 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physics-based Noise Modeling for Extreme Low-light Photography
Aug 04, 2021


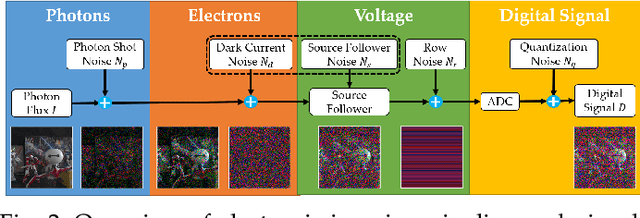
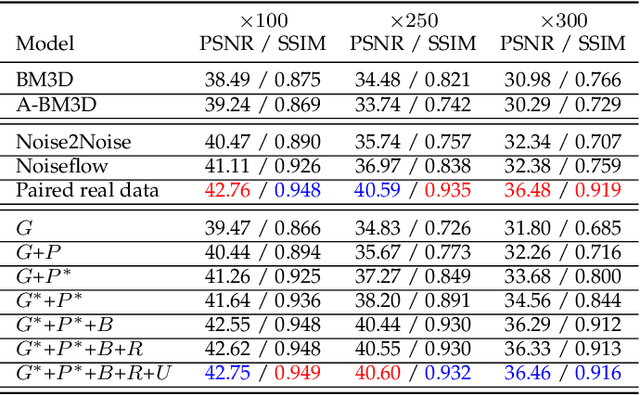
Enhancing the visibility in extreme low-light environments is a challenging task. Under nearly lightless condition, existing image denoising methods could easily break down due to significantly low SNR. In this paper, we systematically study the noise statistics in the imaging pipeline of CMOS photosensors, and formulate a comprehensive noise model that can accurately characterize the real noise structures. Our novel model considers the noise sources caused by digital camera electronics which are largely overlooked by existing methods yet have significant influence on raw measurement in the dark. It provides a way to decouple the intricate noise structure into different statistical distributions with physical interpretations. Moreover, our noise model can be used to synthesize realistic training data for learning-based low-light denoising algorithms. In this regard, although promising results have been shown recently with deep convolutional neural networks, the success heavily depends on abundant noisy clean image pairs for training, which are tremendously difficult to obtain in practice. Generalizing their trained models to images from new devices is also problematic. Extensive experiments on multiple low-light denoising datasets -- including a newly collected one in this work covering various devices -- show that a deep neural network trained with our proposed noise formation model can reach surprisingly-high accuracy. The results are on par with or sometimes even outperform training with paired real data, opening a new door to real-world extreme low-light photography.
Comparing Correspondences: Video Prediction with Correspondence-wise Losses
Apr 19, 2021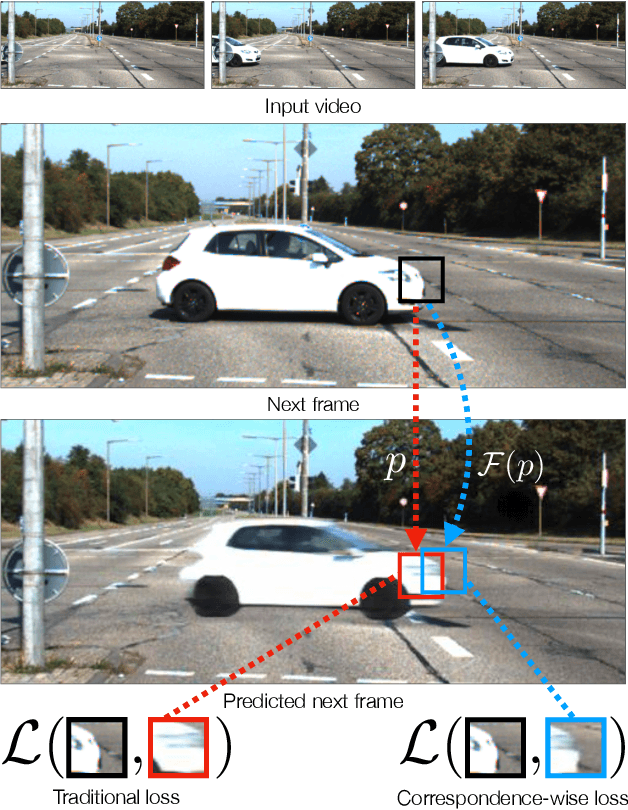
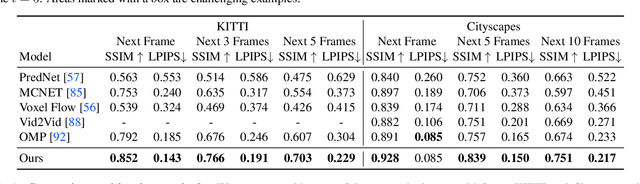
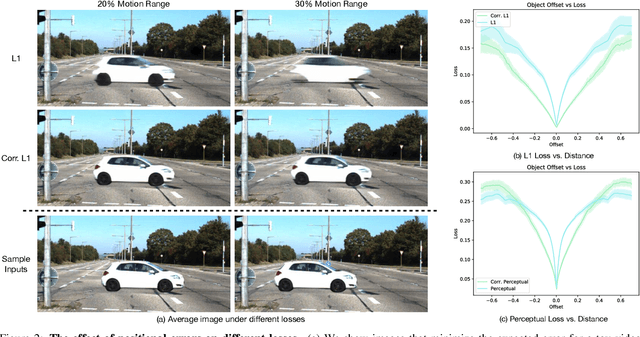
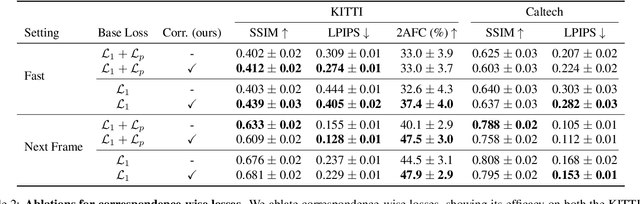
Today's image prediction methods struggle to change the locations of objects in a scene, producing blurry images that average over the many positions they might occupy. In this paper, we propose a simple change to existing image similarity metrics that makes them more robust to positional errors: we match the images using optical flow, then measure the visual similarity of corresponding pixels. This change leads to crisper and more perceptually accurate predictions, and can be used with any image prediction network. We apply our method to predicting future frames of a video, where it obtains strong performance with simple, off-the-shelf architectures.
SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021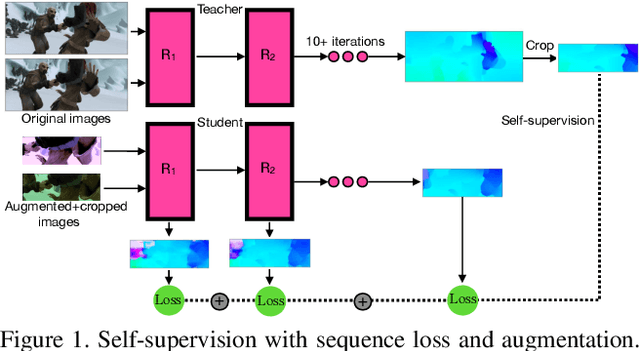
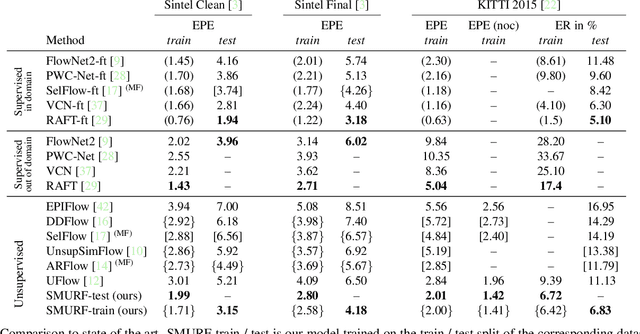
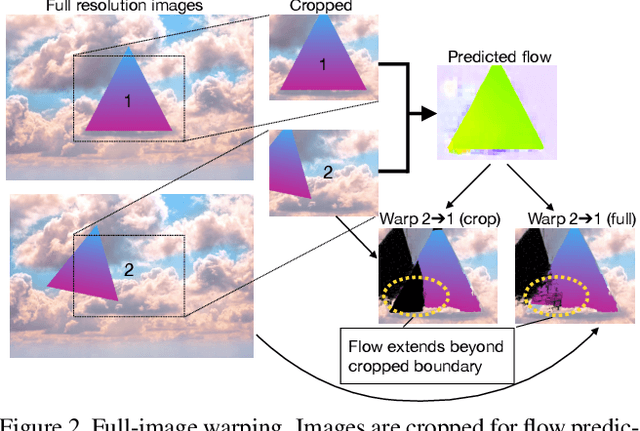
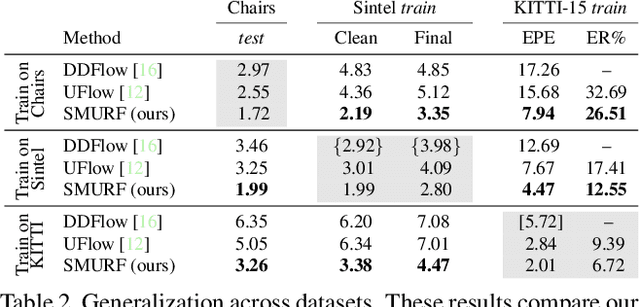
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.
Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation
Oct 02, 2019
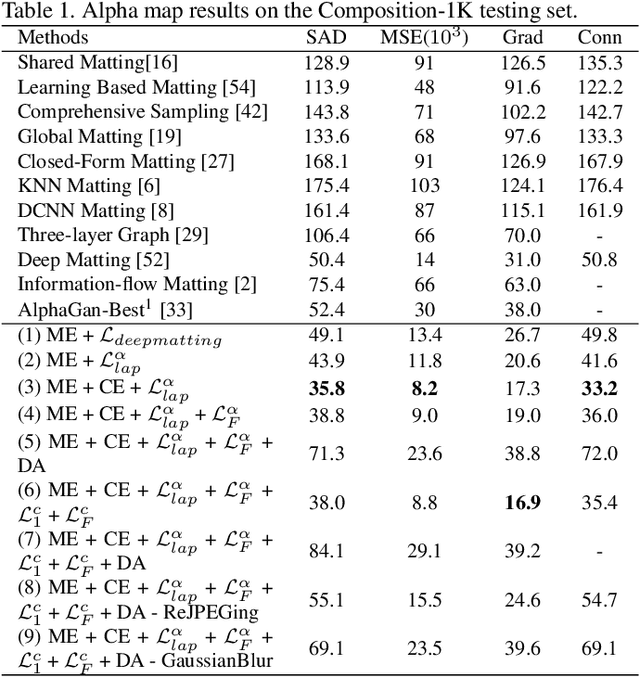
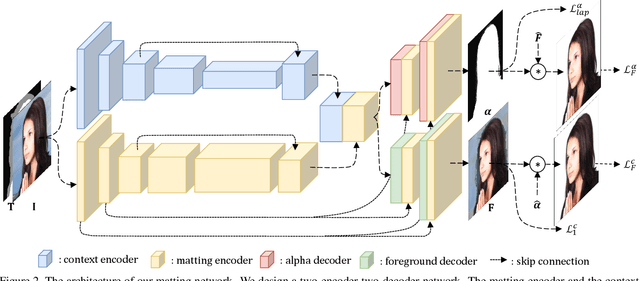
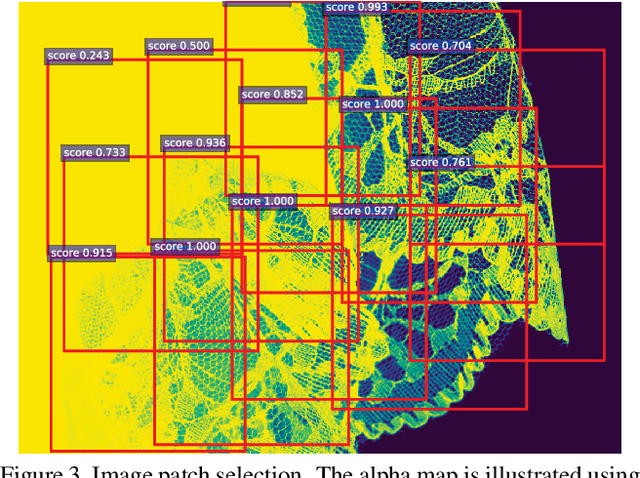
Natural image matting is an important problem in computer vision and graphics. It is an ill-posed problem when only an input image is available without any external information. While the recent deep learning approaches have shown promising results, they only estimate the alpha matte. This paper presents a context-aware natural image matting method for simultaneous foreground and alpha matte estimation. Our method employs two encoder networks to extract essential information for matting. Particularly, we use a matting encoder to learn local features and a context encoder to obtain more global context information. We concatenate the outputs from these two encoders and feed them into decoder networks to simultaneously estimate the foreground and alpha matte. To train this whole deep neural network, we employ both the standard Laplacian loss and the feature loss: the former helps to achieve high numerical performance while the latter leads to more perceptually plausible results. We also report several data augmentation strategies that greatly improve the network's generalization performance. Our qualitative and quantitative experiments show that our method enables high-quality matting for a single natural image. Our inference codes and models have been made publicly available at https://github.com/hqqxyy/Context-Aware-Matting.
InAugment: Improving Classifiers via Internal Augmentation
Apr 08, 2021
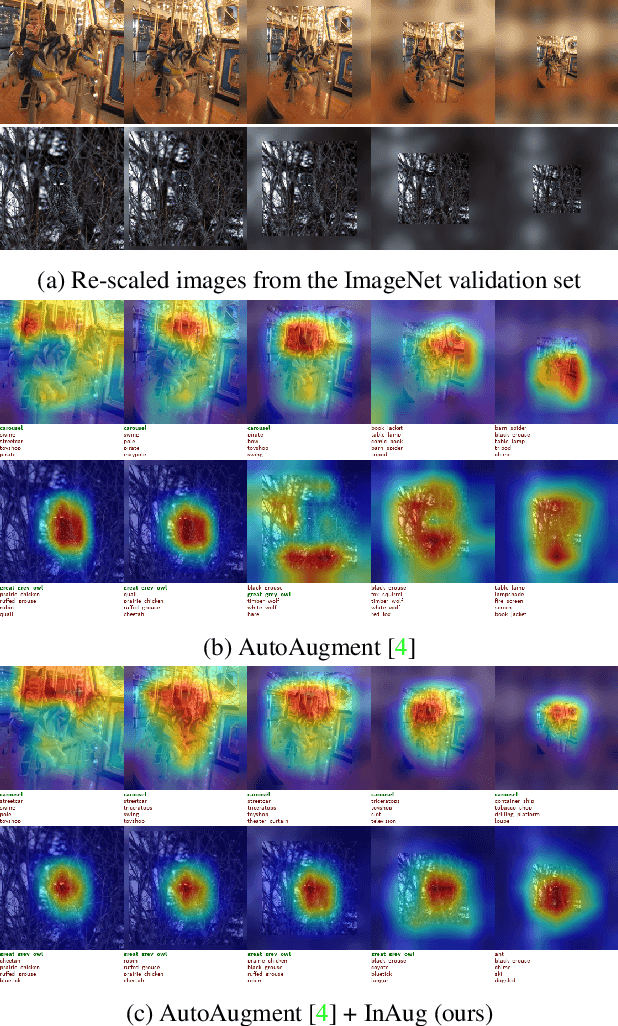

Image augmentation techniques apply transformation functions such as rotation, shearing, or color distortion on an input image. These augmentations were proven useful in improving neural networks' generalization ability. In this paper, we present a novel augmentation operation, InAugment, that exploits image internal statistics. The key idea is to copy patches from the image itself, apply augmentation operations on them, and paste them back at random positions on the same image. This method is simple and easy to implement and can be incorporated with existing augmentation techniques. We test InAugment on two popular datasets -- CIFAR and ImageNet. We show improvement over state-of-the-art augmentation techniques. Incorporating InAugment with Auto Augment yields a significant improvement over other augmentation techniques (e.g., +1% improvement over multiple architectures trained on the CIFAR dataset). We also demonstrate an increase for ResNet50 and EfficientNet-B3 top-1's accuracy on the ImageNet dataset compared to prior augmentation methods. Finally, our experiments suggest that training convolutional neural network using InAugment not only improves the model's accuracy and confidence but its performance on out-of-distribution images.
Spatially Attentive Output Layer for Image Classification
Apr 16, 2020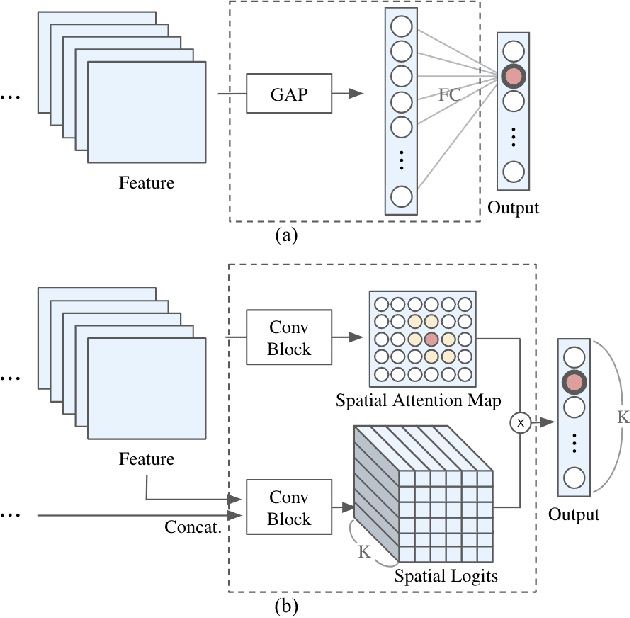
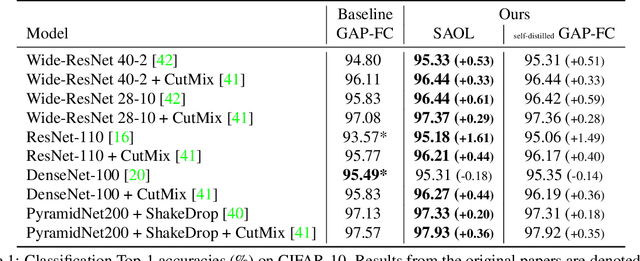
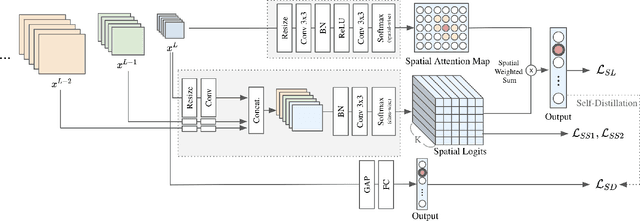
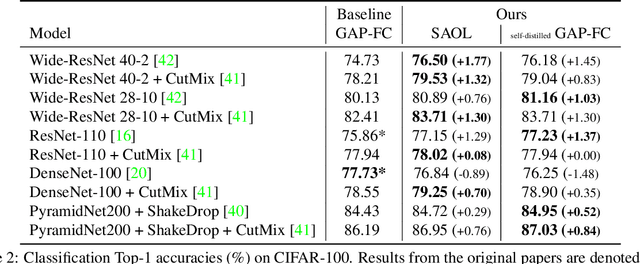
Most convolutional neural networks (CNNs) for image classification use a global average pooling (GAP) followed by a fully-connected (FC) layer for output logits. However, this spatial aggregation procedure inherently restricts the utilization of location-specific information at the output layer, although this spatial information can be beneficial for classification. In this paper, we propose a novel spatial output layer on top of the existing convolutional feature maps to explicitly exploit the location-specific output information. In specific, given the spatial feature maps, we replace the previous GAP-FC layer with a spatially attentive output layer (SAOL) by employing a attention mask on spatial logits. The proposed location-specific attention selectively aggregates spatial logits within a target region, which leads to not only the performance improvement but also spatially interpretable outputs. Moreover, the proposed SAOL also permits to fully exploit location-specific self-supervision as well as self-distillation to enhance the generalization ability during training. The proposed SAOL with self-supervision and self-distillation can be easily plugged into existing CNNs. Experimental results on various classification tasks with representative architectures show consistent performance improvements by SAOL at almost the same computational cost.
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
Sep 28, 2021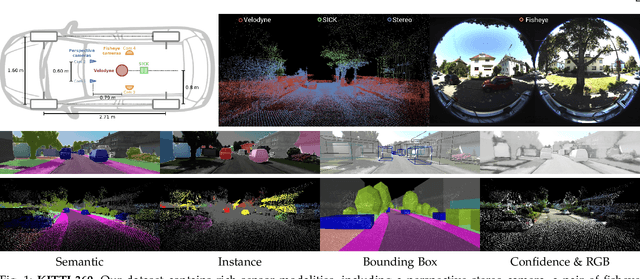
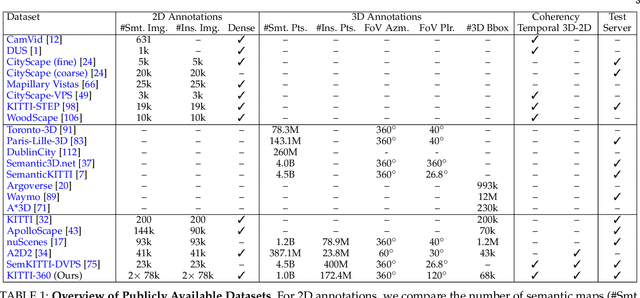
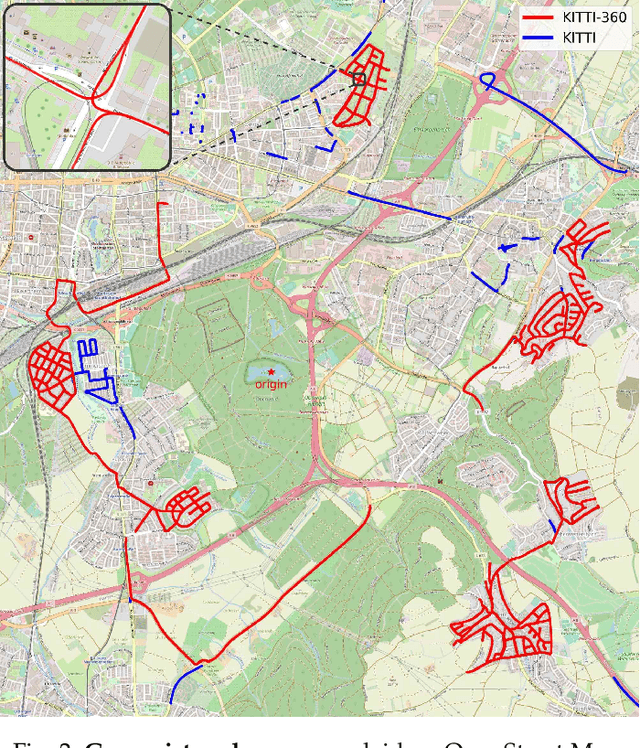
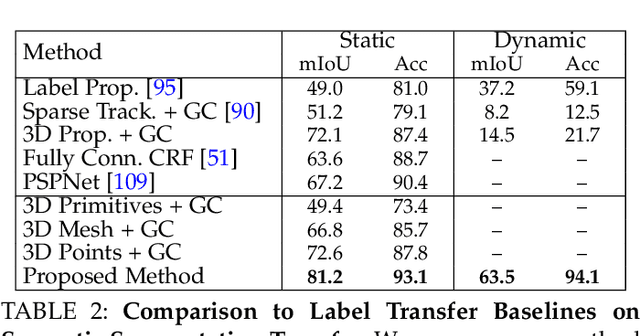
For the last few decades, several major subfields of artificial intelligence including computer vision, graphics, and robotics have progressed largely independently from each other. Recently, however, the community has realized that progress towards robust intelligent systems such as self-driving cars requires a concerted effort across the different fields. This motivated us to develop KITTI-360, successor of the popular KITTI dataset. KITTI-360 is a suburban driving dataset which comprises richer input modalities, comprehensive semantic instance annotations and accurate localization to facilitate research at the intersection of vision, graphics and robotics. For efficient annotation, we created a tool to label 3D scenes with bounding primitives and developed a model that transfers this information into the 2D image domain, resulting in over 150k semantic and instance annotated images and 1B annotated 3D points. Moreover, we established benchmarks and baselines for several tasks relevant to mobile perception, encompassing problems from computer vision, graphics, and robotics on the same dataset. KITTI-360 will enable progress at the intersection of these research areas and thus contributing towards solving one of our grand challenges: the development of fully autonomous self-driving systems.
Computing Spatial Image Convolutions for Event Cameras
Jan 14, 2019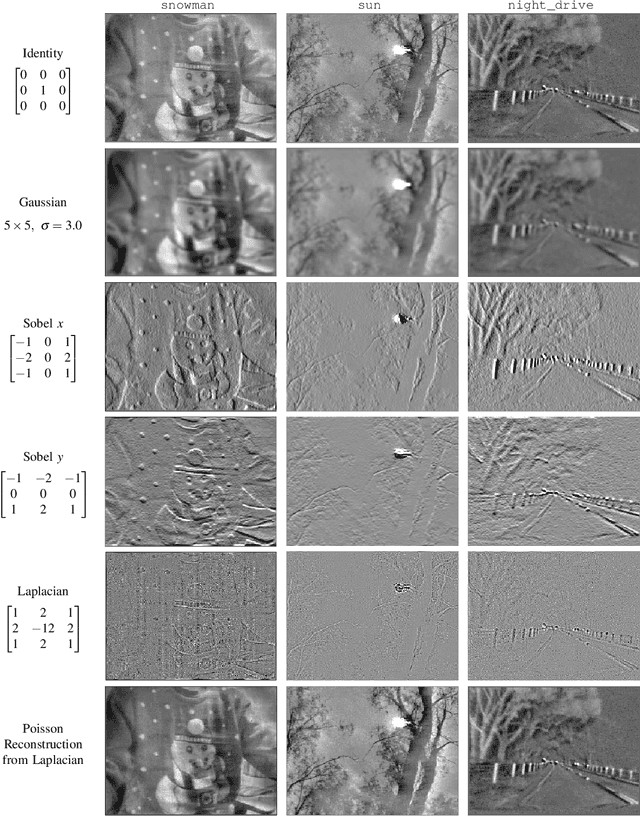


Spatial convolution is arguably the most fundamental of 2D image processing operations. Conventional spatial image convolution can only be applied to a conventional image, that is, an array of pixel values (or similar image representation) that are associated with a single instant in time. Event cameras have serial, asynchronous output with no natural notion of an image frame, and each event arrives with a different timestamp. In this paper, we propose a method to compute the convolution of a linear spatial kernel with the output of an event camera. The approach operates on the event stream output of the camera directly without synthesising pseudo-image frames as is common in the literature. The key idea is the introduction of an internal state that directly encodes the convolved image information, which is updated asynchronously as each event arrives from the camera. The state can be read-off as-often-as and whenever required for use in higher level vision algorithms for real-time robotic systems. We demonstrate the application of our method to corner detection, providing an implementation of a Harris corner-response 'state' that can be used in real-time for feature detection and tracking on robotic systems.
The First Airborne Experiment of Sparse Microwave Imaging: Prototype System Design and Result Analysis
Oct 20, 2021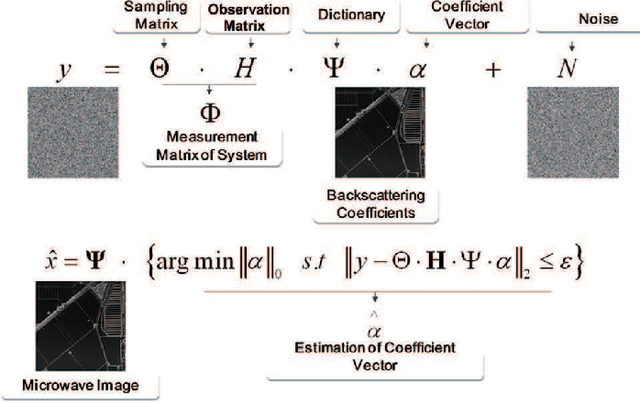
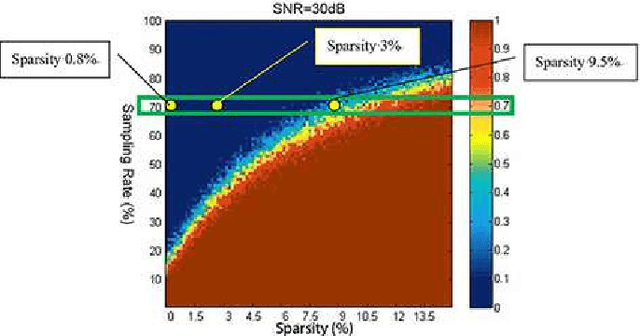


In this paper we report the first airborne experiments of sparse microwave imaging, conducted in September 2013 and May 2014, using our prototype sparse microwave imaging radar system. This is the first reported imaging radar system and airborne experiment that specially designed for sparse microwave imaging. Sparse microwave imaging is a novel concept of radar imaging, it is mainly the combination of traditional radar imaging technology and newly developed sparse signal processing theory, achieving benefits in both improving the imaging quality of current microwave imaging systems and designing optimized sparse microwave imaging radar system to reduce system sampling rate towards the sparse target scenes. During recent years, many researchers focus on related topics of sparse microwave imaging, but rarely few paid attention to prototype system design and experiment. We introduce our prototype sparse microwave imaging radar system, including its system design, hardware considerations and signal processing methods. Several design principles should be considered during the system designing, including the sampling scheme, antenna, SNR, waveform, resolution, etc. We select jittered sampling in azimuth and uniform sampling in range to balance the system complexity and performance. The imaging algorithm is accelerated $\ell_q$ regularization algorithm. To test the prototype radar system and verify the effectiveness of sparse microwave imaging framework, airborne experiments are carried out using our prototype system and we achieve the first sparse microwave image successfully. We analyze the imaging performance of prototype sparse microwave radar system with different sparsities, sampling rates, SNRs and sampling schemes, using three-dimensional phase transit diagram as the evaluation tool.
Filter Distribution Templates in Convolutional Networks for Image Classification Tasks
Apr 28, 2021
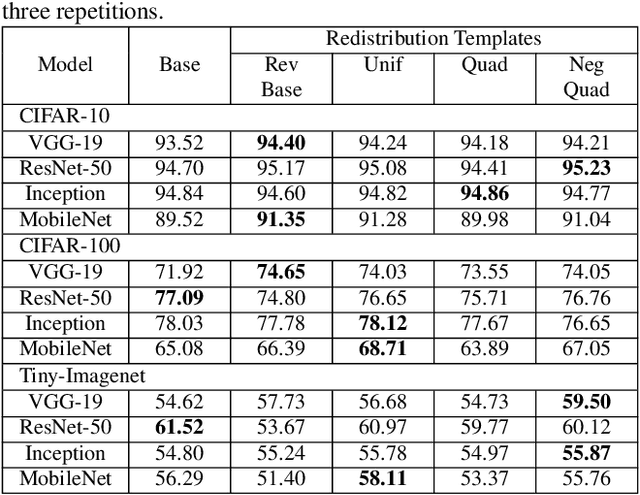
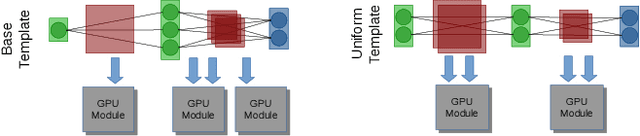
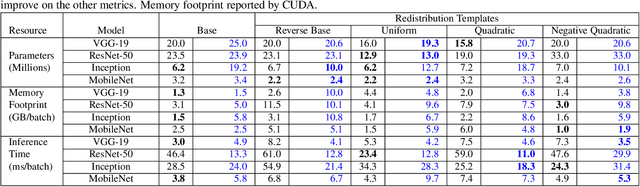
Neural network designers have reached progressive accuracy by increasing models depth, introducing new layer types and discovering new combinations of layers. A common element in many architectures is the distribution of the number of filters in each layer. Neural network models keep a pattern design of increasing filters in deeper layers such as those in LeNet, VGG, ResNet, MobileNet and even in automatic discovered architectures such as NASNet. It remains unknown if this pyramidal distribution of filters is the best for different tasks and constrains. In this work we present a series of modifications in the distribution of filters in four popular neural network models and their effects in accuracy and resource consumption. Results show that by applying this approach, some models improve up to 8.9% in accuracy showing reductions in parameters up to 54%.