 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Forward-Looking Sonar Patch Matching: Modern CNNs, Ensembling, and Uncertainty
Aug 02, 2021
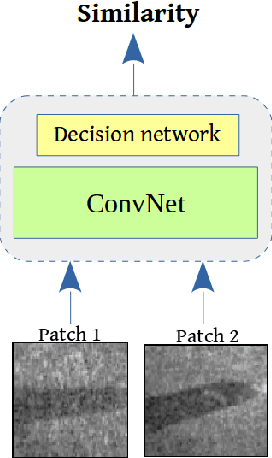
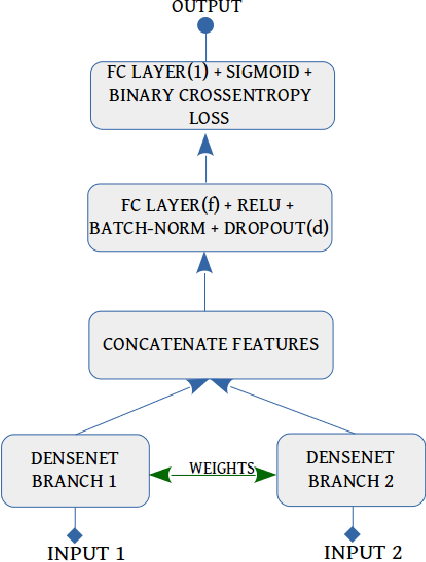
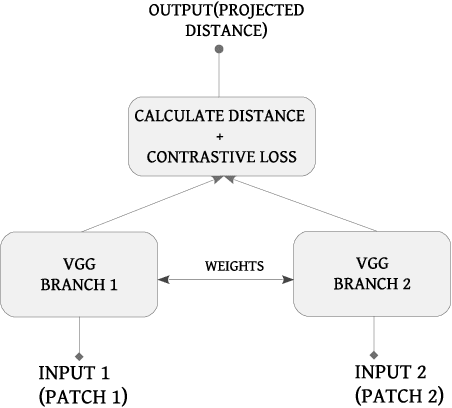
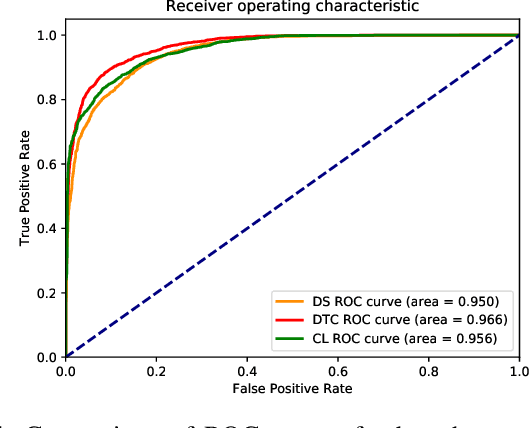
Application of underwater robots are on the rise, most of them are dependent on sonar for underwater vision, but the lack of strong perception capabilities limits them in this task. An important issue in sonar perception is matching image patches, which can enable other techniques like localization, change detection, and mapping. There is a rich literature for this problem in color images, but for acoustic images, it is lacking, due to the physics that produce these images. In this paper we improve on our previous results for this problem (Valdenegro-Toro et al, 2017), instead of modeling features manually, a Convolutional Neural Network (CNN) learns a similarity function and predicts if two input sonar images are similar or not. With the objective of improving the sonar image matching problem further, three state of the art CNN architectures are evaluated on the Marine Debris dataset, namely DenseNet, and VGG, with a siamese or two-channel architecture, and contrastive loss. To ensure a fair evaluation of each network, thorough hyper-parameter optimization is executed. We find that the best performing models are DenseNet Two-Channel network with 0.955 AUC, VGG-Siamese with contrastive loss at 0.949 AUC and DenseNet Siamese with 0.921 AUC. By ensembling the top performing DenseNet two-channel and DenseNet-Siamese models overall highest prediction accuracy obtained is 0.978 AUC, showing a large improvement over the 0.91 AUC in the state of the art.
Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera
Aug 20, 2021This paper presents an effective method for generating a spatiotemporal (time-varying) texture map for a dynamic object using a single RGB-D camera. The input of our framework is a 3D template model and an RGB-D image sequence. Since there are invisible areas of the object at a frame in a single-camera setup, textures of such areas need to be borrowed from other frames. We formulate the problem as an MRF optimization and define cost functions to reconstruct a plausible spatiotemporal texture for a dynamic object. Experimental results demonstrate that our spatiotemporal textures can reproduce the active appearances of captured objects better than approaches using a single texture map.
Character Spotting Using Machine Learning Techniques
Jul 28, 2021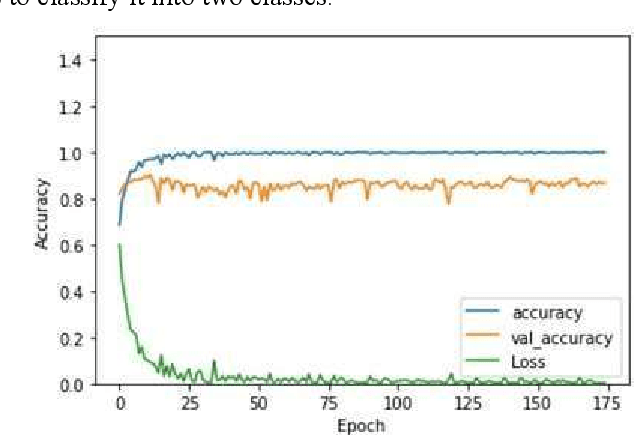
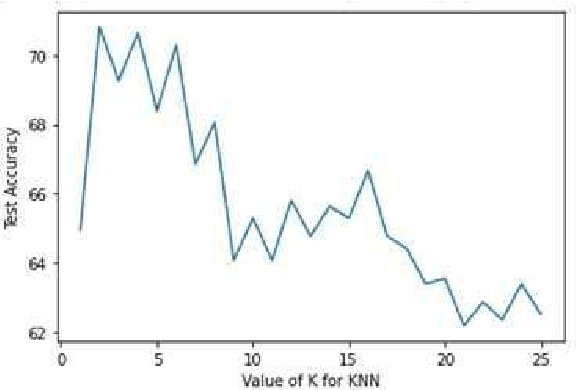
This work presents a comparison of machine learning algorithms that are implemented to segment the characters of text presented as an image. The algorithms are designed to work on degraded documents with text that is not aligned in an organized fashion. The paper investigates the use of Support Vector Machines, K-Nearest Neighbor algorithm and an Encoder Network to perform the operation of character spotting. Character Spotting involves extracting potential characters from a stream of text by selecting regions bound by white space.
Teat Pose Estimation via RGBD Segmentation for Automated Milking
May 20, 2021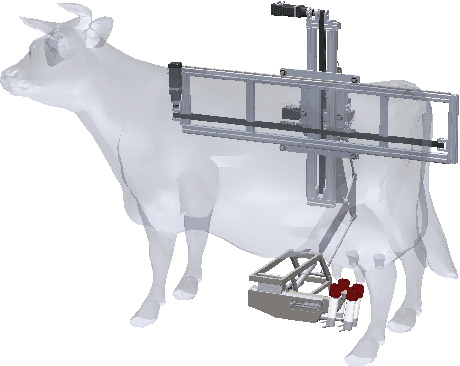
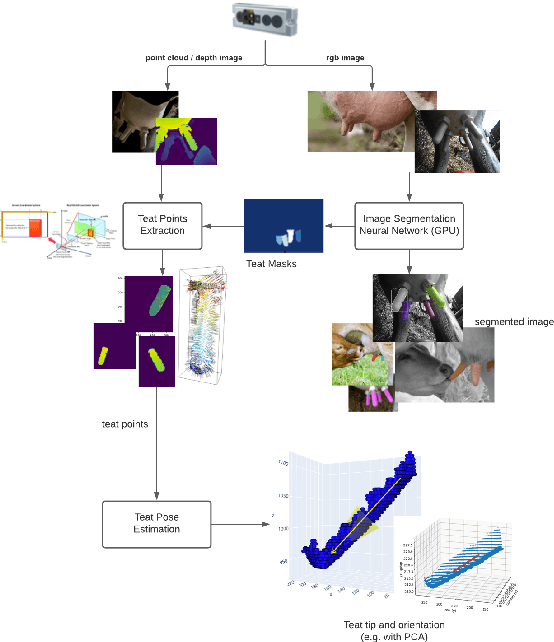
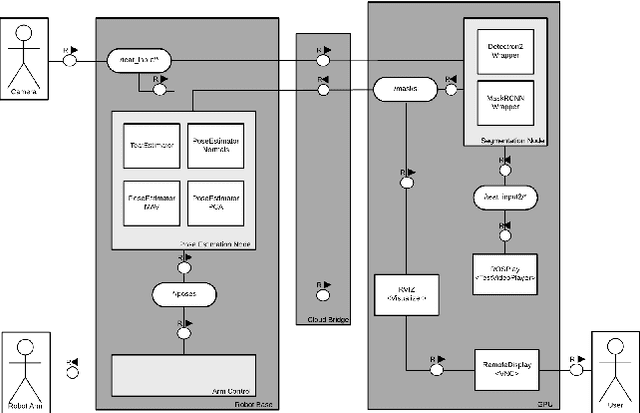
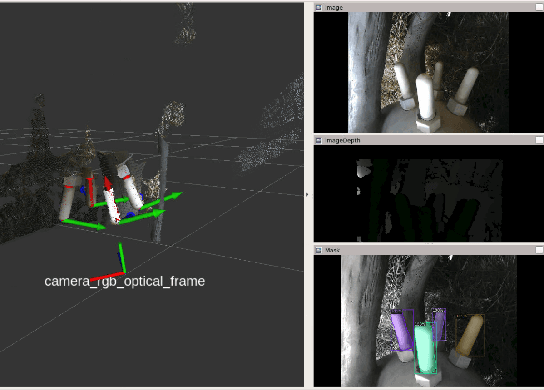
We present initial results in the development of a novel robot using RGBD cameras, image segmentation, and a simple teat pose estimation algorithm for automated milking. We relate on the analysis of the accuracy of different commercial RGBD cameras in realistic conditions. Although preliminary, our initial implementation shows that 2D image segmentation combined with point cloud processing can achieve repeatable millimeter-scale precision in estimating (synthetic) teat tip positions and cup attachment approach. The solution is also applicable in a cloud robotics setup, with GPU-based segmentation executed on an edge device or cloud.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
Jun 19, 2021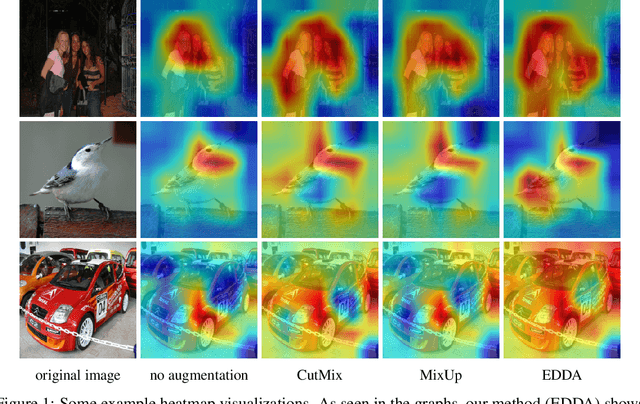
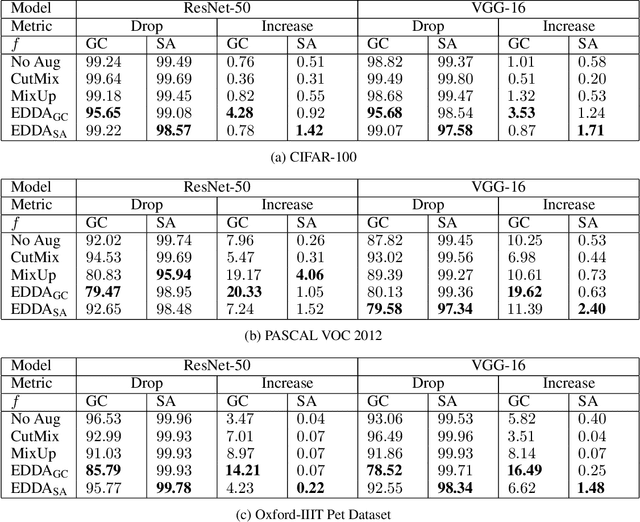
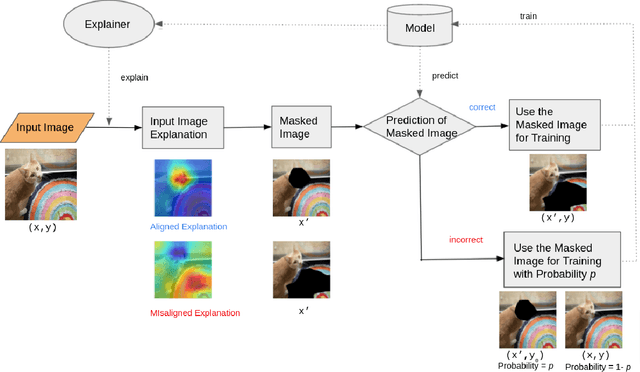
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Distinguishing rule- and exemplar-based generalization in learning systems
Oct 08, 2021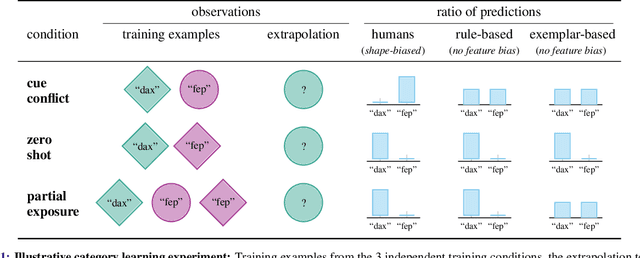
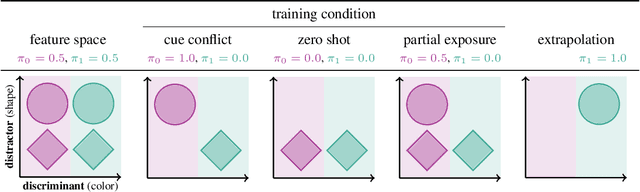
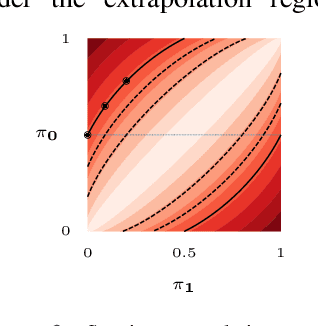
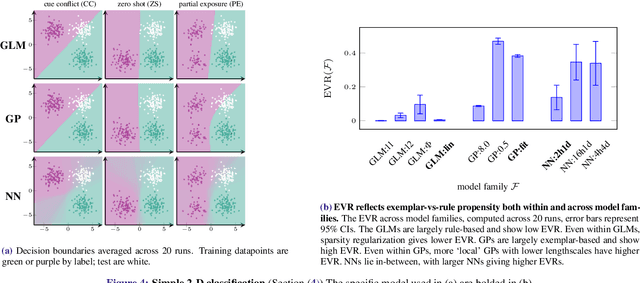
Despite the increasing scale of datasets in machine learning, generalization to unseen regions of the data distribution remains crucial. Such extrapolation is by definition underdetermined and is dictated by a learner's inductive biases. Machine learning systems often do not share the same inductive biases as humans and, as a result, extrapolate in ways that are inconsistent with our expectations. We investigate two distinct such inductive biases: feature-level bias (differences in which features are more readily learned) and exemplar-vs-rule bias (differences in how these learned features are used for generalization). Exemplar- vs. rule-based generalization has been studied extensively in cognitive psychology, and, in this work, we present a protocol inspired by these experimental approaches for directly probing this trade-off in learning systems. The measures we propose characterize changes in extrapolation behavior when feature coverage is manipulated in a combinatorial setting. We present empirical results across a range of models and across both expository and real-world image and language domains. We demonstrate that measuring the exemplar-rule trade-off while controlling for feature-level bias provides a more complete picture of extrapolation behavior than existing formalisms. We find that most standard neural network models have a propensity towards exemplar-based extrapolation and discuss the implications of these findings for research on data augmentation, fairness, and systematic generalization.
On the use of automatically generated synthetic image datasets for benchmarking face recognition
Jun 08, 2021
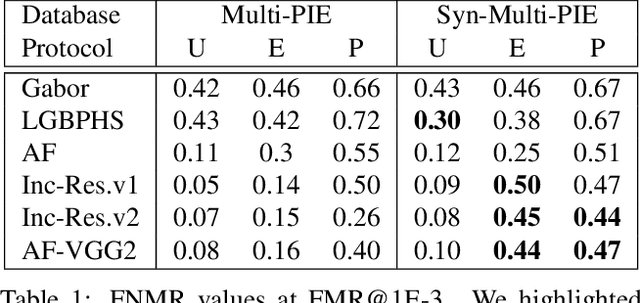

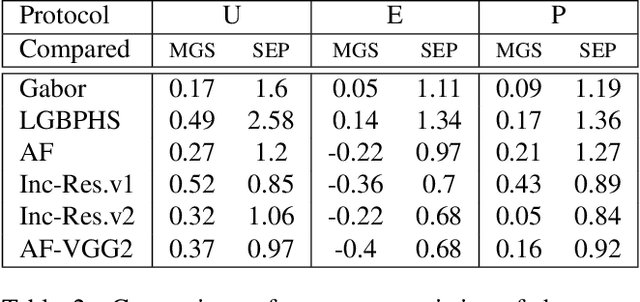
The availability of large-scale face datasets has been key in the progress of face recognition. However, due to licensing issues or copyright infringement, some datasets are not available anymore (e.g. MS-Celeb-1M). Recent advances in Generative Adversarial Networks (GANs), to synthesize realistic face images, provide a pathway to replace real datasets by synthetic datasets, both to train and benchmark face recognition (FR) systems. The work presented in this paper provides a study on benchmarking FR systems using a synthetic dataset. First, we introduce the proposed methodology to generate a synthetic dataset, without the need for human intervention, by exploiting the latent structure of a StyleGAN2 model with multiple controlled factors of variation. Then, we confirm that (i) the generated synthetic identities are not data subjects from the GAN's training dataset, which is verified on a synthetic dataset with 10K+ identities; (ii) benchmarking results on the synthetic dataset are a good substitution, often providing error rates and system ranking similar to the benchmarking on the real dataset.
Improving the Harmony of the Composite Image by Spatial-Separated Attention Module
Jul 15, 2019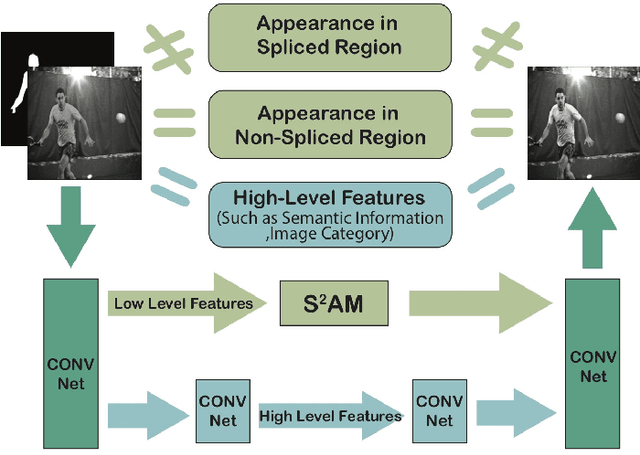
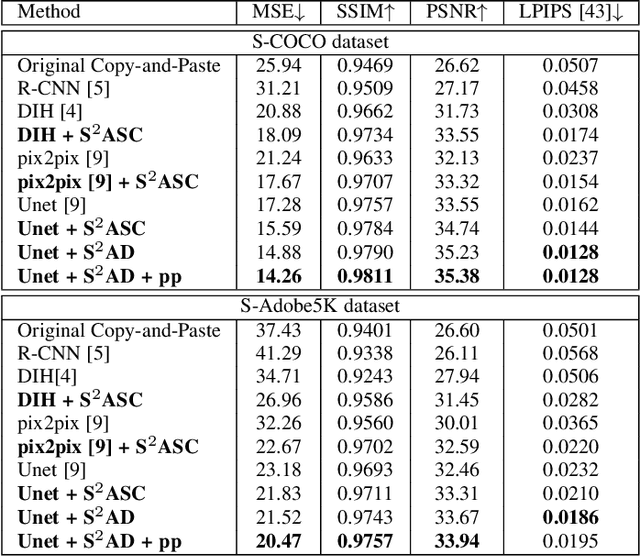
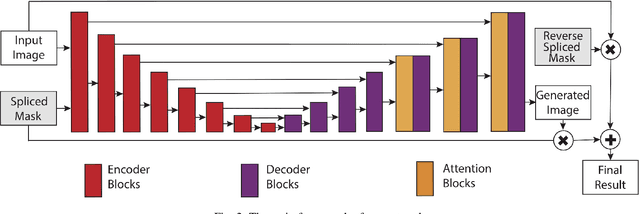
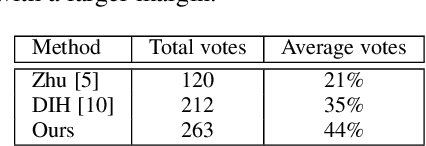
Image composition is one of the most important applications in image processing. However, the inharmonious appearance between the spliced region and background degrade the quality of the image. Thus, we address the problem of Image Harmonization: Given a spliced image and the mask of the spliced region, we try to harmonize the "style'' of the pasted region with the background (non-spliced region). Previous approaches have been focusing on learning directly by the neural network. In this work, we start from an empirical observation: the differences can only be found in the spliced region between the spliced image and the harmonized result while they share the same semantic information and the appearance in the non-spliced region. Thus, in order to learn the feature map in the masked region and the others individually, we propose a novel attention module named Spatial-Separated Attention Module (S2AM). Furthermore, we design a novel image harmonization framework by inserting the S2AM in the coarser low-level features of the Unet structure in two different ways. Besides image harmonization, we make a big step for harmonizing the composite image without the specific mask under previous observation. The experiments show that the proposed S2AM performs better than other state-of-the-art attention modules in our task. Moreover, we demonstrate the advantages of our model against other state-of-the-art image harmonization methods via criteria from multiple points of view. Code is available at https://github.com/vinthony/s2am
QISTA-Net: DNN Architecture to Solve $\ell_q$-norm Minimization Problem and Image Compressed Sensing
Oct 22, 2020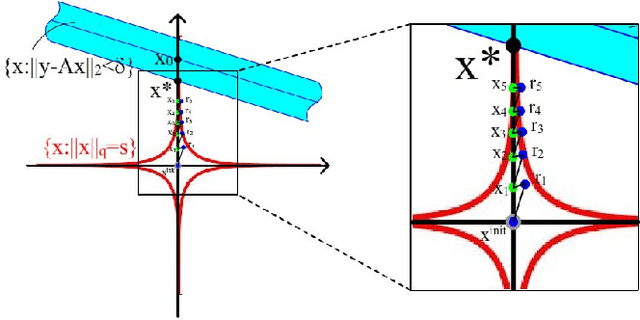

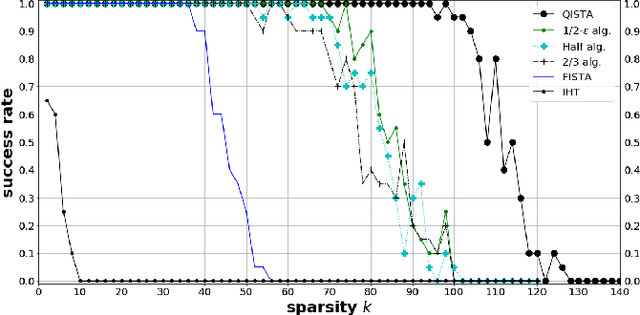
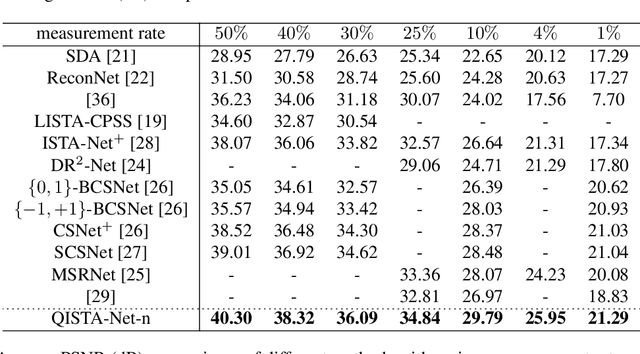
In this paper, we reformulate the non-convex $\ell_q$-norm minimization problem with $q\in(0,1)$ into a 2-step problem, which consists of one convex and one non-convex subproblems, and propose a novel iterative algorithm called QISTA ($\ell_q$-ISTA) to solve the $\left(\ell_q\right)$-problem. By taking advantage of deep learning in accelerating optimization algorithms, together with the speedup strategy that using the momentum from all previous layers in the network, we propose a learning-based method, called QISTA-Net-s, to solve the sparse signal reconstruction problem. Extensive experimental comparisons demonstrate that the QISTA-Net-s yield better reconstruction qualities than state-of-the-art $\ell_1$-norm optimization (plus learning) algorithms even if the original sparse signal is noisy. On the other hand, based on the network architecture associated with QISTA, with considering the use of convolution layers, we proposed the QISTA-Net-n for solving the image CS problem, and the performance of the reconstruction still outperforms most of the state-of-the-art natural images reconstruction methods. QISTA-Net-n is designed in unfolding QISTA and adding the convolutional operator as the dictionary. This makes QISTA-Net-s interpretable. We provide complete experimental results that QISTA-Net-s and QISTA-Net-n contribute the better reconstruction performance than the competing.
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021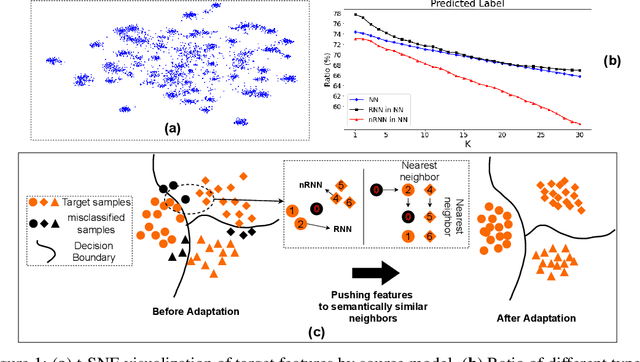
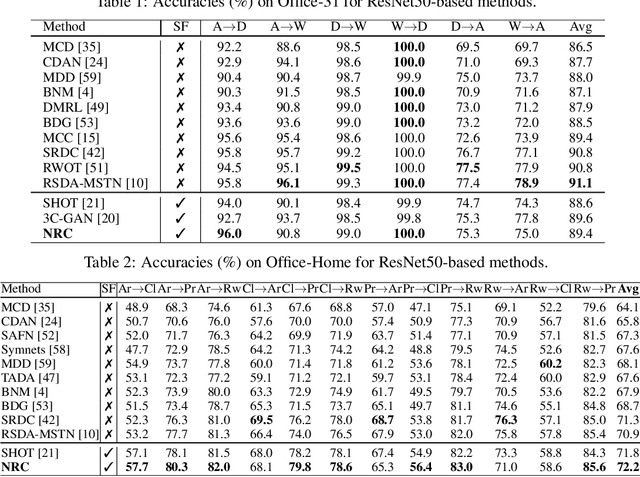
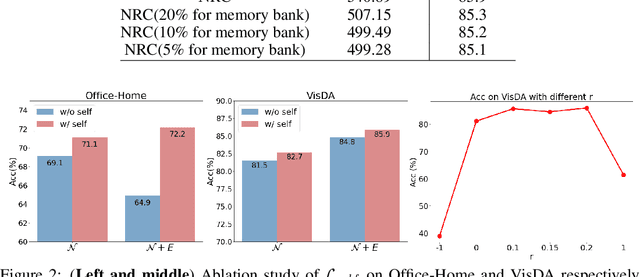
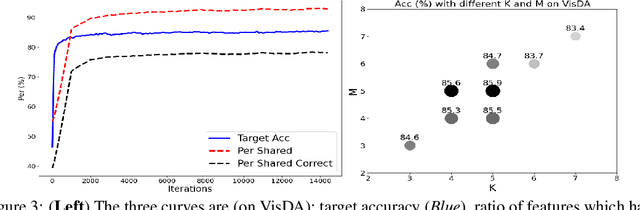
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.