 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GCN-Based Linkage Prediction for Face Clusteringon Imbalanced Datasets: An Empirical Study
Jul 06, 2021
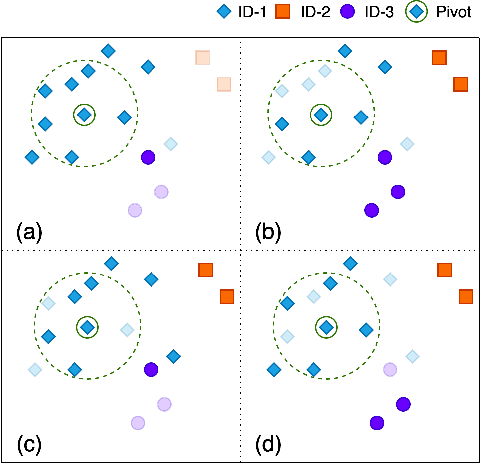
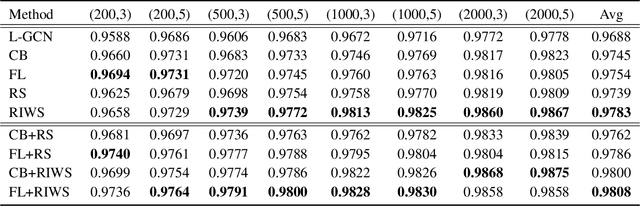
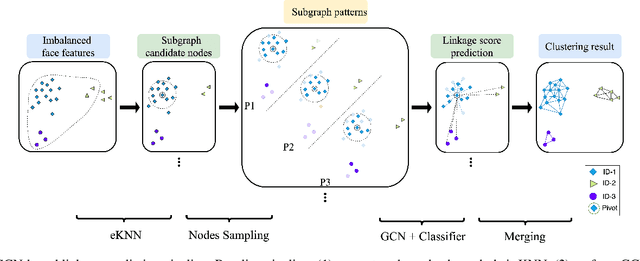
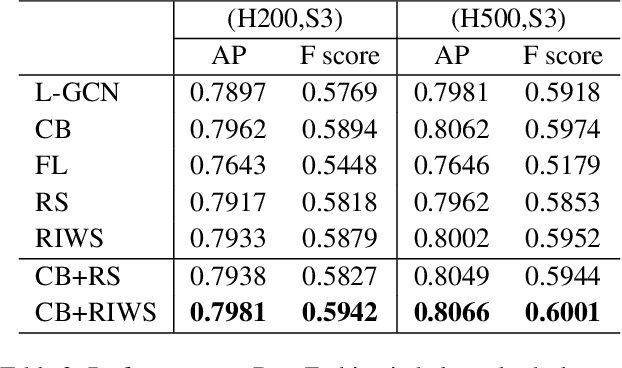
In recent years, benefiting from the expressivepower of Graph Convolutional Networks (GCNs),significant breakthroughs have been made in faceclustering. However, rare attention has been paidto GCN-based clustering on imbalanced data. Al-though imbalance problem has been extensivelystudied, the impact of imbalanced data on GCN-based linkage prediction task is quite different,which would cause problems in two aspects: im-balanced linkage labels and biased graph represen-tations. The problem of imbalanced linkage labelsis similar to that in image classification task, but thelatter is a particular problem in GCN-based clus-tering via linkage prediction. Significantly biasedgraph representations in training can cause catas-trophic overfitting of a GCN model. To tacklethese problems, we evaluate the feasibility of thoseexisting methods for imbalanced image classifica-tion problem on graphs with extensive experiments,and present a new method to alleviate the imbal-anced labels and also augment graph representa-tions using a Reverse-Imbalance Weighted Sam-pling (RIWS) strategy, followed with insightfulanalyses and discussions. A series of imbalancedbenchmark datasets synthesized from MS-Celeb-1M and DeepFashion will be openly available.
RGB-T Image Saliency Detection via Collaborative Graph Learning
May 16, 2019

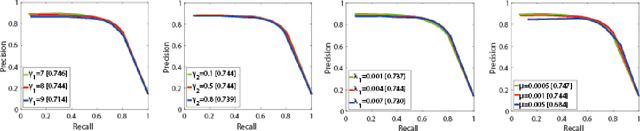
Image saliency detection is an active research topic in the community of computer vision and multimedia. Fusing complementary RGB and thermal infrared data has been proven to be effective for image saliency detection. In this paper, we propose an effective approach for RGB-T image saliency detection. Our approach relies on a novel collaborative graph learning algorithm. In particular, we take superpixels as graph nodes, and collaboratively use hierarchical deep features to jointly learn graph affinity and node saliency in a unified optimization framework. Moreover, we contribute a more challenging dataset for the purpose of RGB-T image saliency detection, which contains 1000 spatially aligned RGB-T image pairs and their ground truth annotations. Extensive experiments on the public dataset and the newly created dataset suggest that the proposed approach performs favorably against the state-of-the-art RGB-T saliency detection methods.
Character Spotting Using Machine Learning Techniques
Jul 28, 2021
This work presents a comparison of machine learning algorithms that are implemented to segment the characters of text presented as an image. The algorithms are designed to work on degraded documents with text that is not aligned in an organized fashion. The paper investigates the use of Support Vector Machines, K-Nearest Neighbor algorithm and an Encoder Network to perform the operation of character spotting. Character Spotting involves extracting potential characters from a stream of text by selecting regions bound by white space.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020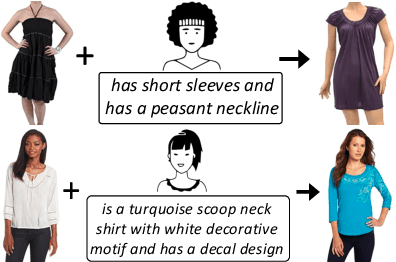
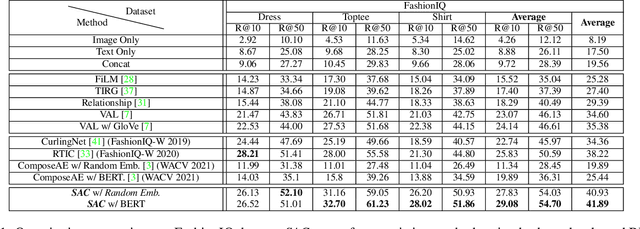
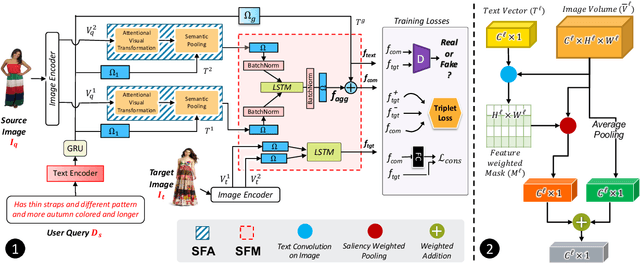
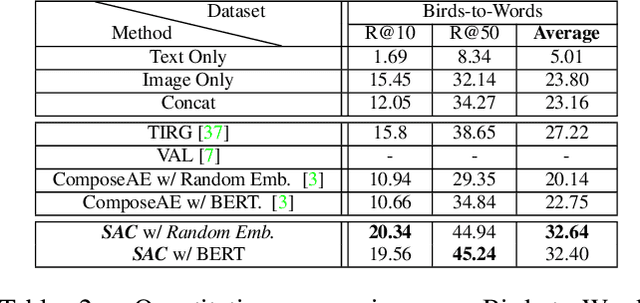
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
May 25, 2019
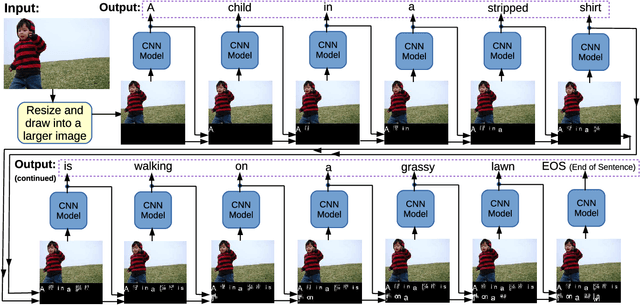
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
MEMO: Test Time Robustness via Adaptation and Augmentation
Oct 18, 2021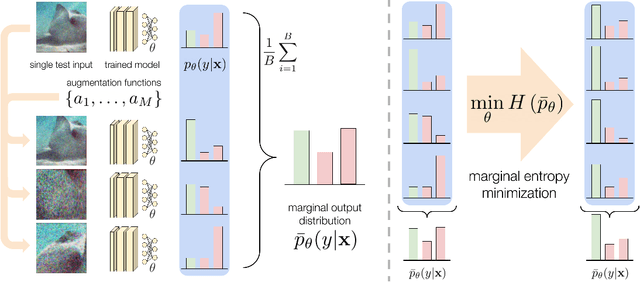


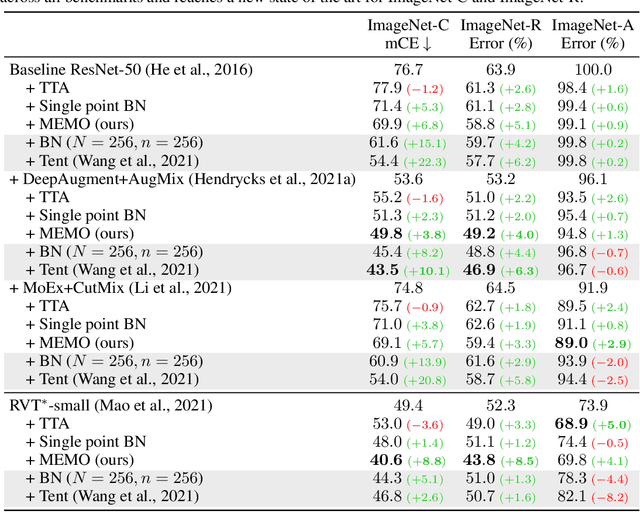
While deep neural networks can attain good accuracy on in-distribution test points, many applications require robustness even in the face of unexpected perturbations in the input, changes in the domain, or other sources of distribution shift. We study the problem of test time robustification, i.e., using the test input to improve model robustness. Recent prior works have proposed methods for test time adaptation, however, they each introduce additional assumptions, such as access to multiple test points, that prevent widespread adoption. In this work, we aim to study and devise methods that make no assumptions about the model training process and are broadly applicable at test time. We propose a simple approach that can be used in any test setting where the model is probabilistic and adaptable: when presented with a test example, perform different data augmentations on the data point, and then adapt (all of) the model parameters by minimizing the entropy of the model's average, or marginal, output distribution across the augmentations. Intuitively, this objective encourages the model to make the same prediction across different augmentations, thus enforcing the invariances encoded in these augmentations, while also maintaining confidence in its predictions. In our experiments, we demonstrate that this approach consistently improves robust ResNet and vision transformer models, achieving accuracy gains of 1-8% over standard model evaluation and also generally outperforming prior augmentation and adaptation strategies. We achieve state-of-the-art results for test shifts caused by image corruptions (ImageNet-C), renditions of common objects (ImageNet-R), and, among ResNet-50 models, adversarially chosen natural examples (ImageNet-A).
Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples
Oct 29, 2020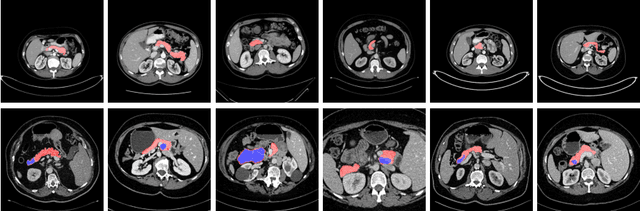
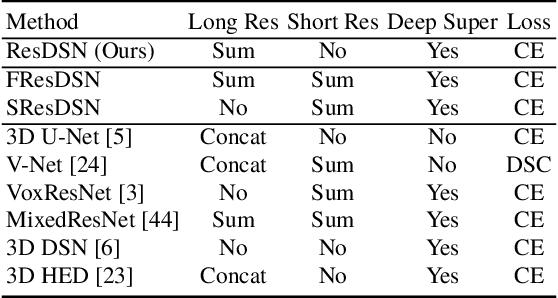

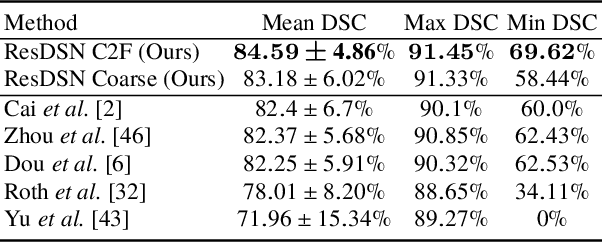
Although deep neural networks have been a dominant method for many 2D vision tasks, it is still challenging to apply them to 3D tasks, such as medical image segmentation, due to the limited amount of annotated 3D data and limited computational resources. In this chapter, by rethinking the strategy to apply 3D Convolutional Neural Networks to segment medical images, we propose a novel 3D-based coarse-to-fine framework to efficiently tackle these challenges. The proposed 3D-based framework outperforms their 2D counterparts by a large margin since it can leverage the rich spatial information along all three axes. We further analyze the threat of adversarial attacks on the proposed framework and show how to defense against the attack. We conduct experiments on three datasets, the NIH pancreas dataset, the JHMI pancreas dataset and the JHMI pathological cyst dataset, where the first two and the last one contain healthy and pathological pancreases respectively, and achieve the current state-of-the-art in terms of Dice-Sorensen Coefficient (DSC) on all of them. Especially, on the NIH pancreas segmentation dataset, we outperform the previous best by an average of over $2\%$, and the worst case is improved by $7\%$ to reach almost $70\%$, which indicates the reliability of our framework in clinical applications.
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
Jul 01, 2020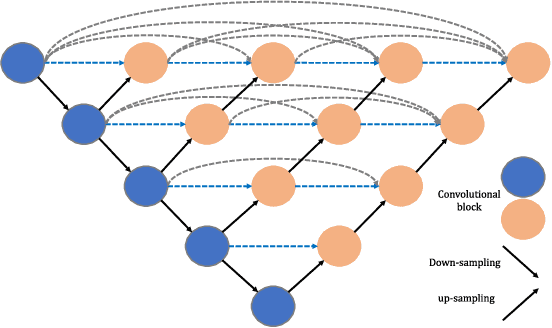



In this paper we propose a novel method for infrared and visible image fusion where we develop nest connection-based network and spatial/channel attention models. The nest connection-based network can preserve significant amounts of information from input data in a multi-scale perspective. The approach comprises three key elements: encoder, fusion strategy and decoder respectively. In our proposed fusion strategy, spatial attention models and channel attention models are developed that describe the importance of each spatial position and of each channel with deep features. Firstly, the source images are fed into the encoder to extract multi-scale deep features. The novel fusion strategy is then developed to fuse these features for each scale. Finally, the fused image is reconstructed by the nest connection-based decoder. Experiments are performed on publicly available datasets. These exhibit that our proposed approach has better fusion performance than other state-of-the-art methods. This claim is justified through both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-nestfuse
Face Video Generation from a Single Image and Landmarks
Apr 25, 2019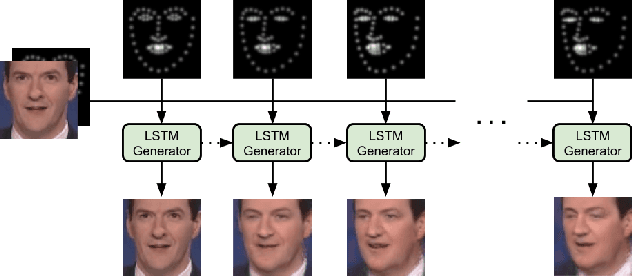
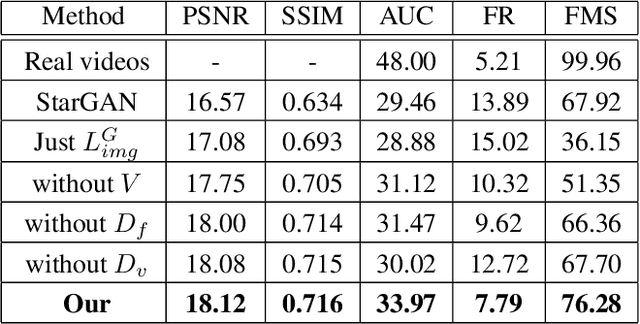
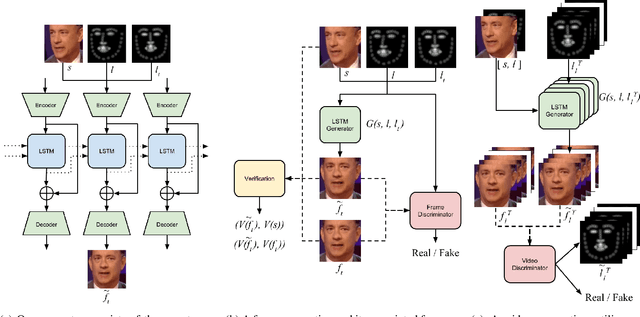
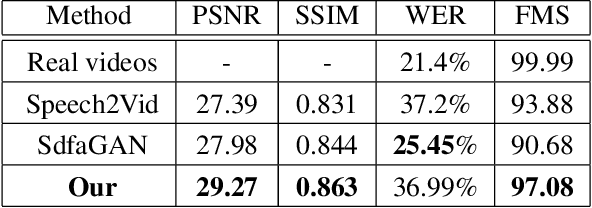
In this paper we are concerned with the challenging problem of producing a full image sequence of a deformable face given only an image and generic facial motions encoded by a set of sparse landmarks. To this end we build upon recent breakthroughs in image-to-image translation such as pix2pix, CycleGAN and StarGAN which learn Deep Convolutional Neural Networks (DCNNs) that learn to map aligned pairs or images between different domains (i.e., having different labels) and propose a new architecture which is not driven any more by labels but by spatial maps, facial landmarks. In particular, we propose the MotionGAN which transforms an input face image into a new one according to a heatmap of target landmarks. We show that it is possible to create very realistic face videos using a single image and a set of target landmarks. Furthermore, our method can be used to edit a facial image with arbitrary motions according to landmarks (e.g., expression, speech, etc.). This provides much more flexibility to face editing, expression transfer, facial video creation, etc. than models based on discrete expressions, audios or action units.
On the use of automatically generated synthetic image datasets for benchmarking face recognition
Jun 08, 2021
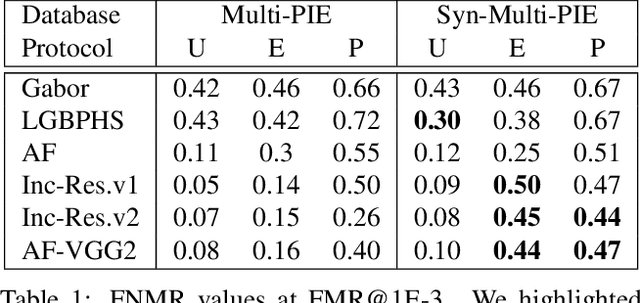

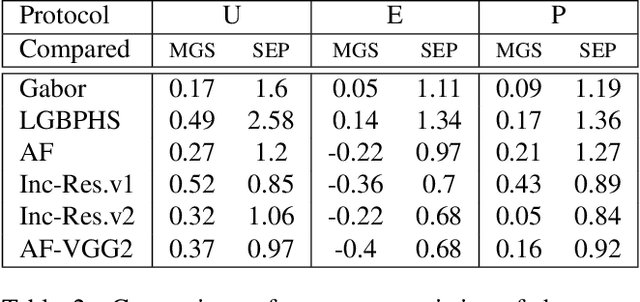
The availability of large-scale face datasets has been key in the progress of face recognition. However, due to licensing issues or copyright infringement, some datasets are not available anymore (e.g. MS-Celeb-1M). Recent advances in Generative Adversarial Networks (GANs), to synthesize realistic face images, provide a pathway to replace real datasets by synthetic datasets, both to train and benchmark face recognition (FR) systems. The work presented in this paper provides a study on benchmarking FR systems using a synthetic dataset. First, we introduce the proposed methodology to generate a synthetic dataset, without the need for human intervention, by exploiting the latent structure of a StyleGAN2 model with multiple controlled factors of variation. Then, we confirm that (i) the generated synthetic identities are not data subjects from the GAN's training dataset, which is verified on a synthetic dataset with 10K+ identities; (ii) benchmarking results on the synthetic dataset are a good substitution, often providing error rates and system ranking similar to the benchmarking on the real dataset.