 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantifying Predictive Uncertainty in Medical Image Analysis with Deep Kernel Learning
Jun 01, 2021
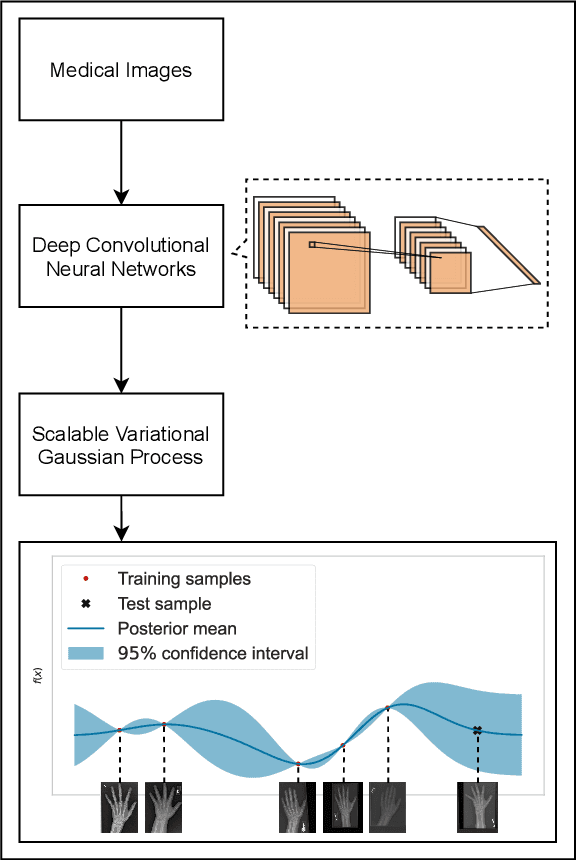
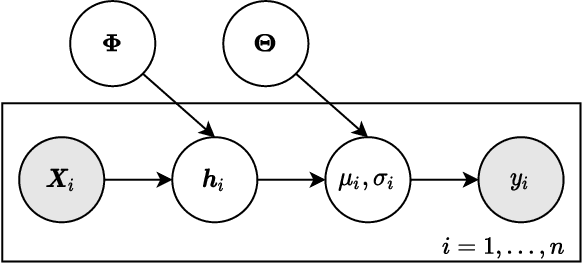
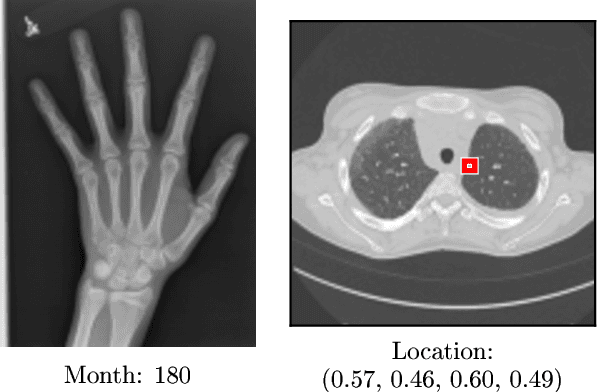
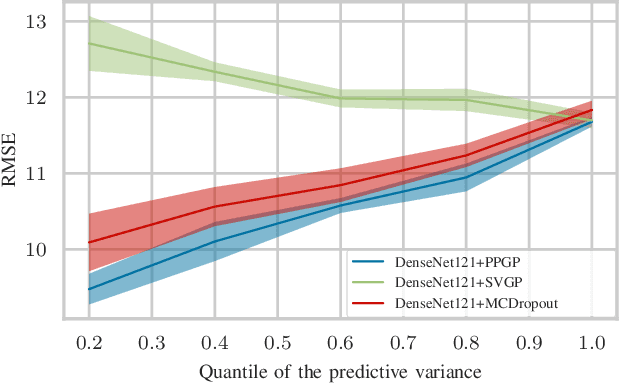
Deep neural networks are increasingly being used for the analysis of medical images. However, most works neglect the uncertainty in the model's prediction. We propose an uncertainty-aware deep kernel learning model which permits the estimation of the uncertainty in the prediction by a pipeline of a Convolutional Neural Network and a sparse Gaussian Process. Furthermore, we adapt different pre-training methods to investigate their impacts on the proposed model. We apply our approach to Bone Age Prediction and Lesion Localization. In most cases, the proposed model shows better performance compared to common architectures. More importantly, our model expresses systematically higher confidence in more accurate predictions and less confidence in less accurate ones. Our model can also be used to detect challenging and controversial test samples. Compared to related methods such as Monte-Carlo Dropout, our approach derives the uncertainty information in a purely analytical fashion and is thus computationally more efficient.
HoloSketch: Wireless Semantic Segmentation by Reconfigurable Intelligent Surfaces
Aug 14, 2021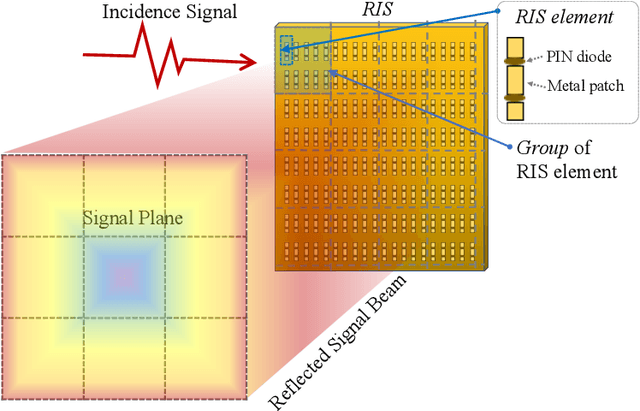
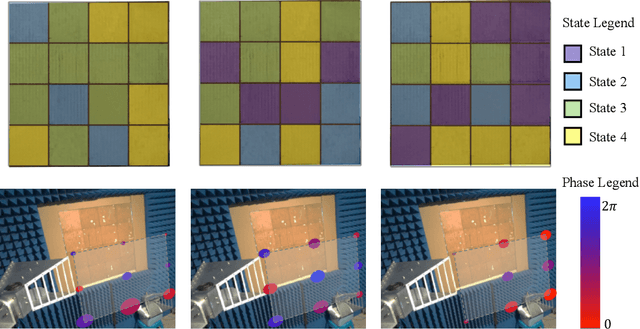

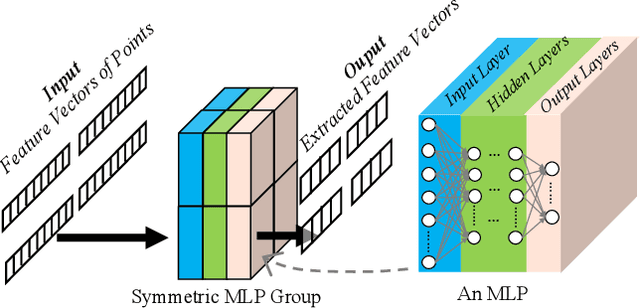
Semantic segmentation is a process of partitioning an image into multiple segments for recognizing humans and objects, which can be widely applied in scenarios such as healthcare and safety monitoring. To avoid privacy violation, using RF signals instead of an image for human and object recognition has gained increasing attention. However, human and object recognition by using RF signals is usually a passive signal collection and analysis process without changing the radio environment, and the recognition accuracy is restricted significantly by unwanted multi-path fading, and/or the limited number of independent channels between RF transceivers in uncontrollable radio environments. This paper introduces HoloSketch, a novel RF-sensing system that performs semantic recognition and segmentation for humans and objects by making the radio environment reconfigurable. A reconfigurable intelligent surface~(RIS) is incorporated into HoloSketch and diversifies the information carried by RF signals. Using compressive sensing techniques, HoloSketch reconstructs a point cloud consisting of the reflection coefficients of humans and objects at different spatial points, and recognizes the semantic meaning of the points by using symmetric multilayer perceptron groups. Our evaluation results show that HoloSketch is capable of generating favorable radio environments and extracting exact point clouds, and labeling the semantic meaning of the points with an average error rate of less than 1% in an indoor space.
End-to-end Alternating Optimization for Blind Super Resolution
May 14, 2021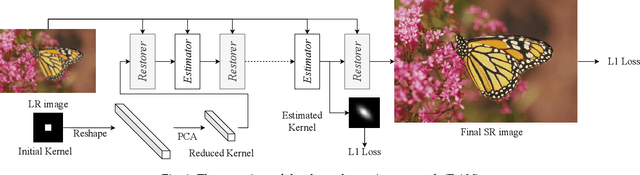
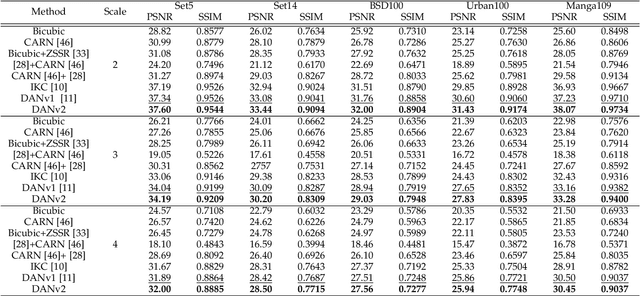
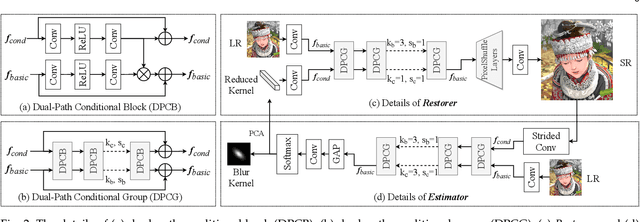

Previous methods decompose the blind super-resolution (SR) problem into two sequential steps: \textit{i}) estimating the blur kernel from given low-resolution (LR) image and \textit{ii}) restoring the SR image based on the estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. A small estimation error of the first step could cause a severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from the LR image, which makes it difficult to predict a highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate the blur kernel and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the predicted kernel, and \textit{Estimator} estimates the blur kernel with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of the blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of the ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at a much higher speed. The source code is available at \url{https://github.com/greatlog/DAN.git}.
Optimal Latent Vector Alignment for Unsupervised Domain Adaptation in Medical Image Segmentation
Jun 15, 2021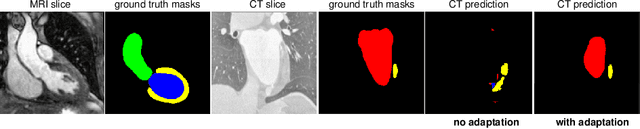
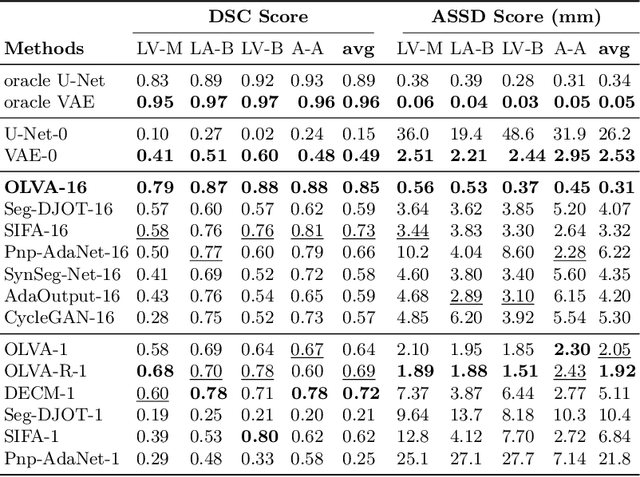
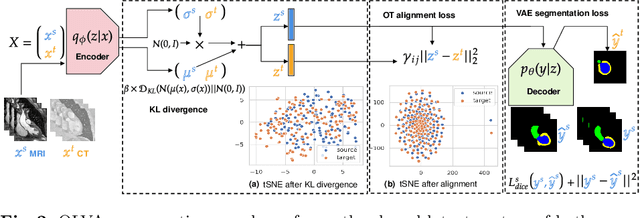
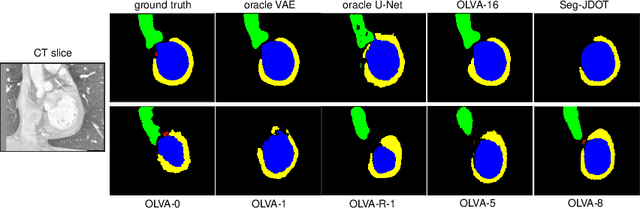
This paper addresses the domain shift problem for segmentation. As a solution, we propose OLVA, a novel and lightweight unsupervised domain adaptation method based on a Variational Auto-Encoder (VAE) and Optimal Transport (OT) theory. Thanks to the VAE, our model learns a shared cross-domain latent space that follows a normal distribution, which reduces the domain shift. To guarantee valid segmentations, our shared latent space is designed to model the shape rather than the intensity variations. We further rely on an OT loss to match and align the remaining discrepancy between the two domains in the latent space. We demonstrate OLVA's effectiveness for the segmentation of multiple cardiac structures on the public Multi-Modality Whole Heart Segmentation (MM-WHS) dataset, where the source domain consists of annotated 3D MR images and the unlabelled target domain of 3D CTs. Our results show remarkable improvements with an additional margin of 12.5\% dice score over concurrent generative training approaches.
IR-NAS: Neural Architecture Search for Image Restoration
Sep 18, 2019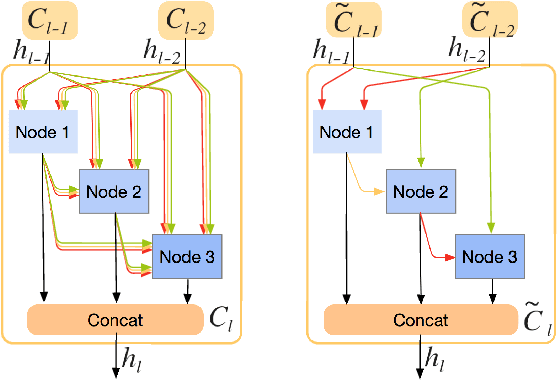
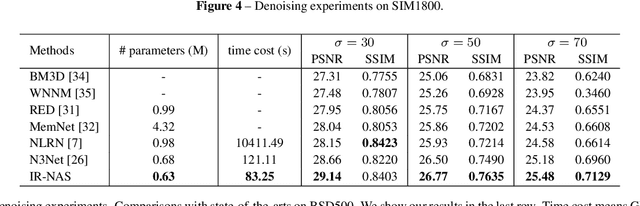
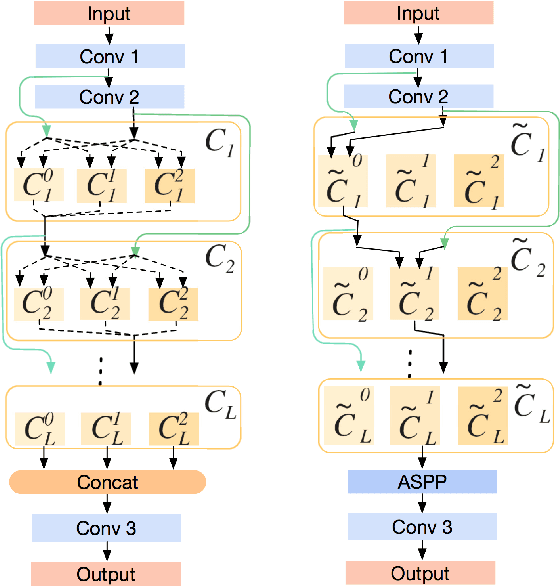
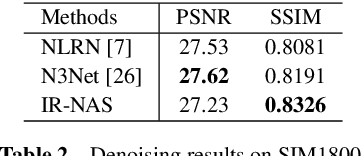
Recently, neural architecture search (NAS) methods have attracted much attention and outperformed manually designed architectures on a few high-level vision tasks. In this paper, we propose IR-NAS, an effort towards employing NAS to automatically design effective neural network architectures for low-level image restoration tasks, and apply to two such tasks: image denoising and image de-raining. IR-NAS adopts an flexible hierarchical search space, including inner cell structures and outer layer widths. The proposed IR-NAS is both memory and computationally efficient, which takes only 6 hours for searching using a single GPU and saves memory by sharing cell weights across different feature levels. We evaluate the effectiveness of our proposed IR-NAS on three different datasets, including an additive white Gaussian noise dataset BSD500, a realistic noise dataset SIM1800 and a challenging de-raining dataset Rain800. Results show that the architectures found by IR-NAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods. We also present analysis on the architectures found by NAS.
S2IGAN: Speech-to-Image Generation via Adversarial Learning
May 14, 2020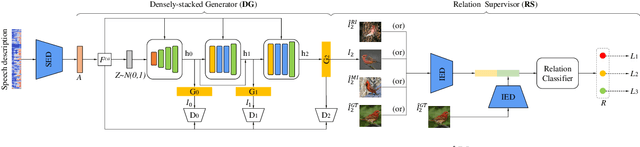
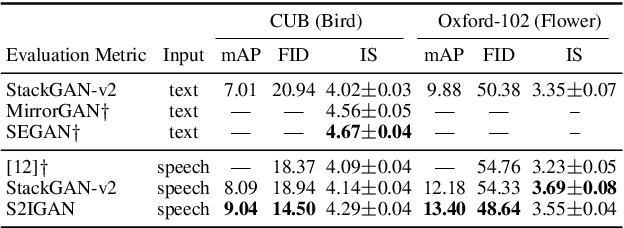


An estimated half of the world's languages do not have a written form, making it impossible for these languages to benefit from any existing text-based technologies. In this paper, a speech-to-image generation (S2IG) framework is proposed which translates speech descriptions to photo-realistic images without using any text information, thus allowing unwritten languages to potentially benefit from this technology. The proposed S2IG framework, named S2IGAN, consists of a speech embedding network (SEN) and a relation-supervised densely-stacked generative model (RDG). SEN learns the speech embedding with the supervision of the corresponding visual information. Conditioned on the speech embedding produced by SEN, the proposed RDG synthesizes images that are semantically consistent with the corresponding speech descriptions. Extensive experiments on two public benchmark datasets CUB and Oxford-102 demonstrate the effectiveness of the proposed S2IGAN on synthesizing high-quality and semantically-consistent images from the speech signal, yielding a good performance and a solid baseline for the S2IG task.
Sub-Pixel Back-Projection Network For Lightweight Single Image Super-Resolution
Aug 03, 2020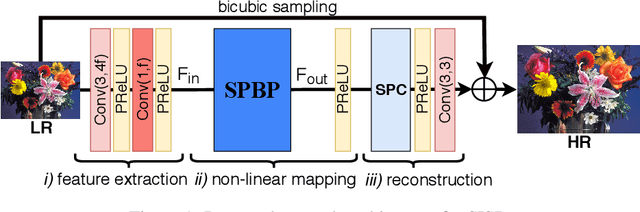
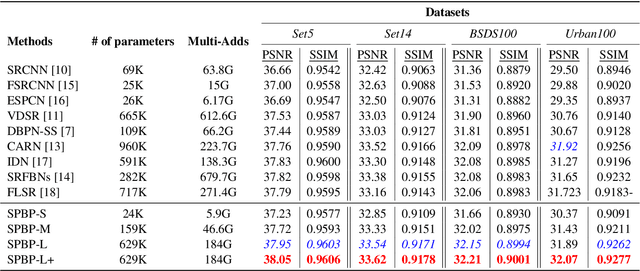
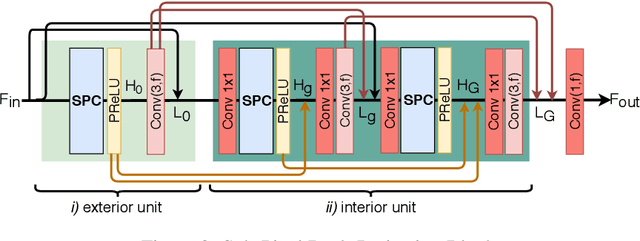
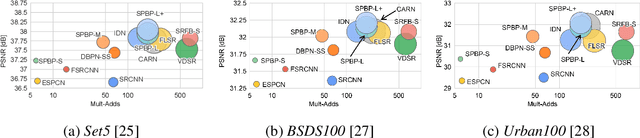
Convolutional neural network (CNN)-based methods have achieved great success for single-image superresolution (SISR). However, most models attempt to improve reconstruction accuracy while increasing the requirement of number of model parameters. To tackle this problem, in this paper, we study reducing the number of parameters and computational cost of CNN-based SISR methods while maintaining the accuracy of super-resolution reconstruction performance. To this end, we introduce a novel network architecture for SISR, which strikes a good trade-off between reconstruction quality and low computational complexity. Specifically, we propose an iterative back-projection architecture using sub-pixel convolution instead of deconvolution layers. We evaluate the performance of computational and reconstruction accuracy for our proposed model with extensive quantitative and qualitative evaluations. Experimental results reveal that our proposed method uses fewer parameters and reduces the computational cost while maintaining reconstruction accuracy against state-of-the-art SISR methods over well-known four SR benchmark datasets. Code is available at "https://github.com/supratikbanerjee/SubPixel-BackProjection_SuperResolution".
Text2Brain: Synthesis of Brain Activation Maps from Free-form Text Query
Sep 28, 2021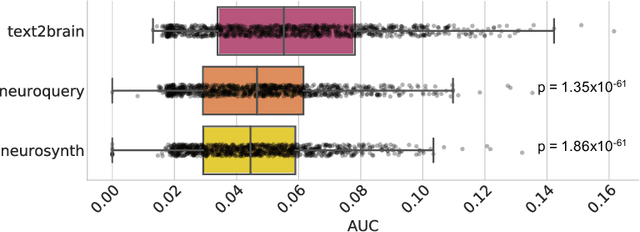
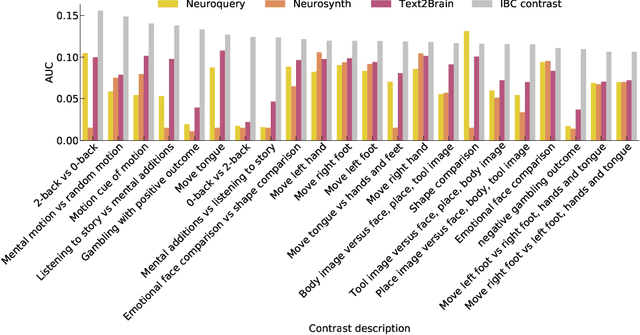
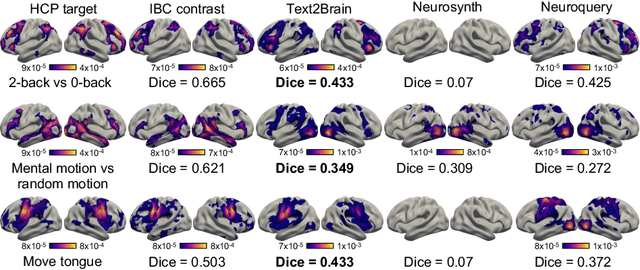
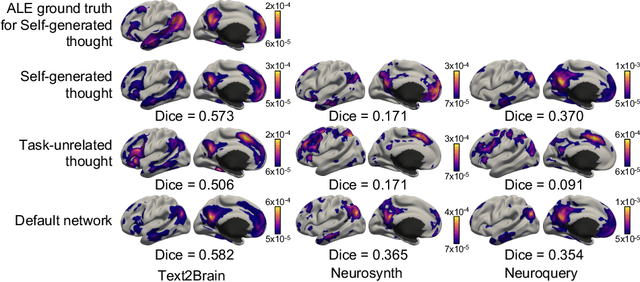
Most neuroimaging experiments are under-powered, limited by the number of subjects and cognitive processes that an individual study can investigate. Nonetheless, over decades of research, neuroscience has accumulated an extensive wealth of results. It remains a challenge to digest this growing knowledge base and obtain new insights since existing meta-analytic tools are limited to keyword queries. In this work, we propose Text2Brain, a neural network approach for coordinate-based meta-analysis of neuroimaging studies to synthesize brain activation maps from open-ended text queries. Combining a transformer-based text encoder and a 3D image generator, Text2Brain was trained on variable-length text snippets and their corresponding activation maps sampled from 13,000 published neuroimaging studies. We demonstrate that Text2Brain can synthesize anatomically-plausible neural activation patterns from free-form textual descriptions of cognitive concepts. Text2Brain is available at https://braininterpreter.com as a web-based tool for retrieving established priors and generating new hypotheses for neuroscience research.
A Column Streaming-Based Convolution Engine and Mapping Algorithm for CNN-based Edge AI accelerators
Sep 15, 2021
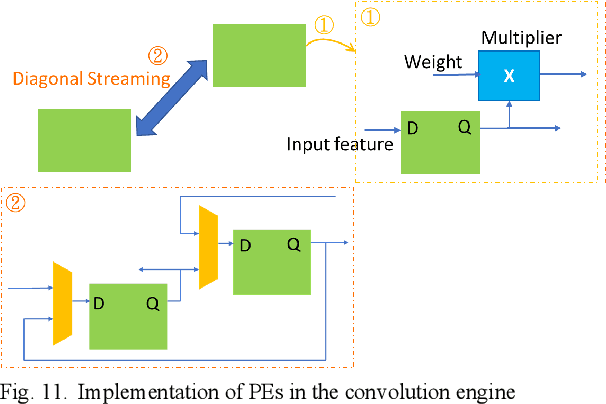
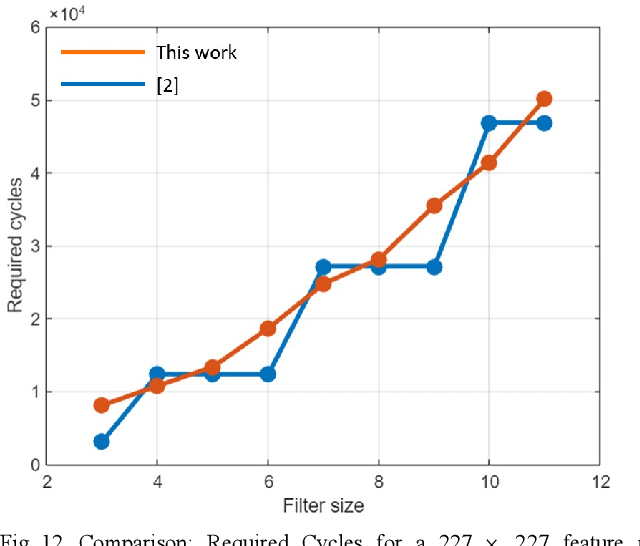
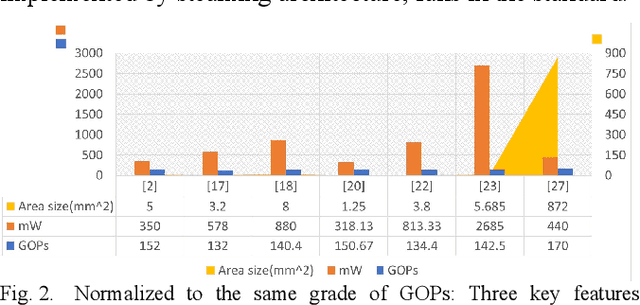
Edge AI accelerators have been emerging as a solution for near customers' applications in areas such as unmanned aerial vehicles (UAVs), image recognition sensors, wearable devices, robotics, and remote sensing satellites. These applications not only require meeting performance targets but also meeting strict area and power constraints due to their portable mobility feature and limited power sources. As a result, a column streaming-based convolution engine has been proposed in this paper that includes column sets of processing elements design for flexibility in terms of the applicability for different CNN algorithms in edge AI accelerators. Comparing to a commercialized CNN accelerator, the key results reveal that the column streaming-based convolution engine requires similar execution cycles for processing a 227 x 227 feature map with avoiding zero-padding penalties.
Hi-Net: Hybrid-fusion Network for Multi-modal MR Image Synthesis
Feb 11, 2020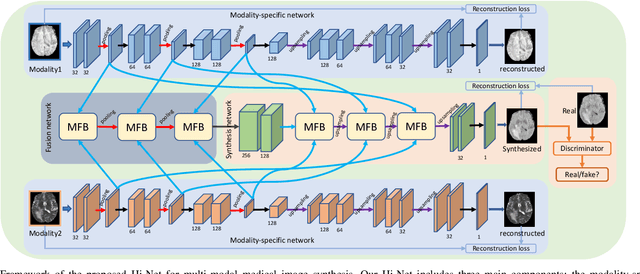
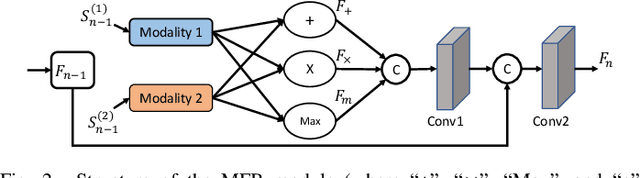
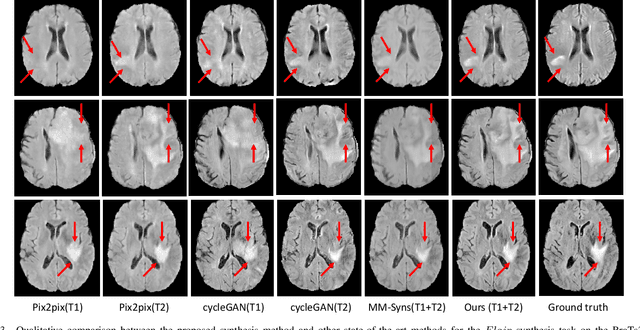
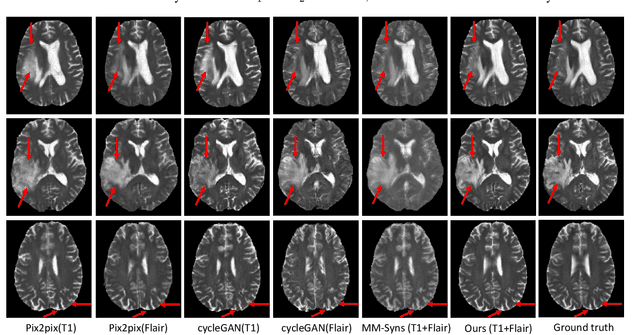
Magnetic resonance imaging (MRI) is a widely used neuroimaging technique that can provide images of different contrasts (i.e., modalities). Fusing this multi-modal data has proven particularly effective for boosting model performance in many tasks. However, due to poor data quality and frequent patient dropout, collecting all modalities for every patient remains a challenge. Medical image synthesis has been proposed as an effective solution to this, where any missing modalities are synthesized from the existing ones. In this paper, we propose a novel Hybrid-fusion Network (Hi-Net) for multi-modal MR image synthesis, which learns a mapping from multi-modal source images (i.e., existing modalities) to target images (i.e., missing modalities). In our Hi-Net, a modality-specific network is utilized to learn representations for each individual modality, and a fusion network is employed to learn the common latent representation of multi-modal data. Then, a multi-modal synthesis network is designed to densely combine the latent representation with hierarchical features from each modality, acting as a generator to synthesize the target images. Moreover, a layer-wise multi-modal fusion strategy is presented to effectively exploit the correlations among multiple modalities, in which a Mixed Fusion Block (MFB) is proposed to adaptively weight different fusion strategies (i.e., element-wise summation, product, and maximization). Extensive experiments demonstrate that the proposed model outperforms other state-of-the-art medical image synthesis methods.