 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation
Sep 20, 2021

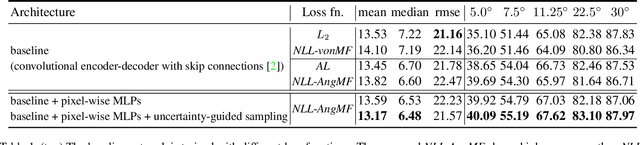

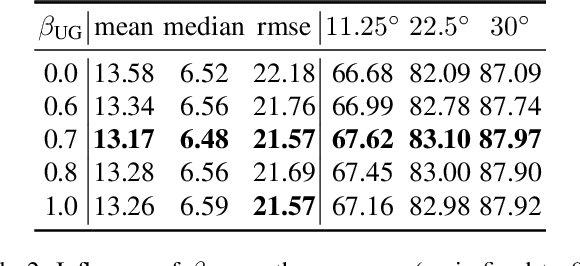
Surface normal estimation from a single image is an important task in 3D scene understanding. In this paper, we address two limitations shared by the existing methods: the inability to estimate the aleatoric uncertainty and lack of detail in the prediction. The proposed network estimates the per-pixel surface normal probability distribution. We introduce a new parameterization for the distribution, such that its negative log-likelihood is the angular loss with learned attenuation. The expected value of the angular error is then used as a measure of the aleatoric uncertainty. We also present a novel decoder framework where pixel-wise multi-layer perceptrons are trained on a subset of pixels sampled based on the estimated uncertainty. The proposed uncertainty-guided sampling prevents the bias in training towards large planar surfaces and improves the quality of prediction, especially near object boundaries and on small structures. Experimental results show that the proposed method outperforms the state-of-the-art in ScanNet and NYUv2, and that the estimated uncertainty correlates well with the prediction error. Code is available at https://github.com/baegwangbin/surface_normal_uncertainty.
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
Sep 28, 2021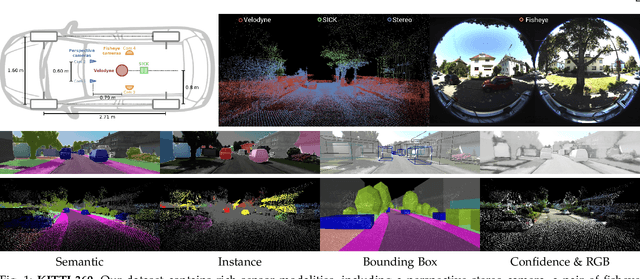
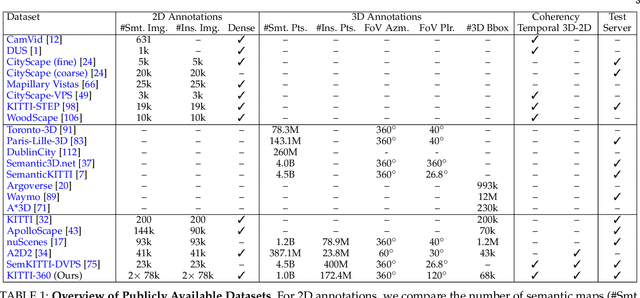
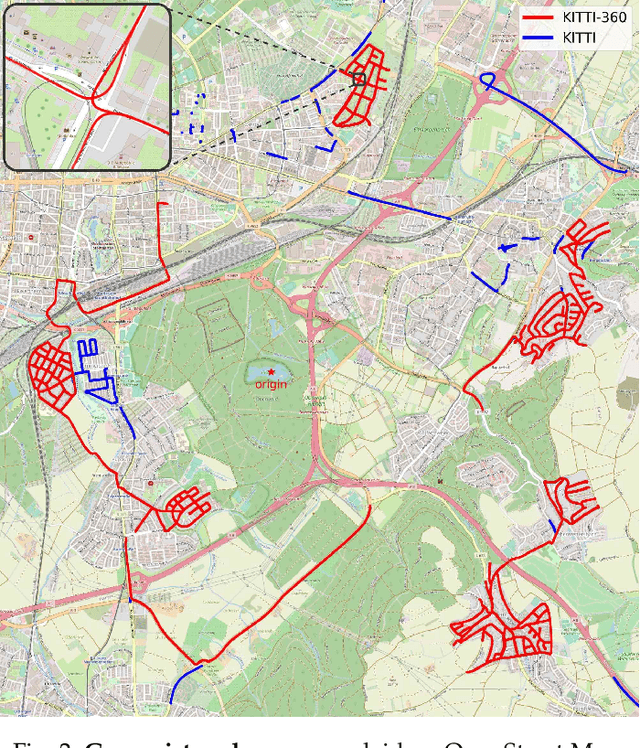
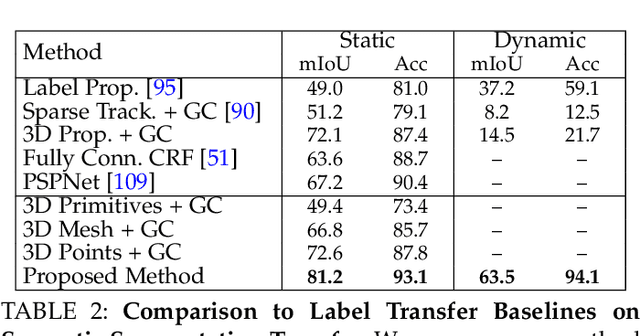
For the last few decades, several major subfields of artificial intelligence including computer vision, graphics, and robotics have progressed largely independently from each other. Recently, however, the community has realized that progress towards robust intelligent systems such as self-driving cars requires a concerted effort across the different fields. This motivated us to develop KITTI-360, successor of the popular KITTI dataset. KITTI-360 is a suburban driving dataset which comprises richer input modalities, comprehensive semantic instance annotations and accurate localization to facilitate research at the intersection of vision, graphics and robotics. For efficient annotation, we created a tool to label 3D scenes with bounding primitives and developed a model that transfers this information into the 2D image domain, resulting in over 150k semantic and instance annotated images and 1B annotated 3D points. Moreover, we established benchmarks and baselines for several tasks relevant to mobile perception, encompassing problems from computer vision, graphics, and robotics on the same dataset. KITTI-360 will enable progress at the intersection of these research areas and thus contributing towards solving one of our grand challenges: the development of fully autonomous self-driving systems.
Testing Deep Learning Models for Image Analysis Using Object-Relevant Metamorphic Relations
Sep 06, 2019
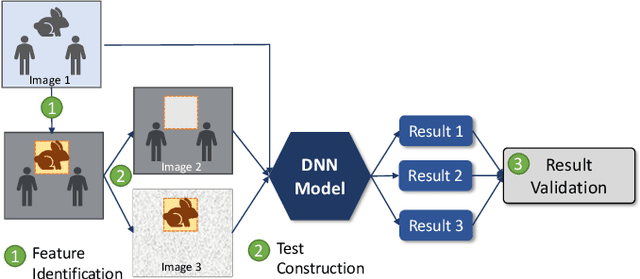
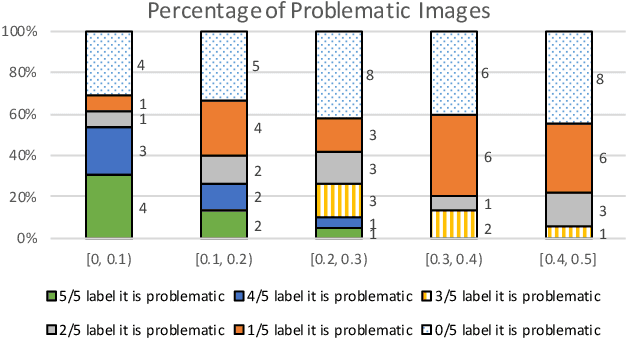
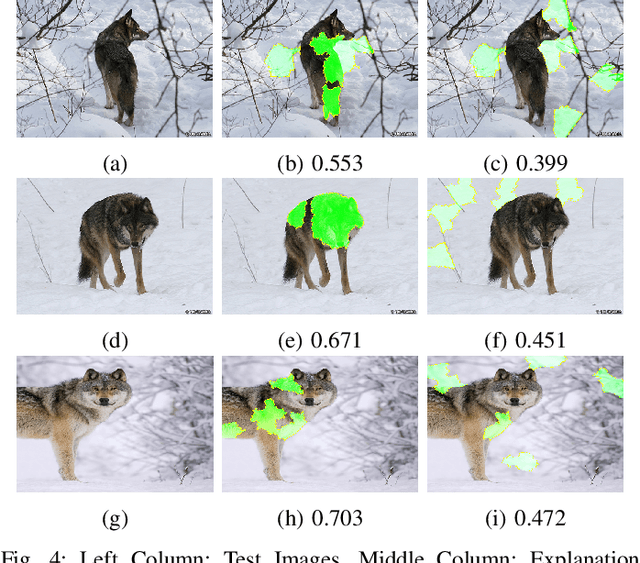
Deep learning models are widely used for image analysis. While they offer high performance in terms of accuracy, people are concerned about if these models inappropriately make inferences using irrelevant features that are not encoded from the target object in a given image. To address the concern, we propose a metamorphic testing approach that assesses if a given inference is made based on irrelevant features. Specifically, we propose two novel metamorphic relations to detect such inappropriate inferences. We applied our approach to 10 image classification models and 10 object detection models, with three large datasets, i.e., ImageNet, COCO, and Pascal VOC. Over 5.3% of the top-5 correct predictions made by the image classification models are subject to inappropriate inferences using irrelevant features. The corresponding rate for the object detection models is over 8.5%. Based on the findings, we further designed a new image generation strategy that can effectively attack existing models. Comparing with a baseline approach, our strategy can double the success rate of attacks.
Patch AutoAugment
Mar 20, 2021
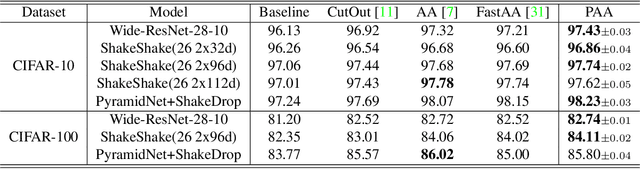
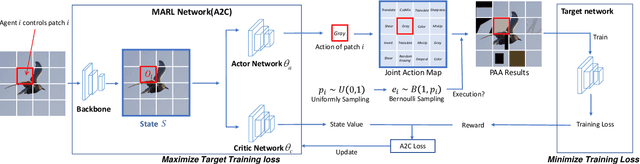
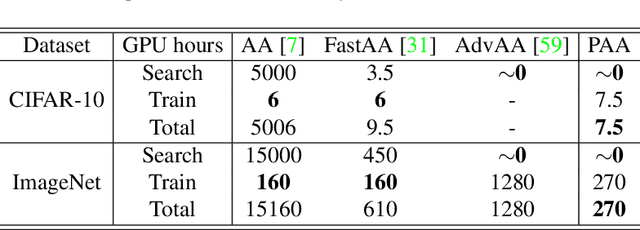
Data augmentation (DA) plays a critical role in training deep neural networks for improving the generalization of models. Recent work has shown that automatic DA policy, such as AutoAugment (AA), significantly improves model performance. However, most automatic DA methods search for DA policies at the image-level without considering that the optimal policies for different regions in an image may be diverse. In this paper, we propose a patch-level automatic DA algorithm called Patch AutoAugment (PAA). PAA divides an image into a grid of patches and searches for the optimal DA policy of each patch. Specifically, PAA allows each patch DA operation to be controlled by an agent and models it as a Multi-Agent Reinforcement Learning (MARL) problem. At each step, PAA samples the most effective operation for each patch based on its content and the semantics of the whole image. The agents cooperate as a team and share a unified team reward for achieving the joint optimal DA policy of the whole image. The experiment shows that PAA consistently improves the target network performance on many benchmark datasets of image classification and fine-grained image recognition. PAA also achieves remarkable computational efficiency, i.e 2.3x faster than FastAA and 56.1x faster than AA on ImageNet.
A Comparison of CNN and Classic Features for Image Retrieval
Aug 25, 2019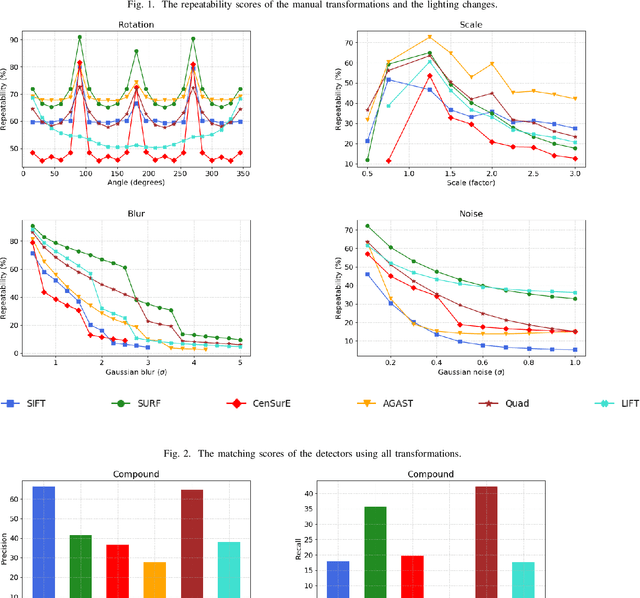
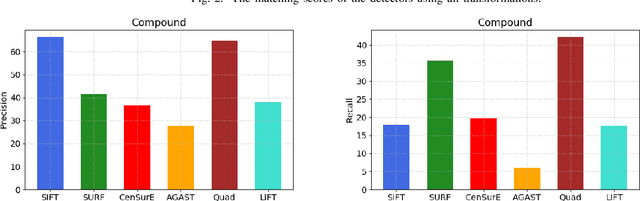
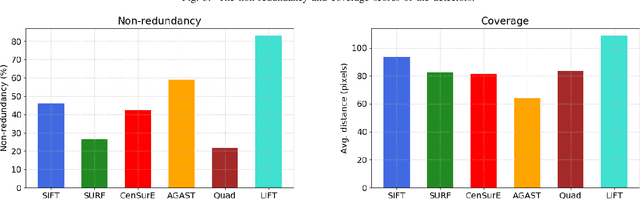

Feature detectors and descriptors have been successfully used for various computer vision tasks, such as video object tracking and content-based image retrieval. Many methods use image gradients in different stages of the detection-description pipeline to describe local image structures. Recently, some, or all, of these stages have been replaced by convolutional neural networks (CNNs), in order to increase their performance. A detector is defined as a selection problem, which makes it more challenging to implement as a CNN. They are therefore generally defined as regressors, converting input images to score maps and keypoints can be selected with non-maximum suppression. This paper discusses and compares several recent methods that use CNNs for keypoint detection. Experiments are performed both on the CNN based approaches, as well as a selection of conventional methods. In addition to qualitative measures defined on keypoints and descriptors, the bag-of-words (BoW) model is used to implement an image retrieval application, in order to determine how the methods perform in practice. The results show that each type of features are best in different contexts.
Multi-scale deep neural networks for real image super-resolution
Apr 24, 2019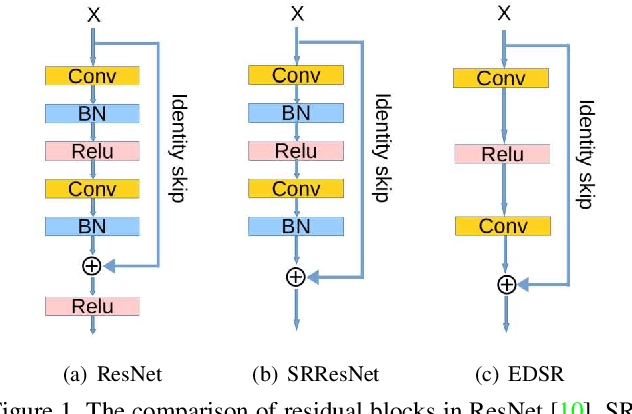

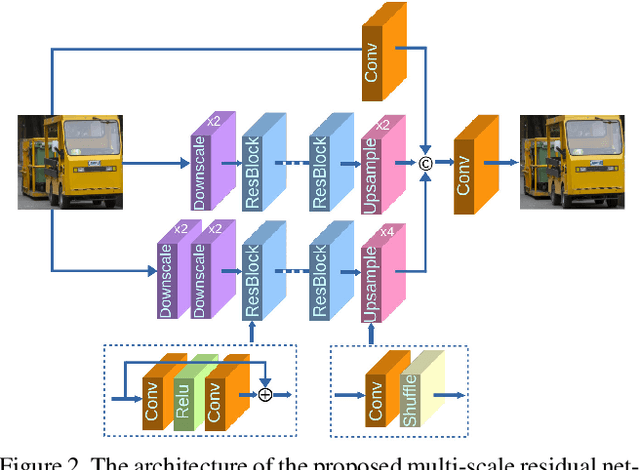

Single image super-resolution (SR) is extremely difficult if the upscaling factors of image pairs are unknown and different from each other, which is common in real image SR. To tackle the difficulty, we develop two multi-scale deep neural networks (MsDNN) in this work. Firstly, due to the high computation complexity in high-resolution spaces, we process an input image mainly in two different downscaling spaces, which could greatly lower the usage of GPU memory. Then, to reconstruct the details of an image, we design a multi-scale residual network (MsRN) in the downscaling spaces based on the residual blocks. Besides, we propose a multi-scale dense network based on the dense blocks to compare with MsRN. Finally, our empirical experiments show the robustness of MsDNN for image SR when the upscaling factor is unknown. According to the preliminary results of NTIRE 2019 image SR challenge, our team (ZXHresearch@fudan) ranks 21-st among all participants. The implementation of MsDNN is released https://github.com/shangqigao/gsq-image-SR
A Deep Image Compression Framework for Face Recognition
Jul 03, 2019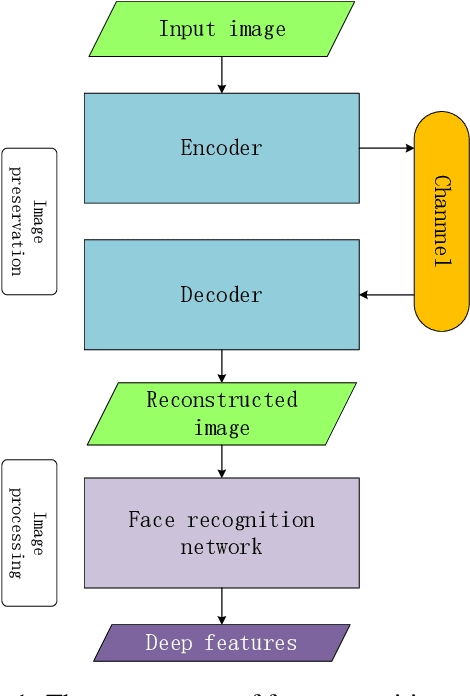
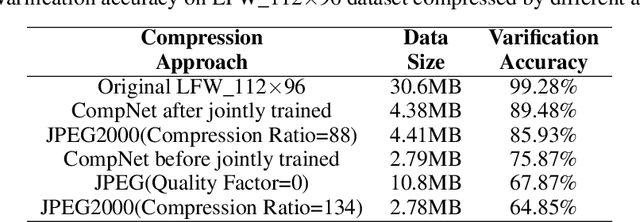


Face recognition technology has advanced rapidly and has been widely used in various applications. Due to the extremely huge amount of data of face images and the large computing resources required correspondingly in large-scale face recognition tasks, there is a requirement for a face image compression approach that is highly suitable for face recognition tasks. In this paper, we propose a deep convolutional autoencoder compression network for face recognition tasks. In the compression process, deep features are extracted from the original image by the convolutional neural networks to produce a compact representation of the original image, which is then encoded and saved by existing codec such as PNG. This compact representation is utilized by the reconstruction network to generate a reconstructed image of the original one. In order to improve the face recognition accuracy when the compression framework is used in a face recognition system, we combine this compression framework with a existing face recognition network for joint optimization. We test the proposed scheme and find that after joint training, the Labeled Faces in the Wild (LFW) dataset compressed by our compression framework has higher face verification accuracy than that compressed by JPEG2000, and is much higher than that compressed by JPEG.
CFSNet: Toward a Controllable Feature Space for Image Restoration
Apr 01, 2019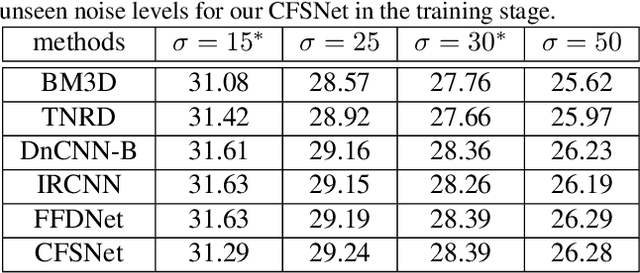
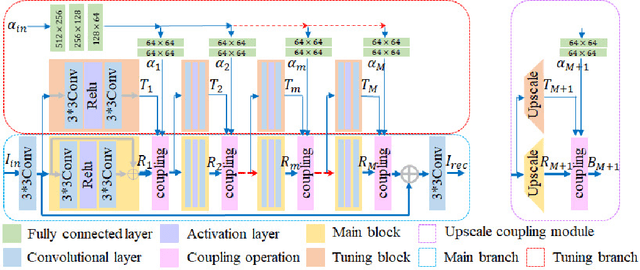
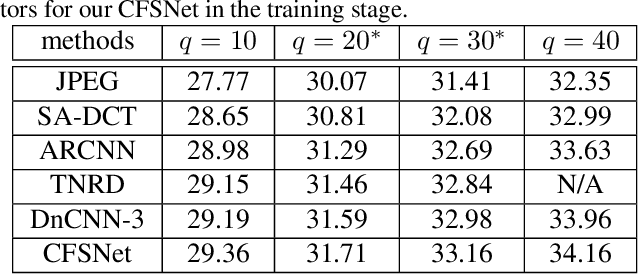
Deep learning methods have witnessed the great progress in image restoration with specific metrics (e.g., PSNR, SSIM). However, the perceptual quality of the restored image is relatively subjective, and it is necessary for users to control the reconstruction result according to personal preferences or image characteristics, which cannot be done using existing deterministic networks. This motivates us to exquisitely design a unified interactive framework for general image restoration tasks. Under this framework, users can control continuous transition of different objectives, e.g., the perception-distortion trade-off of image super-resolution, the trade-off between noise reduction and detail preservation. We achieve this goal by controlling latent features of the designed network. To be specific, our proposed framework, named Controllable Feature Space Network (CFSNet), is entangled by two branches based on different objectives. Our model can adaptively learn the coupling coefficients of different layers and channels, which provides finer control of the restored image quality. Experiments on several typical image restoration tasks fully validate the effective benefits of the proposed method.
Oracle inequalities for image denoising with total variation regularization
Nov 17, 2019We derive oracle results for discrete image denoising with a total variation penalty. We consider the least squares estimator with a penalty on the $\ell^1$-norm of the total discrete derivative of the image. This estimator falls into the class of analysis estimators. A bound on the effective sparsity by means of an interpolating matrix allows us to obtain oracle inequalities with fast rates. The bound is an extension of the bound by Ortelli and van de Geer [2019c] to the two-dimensional case. We also present an oracle inequality with slow rates, which matches, up to a log-term, the rate obtained for the same estimator by Mammen and van de Geer [1997]. The key ingredient for our results are the projection arguments to bound the empirical process due to Dalalyan et al. [2017].
PAT: Pseudo-Adversarial Training For Detecting Adversarial Videos
Sep 13, 2021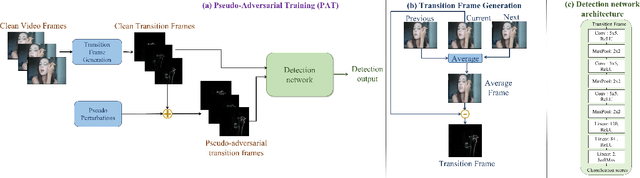
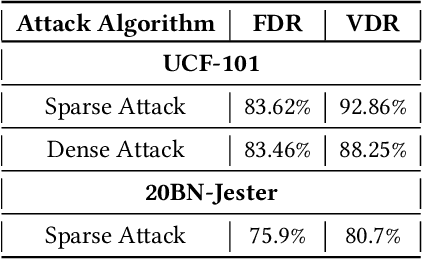

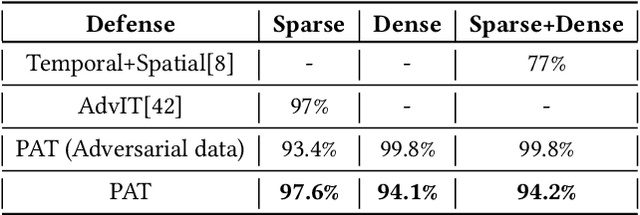
Extensive research has demonstrated that deep neural networks (DNNs) are prone to adversarial attacks. Although various defense mechanisms have been proposed for image classification networks, fewer approaches exist for video-based models that are used in security-sensitive applications like surveillance. In this paper, we propose a novel yet simple algorithm called Pseudo-Adversarial Training (PAT), to detect the adversarial frames in a video without requiring knowledge of the attack. Our approach generates `transition frames' that capture critical deviation from the original frames and eliminate the components insignificant to the detection task. To avoid the necessity of knowing the attack model, we produce `pseudo perturbations' to train our detection network. Adversarial detection is then achieved through the use of the detected frames. Experimental results on UCF-101 and 20BN-Jester datasets show that PAT can detect the adversarial video frames and videos with a high detection rate. We also unveil the potential reasons for the effectiveness of the transition frames and pseudo perturbations through extensive experiments.