 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MONCAE: Multi-Objective Neuroevolution of Convolutional Autoencoders
Jun 07, 2021
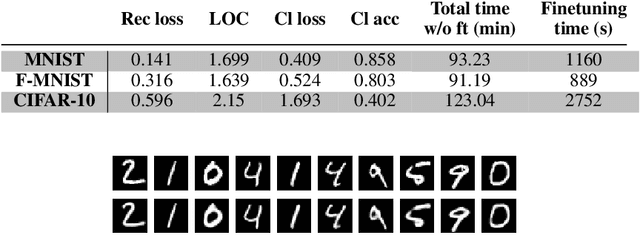


In this paper, we present a novel neuroevolutionary method to identify the architecture and hyperparameters of convolutional autoencoders. Remarkably, we used a hypervolume indicator in the context of neural architecture search for autoencoders, for the first time to our current knowledge. Results show that images were compressed by a factor of more than 10, while still retaining enough information to achieve image classification for the majority of the tasks. Thus, this new approach can be used to speed up the AutoML pipeline for image compression.
IR-NAS: Neural Architecture Search for Image Restoration
Sep 22, 2019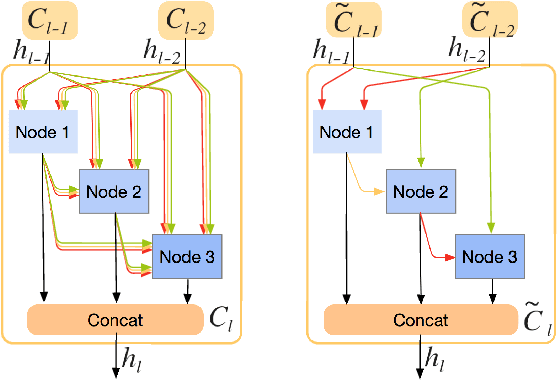
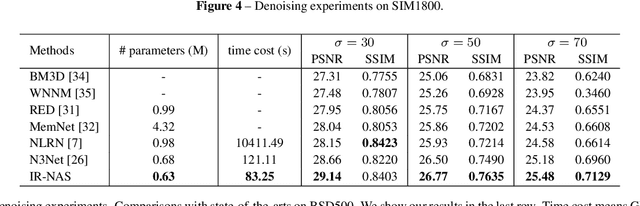
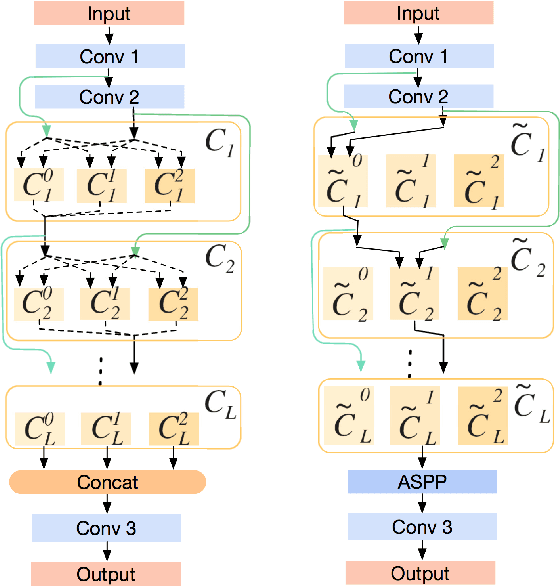
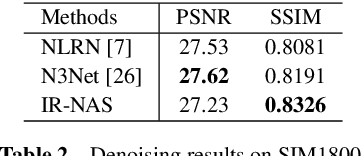
Recently, neural architecture search (NAS) methods have attracted much attention and outperformed manually designed architectures on a few high-level vision tasks. In this paper, we propose IR-NAS, an effort towards employing NAS to automatically design effective neural network architectures for low-level image restoration tasks, and apply to two such tasks: image denoising and image de-raining. IR-NAS adopts an flexible hierarchical search space, including inner cell structures and outer layer widths. The proposed IR-NAS is both memory and computationally efficient, which takes only 6 hours for searching using a single GPU and saves memory by sharing cell weights across different feature levels. We evaluate the effectiveness of our proposed IR-NAS on three different datasets, including an additive white Gaussian noise dataset BSD500, a realistic noise dataset SIM1800 and a challenging de-raining dataset Rain800. Results show that the architectures found by IR-NAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods. We also present analysis on the architectures found by NAS.
Image-based OoD-Detector Principles on Graph-based Input Data in Human Action Recognition
Mar 03, 2020
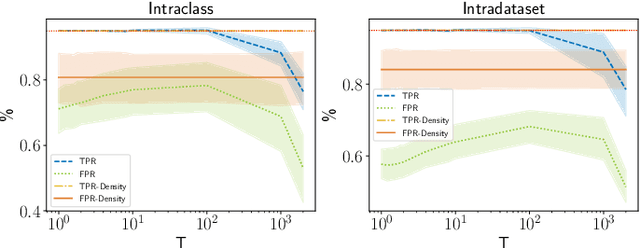
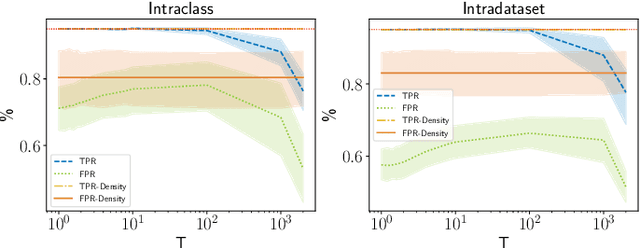
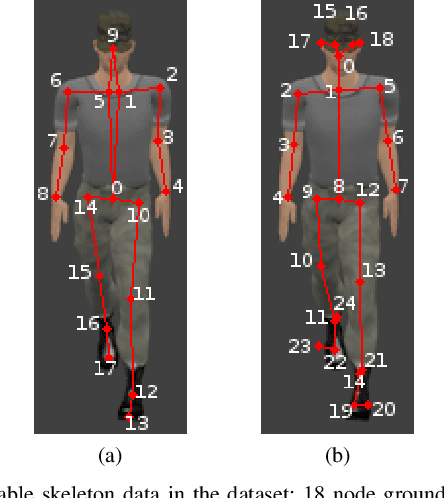
Living in a complex world like ours makes it unacceptable that a practical implementation of a machine learning system assumes a closed world. Therefore, it is necessary for such a learning-based system in a real world environment, to be aware of its own capabilities and limits and to be able to distinguish between confident and unconfident results of the inference, especially if the sample cannot be explained by the underlying distribution. This knowledge is particularly essential in safety-critical environments and tasks e.g. self-driving cars or medical applications. Towards this end, we transfer image-based Out-of-Distribution (OoD)-methods to graph-based data and show the applicability in action recognition. The contribution of this work is (i) the examination of the portability of recent image-based OoD-detectors for graph-based input data, (ii) a Metric Learning-based approach to detect OoD-samples, and (iii) the introduction of a novel semi-synthetic action recognition dataset. The evaluation shows that image-based OoD-methods can be applied to graph-based data. Additionally, there is a gap between the performance on intraclass and intradataset results. First methods as the examined baseline or ODIN provide reasonable results. More sophisticated network architectures - in contrast to their image-based application - were surpassed in the intradataset comparison and even lead to less classification accuracy.
Distribution Aligned Multimodal and Multi-Domain Image Stylization
Jun 02, 2020



Multimodal and multi-domain stylization are two important problems in the field of image style transfer. Currently, there are few methods that can perform both multimodal and multi-domain stylization simultaneously. In this paper, we propose a unified framework for multimodal and multi-domain style transfer with the support of both exemplar-based reference and randomly sampled guidance. The key component of our method is a novel style distribution alignment module that eliminates the explicit distribution gaps between various style domains and reduces the risk of mode collapse. The multimodal diversity is ensured by either guidance from multiple images or random style code, while the multi-domain controllability is directly achieved by using a domain label. We validate our proposed framework on painting style transfer with a variety of different artistic styles and genres. Qualitative and quantitative comparisons with state-of-the-art methods demonstrate that our method can generate high-quality results of multi-domain styles and multimodal instances with reference style guidance or random sampled style.
Large Scale Indexing of Generic Medical Image Data using Unbiased Shallow Keypoints and Deep CNN Features
Oct 20, 2020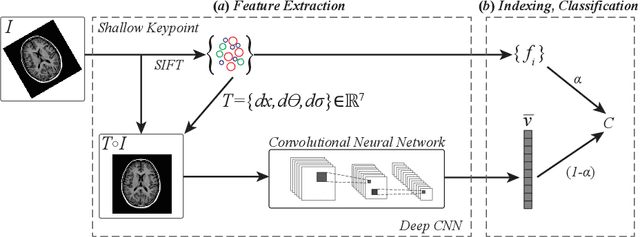
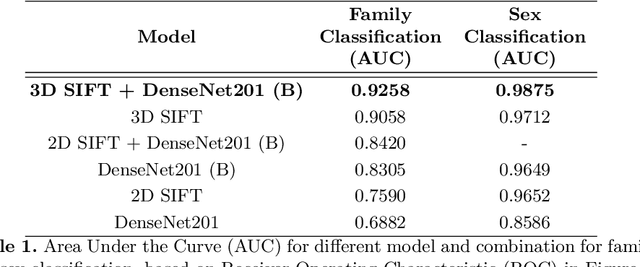
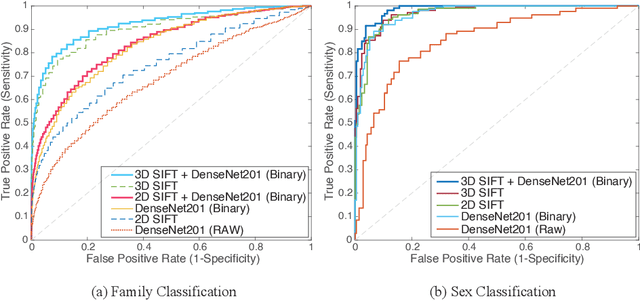
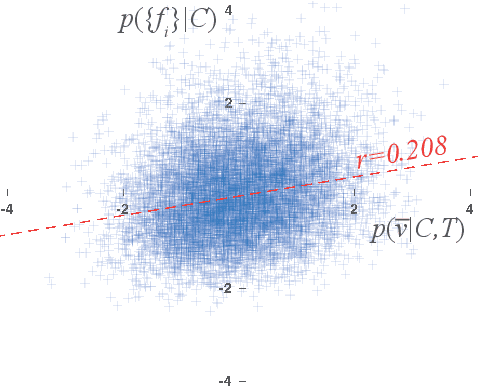
We propose a unified appearance model accounting for traditional shallow (i.e. 3D SIFT keypoints) and deep (i.e. CNN output layers) image feature representations, encoding respectively specific, localized neuroanatomical patterns and rich global information into a single indexing and classification framework. A novel Bayesian model combines shallow and deep features based on an assumption of conditional independence and validated by experiments indexing specific family members and general group categories in 3D MRI neuroimage data of 1010 subjects from the Human Connectome Project, including twins and non-twin siblings. A novel domain adaptation strategy is presented, transforming deep CNN vectors elements into binary class-informative descriptors. A GPU-based implementation of all processing is provided. State-of-the-art performance is achieved in large-scale neuroimage indexing, both in terms of computational complexity, accuracy in identifying family members and sex classification.
DEAL: Deep Evidential Active Learning for Image Classification
Jul 22, 2020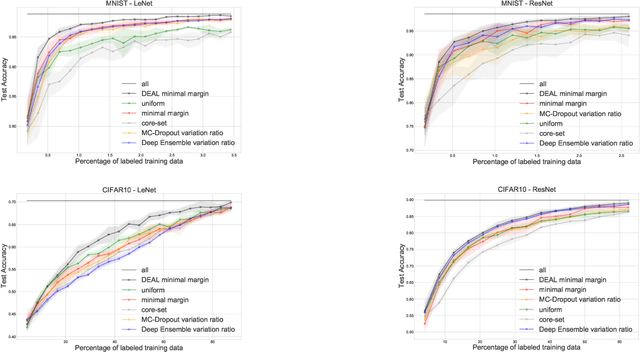
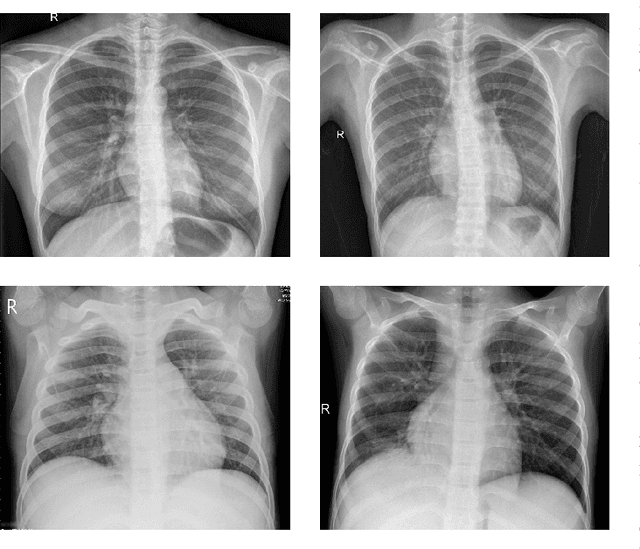
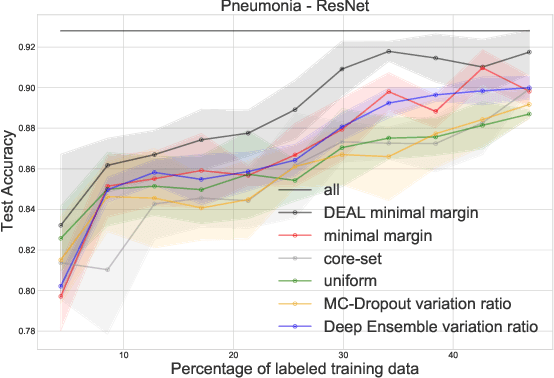

Convolutional Neural Networks (CNNs) have proven to be state-of-the-art models for supervised computer vision tasks, such as image classification. However, large labeled data sets are generally needed for the training and validation of such models. In many domains, unlabeled data is available but labeling is expensive, for instance when specific expert knowledge is required. Active Learning (AL) is one approach to mitigate the problem of limited labeled data. Through selecting the most informative and representative data instances for labeling, AL can contribute to more efficient learning of the model. Recent AL methods for CNNs propose different solutions for the selection of instances to be labeled. However, they do not perform consistently well and are often computationally expensive. In this paper, we propose a novel AL algorithm that efficiently learns from unlabeled data by capturing high prediction uncertainty. By replacing the softmax standard output of a CNN with the parameters of a Dirichlet density, the model learns to identify data instances that contribute efficiently to improving model performance during training. We demonstrate in several experiments with publicly available data that our method consistently outperforms other state-of-the-art AL approaches. It can be easily implemented and does not require extensive computational resources for training. Additionally, we are able to show the benefits of the approach on a real-world medical use case in the field of automated detection of visual signals for pneumonia on chest radiographs.
Annotation-Efficient Learning for Medical Image Segmentation based on Noisy Pseudo Labels and Adversarial Learning
Dec 29, 2020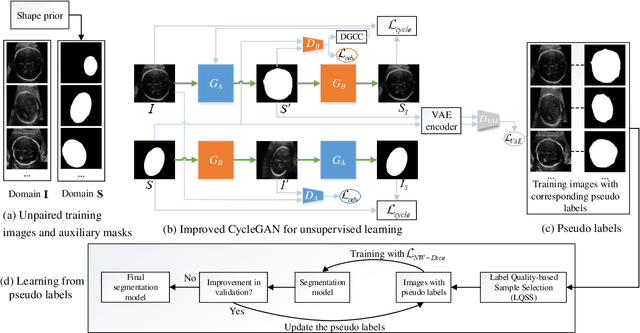
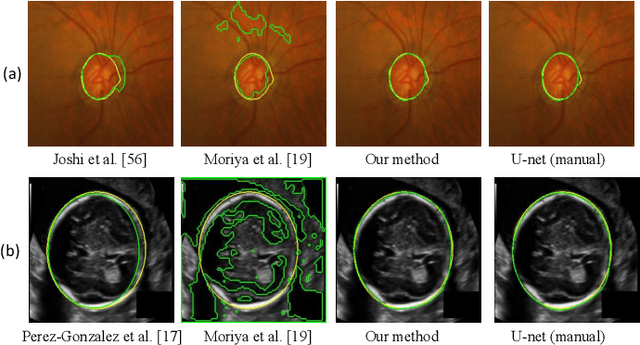
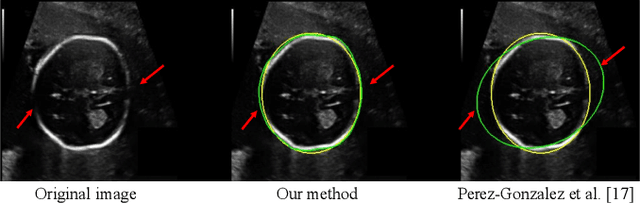
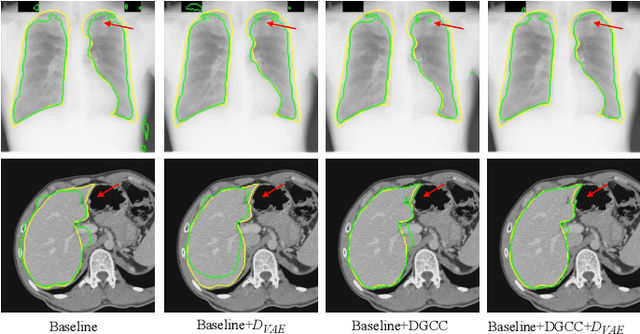
Despite that deep learning has achieved state-of-the-art performance for medical image segmentation, its success relies on a large set of manually annotated images for training that are expensive to acquire. In this paper, we propose an annotation-efficient learning framework for segmentation tasks that avoids annotations of training images, where we use an improved Cycle-Consistent Generative Adversarial Network (GAN) to learn from a set of unpaired medical images and auxiliary masks obtained either from a shape model or public datasets. We first use the GAN to generate pseudo labels for our training images under the implicit high-level shape constraint represented by a Variational Auto-encoder (VAE)-based discriminator with the help of the auxiliary masks, and build a Discriminator-guided Generator Channel Calibration (DGCC) module which employs our discriminator's feedback to calibrate the generator for better pseudo labels. To learn from the pseudo labels that are noisy, we further introduce a noise-robust iterative learning method using noise-weighted Dice loss. We validated our framework with two situations: objects with a simple shape model like optic disc in fundus images and fetal head in ultrasound images, and complex structures like lung in X-Ray images and liver in CT images. Experimental results demonstrated that 1) Our VAE-based discriminator and DGCC module help to obtain high-quality pseudo labels. 2) Our proposed noise-robust learning method can effectively overcome the effect of noisy pseudo labels. 3) The segmentation performance of our method without using annotations of training images is close or even comparable to that of learning from human annotations.
ParNet: Position-aware Aggregated Relation Network for Image-Text matching
Jun 17, 2019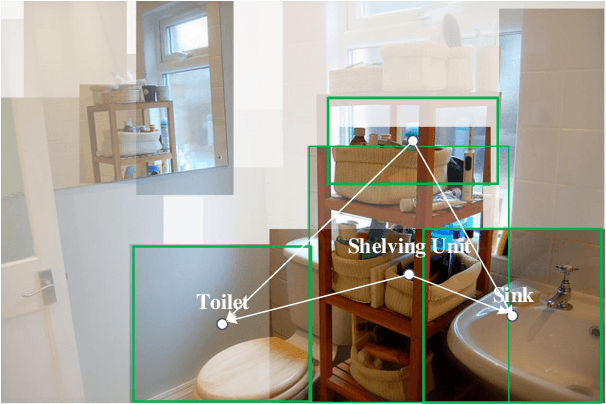
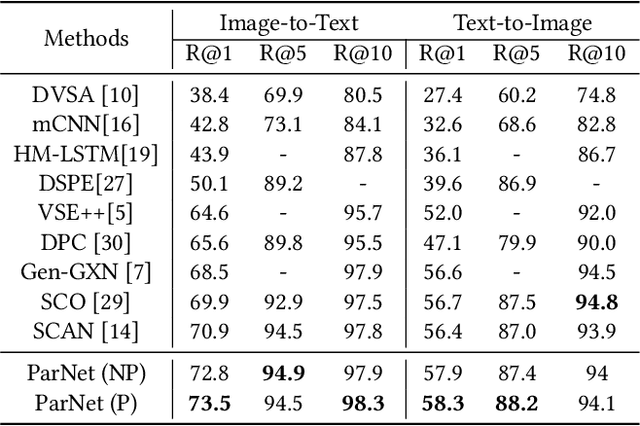
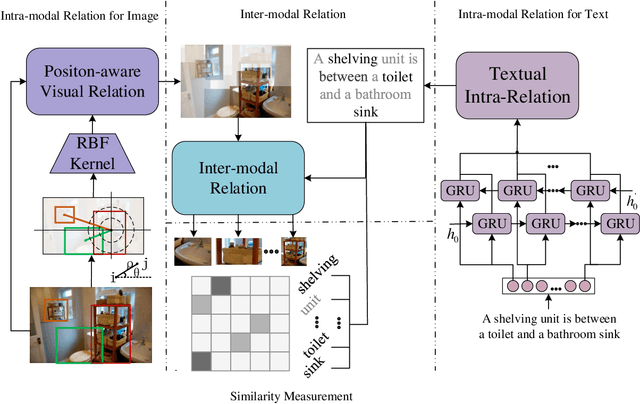
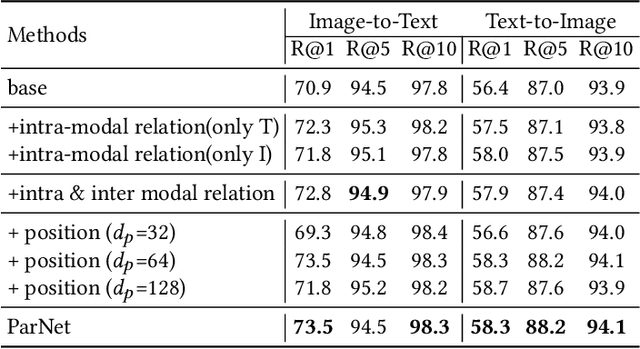
Exploring fine-grained relationship between entities(e.g. objects in image or words in sentence) has great contribution to understand multimedia content precisely. Previous attention mechanism employed in image-text matching either takes multiple self attention steps to gather correspondences or uses image objects (or words) as context to infer image-text similarity. However, they only take advantage of semantic information without considering that objects' relative position also contributes to image understanding. To this end, we introduce a novel position-aware relation module to model both the semantic and spatial relationship simultaneously for image-text matching in this paper. Given an image, our method utilizes the location of different objects to capture spatial relationship innovatively. With the combination of semantic and spatial relationship, it's easier to understand the content of different modalities (images and sentences) and capture fine-grained latent correspondences of image-text pairs. Besides, we employ a two-step aggregated relation module to capture interpretable alignment of image-text pairs. The first step, we call it intra-modal relation mechanism, in which we computes responses between different objects in an image or different words in a sentence separately; The second step, we call it inter-modal relation mechanism, in which the query plays a role of textual context to refine the relationship among object proposals in an image. In this way, our position-aware aggregated relation network (ParNet) not only knows which entities are relevant by attending on different objects (words) adaptively, but also adjust the inter-modal correspondence according to the latent alignments according to query's content. Our approach achieves the state-of-the-art results on MS-COCO dataset.
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021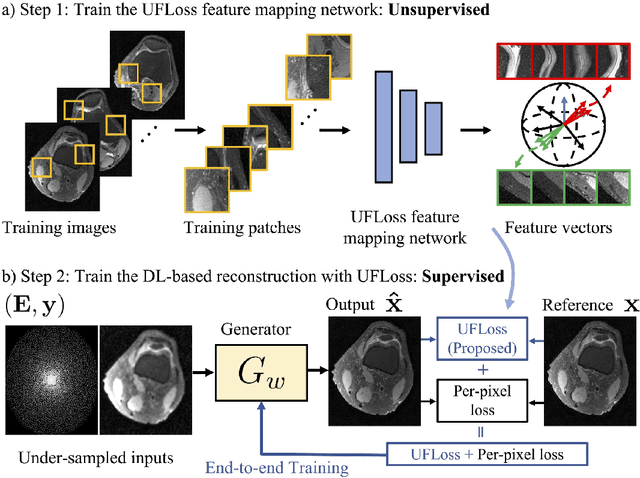
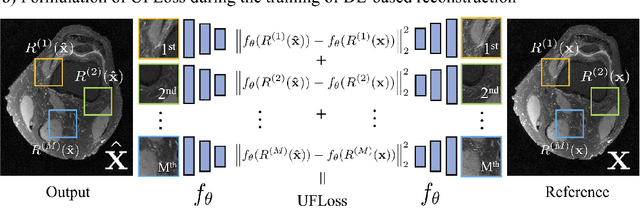
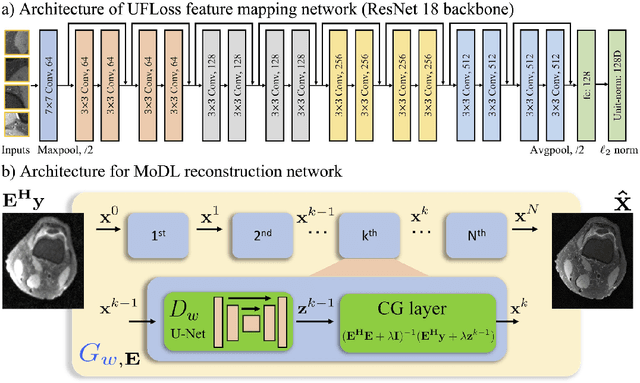
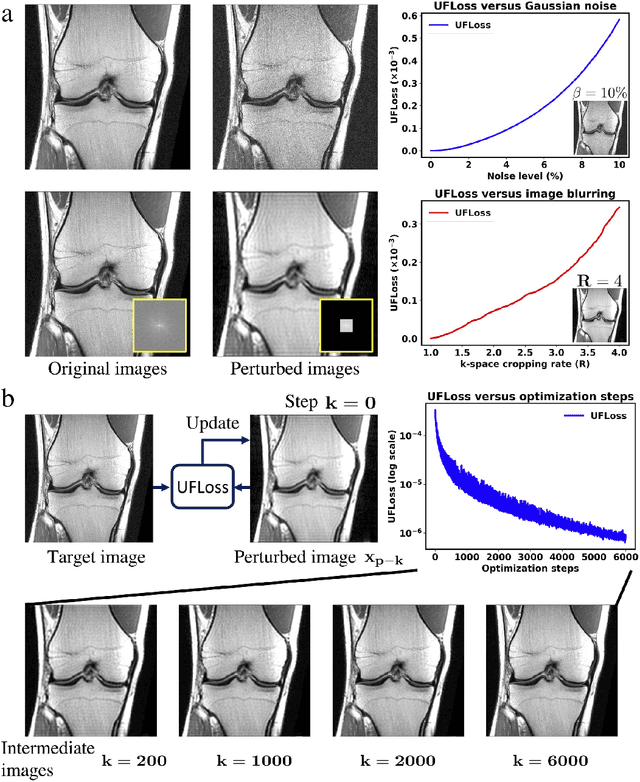
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.
Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection
Oct 26, 2021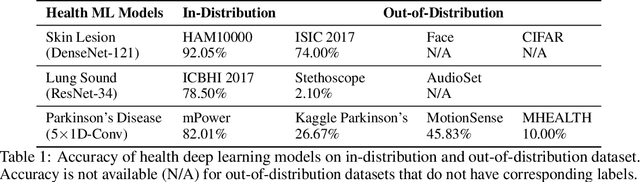
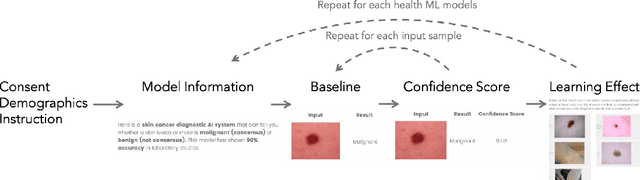
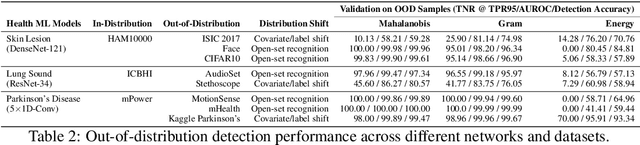

Unpredictable ML model behavior on unseen data, especially in the health domain, raises serious concerns about its safety as repercussions for mistakes can be fatal. In this paper, we explore the feasibility of using state-of-the-art out-of-distribution detectors for reliable and trustworthy diagnostic predictions. We select publicly available deep learning models relating to various health conditions (e.g., skin cancer, lung sound, and Parkinson's disease) using various input data types (e.g., image, audio, and motion data). We demonstrate that these models show unreasonable predictions on out-of-distribution datasets. We show that Mahalanobis distance- and Gram matrices-based out-of-distribution detection methods are able to detect out-of-distribution data with high accuracy for the health models that operate on different modalities. We then translate the out-of-distribution score into a human interpretable CONFIDENCE SCORE to investigate its effect on the users' interaction with health ML applications. Our user study shows that the \textsc{confidence score} helped the participants only trust the results with a high score to make a medical decision and disregard results with a low score. Through this work, we demonstrate that dataset shift is a critical piece of information for high-stake ML applications, such as medical diagnosis and healthcare, to provide reliable and trustworthy predictions to the users.