 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning in Medical Image Registration: A Survey
Mar 05, 2019
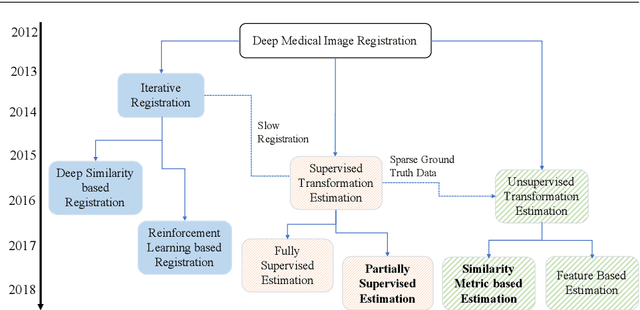
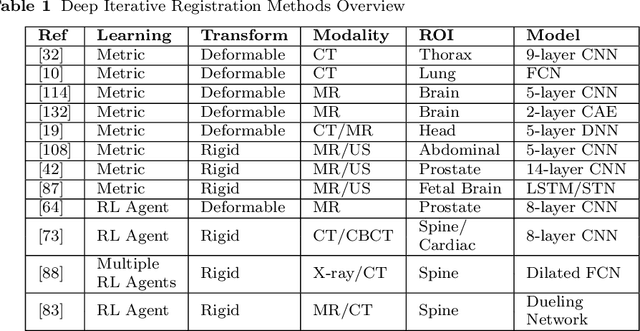
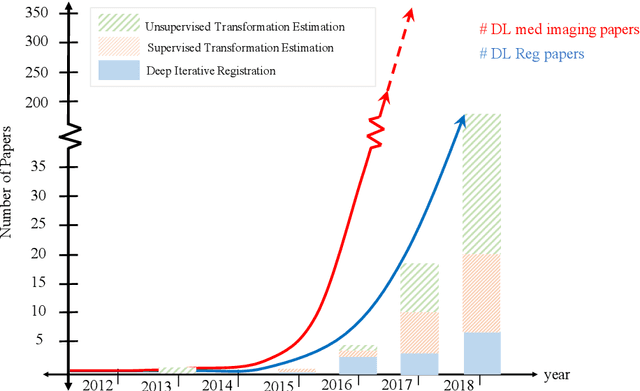
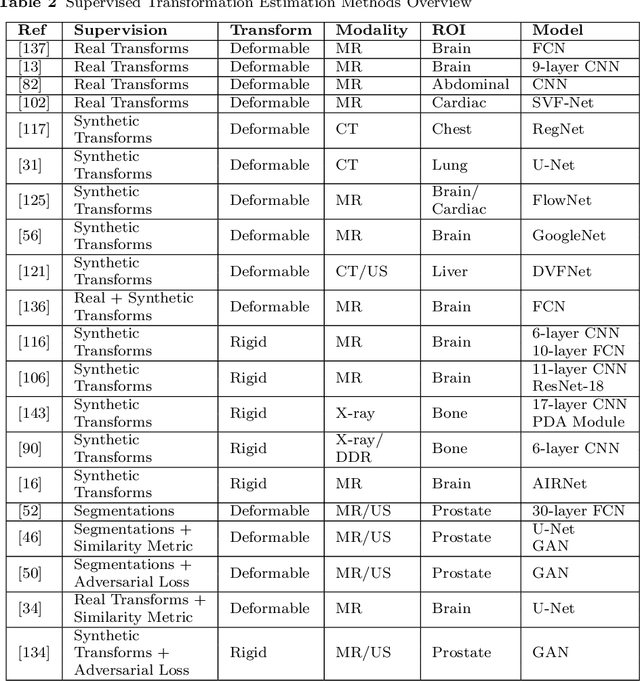
The establishment of image correspondence through robust image registration is critical to many clinical tasks such as image fusion, organ atlas creation, and tumor growth monitoring, and is a very challenging problem. Since the beginning of the recent deep learning renaissance, the medical imaging research community has developed deep learning based approaches and achieved the state-of-the-art in many applications, including image registration. The rapid adoption of deep learning for image registration applications over the past few years necessitates a comprehensive summary and outlook, which is the main scope of this survey. This requires placing a focus on the different research areas as well as highlighting challenges that practitioners face. This survey, therefore, outlines the evolution of deep learning based medical image registration in the context of both research challenges and relevant innovations in the past few years. Further, this survey highlights future research directions to show how this field may be possibly moved forward to the next level.
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
Jul 01, 2020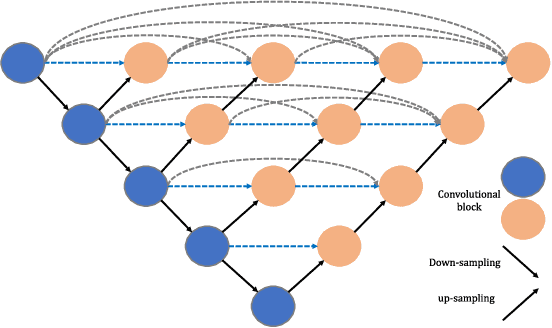



In this paper we propose a novel method for infrared and visible image fusion where we develop nest connection-based network and spatial/channel attention models. The nest connection-based network can preserve significant amounts of information from input data in a multi-scale perspective. The approach comprises three key elements: encoder, fusion strategy and decoder respectively. In our proposed fusion strategy, spatial attention models and channel attention models are developed that describe the importance of each spatial position and of each channel with deep features. Firstly, the source images are fed into the encoder to extract multi-scale deep features. The novel fusion strategy is then developed to fuse these features for each scale. Finally, the fused image is reconstructed by the nest connection-based decoder. Experiments are performed on publicly available datasets. These exhibit that our proposed approach has better fusion performance than other state-of-the-art methods. This claim is justified through both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-nestfuse
Ultrasound Domain Adaptation Using Frequency Domain Analysis
Sep 21, 2021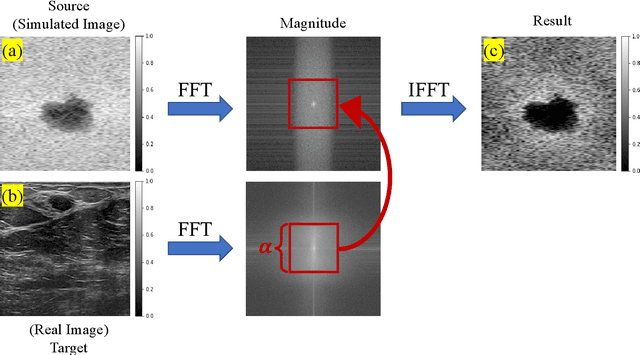
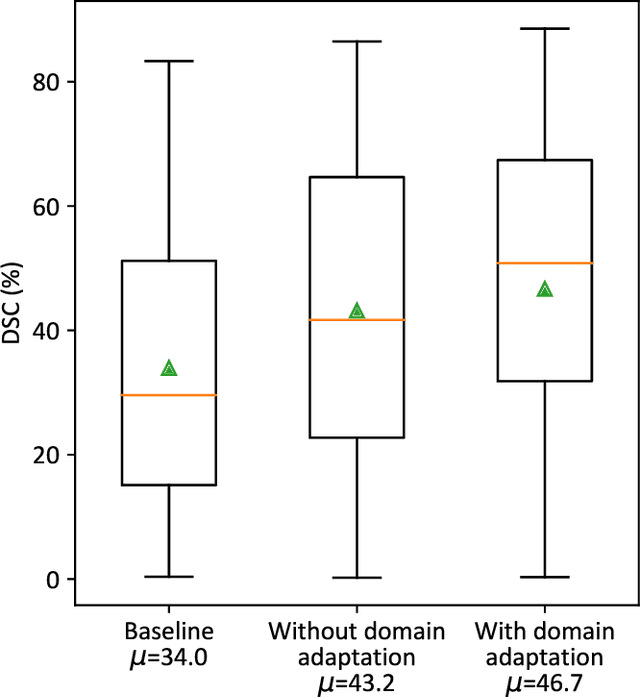
A common issue in exploiting simulated ultrasound data for training neural networks is the domain shift problem, where the trained models on synthetic data are not generalizable to clinical data. Recently, Fourier Domain Adaptation (FDA) has been proposed in the field of computer vision to tackle the domain shift problem by replacing the magnitude of the low-frequency spectrum of a synthetic sample (source) with a real sample (target). This method is attractive in ultrasound imaging given that two important differences between synthetic and real ultrasound data are caused by unknown values of attenuation and speed of sound (SOS) in real tissues. Attenuation leads to slow variations in the amplitude of the B-mode image, and SOS mismatch creates aberration and subsequent blurring. As such, both domain shifts cause differences in the low-frequency components of the envelope data, which are replaced in the proposed method. We demonstrate that applying the FDA method to the synthetic data, simulated by Field II, obtains an 3.5\% higher Dice similarity coefficient for a breast lesion segmentation task.
Image Manipulation with Natural Language using Two-sidedAttentive Conditional Generative Adversarial Network
Dec 16, 2019
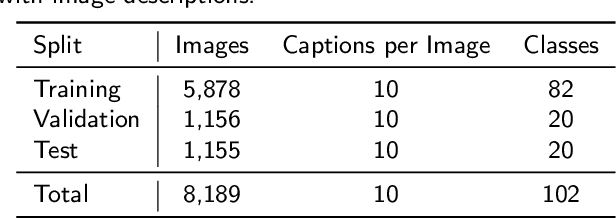
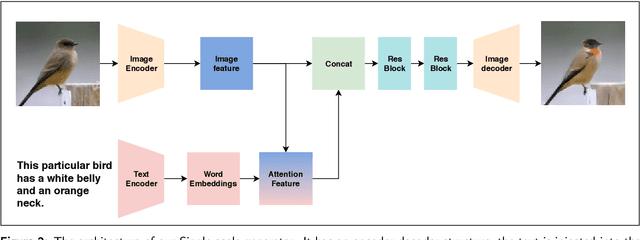
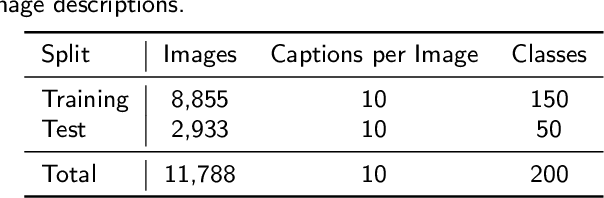
Altering the content of an image with photo editing tools is a tedious task for an inexperienced user. Especially, when modifying the visual attributes of a specific object in an image without affecting other constituents such as background etc. To simplify the process of image manipulation and to provide more control to users, it is better to utilize a simpler interface like natural language. Therefore, in this paper, we address the challenge of manipulating images using natural language description. We propose the Two-sidEd Attentive conditional Generative Adversarial Network (TEA-cGAN) to generate semantically manipulated images while preserving other contents such as background intact. TEA-cGAN uses fine-grained attention both in the generator and discriminator of Generative Adversarial Network (GAN) based framework at different scales. Experimental results show that TEA-cGAN which generates 128x128 and 256x256 resolution images outperforms existing methods on CUB and Oxford-102 datasets both quantitatively and qualitatively.
Applying the Case Difference Heuristic to Learn Adaptations from Deep Network Features
Jul 15, 2021
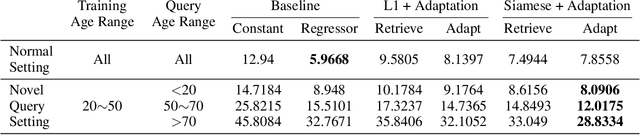
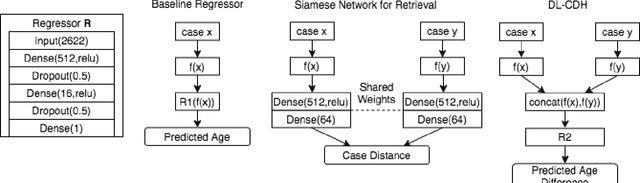
The case difference heuristic (CDH) approach is a knowledge-light method for learning case adaptation knowledge from the case base of a case-based reasoning system. Given a pair of cases, the CDH approach attributes the difference in their solutions to the difference in the problems they solve, and generates adaptation rules to adjust solutions accordingly when a retrieved case and new query have similar problem differences. As an alternative to learning adaptation rules, several researchers have applied neural networks to learn to predict solution differences from problem differences. Previous work on such approaches has assumed that the feature set describing problems is predefined. This paper investigates a two-phase process combining deep learning for feature extraction and neural network based adaptation learning from extracted features. Its performance is demonstrated in a regression task on an image data: predicting age given the image of a face. Results show that the combined process can successfully learn adaptation knowledge applicable to nonsymbolic differences in cases. The CBR system achieves slightly lower performance overall than a baseline deep network regressor, but better performance than the baseline on novel queries.
Controllable List-wise Ranking for Universal No-reference Image Quality Assessment
Nov 24, 2019
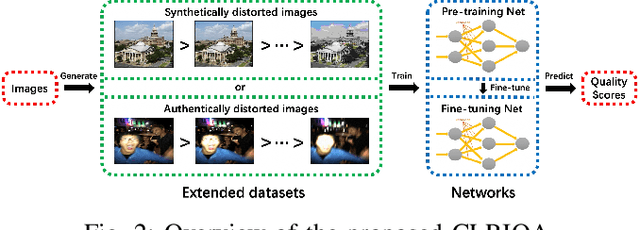

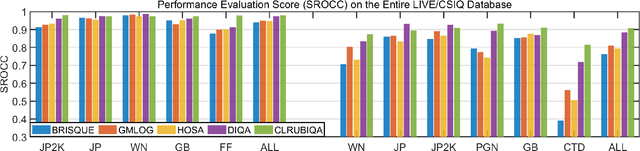
No-reference image quality assessment (NR-IQA) has received increasing attention in the IQA community since reference image is not always available. Real-world images generally suffer from various types of distortion. Unfortunately, existing NR-IQA methods do not work with all types of distortion. It is a challenging task to develop universal NR-IQA that has the ability of evaluating all types of distorted images. In this paper, we propose a universal NR-IQA method based on controllable list-wise ranking (CLRIQA). First, to extend the authentically distorted image dataset, we present an imaging-heuristic approach, in which the over-underexposure is formulated as an inverse of Weber-Fechner law, and fusion strategy and probabilistic compression are adopted, to generate the degraded real-world images. These degraded images are label-free yet associated with quality ranking information. We then design a controllable list-wise ranking function by limiting rank range and introducing an adaptive margin to tune rank interval. Finally, the extended dataset and controllable list-wise ranking function are used to pre-train a CNN. Moreover, in order to obtain an accurate prediction model, we take advantage of the original dataset to further fine-tune the pre-trained network. Experiments evaluated on four benchmark datasets (i.e. LIVE, CSIQ, TID2013, and LIVE-C) show that the proposed CLRIQA improves the state of the art by over 8% in terms of overall performance. The code and model are publicly available at https://github.com/GZHU-Image-Lab/CLRIQA.
Unsupervised Domain Adaptation for Retinal Vessel Segmentation with Adversarial Learning and Transfer Normalization
Aug 04, 2021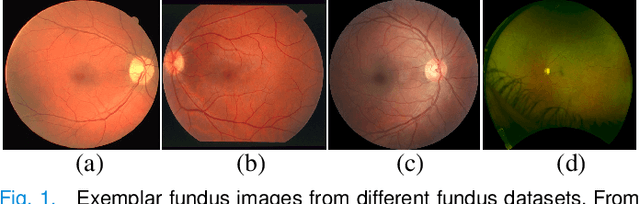
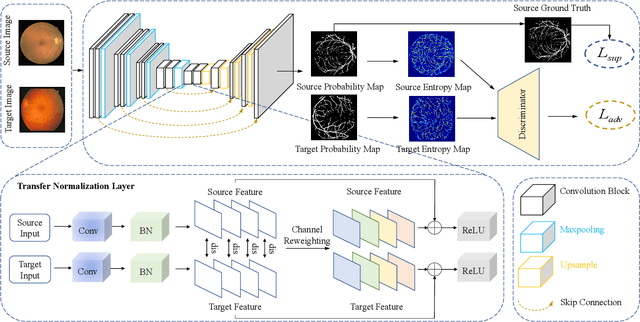
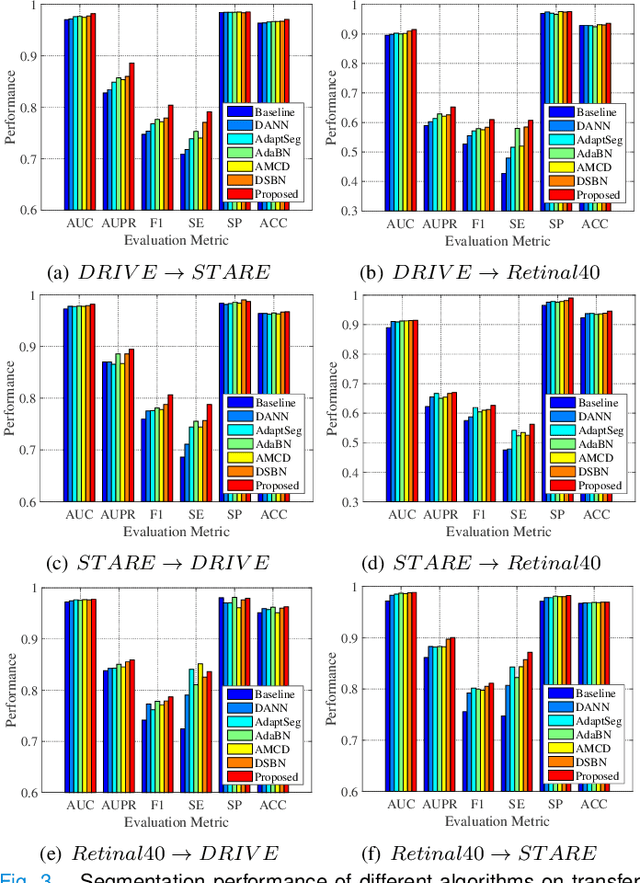

Retinal vessel segmentation plays a key role in computer-aided screening, diagnosis, and treatment of various cardiovascular and ophthalmic diseases. Recently, deep learning-based retinal vessel segmentation algorithms have achieved remarkable performance. However, due to the domain shift problem, the performance of these algorithms often degrades when they are applied to new data that is different from the training data. Manually labeling new data for each test domain is often a time-consuming and laborious task. In this work, we explore unsupervised domain adaptation in retinal vessel segmentation by using entropy-based adversarial learning and transfer normalization layer to train a segmentation network, which generalizes well across domains and requires no annotation of the target domain. Specifically, first, an entropy-based adversarial learning strategy is developed to reduce the distribution discrepancy between the source and target domains while also achieving the objective of entropy minimization on the target domain. In addition, a new transfer normalization layer is proposed to further boost the transferability of the deep network. It normalizes the features of each domain separately to compensate for the domain distribution gap. Besides, it also adaptively selects those feature channels that are more transferable between domains, thus further enhancing the generalization performance of the network. We conducted extensive experiments on three regular fundus image datasets and an ultra-widefield fundus image dataset, and the results show that our approach yields significant performance gains compared to other state-of-the-art methods.
End-to-End Monocular Vanishing Point Detection Exploiting Lane Annotations
Aug 31, 2021
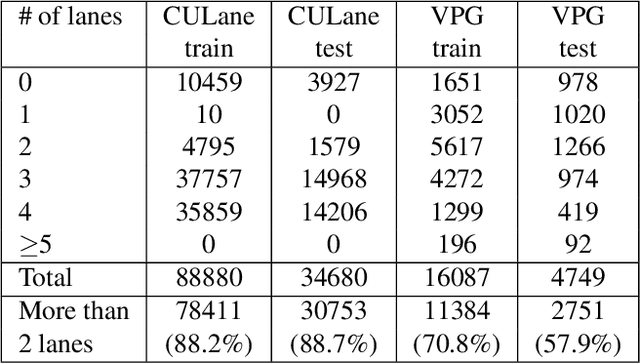
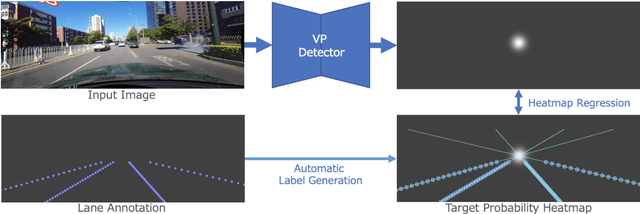
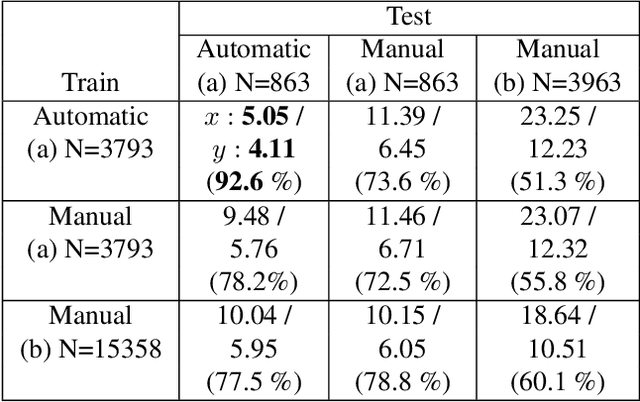
Vanishing points (VPs) play a vital role in various computer vision tasks, especially for recognizing the 3D scenes from an image. In the real-world scenario of automobile applications, it is costly to manually obtain the external camera parameters when the camera is attached to the vehicle or the attachment is accidentally perturbed. In this paper we introduce a simple but effective end-to-end vanishing point detection. By automatically calculating intersection of the extrapolated lane marker annotations, we obtain geometrically consistent VP labels and mitigate human annotation errors caused by manual VP labeling. With the calculated VP labels we train end-to-end VP Detector via heatmap estimation. The VP Detector realizes higher accuracy than the methods utilizing manual annotation or lane detection, paving the way for accurate online camera calibration.
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
Sep 28, 2021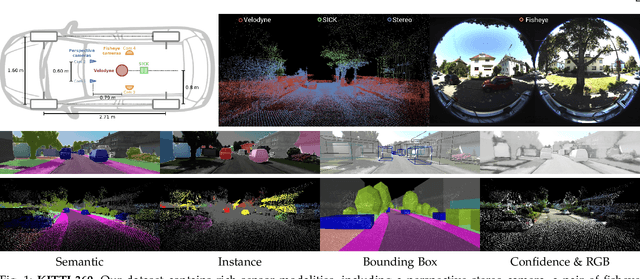
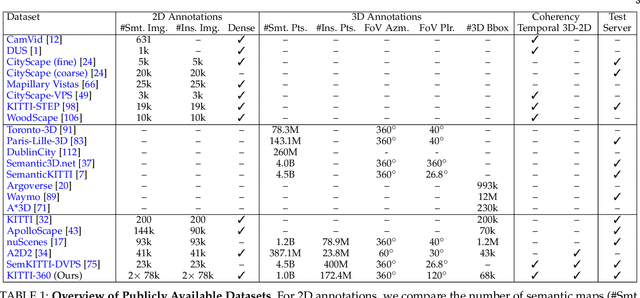
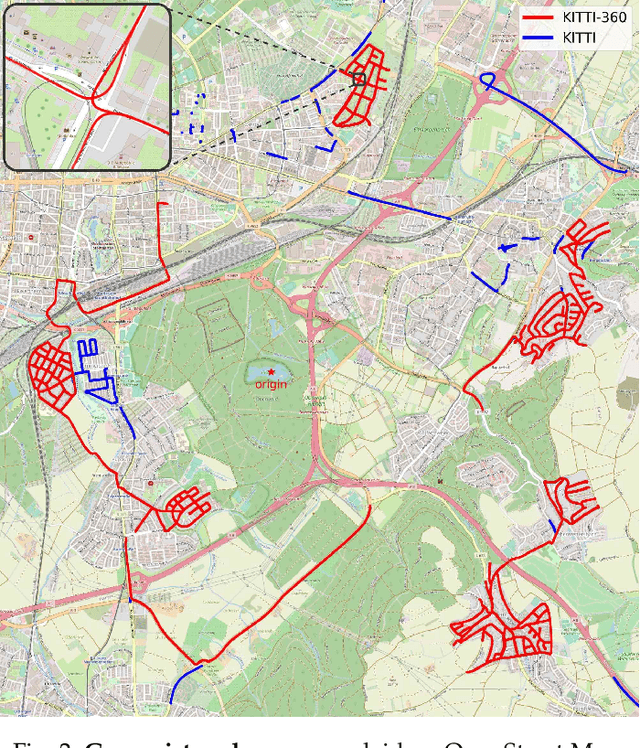
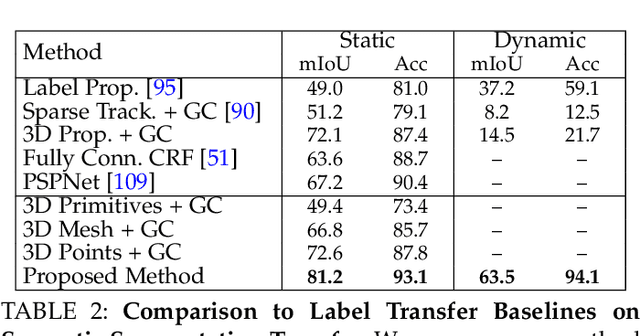
For the last few decades, several major subfields of artificial intelligence including computer vision, graphics, and robotics have progressed largely independently from each other. Recently, however, the community has realized that progress towards robust intelligent systems such as self-driving cars requires a concerted effort across the different fields. This motivated us to develop KITTI-360, successor of the popular KITTI dataset. KITTI-360 is a suburban driving dataset which comprises richer input modalities, comprehensive semantic instance annotations and accurate localization to facilitate research at the intersection of vision, graphics and robotics. For efficient annotation, we created a tool to label 3D scenes with bounding primitives and developed a model that transfers this information into the 2D image domain, resulting in over 150k semantic and instance annotated images and 1B annotated 3D points. Moreover, we established benchmarks and baselines for several tasks relevant to mobile perception, encompassing problems from computer vision, graphics, and robotics on the same dataset. KITTI-360 will enable progress at the intersection of these research areas and thus contributing towards solving one of our grand challenges: the development of fully autonomous self-driving systems.
Robust Reflection Removal with Reflection-free Flash-only Cues
Mar 07, 2021
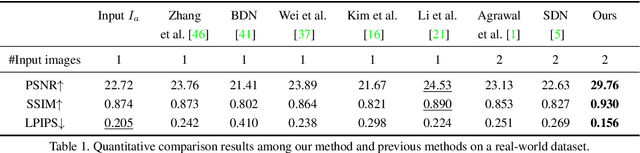
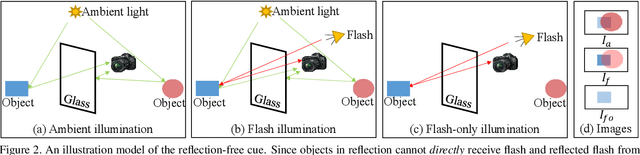
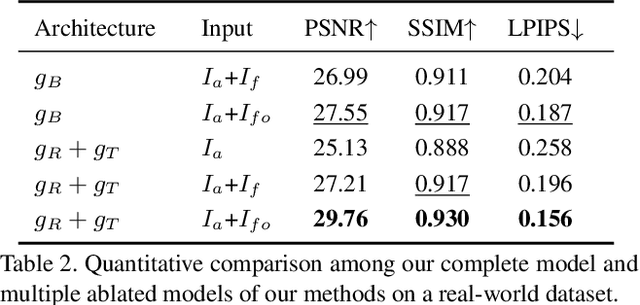
We propose a simple yet effective reflection-free cue for robust reflection removal from a pair of flash and ambient (no-flash) images. The reflection-free cue exploits a flash-only image obtained by subtracting the ambient image from the corresponding flash image in raw data space. The flash-only image is equivalent to an image taken in a dark environment with only a flash on. We observe that this flash-only image is visually reflection-free, and thus it can provide robust cues to infer the reflection in the ambient image. Since the flash-only image usually has artifacts, we further propose a dedicated model that not only utilizes the reflection-free cue but also avoids introducing artifacts, which helps accurately estimate reflection and transmission. Our experiments on real-world images with various types of reflection demonstrate the effectiveness of our model with reflection-free flash-only cues: our model outperforms state-of-the-art reflection removal approaches by more than 5.23dB in PSNR, 0.04 in SSIM, and 0.068 in LPIPS. Our source code and dataset will be publicly available at \href{https://github.com/ChenyangLEI/flash-reflection-removal}{this website}.