 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fully Spiking Variational Autoencoder
Oct 05, 2021
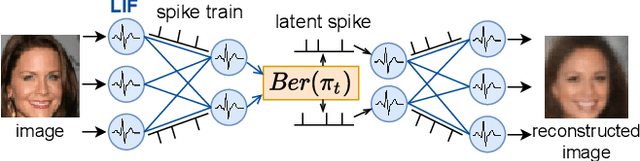
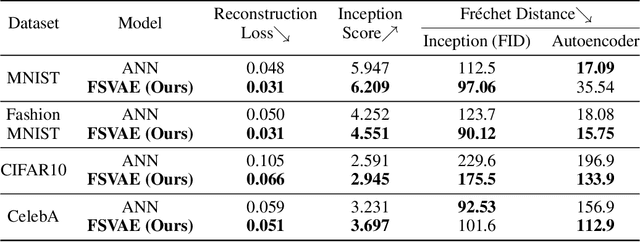
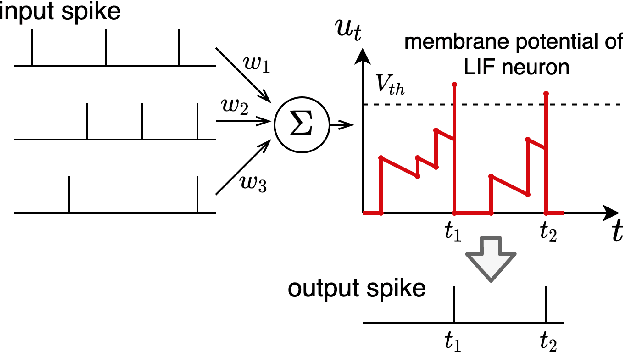

Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature. Therefore, SNNs are expected to have various applications, including as generative models being running on edge devices to create high-quality images. In this study, we build a variational autoencoder (VAE) with SNN to enable image generation. VAE is known for its stability among generative models; recently, its quality advanced. In vanilla VAE, the latent space is represented as a normal distribution, and floating-point calculations are required in sampling. However, this is not possible in SNNs because all features must be binary time series data. Therefore, we constructed the latent space with an autoregressive SNN model, and randomly selected samples from its output to sample the latent variables. This allows the latent variables to follow the Bernoulli process and allows variational learning. Thus, we build the Fully Spiking Variational Autoencoder where all modules are constructed with SNN. To the best of our knowledge, we are the first to build a VAE only with SNN layers. We experimented with several datasets, and confirmed that it can generate images with the same or better quality compared to conventional ANNs. The code is available at https://github.com/kamata1729/FullySpikingVAE
Instance-based Vision Transformer for Subtyping of Papillary Renal Cell Carcinoma in Histopathological Image
Jun 23, 2021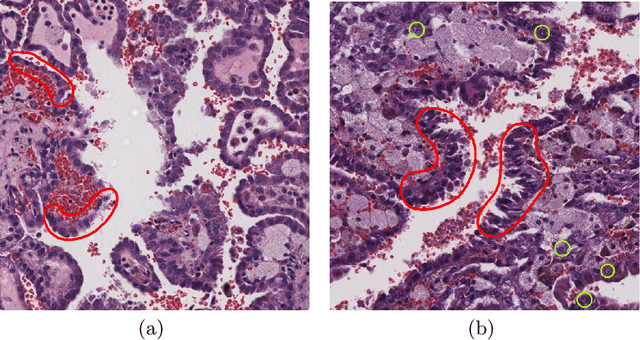
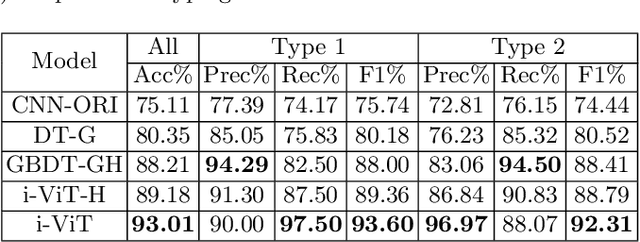
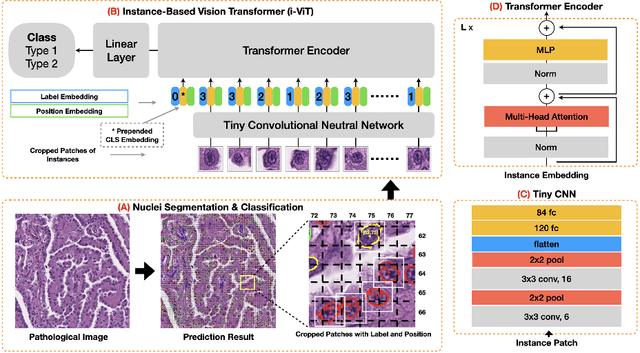
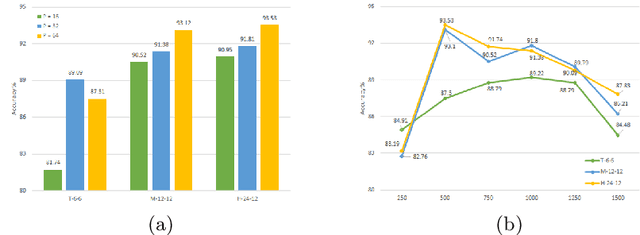
Histological subtype of papillary (p) renal cell carcinoma (RCC), type 1 vs. type 2, is an essential prognostic factor. The two subtypes of pRCC have a similar pattern, i.e., the papillary architecture, yet some subtle differences, including cellular and cell-layer level patterns. However, the cellular and cell-layer level patterns almost cannot be captured by existing CNN-based models in large-size histopathological images, which brings obstacles to directly applying these models to such a fine-grained classification task. This paper proposes a novel instance-based Vision Transformer (i-ViT) to learn robust representations of histopathological images for the pRCC subtyping task by extracting finer features from instance patches (by cropping around segmented nuclei and assigning predicted grades). The proposed i-ViT takes top-K instances as input and aggregates them for capturing both the cellular and cell-layer level patterns by a position-embedding layer, a grade-embedding layer, and a multi-head multi-layer self-attention module. To evaluate the performance of the proposed framework, experienced pathologists are invited to selected 1162 regions of interest from 171 whole slide images of type 1 and type 2 pRCC. Experimental results show that the proposed method achieves better performance than existing CNN-based models with a significant margin.
Automatic Polyp Segmentation via Multi-scale Subtraction Network
Aug 11, 2021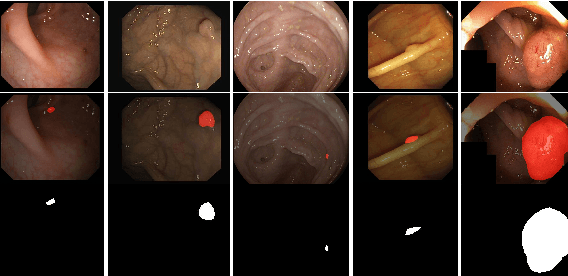
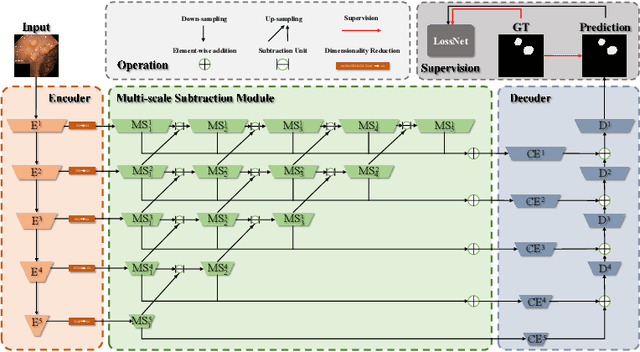
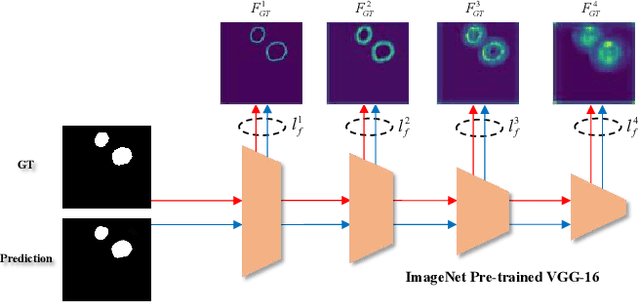
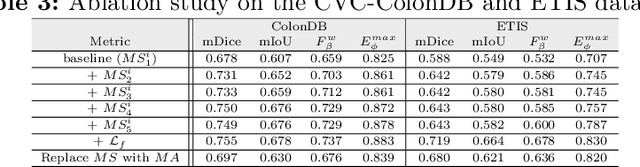
More than 90\% of colorectal cancer is gradually transformed from colorectal polyps. In clinical practice, precise polyp segmentation provides important information in the early detection of colorectal cancer. Therefore, automatic polyp segmentation techniques are of great importance for both patients and doctors. Most existing methods are based on U-shape structure and use element-wise addition or concatenation to fuse different level features progressively in decoder. However, both the two operations easily generate plenty of redundant information, which will weaken the complementarity between different level features, resulting in inaccurate localization and blurred edges of polyps. To address this challenge, we propose a multi-scale subtraction network (MSNet) to segment polyp from colonoscopy image. Specifically, we first design a subtraction unit (SU) to produce the difference features between adjacent levels in encoder. Then, we pyramidally equip the SUs at different levels with varying receptive fields, thereby obtaining rich multi-scale difference information. In addition, we build a training-free network "LossNet" to comprehensively supervise the polyp-aware features from bottom layer to top layer, which drives the MSNet to capture the detailed and structural cues simultaneously. Extensive experiments on five benchmark datasets demonstrate that our MSNet performs favorably against most state-of-the-art methods under different evaluation metrics. Furthermore, MSNet runs at a real-time speed of $\sim$70fps when processing a $352 \times 352$ image. The source code will be publicly available at \url{https://github.com/Xiaoqi-Zhao-DLUT/MSNet}. \keywords{Colorectal Cancer \and Automatic Polyp Segmentation \and Subtraction \and LossNet.}
EfficientCLIP: Efficient Cross-Modal Pre-training by Ensemble Confident Learning and Language Modeling
Sep 10, 2021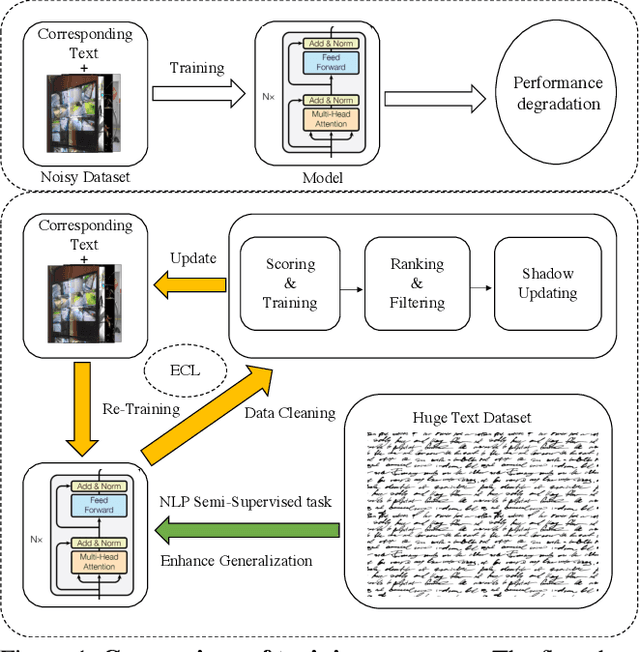
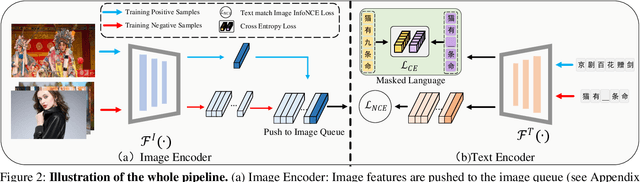
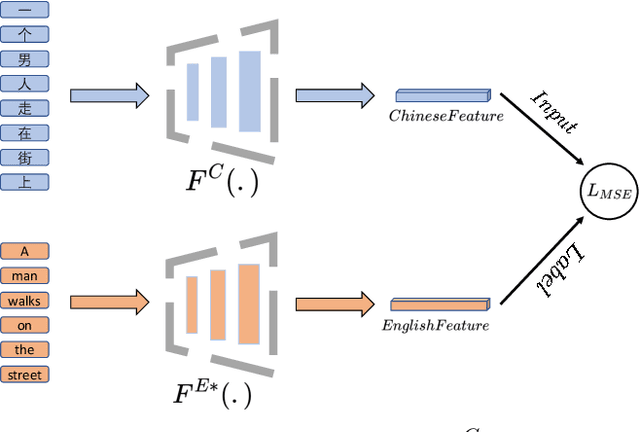
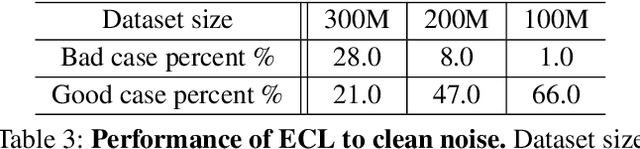
While large scale pre-training has achieved great achievements in bridging the gap between vision and language, it still faces several challenges. First, the cost for pre-training is expensive. Second, there is no efficient way to handle the data noise which degrades model performance. Third, previous methods only leverage limited image-text paired data, while ignoring richer single-modal data, which may result in poor generalization to single-modal downstream tasks. In this work, we propose an EfficientCLIP method via Ensemble Confident Learning to obtain a less noisy data subset. Extra rich non-paired single-modal text data is used for boosting the generalization of text branch. We achieve the state-of-the-art performance on Chinese cross-modal retrieval tasks with only 1/10 training resources compared to CLIP and WenLan, while showing excellent generalization to single-modal tasks, including text retrieval and text classification.
Time Series to Images: Monitoring the Condition of Industrial Assets with Deep Learning Image Processing Algorithms
May 19, 2020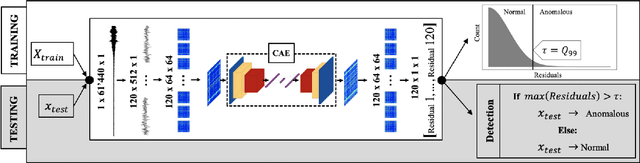
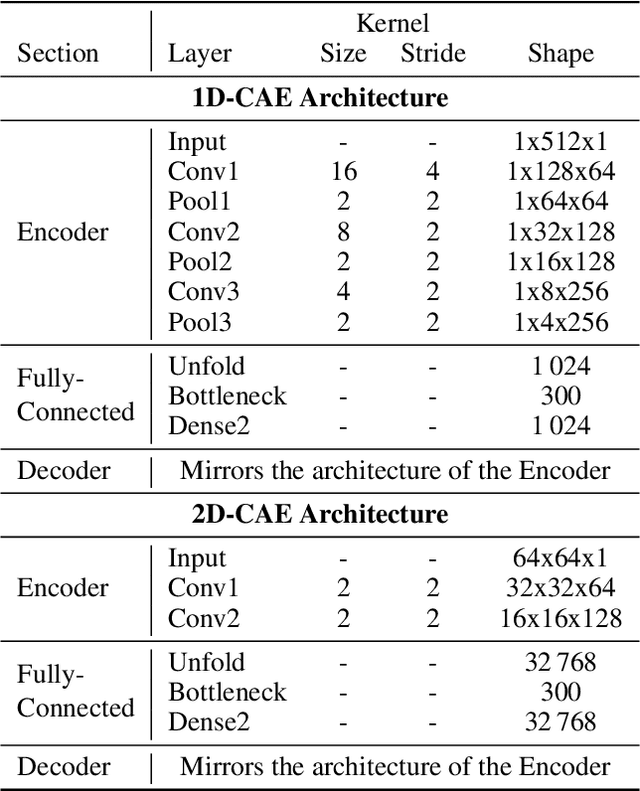
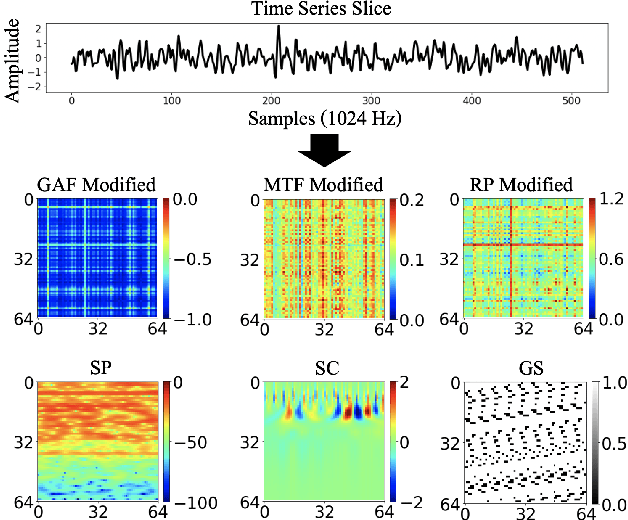
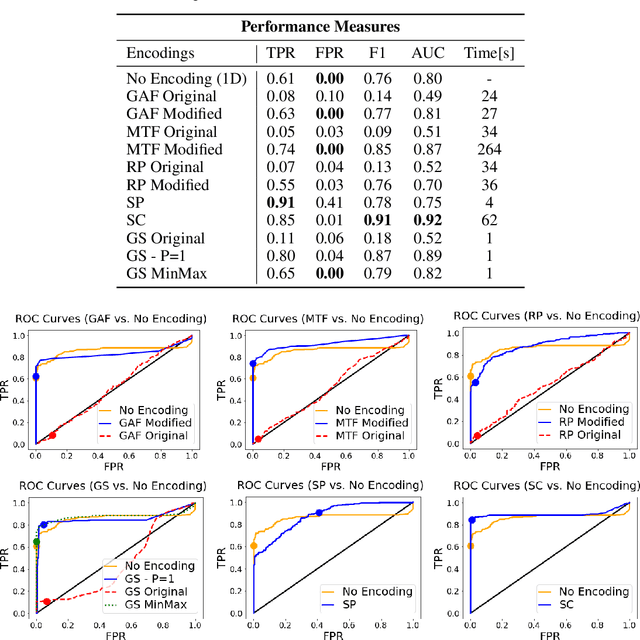
The ability to detect anomalies in time series is considered as highly valuable within plenty of application domains. The sequential nature of time series objects is responsible for an additional feature complexity, ultimately requiring specialized approaches for solving the task. Essential characteristics of time series, laying outside the time domain, are often difficult to capture with state-of-the-art anomaly detection methods, when no transformations on the time series have been applied. Inspired by the success of deep learning methods in computer vision, several studies have proposed to transform time-series into image-like representations, leading to very promising results. However, most of the previous studies implementing time-series to image encodings have focused on the supervised classification. The application to unsupervised anomaly detection tasks has been limited. The paper has the following contributions: First, we evaluate the application of six time-series to image encodings to DL algorithms: Gramian Angular Field, Markov Transition Field, Recurrence Plot, Grey Scale Encoding, Spectrogram and Scalogram. Second, we propose modifications of the original encoding definitions, to make them more robust to the variability in large datasets. And third, we provide a comprehensive comparison between using the raw time series directly and the different encodings, with and without the proposed improvements. The comparison is performed on a dataset collected and released by Airbus, containing highly complex vibration measurements from real helicopters flight tests. The different encodings provide competitive results for anomaly detection.
Multi-task deep CNN model for no-reference image quality assessment on smartphone camera photos
Aug 27, 2020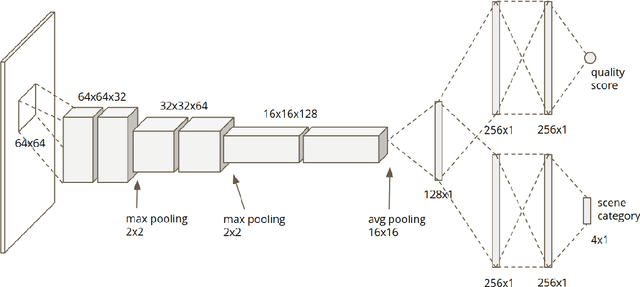
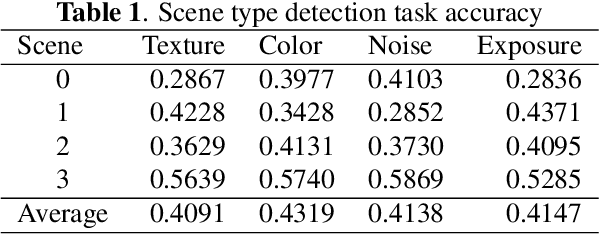
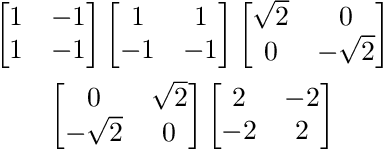
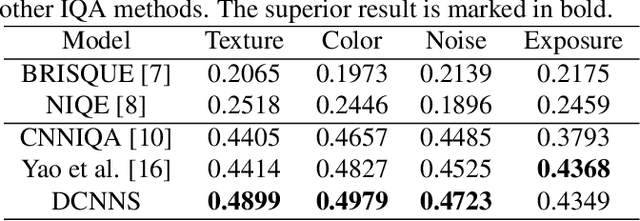
Smartphone is the most successful consumer electronic product in today's mobile social network era. The smartphone camera quality and its image post-processing capability is the dominant factor that impacts consumer's buying decision. However, the quality evaluation of photos taken from smartphones remains a labor-intensive work and relies on professional photographers and experts. As an extension of the prior CNN-based NR-IQA approach, we propose a multi-task deep CNN model with scene type detection as an auxiliary task. With the shared model parameters in the convolution layer, the learned feature maps could become more scene-relevant and enhance the performance. The evaluation result shows improved SROCC performance compared to traditional NR-IQA methods and single task CNN-based models.
Multi-Kernel Filtering: An Extension of Bilateral Filtering Using Image Context
Aug 17, 2019
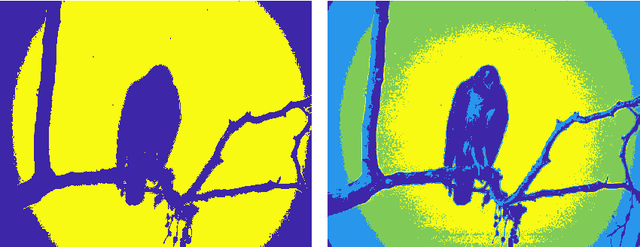
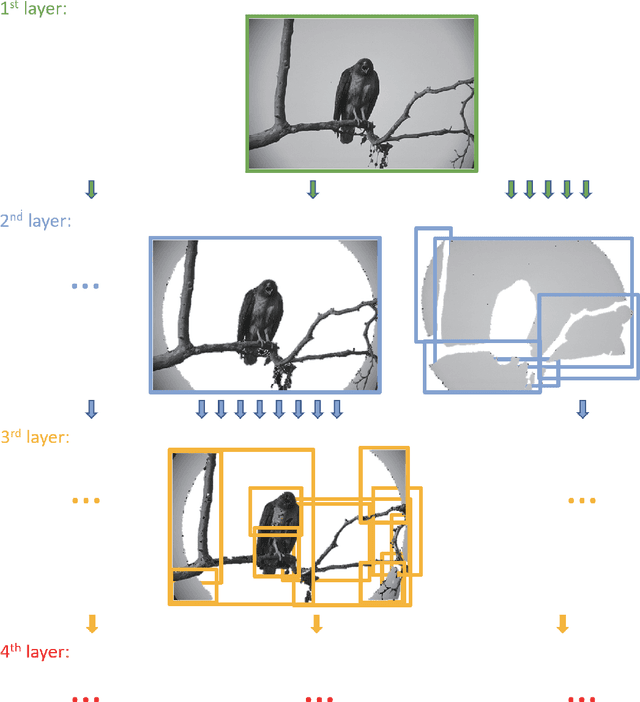
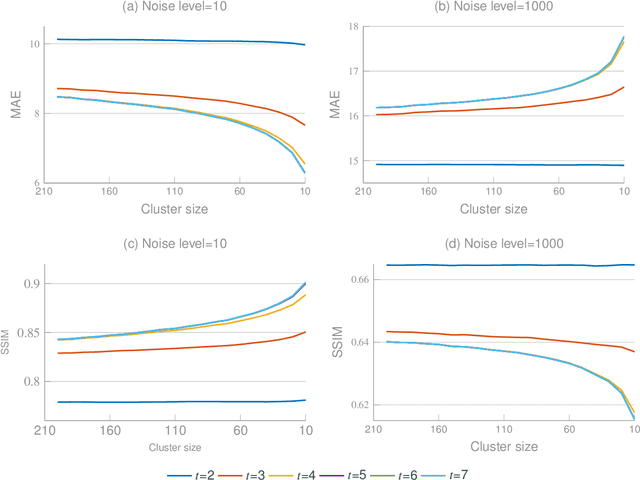
Bilateral filtering is one of the most classical denoising filters. However, the parameter of its range kernel needs to be initialized manually, which hampers its adaptivity across images with different characteristics. For coping with image variation (e.g., changeable signal-to-noise ratio and spatially-varying noise), it is necessary to adapt the kernel to specific image characteristics automatically. In this paper, we propose multi-kernel filter (MKF) inspired by adaptive mechanisms of human vision. We first design a hierarchically clustering algorithm to generate a hierarchy of large to small coherent image patches, organized as a cluster tree, so that multi-scale represent an image. One leaf cluster and two corresponding predecessor clusters are used to generate one of a number of range kernels that are capable of catering to image variation. We evaluate MKF on two public datasets, BSD$300$ and Phantom$\alpha$s. Extensive experimental results show that MKF outperforms various state-of-the-art filters on both mean absolute error and structural similarity.
Multi-level Metric Learning for Few-shot Image Recognition
Apr 12, 2021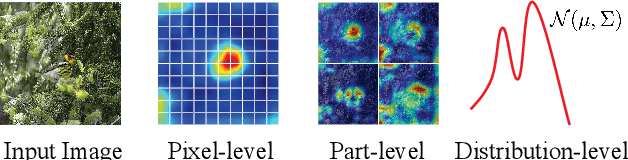
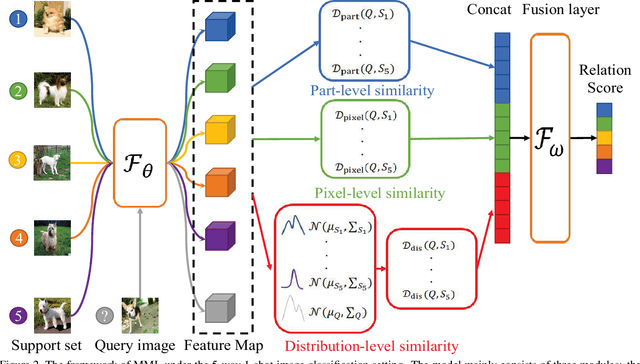
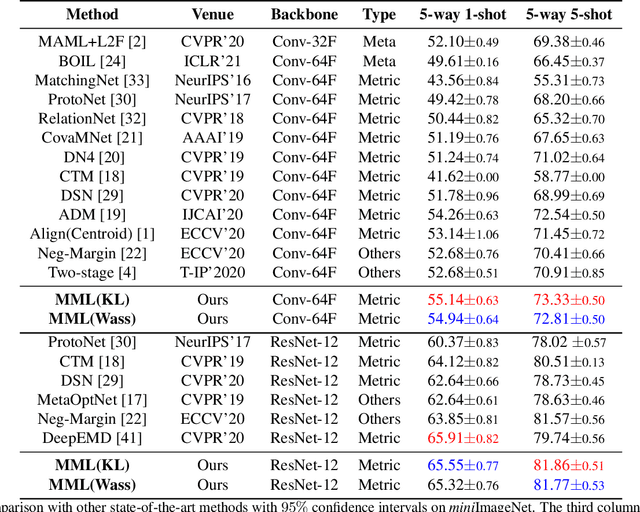
Few-shot learning is devoted to training a model on few samples. Recently, the method based on local descriptor metric-learning has achieved great performance. Most of these approaches learn a model based on a pixel-level metric. However, such works can only measure the relations between them on a single level, which is not comprehensive and effective. We argue that if query images can simultaneously be well classified via three distinct level similarity metrics, the query images within a class can be more tightly distributed in a smaller feature space, generating more discriminative feature maps. Motivated by this, we propose a novel Multi-level Metric Learning (MML) method for few-shot learning, which not only calculates the pixel-level similarity but also considers the similarity of part-level features and the similarity of distributions. First, we use a feature extractor to get the feature maps of images. Second, a multi-level metric module is proposed to calculate the part-level, pixel-level, and distribution-level similarities simultaneously. Specifically, the distribution-level similarity metric calculates the distribution distance (i.e., Wasserstein distance, Kullback-Leibler divergence) between query images and the support set, the pixel-level, and the part-level metric calculates the pixel-level and part-level similarities respectively. Finally, the fusion layer fuses three kinds of relation scores to obtain the final similarity score. Extensive experiments on popular benchmarks demonstrate that the MML method significantly outperforms the current state-of-the-art methods.
Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Sep 28, 2021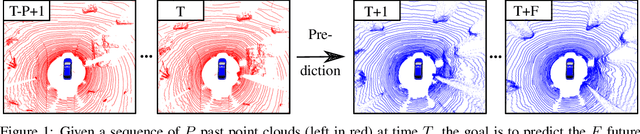
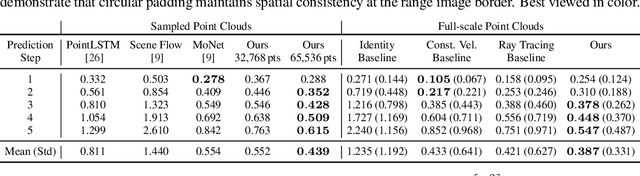
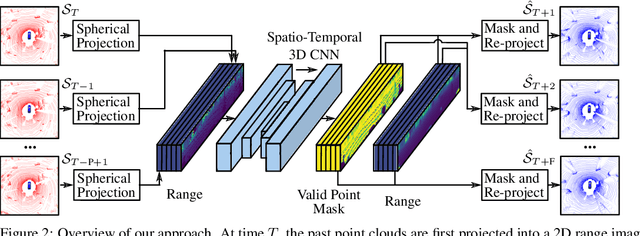
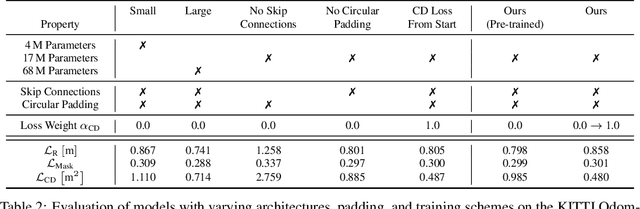
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.
Adversarial Attacks on Black Box Video Classifiers: Leveraging the Power of Geometric Transformations
Oct 05, 2021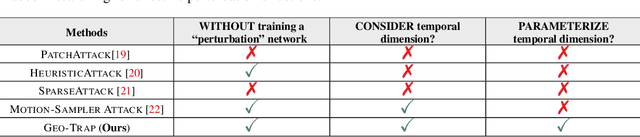
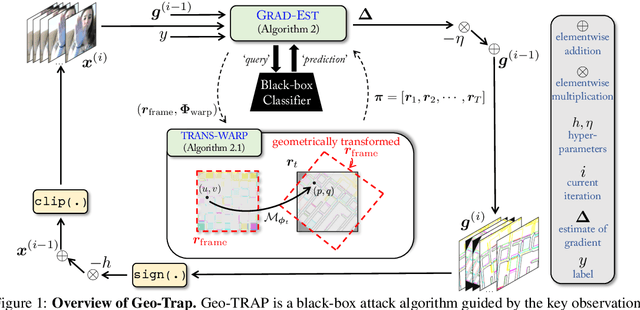
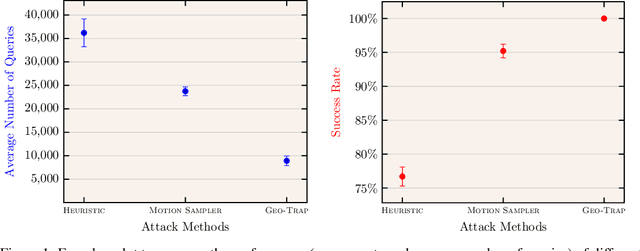
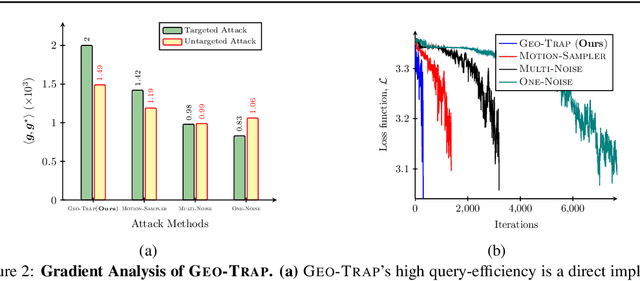
When compared to the image classification models, black-box adversarial attacks against video classification models have been largely understudied. This could be possible because, with video, the temporal dimension poses significant additional challenges in gradient estimation. Query-efficient black-box attacks rely on effectively estimated gradients towards maximizing the probability of misclassifying the target video. In this work, we demonstrate that such effective gradients can be searched for by parameterizing the temporal structure of the search space with geometric transformations. Specifically, we design a novel iterative algorithm Geometric TRAnsformed Perturbations (GEO-TRAP), for attacking video classification models. GEO-TRAP employs standard geometric transformation operations to reduce the search space for effective gradients into searching for a small group of parameters that define these operations. This group of parameters describes the geometric progression of gradients, resulting in a reduced and structured search space. Our algorithm inherently leads to successful perturbations with surprisingly few queries. For example, adversarial examples generated from GEO-TRAP have better attack success rates with ~73.55% fewer queries compared to the state-of-the-art method for video adversarial attacks on the widely used Jester dataset. Overall, our algorithm exposes vulnerabilities of diverse video classification models and achieves new state-of-the-art results under black-box settings on two large datasets.