 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SALYPATH: A Deep-Based Architecture for visual attention prediction
Jun 29, 2021
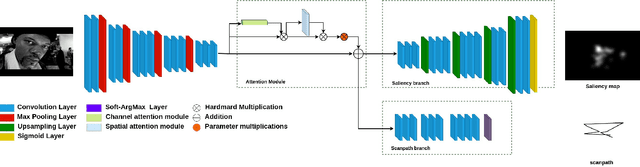


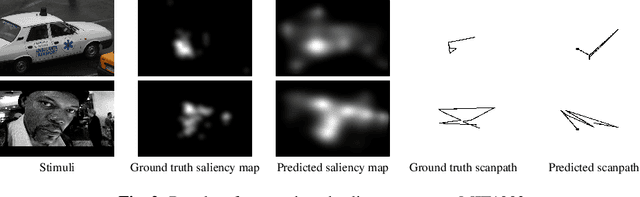
Human vision is naturally more attracted by some regions within their field of view than others. This intrinsic selectivity mechanism, so-called visual attention, is influenced by both high- and low-level factors; such as the global environment (illumination, background texture, etc.), stimulus characteristics (color, intensity, orientation, etc.), and some prior visual information. Visual attention is useful for many computer vision applications such as image compression, recognition, and captioning. In this paper, we propose an end-to-end deep-based method, so-called SALYPATH (SALiencY and scanPATH), that efficiently predicts the scanpath of an image through features of a saliency model. The idea is predict the scanpath by exploiting the capacity of a deep-based model to predict the saliency. The proposed method was evaluated through 2 well-known datasets. The results obtained showed the relevance of the proposed framework comparing to state-of-the-art models.
MIX'EM: Unsupervised Image Classification using a Mixture of Embeddings
Jul 18, 2020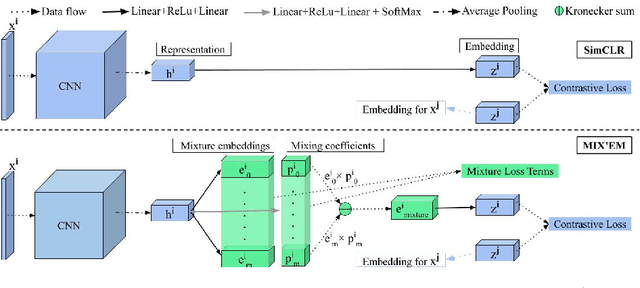
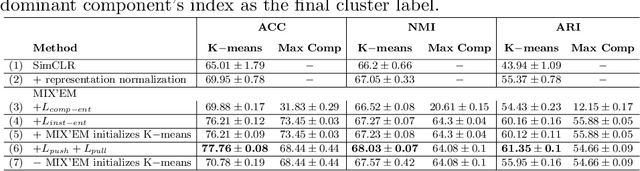
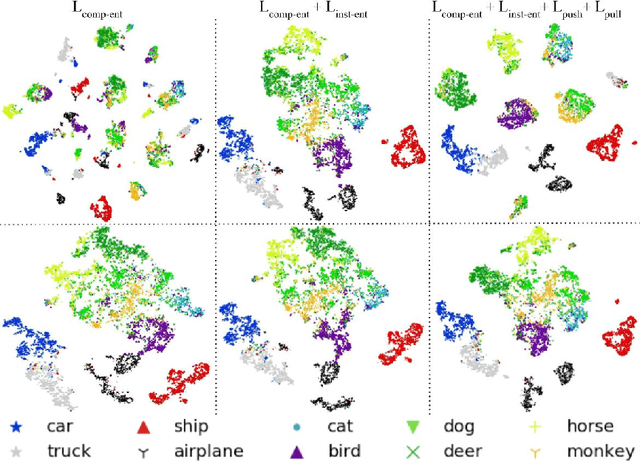
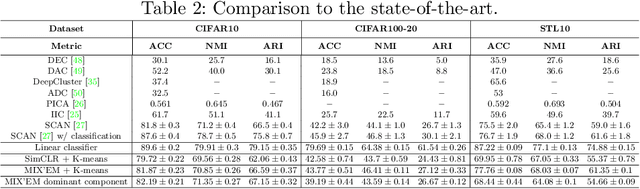
We present MIX'EM, a novel solution for unsupervised image classification. Our model generates representations that by themselves are sufficient to drive a general-purpose clustering method to deliver high-quality classification without supervision. MIX'EM integrates an internal mixture of embeddings module into the contrastive visual representation learning framework to disentangle the representation space at the category level. It generates a set of embeddings from a visual representation and mixes them to construct the contrastive loss input. Parallel to the contrastive loss, we introduce three techniques to train MIX'EM and avoid a degenerate solution; (i) we maximize entropy across mixture components to diversify them, and (ii) minimize component entropy conditioned on instances to enforce a clustered embedding space. Applying (i) and (ii) lead to the emergence of semantic categories through the mixture coefficients, making it possible to (iii) apply an associative embedding loss to enforce semantic separability directly. Subsequently, we run K-means on the representations to acquire semantic classification, which outperforms the state-of-the-art by a large margin. We conduct extensive experiments and analyses on STL10, CIFAR10, and CIFAR100-20 datasets, achieving 78\%, 82\%, and 44\% accuracy, respectively. Essential to robust high accuracy is using MIX'EM to initialize K-means. Finally, we report impressively high accuracy baselines (70\% on STL10) achieved solely by applying K-means to the "normalized" representations learned using the contrastive loss.
Multi-modal Conditional Bounding Box Regression for Music Score Following
May 10, 2021
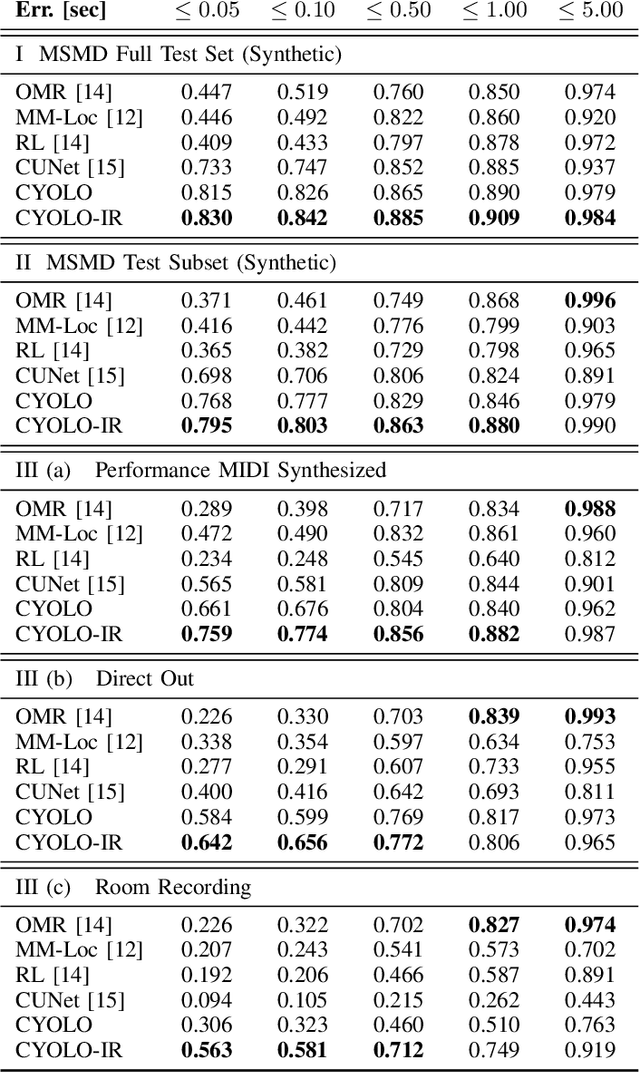
This paper addresses the problem of sheet-image-based on-line audio-to-score alignment also known as score following. Drawing inspiration from object detection, a conditional neural network architecture is proposed that directly predicts x,y coordinates of the matching positions in a complete score sheet image at each point in time for a given musical performance. Experiments are conducted on a synthetic polyphonic piano benchmark dataset and the new method is compared to several existing approaches from the literature for sheet-image-based score following as well as an Optical Music Recognition baseline. The proposed approach achieves new state-of-the-art results and furthermore significantly improves the alignment performance on a set of real-world piano recordings by applying Impulse Responses as a data augmentation technique.
Comparison of the P300 detection accuracy related to the BCI speller and image recognition scenarios
Dec 24, 2019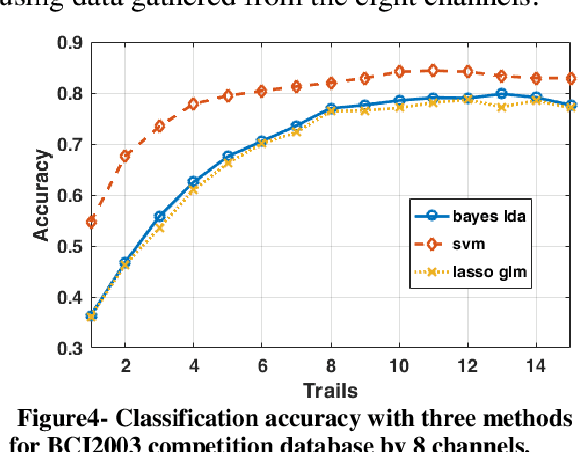
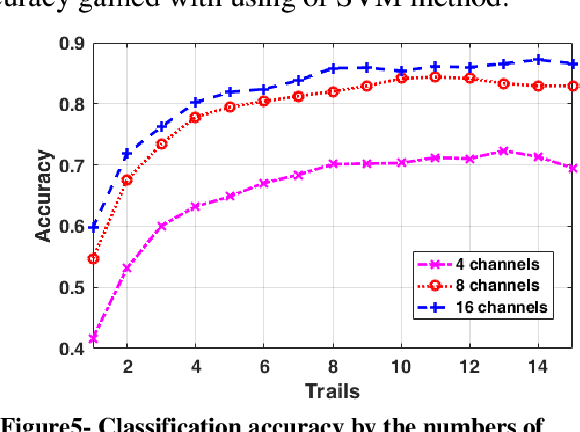
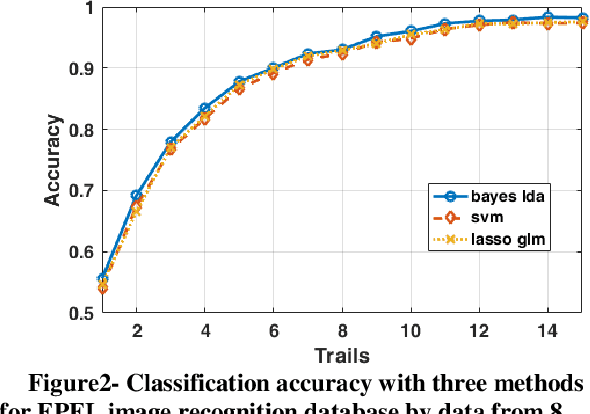
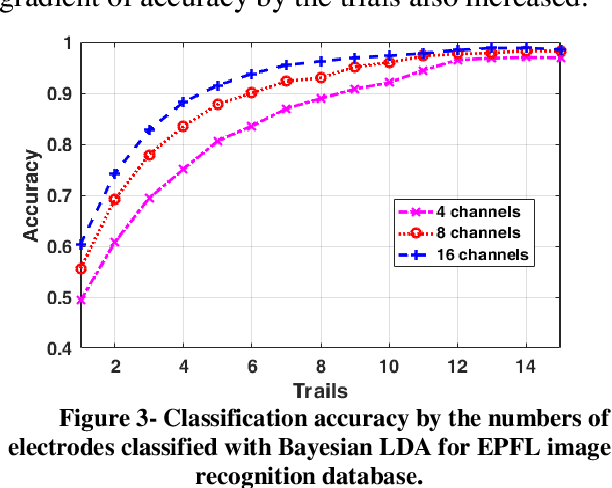
There are several protocols in the Electroencephalography (EEG) recording scenarios which produce various types of event-related potentials (ERP). P300 pattern is a well-known ERP which produced by auditory and visual oddball paradigm and BCI speller system. In this study, P300 and non-P300 separability are investigated in two scenarios including image recognition paradigm and BCI speller. Image recognition scenario is an experiment that examines the participants, knowledge about an image that shown to them before by analyzing the EEG signal recorded during the observing of that image as visual stimulation. To do this, three types of famous classifiers (SVM, Bayes LDA, and sparse logistic regression) were used to classify EEG recordings in six classes problem. Filtered and down-sampled (temporal samples) of EEG recording were considered as features in classification P300 pattern. Also, different sets of EEG recording including 4, 8 and 16 channels and different trial numbers were used to considering various situations in comparison. The accuracy was increased by increasing the number of trials and channels. The results prove that better accuracy is observed in the case of the image recognition scenario for the different sets of channels and by using the different number of trials. So it can be concluded that P300 pattern which produced in image recognition paradigm is more separable than BCI (matrix speller).
Region-adaptive Texture Enhancement for Detailed Person Image Synthesis
May 26, 2020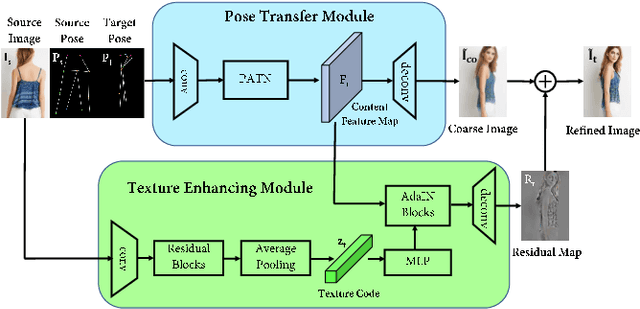
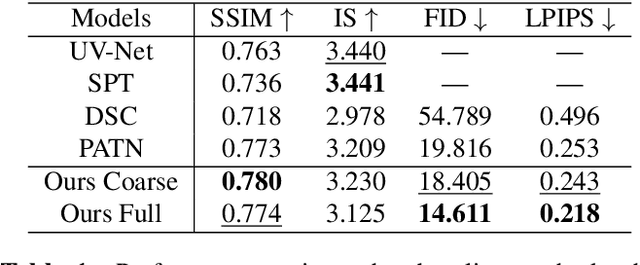

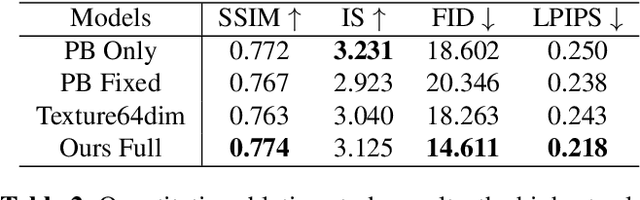
The ability to produce convincing textural details is essential for the fidelity of synthesized person images. However, existing methods typically follow a ``warping-based'' strategy that propagates appearance features through the same pathway used for pose transfer. However, most fine-grained features would be lost due to down-sampling, leading to over-smoothed clothes and missing details in the output images. In this paper we presents RATE-Net, a novel framework for synthesizing person images with sharp texture details. The proposed framework leverages an additional texture enhancing module to extract appearance information from the source image and estimate a fine-grained residual texture map, which helps to refine the coarse estimation from the pose transfer module. In addition, we design an effective alternate updating strategy to promote mutual guidance between two modules for better shape and appearance consistency. Experiments conducted on DeepFashion benchmark dataset have demonstrated the superiority of our framework compared with existing networks.
Gradient Step Denoiser for convergent Plug-and-Play
Oct 07, 2021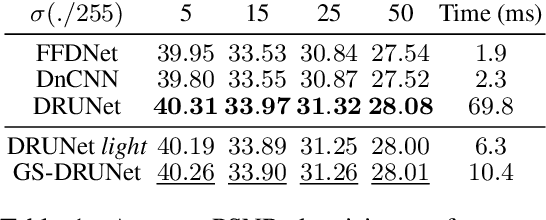
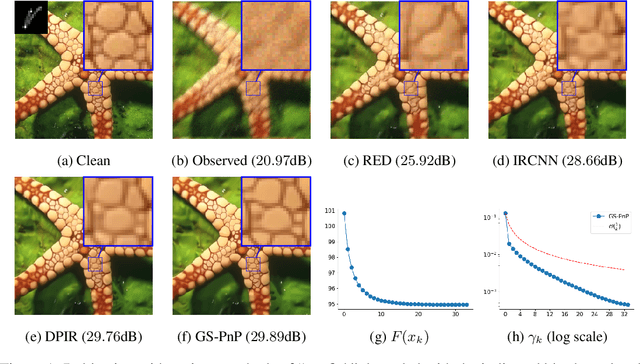
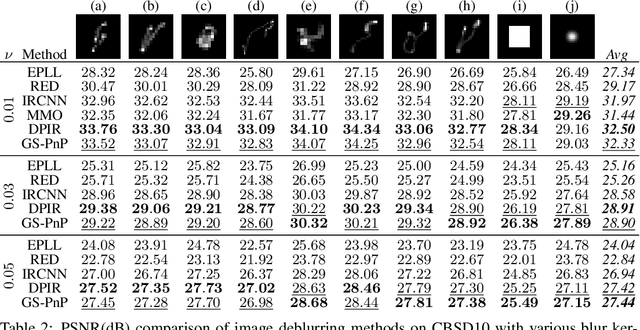
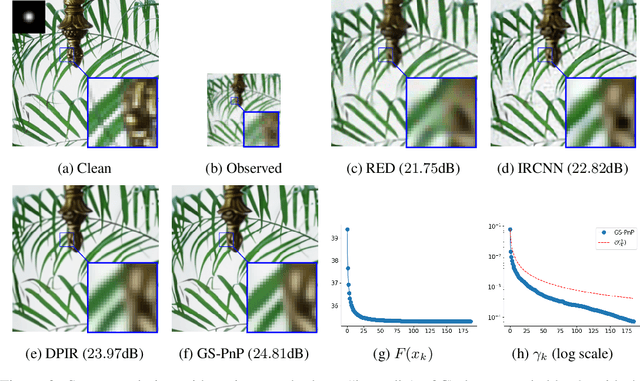
Plug-and-Play methods constitute a class of iterative algorithms for imaging problems where regularization is performed by an off-the-shelf denoiser. Although Plug-and-Play methods can lead to tremendous visual performance for various image problems, the few existing convergence guarantees are based on unrealistic (or suboptimal) hypotheses on the denoiser, or limited to strongly convex data terms. In this work, we propose a new type of Plug-and-Play methods, based on half-quadratic splitting, for which the denoiser is realized as a gradient descent step on a functional parameterized by a deep neural network. Exploiting convergence results for proximal gradient descent algorithms in the non-convex setting, we show that the proposed Plug-and-Play algorithm is a convergent iterative scheme that targets stationary points of an explicit global functional. Besides, experiments show that it is possible to learn such a deep denoiser while not compromising the performance in comparison to other state-of-the-art deep denoisers used in Plug-and-Play schemes. We apply our proximal gradient algorithm to various ill-posed inverse problems, e.g. deblurring, super-resolution and inpainting. For all these applications, numerical results empirically confirm the convergence results. Experiments also show that this new algorithm reaches state-of-the-art performance, both quantitatively and qualitatively.
Convolutional versus Dense Neural Networks: Comparing the Two Neural Networks Performance in Predicting Building Operational Energy Use Based on the Building Shape
Aug 29, 2021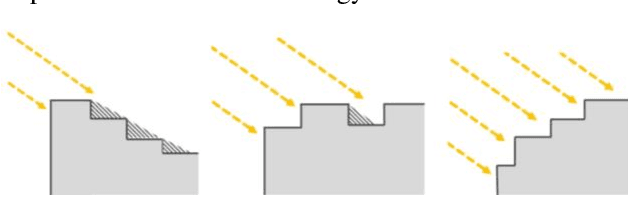
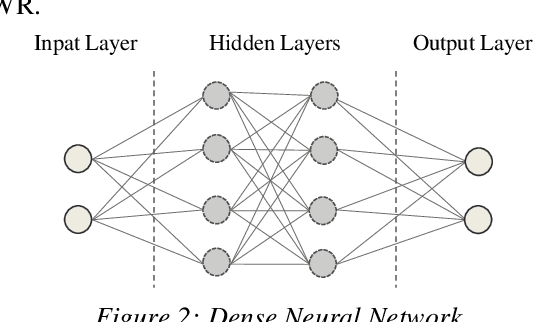
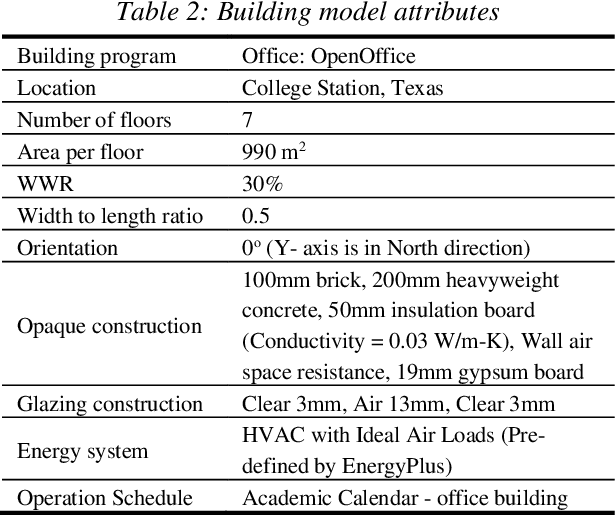
A building self-shading shape impacts substantially on the amount of direct sunlight received by the building and contributes significantly to building operational energy use, in addition to other major contributing variables, such as materials and window-to-wall ratios. Deep Learning has the potential to assist designers and engineers by efficiently predicting building energy performance. This paper assesses the applicability of two different neural networks structures, Dense Neural Network (DNN) and Convolutional Neural Network (CNN), for predicting building operational energy use with respect to building shape. The comparison between the two neural networks shows that the DNN model surpasses the CNN model in performance, simplicity, and computation time. However, image-based CNN has the benefit of utilizing architectural graphics that facilitates design communication.
Deep Multimodal Image-Text Embeddings for Automatic Cross-Media Retrieval
Feb 23, 2020
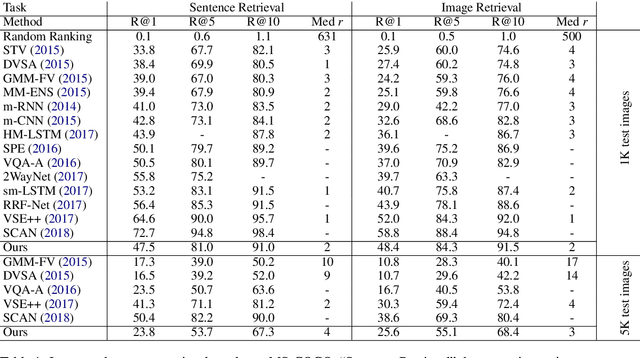
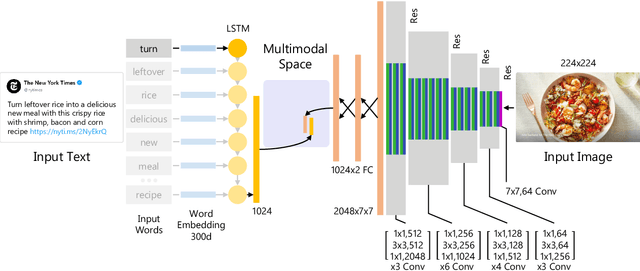
This paper considers the task of matching images and sentences by learning a visual-textual embedding space for cross-modal retrieval. Finding such a space is a challenging task since the features and representations of text and image are not comparable. In this work, we introduce an end-to-end deep multimodal convolutional-recurrent network for learning both vision and language representations simultaneously to infer image-text similarity. The model learns which pairs are a match (positive) and which ones are a mismatch (negative) using a hinge-based triplet ranking. To learn about the joint representations, we leverage our newly extracted collection of tweets from Twitter. The main characteristic of our dataset is that the images and tweets are not standardized the same as the benchmarks. Furthermore, there can be a higher semantic correlation between the pictures and tweets contrary to benchmarks in which the descriptions are well-organized. Experimental results on MS-COCO benchmark dataset show that our model outperforms certain methods presented previously and has competitive performance compared to the state-of-the-art. The code and dataset have been made available publicly.
Subjective and Objective De-raining Quality Assessment Towards Authentic Rain Image
Sep 29, 2019
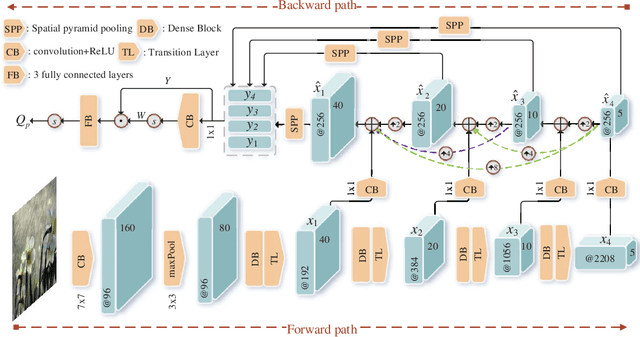
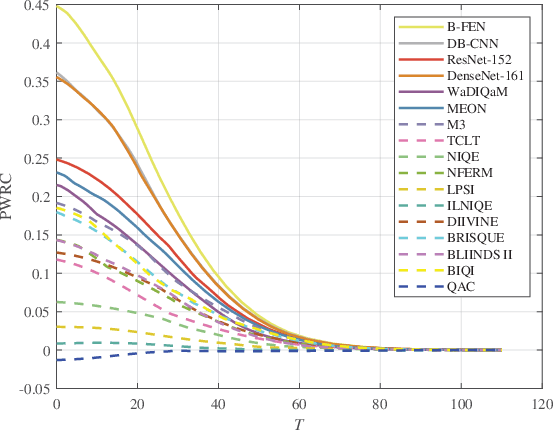

Images acquired by outdoor vision systems easily suffer poor visibility and annoying interference due to the rainy weather, which brings great challenge for accurately understanding and describing the visual contents. Recent researches have devoted great efforts on the task of rain removal for improving the image visibility. However, there is very few exploration about the quality assessment of de-rained image, even it is crucial for accurately measuring the performance of various de-raining algorithms. In this paper, we first create a de-raining quality assessment (DQA) database that collects 206 authentic rain images and their de-rained versions produced by 6 representative single image rain removal algorithms. Then, a subjective study is conducted on our DQA database, which collects the subject-rated scores of all de-rained images. To quantitatively measure the quality of de-rained image with non-uniform artifacts, we propose a bi-directional feature embedding network (B-FEN) which integrates the features of global perception and local difference together. Experiments confirm that the proposed method significantly outperforms many existing universal blind image quality assessment models. To help the research towards perceptually preferred de-raining algorithm, we will publicly release our DQA database and B-FEN source code on https://github.com/wqb-uestc.
BigEarthNet Dataset with A New Class-Nomenclature for Remote Sensing Image Understanding
Feb 18, 2020


This paper presents BigEarthNet that is a large-scale Sentinel-2 multispectral image dataset with a new class nomenclature to advance deep learning (DL) studies in remote sensing (RS). BigEarthNet is made up of 590,326 image patches annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its most thematic detailed Level-3 class nomenclature. Initial research demonstrates that some CLC classes are challenging to be accurately described by considering only Sentinel-2 images. To increase the effectiveness of BigEarthNet, in this paper we introduce an alternative class-nomenclature to allow DL models for better learning and describing the complex spatial and spectral information content of the Sentinel-2 images. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of Sentinel-2 images in a new nomenclature of 19 classes. Then, the new class-nomenclature of BigEarthNet is used within state-of-the-art DL models in the context of multi-label classification. Results show that the models trained from scratch on BigEarthNet outperform those pre-trained on ImageNet, especially in relation to some complex classes including agriculture, other vegetated and natural environments. All DL models are made publicly available at http://bigearth.net/#downloads, offering an important resource to guide future progress on RS image analysis.