 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Styleformer: Transformer based Generative Adversarial Networks with Style Vector
Jun 13, 2021
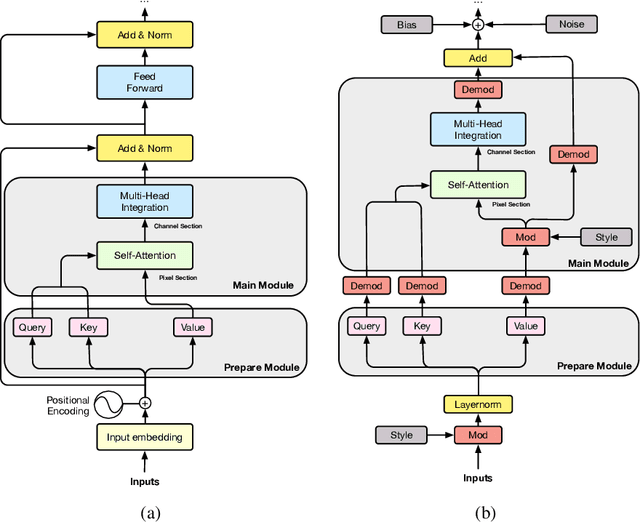
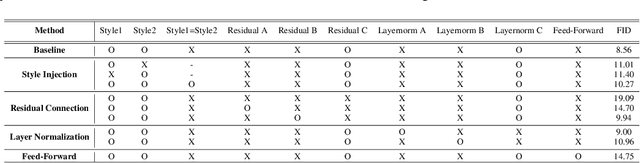
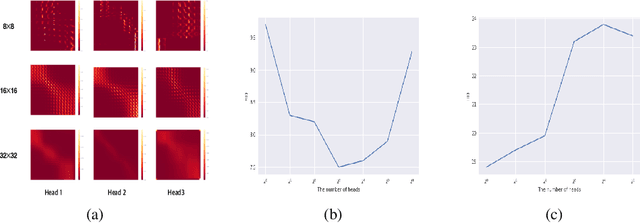

We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 20.11, IS 10.16, and FID 3.66, respectively on STL-10 and CelebA. We release our code at https://github.com/Jeeseung-Park/Styleformer.
On Circuit-based Hybrid Quantum Neural Networks for Remote Sensing Imagery Classification
Sep 20, 2021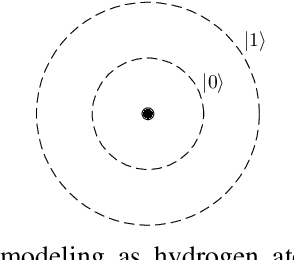

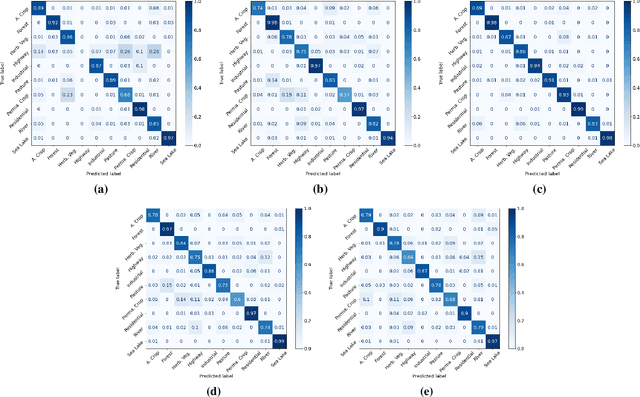
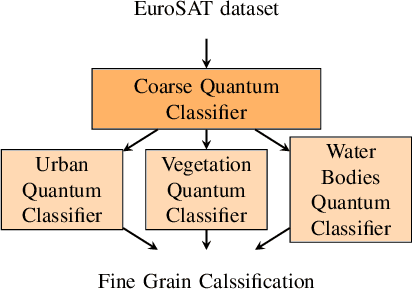
This article aims to investigate how circuit-based hybrid Quantum Convolutional Neural Networks (QCNNs) can be successfully employed as image classifiers in the context of remote sensing. The hybrid QCNNs enrich the classical architecture of CNNs by introducing a quantum layer within a standard neural network. The novel QCNN proposed in this work is applied to the Land Use and Land Cover (LULC) classification, chosen as an Earth Observation (EO) use case, and tested on the EuroSAT dataset used as reference benchmark. The results of the multiclass classification prove the effectiveness of the presented approach, by demonstrating that the QCNN performances are higher than the classical counterparts. Moreover, investigation of various quantum circuits shows that the ones exploiting quantum entanglement achieve the best classification scores. This study underlines the potentialities of applying quantum computing to an EO case study and provides the theoretical and experimental background for futures investigations.
Robotic Grasping through Combined image-Based Grasp Proposal and 3D Reconstruction
Mar 03, 2020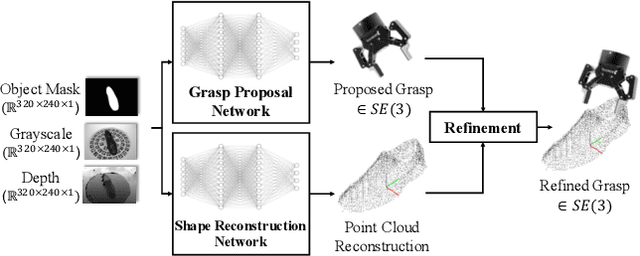
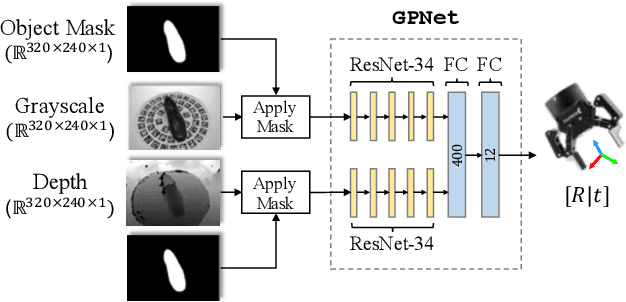
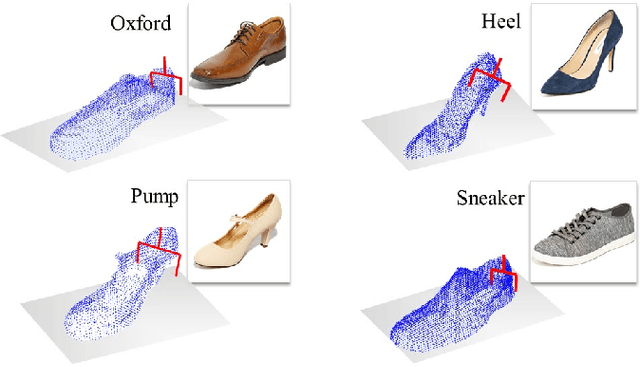
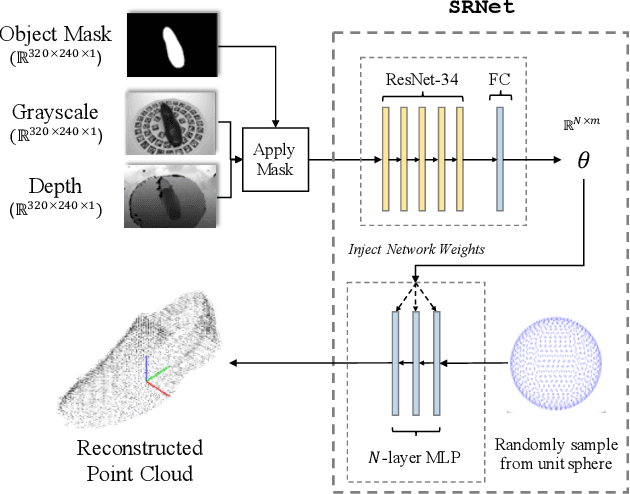
We present a novel approach to robotic grasp planning using both a learned grasp proposal network and a learned 3D shape reconstruction network. Our system generates 6-DOF grasps from a single RGB-D image of the target object, which is provided as input to both networks. By using the geometric reconstruction to refine the the candidate grasp produced by the grasp proposal network, our system is able to accurately grasp both known and unknown objects, even when the grasp location on the object is not visible in the input image. This paper presents the network architectures, training procedures, and grasp refinement method that comprise our system. Hardware experiments demonstrate the efficacy of our system at grasping both known and unknown objects (91% success rate). We additionally perform ablation studies that show the benefits of combining a learned grasp proposal with geometric reconstruction for grasping, and also show that our system outperforms several baselines in a grasping task.
Towards Fast Region Adaptive Ultrasound Beamformer for Plane Wave Imaging Using Convolutional Neural Networks
Jun 13, 2021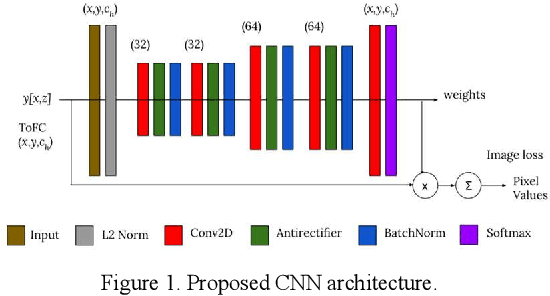

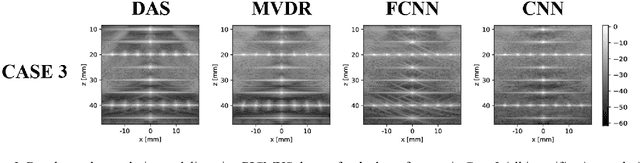
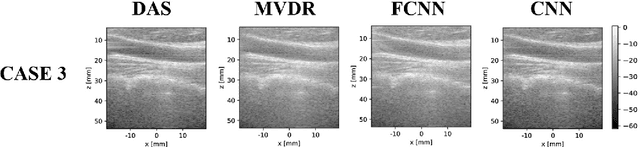
Automatic learning algorithms for improving the image quality of diagnostic B-mode ultrasound (US) images have been gaining popularity in the recent past. In this work, a novel convolutional neural network (CNN) is trained using time of flight corrected in-vivo receiver data of plane wave transmit to produce corresponding high-quality minimum variance distortion less response (MVDR) beamformed image. A comprehensive performance comparison in terms of qualitative and quantitative measures for fully connected neural network (FCNN), the proposed CNN architecture, MVDR and Delay and Sum (DAS) using the dataset from Plane wave Imaging Challenge in Ultrasound (PICMUS) is also reported in this work. The CNN architecture could leverage the spatial information and will be more region adaptive during the beamforming process. This is evident from the improvement seen over the baseline FCNN approach and conventional MVDR beamformer, both in resolution and contrast with an improvement of 6 dB in CNR using only zero-angle transmission over the baseline. With the observed reduction in the requirement of number of angles to produce similar image metrics would prove advantageous in providing a possibility for higher frame rates.
Oracle inequalities for image denoising with total variation regularization
Dec 14, 2019We derive oracle results for discrete image denoising with a total variation penalty. We consider the least squares estimator with a penalty on the $\ell^1$-norm of the total discrete derivative of the image. This estimator falls into the class of analysis estimators. A bound on the effective sparsity by means of an interpolating matrix allows us to obtain oracle inequalities with fast rates. The bound is an extension of the bound by Ortelli and van de Geer [2019c] to the two-dimensional case. We also present an oracle inequality with slow rates, which matches, up to a log-term, the rate obtained for the same estimator by Mammen and van de Geer [1997]. The key ingredient for our results are the projection arguments to bound the empirical process due to Dalalyan et al. [2017].
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
Sep 20, 2021
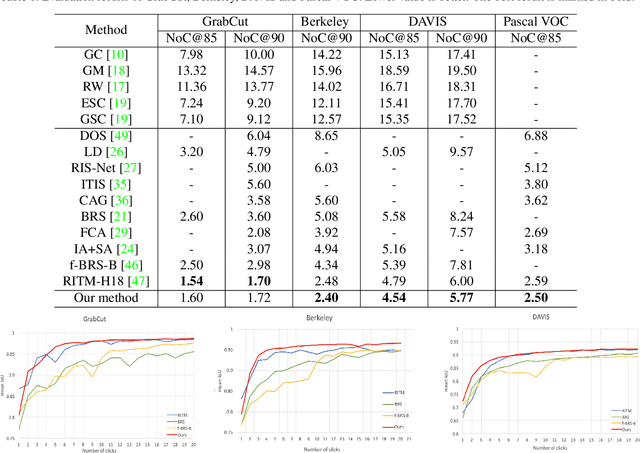
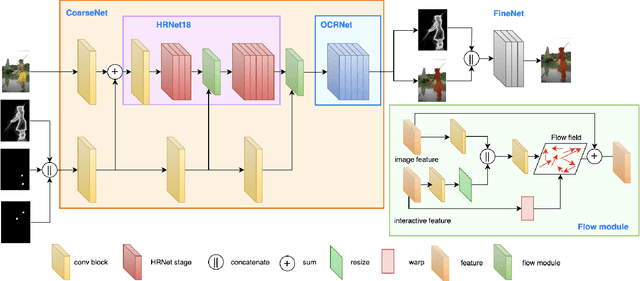

High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.
Evaluation of Various Open-Set Medical Imaging Tasks with Deep Neural Networks
Oct 21, 2021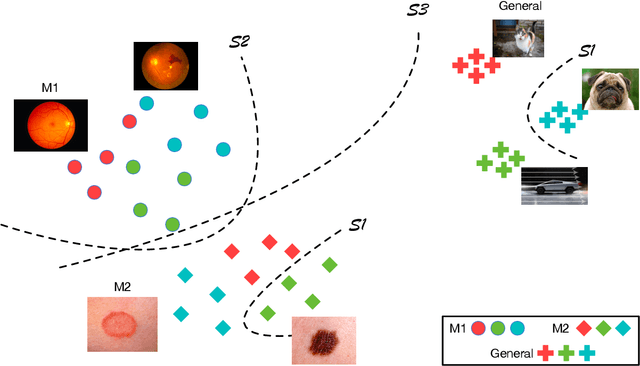
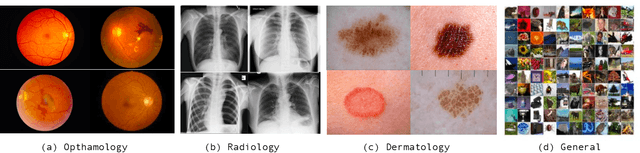
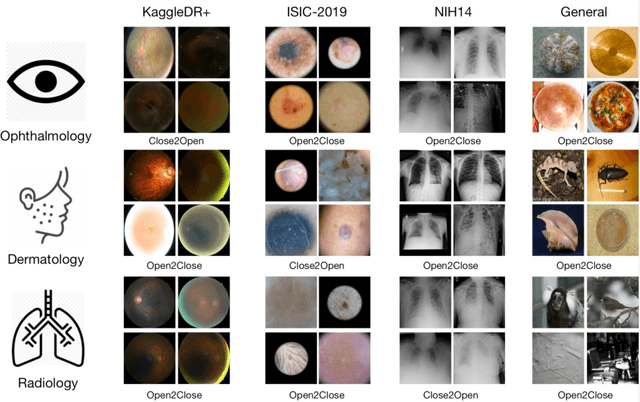
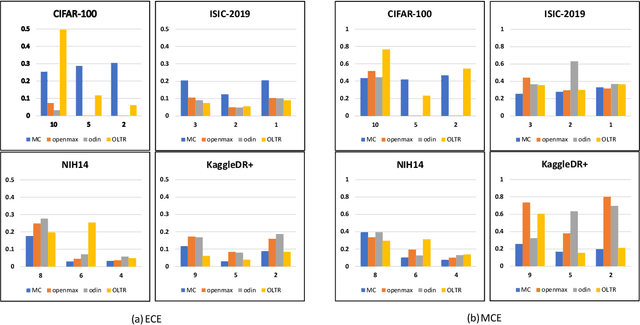
The current generation of deep neural networks has achieved close-to-human results on "closed-set" image recognition; that is, the classes being evaluated overlap with the training classes. Many recent methods attempt to address the importance of the unknown, which are termed "open-set" recognition algorithms, try to reject unknown classes as well as maintain high recognition accuracy on known classes. However, it is still unclear how different general domain-trained open-set methods from ImageNet would perform on a different but more specific domain, such as the medical domain. Without principled and formal evaluations to measure the effectiveness of those general open-set methods, artificial intelligence (AI)-based medical diagnostics would experience ineffective adoption and increased risks of bad decision making. In this paper, we conduct rigorous evaluations amongst state-of-the-art open-set methods, exploring different open-set scenarios from "similar-domain" to "different-domain" scenarios and comparing them on various general and medical domain datasets. We summarise the results and core ideas and explain how the models react to various degrees of openness and different distributions of open classes. We show the main difference between general domain-trained and medical domain-trained open-set models with our quantitative and qualitative analysis of the results. We also identify aspects of model robustness in real clinical workflow usage according to confidence calibration and the inference efficiency.
Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images
Jul 19, 2021
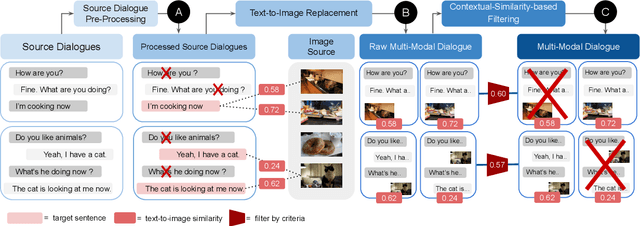
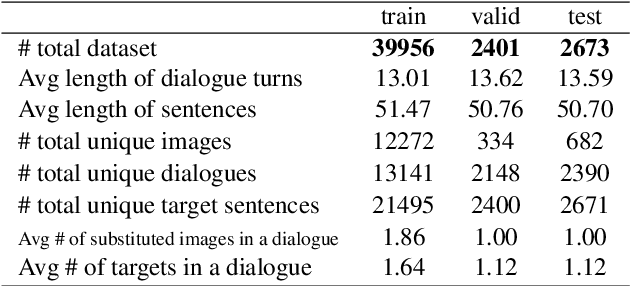
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.
Controllable and Compositional Generation with Latent-Space Energy-Based Models
Oct 21, 2021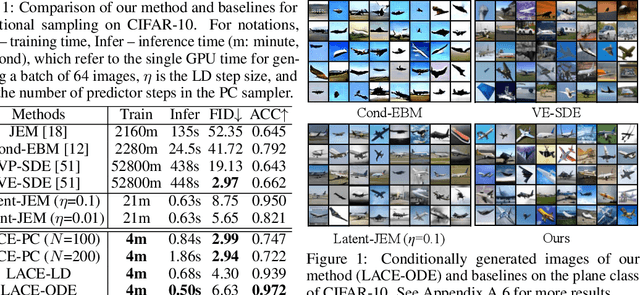

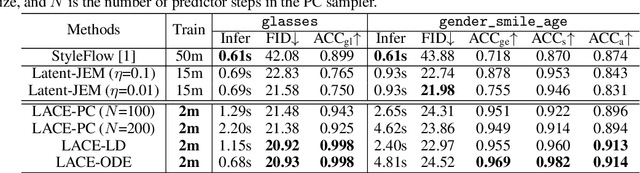

Controllable generation is one of the key requirements for successful adoption of deep generative models in real-world applications, but it still remains as a great challenge. In particular, the compositional ability to generate novel concept combinations is out of reach for most current models. In this work, we use energy-based models (EBMs) to handle compositional generation over a set of attributes. To make them scalable to high-resolution image generation, we introduce an EBM in the latent space of a pre-trained generative model such as StyleGAN. We propose a novel EBM formulation representing the joint distribution of data and attributes together, and we show how sampling from it is formulated as solving an ordinary differential equation (ODE). Given a pre-trained generator, all we need for controllable generation is to train an attribute classifier. Sampling with ODEs is done efficiently in the latent space and is robust to hyperparameters. Thus, our method is simple, fast to train, and efficient to sample. Experimental results show that our method outperforms the state-of-the-art in both conditional sampling and sequential editing. In compositional generation, our method excels at zero-shot generation of unseen attribute combinations. Also, by composing energy functions with logical operators, this work is the first to achieve such compositionality in generating photo-realistic images of resolution 1024x1024.
Progressive Retinex: Mutually Reinforced Illumination-Noise Perception Network for Low Light Image Enhancement
Nov 26, 2019Contrast enhancement and noise removal are coupled problems for low-light image enhancement. The existing Retinex based methods do not take the coupling relation into consideration, resulting in under or over-smoothing of the enhanced images. To address this issue, this paper presents a novel progressive Retinex framework, in which illumination and noise of low-light image are perceived in a mutually reinforced manner, leading to noise reduction low-light enhancement results. Specifically, two fully pointwise convolutional neural networks are devised to model the statistical regularities of ambient light and image noise respectively, and to leverage them as constraints to facilitate the mutual learning process. The proposed method not only suppresses the interference caused by the ambiguity between tiny textures and image noises, but also greatly improves the computational efficiency. Moreover, to solve the problem of insufficient training data, we propose an image synthesis strategy based on camera imaging model, which generates color images corrupted by illumination-dependent noises. Experimental results on both synthetic and real low-light images demonstrate the superiority of our proposed approaches against the State-Of-The-Art (SOTA) low-light enhancement methods.