 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving the Harmony of the Composite Image by Spatial-Separated Attention Module
Jul 15, 2019
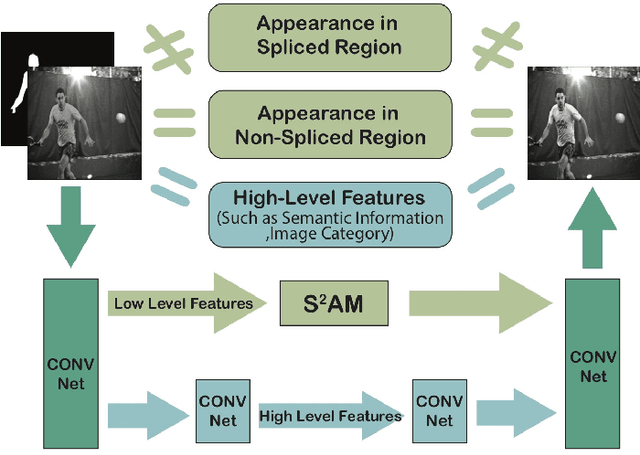
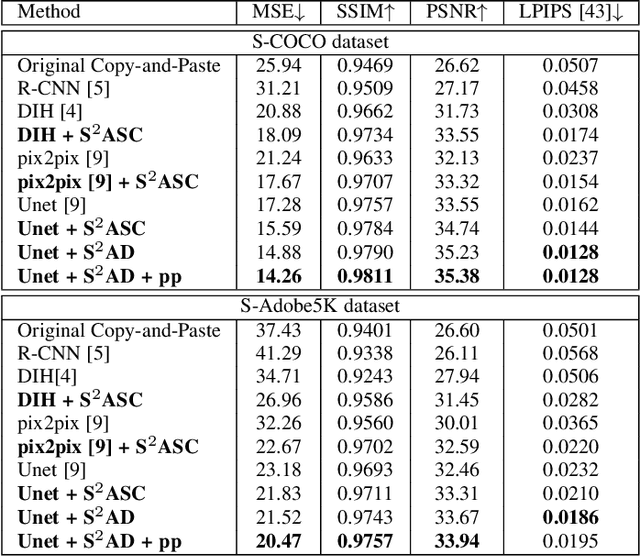
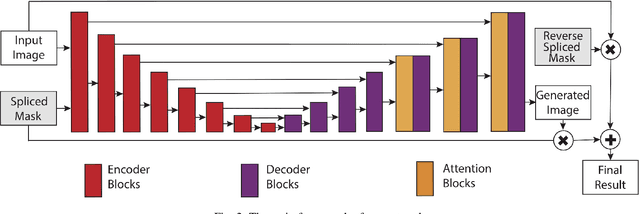
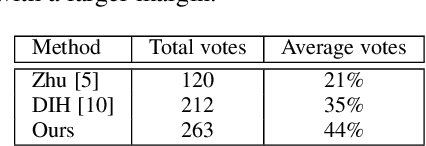
Image composition is one of the most important applications in image processing. However, the inharmonious appearance between the spliced region and background degrade the quality of the image. Thus, we address the problem of Image Harmonization: Given a spliced image and the mask of the spliced region, we try to harmonize the "style'' of the pasted region with the background (non-spliced region). Previous approaches have been focusing on learning directly by the neural network. In this work, we start from an empirical observation: the differences can only be found in the spliced region between the spliced image and the harmonized result while they share the same semantic information and the appearance in the non-spliced region. Thus, in order to learn the feature map in the masked region and the others individually, we propose a novel attention module named Spatial-Separated Attention Module (S2AM). Furthermore, we design a novel image harmonization framework by inserting the S2AM in the coarser low-level features of the Unet structure in two different ways. Besides image harmonization, we make a big step for harmonizing the composite image without the specific mask under previous observation. The experiments show that the proposed S2AM performs better than other state-of-the-art attention modules in our task. Moreover, we demonstrate the advantages of our model against other state-of-the-art image harmonization methods via criteria from multiple points of view. Code is available at https://github.com/vinthony/s2am
Towards Accurate Camera Geopositioning by Image Matching
Mar 13, 2019In this work, we present a camera geopositioning system based on matching a query image against a database with panoramic images. For matching, our system uses memory vectors aggregated from global image descriptors based on convolutional features to facilitate fast searching in the database. To speed up searching, a clustering algorithm is used to balance geographical positioning and computation time. We refine the obtained position from the query image using a new outlier removal algorithm. The matching of the query image is obtained with a recall@5 larger than 90% for panorama-to-panorama matching. We cluster available panoramas from geographically adjacent locations into a single compact representation and observe computational gains of approximately 50% at the cost of only a small (approximately 3%) recall loss. Finally, we present a coordinate estimation algorithm that reduces the median geopositioning error by up to 20%.
Exploring Heterogeneous Metadata for Video Recommendation with Two-tower Model
Sep 22, 2021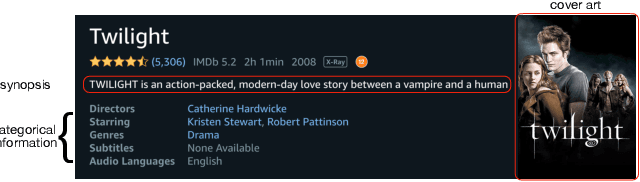
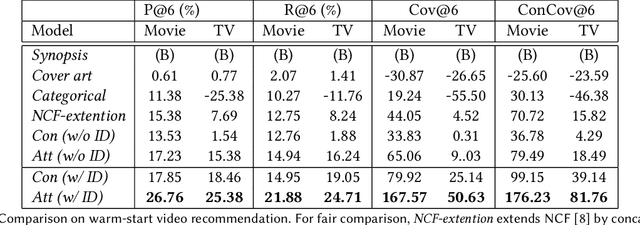
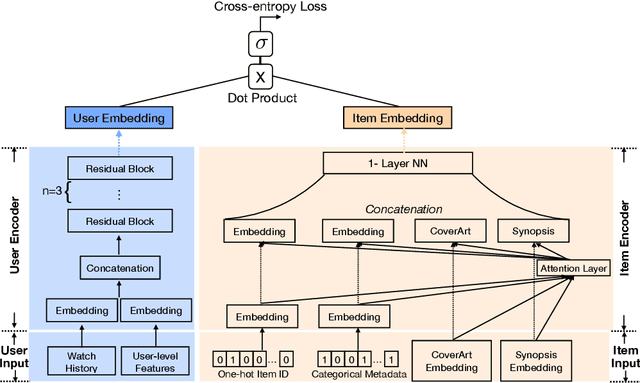

Online video services acquire new content on a daily basis to increase engagement, and improve the user experience. Traditional recommender systems solely rely on watch history, delaying the recommendation of newly added titles to the right customer. However, one can use the metadata information of a cold-start title to bootstrap the personalization. In this work, we propose to adopt a two-tower model, in which one tower is to learn the user representation based on their watch history, and the other tower is to learn the effective representations for titles using metadata. The contribution of this work can be summarized as: (1) we show the feasibility of using two-tower model for recommendations and conduct a series of offline experiments to show its performance for cold-start titles; (2) we explore different types of metadata (categorical features, text description, cover-art image) and an attention layer to fuse them; (3) with our Amazon proprietary data, we show that the attention layer can assign weights adaptively to different metadata with improved recommendation for warm- and cold-start items.
MLAN: Multi-Level Adversarial Network for Domain Adaptive Semantic Segmentation
Mar 24, 2021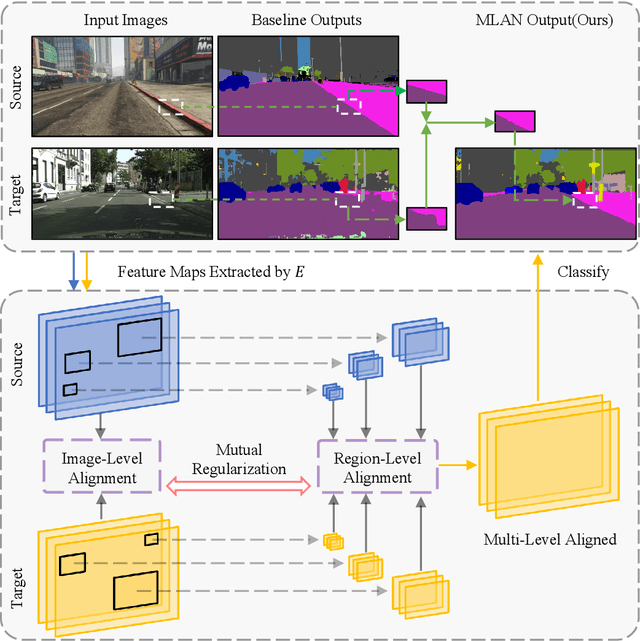

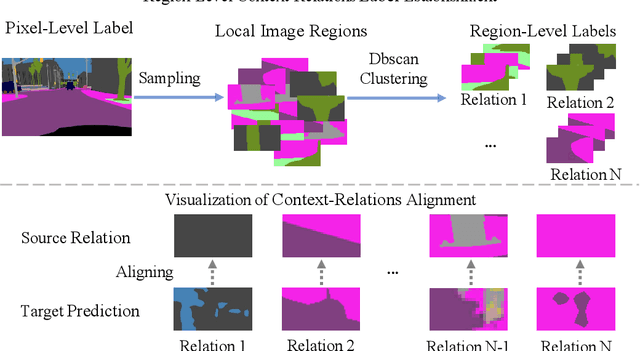

Recent progresses in domain adaptive semantic segmentation demonstrate the effectiveness of adversarial learning (AL) in unsupervised domain adaptation. However, most adversarial learning based methods align source and target distributions at a global image level but neglect the inconsistency around local image regions. This paper presents a novel multi-level adversarial network (MLAN) that aims to address inter-domain inconsistency at both global image level and local region level optimally. MLAN has two novel designs, namely, region-level adversarial learning (RL-AL) and co-regularized adversarial learning (CR-AL). Specifically, RL-AL models prototypical regional context-relations explicitly in the feature space of a labelled source domain and transfers them to an unlabelled target domain via adversarial learning. CR-AL fuses region-level AL and image-level AL optimally via mutual regularization. In addition, we design a multi-level consistency map that can guide domain adaptation in both input space ($i.e.$, image-to-image translation) and output space ($i.e.$, self-training) effectively. Extensive experiments show that MLAN outperforms the state-of-the-art with a large margin consistently across multiple datasets.
Acoustic Anomaly Detection for Machine Sounds based on Image Transfer Learning
Jun 05, 2020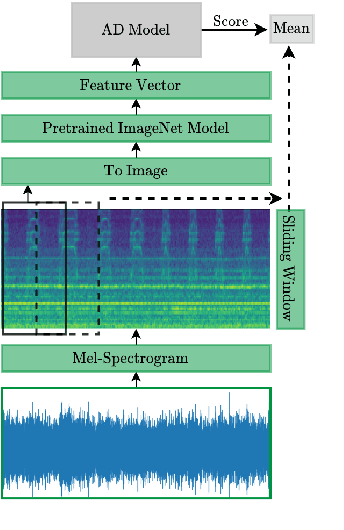
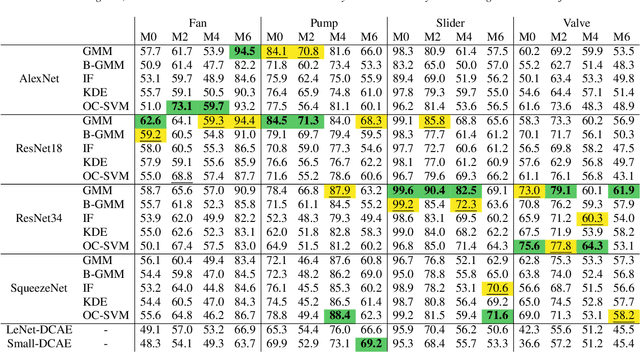
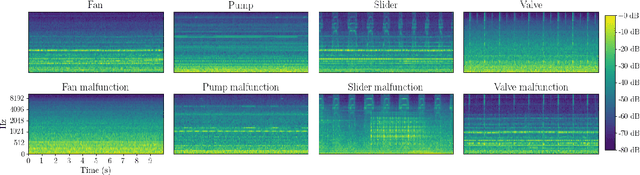
In industrial applications, the early detection of malfunctioning factory machinery is crucial. In this paper, we consider acoustic malfunction detection via transfer learning. Contrary to the majority of current approaches which are based on deep autoencoders, we propose to extract features using neural networks that were pretrained on the task of image classification. We then use these features to train a variety of anomaly detection models and show that this improves results compared to convolutional autoencoders in recordings of four different factory machines in noisy environments. Moreover, we find that features extracted from ResNet based networks yield better results than those from AlexNet and Squeezenet. In our setting, Gaussian Mixture Models and One-Class Support Vector Machines achieve the best anomaly detection performance.
An MRF-UNet Product of Experts for Image Segmentation
Apr 12, 2021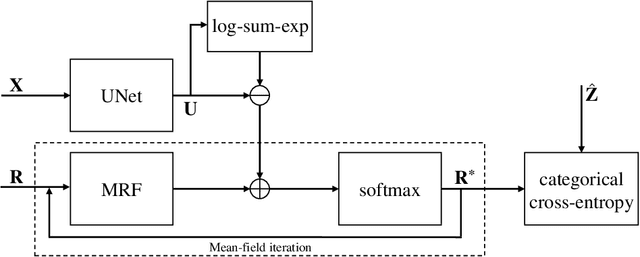
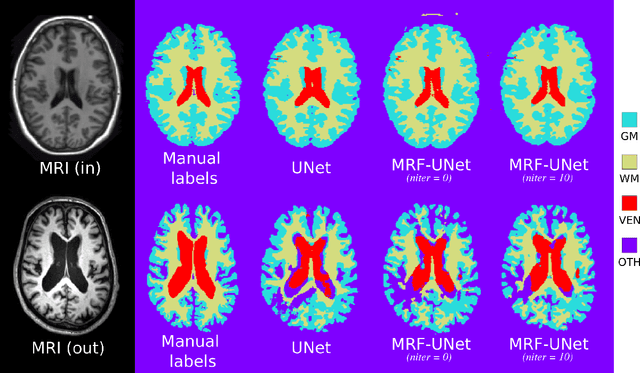
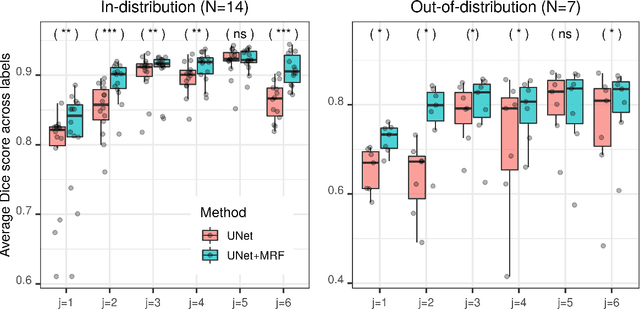
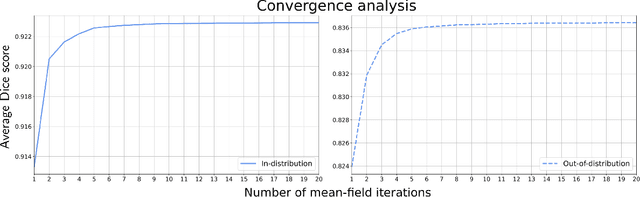
While convolutional neural networks (CNNs) trained by back-propagation have seen unprecedented success at semantic segmentation tasks, they are known to struggle on out-of-distribution data. Markov random fields (MRFs) on the other hand, encode simpler distributions over labels that, although less flexible than UNets, are less prone to over-fitting. In this paper, we propose to fuse both strategies by computing the product of distributions of a UNet and an MRF. As this product is intractable, we solve for an approximate distribution using an iterative mean-field approach. The resulting MRF-UNet is trained jointly by back-propagation. Compared to other works using conditional random fields (CRFs), the MRF has no dependency on the imaging data, which should allow for less over-fitting. We show on 3D neuroimaging data that this novel network improves generalisation to out-of-distribution samples. Furthermore, it allows the overall number of parameters to be reduced while preserving high accuracy. These results suggest that a classic MRF smoothness prior can allow for less over-fitting when principally integrated into a CNN model. Our implementation is available at https://github.com/balbasty/nitorch.
An improved 3D region detection network: automated detection of the 12th thoracic vertebra in image guided radiation therapy
Mar 26, 2020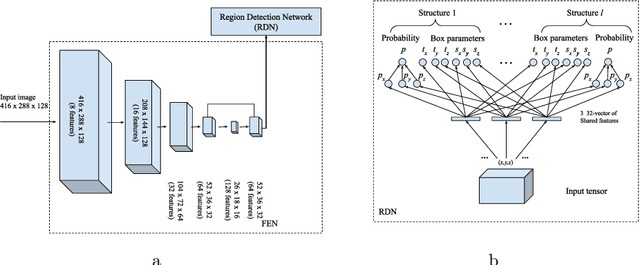
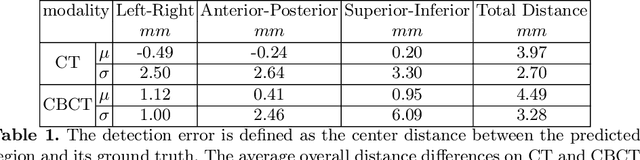
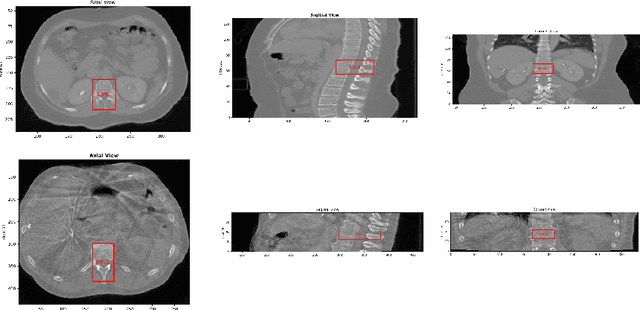
Abstract. Image guidance has been widely used in radiation therapy. Correctly identifying anatomical landmarks, like the 12th thoracic vertebra (T12), is the key to success. Until recently, the detection of those landmarks still requires tedious manual inspections and annotations; and superior-inferior misalignment to the wrong vertebral body is still relatively common in image guided radiation therapy. It is necessary to develop an automated approach to detect those landmarks from images. There are three major challenges to identify T12 vertebra automatically: 1) subtle difference in the structures with high similarity, 2) limited annotated training data, and 3) high memory usage of 3D networks. Abstract. In this study, we propose a novel 3D full convolutional network (FCN) that is trained to detect anatomical structures from 3D volumetric data, requiring only a small amount of training data. Comparing with existing approaches, the network architecture, target generation and loss functions were significantly improved to address the challenges specific to medical images. In our experiments, the proposed network, which was trained from a small amount of annotated images, demonstrated the capability of accurately detecting structures with high similarity. Furthermore, the trained network showed the capability of cross-modality learning. This is meaningful in the situation where image annotations in one modality are easier to obtain than others. The cross-modality learning ability also indicated that the learned features were robust to noise in different image modalities. In summary, our approach has a great potential to be integrated into the clinical workflow to improve the safety of image guided radiation therapy.
Parameter Constrained Transfer Learning for Low Dose PET Image Denoising
Oct 13, 2019



Positron emission tomography (PET) is widely used in clinical practice. However, the potential risk of PET-associated radiation dose to patients needs to be minimized. With reduction of the radiation dose, the resultant images may suffer from noise and artifacts which compromises the diagnostic performance. In this paper, we propose a parameter-constrained generative adversarial network with Wasserstein distance and perceptual loss (PC-WGAN) for low-dose PET image denoising. This method makes two main contributions: 1) a PC-WGAN framework is designed to denoise low-dose PET images without compromising structural details; and 2) a transfer learning strategy is developed to train PC-WGAN with parameters being constrained, which has major merits; namely, making the training process of PC-WGAN efficient and improving the quality of denoised images. The experimental results on clinical data show that the proposed network can suppress image noise more effectively while preserving better image fidelity than three selected state-of-the-art methods.
Deeply Matting-based Dual Generative Adversarial Network for Image and Document Label Supervision
Sep 19, 2019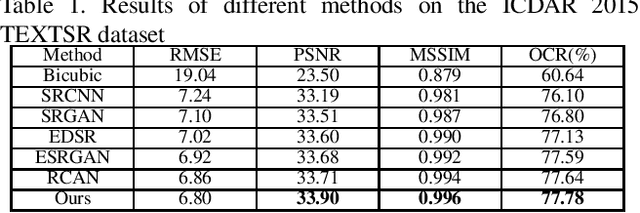
Although many methods have been proposed to deal with nature image super-resolution (SR) and get impressive performance, the text images SR is not good due to their ignorance of document images. In this paper, we propose a matting-based dual generative adversarial network (mdGAN) for document image SR. Firstly, the input image is decomposed into document text, foreground and background layers using deep image matting. Then two parallel branches are constructed to recover text boundary information and color information respectively. Furthermore, in order to improve the restoration accuracy of characters in output image, we use the input image's corresponding ground truth text label as extra supervise information to refine the two-branch networks during training. Experiments on real text images demonstrate that our method outperforms several state-of-the-art methods quantitatively and qualitatively.
Synergic Adversarial Label Learning with DR and AMD for Retinal Image Grading
Mar 24, 2020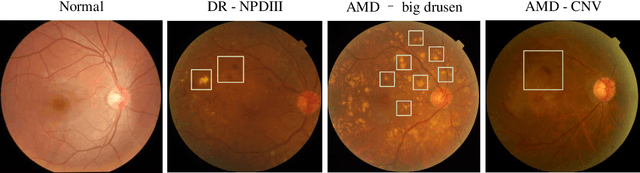
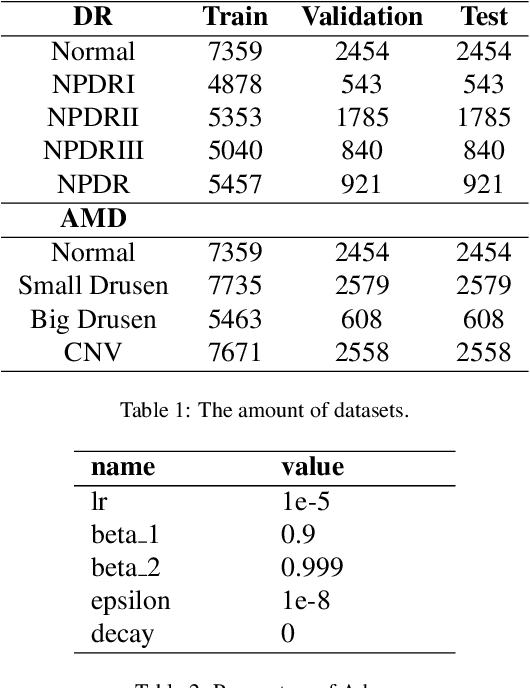
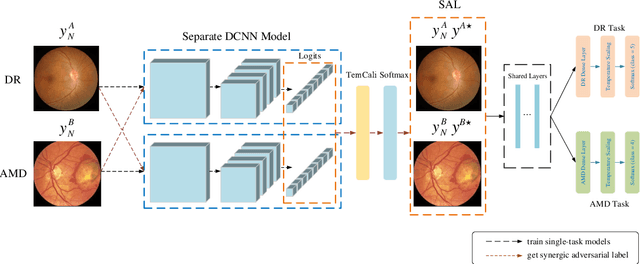
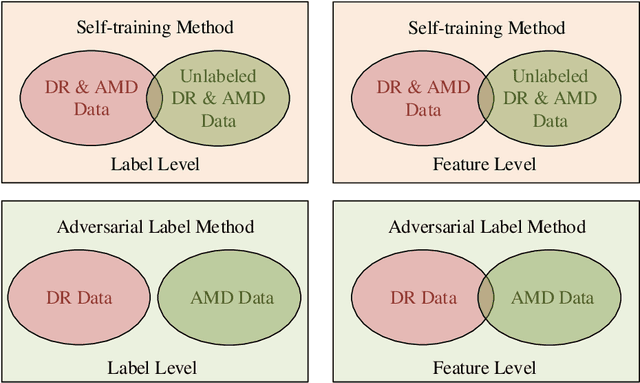
The need for comprehensive and automated screening methods for retinal image classification has long been recognized. Well-qualified doctors annotated images are very expensive and only a limited amount of data is available for various retinal diseases such as age-related macular degeneration (AMD) and diabetic retinopathy (DR). Some studies show that AMD and DR share some common features like hemorrhagic points and exudation but most classification algorithms only train those disease models independently. Inspired by knowledge distillation where additional monitoring signals from various sources is beneficial to train a robust model with much fewer data. We propose a method called synergic adversarial label learning (SALL) which leverages relevant retinal disease labels in both semantic and feature space as additional signals and train the model in a collaborative manner. Our experiments on DR and AMD fundus image classification task demonstrate that the proposed method can significantly improve the accuracy of the model for grading diseases. In addition, we conduct additional experiments to show the effectiveness of SALL from the aspects of reliability and interpretability in the context of medical imaging application.