 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Oracle inequalities for image denoising with total variation regularization
Dec 14, 2019
We derive oracle results for discrete image denoising with a total variation penalty. We consider the least squares estimator with a penalty on the $\ell^1$-norm of the total discrete derivative of the image. This estimator falls into the class of analysis estimators. A bound on the effective sparsity by means of an interpolating matrix allows us to obtain oracle inequalities with fast rates. The bound is an extension of the bound by Ortelli and van de Geer [2019c] to the two-dimensional case. We also present an oracle inequality with slow rates, which matches, up to a log-term, the rate obtained for the same estimator by Mammen and van de Geer [1997]. The key ingredient for our results are the projection arguments to bound the empirical process due to Dalalyan et al. [2017].
Linearized Multi-Sampling for Differentiable Image Transformation
Jan 22, 2019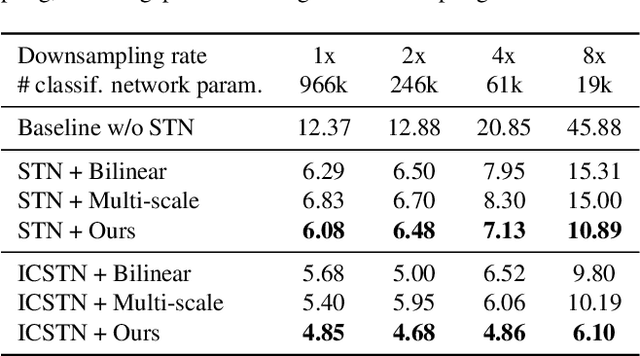
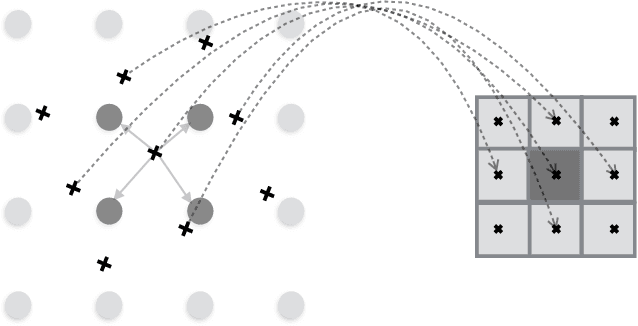
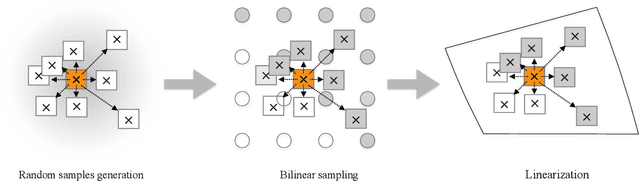
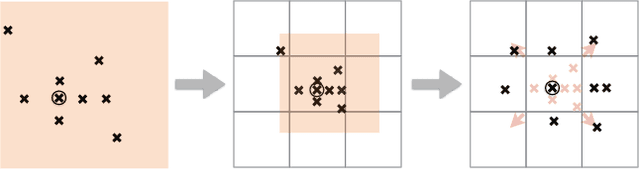
We propose a novel image sampling method for differentiable image transformation in deep neural networks. The sampling schemes currently used in deep learning, such as Spatial Transformer Networks, rely on bilinear interpolation, which performs poorly under severe scale changes, and more importantly, results in poor gradient propagation. This is due to their strict reliance on direct neighbors. Instead, we propose to generate random auxiliary samples in the vicinity of each pixel in the sampled image, and create a linear approximation using their intensity values. We then use this approximation as a differentiable formula for the transformed image. However, we observe that these auxiliary samples may collapse to a single pixel under severe image transformations, and propose to address it by adding constraints to the distance between the center pixel and the auxiliary samples. We demonstrate that our approach produces more representative gradients with a wider basin of convergence for image alignment, which leads to considerable performance improvements when training networks for image registration and classification tasks, particularly under large downsampling.
Neural Dubber: Dubbing for Silent Videos According to Scripts
Oct 15, 2021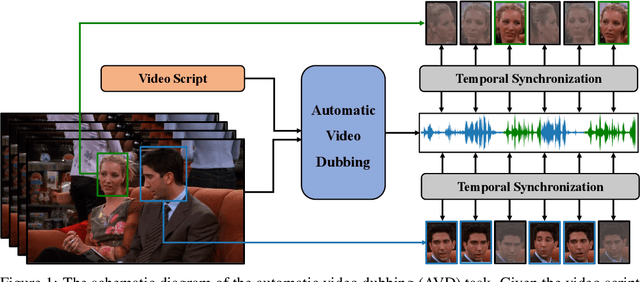
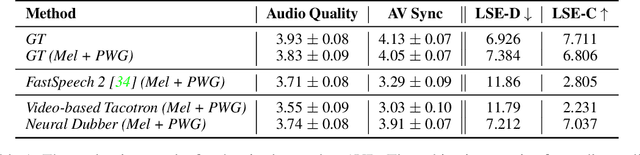
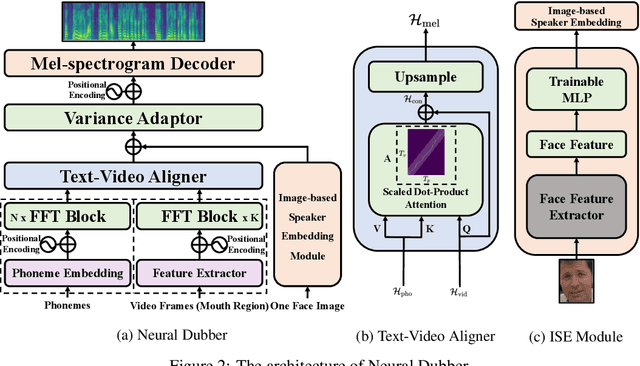
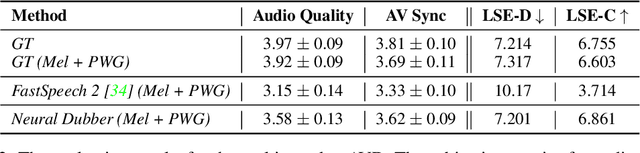
Dubbing is a post-production process of re-recording actors' dialogues, which is extensively used in filmmaking and video production. It is usually performed manually by professional voice actors who read lines with proper prosody, and in synchronization with the pre-recorded videos. In this work, we propose Neural Dubber, the first neural network model to solve a novel automatic video dubbing (AVD) task: synthesizing human speech synchronized with the given silent video from the text. Neural Dubber is a multi-modal text-to-speech (TTS) model that utilizes the lip movement in the video to control the prosody of the generated speech. Furthermore, an image-based speaker embedding (ISE) module is developed for the multi-speaker setting, which enables Neural Dubber to generate speech with a reasonable timbre according to the speaker's face. Experiments on the chemistry lecture single-speaker dataset and LRS2 multi-speaker dataset show that Neural Dubber can generate speech audios on par with state-of-the-art TTS models in terms of speech quality. Most importantly, both qualitative and quantitative evaluations show that Neural Dubber can control the prosody of synthesized speech by the video, and generate high-fidelity speech temporally synchronized with the video.
Guiding Visual Question Generation
Oct 15, 2021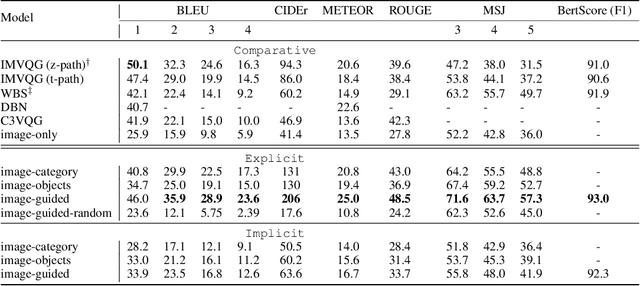
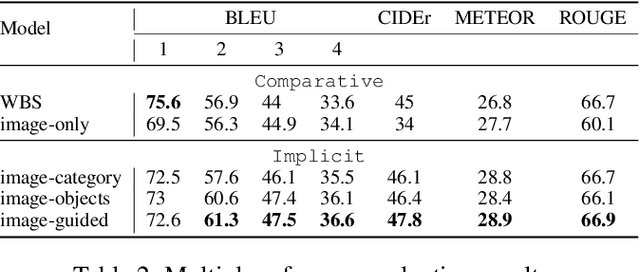


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.
Scalable Data Balancing for Unlabeled Satellite Imagery
Jul 07, 2021



Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.
Progressive Retinex: Mutually Reinforced Illumination-Noise Perception Network for Low Light Image Enhancement
Nov 26, 2019Contrast enhancement and noise removal are coupled problems for low-light image enhancement. The existing Retinex based methods do not take the coupling relation into consideration, resulting in under or over-smoothing of the enhanced images. To address this issue, this paper presents a novel progressive Retinex framework, in which illumination and noise of low-light image are perceived in a mutually reinforced manner, leading to noise reduction low-light enhancement results. Specifically, two fully pointwise convolutional neural networks are devised to model the statistical regularities of ambient light and image noise respectively, and to leverage them as constraints to facilitate the mutual learning process. The proposed method not only suppresses the interference caused by the ambiguity between tiny textures and image noises, but also greatly improves the computational efficiency. Moreover, to solve the problem of insufficient training data, we propose an image synthesis strategy based on camera imaging model, which generates color images corrupted by illumination-dependent noises. Experimental results on both synthetic and real low-light images demonstrate the superiority of our proposed approaches against the State-Of-The-Art (SOTA) low-light enhancement methods.
Styleformer: Transformer based Generative Adversarial Networks with Style Vector
Jun 13, 2021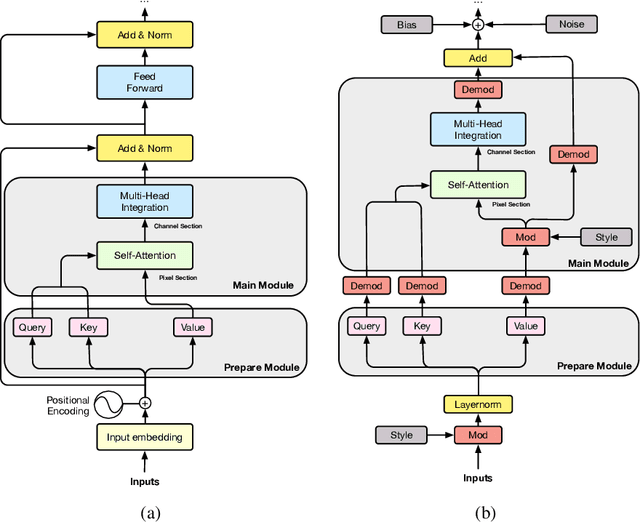
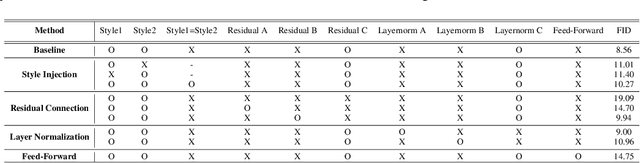
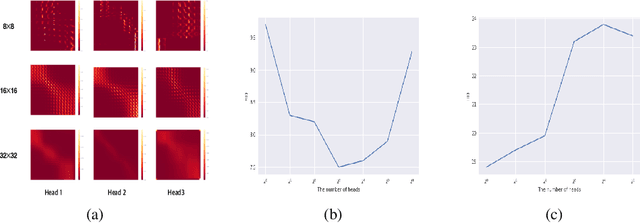

We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 20.11, IS 10.16, and FID 3.66, respectively on STL-10 and CelebA. We release our code at https://github.com/Jeeseung-Park/Styleformer.
Towards Fast Region Adaptive Ultrasound Beamformer for Plane Wave Imaging Using Convolutional Neural Networks
Jun 13, 2021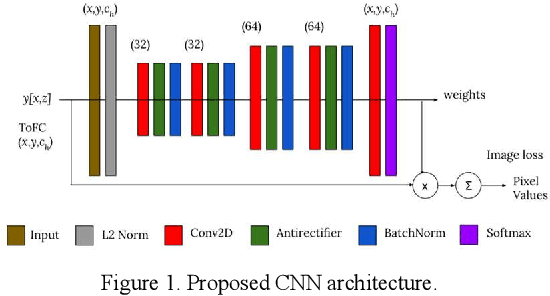

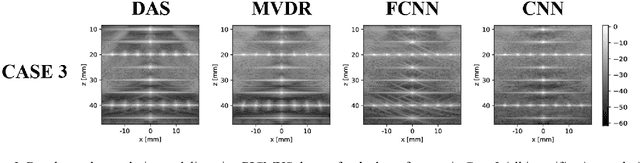
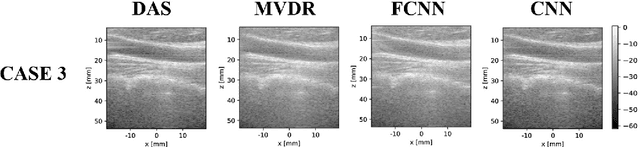
Automatic learning algorithms for improving the image quality of diagnostic B-mode ultrasound (US) images have been gaining popularity in the recent past. In this work, a novel convolutional neural network (CNN) is trained using time of flight corrected in-vivo receiver data of plane wave transmit to produce corresponding high-quality minimum variance distortion less response (MVDR) beamformed image. A comprehensive performance comparison in terms of qualitative and quantitative measures for fully connected neural network (FCNN), the proposed CNN architecture, MVDR and Delay and Sum (DAS) using the dataset from Plane wave Imaging Challenge in Ultrasound (PICMUS) is also reported in this work. The CNN architecture could leverage the spatial information and will be more region adaptive during the beamforming process. This is evident from the improvement seen over the baseline FCNN approach and conventional MVDR beamformer, both in resolution and contrast with an improvement of 6 dB in CNR using only zero-angle transmission over the baseline. With the observed reduction in the requirement of number of angles to produce similar image metrics would prove advantageous in providing a possibility for higher frame rates.
Toward Efficient and Robust Multiple Camera Visual-inertial Odometry
Sep 24, 2021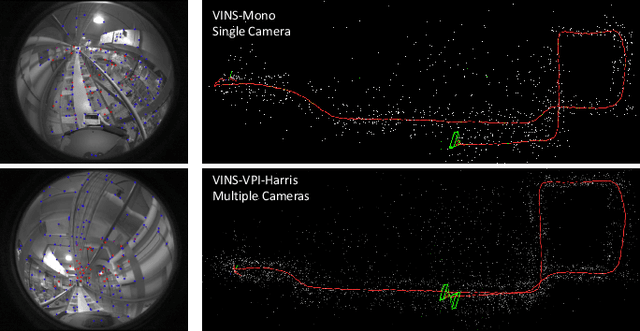
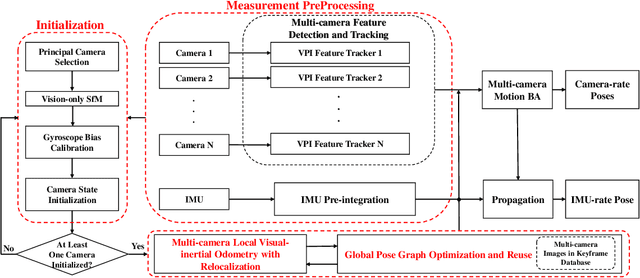
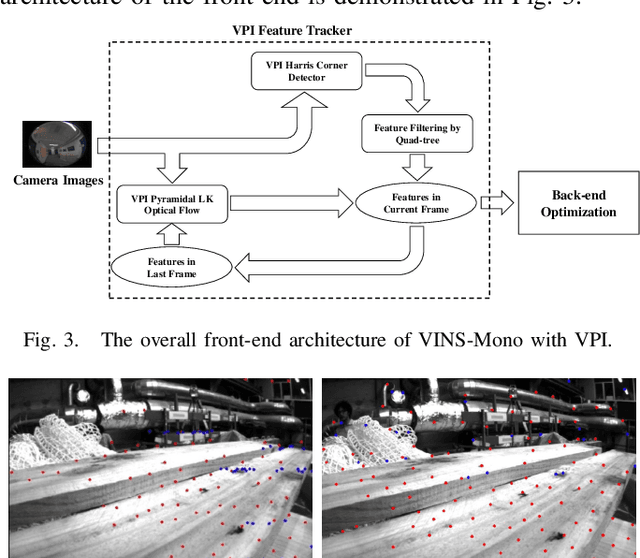
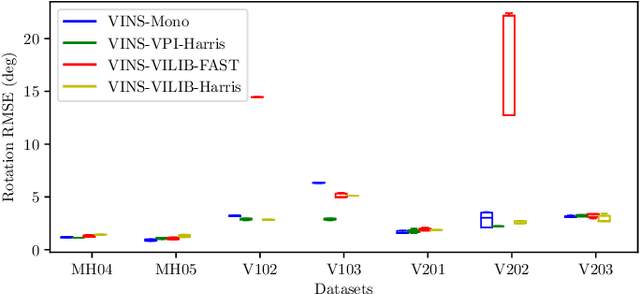
Efficiency and robustness are the essential criteria for the visual-inertial odometry (VIO) system. To process massive visual data, the high cost on CPU resources and computation latency limits VIO's possibility in integration with other applications. Recently, the powerful embedded GPUs have great potentials to improve the front-end image processing capability. Meanwhile, multi-camera systems can increase the visual constraints for back-end optimization. Inspired by these insights, we incorporate the GPU-enhanced algorithms in the field of VIO and thus propose a new front-end with NVIDIA Vision Programming Interface (VPI). This new front-end then enables multi-camera VIO feature association and provides more stable back-end pose optimization. Experiments with our new front-end on monocular datasets show the CPU resource occupation rate and computational latency are reduced by 40.4% and 50.6% without losing accuracy compared with the original VIO. The multi-camera system shows a higher VIO initialization success rate and better robustness overall state estimation.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021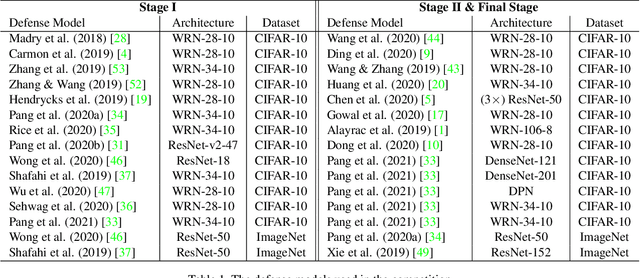
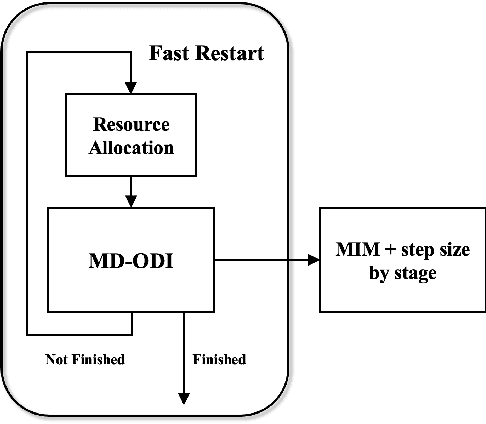
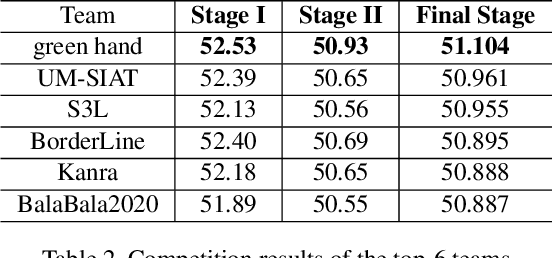
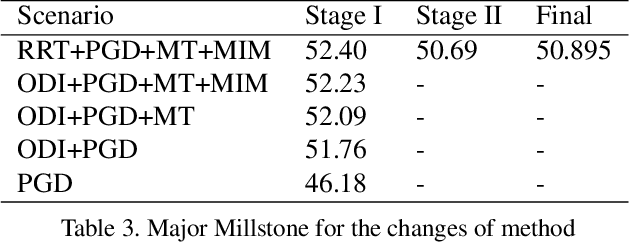
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.