 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Learning with Kernel Dependence Maximization
Jun 15, 2021
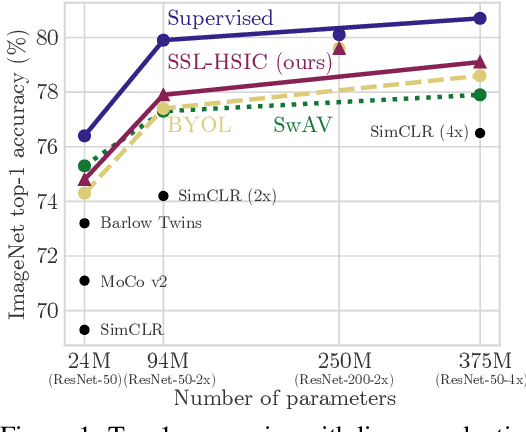
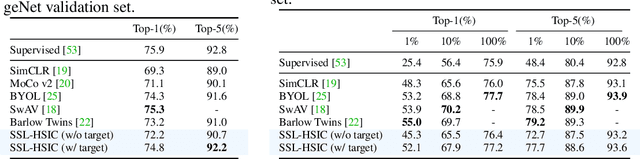
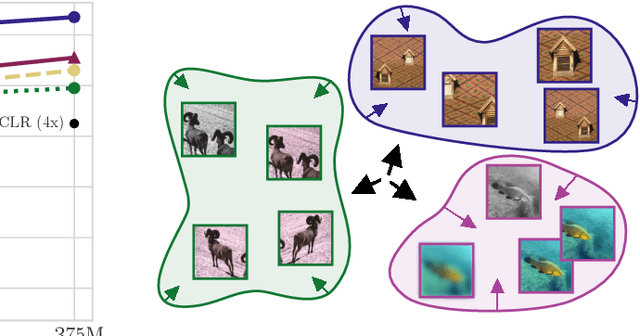
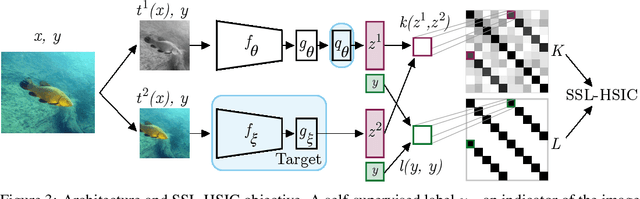
We approach self-supervised learning of image representations from a statistical dependence perspective, proposing Self-Supervised Learning with the Hilbert-Schmidt Independence Criterion (SSL-HSIC). SSL-HSIC maximizes dependence between representations of transformed versions of an image and the image identity, while minimizing the kernelized variance of those features. This self-supervised learning framework yields a new understanding of InfoNCE, a variational lower bound on the mutual information (MI) between different transformations. While the MI itself is known to have pathologies which can result in meaningless representations being learned, its bound is much better behaved: we show that it implicitly approximates SSL-HSIC (with a slightly different regularizer). Our approach also gives us insight into BYOL, since SSL-HSIC similarly learns local neighborhoods of samples. SSL-HSIC allows us to directly optimize statistical dependence in time linear in the batch size, without restrictive data assumptions or indirect mutual information estimators. Trained with or without a target network, SSL-HSIC matches the current state-of-the-art for standard linear evaluation on ImageNet, semi-supervised learning and transfer to other classification and vision tasks such as semantic segmentation, depth estimation and object recognition.
Learning Multilingual Word Embeddings Using Image-Text Data
May 29, 2019
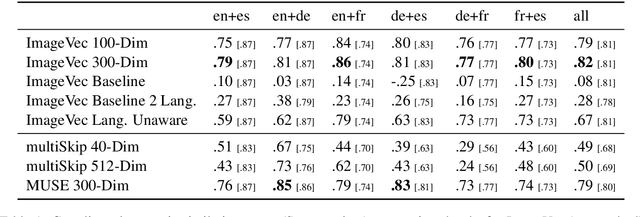
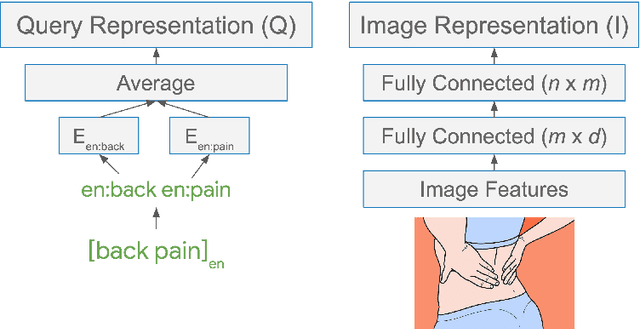
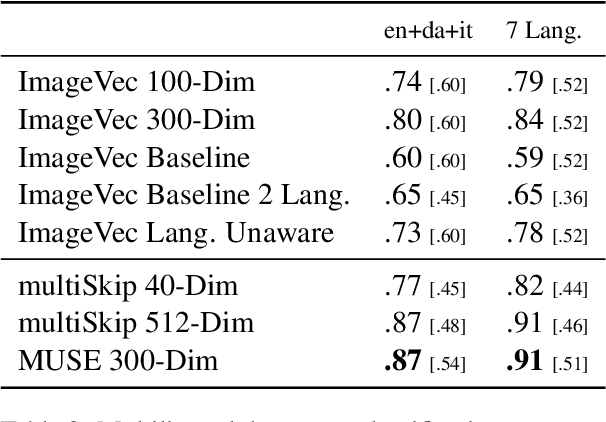
There has been significant interest recently in learning multilingual word embeddings -- in which semantically similar words across languages have similar embeddings. State-of-the-art approaches have relied on expensive labeled data, which is unavailable for low-resource languages, or have involved post-hoc unification of monolingual embeddings. In the present paper, we investigate the efficacy of multilingual embeddings learned from weakly-supervised image-text data. In particular, we propose methods for learning multilingual embeddings using image-text data, by enforcing similarity between the representations of the image and that of the text. Our experiments reveal that even without using any expensive labeled data, a bag-of-words-based embedding model trained on image-text data achieves performance comparable to the state-of-the-art on crosslingual semantic similarity tasks.
Affinity Fusion Graph-based Framework for Natural Image Segmentation
Jun 24, 2020

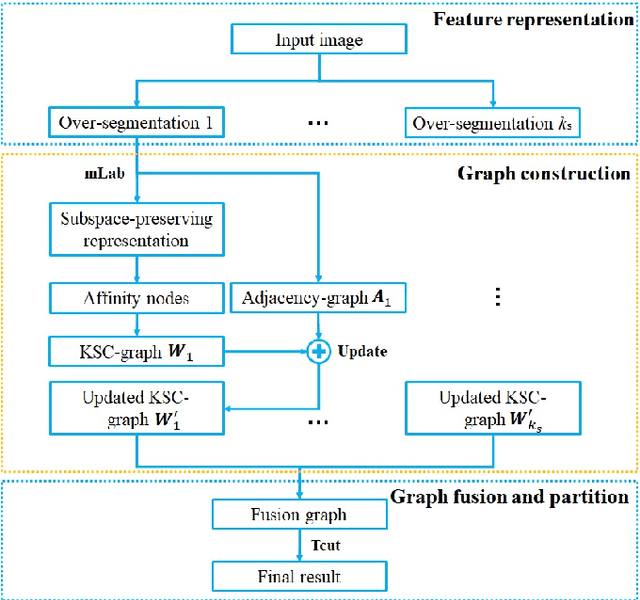
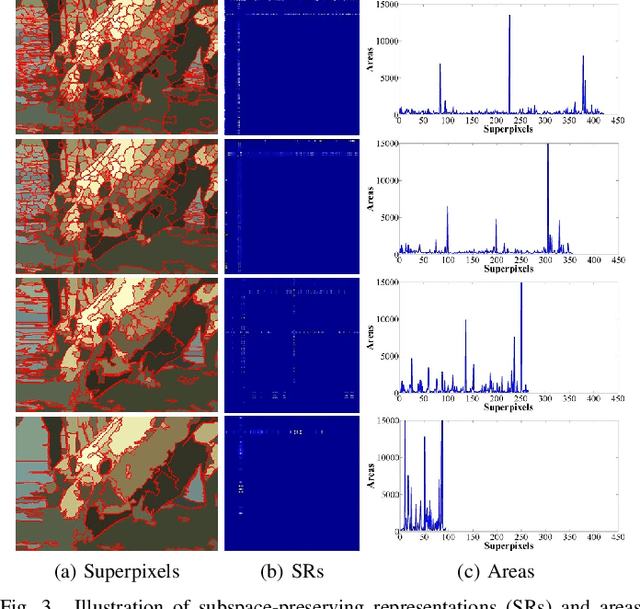
This paper proposes an affinity fusion graph framework to effectively connect different graphs with highly discriminating power and nonlinearity for natural image segmentation. The proposed framework combines adjacency-graphs and kernel spectral clustering based graphs (KSC-graphs) according to a new definition named affinity nodes of multi-scale superpixels. These affinity nodes are selected based on a better affiliation of superpixels, namely subspace-preserving representation which is generated by sparse subspace clustering based on subspace pursuit. Then a KSC-graph is built via a novel kernel spectral clustering to explore the nonlinear relationships among these affinity nodes. Moreover, an adjacency-graph at each scale is constructed, which is further used to update the proposed KSC-graph at affinity nodes. The fusion graph is built across different scales, and it is partitioned to obtain final segmentation result. Experimental results on the Berkeley segmentation dataset and Microsoft Research Cambridge dataset show the superiority of our framework in comparison with the state-of-the-art methods. The code is available at https://github.com/Yangzhangcst/AF-graph.
Towards Unsupervised Image Captioning with Shared Multimodal Embeddings
Aug 25, 2019
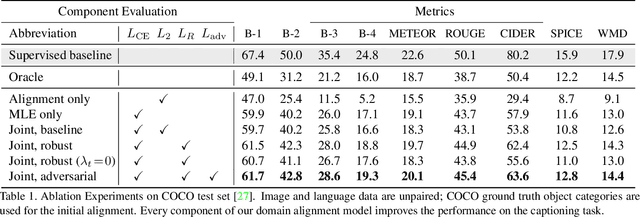
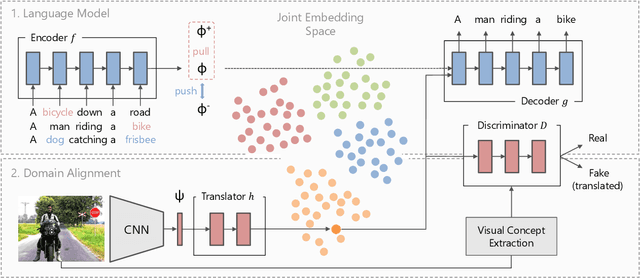
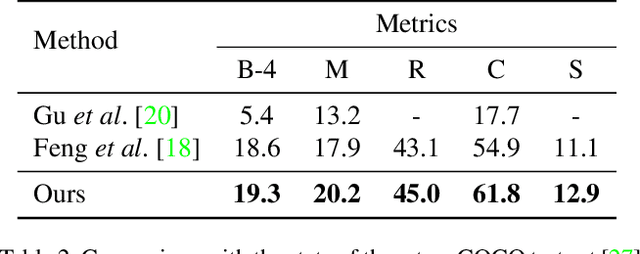
Understanding images without explicit supervision has become an important problem in computer vision. In this paper, we address image captioning by generating language descriptions of scenes without learning from annotated pairs of images and their captions. The core component of our approach is a shared latent space that is structured by visual concepts. In this space, the two modalities should be indistinguishable. A language model is first trained to encode sentences into semantically structured embeddings. Image features that are translated into this embedding space can be decoded into descriptions through the same language model, similarly to sentence embeddings. This translation is learned from weakly paired images and text using a loss robust to noisy assignments and a conditional adversarial component. Our approach allows to exploit large text corpora outside the annotated distributions of image/caption data. Our experiments show that the proposed domain alignment learns a semantically meaningful representation which outperforms previous work.
RPCL: A Framework for Improving Cross-Domain Detection with Auxiliary Tasks
Apr 18, 2021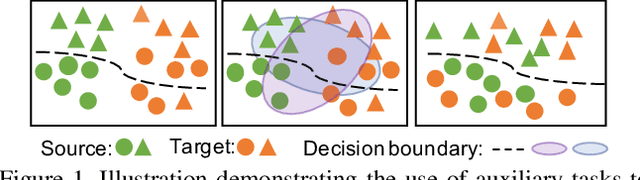
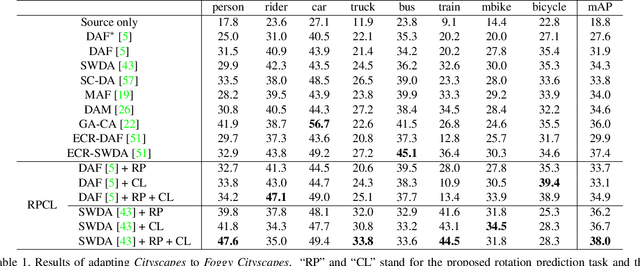
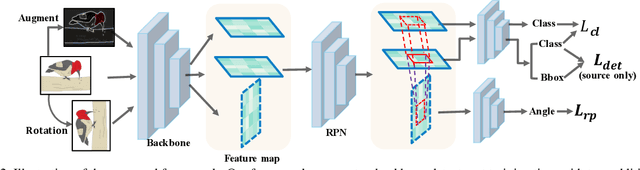
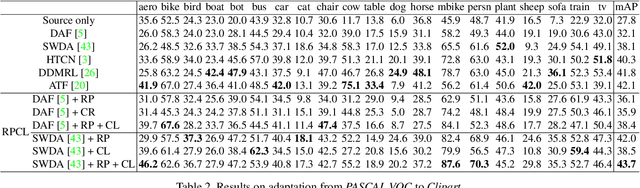
Cross-Domain Detection (XDD) aims to train an object detector using labeled image from a source domain but have good performance in the target domain with only unlabeled images. Existing approaches achieve this either by aligning the feature maps or the region proposals from the two domains, or by transferring the style of source images to that of target image. Contrasted with prior work, this paper provides a complementary solution to align domains by learning the same auxiliary tasks in both domains simultaneously. These auxiliary tasks push image from both domains towards shared spaces, which bridges the domain gap. Specifically, this paper proposes Rotation Prediction and Consistency Learning (PRCL), a framework complementing existing XDD methods for domain alignment by leveraging the two auxiliary tasks. The first one encourages the model to extract region proposals from foreground regions by rotating an image and predicting the rotation angle from the extracted region proposals. The second task encourages the model to be robust to changes in the image space by optimizing the model to make consistent class predictions for region proposals regardless of image perturbations. Experiments show the detection performance can be consistently and significantly enhanced by applying the two proposed tasks to existing XDD methods.
Momentum Centering and Asynchronous Update for Adaptive Gradient Methods
Oct 17, 2021
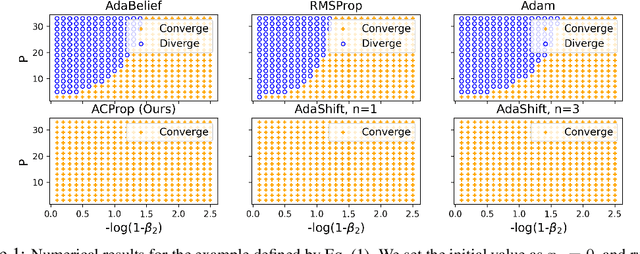
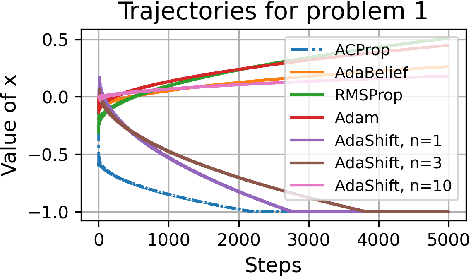
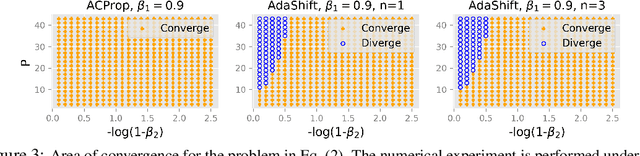
We propose ACProp (Asynchronous-centering-Prop), an adaptive optimizer which combines centering of second momentum and asynchronous update (e.g. for $t$-th update, denominator uses information up to step $t-1$, while numerator uses gradient at $t$-th step). ACProp has both strong theoretical properties and empirical performance. With the example by Reddi et al. (2018), we show that asynchronous optimizers (e.g. AdaShift, ACProp) have weaker convergence condition than synchronous optimizers (e.g. Adam, RMSProp, AdaBelief); within asynchronous optimizers, we show that centering of second momentum further weakens the convergence condition. We demonstrate that ACProp has a convergence rate of $O(\frac{1}{\sqrt{T}})$ for the stochastic non-convex case, which matches the oracle rate and outperforms the $O(\frac{logT}{\sqrt{T}})$ rate of RMSProp and Adam. We validate ACProp in extensive empirical studies: ACProp outperforms both SGD and other adaptive optimizers in image classification with CNN, and outperforms well-tuned adaptive optimizers in the training of various GAN models, reinforcement learning and transformers. To sum up, ACProp has good theoretical properties including weak convergence condition and optimal convergence rate, and strong empirical performance including good generalization like SGD and training stability like Adam. We provide the implementation at https://github.com/juntang-zhuang/ACProp-Optimizer.
EventGAN: Leveraging Large Scale Image Datasets for Event Cameras
Dec 03, 2019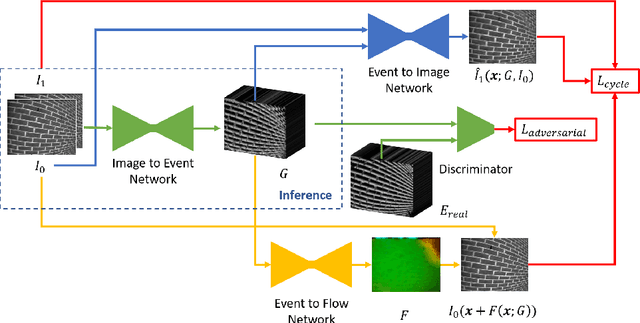



Event cameras provide a number of benefits over traditional cameras, such as the ability to track incredibly fast motions, high dynamic range, and low power consumption. However, their application into computer vision problems, many of which are primarily dominated by deep learning solutions, has been limited by the lack of labeled training data for events. In this work, we propose a method which leverages the existing labeled data for images by simulating events from a pair of temporal image frames, using a convolutional neural network. We train this network on pairs of images and events, using an adversarial discriminator loss and a pair of cycle consistency losses. The cycle consistency losses utilize a pair of pre-trained self-supervised networks which perform optical flow estimation and image reconstruction from events, and constrain our network to generate events which result in accurate outputs from both of these networks. Trained fully end to end, our network learns a generative model for events from images without the need for accurate modeling of the motion in the scene, exhibited by modeling based methods, while also implicitly modeling event noise. Using this simulator, we train a pair of downstream networks on object detection and 2D human pose estimation from events, using simulated data from large scale image datasets, and demonstrate the networks' abilities to generalize to datasets with real events.
CAGAN: Text-To-Image Generation with Combined Attention GANs
Apr 26, 2021
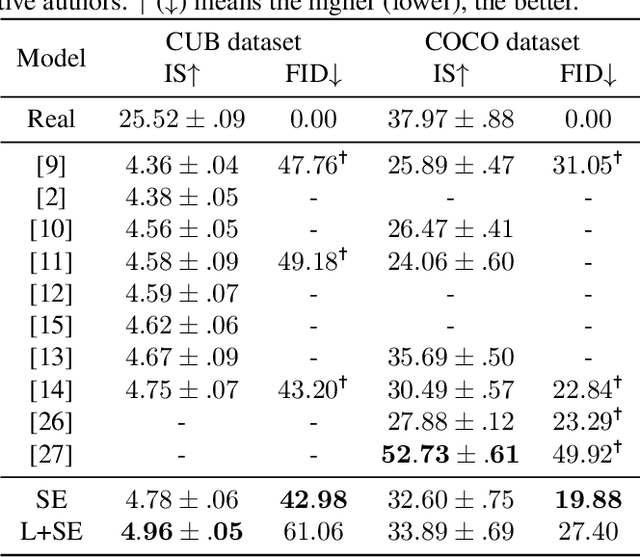
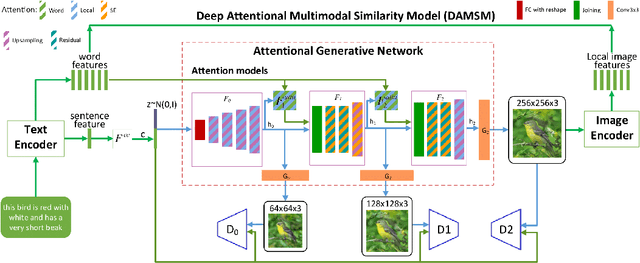

Generating images according to natural language descriptions is a challenging task. In this work, we propose the Combined Attention Generative Adversarial Network (CAGAN) to generate photo-realistic images according to textual descriptions. The proposed CAGAN utilises two attention models: word attention to draw different sub-regions conditioned on related words; and squeeze-and-excitation attention to capture non-linear interaction among channels. With spectral normalisation to stabilise training, our proposed CAGAN improves the state of the art on the IS and FID on the CUB dataset and the FID on the more challenging COCO dataset. Furthermore, we demonstrate that judging a model by a single evaluation metric can be misleading by developing an additional model adding local self-attention which scores a higher IS, outperforming the state of the art on the CUB dataset, but generates unrealistic images through feature repetition.
Weakly-supervised High-resolution Segmentation of Mammography Images for Breast Cancer Diagnosis
Jun 15, 2021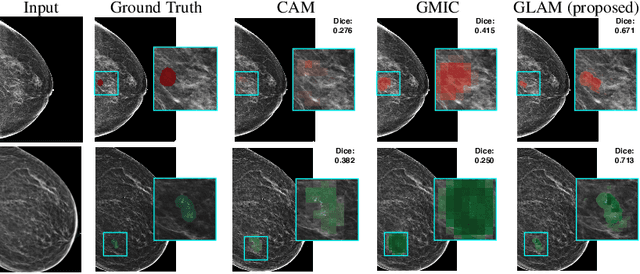

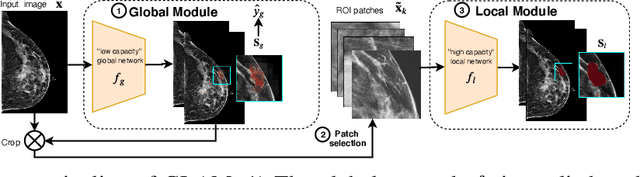

In the last few years, deep learning classifiers have shown promising results in image-based medical diagnosis. However, interpreting the outputs of these models remains a challenge. In cancer diagnosis, interpretability can be achieved by localizing the region of the input image responsible for the output, i.e. the location of a lesion. Alternatively, segmentation or detection models can be trained with pixel-wise annotations indicating the locations of malignant lesions. Unfortunately, acquiring such labels is labor-intensive and requires medical expertise. To overcome this difficulty, weakly-supervised localization can be utilized. These methods allow neural network classifiers to output saliency maps highlighting the regions of the input most relevant to the classification task (e.g. malignant lesions in mammograms) using only image-level labels (e.g. whether the patient has cancer or not) during training. When applied to high-resolution images, existing methods produce low-resolution saliency maps. This is problematic in applications in which suspicious lesions are small in relation to the image size. In this work, we introduce a novel neural network architecture to perform weakly-supervised segmentation of high-resolution images. The proposed model selects regions of interest via coarse-level localization, and then performs fine-grained segmentation of those regions. We apply this model to breast cancer diagnosis with screening mammography, and validate it on a large clinically-realistic dataset. Measured by Dice similarity score, our approach outperforms existing methods by a large margin in terms of localization performance of benign and malignant lesions, relatively improving the performance by 39.6% and 20.0%, respectively. Code and the weights of some of the models are available at https://github.com/nyukat/GLAM
Real-World Application of Various Trajectory Planning Algorithms on MIT RACECAR
Aug 17, 2021
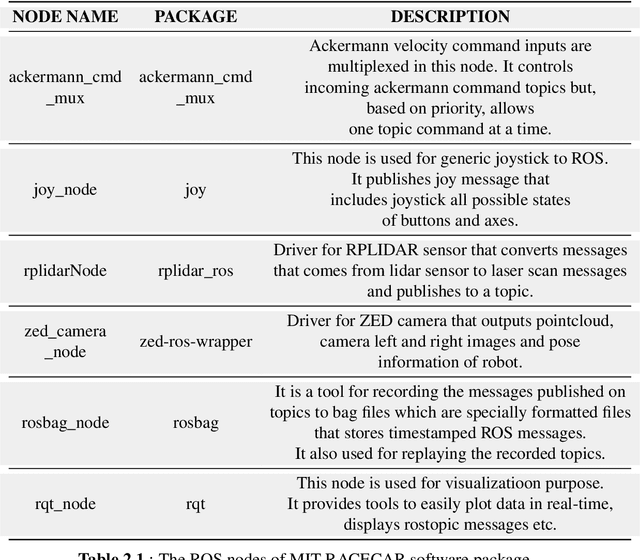


In the project, the vehicle was first controlled with ROS. For this purpose, the necessary nodes were prepared to be controlled with a joystick. Afterwards, DWA(Dynamic Window Approach), TEB(Timed-Elastic Band) and APF(Artificial Potential Field) path planning algorithms were applied to MIT RACECAR, respectively. These algorithms have advantages and disadvantages against each other on different issues. For this reason, a scenario was created to compare algorithms. On a curved double lane road created according to this scenario, MIT RACECAR has to follow the lanes and when it encounters an obstacle, it has to change lanes without leaving the road and pass without hitting the obstacle. In addition, an image processing algorithm was developed to obtain the position information of the lanes needed to implement this scenario. This algorithm detects the target point by processing the image taken from the ZED camera and gives the target point information to the path planning algorithm. After the necessary tools were created, the algorithms were tested against the scenario. In these tests, measurements such as how many obstacles the algorithm successfully passed, how simple routes it chose, and computational costs they have. According to these results, although it was not the algorithm that successfully passed the most obstacles, APF was chosen due to its low processing load and simple working logic. It was believed that with its uncomplicated structure, APF would also provide advantages in the future stages of the project.