 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SiWa: See into Walls via Deep UWB Radar
Oct 28, 2021
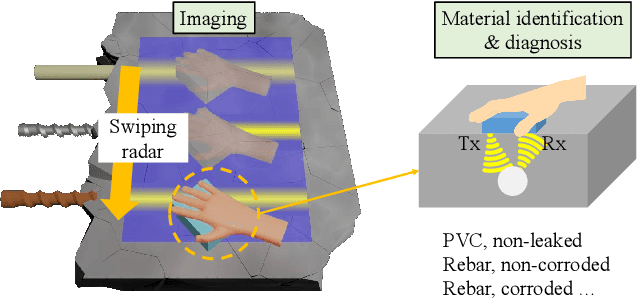


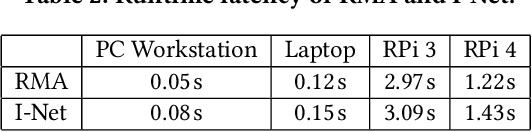
Being able to see into walls is crucial for diagnostics of building health; it enables inspections of wall structure without undermining the structural integrity. However, existing sensing devices do not seem to offer a full capability in mapping the in-wall structure while identifying their status (e.g., seepage and corrosion). In this paper, we design and implement SiWa as a low-cost and portable system for wall inspections. Built upon a customized IR-UWB radar, SiWa scans a wall as a user swipes its probe along the wall surface; it then analyzes the reflected signals to synthesize an image and also to identify the material status. Although conventional schemes exist to handle these problems individually, they require troublesome calibrations that largely prevent them from practical adoptions. To this end, we equip SiWa with a deep learning pipeline to parse the rich sensory data. With an ingenious construction and innovative training, the deep learning modules perform structural imaging and the subsequent analysis on material status, without the need for parameter tuning and calibrations. We build SiWa as a prototype and evaluate its performance via extensive experiments and field studies; results confirm that SiWa accurately maps in-wall structures, identifies their materials, and detects possible failures, suggesting a promising solution for diagnosing building health with lower effort and cost.
* 14 pages
BiaSwap: Removing dataset bias with bias-tailored swapping augmentation
Aug 23, 2021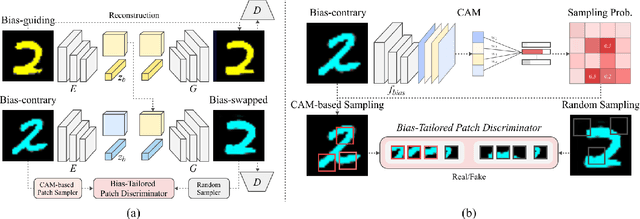
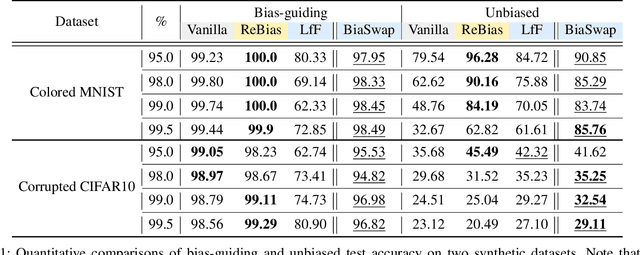

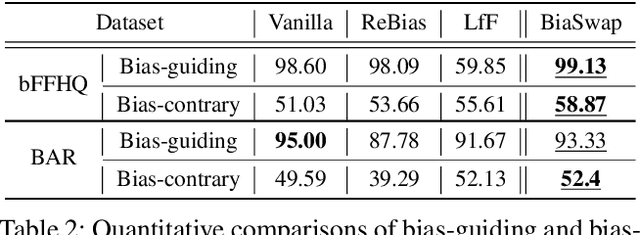
Deep neural networks often make decisions based on the spurious correlations inherent in the dataset, failing to generalize in an unbiased data distribution. Although previous approaches pre-define the type of dataset bias to prevent the network from learning it, recognizing the bias type in the real dataset is often prohibitive. This paper proposes a novel bias-tailored augmentation-based approach, BiaSwap, for learning debiased representation without requiring supervision on the bias type. Assuming that the bias corresponds to the easy-to-learn attributes, we sort the training images based on how much a biased classifier can exploits them as shortcut and divide them into bias-guiding and bias-contrary samples in an unsupervised manner. Afterwards, we integrate the style-transferring module of the image translation model with the class activation maps of such biased classifier, which enables to primarily transfer the bias attributes learned by the classifier. Therefore, given the pair of bias-guiding and bias-contrary, BiaSwap generates the bias-swapped image which contains the bias attributes from the bias-contrary images, while preserving bias-irrelevant ones in the bias-guiding images. Given such augmented images, BiaSwap demonstrates the superiority in debiasing against the existing baselines over both synthetic and real-world datasets. Even without careful supervision on the bias, BiaSwap achieves a remarkable performance on both unbiased and bias-guiding samples, implying the improved generalization capability of the model.
Lifelong GAN: Continual Learning for Conditional Image Generation
Jul 23, 2019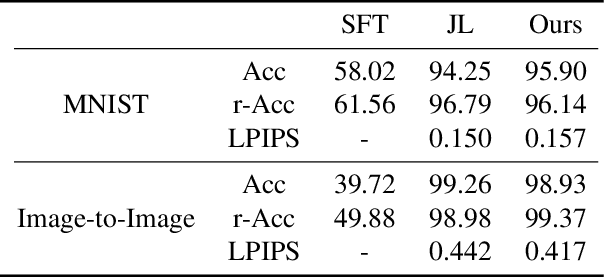
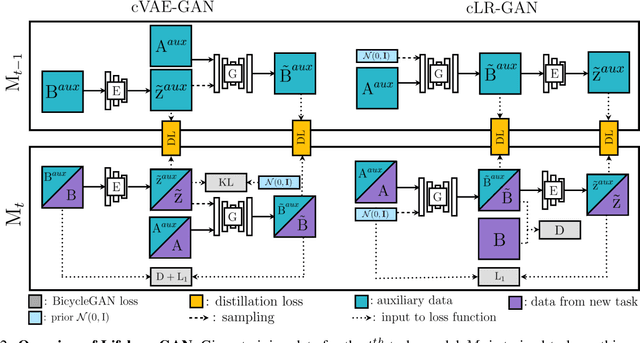
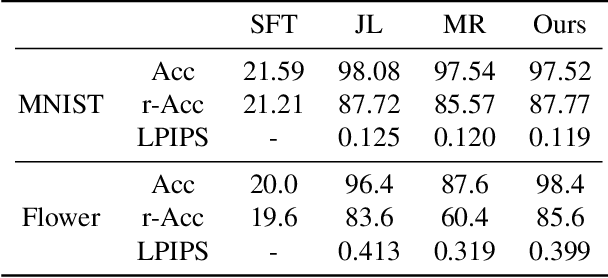

Lifelong learning is challenging for deep neural networks due to their susceptibility to catastrophic forgetting. Catastrophic forgetting occurs when a trained network is not able to maintain its ability to accomplish previously learned tasks when it is trained to perform new tasks. We study the problem of lifelong learning for generative models, extending a trained network to new conditional generation tasks without forgetting previous tasks, while assuming access to the training data for the current task only. In contrast to state-of-the-art memory replay based approaches which are limited to label-conditioned image generation tasks, a more generic framework for continual learning of generative models under different conditional image generation settings is proposed in this paper. Lifelong GAN employs knowledge distillation to transfer learned knowledge from previous networks to the new network. This makes it possible to perform image-conditioned generation tasks in a lifelong learning setting. We validate Lifelong GAN for both image-conditioned and label-conditioned generation tasks, and provide qualitative and quantitative results to show the generality and effectiveness of our method.
Noise or Signal: The Role of Image Backgrounds in Object Recognition
Jun 17, 2020
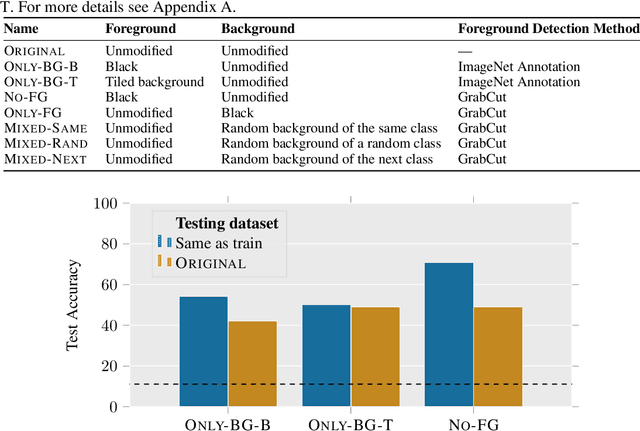
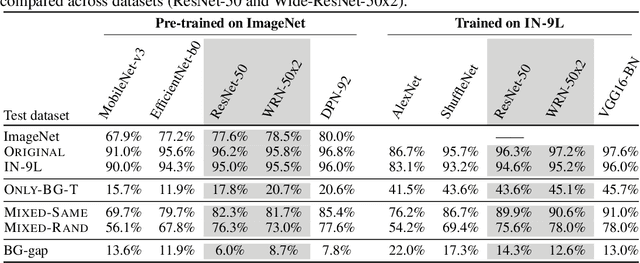

We assess the tendency of state-of-the-art object recognition models to depend on signals from image backgrounds. We create a toolkit for disentangling foreground and background signal on ImageNet images, and find that (a) models can achieve non-trivial accuracy by relying on the background alone, (b) models often misclassify images even in the presence of correctly classified foregrounds--up to 87.5% of the time with adversarially chosen backgrounds, and (c) more accurate models tend to depend on backgrounds less. Our analysis of backgrounds brings us closer to understanding which correlations machine learning models use, and how they determine models' out of distribution performance.
Pose Recognition in the Wild: Animal pose estimation using Agglomerative Clustering and Contrastive Learning
Nov 16, 2021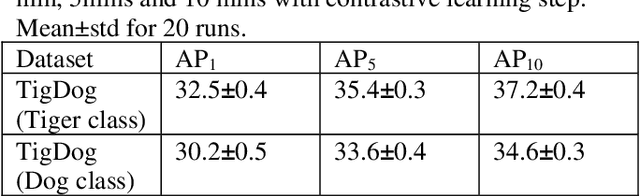
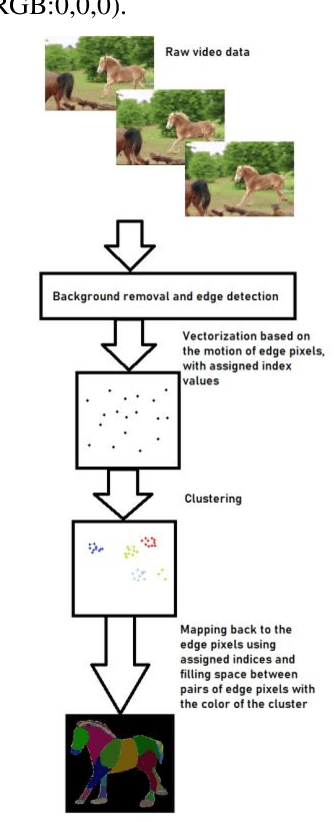
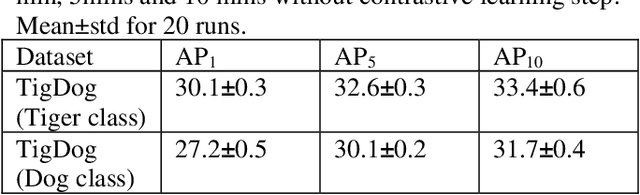

Animal pose estimation has recently come into the limelight due to its application in biology, zoology, and aquaculture. Deep learning methods have effectively been applied to human pose estimation. However, the major bottleneck to the application of these methods to animal pose estimation is the unavailability of sufficient quantities of labeled data. Though there are ample quantities of unlabelled data publicly available, it is economically impractical to label large quantities of data for each animal. In addition, due to the wide variety of body shapes in the animal kingdom, the transfer of knowledge across domains is ineffective. Given the fact that the human brain is able to recognize animal pose without requiring large amounts of labeled data, it is only reasonable that we exploit unsupervised learning to tackle the problem of animal pose recognition from the available, unlabelled data. In this paper, we introduce a novel architecture that is able to recognize the pose of multiple animals fromunlabelled data. We do this by (1) removing background information from each image and employing an edge detection algorithm on the body of the animal, (2) Tracking motion of the edge pixels and performing agglomerative clustering to segment body parts, (3) employing contrastive learning to discourage grouping of distant body parts together. Hence we are able to distinguish between body parts of the animal, based on their visual behavior, instead of the underlying anatomy. Thus, we are able to achieve a more effective classification of the data than their human-labeled counterparts. We test our model on the TigDog and WLD (WildLife Documentary) datasets, where we outperform state-of-the-art approaches by a significant margin. We also study the performance of our model on other public data to demonstrate the generalization ability of our model.
Very Long Natural Scenery Image Prediction by Outpainting
Dec 29, 2019
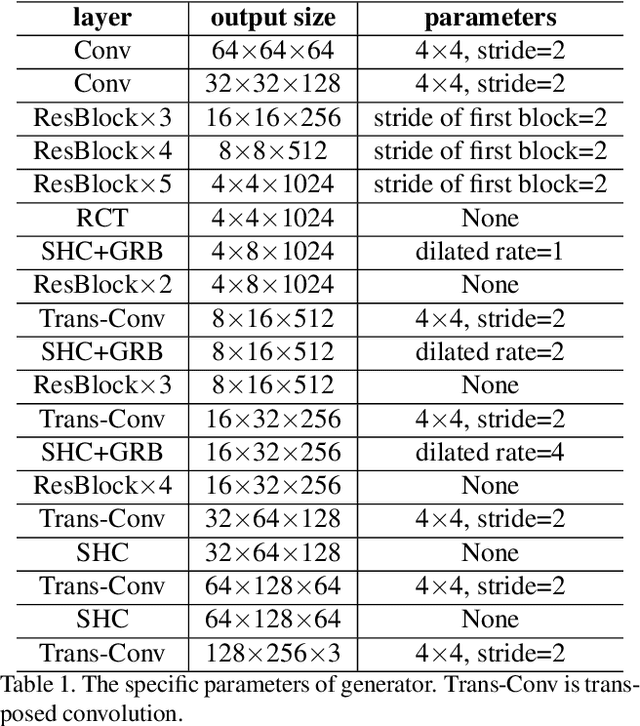

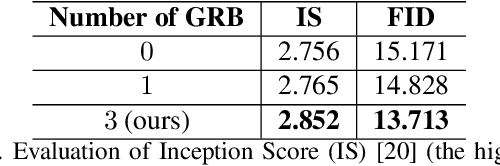
Comparing to image inpainting, image outpainting receives less attention due to two challenges in it. The first challenge is how to keep the spatial and content consistency between generated images and original input. The second challenge is how to maintain high quality in generated results, especially for multi-step generations in which generated regions are spatially far away from the initial input. To solve the two problems, we devise some innovative modules, named Skip Horizontal Connection and Recurrent Content Transfer, and integrate them into our designed encoder-decoder structure. By this design, our network can generate highly realistic outpainting prediction effectively and efficiently. Other than that, our method can generate new images with very long sizes while keeping the same style and semantic content as the given input. To test the effectiveness of the proposed architecture, we collect a new scenery dataset with diverse, complicated natural scenes. The experimental results on this dataset have demonstrated the efficacy of our proposed network. The code and dataset are available from https://github.com/z-x-yang/NS-Outpainting.
Robust Reflection Removal with Reflection-free Flash-only Cues
Mar 30, 2021
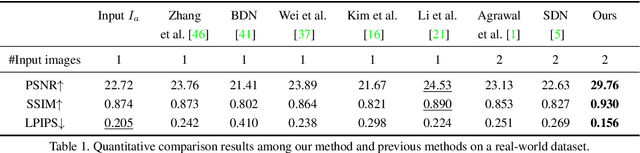
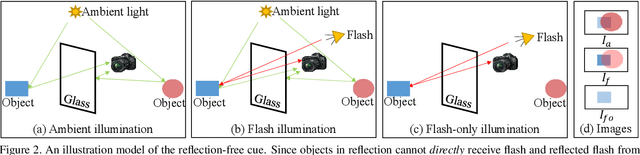
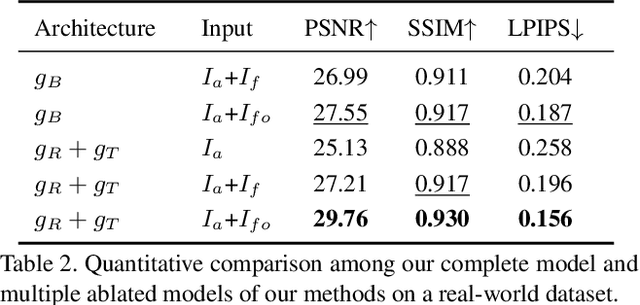
We propose a simple yet effective reflection-free cue for robust reflection removal from a pair of flash and ambient (no-flash) images. The reflection-free cue exploits a flash-only image obtained by subtracting the ambient image from the corresponding flash image in raw data space. The flash-only image is equivalent to an image taken in a dark environment with only a flash on. We observe that this flash-only image is visually reflection-free, and thus it can provide robust cues to infer the reflection in the ambient image. Since the flash-only image usually has artifacts, we further propose a dedicated model that not only utilizes the reflection-free cue but also avoids introducing artifacts, which helps accurately estimate reflection and transmission. Our experiments on real-world images with various types of reflection demonstrate the effectiveness of our model with reflection-free flash-only cues: our model outperforms state-of-the-art reflection removal approaches by more than 5.23dB in PSNR, 0.04 in SSIM, and 0.068 in LPIPS. Our source code and dataset are publicly available at {github.com/ChenyangLEI/flash-reflection-removal}.
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 10, 2021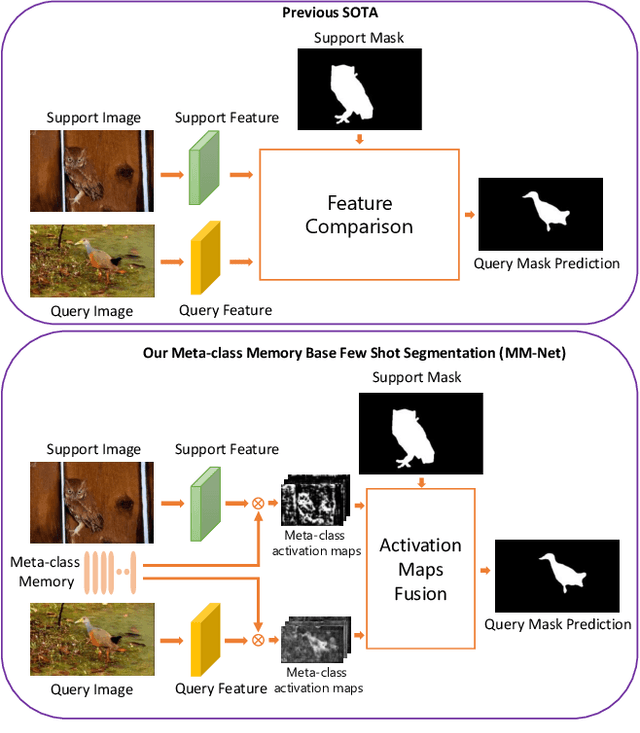
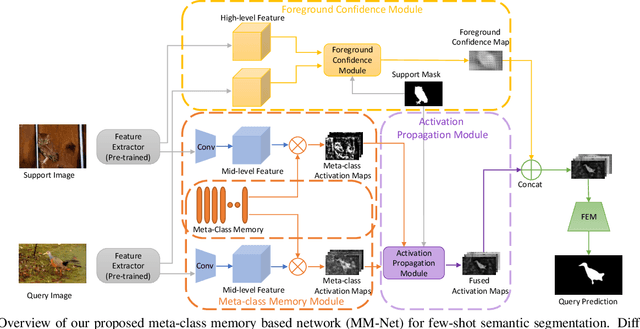
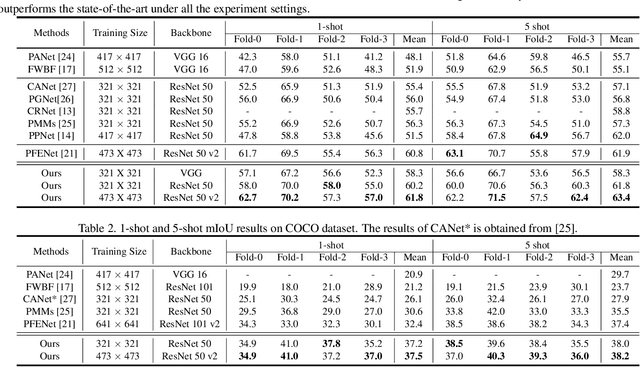
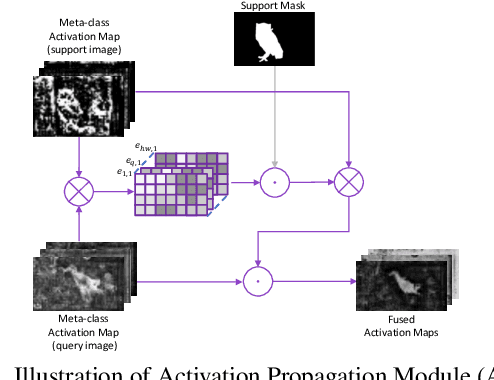
Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.
Intermediate Layers Matter in Momentum Contrastive Self Supervised Learning
Oct 27, 2021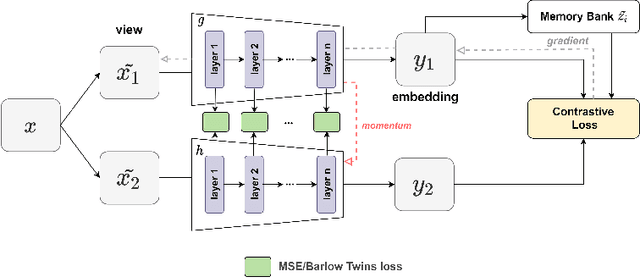
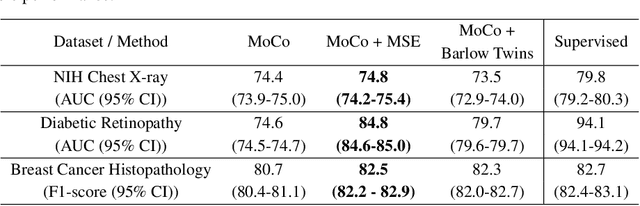
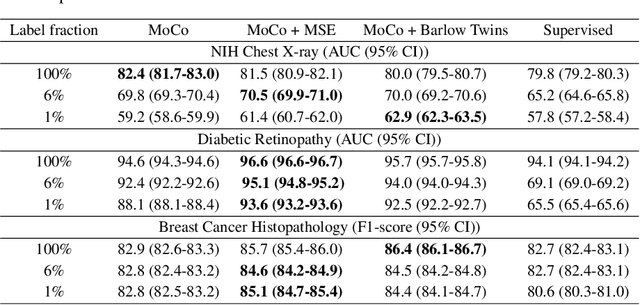
We show that bringing intermediate layers' representations of two augmented versions of an image closer together in self-supervised learning helps to improve the momentum contrastive (MoCo) method. To this end, in addition to the contrastive loss, we minimize the mean squared error between the intermediate layer representations or make their cross-correlation matrix closer to an identity matrix. Both loss objectives either outperform standard MoCo, or achieve similar performances on three diverse medical imaging datasets: NIH-Chest Xrays, Breast Cancer Histopathology, and Diabetic Retinopathy. The gains of the improved MoCo are especially large in a low-labeled data regime (e.g. 1% labeled data) with an average gain of 5% across three datasets. We analyze the models trained using our novel approach via feature similarity analysis and layer-wise probing. Our analysis reveals that models trained via our approach have higher feature reuse compared to a standard MoCo and learn informative features earlier in the network. Finally, by comparing the output probability distribution of models fine-tuned on small versus large labeled data, we conclude that our proposed method of pre-training leads to lower Kolmogorov-Smirnov distance, as compared to a standard MoCo. This provides additional evidence that our proposed method learns more informative features in the pre-training phase which could be leveraged in a low-labeled data regime.
Understanding the Intrinsic Robustness of Image Distributions using Conditional Generative Models
Mar 01, 2020


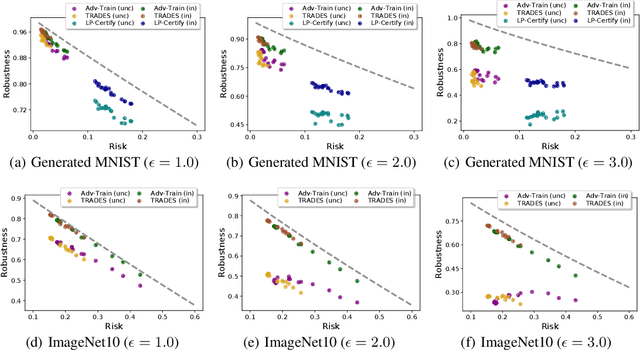
Starting with Gilmer et al. (2018), several works have demonstrated the inevitability of adversarial examples based on different assumptions about the underlying input probability space. It remains unclear, however, whether these results apply to natural image distributions. In this work, we assume the underlying data distribution is captured by some conditional generative model, and prove intrinsic robustness bounds for a general class of classifiers, which solves an open problem in Fawzi et al. (2018). Building upon the state-of-the-art conditional generative models, we study the intrinsic robustness of two common image benchmarks under $\ell_2$ perturbations, and show the existence of a large gap between the robustness limits implied by our theory and the adversarial robustness achieved by current state-of-the-art robust models. Code for all our experiments is available at https://github.com/xiaozhanguva/Intrinsic-Rob.