 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variational Topic Inference for Chest X-Ray Report Generation
Jul 15, 2021
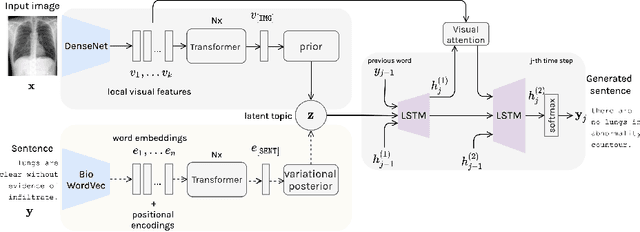
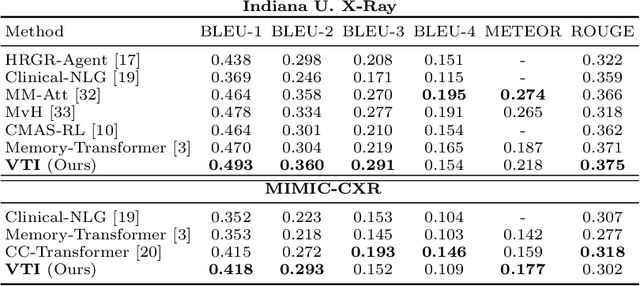
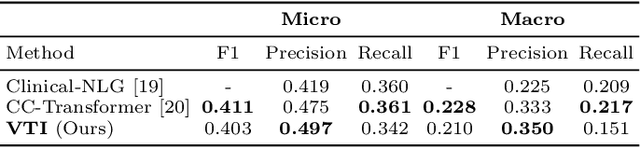
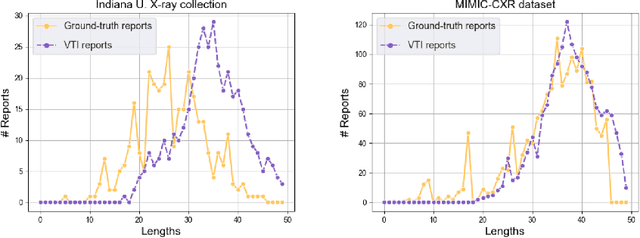
Automating report generation for medical imaging promises to reduce workload and assist diagnosis in clinical practice. Recent work has shown that deep learning models can successfully caption natural images. However, learning from medical data is challenging due to the diversity and uncertainty inherent in the reports written by different radiologists with discrepant expertise and experience. To tackle these challenges, we propose variational topic inference for automatic report generation. Specifically, we introduce a set of topics as latent variables to guide sentence generation by aligning image and language modalities in a latent space. The topics are inferred in a conditional variational inference framework, with each topic governing the generation of a sentence in the report. Further, we adopt a visual attention module that enables the model to attend to different locations in the image and generate more informative descriptions. We conduct extensive experiments on two benchmarks, namely Indiana U. Chest X-rays and MIMIC-CXR. The results demonstrate that our proposed variational topic inference method can generate novel reports rather than mere copies of reports used in training, while still achieving comparable performance to state-of-the-art methods in terms of standard language generation criteria.
Anchor-free Oriented Proposal Generator for Object Detection
Oct 05, 2021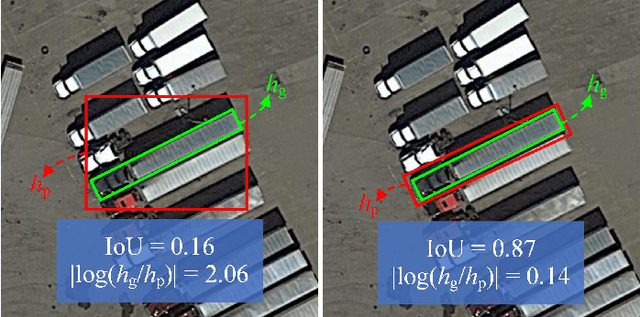

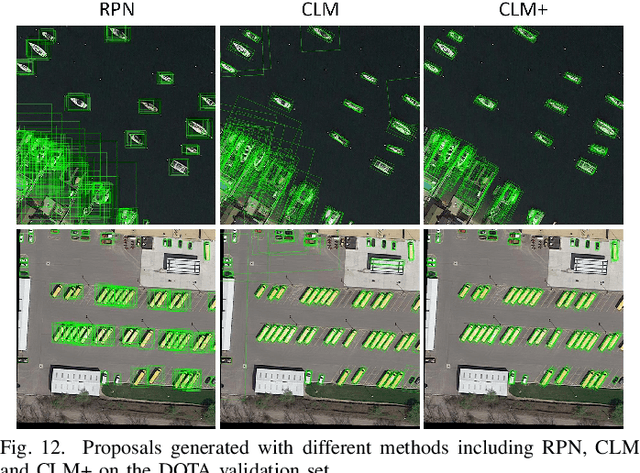
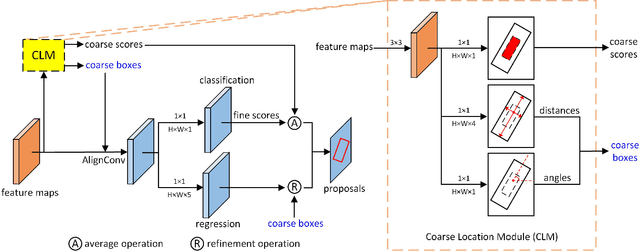
Oriented object detection is a practical and challenging task in remote sensing image interpretation. Nowadays, oriented detectors mostly use horizontal boxes as intermedium to derive oriented boxes from them. However, the horizontal boxes are inclined to get a small Intersection-over-Unions (IoUs) with ground truths, which may have some undesirable effects, such as introducing redundant noise, mismatching with ground truths, detracting from the robustness of detectors, etc. In this paper, we propose a novel Anchor-free Oriented Proposal Generator (AOPG) that abandons the horizontal boxes-related operations from the network architecture. AOPG first produces coarse oriented boxes by Coarse Location Module (CLM) in an anchor-free manner and then refines them into high-quality oriented proposals. After AOPG, we apply a Fast R-CNN head to produce the final detection results. Furthermore, the shortage of large-scale datasets is also a hindrance to the development of oriented object detection. To alleviate the data insufficiency, we release a new dataset on the basis of our DIOR dataset and name it DIOR-R. Massive experiments demonstrate the effectiveness of AOPG. Particularly, without bells and whistles, we achieve the highest accuracy of 64.41$\%$, 75.24$\%$ and 96.22$\%$ mAP on the DIOR-R, DOTA and HRSC2016 datasets respectively. Code and models are available at https://github.com/jbwang1997/AOPG.
Disentangled Cycle Consistency for Highly-realistic Virtual Try-On
Mar 17, 2021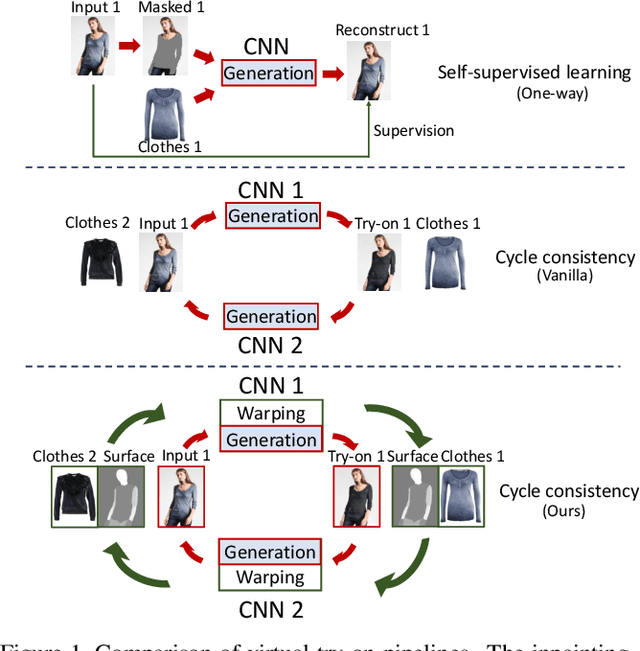
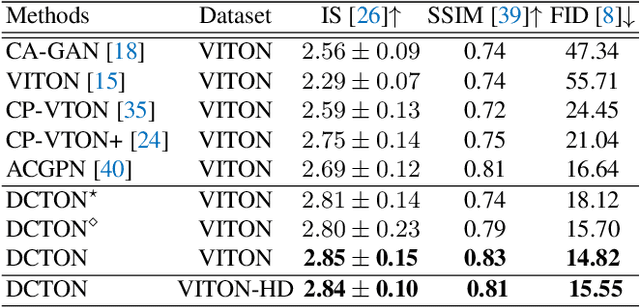

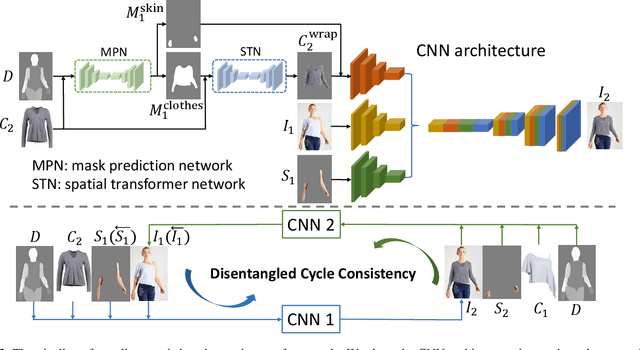
Image virtual try-on replaces the clothes on a person image with a desired in-shop clothes image. It is challenging because the person and the in-shop clothes are unpaired. Existing methods formulate virtual try-on as either in-painting or cycle consistency. Both of these two formulations encourage the generation networks to reconstruct the input image in a self-supervised manner. However, existing methods do not differentiate clothing and non-clothing regions. A straight-forward generation impedes virtual try-on quality because of the heavily coupled image contents. In this paper, we propose a Disentangled Cycle-consistency Try-On Network (DCTON). The DCTON is able to produce highly-realistic try-on images by disentangling important components of virtual try-on including clothes warping, skin synthesis, and image composition. To this end, DCTON can be naturally trained in a self-supervised manner following cycle consistency learning. Extensive experiments on challenging benchmarks show that DCTON outperforms state-of-the-art approaches favorably.
Image Identification Using SIFT Algorithm: Performance Analysis against Different Image Deformations
Mar 13, 2018
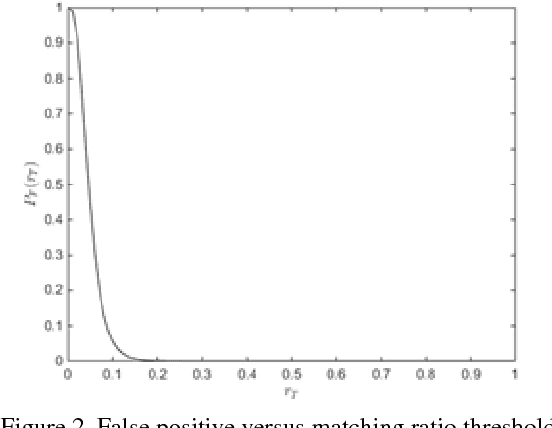
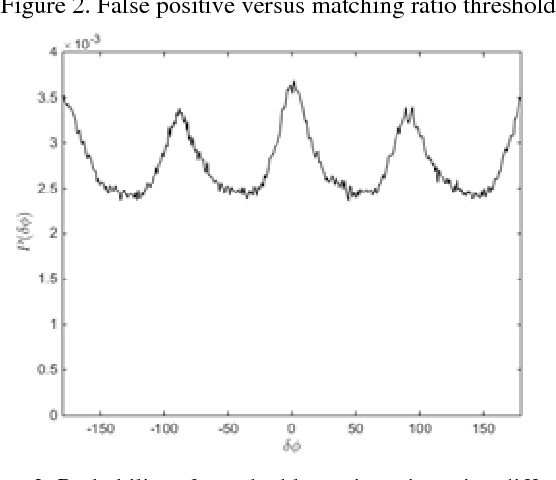
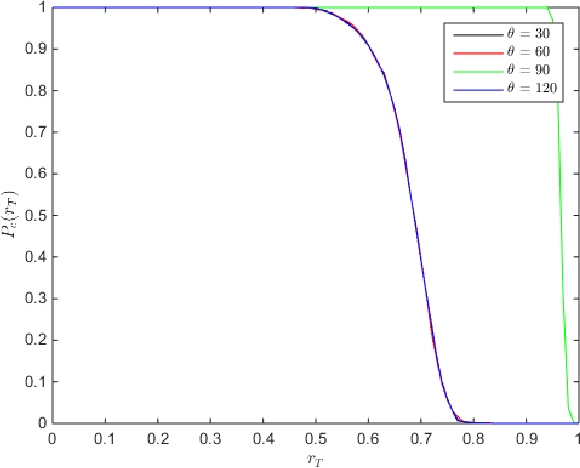
Image identification is one of the most challenging tasks in different areas of computer vision. Scale-invariant feature transform is an algorithm to detect and describe local features in images to further use them as an image matching criteria. In this paper, the performance of the SIFT matching algorithm against various image distortions such as rotation, scaling, fisheye and motion distortion are evaluated and false and true positive rates for a large number of image pairs are calculated and presented. We also evaluate the distribution of the matched keypoint orientation difference for each image deformation.
Physics-based Noise Modeling for Extreme Low-light Photography
Aug 04, 2021

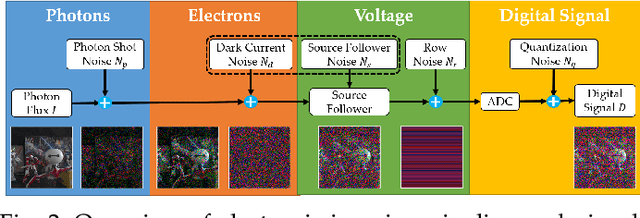
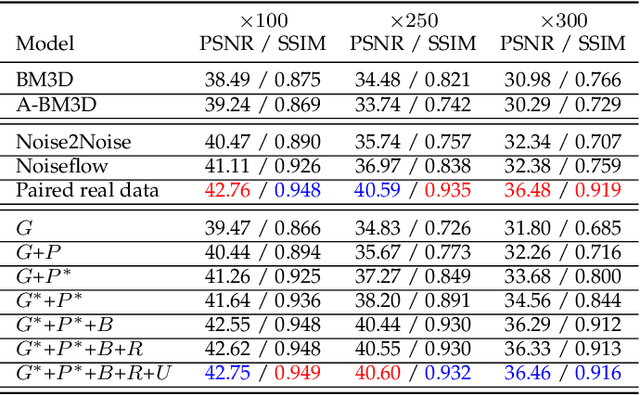
Enhancing the visibility in extreme low-light environments is a challenging task. Under nearly lightless condition, existing image denoising methods could easily break down due to significantly low SNR. In this paper, we systematically study the noise statistics in the imaging pipeline of CMOS photosensors, and formulate a comprehensive noise model that can accurately characterize the real noise structures. Our novel model considers the noise sources caused by digital camera electronics which are largely overlooked by existing methods yet have significant influence on raw measurement in the dark. It provides a way to decouple the intricate noise structure into different statistical distributions with physical interpretations. Moreover, our noise model can be used to synthesize realistic training data for learning-based low-light denoising algorithms. In this regard, although promising results have been shown recently with deep convolutional neural networks, the success heavily depends on abundant noisy clean image pairs for training, which are tremendously difficult to obtain in practice. Generalizing their trained models to images from new devices is also problematic. Extensive experiments on multiple low-light denoising datasets -- including a newly collected one in this work covering various devices -- show that a deep neural network trained with our proposed noise formation model can reach surprisingly-high accuracy. The results are on par with or sometimes even outperform training with paired real data, opening a new door to real-world extreme low-light photography.
DeepEdge: A Deep Reinforcement Learning based Task Orchestrator for Edge Computing
Oct 05, 2021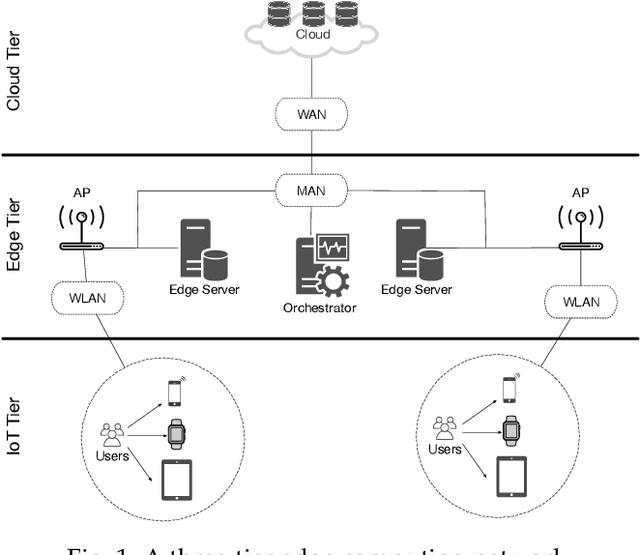

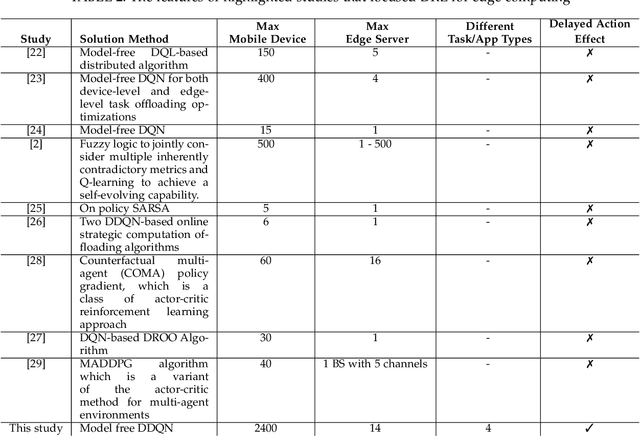

The improvements in the edge computing technology pave the road for diversified applications that demand real-time interaction. However, due to the mobility of the end-users and the dynamic edge environment, it becomes challenging to handle the task offloading with high performance. Moreover, since each application in mobile devices has different characteristics, a task orchestrator must be adaptive and have the ability to learn the dynamics of the environment. For this purpose, we develop a deep reinforcement learning based task orchestrator, DeepEdge, which learns to meet different task requirements without needing human interaction even under the heavily-loaded stochastic network conditions in terms of mobile users and applications. Given the dynamic offloading requests and time-varying communication conditions, we successfully model the problem as a Markov process and then apply the Double Deep Q-Network (DDQN) algorithm to implement DeepEdge. To evaluate the robustness of DeepEdge, we experiment with four different applications including image rendering, infotainment, pervasive health, and augmented reality in the network under various loads. Furthermore, we compare the performance of our agent with the four different task offloading approaches in the literature. Our results show that DeepEdge outperforms its competitors in terms of the percentage of satisfactorily completed tasks.
Fully Spiking Variational Autoencoder
Oct 05, 2021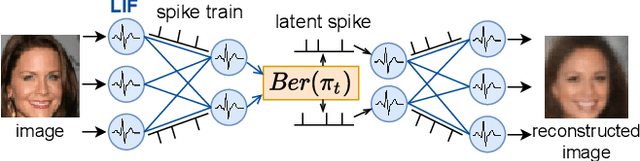
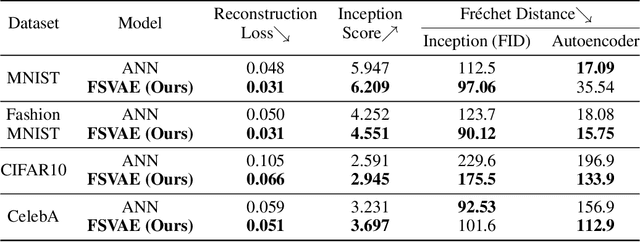
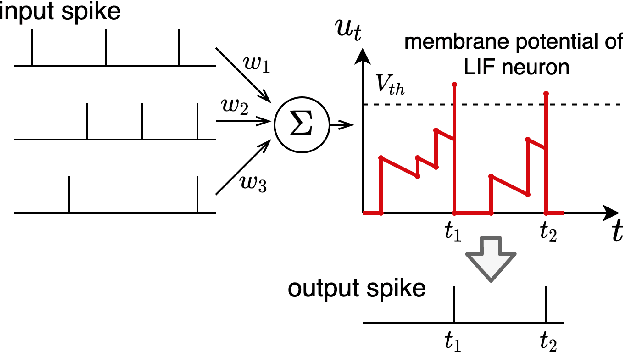

Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature. Therefore, SNNs are expected to have various applications, including as generative models being running on edge devices to create high-quality images. In this study, we build a variational autoencoder (VAE) with SNN to enable image generation. VAE is known for its stability among generative models; recently, its quality advanced. In vanilla VAE, the latent space is represented as a normal distribution, and floating-point calculations are required in sampling. However, this is not possible in SNNs because all features must be binary time series data. Therefore, we constructed the latent space with an autoregressive SNN model, and randomly selected samples from its output to sample the latent variables. This allows the latent variables to follow the Bernoulli process and allows variational learning. Thus, we build the Fully Spiking Variational Autoencoder where all modules are constructed with SNN. To the best of our knowledge, we are the first to build a VAE only with SNN layers. We experimented with several datasets, and confirmed that it can generate images with the same or better quality compared to conventional ANNs. The code is available at https://github.com/kamata1729/FullySpikingVAE
Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Sep 28, 2021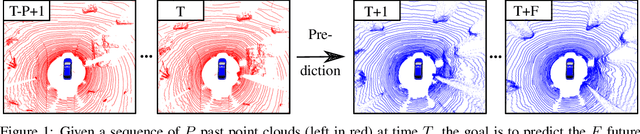
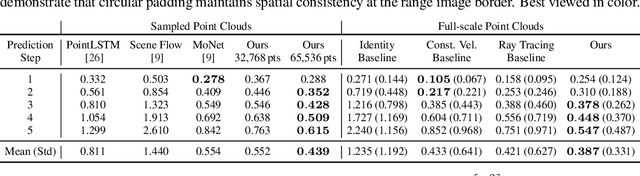
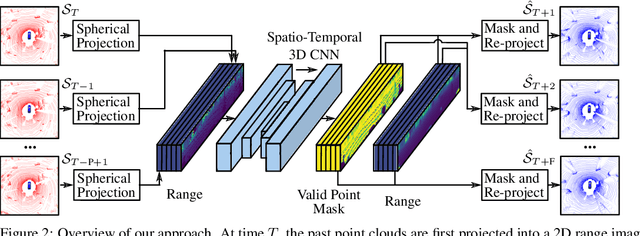
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.
Deep Learning for Earth Image Segmentation based on Imperfect Polyline Labels with Annotation Errors
Oct 02, 2020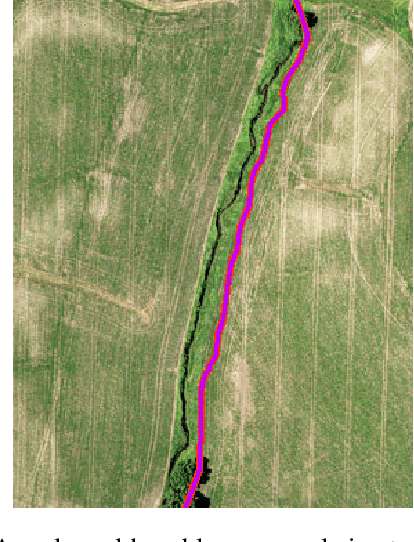
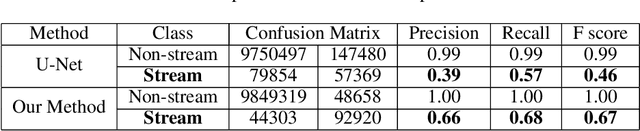
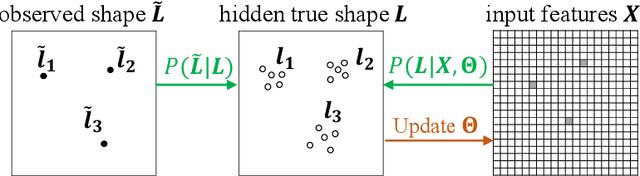
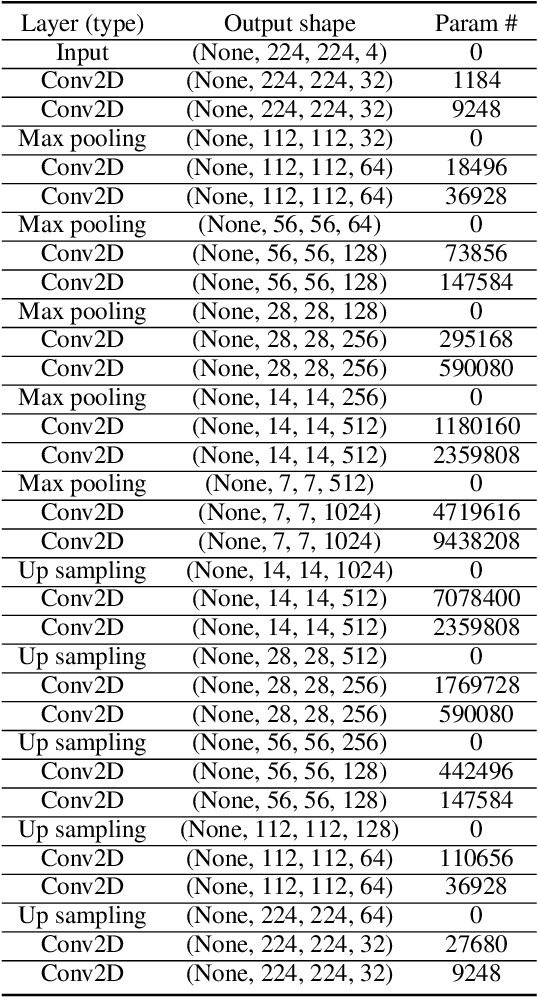
In recent years, deep learning techniques (e.g., U-Net, DeepLab) have achieved tremendous success in image segmentation. The performance of these models heavily relies on high-quality ground truth segment labels. Unfortunately, in many real-world problems, ground truth segment labels often have geometric annotation errors due to manual annotation mistakes, GPS errors, or visually interpreting background imagery at a coarse resolution. Such location errors will significantly impact the training performance of existing deep learning algorithms. Existing research on label errors either models ground truth errors in label semantics (assuming label locations to be correct) or models label location errors with simple square patch shifting. These methods cannot fully incorporate the geometric properties of label location errors. To fill the gap, this paper proposes a generic learning framework based on the EM algorithm to update deep learning model parameters and infer hidden true label locations simultaneously. Evaluations on a real-world hydrological dataset in the streamline refinement application show that the proposed framework outperforms baseline methods in classification accuracy (reducing the number of false positives by 67% and reducing the number of false negatives by 55%).
SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021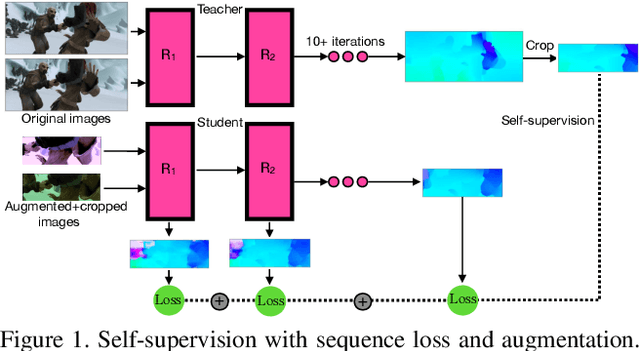
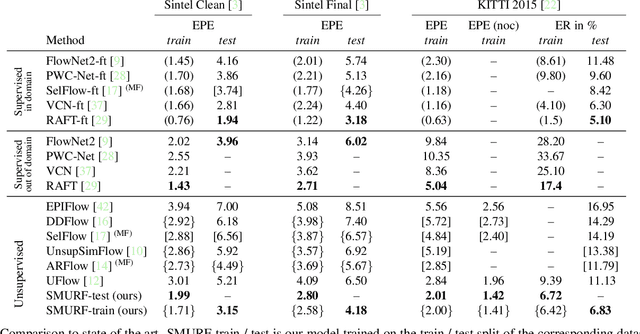
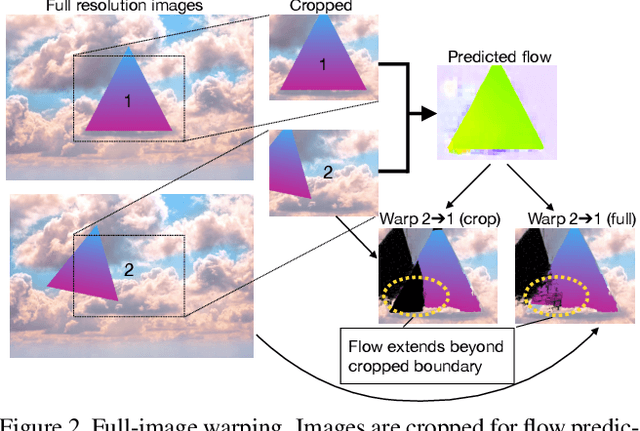
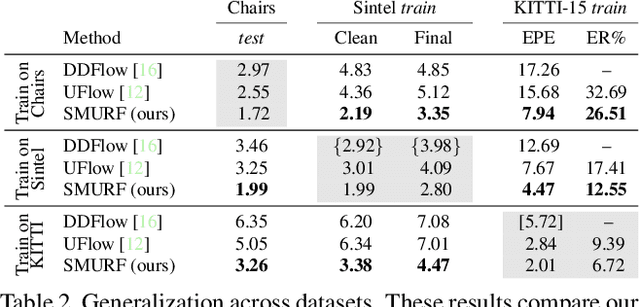
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.