 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperspectral-Multispectral Image Fusion with Weighted LASSO
Mar 15, 2020
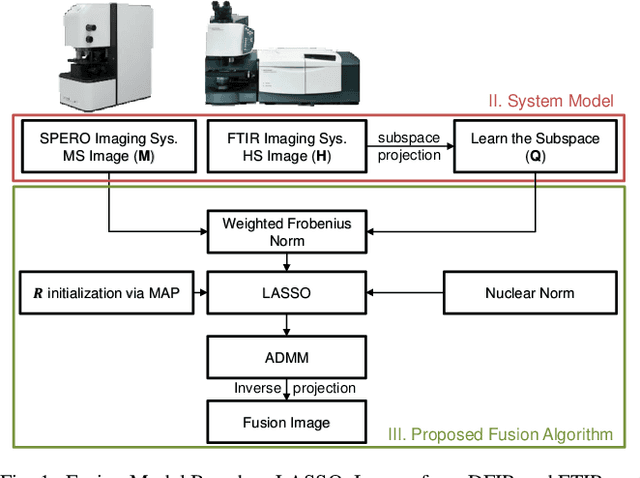

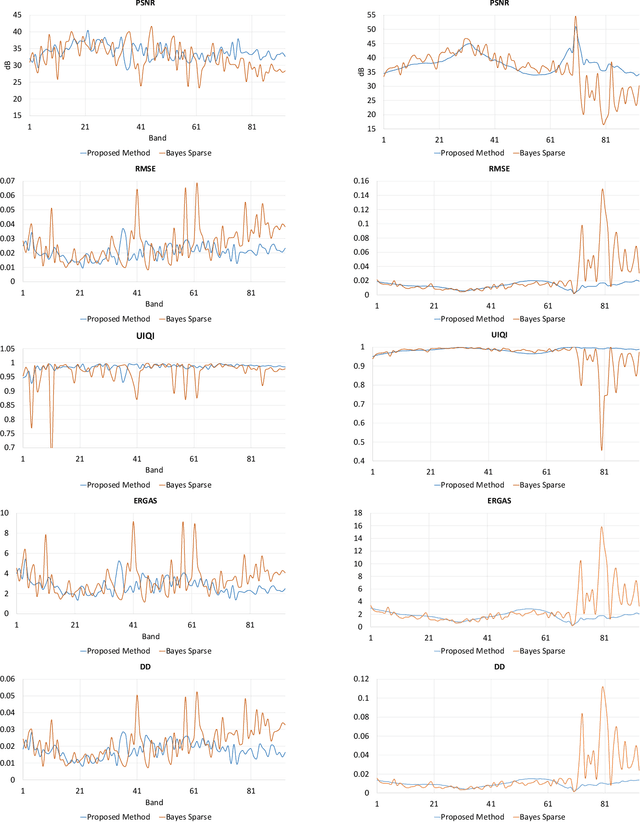
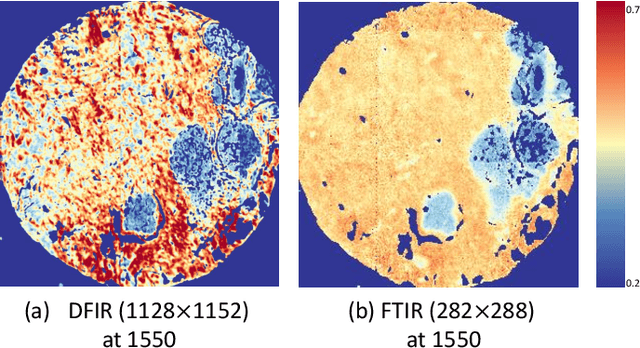
Spectral imaging enables spatially-resolved identification of materials in remote sensing, biomedicine, and astronomy. However, acquisition times require balancing spectral and spatial resolution with signal-to-noise. Hyperspectral imaging provides superior material specificity, while multispectral images are faster to collect at greater fidelity. We propose an approach for fusing hyperspectral and multispectral images to provide high-quality hyperspectral output. The proposed optimization leverages the least absolute shrinkage and selection operator (LASSO) to perform variable selection and regularization. Computational time is reduced by applying the alternating direction method of multipliers (ADMM), as well as initializing the fusion image by estimating it using maximum a posteriori (MAP) based on Hardie's method. We demonstrate that the proposed sparse fusion and reconstruction provides quantitatively superior results when compared to existing methods on publicly available images. Finally, we show how the proposed method can be practically applied in biomedical infrared spectroscopic microscopy.
Cluster Analysis with Deep Embeddings and Contrastive Learning
Oct 02, 2021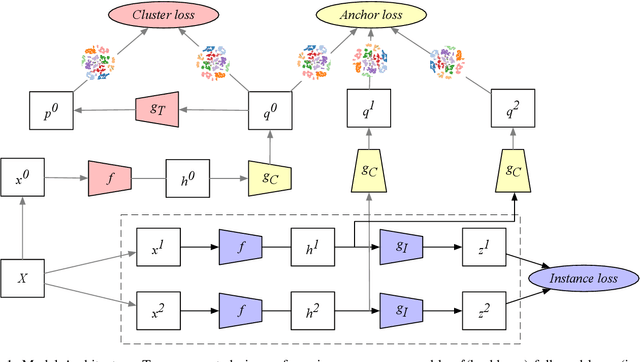
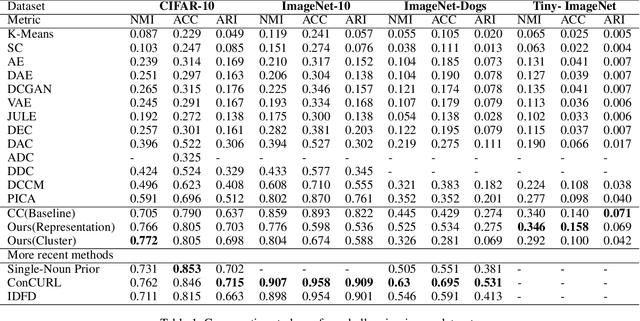
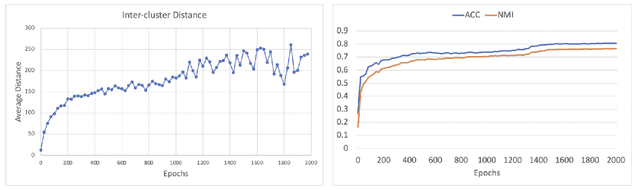
Unsupervised disentangled representation learning is a long-standing problem in computer vision. This work proposes a novel framework for performing image clustering from deep embeddings by combining instance-level contrastive learning with a deep embedding based cluster center predictor. Our approach jointly learns representations and predicts cluster centers in an end-to-end manner. This is accomplished via a three-pronged approach that combines a clustering loss, an instance-wise contrastive loss, and an anchor loss. Our fundamental intuition is that using an ensemble loss that incorporates instance-level features and a clustering procedure focusing on semantic similarity reinforces learning better representations in the latent space. We observe that our method performs exceptionally well on popular vision datasets when evaluated using standard clustering metrics such as Normalized Mutual Information (NMI), in addition to producing geometrically well-separated cluster embeddings as defined by the Euclidean distance. Our framework performs on par with widely accepted clustering methods and outperforms the state-of-the-art contrastive learning method on the CIFAR-10 dataset with an NMI score of 0.772, a 7-8% improvement on the strong baseline.
HCR-Net: A deep learning based script independent handwritten character recognition network
Aug 15, 2021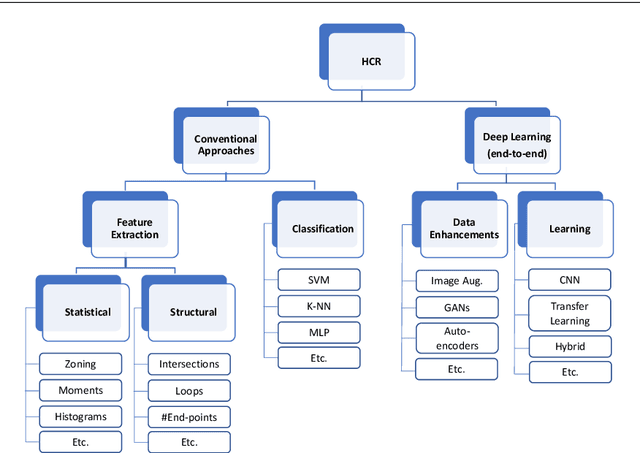
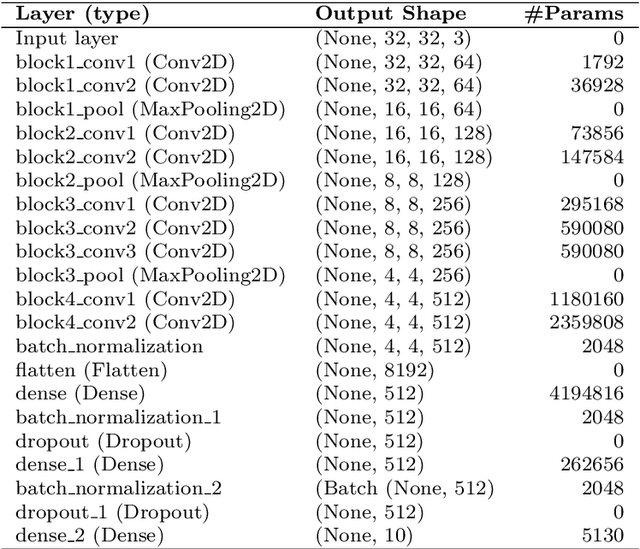


Handwritten character recognition (HCR) is a challenging learning problem in pattern recognition, mainly due to similarity in structure of characters, different handwriting styles, noisy datasets and a large variety of languages and scripts. HCR problem is studied extensively for a few decades but there is very limited research on script independent models. This is because of factors, like, diversity of scripts, focus of the most of conventional research efforts on handcrafted feature extraction techniques which are language/script specific and are not always available, and unavailability of public datasets and codes to reproduce the results. On the other hand, deep learning has witnessed huge success in different areas of pattern recognition, including HCR, and provides end-to-end learning, i.e., automated feature extraction and recognition. In this paper, we have proposed a novel deep learning architecture which exploits transfer learning and image-augmentation for end-to-end learning for script independent handwritten character recognition, called HCR-Net. The network is based on a novel transfer learning approach for HCR, where some of lower layers of a pre-trained VGG16 network are utilised. Due to transfer learning and image-augmentation, HCR-Net provides faster training, better performance and better generalisations. The experimental results on publicly available datasets of Bangla, Punjabi, Hindi, English, Swedish, Urdu, Farsi, Tibetan, Kannada, Malayalam, Telugu, Marathi, Nepali and Arabic languages prove the efficacy of HCR-Net and establishes several new benchmarks. For reproducibility of the results and for the advancements of the HCR research, complete code is publicly released at \href{https://github.com/jmdvinodjmd/HCR-Net}{GitHub}.
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Jul 27, 2021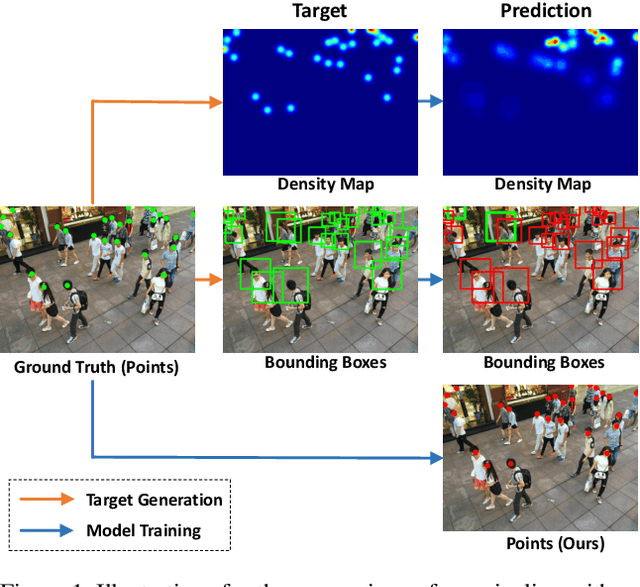
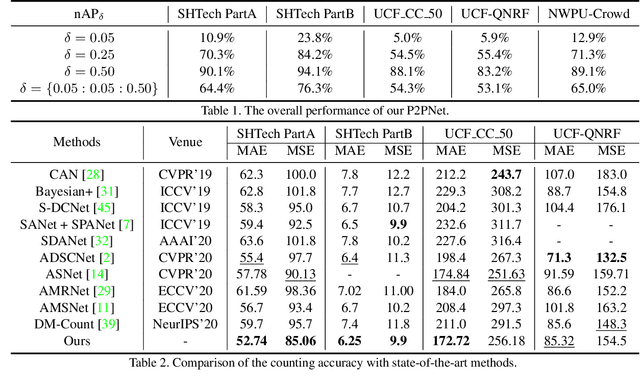
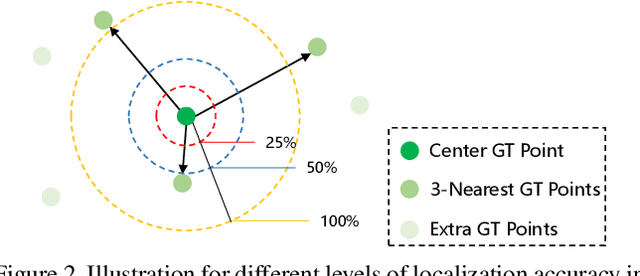
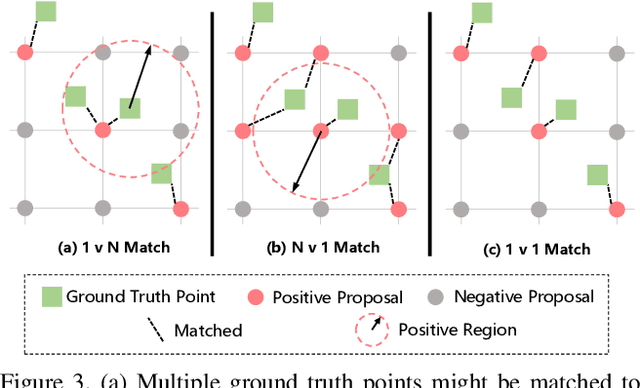
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.
Beyond Classification: Directly Training Spiking Neural Networks for Semantic Segmentation
Oct 14, 2021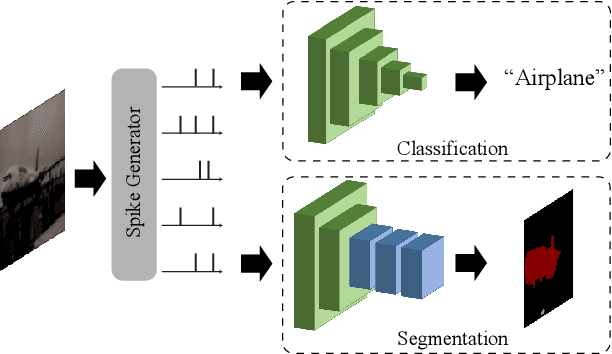
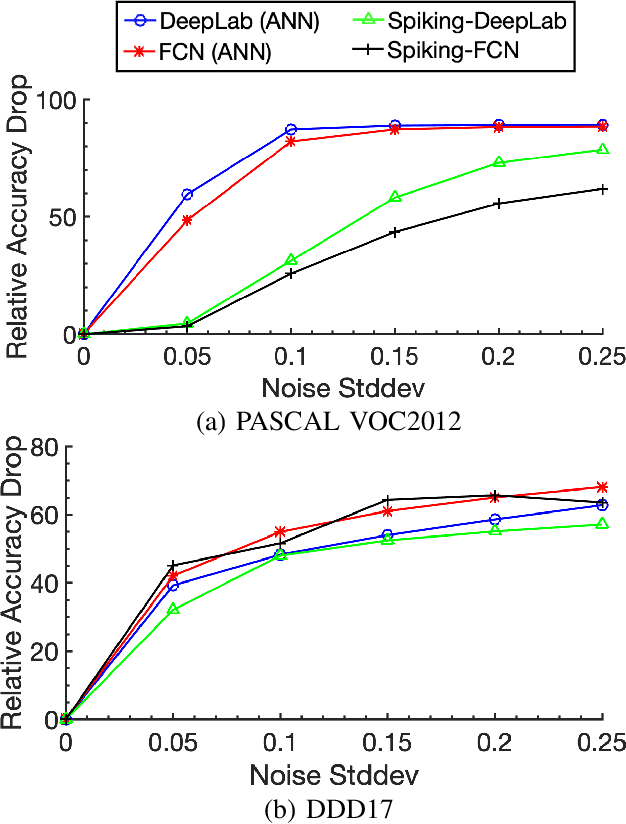
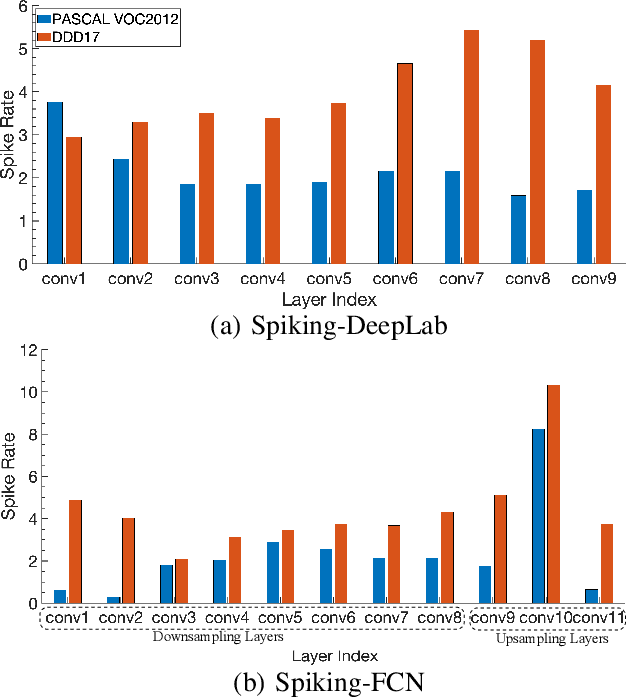
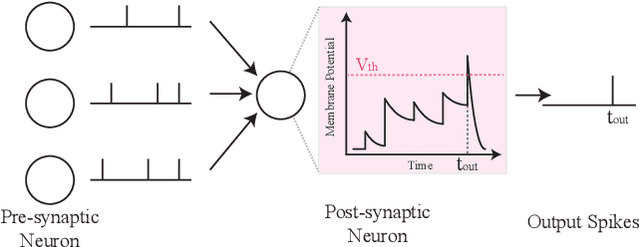
Spiking Neural Networks (SNNs) have recently emerged as the low-power alternative to Artificial Neural Networks (ANNs) because of their sparse, asynchronous, and binary event-driven processing. Due to their energy efficiency, SNNs have a high possibility of being deployed for real-world, resource-constrained systems such as autonomous vehicles and drones. However, owing to their non-differentiable and complex neuronal dynamics, most previous SNN optimization methods have been limited to image recognition. In this paper, we explore the SNN applications beyond classification and present semantic segmentation networks configured with spiking neurons. Specifically, we first investigate two representative SNN optimization techniques for recognition tasks (i.e., ANN-SNN conversion and surrogate gradient learning) on semantic segmentation datasets. We observe that, when converted from ANNs, SNNs suffer from high latency and low performance due to the spatial variance of features. Therefore, we directly train networks with surrogate gradient learning, resulting in lower latency and higher performance than ANN-SNN conversion. Moreover, we redesign two fundamental ANN segmentation architectures (i.e., Fully Convolutional Networks and DeepLab) for the SNN domain. We conduct experiments on two public semantic segmentation benchmarks including the PASCAL VOC2012 dataset and the DDD17 event-based dataset. In addition to showing the feasibility of SNNs for semantic segmentation, we show that SNNs can be more robust and energy-efficient compared to their ANN counterparts in this domain.
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
Jun 21, 2021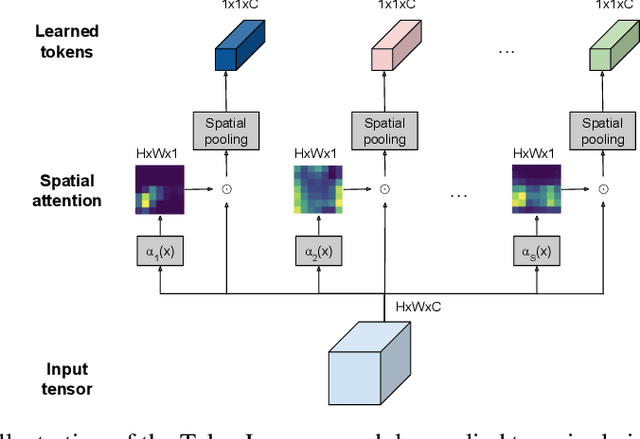
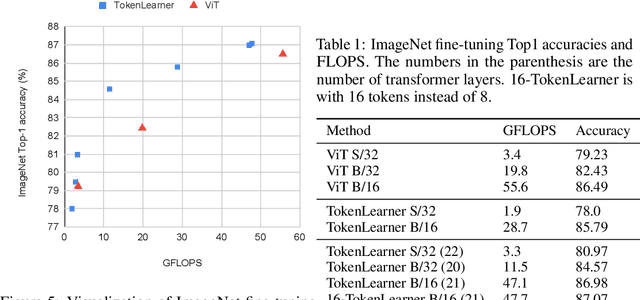
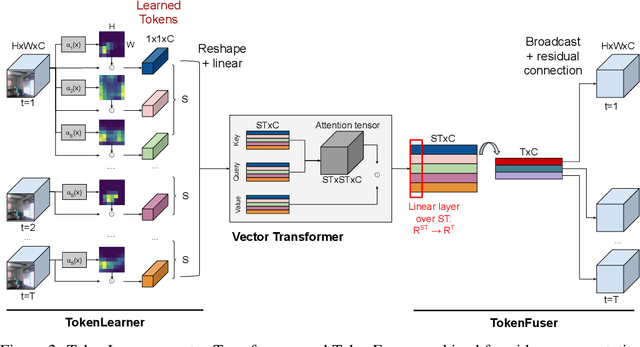

In this paper, we introduce a novel visual representation learning which relies on a handful of adaptively learned tokens, and which is applicable to both image and video understanding tasks. Instead of relying on hand-designed splitting strategies to obtain visual tokens and processing a large number of densely sampled patches for attention, our approach learns to mine important tokens in visual data. This results in efficiently and effectively finding a few important visual tokens and enables modeling of pairwise attention between such tokens, over a longer temporal horizon for videos, or the spatial content in images. Our experiments demonstrate strong performance on several challenging benchmarks for both image and video recognition tasks. Importantly, due to our tokens being adaptive, we accomplish competitive results at significantly reduced compute amount.
Contrastive Attention for Automatic Chest X-ray Report Generation
Jun 13, 2021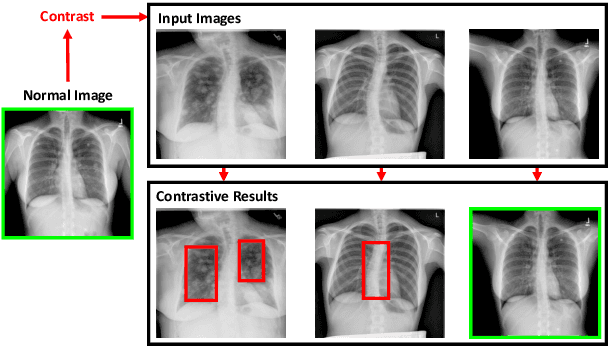
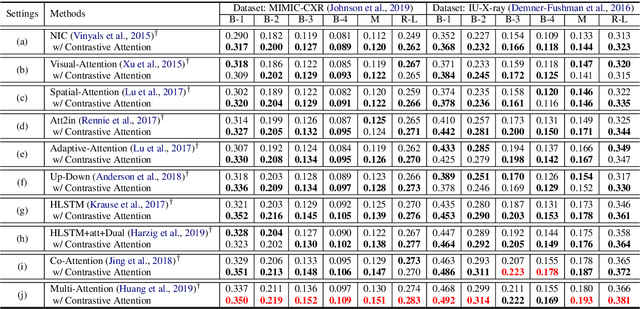
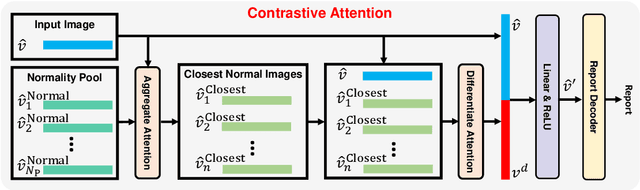

Recently, chest X-ray report generation, which aims to automatically generate descriptions of given chest X-ray images, has received growing research interests. The key challenge of chest X-ray report generation is to accurately capture and describe the abnormal regions. In most cases, the normal regions dominate the entire chest X-ray image, and the corresponding descriptions of these normal regions dominate the final report. Due to such data bias, learning-based models may fail to attend to abnormal regions. In this work, to effectively capture and describe abnormal regions, we propose the Contrastive Attention (CA) model. Instead of solely focusing on the current input image, the CA model compares the current input image with normal images to distill the contrastive information. The acquired contrastive information can better represent the visual features of abnormal regions. According to the experiments on the public IU-X-ray and MIMIC-CXR datasets, incorporating our CA into several existing models can boost their performance across most metrics. In addition, according to the analysis, the CA model can help existing models better attend to the abnormal regions and provide more accurate descriptions which are crucial for an interpretable diagnosis. Specifically, we achieve the state-of-the-art results on the two public datasets.
Transform-Invariant Convolutional Neural Networks for Image Classification and Search
Nov 28, 2019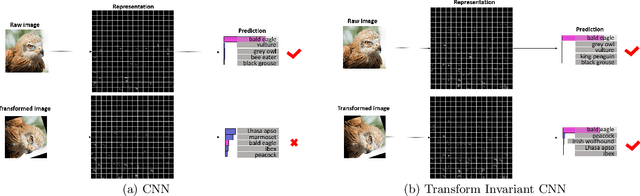
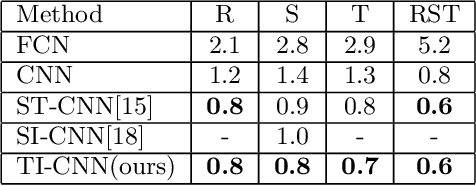
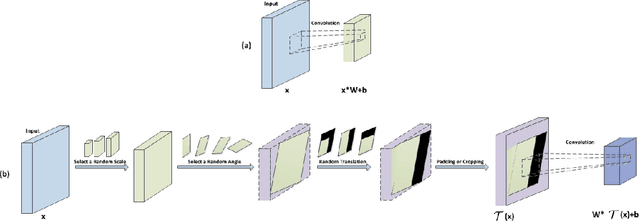
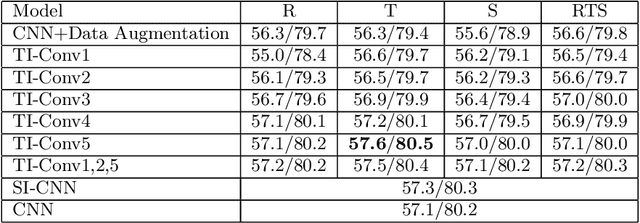
Convolutional neural networks (CNNs) have achieved state-of-the-art results on many visual recognition tasks. However, current CNN models still exhibit a poor ability to be invariant to spatial transformations of images. Intuitively, with sufficient layers and parameters, hierarchical combinations of convolution (matrix multiplication and non-linear activation) and pooling operations should be able to learn a robust mapping from transformed input images to transform-invariant representations. In this paper, we propose randomly transforming (rotation, scale, and translation) feature maps of CNNs during the training stage. This prevents complex dependencies of specific rotation, scale, and translation levels of training images in CNN models. Rather, each convolutional kernel learns to detect a feature that is generally helpful for producing the transform-invariant answer given the combinatorially large variety of transform levels of its input feature maps. In this way, we do not require any extra training supervision or modification to the optimization process and training images. We show that random transformation provides significant improvements of CNNs on many benchmark tasks, including small-scale image recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com/jasonustc/caffe-multigpu/tree/TICNN.
Playing for 3D Human Recovery
Oct 14, 2021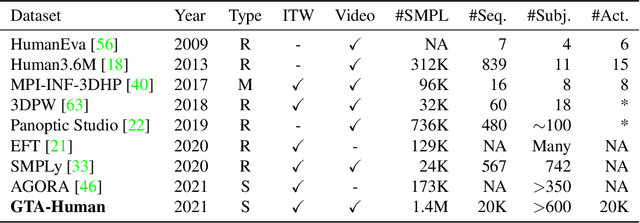

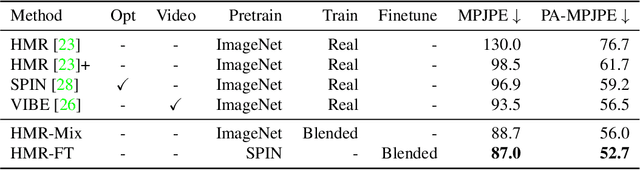
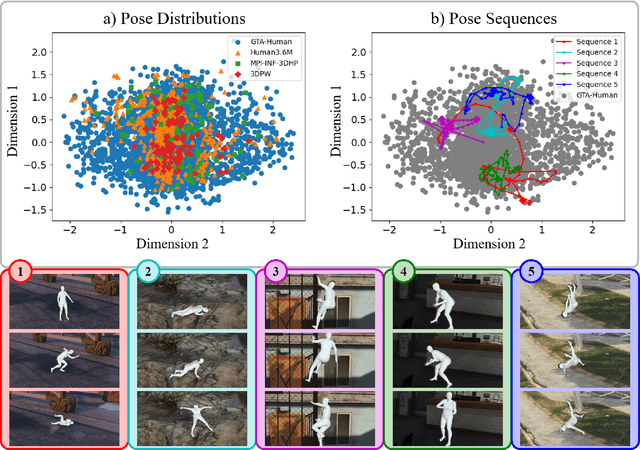
Image- and video-based 3D human recovery (i.e. pose and shape estimation) have achieved substantial progress. However, due to the prohibitive cost of motion capture, existing datasets are often limited in scale and diversity, which hinders the further development of more powerful models. In this work, we obtain massive human sequences as well as their 3D ground truths by playing video games. Specifically, we contribute, GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine. With a rich set of subjects, actions, and scenarios, GTA-Human serves as both an effective training source. Notably, the "unreasonable effectiveness of data" phenomenon is validated in 3D human recovery using our game-playing data. A simple frame-based baseline trained on GTA-Human already outperforms more sophisticated methods by a large margin; for video-based methods, GTA-Human demonstrates superiority over even the in-domain training set. We extend our study to larger models to observe the same consistent improvements, and the study on supervision signals suggests the rich collection of SMPL annotations is key. Furthermore, equipped with the diverse annotations in GTA-Human, we systematically investigate the performance of various methods under a wide spectrum of real-world variations, e.g. camera angles, poses, and occlusions. We hope our work could pave way for scaling up 3D human recovery to the real world.
Seeking Visual Discomfort: Curiosity-driven Representations for Reinforcement Learning
Oct 02, 2021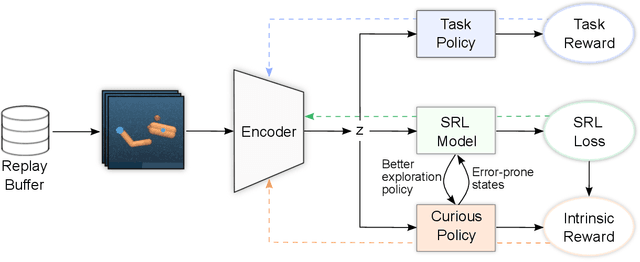
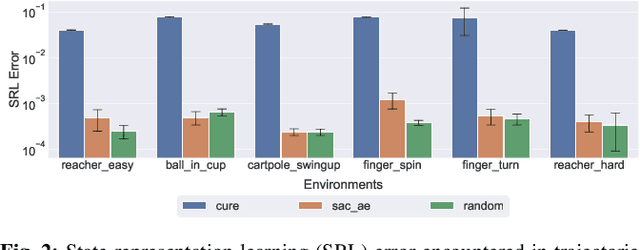
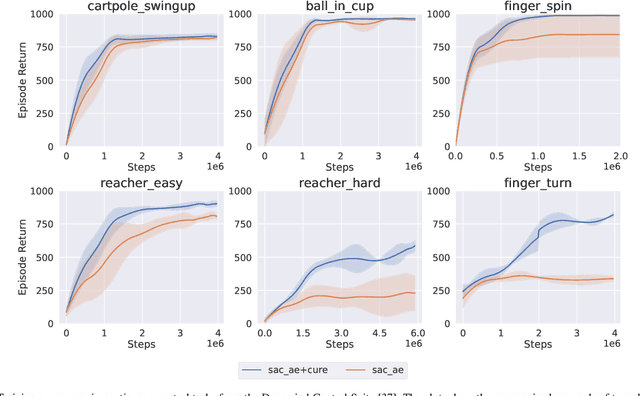
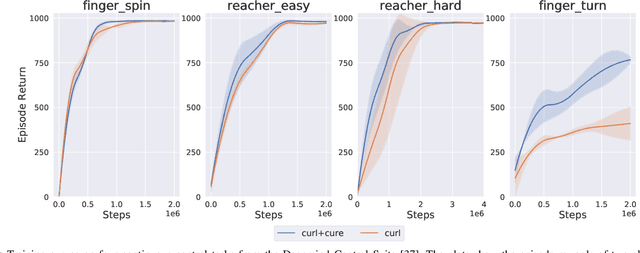
Vision-based reinforcement learning (RL) is a promising approach to solve control tasks involving images as the main observation. State-of-the-art RL algorithms still struggle in terms of sample efficiency, especially when using image observations. This has led to increased attention on integrating state representation learning (SRL) techniques into the RL pipeline. Work in this field demonstrates a substantial improvement in sample efficiency among other benefits. However, to take full advantage of this paradigm, the quality of samples used for training plays a crucial role. More importantly, the diversity of these samples could affect the sample efficiency of vision-based RL, but also its generalization capability. In this work, we present an approach to improve sample diversity for state representation learning. Our method enhances the exploration capability of RL algorithms, by taking advantage of the SRL setup. Our experiments show that our proposed approach boosts the visitation of problematic states, improves the learned state representation, and outperforms the baselines for all tested environments. These results are most apparent for environments where the baseline methods struggle. Even in simple environments, our method stabilizes the training, reduces the reward variance, and promotes sample efficiency.