 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IR-NAS: Neural Architecture Search for Image Restoration
Sep 18, 2019
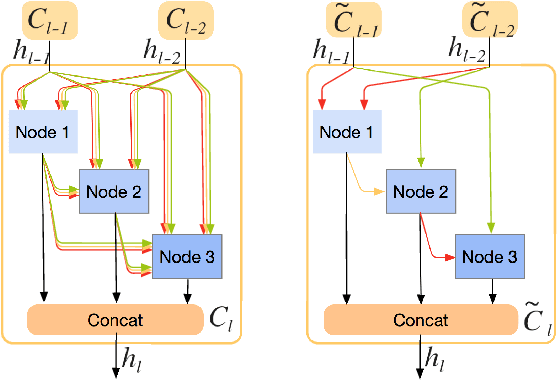
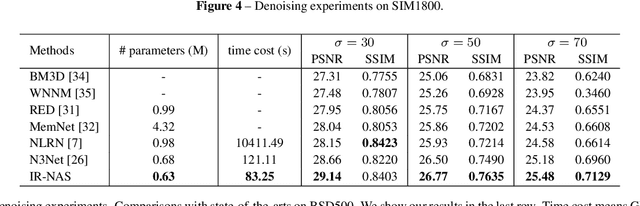
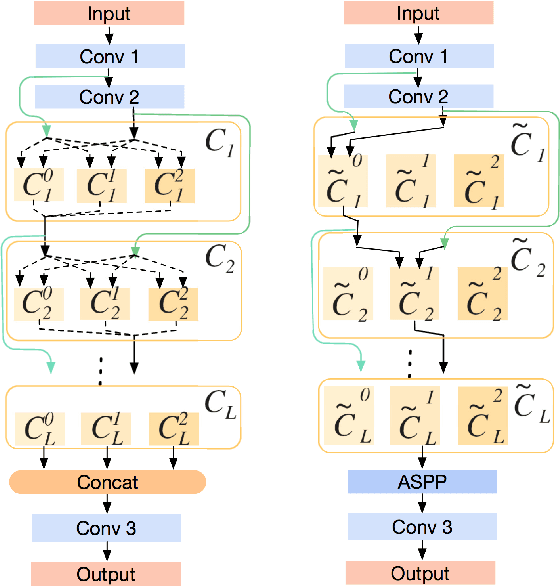
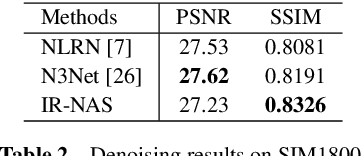
Recently, neural architecture search (NAS) methods have attracted much attention and outperformed manually designed architectures on a few high-level vision tasks. In this paper, we propose IR-NAS, an effort towards employing NAS to automatically design effective neural network architectures for low-level image restoration tasks, and apply to two such tasks: image denoising and image de-raining. IR-NAS adopts an flexible hierarchical search space, including inner cell structures and outer layer widths. The proposed IR-NAS is both memory and computationally efficient, which takes only 6 hours for searching using a single GPU and saves memory by sharing cell weights across different feature levels. We evaluate the effectiveness of our proposed IR-NAS on three different datasets, including an additive white Gaussian noise dataset BSD500, a realistic noise dataset SIM1800 and a challenging de-raining dataset Rain800. Results show that the architectures found by IR-NAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods. We also present analysis on the architectures found by NAS.
Learning Equivariances and Partial Equivariances from Data
Oct 19, 2021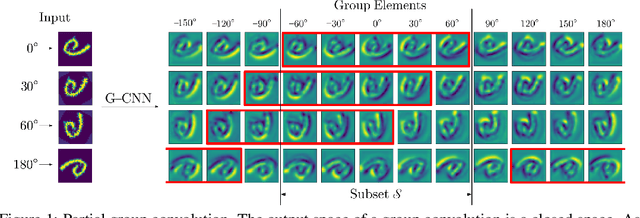

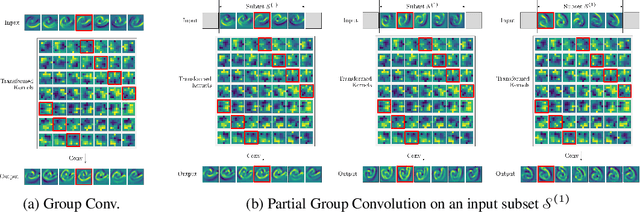
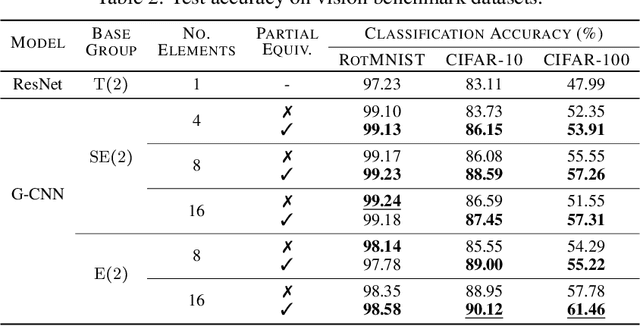
Group equivariant Convolutional Neural Networks (G-CNNs) constrain features to respect the chosen symmetries, and lead to better generalization when these symmetries appear in the data. However, if the chosen symmetries are not present, group equivariant architectures lead to overly constrained models and worse performance. Frequently, the distribution of the data can be better represented by a subset of a group than by the group as a whole, e.g., rotations in $[-90^{\circ}, 90^{\circ}]$. In such cases, a model that respects equivariance partially is better suited to represent the data. Moreover, relevant symmetries may differ for low and high-level features, e.g., edge orientations in a face, and face poses relative to the camera. As a result, the optimal level of equivariance may differ per layer. In this work, we introduce Partial G-CNNs: a family of equivariant networks able to learn partial and full equivariances from data at every layer end-to-end. Partial G-CNNs retain full equivariance whenever beneficial, e.g., for rotated MNIST, but are able to restrict it whenever it becomes harmful, e.g., for 6~/~9 or natural image classification. Partial G-CNNs perform on par with G-CNNs when full equivariance is necessary, and outperform them otherwise. Our method is applicable to discrete groups, continuous groups and combinations thereof.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021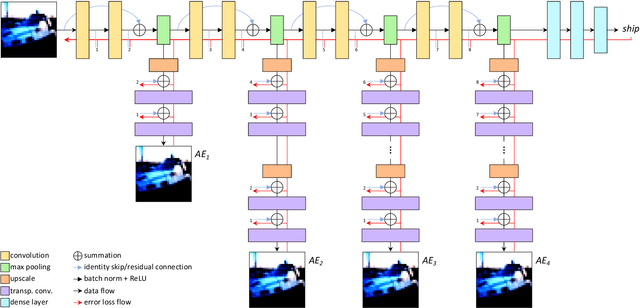
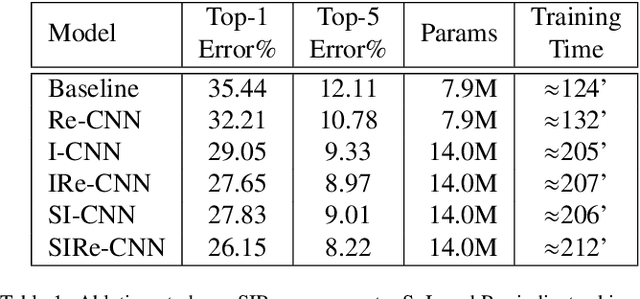

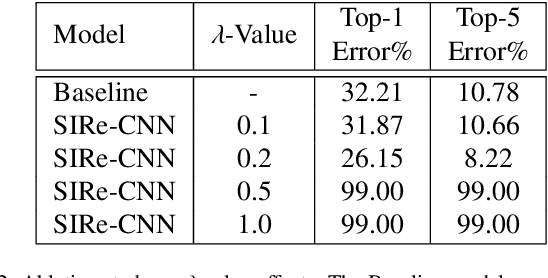
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
Knothe-Rosenblatt transport for Unsupervised Domain Adaptation
Oct 06, 2021
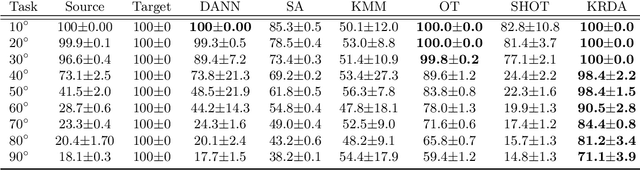
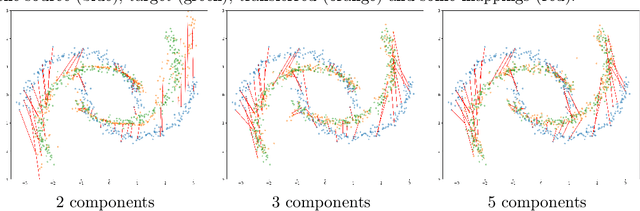
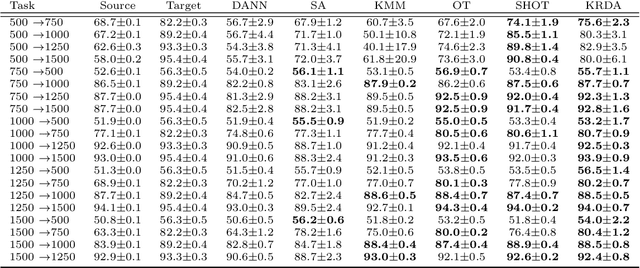
Unsupervised domain adaptation (UDA) aims at exploiting related but different data sources to tackle a common task in a target domain. UDA remains a central yet challenging problem in machine learning. In this paper, we present an approach tailored to moderate-dimensional tabular problems which are hugely important in industrial applications and less well-served by the plethora of methods designed for image and language data. Knothe-Rosenblatt Domain Adaptation (KRDA) is based on the Knothe-Rosenblatt transport: we exploit autoregressive density estimation algorithms to accurately model the different sources by an autoregressive model using a mixture of Gaussians. KRDA then takes advantage of the triangularity of the autoregressive models to build an explicit mapping of the source samples into the target domain. We show that the transfer map built by KRDA preserves each component quantiles of the observations, hence aligning the representations of the different data sets in the same target domain. Finally, we show that KRDA has state-of-the-art performance on both synthetic and real world UDA problems.
Cross-Modality Brain Tumor Segmentation via Bidirectional Global-to-Local Unsupervised Domain Adaptation
May 17, 2021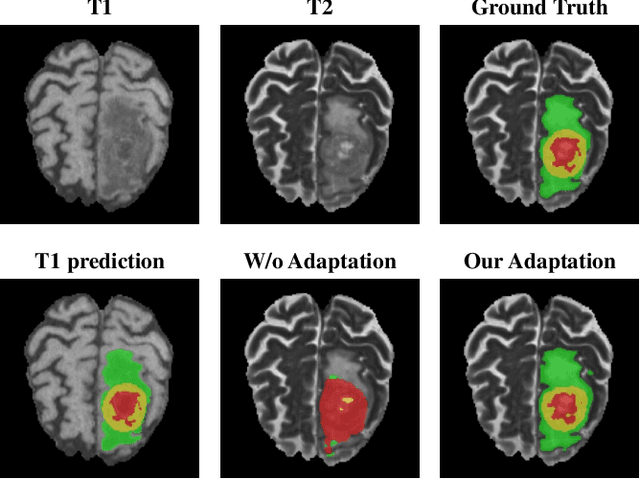
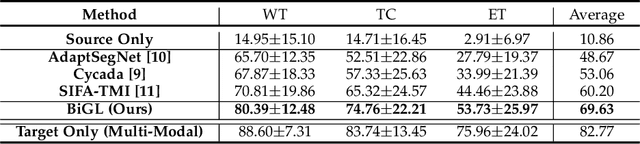
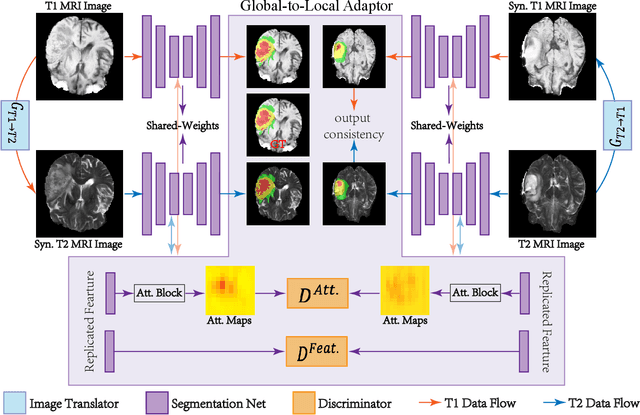
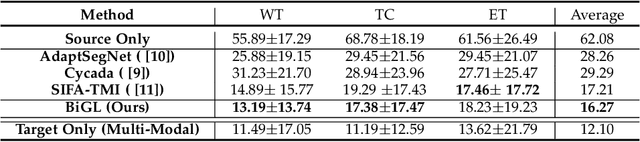
Accurate segmentation of brain tumors from multi-modal Magnetic Resonance (MR) images is essential in brain tumor diagnosis and treatment. However, due to the existence of domain shifts among different modalities, the performance of networks decreases dramatically when training on one modality and performing on another, e.g., train on T1 image while performing on T2 image, which is often required in clinical applications. This also prohibits a network from being trained on labeled data and then transferred to unlabeled data from a different domain. To overcome this, unsupervised domain adaptation (UDA) methods provide effective solutions to alleviate the domain shift between labeled source data and unlabeled target data. In this paper, we propose a novel Bidirectional Global-to-Local (BiGL) adaptation framework under a UDA scheme. Specifically, a bidirectional image synthesis and segmentation module is proposed to segment the brain tumor using the intermediate data distributions generated for the two domains, which includes an image-to-image translator and a shared-weighted segmentation network. Further, a global-to-local consistency learning module is proposed to build robust representation alignments in an integrated way. Extensive experiments on a multi-modal brain MR benchmark dataset demonstrate that the proposed method outperforms several state-of-the-art unsupervised domain adaptation methods by a large margin, while a comprehensive ablation study validates the effectiveness of each key component. The implementation code of our method will be released at \url{https://github.com/KeleiHe/BiGL}.
S2IGAN: Speech-to-Image Generation via Adversarial Learning
May 14, 2020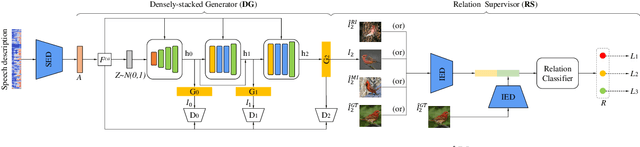
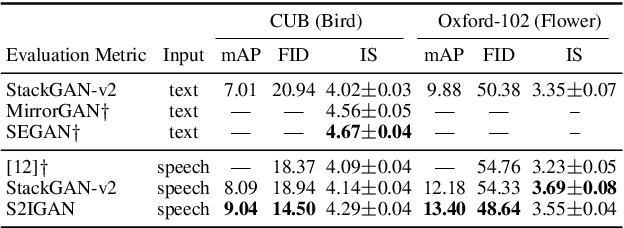


An estimated half of the world's languages do not have a written form, making it impossible for these languages to benefit from any existing text-based technologies. In this paper, a speech-to-image generation (S2IG) framework is proposed which translates speech descriptions to photo-realistic images without using any text information, thus allowing unwritten languages to potentially benefit from this technology. The proposed S2IG framework, named S2IGAN, consists of a speech embedding network (SEN) and a relation-supervised densely-stacked generative model (RDG). SEN learns the speech embedding with the supervision of the corresponding visual information. Conditioned on the speech embedding produced by SEN, the proposed RDG synthesizes images that are semantically consistent with the corresponding speech descriptions. Extensive experiments on two public benchmark datasets CUB and Oxford-102 demonstrate the effectiveness of the proposed S2IGAN on synthesizing high-quality and semantically-consistent images from the speech signal, yielding a good performance and a solid baseline for the S2IG task.
Learning Content-Weighted Deep Image Compression
Apr 01, 2019
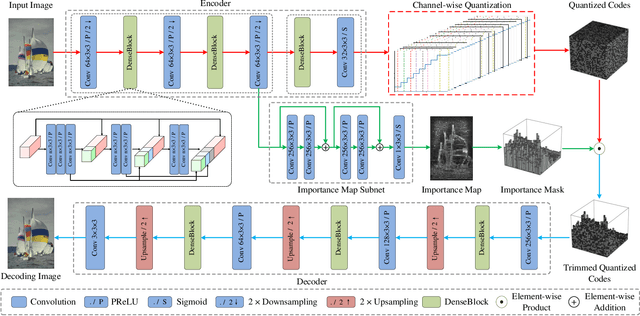
Learning-based lossy image compression usually involves the joint optimization of rate-distortion performance. Most existing methods adopt spatially invariant bit length allocation and incorporate discrete entropy approximation to constrain compression rate. Nonetheless, the information content is spatially variant, where the regions with complex and salient structures generally are more essential to image compression. Taking the spatial variation of image content into account, this paper presents a content-weighted encoder-decoder model, which involves an importance map subnet to produce the importance mask for locally adaptive bit rate allocation. Consequently, the summation of importance mask can thus be utilized as an alternative of entropy estimation for compression rate control. Furthermore, the quantized representations of the learned code and importance map are still spatially dependent, which can be losslessly compressed using arithmetic coding. To compress the codes effectively and efficiently, we propose a trimmed convolutional network to predict the conditional probability of quantized codes. Experiments show that the proposed method can produce visually much better results, and performs favorably in comparison with deep and traditional lossy image compression approaches.
Sub-Pixel Back-Projection Network For Lightweight Single Image Super-Resolution
Aug 03, 2020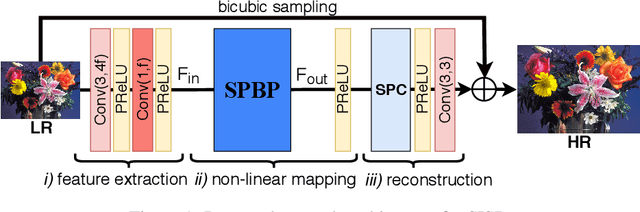
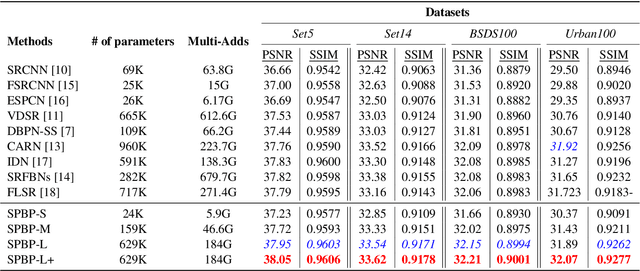
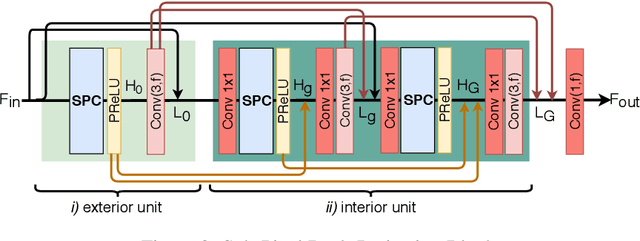
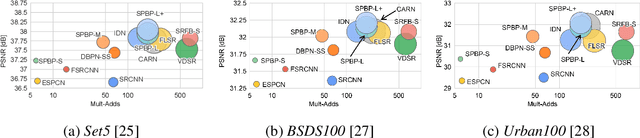
Convolutional neural network (CNN)-based methods have achieved great success for single-image superresolution (SISR). However, most models attempt to improve reconstruction accuracy while increasing the requirement of number of model parameters. To tackle this problem, in this paper, we study reducing the number of parameters and computational cost of CNN-based SISR methods while maintaining the accuracy of super-resolution reconstruction performance. To this end, we introduce a novel network architecture for SISR, which strikes a good trade-off between reconstruction quality and low computational complexity. Specifically, we propose an iterative back-projection architecture using sub-pixel convolution instead of deconvolution layers. We evaluate the performance of computational and reconstruction accuracy for our proposed model with extensive quantitative and qualitative evaluations. Experimental results reveal that our proposed method uses fewer parameters and reduces the computational cost while maintaining reconstruction accuracy against state-of-the-art SISR methods over well-known four SR benchmark datasets. Code is available at "https://github.com/supratikbanerjee/SubPixel-BackProjection_SuperResolution".
Automated Robustness with Adversarial Training as a Post-Processing Step
Sep 06, 2021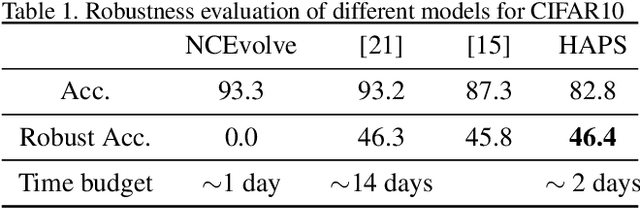
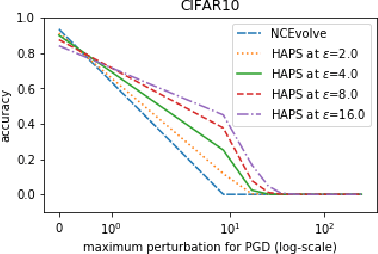

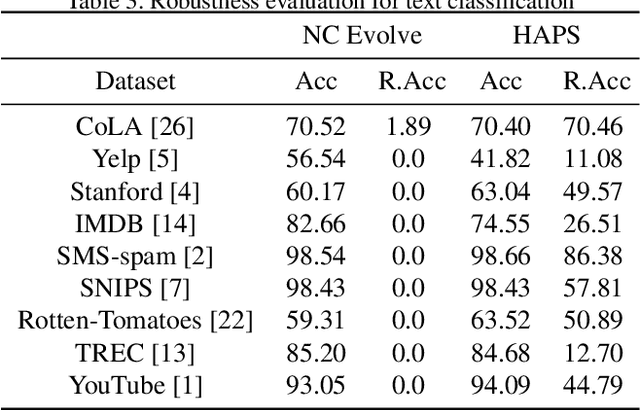
Adversarial training is a computationally expensive task and hence searching for neural network architectures with robustness as the criterion can be challenging. As a step towards practical automation, this work explores the efficacy of a simple post processing step in yielding robust deep learning model. To achieve this, we adopt adversarial training as a post-processing step for optimised network architectures obtained from a neural architecture search algorithm. Specific policies are adopted for tuning the hyperparameters of the different steps, resulting in a fully automated pipeline for generating adversarially robust deep learning models. We evidence the usefulness of the proposed pipeline with extensive experimentation across 11 image classification and 9 text classification tasks.
Contrastive Active Inference
Oct 19, 2021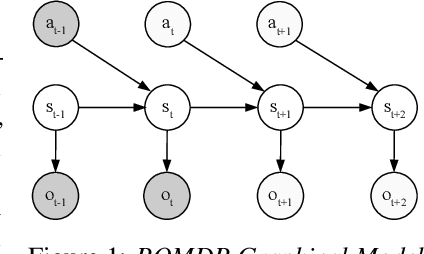
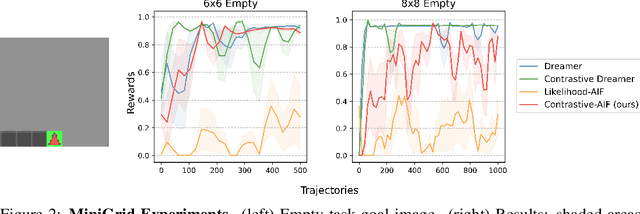

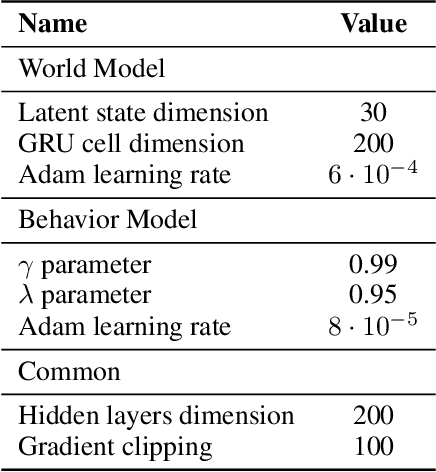
Active inference is a unifying theory for perception and action resting upon the idea that the brain maintains an internal model of the world by minimizing free energy. From a behavioral perspective, active inference agents can be seen as self-evidencing beings that act to fulfill their optimistic predictions, namely preferred outcomes or goals. In contrast, reinforcement learning requires human-designed rewards to accomplish any desired outcome. Although active inference could provide a more natural self-supervised objective for control, its applicability has been limited because of the shortcomings in scaling the approach to complex environments. In this work, we propose a contrastive objective for active inference that strongly reduces the computational burden in learning the agent's generative model and planning future actions. Our method performs notably better than likelihood-based active inference in image-based tasks, while also being computationally cheaper and easier to train. We compare to reinforcement learning agents that have access to human-designed reward functions, showing that our approach closely matches their performance. Finally, we also show that contrastive methods perform significantly better in the case of distractors in the environment and that our method is able to generalize goals to variations in the background.