
It has been shown that equivariant convolution is very helpful for many types of computer vision tasks. Recently, the 2D filter parametrization technique plays an important role when designing equivariant convolutions. However, the current filter parametrization method still has its evident drawbacks, where the most critical one lies in the accuracy problem of filter representation. Against this issue, in this paper we modify the classical Fourier series expansion for 2D filters, and propose a new set of atomic basis functions for filter parametrization. The proposed filter parametrization method not only finely represents 2D filters with zero error when the filter is not rotated, but also substantially alleviates the fence-effect-caused quality degradation when the filter is rotated. Accordingly, we construct a new equivariant convolution method based on the proposed filter parametrization method, named F-Conv. We prove that the equivariance of the proposed F-Conv is exact in the continuous domain, which becomes approximate only after discretization. Extensive experiments show the superiority of the proposed method. Particularly, we adopt rotation equivariant convolution methods to image super-resolution task, and F-Conv evidently outperforms previous filter parametrization based method in this task, reflecting its intrinsic capability of faithfully preserving rotation symmetries in local image features.
MS-NAS: Multi-Scale Neural Architecture Search for Medical Image Segmentation
Jul 13, 2020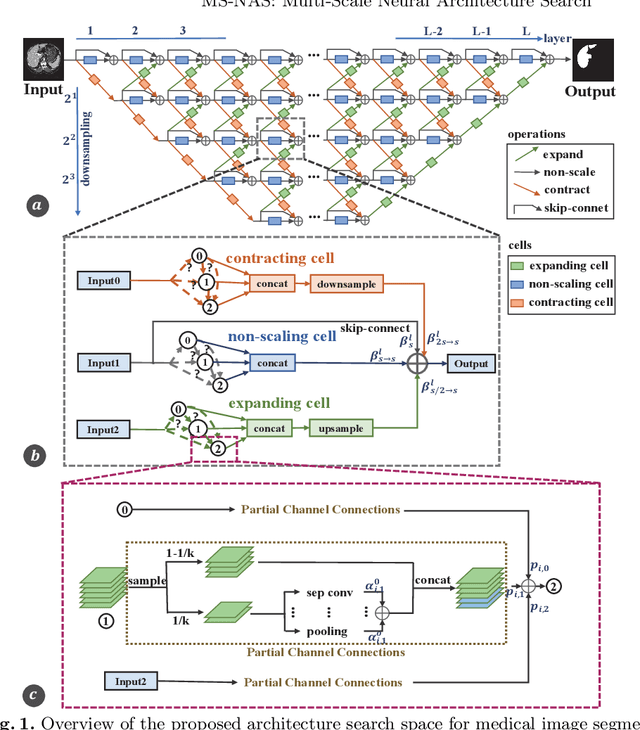

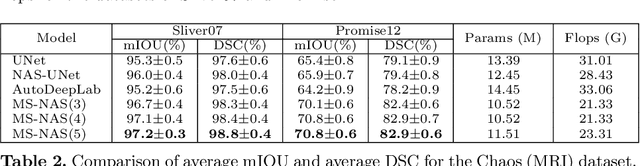
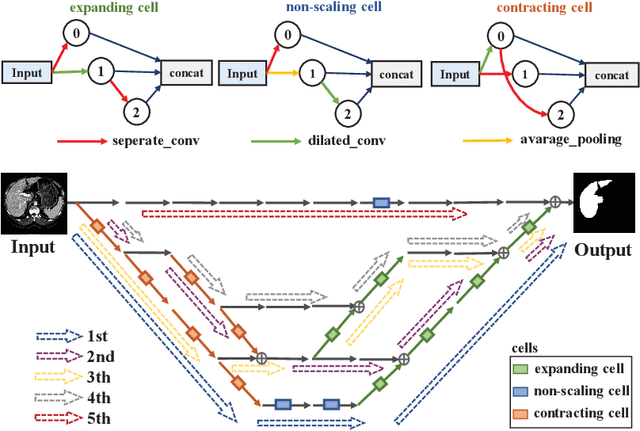
The recent breakthroughs of Neural Architecture Search (NAS) have motivated various applications in medical image segmentation. However, most existing work either simply rely on hyper-parameter tuning or stick to a fixed network backbone, thereby limiting the underlying search space to identify more efficient architecture. This paper presents a Multi-Scale NAS (MS-NAS) framework that is featured with multi-scale search space from network backbone to cell operation, and multi-scale fusion capability to fuse features with different sizes. To mitigate the computational overhead due to the larger search space, a partial channel connection scheme and a two-step decoding method are utilized to reduce computational overhead while maintaining optimization quality. Experimental results show that on various datasets for segmentation, MS-NAS outperforms the state-of-the-art methods and achieves 0.6-5.4% mIOU and 0.4-3.5% DSC improvements, while the computational resource consumption is reduced by 18.0-24.9%.
Confidence-Aware Active Feedback for Efficient Instance Search
Oct 23, 2021
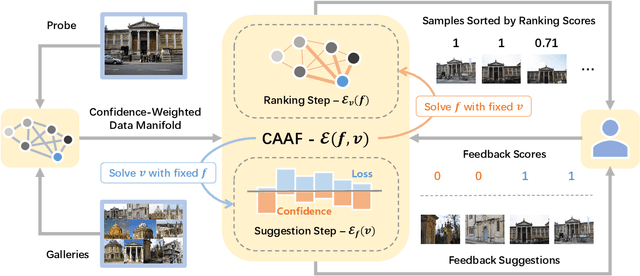
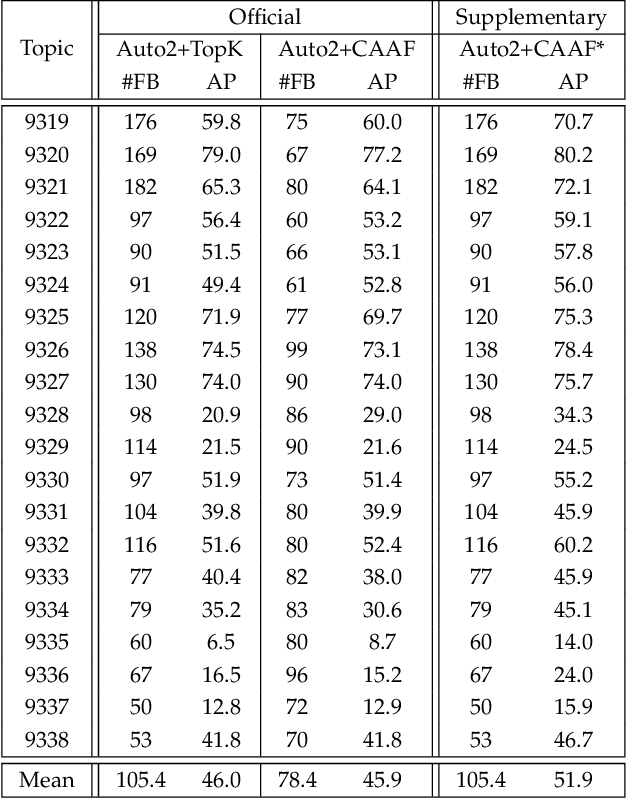
Relevance feedback is widely used in instance search (INS) tasks to further refine imperfect ranking results, but it often comes with low interaction efficiency. Active learning (AL) technique has achieved great success in improving annotation efficiency in classification tasks. However, considering irrelevant samples' diversity and class imbalance in INS tasks, existing AL methods cannot always select the most suitable feedback candidates for INS problems. In addition, they are often too computationally complex to be applied in interactive INS scenario. To address the above problems, we propose a confidence-aware active feedback (CAAF) method that can efficiently select the most valuable feedback candidates to improve the re-ranking performance. Specifically, inspired by the explicit sample difficulty modeling in self-paced learning, we utilize a pairwise manifold ranking loss to evaluate the ranking confidence of each unlabeled sample, and formulate the INS process as a confidence-weighted manifold ranking problem. Furthermore, we introduce an approximate optimization scheme to simplify the solution from QP problems with constraints to closed-form expressions, and selects only the top-K samples in the initial ranking list for INS, so that CAAF is able to handle large-scale INS tasks in a short period of time. Extensive experiments on both image and video INS tasks demonstrate the effectiveness of the proposed CAAF method. In particular, CAAF outperforms the first-place record in the public large-scale video INS evaluation of TRECVID 2021.
Hyperspectral-Multispectral Image Fusion with Weighted LASSO
Mar 15, 2020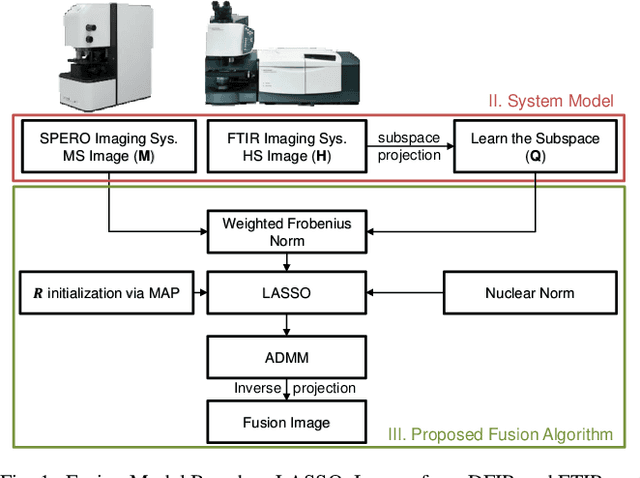

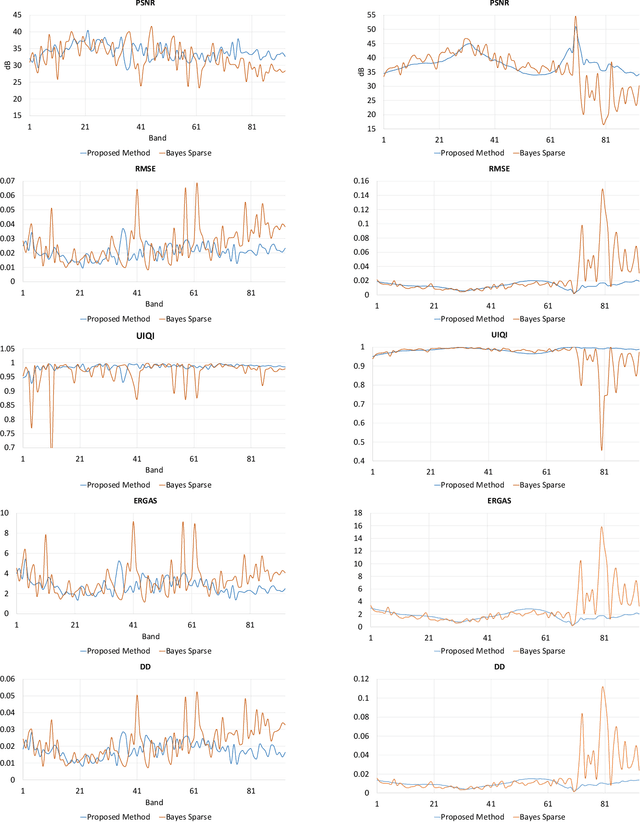
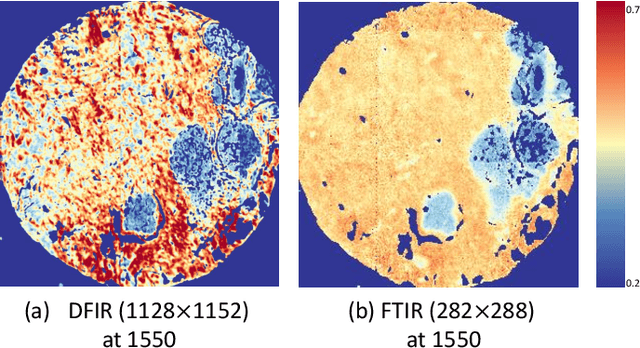
Spectral imaging enables spatially-resolved identification of materials in remote sensing, biomedicine, and astronomy. However, acquisition times require balancing spectral and spatial resolution with signal-to-noise. Hyperspectral imaging provides superior material specificity, while multispectral images are faster to collect at greater fidelity. We propose an approach for fusing hyperspectral and multispectral images to provide high-quality hyperspectral output. The proposed optimization leverages the least absolute shrinkage and selection operator (LASSO) to perform variable selection and regularization. Computational time is reduced by applying the alternating direction method of multipliers (ADMM), as well as initializing the fusion image by estimating it using maximum a posteriori (MAP) based on Hardie's method. We demonstrate that the proposed sparse fusion and reconstruction provides quantitatively superior results when compared to existing methods on publicly available images. Finally, we show how the proposed method can be practically applied in biomedical infrared spectroscopic microscopy.
OMASGAN: Out-of-Distribution Minimum Anomaly Score GAN for Sample Generation on the Boundary
Oct 28, 2021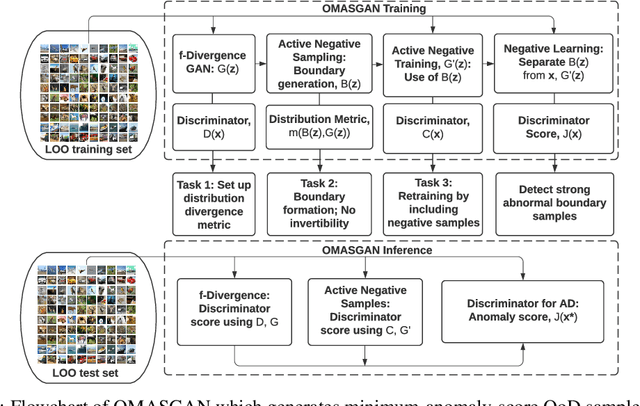
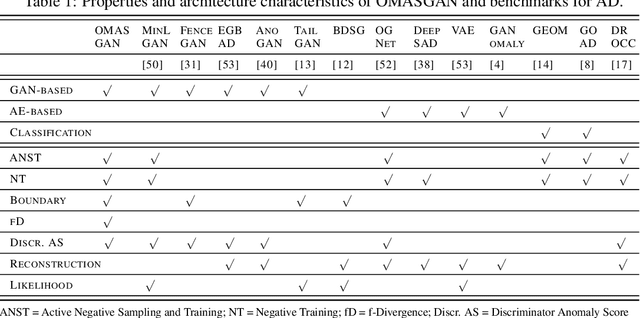
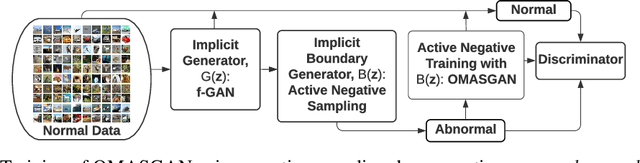
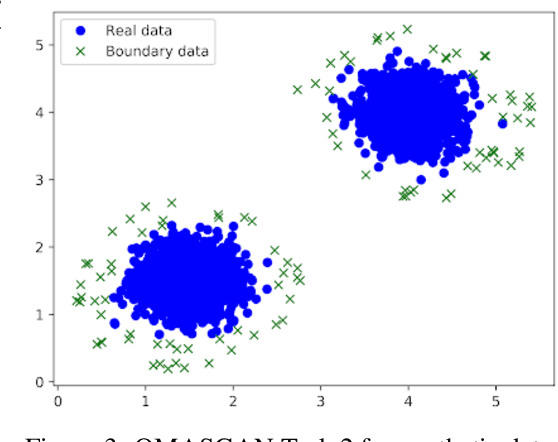
Generative models trained in an unsupervised manner may set high likelihood and low reconstruction loss to Out-of-Distribution (OoD) samples. This increases Type II errors and leads to missed anomalies, overall decreasing Anomaly Detection (AD) performance. In addition, AD models underperform due to the rarity of anomalies. To address these limitations, we propose the OoD Minimum Anomaly Score GAN (OMASGAN). OMASGAN generates, in a negative data augmentation manner, anomalous samples on the estimated distribution boundary. These samples are then used to refine an AD model, leading to more accurate estimation of the underlying data distribution including multimodal supports with disconnected modes. OMASGAN performs retraining by including the abnormal minimum-anomaly-score OoD samples generated on the distribution boundary in a self-supervised learning manner. For inference, for AD, we devise a discriminator which is trained with negative and positive samples either generated (negative or positive) or real (only positive). OMASGAN addresses the rarity of anomalies by generating strong and adversarial OoD samples on the distribution boundary using only normal class data, effectively addressing mode collapse. A key characteristic of our model is that it uses any f-divergence distribution metric in its variational representation, not requiring invertibility. OMASGAN does not use feature engineering and makes no assumptions about the data distribution. The evaluation of OMASGAN on image data using the leave-one-out methodology shows that it achieves an improvement of at least 0.24 and 0.07 points in AUROC on average on the MNIST and CIFAR-10 datasets, respectively, over other benchmark and state-of-the-art models for AD.
Inpainting Transformer for Anomaly Detection
Apr 28, 2021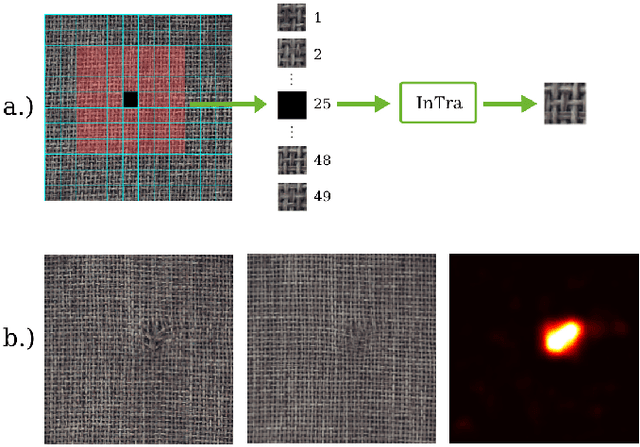
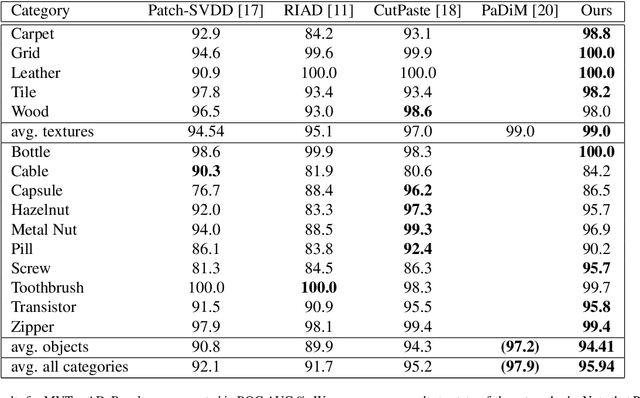
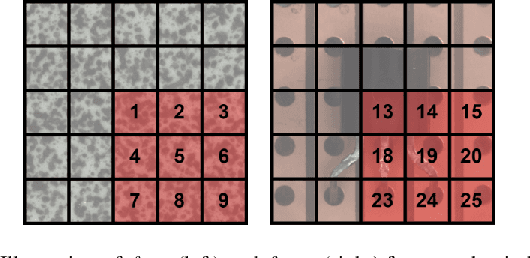
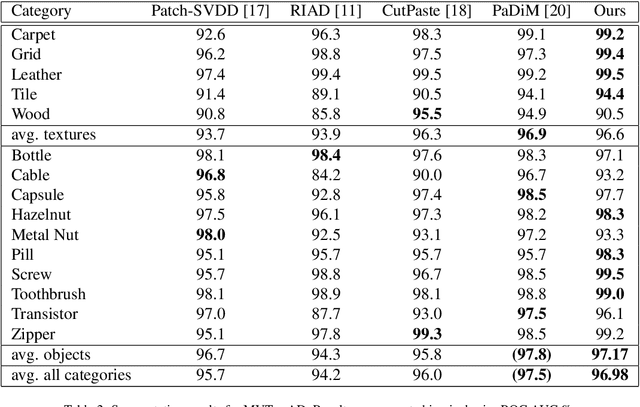
Anomaly detection in computer vision is the task of identifying images which deviate from a set of normal images. A common approach is to train deep convolutional autoencoders to inpaint covered parts of an image and compare the output with the original image. By training on anomaly-free samples only, the model is assumed to not being able to reconstruct anomalous regions properly. For anomaly detection by inpainting we suggest it to be beneficial to incorporate information from potentially distant regions. In particular we pose anomaly detection as a patch-inpainting problem and propose to solve it with a purely self-attention based approach discarding convolutions. The proposed Inpainting Transformer (InTra) is trained to inpaint covered patches in a large sequence of image patches, thereby integrating information across large regions of the input image. When learning from scratch, InTra achieves better than state-of-the-art results on the MVTec AD [1] dataset for detection and localization.
An Ultra-Fast Method for Simulation of Realistic Ultrasound Images
Sep 21, 2021
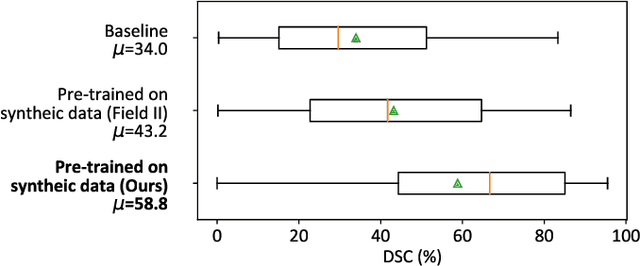
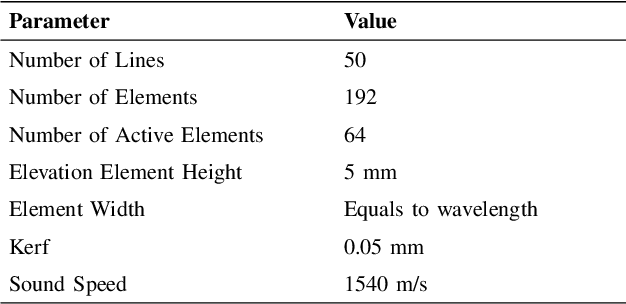
Convolutional neural networks (CNNs) have attracted a rapidly growing interest in a variety of different processing tasks in the medical ultrasound community. However, the performance of CNNs is highly reliant on both the amount and fidelity of the training data. Therefore, scarce data is almost always a concern, particularly in the medical field, where clinical data is not easily accessible. The utilization of synthetic data is a popular approach to address this challenge. However, but simulating a large number of images using packages such as Field II is time-consuming, and the distribution of simulated images is far from that of the real images. Herein, we introduce a novel ultra-fast ultrasound image simulation method based on the Fourier transform and evaluate its performance in a lesion segmentation task. We demonstrate that data augmentation using the images generated by the proposed method substantially outperforms Field II in terms of Dice similarity coefficient, while the simulation is almost 36000 times faster (both on CPU).
Online Refinement of Low-level Feature Based Activation Map for Weakly Supervised Object Localization
Oct 12, 2021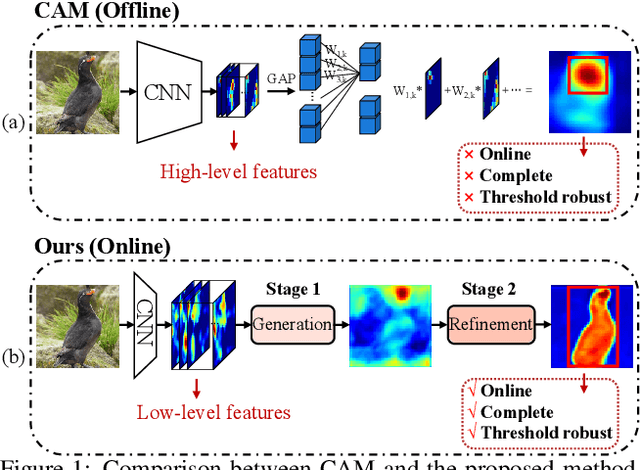
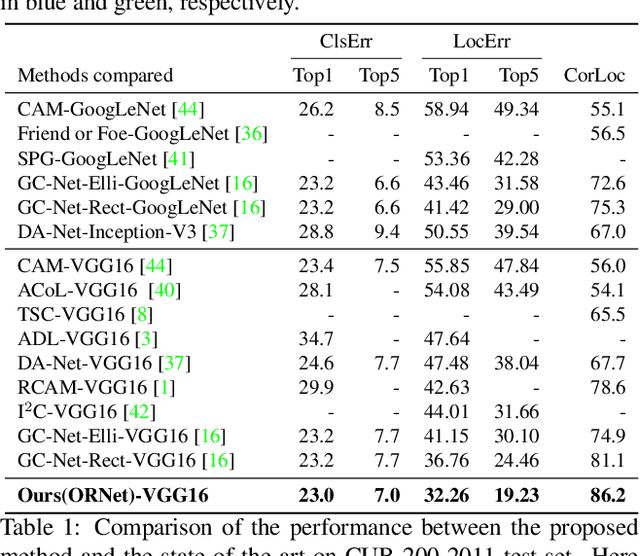

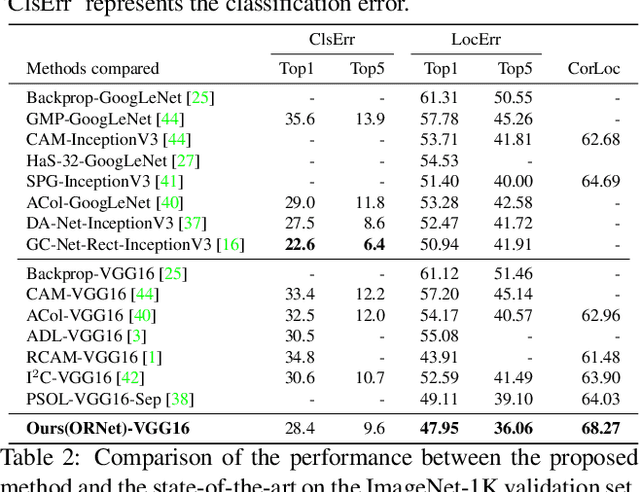
We present a two-stage learning framework for weakly supervised object localization (WSOL). While most previous efforts rely on high-level feature based CAMs (Class Activation Maps), this paper proposes to localize objects using the low-level feature based activation maps. In the first stage, an activation map generator produces activation maps based on the low-level feature maps in the classifier, such that rich contextual object information is included in an online manner. In the second stage, we employ an evaluator to evaluate the activation maps predicted by the activation map generator. Based on this, we further propose a weighted entropy loss, an attentive erasing, and an area loss to drive the activation map generator to substantially reduce the uncertainty of activations between object and background, and explore less discriminative regions. Based on the low-level object information preserved in the first stage, the second stage model gradually generates a well-separated, complete, and compact activation map of object in the image, which can be easily thresholded for accurate localization. Extensive experiments on CUB-200-2011 and ImageNet-1K datasets show that our framework surpasses previous methods by a large margin, which sets a new state-of-the-art for WSOL.