 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Synthesis of Adversarial Visual Examples Using a Deep Image Prior
Jul 03, 2019




We present a novel method for generating robust adversarial image examples building upon the recent `deep image prior' (DIP) that exploits convolutional network architectures to enforce plausible texture in image synthesis. Adversarial images are commonly generated by perturbing images to introduce high frequency noise that induces image misclassification, but that is fragile to subsequent digital manipulation of the image. We show that using DIP to reconstruct an image under adversarial constraint induces perturbations that are more robust to affine deformation, whilst remaining visually imperceptible. Furthermore we show that our DIP approach can also be adapted to produce local adversarial patches (`adversarial stickers'). We demonstrate robust adversarial examples over a broad gamut of images and object classes drawn from the ImageNet dataset.
Transform-Invariant Convolutional Neural Networks for Image Classification and Search
Nov 28, 2019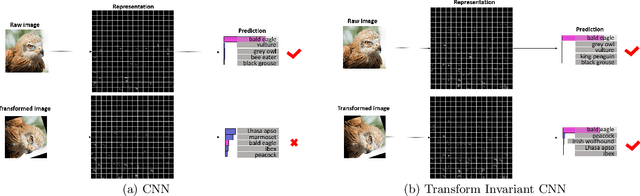
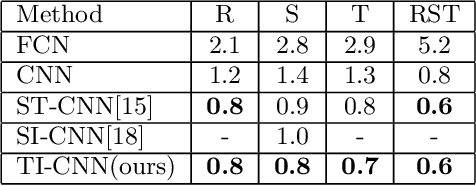
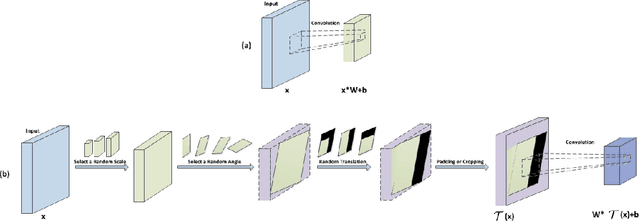
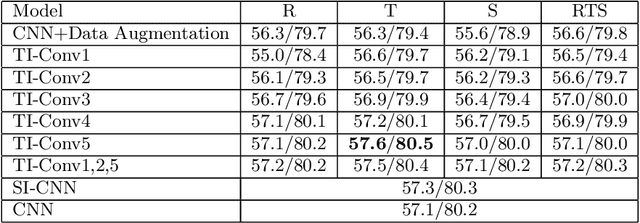
Convolutional neural networks (CNNs) have achieved state-of-the-art results on many visual recognition tasks. However, current CNN models still exhibit a poor ability to be invariant to spatial transformations of images. Intuitively, with sufficient layers and parameters, hierarchical combinations of convolution (matrix multiplication and non-linear activation) and pooling operations should be able to learn a robust mapping from transformed input images to transform-invariant representations. In this paper, we propose randomly transforming (rotation, scale, and translation) feature maps of CNNs during the training stage. This prevents complex dependencies of specific rotation, scale, and translation levels of training images in CNN models. Rather, each convolutional kernel learns to detect a feature that is generally helpful for producing the transform-invariant answer given the combinatorially large variety of transform levels of its input feature maps. In this way, we do not require any extra training supervision or modification to the optimization process and training images. We show that random transformation provides significant improvements of CNNs on many benchmark tasks, including small-scale image recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com/jasonustc/caffe-multigpu/tree/TICNN.
SOLVER: Scene-Object Interrelated Visual Emotion Reasoning Network
Oct 24, 2021


Visual Emotion Analysis (VEA) aims at finding out how people feel emotionally towards different visual stimuli, which has attracted great attention recently with the prevalence of sharing images on social networks. Since human emotion involves a highly complex and abstract cognitive process, it is difficult to infer visual emotions directly from holistic or regional features in affective images. It has been demonstrated in psychology that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. Inspired by this, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict emotions from images. To mine the emotional relationships between distinct objects, we first build up an Emotion Graph based on semantic concepts and visual features. Then, we conduct reasoning on the Emotion Graph using Graph Convolutional Network (GCN), yielding emotion-enhanced object features. We also design a Scene-Object Fusion Module to integrate scenes and objects, which exploits scene features to guide the fusion process of object features with the proposed scene-based attention mechanism. Extensive experiments and comparisons are conducted on eight public visual emotion datasets, and the results demonstrate that the proposed SOLVER consistently outperforms the state-of-the-art methods by a large margin. Ablation studies verify the effectiveness of our method and visualizations prove its interpretability, which also bring new insight to explore the mysteries in VEA. Notably, we further discuss SOLVER on three other potential datasets with extended experiments, where we validate the robustness of our method and notice some limitations of it.
* Accepted by TIP
Few-shot Semantic Image Synthesis Using StyleGAN Prior
Mar 27, 2021
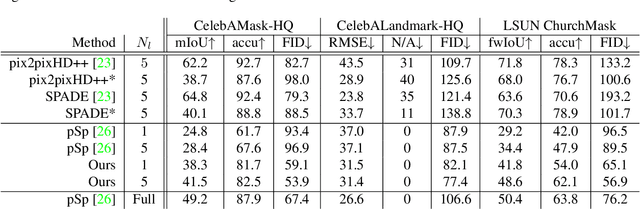

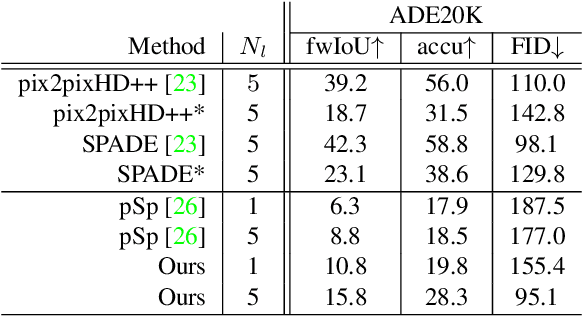
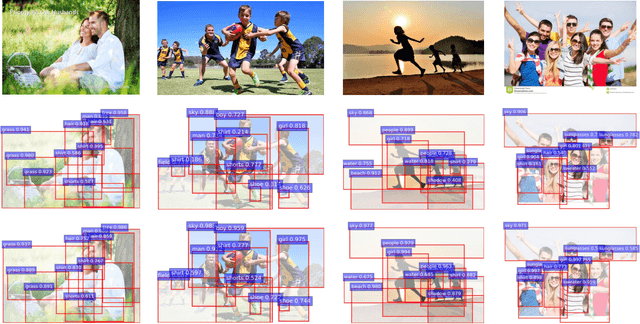
This paper tackles a challenging problem of generating photorealistic images from semantic layouts in few-shot scenarios where annotated training pairs are hardly available but pixel-wise annotation is quite costly. We present a training strategy that performs pseudo labeling of semantic masks using the StyleGAN prior. Our key idea is to construct a simple mapping between the StyleGAN feature and each semantic class from a few examples of semantic masks. With such mappings, we can generate an unlimited number of pseudo semantic masks from random noise to train an encoder for controlling a pre-trained StyleGAN generator. Although the pseudo semantic masks might be too coarse for previous approaches that require pixel-aligned masks, our framework can synthesize high-quality images from not only dense semantic masks but also sparse inputs such as landmarks and scribbles. Qualitative and quantitative results with various datasets demonstrate improvement over previous approaches with respect to layout fidelity and visual quality in as few as one- or five-shot settings.
Breast Cancer: Model Reconstruction and Image Registration from Segmented Deformed Image using Visual and Force based Analysis
Feb 14, 2019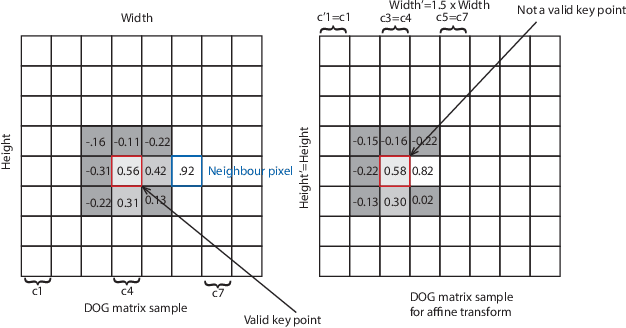

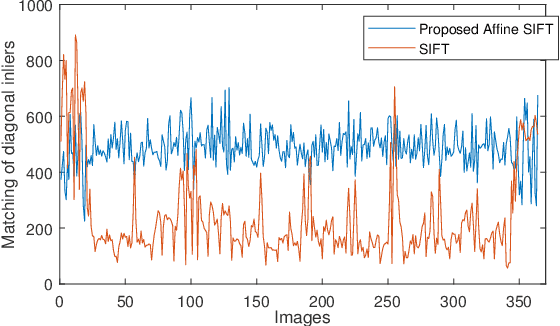
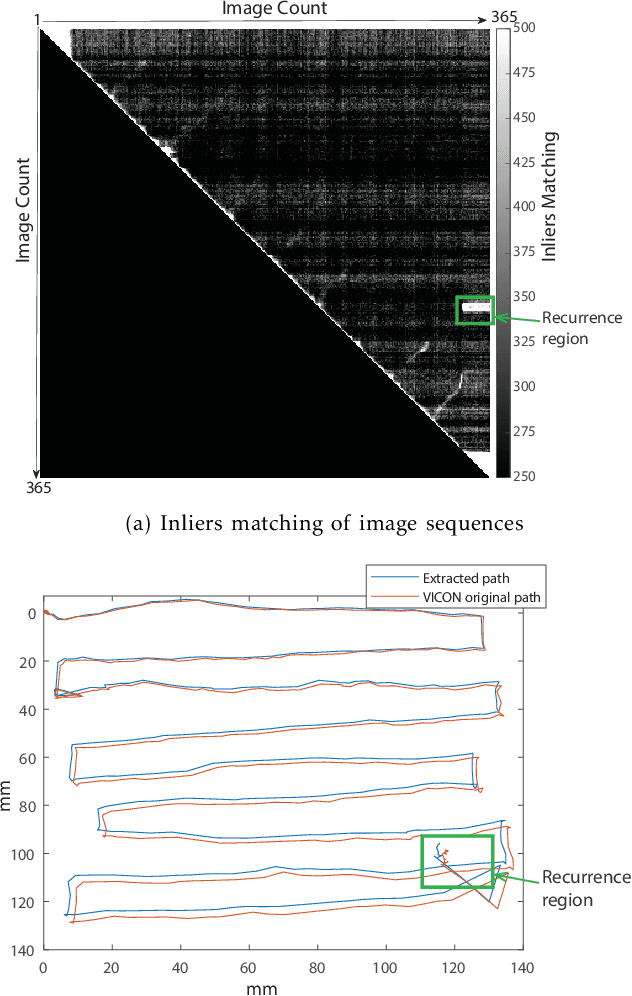
Breast lesion localization using tactile imaging is a new and developing direction in medical science. To achieve the goal, proper image reconstruction and image registration can be a valuable asset. In this paper, a new approach of the segmentation-based image surface reconstruction algorithm is used to reconstruct the surface of a breast phantom. In breast tissue, the sub-dermal vein network is used as a distinguishable pattern for reconstruction. The proposed image capturing device contacts the surface of the phantom, and surface deformation will occur due to applied force at the time of scanning. A novel force based surface rectification system is used to reconstruct a deformed surface image to its original structure. For the construction of the full surface from rectified images, advanced affine scale-invariant feature transform (A-SIFT) is proposed to reduce the affine effect in time when data capturing. Camera position based image stitching approach is applied to construct the final original non-rigid surface. The proposed model is validated in theoretical models and real scenarios, to demonstrate its advantages with respect to competing methods. The result of the proposed method, applied to path reconstruction, ends with a positioning accuracy of 99.7%
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
Aug 20, 2021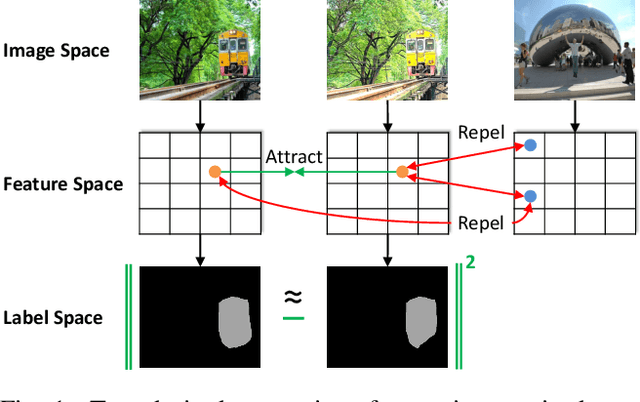
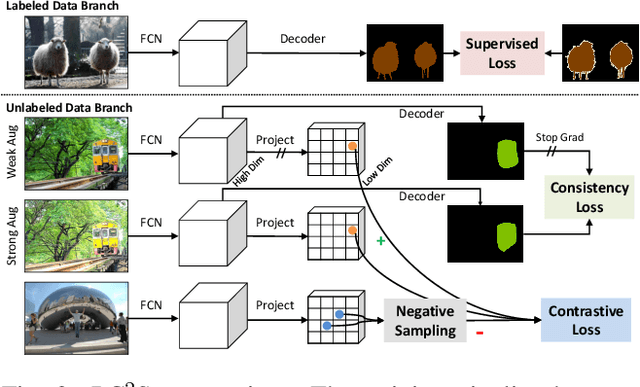
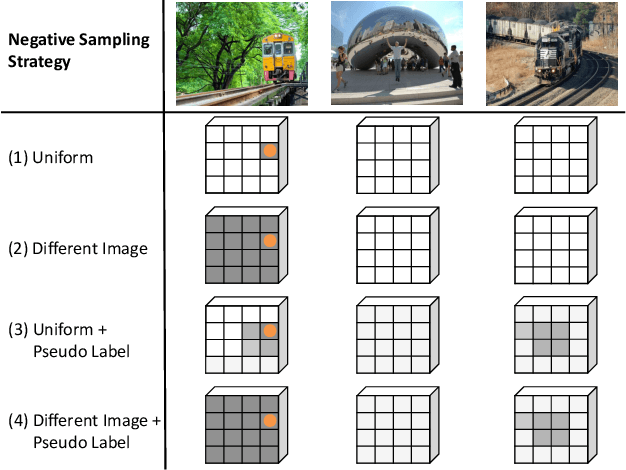

We present a novel semi-supervised semantic segmentation method which jointly achieves two desiderata of segmentation model regularities: the label-space consistency property between image augmentations and the feature-space contrastive property among different pixels. We leverage the pixel-level L2 loss and the pixel contrastive loss for the two purposes respectively. To address the computational efficiency issue and the false negative noise issue involved in the pixel contrastive loss, we further introduce and investigate several negative sampling techniques. Extensive experiments demonstrate the state-of-the-art performance of our method (PC2Seg) with the DeepLab-v3+ architecture, in several challenging semi-supervised settings derived from the VOC, Cityscapes, and COCO datasets.
Scalable and accurate multi-GPU based image reconstruction of large-scale ptychography data
Jun 14, 2021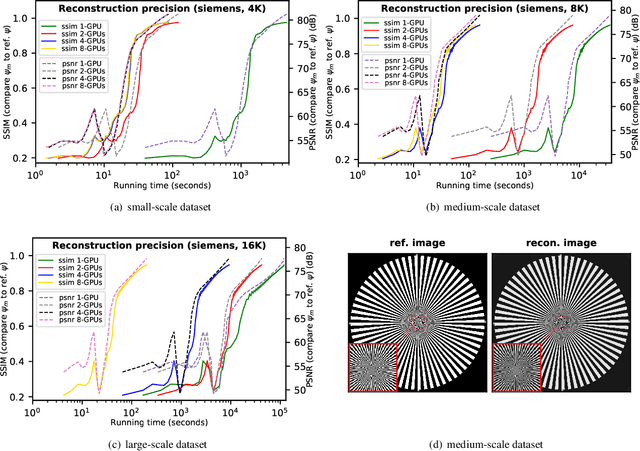
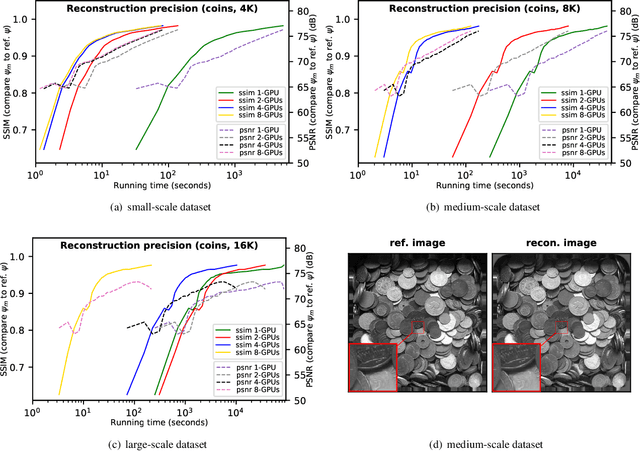
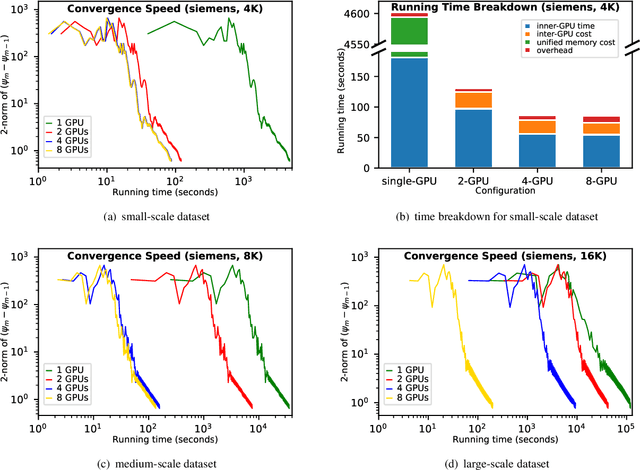
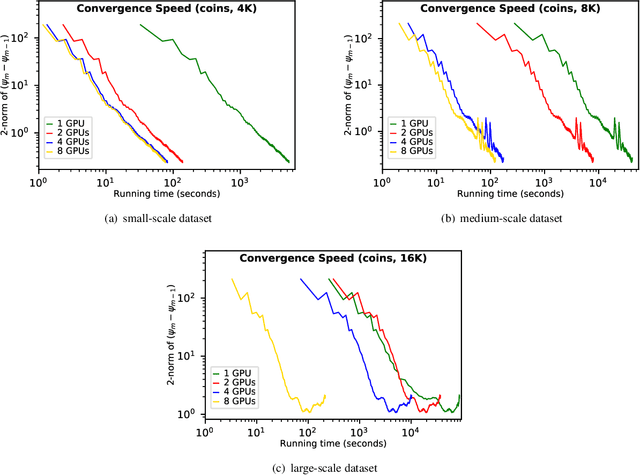
While the advances in synchrotron light sources, together with the development of focusing optics and detectors, allow nanoscale ptychographic imaging of materials and biological specimens, the corresponding experiments can yield terabyte-scale large volumes of data that can impose a heavy burden on the computing platform. While Graphical Processing Units (GPUs) provide high performance for such large-scale ptychography datasets, a single GPU is typically insufficient for analysis and reconstruction. Several existing works have considered leveraging multiple GPUs to accelerate the ptychographic reconstruction. However, they utilize only Message Passing Interface (MPI) to handle the communications between GPUs. It poses inefficiency for the configuration that has multiple GPUs in a single node, especially while processing a single large projection, since it provides no optimizations to handle the heterogeneous GPU interconnections containing both low-speed links, e.g., PCIe, and high-speed links, e.g., NVLink. In this paper, we provide a multi-GPU implementation that can effectively solve large-scale ptychographic reconstruction problem with optimized performance on intra-node multi-GPU. We focus on the conventional maximum-likelihood reconstruction problem using conjugate-gradient (CG) for the solution and propose a novel hybrid parallelization model to address the performance bottlenecks in CG solver. Accordingly, we develop a tool called PtyGer (Ptychographic GPU(multiple)-based reconstruction), implementing our hybrid parallelization model design. The comprehensive evaluation verifies that PtyGer can fully preserve the original algorithm's accuracy while achieving outstanding intra-node GPU scalability.
Determination of the Interface between Amorphous Insulator and Crystalline 4H-SiC in Transmission Electron Microscope Image by using Convolutional Neural Network
Oct 14, 2020


A rough interface seems to be one of the possible reasons for low channel mobility (conductivity) in SiC MOSFETs. To evaluate the mobility by interface roughness, we drew a boundary line between amorphous insulator and crystalline 4H-SiC in a cross-sectional image obtained by a transmission electron microscope (TEM), by using the deep learning approach of convolutional neural network (CNN). We show that the CNN model recognizes the interface very well, even when the interface is too rough to draw the boundary line manually. Power spectral density of interface roughness was calculated.
Camera Calibration through Camera Projection Loss
Oct 07, 2021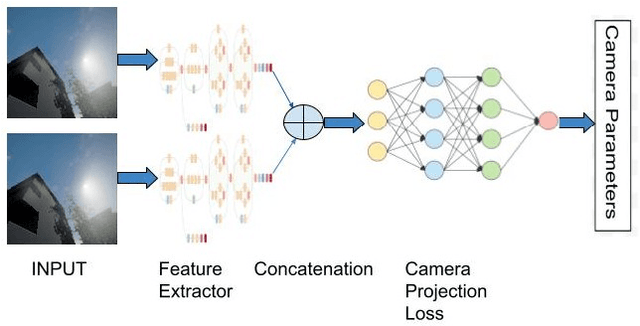



Camera calibration is a necessity in various tasks including 3D reconstruction, hand-eye coordination for a robotic interaction, autonomous driving, etc. In this work we propose a novel method to predict extrinsic (baseline, pitch, and translation), intrinsic (focal length and principal point offset) parameters using an image pair. Unlike existing methods, instead of designing an end-to-end solution, we proposed a new representation that incorporates camera model equations as a neural network in multi-task learning framework. We estimate the desired parameters via novel \emph{camera projection loss} (CPL) that uses the camera model neural network to reconstruct the 3D points and uses the reconstruction loss to estimate the camera parameters. To the best of our knowledge, ours is the first method to jointly estimate both the intrinsic and extrinsic parameters via a multi-task learning methodology that combines analytical equations in learning framework for the estimation of camera parameters. We also proposed a novel dataset using CARLA Simulator. Empirically, we demonstrate that our proposed approach achieves better performance with respect to both deep learning-based and traditional methods on 7 out of 10 parameters evaluated using both synthetic and real data. Our code and generated dataset will be made publicly available to facilitate future research.
Robust Tensor Decomposition for Image Representation Based on Generalized Correntropy
May 10, 2020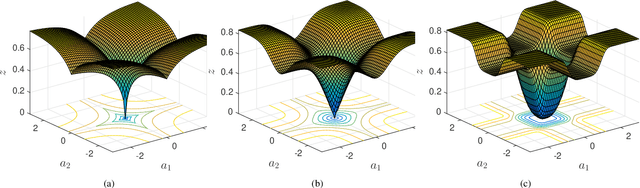
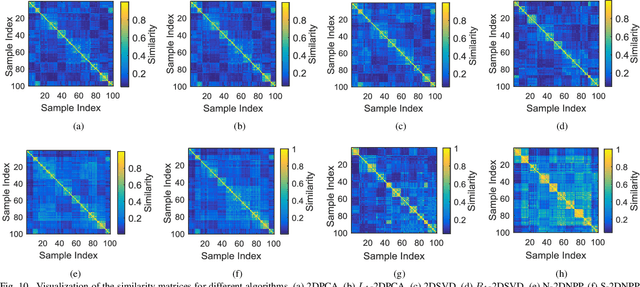
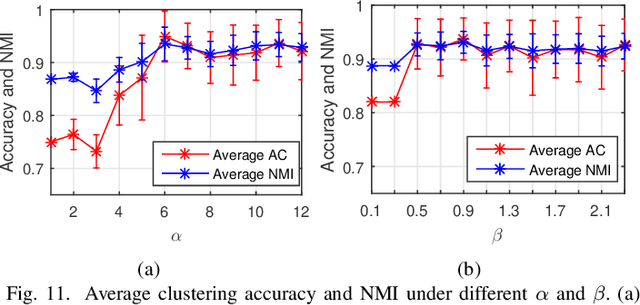
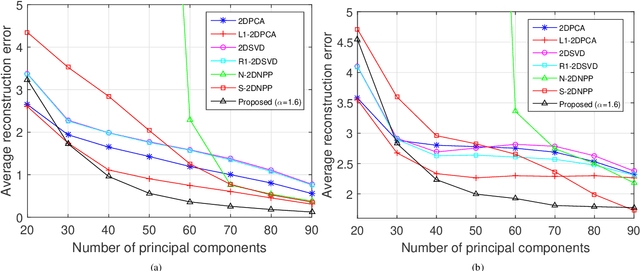
Traditional tensor decomposition methods, e.g., two dimensional principal component analysis and two dimensional singular value decomposition, that minimize mean square errors, are sensitive to outliers. To overcome this problem, in this paper we propose a new robust tensor decomposition method using generalized correntropy criterion (Corr-Tensor). A Lagrange multiplier method is used to effectively optimize the generalized correntropy objective function in an iterative manner. The Corr-Tensor can effectively improve the robustness of tensor decomposition with the existence of outliers without introducing any extra computational cost. Experimental results demonstrated that the proposed method significantly reduces the reconstruction error on face reconstruction and improves the accuracies on handwritten digit recognition and facial image clustering.