 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TöRF: Time-of-Flight Radiance Fields for Dynamic Scene View Synthesis
Sep 30, 2021

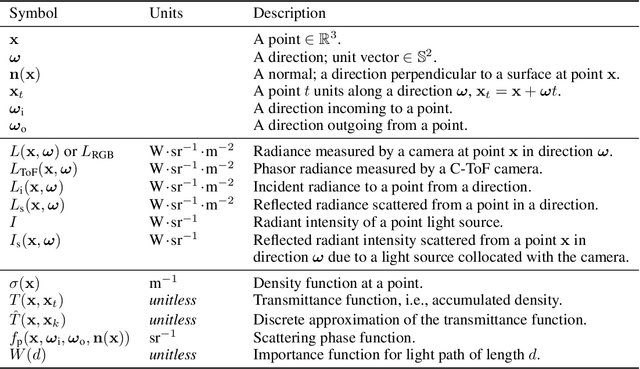
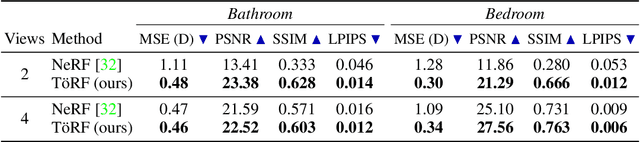
Neural networks can represent and accurately reconstruct radiance fields for static 3D scenes (e.g., NeRF). Several works extend these to dynamic scenes captured with monocular video, with promising performance. However, the monocular setting is known to be an under-constrained problem, and so methods rely on data-driven priors for reconstructing dynamic content. We replace these priors with measurements from a time-of-flight (ToF) camera, and introduce a neural representation based on an image formation model for continuous-wave ToF cameras. Instead of working with processed depth maps, we model the raw ToF sensor measurements to improve reconstruction quality and avoid issues with low reflectance regions, multi-path interference, and a sensor's limited unambiguous depth range. We show that this approach improves robustness of dynamic scene reconstruction to erroneous calibration and large motions, and discuss the benefits and limitations of integrating RGB+ToF sensors that are now available on modern smartphones.
Identifying the key components in ResNet-50 for diabetic retinopathy grading from fundus images: a systematic investigation
Oct 27, 2021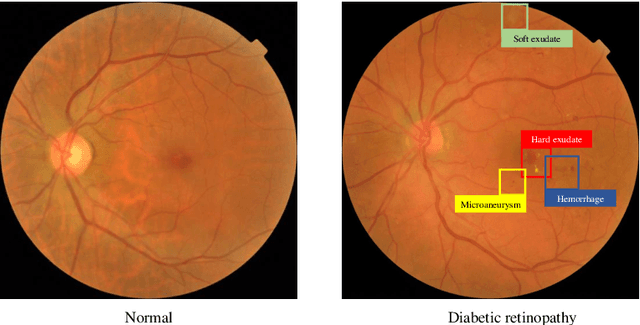
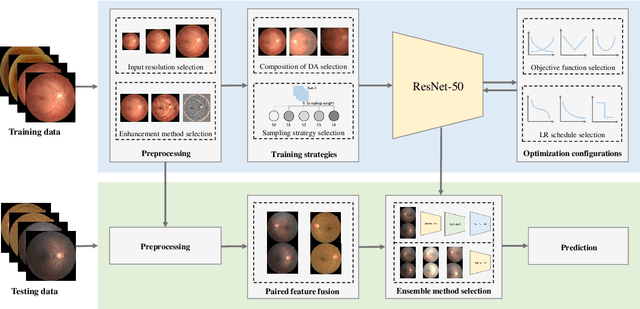

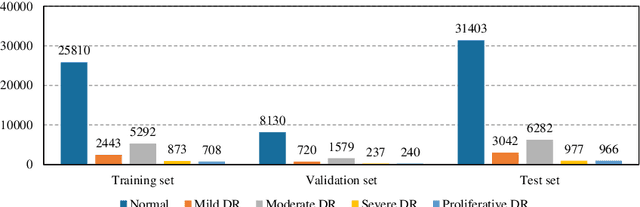
Although deep learning based diabetic retinopathy (DR) classification methods typically benefit from well-designed architectures of convolutional neural networks, the training setting also has a non-negligible impact on the prediction performance. The training setting includes various interdependent components, such as objective function, data sampling strategy and data augmentation approach. To identify the key components in a standard deep learning framework (ResNet-50) for DR grading, we systematically analyze the impact of several major components. Extensive experiments are conducted on a publicly-available dataset EyePACS. We demonstrate that (1) the ResNet-50 framework for DR grading is sensitive to input resolution, objective function, and composition of data augmentation, (2) using mean square error as the loss function can effectively improve the performance with respect to a task-specific evaluation metric, namely the quadratically-weighted Kappa, (3) utilizing eye pairs boosts the performance of DR grading and (4) using data resampling to address the problem of imbalanced data distribution in EyePACS hurts the performance. Based on these observations and an optimal combination of the investigated components, our framework, without any specialized network design, achieves the state-of-the-art result (0.8631 for Kappa) on the EyePACS test set (a total of 42670 fundus images) with only image-level labels. Our codes and pre-trained model are available at https://github.com/YijinHuang/pytorch-classification
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer
Aug 09, 2021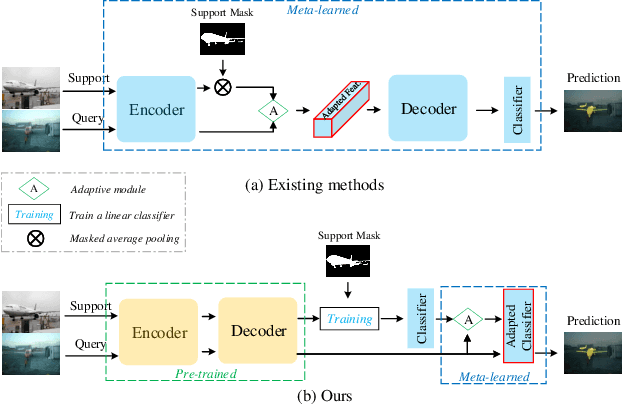
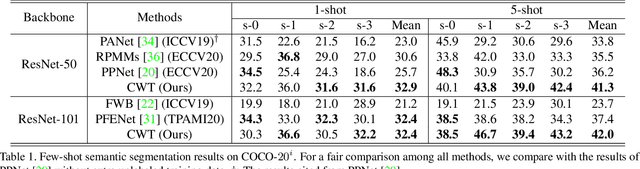

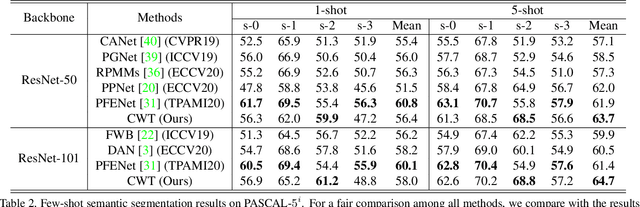
A few-shot semantic segmentation model is typically composed of a CNN encoder, a CNN decoder and a simple classifier (separating foreground and background pixels). Most existing methods meta-learn all three model components for fast adaptation to a new class. However, given that as few as a single support set image is available, effective model adaption of all three components to the new class is extremely challenging. In this work we propose to simplify the meta-learning task by focusing solely on the simplest component, the classifier, whilst leaving the encoder and decoder to pre-training. We hypothesize that if we pre-train an off-the-shelf segmentation model over a set of diverse training classes with sufficient annotations, the encoder and decoder can capture rich discriminative features applicable for any unseen classes, rendering the subsequent meta-learning stage unnecessary. For the classifier meta-learning, we introduce a Classifier Weight Transformer (CWT) designed to dynamically adapt the supportset trained classifier's weights to each query image in an inductive way. Extensive experiments on two standard benchmarks show that despite its simplicity, our method outperforms the state-of-the-art alternatives, often by a large margin.Code is available on https://github.com/zhiheLu/CWT-for-FSS.
Fusion of Complex Networks-based Global and Local Features for Texture Classification
Jun 20, 2021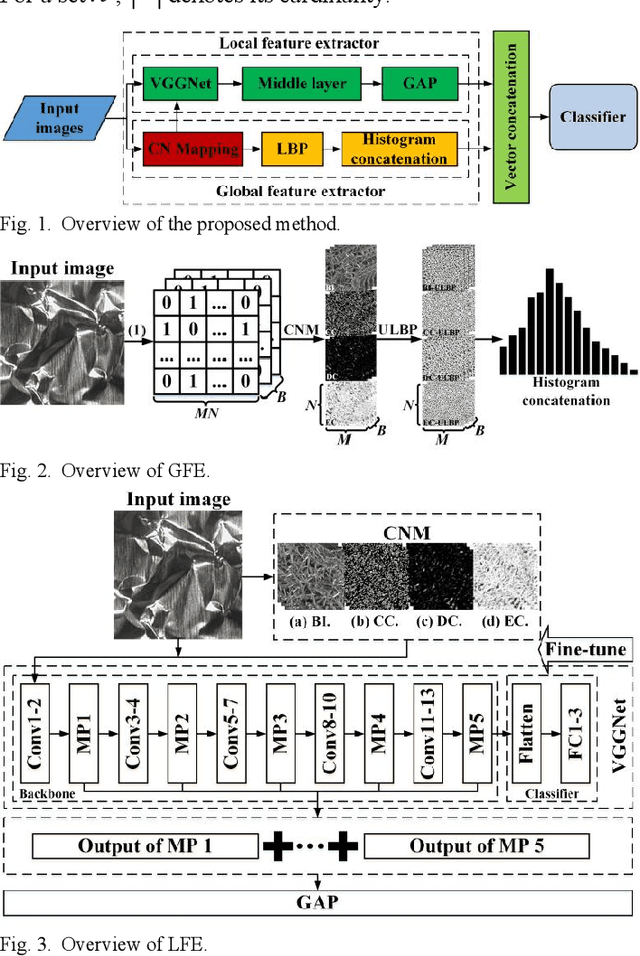
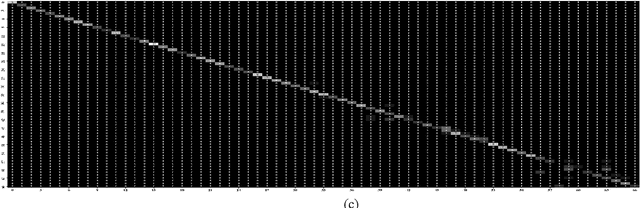
To realize accurate texture classification, this article proposes a complex networks (CN)-based multi-feature fusion method to recognize texture images. Specifically, we propose two feature extractors to detect the global and local features of texture images respectively. To capture the global features, we first map a texture image as an undirected graph based on pixel location and intensity, and three feature measurements are designed to further decipher the image features, which retains the image information as much as possible. Then, given the original band images (BI) and the generated feature images, we encode them based on the local binary patterns (LBP). Therefore, the global feature vector is obtained by concatenating four spatial histograms. To decipher the local features, we jointly transfer and fine-tune the pre-trained VGGNet-16 model. Next, we fuse and connect the middle outputs of max-pooling layers (MP), and generate the local feature vector by a global average pooling layer (GAP). Finally, the global and local feature vectors are concatenated to form the final feature representation of texture images. Experiment results show that the proposed method outperforms the state-of-the-art statistical descriptors and the deep convolutional neural networks (CNN) models.
Joint coded aperture optimization and compressive hyperspectral image classification using 3D coded neural network
Oct 04, 2020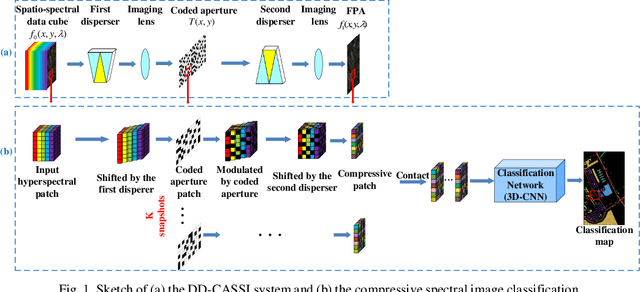

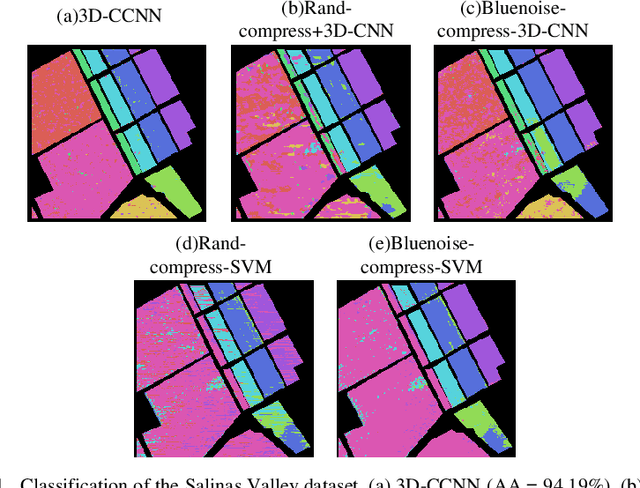

Hyperspectral image classification (HIC) is an active research topic in remote sensing. However, the huge volume of three-dimensional (3D) hyperspectral images poses big challenges in data acquisition, storage, transmission and processing. To overcome these limitations, this paper develops a novel deep learning HIC approach based on the compressive measurements of coded-aperture snapshot spectral imaging (CASSI) system, without reconstructing the complete hyperspectral data cube. A new kind of deep learning strategy, namely 3D coded convolutional neural network (3D-CCNN) is proposed to efficiently solve for the HIC problem, where the hardware-based coded aperture is regarded as a pixel-wise connected network layer. An end-to-end training method is developed to jointly optimize the network parameters and the coded aperture pattern with periodic structure. The accuracy of HIC approach is effectively improved by involving the degrees of optimization freedom from the coded aperture. The superiority of the proposed method is assessed on some public hyperspectral datasets over the state-of-the-art HIC methods.
Reconstruct, Rasterize and Backprop: Dense shape and pose estimation from a single image
Apr 25, 2020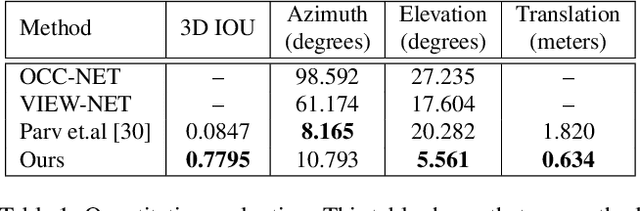

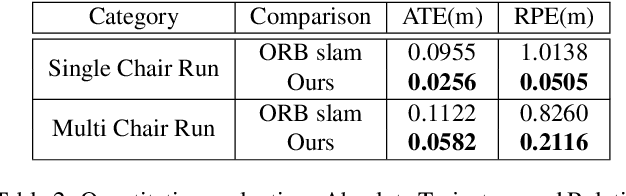

This paper presents a new system to obtain dense object reconstructions along with 6-DoF poses from a single image. Geared towards high fidelity reconstruction, several recent approaches leverage implicit surface representations and deep neural networks to estimate a 3D mesh of an object, given a single image. However, all such approaches recover only the shape of an object; the reconstruction is often in a canonical frame, unsuitable for downstream robotics tasks. To this end, we leverage recent advances in differentiable rendering (in particular, rasterization) to close the loop with 3D reconstruction in camera frame. We demonstrate that our approach---dubbed reconstruct, rasterize and backprop (RRB) achieves significantly lower pose estimation errors compared to prior art, and is able to recover dense object shapes and poses from imagery. We further extend our results to an (offline) setup, where we demonstrate a dense monocular object-centric egomotion estimation system.
Transferability of Adversarial Examples to Attack Cloud-based Image Classifier Service
Jan 20, 2020

In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. While many recent works demonstrated that DL models are vulnerable to adversarial examples. Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security. In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose a novel attack method, Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model, which achieves a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our method finds the adversarial examples using only two queries per image; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that FFL-PGD attack has a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services. Our defense technology is mainly divided into model training stage and image preprocessing stage.
Deep Homography Estimation in Dynamic Surgical Scenes for Laparoscopic Camera Motion Extraction
Sep 30, 2021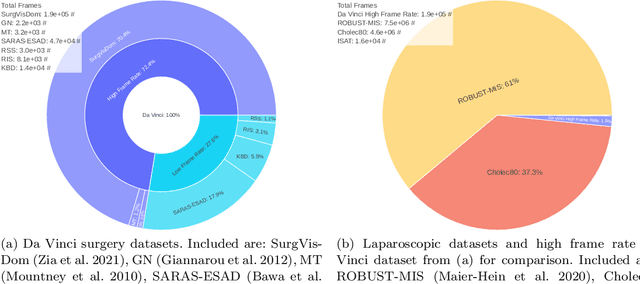
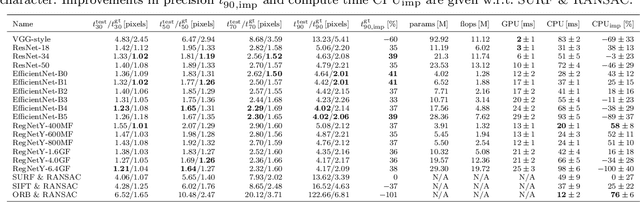
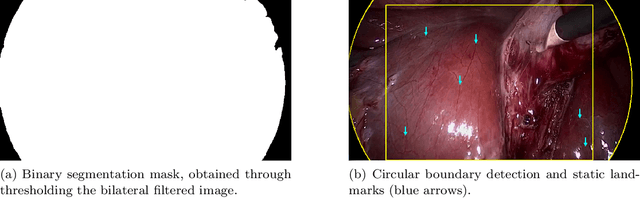
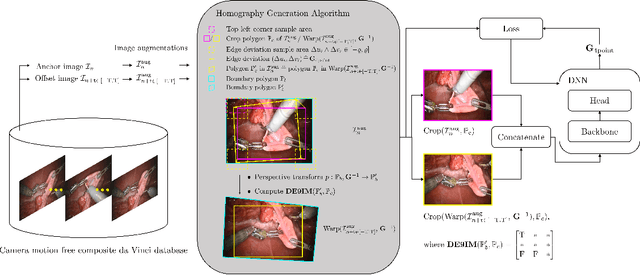
Current laparoscopic camera motion automation relies on rule-based approaches or only focuses on surgical tools. Imitation Learning (IL) methods could alleviate these shortcomings, but have so far been applied to oversimplified setups. Instead of extracting actions from oversimplified setups, in this work we introduce a method that allows to extract a laparoscope holder's actions from videos of laparoscopic interventions. We synthetically add camera motion to a newly acquired dataset of camera motion free da Vinci surgery image sequences through the introduction of a novel homography generation algorithm. The synthetic camera motion serves as a supervisory signal for camera motion estimation that is invariant to object and tool motion. We perform an extensive evaluation of state-of-the-art (SOTA) Deep Neural Networks (DNNs) across multiple compute regimes, finding our method transfers from our camera motion free da Vinci surgery dataset to videos of laparoscopic interventions, outperforming classical homography estimation approaches in both, precision by 41%, and runtime on a CPU by 43%.
ShadingNet: Image Intrinsics by Fine-Grained Shading Decomposition
Dec 09, 2019



In general, intrinsic image decomposition algorithms interpret shading as one unified component including all photometric effects. As shading transitions are generally smoother than albedo changes, these methods may fail in distinguishing strong (cast) shadows from albedo variations. That in return may leak into albedo map predictions. Therefore, in this paper, we propose to decompose the shading component into direct (illumination) and indirect shading (ambient light and shadows). The aim is to distinguish strong cast shadows from reflectance variations. Two end-to-end supervised CNN models (ShadingNets) are proposed exploiting the fine-grained shading model. Furthermore, surface normal features are jointly learned by the proposed CNN networks. Surface normals are expected to assist the decomposition task. A large-scale dataset of scene-level synthetic images of outdoor natural environments is provided with intrinsic image ground-truths. Large scale experiments show that our CNN approach using fine-grained shading decomposition outperforms state-of-the-art methods using unified shading.
DRMIME: Differentiable Mutual Information and Matrix Exponential for Multi-Resolution Image Registration
Jan 27, 2020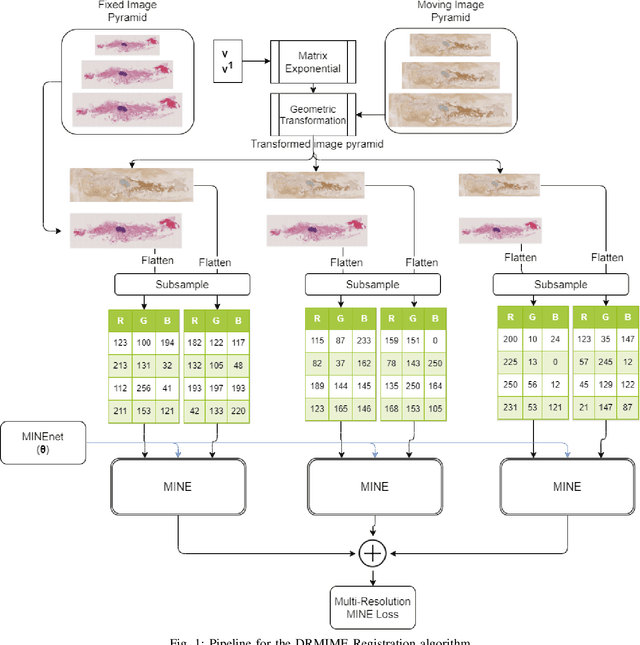
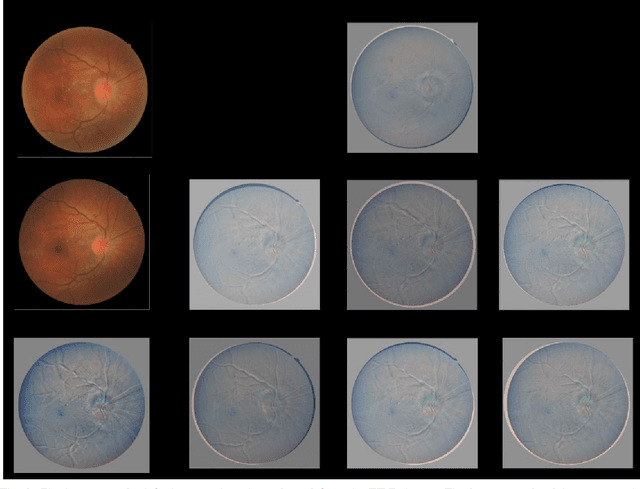
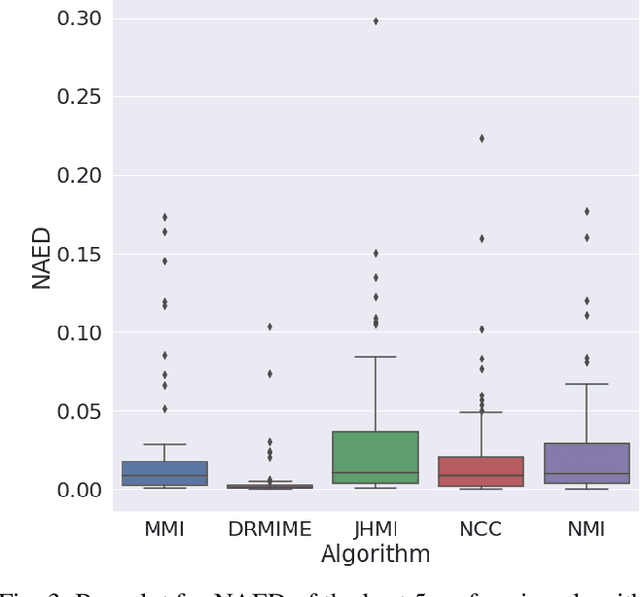
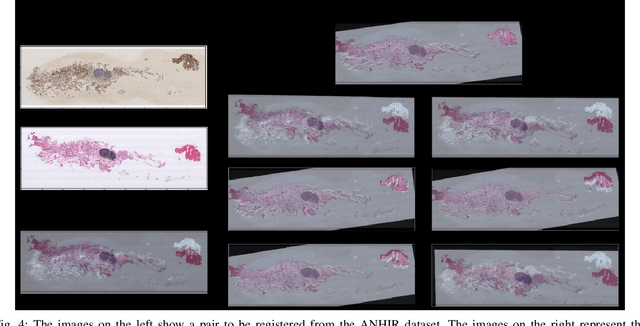
In this work, we present a novel unsupervised image registration algorithm. It is differentiable end-to-end and can be used for both multi-modal and mono-modal registration. This is done using mutual information (MI) as a metric. The novelty here is that rather than using traditional ways of approximating MI, we use a neural estimator called MINE and supplement it with matrix exponential for transformation matrix computation. This leads to improved results as compared to the standard algorithms available out-of-the-box in state-of-the-art image registration toolboxes.