 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Considering user agreement in learning to predict the aesthetic quality
Oct 13, 2021
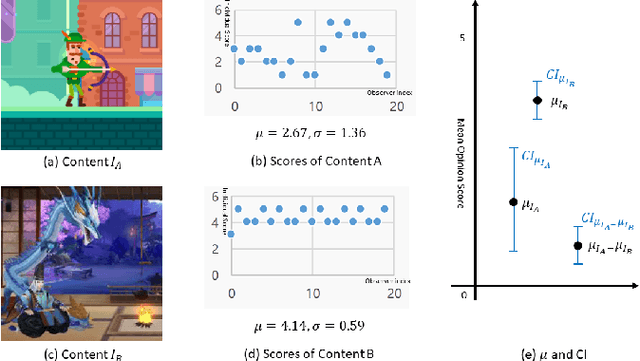
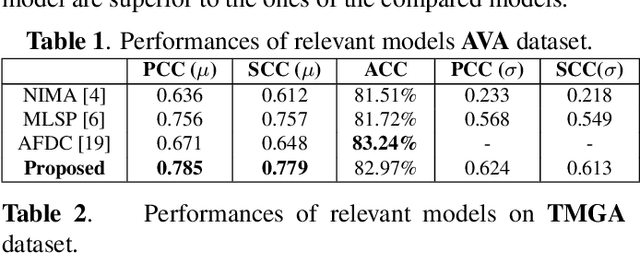
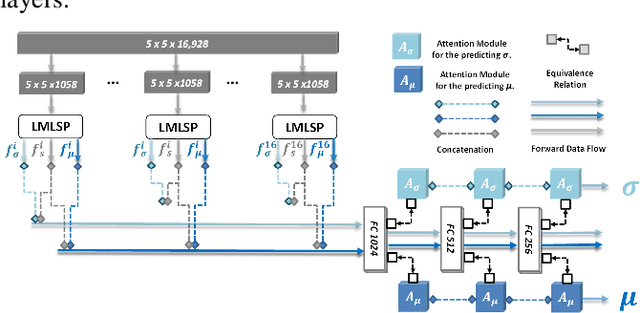
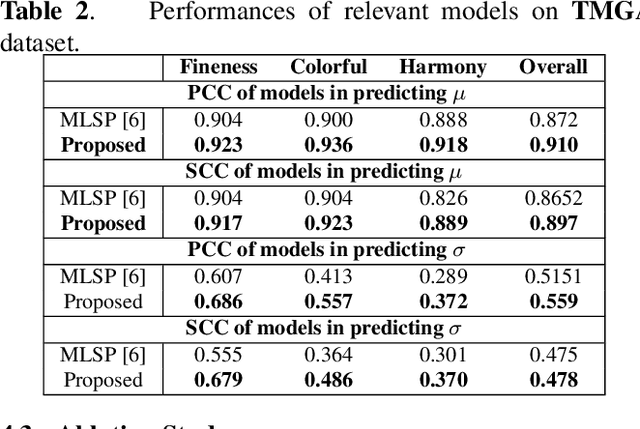
How to robustly rank the aesthetic quality of given images has been a long-standing ill-posed topic. Such challenge stems mainly from the diverse subjective opinions of different observers about the varied types of content. There is a growing interest in estimating the user agreement by considering the standard deviation of the scores, instead of only predicting the mean aesthetic opinion score. Nevertheless, when comparing a pair of contents, few studies consider how confident are we regarding the difference in the aesthetic scores. In this paper, we thus propose (1) a re-adapted multi-task attention network to predict both the mean opinion score and the standard deviation in an end-to-end manner; (2) a brand-new confidence interval ranking loss that encourages the model to focus on image-pairs that are less certain about the difference of their aesthetic scores. With such loss, the model is encouraged to learn the uncertainty of the content that is relevant to the diversity of observers' opinions, i.e., user disagreement. Extensive experiments have demonstrated that the proposed multi-task aesthetic model achieves state-of-the-art performance on two different types of aesthetic datasets, i.e., AVA and TMGA.
Image Segmentation using Multi-Threshold technique by Histogram Sampling
Sep 11, 2019
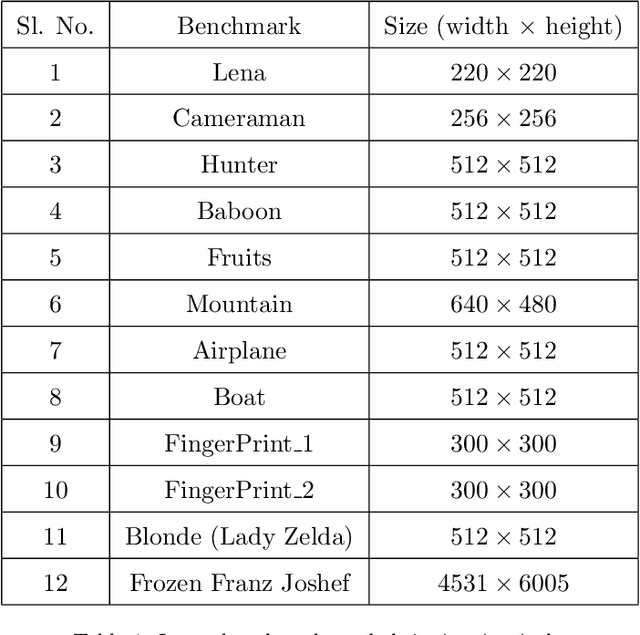
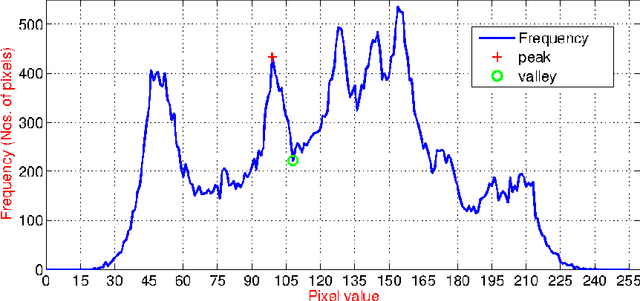
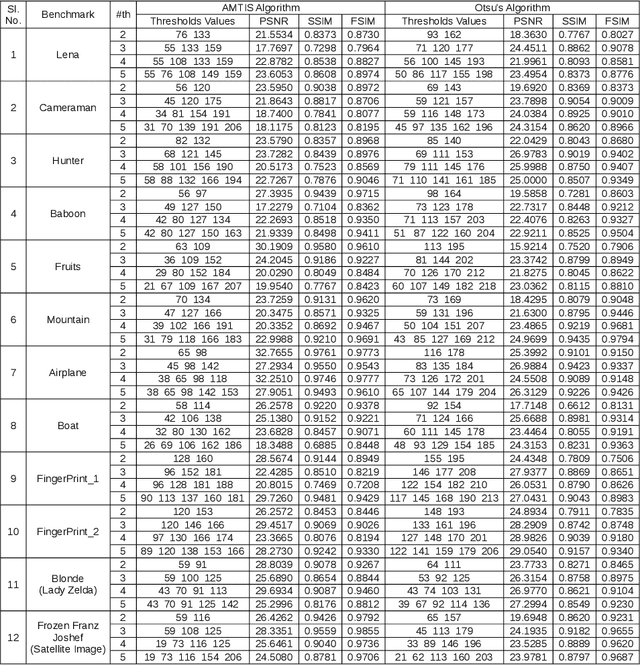
The segmentation of digital images is one of the essential steps in image processing or a computer vision system. It helps in separating the pixels into different regions according to their intensity level. A large number of segmentation techniques have been proposed, and a few of them use complex computational operations. Among all, the most straightforward procedure that can be easily implemented is thresholding. In this paper, we present a unique heuristic approach for image segmentation that automatically determines multilevel thresholds by sampling the histogram of a digital image. Our approach emphasis on selecting a valley as optimal threshold values. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We observed a maximum speed-up of 35.58x and a minimum speed-up of 10.21x on popular image processing benchmarks. To demonstrate the correctness of our approach in determining threshold values, we compute PSNR, SSIM, and FSIM values to compare with the values obtained by Otsu's method. This evaluation shows that our approach is comparable and better in many cases as compared to well known Otsu's method.
Clustering by Maximizing Mutual Information Across Views
Jul 24, 2021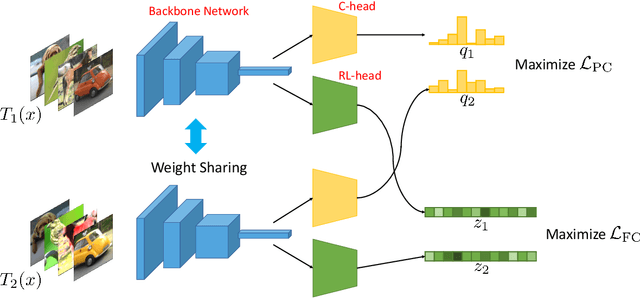
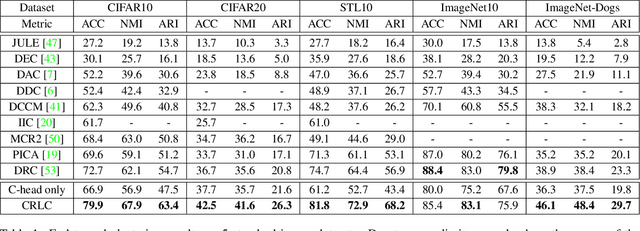


We propose a novel framework for image clustering that incorporates joint representation learning and clustering. Our method consists of two heads that share the same backbone network - a "representation learning" head and a "clustering" head. The "representation learning" head captures fine-grained patterns of objects at the instance level which serve as clues for the "clustering" head to extract coarse-grain information that separates objects into clusters. The whole model is trained in an end-to-end manner by minimizing the weighted sum of two sample-oriented contrastive losses applied to the outputs of the two heads. To ensure that the contrastive loss corresponding to the "clustering" head is optimal, we introduce a novel critic function called "log-of-dot-product". Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art single-stage clustering methods across a variety of image datasets, improving over the best baseline by about 5-7% in accuracy on CIFAR10/20, STL10, and ImageNet-Dogs. Further, the "two-stage" variant of our method also achieves better results than baselines on three challenging ImageNet subsets.
Discriminative Region-based Multi-Label Zero-Shot Learning
Aug 20, 2021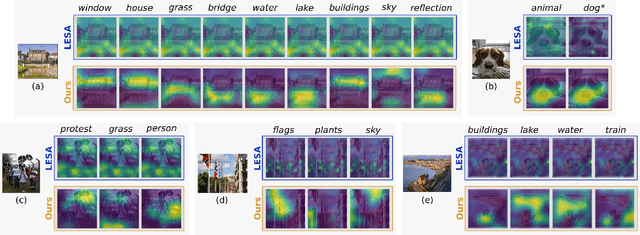
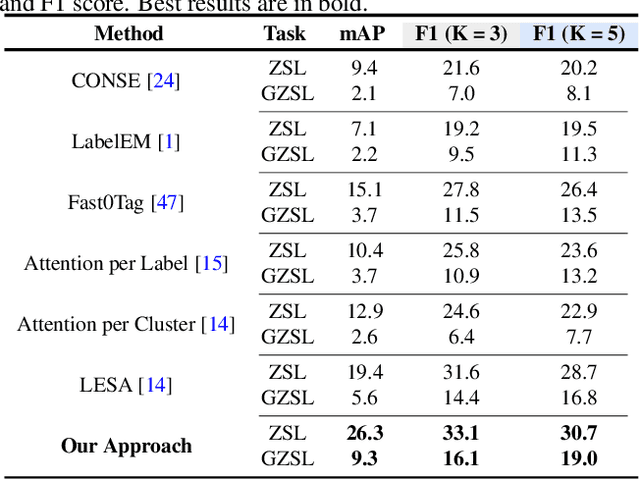
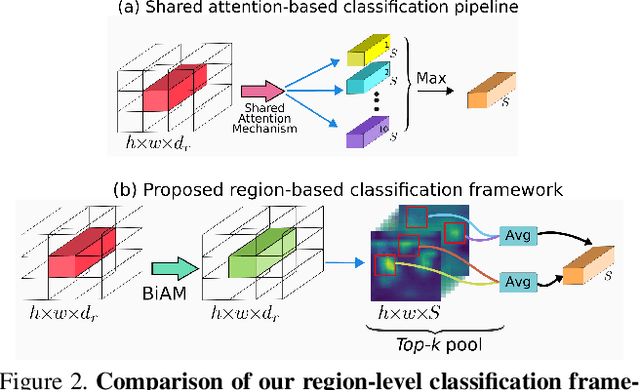
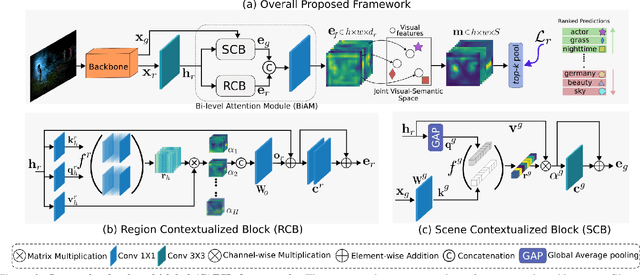
Multi-label zero-shot learning (ZSL) is a more realistic counter-part of standard single-label ZSL since several objects can co-exist in a natural image. However, the occurrence of multiple objects complicates the reasoning and requires region-specific processing of visual features to preserve their contextual cues. We note that the best existing multi-label ZSL method takes a shared approach towards attending to region features with a common set of attention maps for all the classes. Such shared maps lead to diffused attention, which does not discriminatively focus on relevant locations when the number of classes are large. Moreover, mapping spatially-pooled visual features to the class semantics leads to inter-class feature entanglement, thus hampering the classification. Here, we propose an alternate approach towards region-based discriminability-preserving multi-label zero-shot classification. Our approach maintains the spatial resolution to preserve region-level characteristics and utilizes a bi-level attention module (BiAM) to enrich the features by incorporating both region and scene context information. The enriched region-level features are then mapped to the class semantics and only their class predictions are spatially pooled to obtain image-level predictions, thereby keeping the multi-class features disentangled. Our approach sets a new state of the art on two large-scale multi-label zero-shot benchmarks: NUS-WIDE and Open Images. On NUS-WIDE, our approach achieves an absolute gain of 6.9% mAP for ZSL, compared to the best published results.
Maximum Entropy on the Mean: A Paradigm Shift for Regularization in Image Deblurring
Feb 24, 2020



Image deblurring is a notoriously challenging ill-posed inverse problem. In recent years, a wide variety of approaches have been proposed based upon regularization at the level of the image or on techniques from machine learning. We propose an alternative approach, shifting the paradigm towards regularization at the level of the probability distribution on the space of images. Our method is based upon the idea of maximum entropy on the mean wherein we work at the level of the probability density function of the image whose expectation is our estimate of the ground truth. Using techniques from convex analysis and probability theory, we show that the method is computationally feasible and amenable to very large blurs. Moreover, when images are imbedded with symbology (a known pattern), we show how our method can be applied to approximate the unknown blur kernel with remarkable effects. While our method is stable with respect to small amounts of noise, it does not actively denoise. However, for moderate to large amounts of noise, it performs well by preconditioned denoising with a state of the art method.
Winning Ticket in Noisy Image Classification
Feb 23, 2021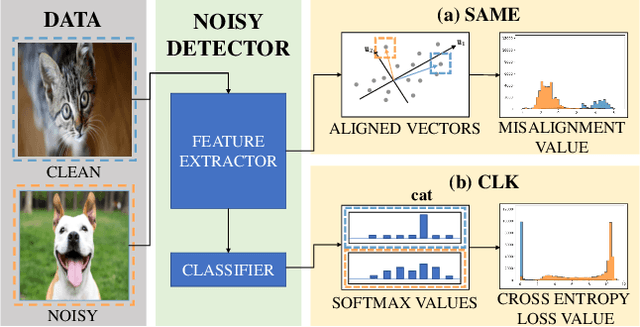

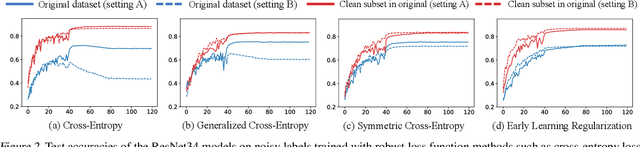
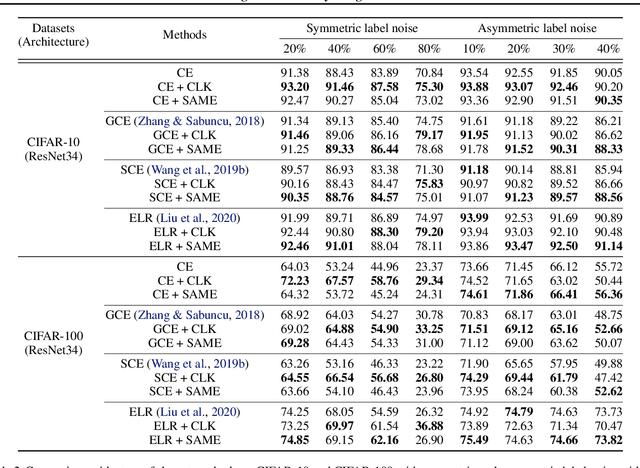
Modern deep neural networks (DNNs) become frail when the datasets contain noisy (incorrect) class labels. Many robust techniques have emerged via loss adjustment, robust loss function, and clean sample selection to mitigate this issue using the whole dataset. Here, we empirically observe that the dataset which contains only clean instances in original noisy datasets leads to better optima than the original dataset even with fewer data. Based on these results, we state the winning ticket hypothesis: regardless of robust methods, any DNNs reach the best performance when trained on the dataset possessing only clean samples from the original (winning ticket). We propose two simple yet effective strategies to identify winning tickets by looking at the loss landscape and latent features in DNNs. We conduct numerical experiments by collaborating the two proposed methods purifying data and existing robust methods for CIFAR-10 and CIFAR-100. The results support that our framework consistently and remarkably improves performance.
Robust Semi-Supervised Classification using GANs with Self-Organizing Maps
Oct 19, 2021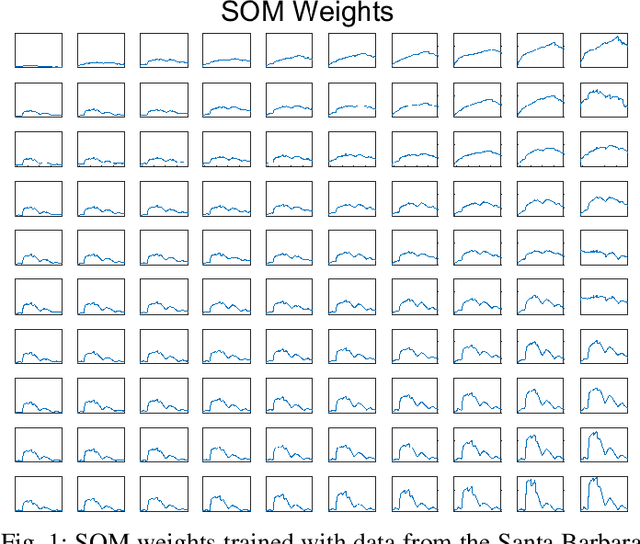
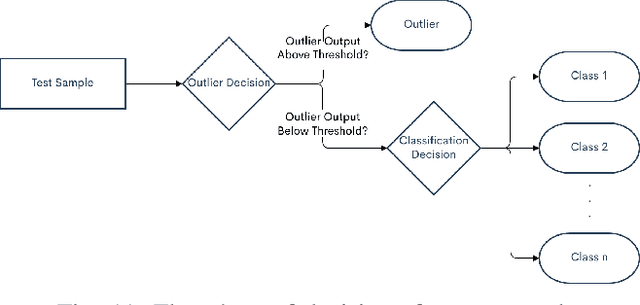
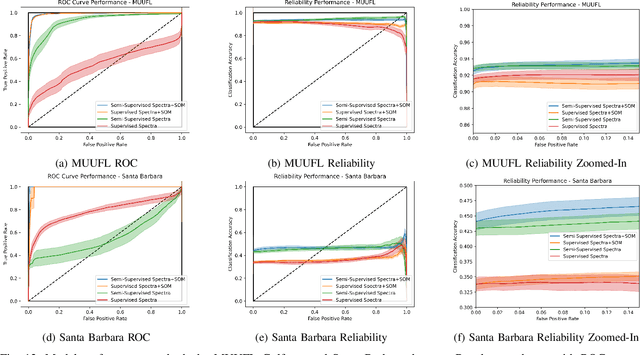
Generative adversarial networks (GANs) have shown tremendous promise in learning to generate data and effective at aiding semi-supervised classification. However, to this point, semi-supervised GAN methods make the assumption that the unlabeled data set contains only samples of the joint distribution of the classes of interest, referred to as inliers. Consequently, when presented with a sample from other distributions, referred to as outliers, GANs perform poorly at determining that it is not qualified to make a decision on the sample. The problem of discriminating outliers from inliers while maintaining classification accuracy is referred to here as the DOIC problem. In this work, we describe an architecture that combines self-organizing maps (SOMs) with SS-GANS with the goal of mitigating the DOIC problem and experimental results indicating that the architecture achieves the goal. Multiple experiments were conducted on hyperspectral image data sets. The SS-GANS performed slightly better than supervised GANS on classification problems with and without the SOM. Incorporating the SOMs into the SS-GANs and the supervised GANS led to substantially mitigation of the DOIC problem when compared to SS-GANS and GANs without the SOMs. Furthermore, the SS-GANS performed much better than GANS on the DOIC problem, even without the SOMs.
Deep Learning for Musculoskeletal Image Analysis
Mar 01, 2020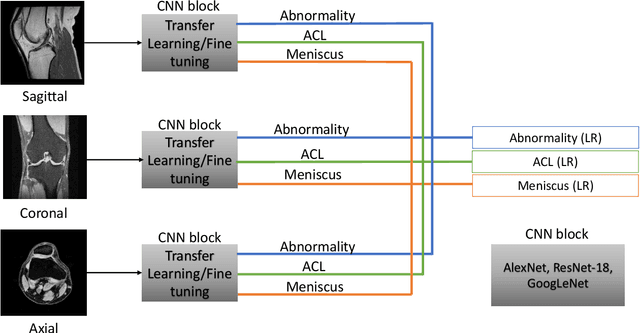
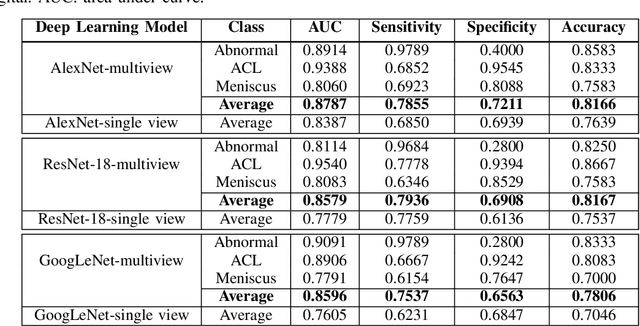
The diagnosis, prognosis, and treatment of patients with musculoskeletal (MSK) disorders require radiology imaging (using computed tomography, magnetic resonance imaging(MRI), and ultrasound) and their precise analysis by expert radiologists. Radiology scans can also help assessment of metabolic health, aging, and diabetes. This study presents how machinelearning, specifically deep learning methods, can be used for rapidand accurate image analysis of MRI scans, an unmet clinicalneed in MSK radiology. As a challenging example, we focus on automatic analysis of knee images from MRI scans and study machine learning classification of various abnormalities including meniscus and anterior cruciate ligament tears. Using widely used convolutional neural network (CNN) based architectures, we comparatively evaluated the knee abnormality classification performances of different neural network architectures under limited imaging data regime and compared single and multi-view imaging when classifying the abnormalities. Promising results indicated the potential use of multi-view deep learning based classification of MSK abnormalities in routine clinical assessment.
Fast and Robust Cascade Model for Multiple Degradation Single Image Super-Resolution
Nov 16, 2020
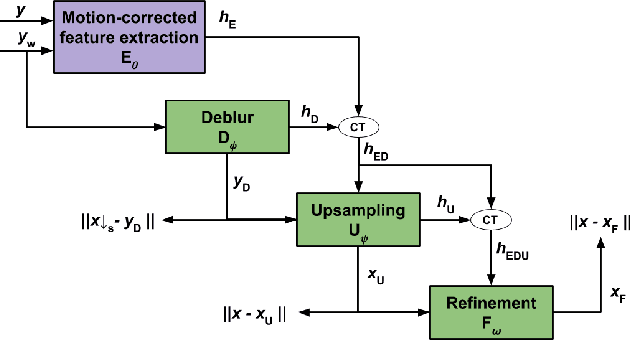

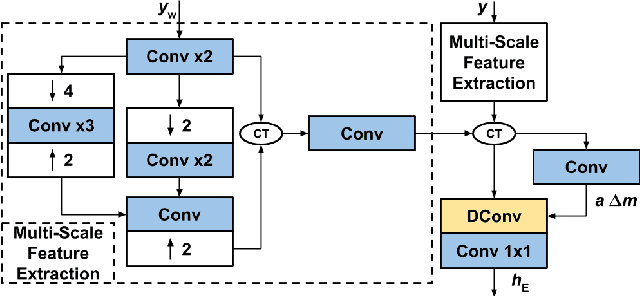
Single Image Super-Resolution (SISR) is one of the low-level computer vision problems that has received increased attention in the last few years. Current approaches are primarily based on harnessing the power of deep learning models and optimization techniques to reverse the degradation model. Owing to its hardness, isotropic blurring or Gaussians with small anisotropic deformations have been mainly considered. Here, we widen this scenario by including large non-Gaussian blurs that arise in real camera movements. Our approach leverages the degradation model and proposes a new formulation of the Convolutional Neural Network (CNN) cascade model, where each network sub-module is constrained to solve a specific degradation: deblurring or upsampling. A new densely connected CNN-architecture is proposed where the output of each sub-module is restricted using some external knowledge to focus it on its specific task. As far we know this use of domain-knowledge to module-level is a novelty in SISR. To fit the finest model, a final sub-module takes care of the residual errors propagated by the previous sub-modules. We check our model with three state of the art (SOTA) datasets in SISR and compare the results with the SOTA models. The results show that our model is the only one able to manage our wider set of deformations. Furthermore, our model overcomes all current SOTA methods for a standard set of deformations. In terms of computational load, our model also improves on the two closest competitors in terms of efficiency. Although the approach is non-blind and requires an estimation of the blur kernel, it shows robustness to blur kernel estimation errors, making it a good alternative to blind models.
A New Automatic Change Detection Frame-work Based on Region Growing and Weighted Local Mutual Information: Analysis of Breast Tumor Response to Chemotherapy in Serial MR Images
Oct 19, 2021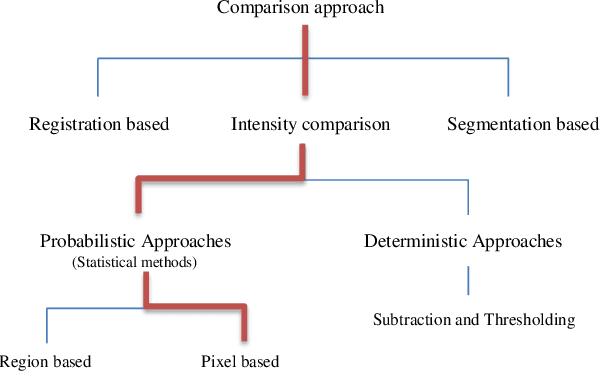
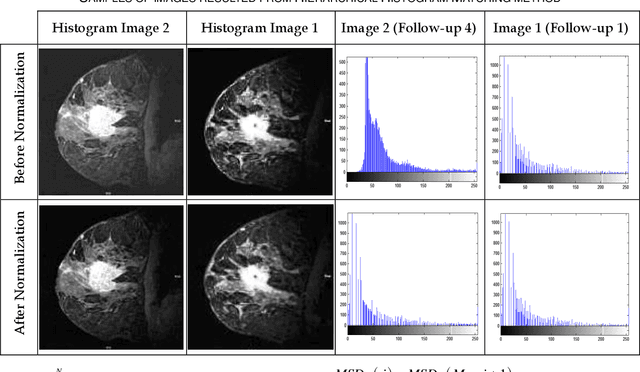
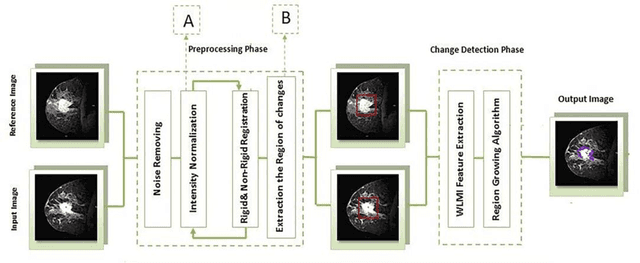
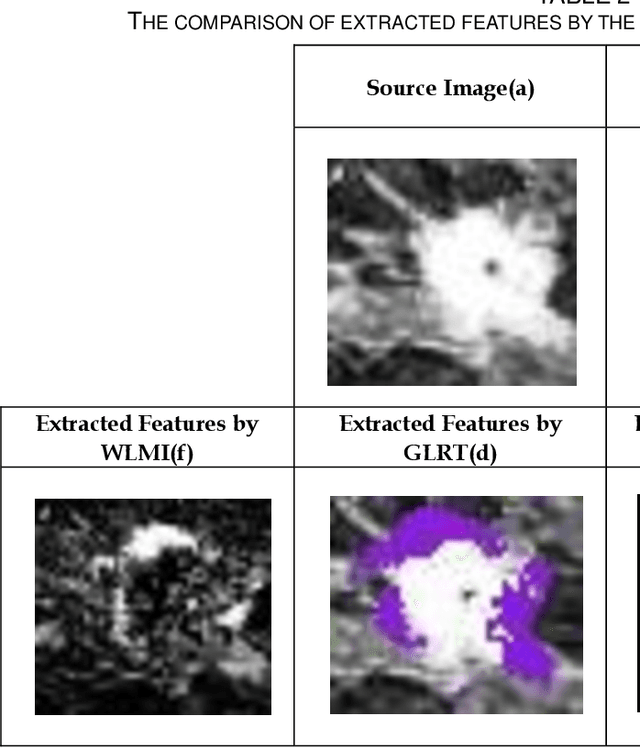
The automatic analysis of subtle changes between longitudinal MR images is an important task as it is still a challenging issue in scope of the breast medical image processing. In this paper we propose an effective automatic change detection framework composed of two phases since previously used methods have features with low distinctive power. First, in the preprocessing phase an intensity normalization method is suggested based on Hierarchical Histogram Matching (HHM) that is more robust to noise than previous methods. To eliminate undesirable changes and extract the regions containing significant changes the proposed Extraction Region of Changes (EROC) method is applied based on intensity distribution and Hill-Climbing algorithm. Second, in the detection phase a region growing-based approach is suggested to differentiate significant changes from unreal ones. Due to using proposed Weighted Local Mutual Information (WLMI) method to extract high level features and also utilizing the principle of the local consistency of changes, the proposed approach enjoys reasonable performance. The experimental results on both simulated and real longitudinal Breast MR Images confirm the effectiveness of the proposed framework. Also, this framework outperforms the human expert in some cases which can detect many lesion evolutions that are missed by expert.